基于圖像識別的防瞌睡系統設計
2022-03-24 09:11:44林盛楠
科技創新與應用 2022年6期
林盛楠
(武警工程大學密碼工程學院,陜西 西安 710086)
作者簡介:林盛楠(1999-),女,碩士研究生在讀,研究方向為圖像識別。
DOI:10.19981/j.CN23-1581/G3.2022.06.032
為保障單位安全,單位內部設有值班室。事實證明,因為生理疲勞等客觀原因,僅從規章制度上難以有效地杜絕值班人員瞌睡情況發生。值班人員由于工作壓力大、休息時間不夠及心理情緒影響等因素,均可能導致在值班時瞌睡,從而不能履行好職責導致事故發生。因此,通過圖像識別的方法揭示值班人員的瞌睡特征,實時準確地對值班人員瞌睡狀態進行檢測,并確保正常值班的情況下給出預警機制,可以很大程度上減少安全事故的發生。本文針對值班人員打瞌睡不履職盡責的情況,設計依托Python Dlib 庫和OpenCV 的圖像識別技術實現的非接觸防瞌睡系統。在詳細介紹圖像采集、圖像處理的基礎上,進一步比較判定值班人員處在正常或者疲勞狀態并用聲光提示。
目前,對人員瞌睡檢測的研究已經有很多,基于人員生理特征的檢測方法主要有5 種:檢測頭部狀態、檢測瞳孔信息、檢測腦電信號、檢測脈搏頻率和檢測眼睛活動信息[1]。本課題選擇非接觸式眼動信息檢測技術,對值班人員的瞌睡程度進行24 h 實時檢測,如果結合“人形”檢測還可以進一步拓展“脫崗”檢測等功能。
本文介紹了一種基于圖像識別的防瞌睡系統,該防瞌睡系統通過攝像頭采集到值班人員人臉的圖像,利用人臉檢測技術定位人臉區域并進行人眼定位與人眼疲勞狀態分析,當檢測到值班人員瞌睡時,能及時對值班人員進行預警。
1 系統基本結構
本系統主要完成對攝像頭獲得的圖像進行分析處理,判定值班人員是否瞌睡,主要包括:利用攝像頭進行圖像采集;對采集到的圖像進行人臉檢測;在檢測人臉的基礎上進行人眼定位;提取人眼特征點位置;對人眼狀態進行識別;判定值班人員是否瞌睡和對處理結果進行分析處理。若判定瞌睡則報警,否則返回,重新檢測圖像(圖1)。
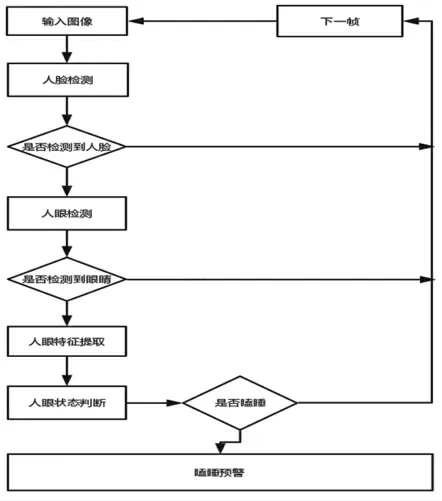
圖1 系統流程圖
通過對目前人臉檢測技術的對比,本系統人臉檢測部分采用基于Haar 特征的AdaBoost 算法,實效性高。人眼定位技術采用Dlib 開源庫通過OpenCV 圖像處理進行人臉特征點定位,準確性高,最后利用EAR 值判定值班人員狀態。
2 系統各部分設計
該系統主要由圖像數據采集、圖像識別以及瞌睡判定與預警3 部分組成。圖像識別包括了人臉檢測和人眼定位,是整個系統的關鍵技術。該系統的各部分內容如下。
2.1 人臉檢測
人臉識別[2]的關鍵環節是人臉檢測,由于人臉特征中具有灰度特征,例如,眼睛通常比臉頰顏色深;鼻梁的兩側比鼻梁顏色深;嘴巴顏色比周圍顏色深。因此,可以簡單地用矩形特征(Haar 特征)描繪面部特征。通過特征模板圖像窗口的大小位置變換得到的特征稱為矩形特征。Haar 特征的數值編碼反映了人臉圖像的灰度級。在對人臉進行檢測時,人臉特征可以通過對Haar 特征的編碼進行描述。在固定樣本的前提下,Haar 特征的檢測編碼能夠準確地顯示指定區域的形態,而且其檢測速度比用像素檢測的編碼系統要好得多。因此,防瞌睡系統采用基于Haar 特征的AdaBoost 算法進行人臉檢測。
積分圖[3]模型是一種能夠描述圖像中全局矩形特征信息的矩陣表示方法。Viola 將積分圖[4]應用到計算Haar特征中。定義圖像中坐標為(x,y)的點的積分圖=此點左上角方向上所有像素值的和,點(x,y)的積分圖等于陰影部分的所有像素和。通過一個圖像區域端點的積分圖能夠計算該圖像區域的像素值。
AdaBoost[5]是集成學習系統中的最常用的特征分析方法之一,它將許多弱分類器的特征分析與結合,達到一個強分類器h(x,f,p,θ)的特征分類和訓練效果。在確定各訓練窗口樣本中Haar 特征的數量和特征值后,對Haar特征窗口中的每一個矩形特征f,訓練弱分類器,x 是一個24×24 大小的子窗口,p 是表示不等號的特征方向,θ是Haar 特征的閾值。
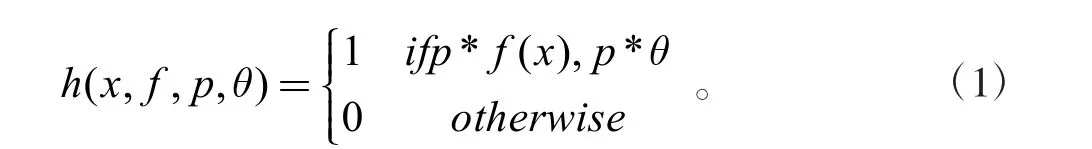
級聯分類器是由幾個簡單分類器和AdaBoost 強分類器連接而成的。分類器訓練過程:
選擇一個級聯分類器每層的誤檢率f;檢測率d,標準誤檢率Ftarget;
設P 為一組正例,N 為一組負例;
初始值設F0=1.0,D0=1.0;令i=1;
當Fi>Ftarget時;i=i+1;ni=0,Fi=Fi-1;
當Fi>f×Fi-1;ni=ni+1;
訓練一個有n 個特征的級聯分類器;
分類器的數量每層遞增,訓練得出Fi和Di;
訓練直至完全達到目標分類器的檢測準確率和誤檢率。
綜上所述,基于Haar 特征的AdaBoost 人臉檢測算法共包括4 部分:Haar 特征、積分圖快速計算像素值、AdaBoost 訓練強分類器和將多個強分類器級聯的級聯分類器,提高人臉檢測精確度。
進行人臉檢測時,由于人臉大小具有差異性,可選擇2 種方式實現檢測:縮小檢測圖像和放大檢測窗口。縮小檢測圖像的方法是固定檢測窗口不變,將檢測圖像進行大小變換,將變換后的圖像通過檢測窗口進行圖像輸入。放大檢測窗口的方法是保持檢測圖像不變,將檢測窗口進行大小變換,然后依次使用變換后的檢測窗口檢測圖像。
由于人臉尺寸不同,放大檢測窗口不易控制變換程度,可能會造成漏檢率或誤檢率上升。因此,本系統采用縮小檢測圖像的方法進行人臉檢測。
2.2 人眼定位
人臉檢測技術已經解決了圖上是否有人臉的問題,人眼定位解決了人眼的位置問題。通過ERT 算法訓練,在Python 中建立了Dlib 官方開源庫[6],效果較好。因此,本系統在Python 平臺下采用Dlib 庫進行人眼定位。
Python Dlib 庫是在Python3 中用于在人臉圖像處理的經典模型庫,Dlib 庫中有一個經過ERT 算法訓練的人臉關鍵點[7]檢測器,在利用AdaBoost 算法確定人臉大致位置后,在OpenCV 平臺下使用Dlib 庫正式訓練的68 點模型“shape_predictor_68_face_landmarks.dat”進行圖像處理,在人臉上繪制68 個點并顯示序列號。通過Dlib 庫人臉識別68 特征點檢測,分別獲取左右眼面部標志的索引,利用OpenCV 對視頻流進行灰度化處理,檢測出人眼的位置信息。利用數字序號定位人眼[8],使用該模型庫可以方便地用于人臉檢測和簡單的應用(圖2)。
2.3 瞌睡狀態檢測指標
在人臉特征點68 位定位中可以看到37-42 為左眼位置,43-48 為右眼位置。當人眨眼時,這6 個點之間的距離會發生變化(圖2)。

圖2 人臉特征點位置編號示意圖
本防瞌睡系統主要提取值班人員眼睛狀態的EAR值[9]指標,基于EAR 值在視頻處理序列的基礎上,判定值班人員瞌睡狀態。其中,指標定義如下:
EAR(Eye Aspect Ratio)是描述眼睛張開程度,即眼睛縱橫比。利用上下眼皮特征點之間的距離描述眼睛張開程度,當EAR 低于閾值時,眼睛處于閉合狀態。
在進行人眼定位后,開始根據人眼定位坐標計算眼睛縱橫比EAR,根據大量實驗數據顯示,正常狀態下,人眼縱橫比大概在0.2~0.3 之間。在本系統中,設定閾值為0.2。當前幀2 只眼睛縱橫比與前1 幀的差值的絕對值大于0.2,則認為值班人員處于瞌睡狀態[10](圖3)。

圖3 眼長寬比方程
在OpenCV 平臺下,構造函數計算左右眼EAR 值,而后求平均值作為最終的EAR 值與設定的閾值做對比,若小于閾值,則更換下一個值班室的攝像頭繼續檢測,若連續3 次小于閾值,則屏幕顯示睡著,判定值班人員瞌睡,并發出警報聲,對值班人員進行預警,然后重置眼幀計數器,繼續檢測。
3 實驗與結果
實驗中主要運用前文所說的原理和方法,軟件編程[11]實現,并對人臉檢測和人眼定位算法進行測試。在進行檢測人臉的過程中,利用Python 平臺和OpenCV 中訓練好的基于Haar 特征的AdaBoost 級聯分類器來進行對人臉的檢測。檢測中,通過ORL 人臉數據庫人臉檢測技術的準確率進行測試,并通過統計得出算法的測試結果,最后對測試結果的準確率進行分析。在人臉檢測的基礎上,通過標定人臉特征點方法進行人眼定位,得出測試結果,并分析該方法的檢測準確率。
3.1 人臉檢測結果分析
本系統中,通過OpenCV[12]中已經訓練好的級聯分類器檢測人臉,由于值班室一般是單人執勤,所以在檢測過程中,我們只取單人的圖像來驗證算法的精確度。因此,本系統使用ORL 人臉數據庫來檢測系統的精確度。ORL人臉數據庫包含40 個人在不同表情下的人臉圖像共400 張,圖片大小為92×112(單位/像素)。部分樣本如圖4所示。

圖4 ORL 人臉數據庫
利用OpenCV 中已經訓練好的人臉分類器進行人臉數正確檢測,測試結果見表1。

表1 人臉檢測結果
上述數據表明,本系統進行人臉檢測時具有較高的精確度,對于復雜的光照環境,仍能精確檢測到人臉。部分正確的檢測結果如圖5 所示。但本系統使用的是OpenCV 平臺[13]中訓練好的級聯分類器,還不夠精確,但能夠說明基于Haar 算法的AdaBoost 算法在人臉檢測上可以滿足本系統對于人臉檢測實效性和準確性的需求。

圖5 人臉正確檢測結果
3.2 人眼定位結果分析
在本系統人眼定位技術中,采取利用Python Dlib 開源庫進行人臉特征點定位的方法進行檢測,測試樣本集仍采用ORL 人臉數據庫,在檢測到人臉的基礎上繼續定位人眼,定位結果見表2。

表2 人眼定位檢測結果
根據以上結果可以發現,基于Dlib 庫的人臉特征點定位法對人眼進行定位的精確度較高,同時定位速率也較快,符合本系統實時性和實效性要求。部分正確定位人眼的結果如圖6 所示。但若人眼附近有遮擋物,眉毛與眼睛相近時,很可能導致因定位相近而無法定位眼睛準確位置,從而無法檢測。當圖像分辨率小于63×74 時,無法識別圖像中人臉及人眼位置,當圖像亮度為-129 或+125時,圖像也無法識別。

圖6 人眼正確定位測試結果
3.3 人眼狀態檢測結果分析
對于人眼狀態檢測,本系統利用EAR 值即眼睛縱橫比進行判定,設定閾值為0.2,若檢測到的EAR 值小于0.2,則判定為閉眼。檢測中仍采用ORL 人臉數據庫作為測試樣本集。由于需先定位到人眼,才能檢測到閉眼情況,因此此次檢測在人眼定位結果下繼續進行。
對人眼狀態的檢測結果見表3。

表3 人眼狀態檢測結果
下面是部分誤檢的圖像,如圖7 所示。

圖7 人臉錯誤檢測圖像
通過以上檢測結果發現,錯識誤識人眼狀態的主要原因有:人臉視線向下、人眼區域光照不均勻和人眼的個體性強、不能適應閾值設置等。
實驗結果表明:使用EAR 值作為眼睛的閉合標準準確率較高,閾值設定為0.2 也比較符合人眼的生理特征。因此,本系統使用EAR 值檢測法具有較高的精確度,同時算法簡便,也符合值班室檢測環境。
4 結論
本系統通過攝像頭對值班人員臉部圖像進行采集,通過對人眼狀態的檢測判定值班人員是否瞌睡。檢測指標為眼睛縱橫比EAR 值。本系統檢測的主要步驟為人臉采集與檢測和人眼定位與狀態識別。采集到圖像后進行人臉檢測,確定人臉位置后進行人眼定位和人眼狀態分析。本系統主要使用在OpenCV 中訓練好的級聯分類器來進行人臉檢測,在此基礎上通過Dlib 庫進行了人眼識別與人眼定位,而后利用EAR 值進行人眼狀態判斷,最后通過眨眼次數判定值班人員是否瞌睡。實驗結果證明,本系統可實時有效地檢測值班人員是否瞌睡。繼續優化級聯分類器算法,精確分析值班人員眼部狀態是下一步研究的重點。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(2017年9期)2017-09-26 03:41:45
