基于LSTM模型對印度新冠肺炎疫情的預測
2022-03-21 14:29:56王劍輝蔣杏麗
沈陽師范大學學報(自然科學版) 2022年6期
王劍輝, 蔣杏麗
(沈陽師范大學 數學與系統科學學院, 沈陽 110034)
0 引 言
印度于2020年1月30日報告了首例新冠肺炎疫情確診病例,隨后疫情在印度蔓延并暴發。截至文章成稿時,印度累計確診人數已經超過了4 000萬,僅次于美國[1]。新冠肺炎疫情很難被預知和掌控,很多學者建立神經網絡模型來預測新冠的傳播規律和發展趨勢。
機器學習和人工智能(artificial intelligence)算法被廣泛用于預測分析和模式識別[2]。國內外眾多研究者也利用機器學習[3]和SEIR(susceptible-exposed-infectious-recovered)模型[4]去分析并預測新冠肺炎疫情。Hidayat等[5]利用線性回歸、向量自回歸和多層感知機模型來預測印度新冠肺炎疫情。Saleh等[6-7]使用差分自回歸移動平均(auto regressive integrated moving average model,ARIMA)模型預測西班牙、意大利等受疫情影響較大的國家的經濟狀況。與循環神經網絡(recurrent neural network,RNN)[8]相比,LSTM在處理時間序列并具長期記憶的數據時更有優勢,它更適用于對長序列數據進行分類、處理及預測[9-10]。
首先采集印度確診病例數據,數據預處理并劃分后應用到LSTM模型上,在訓練的過程中使用Adam優化器不斷優化模型直至完成所定義的Epoch。
1 數據集提取與LSTM模型
1.1 LSTM數據集
研究使用的數據集是印度在2022年3月1日至2022年11月8日期間的新冠肺炎累計確診病例, 數據來源于印度疫情實時大數據報告網站。 將建模需要的確診病例提取出來, 部分確診病例數據見表1。
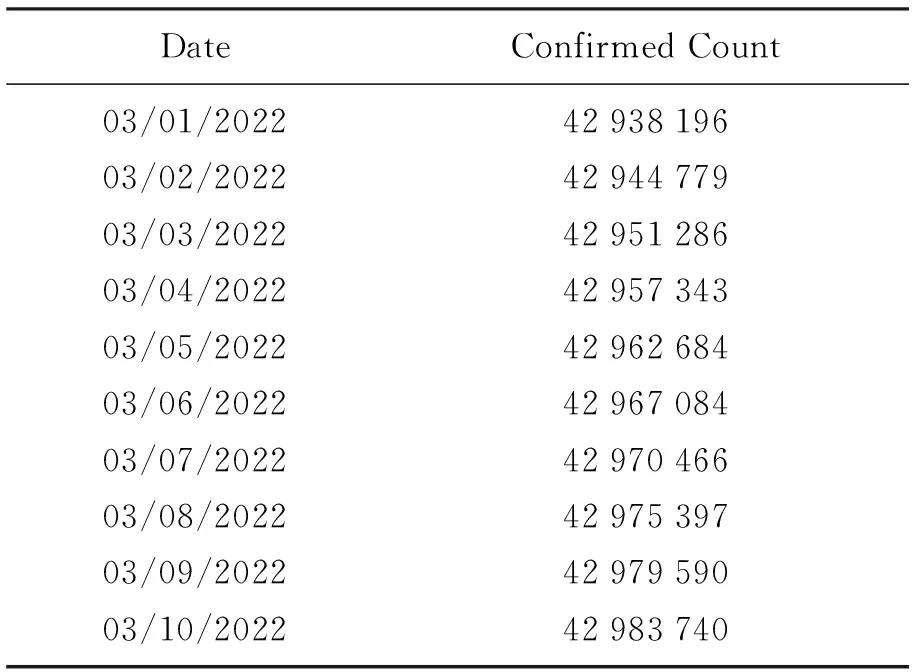
表1 部分印度每日確診病例數
數據預處理后,將3月1日至9月7日期間的數據按7∶3的比例劃分為訓練集和測試集2個部分。其中,訓練集用來訓練LSTM模型[11]使其參數最優化,測試集對建立的預測模型進行驗證并調試參數。為了能實現根據已知確診病例來預測未來任意一段時間內確診病例的目的,將后3個月(9月8日至11月8日)的數據用于模型實際應用,以便于觀察出模型的預測效果。
1.2 LSTM預測模型
LSTM模型是由Hochreiter和Schmidhuber于20世紀90年代提出的一種特殊的RNN,它很好地解決了RNN梯度消失和梯度爆炸等重大問題。LSTM模型結構如圖1所示。
在某一時刻,LSTM的輸入包括當前時刻網絡的輸入值xt、上一時刻LSTM的輸出值ht-1以及上一時刻的單元狀態ct-1;輸出包含當前時刻LSTM的輸出值ht和當前時刻的單元狀態ct。在LSTM中,有3個門[12]來控制長期狀態,每個門[13]利用sigmoid函數來篩選數據,0代表不通過,1代表通過。
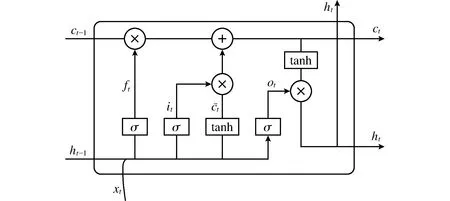
圖1 LSTM模型內部結構Fig.1 Internal structure of LSTM model
2 LSTM預測模型的建立及評估
建立LSTM模型預測印度某段時間內新冠肺炎疫情的確診數, 模型分為輸入層、LSTM層和輸出層。 輸入層中節點數是提取到的數據數量, LSTM隱藏層數設置為4, 輸出層引入一個全連接層來將最后結果降成一維并輸出。 將參數Batch_Size設置為1, Epoch設置為100, 學習率設置為0.001, 此外還使用了Adam算法[14]作為模型優化器, 將MSE作為模型的損失函數, 選用準確度作為模型的評價指標。 對比LSTM和SVM模型的準確度得到二者的擬合效果, 準確度越大說明模型預測效果越好。
圖2為印度在3月1日至9月7日的新冠肺炎確診病例折線圖。
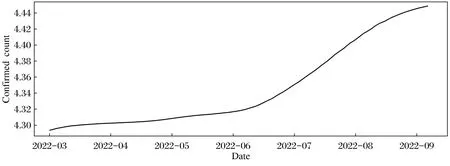
圖2 每日確診病例數Fig.2 Daily number of confirmed cases
將3月1日至9月7日數據的70%用于訓練模型,剩下的數據用于對模型進行測試。最后結果如圖3和圖4所示,建立的預測模型的損失值隨著Epoch增大而減小,模型的真實值與預測值擬合效果較好。
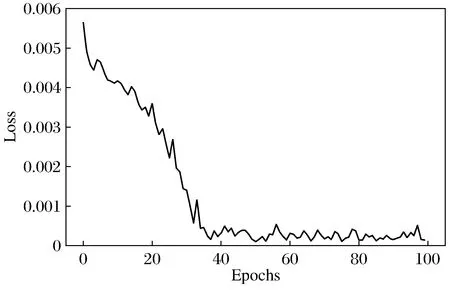
圖3 LSTM模型損失值Fig.3 Loss value of LSTM model

圖4 模型預測值與真實值對比
訓練好LSTM模型后,圖5為模型對印度9月8日至11月8日預測的確診病例數,圖6是同樣時間段印度疫情實際確診病例數統計,對比可知模型確實能夠成功預測未來某段時間內的新冠肺炎疫情發展情況。最終得到LSTM預測模型的準確度為87.49%,而SVM模型的準確度僅為73.25%,表明在新冠肺炎疫情預測的效果上LSTM更準確。

圖5 60天內確診病例預測數Fig.5 Prediction of confirmed cases within 60 days
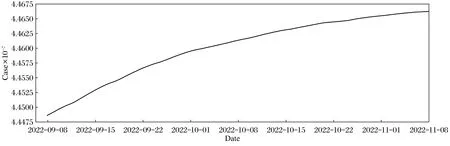
圖6 確診實際數據Fig.6 Actual data of confirmed cases
3 結 論
本文收集印度新冠肺炎累計確診病例數后,運用深度學習中的LSTM算法對其某一段時間內的累計確診病例數進行預估。目前使用LSTM模型預測印度新冠肺炎病例數的研究并不多,由于數據大小受限,該模型的預測準確率還需要進一步提高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂天地(音樂創作版)(2022年1期)2022-04-26 13:51:10
中外文摘(2021年23期)2021-12-29 03:54:04
幼兒100(2021年8期)2021-04-10 05:39:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年5期)2020-09-25 08:56:22
快樂作文(1.2年級)(2020年8期)2020-09-10 07:22:44
數學物理學報(2020年2期)2020-06-02 11:29:24
37°女人(2020年5期)2020-05-11 05:58:52
光學精密工程(2016年6期)2016-11-07 09:07:19
