基于知網的詞語語義相似度改進算法研究*
2022-03-17 10:16:44MariusPetrescu潘俊輝王浩暢
計算機與數字工程 2022年2期
王 輝 Marius.Petrescu 潘俊輝 王浩暢 張 強
(1.東北石油大學計算機與信息技術學院 大慶 163318)(2.普洛耶什蒂石油天然氣大學 普洛耶什蒂 100680)
1 引言
詞語相似度計算在面向各領域的自動問答系統、詞語語義排歧、信息檢索等方面都有著廣泛的應用[1]。目前,中文詞語語義相似度計算方法大致可分為兩類:一類是依賴大規模語料庫統計詞語相關性,如利用相關熵[2]或平均互信息[3]等計算詞語相似度,計算過程復雜,計算結果受訓練數據噪聲和數據稀疏影響;另一類是根據世界知識(Ontology)或某種分類體系(Taxonomy),借助現有同義詞詞林[4]、WordNet[5]、知網[6]等,分析詞語在樹型結構中的語義信息進行詞語相似度計算,計算方法簡單有效,易受個體主觀意識影響。然而,專家所劃分的詞語知識概念體系具有一定權威性,根據概念關系計算詞語相似度計算也更合理。
與WordNet 和同義詞詞林不同,知網作為目前國內詞語語義研究的主流工具,其是一部比較詳盡的詞語語義知識詞典,采用多維知識表示形式描述一個詞的語義。因此,基于知網的中文詞語語義相似度的計算,可歸結為義項各組合間的相似度計算,進而逐步歸結為義原相似度的計算[7]。如,張碩望等考慮了詞語與義原之間的包含關系[8],王小林等簡化了義原分類[9],吳華等提取詞語的上下文語境特征作為語義承載單元[10]。
在基于本體知識的相似度算法基礎上,本文深入研究知網描述語言特征和結構,綜合考慮義原距層次樹根節點深度、義原所在區域密度及其主次關系對義原相似度的影響,提出一種義原相似度計算改進方法,進而得到了新的詞語語義相似度算法。
2 基于知網的詞語語義相似度計算
2.1 知網
1988 年,中科院計算機語言信息工程研究中心董振東提出,自然語言處理系統需要強大的知識庫支持,應首先建立一種以中英文詞語代表的概念為描述對象,以揭示概念間及其屬性間的關系為基本內容的常識知識庫[11]。數年后,此庫被稱為知識系統的常識性知識庫,即知網(HowNet)。自1999年公布以來,知網作為一部詳盡的語義知識詞典,已被廣泛應用于自然語言處理、機器翻譯等方面的研究。
知網與其他樹狀詞匯數據庫有著本質不同,知網的哲學和根本特性決定了它獨特的建設方法,其側重利用中文詞語意義結構特征來分析和提取義素,采用一套基于義原和關系的結構化標注語言——知識庫描述語言(KDML)標注語義。
在知網中,主要包含“義項“和“義原”兩個概念,每個漢語詞語均由義項的集合語義來描述,義項由“知識表示語言”——義原來定義,義原則是描述概念的、不可再分的最小意義單位[12]。每個漢語詞語的義項可分為虛詞義項和實詞義項,其中實詞義項集合語義可由四類義原集合描述組成,即第一基本義原描述、其他基本義原描述、關系義原描述、關系符號描述[13]。
2.2 詞語語義相似度計算
假設有兩個中文詞語w1和w2,若w1涉及n個義項:s11,s12,…,s1n,w2涉及m 個義項:s21,s22,…,s2m,詞語w1和w2語義相似度sim(w1,w2)定義為涉及到的各個義項間相似度最大值[14],如式(1)所示。
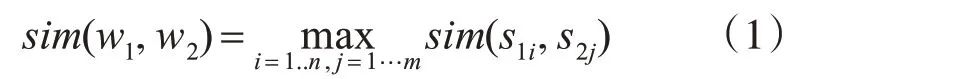
式中,sim(s1i,s2j)為義項s1i與s2j之間相似度。故,詞語語義相似度計算歸結為義項相似度的計算。
2.3 義項相似度計算
知網中,義項分為虛詞義項與實詞義項,因此,義項相似度計算分為虛詞義項相似度計算和實詞義項相似度計算。
2.3.1 虛詞義項相似度計算
由于虛詞本身沒有詞匯意義的特點,虛詞與實詞不可以互相替換,導致虛詞義項與實詞義項的相似度總是歸為零[15]。虛詞義項總是用句法義原或關系義原描述,故為得到虛詞義項相似度,實際需要計算的是其對應的句法義原或關系義原之間相似度。
2.3.2 實詞義項相似度計算
實詞義項是用語義表達式來描述的,故為得到整體的實詞義項相似度,應分別計算第一基本義原描述式、其他基本義原描述式、關系義原描述式及關系符號描述式四類義原集合的相似度。
1)第一基本義原描述式
指描述該實詞最基本語義特征的義原,也是對最重要的一個描述式,相似度記為sim1(s1,s2)。
2)其他基本義原描述式
指除第一基本義原外,用基本義原(或具體詞)描述的所有其他基本義原(或具體詞),相似度記為sim2(s1,s2)。
3)關系義原描述式
指描述式中每個特征屬性都是關系義原,如“關系義原=基本義原”或者“關系義原=(具體詞)”,相似度記為sim3(s1,s2)。
4)關系符號描述式
指所有用符號義原描述的描述式,如“關系符號基本義原(具體詞)”,相似度記為sim4(s1,s2)。
因此,可用虛詞義項和實詞義項的各部分相似度表示義項整體相似度,如式(2)所示。
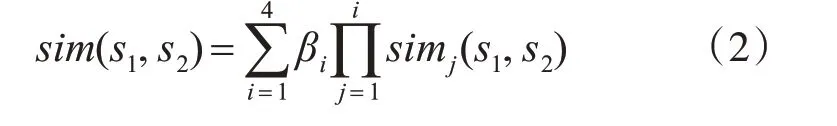
式中,βi(1 ≤i≤4)為可調節的參數,且有β1+β2+β3+β4=1,β1≥β2≥β3≥β4。后者不等式反映了sim1到sim4對義項相似度的影響依次減弱,由于第一基本義原描述式反映的是義項最貼切、最主要的特征,sim1影響最大,一般β1≥0.5。因此,義項相似度的計算可歸結于義原相似度計算。
2.4 義原相似度計算
義原相似度是由義原的語義距離計算得到的,所有義原根據上下位關系均構成樹狀義原層次體系。然而,分屬不同義項領域的多棵樹狀義原層次樹并無交集,不同樹的義原間沒有任何可行路徑,語義距離也不存在,這類義原相似度為零。屬于同一棵樹的不同義原之間存在可行路徑,劉群等提出可利用義原節點在樹狀結構的距離關系來計算這類義原相似度[11],如式(3)所示。
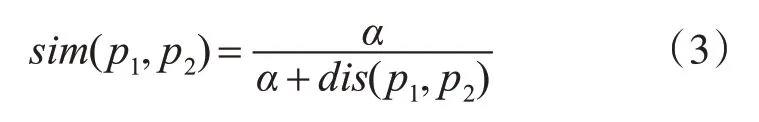
式中,p1和p2為兩個義原;dis(p1,p2)為義原p1和p2處于同棵義原樹的義原距離,當兩義原分屬不同樹時,dis(p1,p2)取一個較大常數,一般取值為20[16];α為可調節的參數,取值為1.6。
3 改進的詞語語義相似度計算方法
Rigau 在利用Wordnet 計算詞語的語義相似度時,提出在義原樹中,影響義原距離最主要的兩個因素是義原深度與義原密度[11]。義原深度指義原距所在層次體系樹根節點的路徑長度,長度越短,其表達的概念(即義項)越抽象,反之,表達的概念越具體。義原深度相同的兩個節點,若位于層次樹的越底層,其語義距離較大。義原密度(即義原區域密度)指義原所在層次體系樹的同層兄弟節點總數(含自身),總數越大,則說明分類越細致,其攜帶的語義信息越詳細。路徑長度相同的兩個節點,若位于層次樹中的高密度區域,其語義距離應大于位于低密度區域的相同路徑長度的兩個節點。
因知網中均采用單個義原描述第一基本義原,導致其距離義原樹的根節點很近,義原深度與密度對第一基本義原影響不大,本節僅改進除第一基本義原之外的義原相似度算法。
本節參照張小川等利用距離約束最小層次義原深度因素,保證義原距離對相似度計算結果主導作用的方法[6],以及葛斌等提到的綜合考慮義原層次樹的深度、密度等因素對義原節點權重的影響[17],改進式(2)得到新的義原相似度計算方法,如式(4)所示。

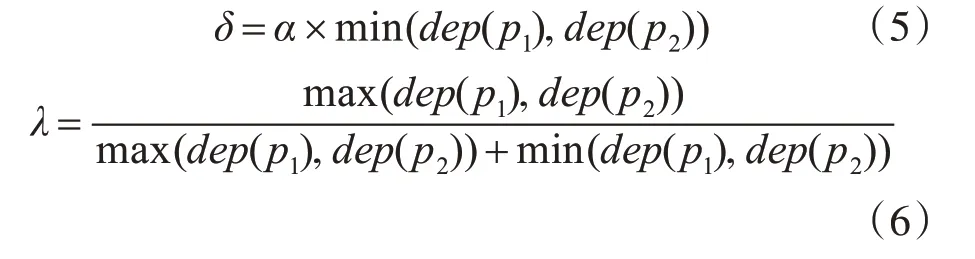
式中,sim(p1,p2) 為義原p1和p2的相似度;dis(p1,p2) 為義原距離;min(dep(p1),dep(p2)) 為義原最小深度;max(dep(p1),dep(p2))為義原最大深度;G是義原p1和p2的最小公共父節點;f(·)為當前義原的兄弟節點個數,能夠反映其所在樹中的密度信息;γ1+γ2=1,γ1和γ2為權重因子,分別取值為0.5;α和ε為調節參數,取值分別為0.5和2。
李蕾等認為義原深度越大,義原距離越小;義原密度越大,義原距離越小。綜合考慮義原深度與義原密度,設置權重因子來限制義原深度與義原密度的影響[18],將dis(p1,p2)義原距離取為邊權重之和,如式(7)所示。

式中,weight(ip,q)為層次樹種每條邊的權重,隨層數遞增而單調遞減;ip,q為義原p與q之間的邊;q是義原p的上一層父節點;depth為當前義原層次樹樹高;kp為義原p所在層編號;max 為義原p所在樹中所有義原節點總數;c1+c2=1,c1和c2為權重因子,分別取值為0.7和0.3;θ為調節參數,取值為4。
4 實驗結果與分析
本文的實驗數據來自《知網》網站(http://www.keenage.com/)。根據文獻[11]多次嘗試中取得的經驗,結合多次實驗,設置了實驗參數值,如表1 所示。
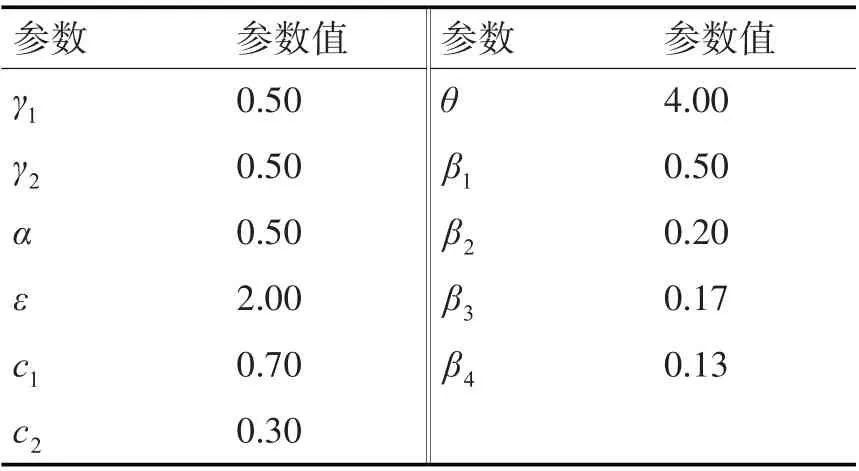
表1 實驗參數設置
本文實驗使用5 種不同方法來計算比較義原相似度,實驗結果如表2 所示。方法1 為文獻[11]算法;方法2 為文獻[6]算法;方法3 為文獻[17]算法;方法4為文獻[18]算法;方法5為本文算法。
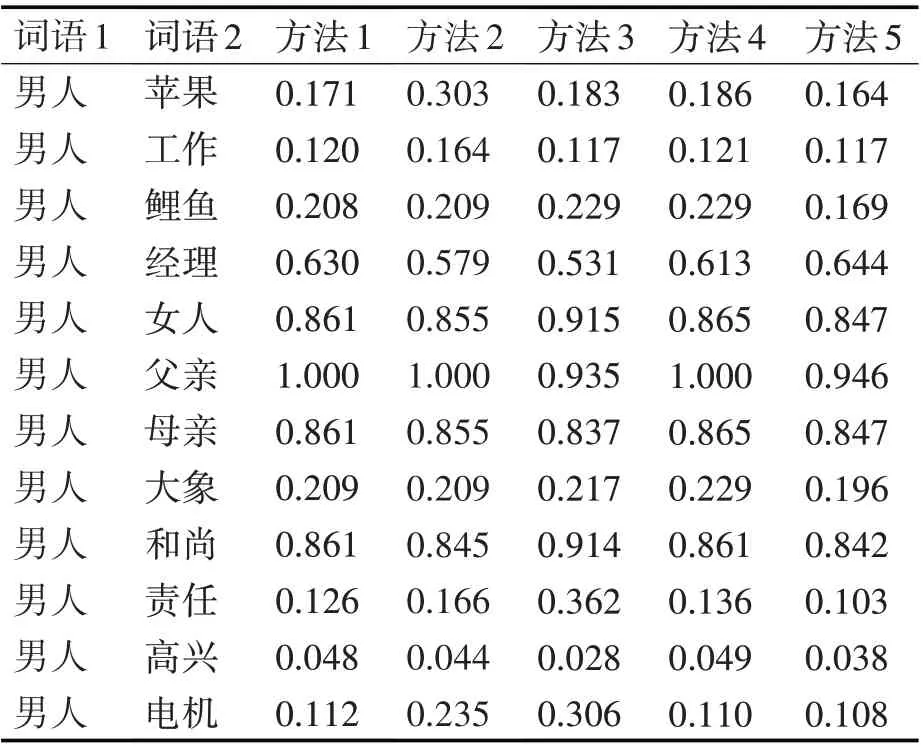
表2 實驗結果對比
方法1 僅考慮了詞語中義原距離因素,沒有考慮義原層次樹種節點深度與區域密度的影響,因而實驗結果比較粗糙,如“男人-女人”、“男人-母親”相似度相同,且接近于“男人-父親”相似度。方法2 與1 比較,部分數據有所降低,主要是因為方法2在義原語義相似度計算中用集合的加權平均值代替了最大值,使得實驗結果稍客觀,效果不夠明顯。方法3與方法1、2比較,由于加入了層次權重,可以比較細膩地區別不同詞匯,更符合人為認知判定標準,比如“男人-母親”相似度明顯降低;“男人-父親”相似度在前兩個方法中相同,但在方法3中有所降低,這是符合人為判定標準的。但也有不太合理的地方,比如“男人-女人”相似度在前三個方法中,均得到了大于或等于“男人-和尚”相似度的數值。方法4 與前三個方法比較,由于加入了調整義原深度與密度主次關系的權重因子,大部分相似度更加合理,只出現了個別相似度遺漏,比如“男人-父親”相似度重新回到方法1的數值。方法5與前四個方法比較較為合理,在深入分析義原深度、義原區域密度及其主次關系之后,將詞語語義相似度刻畫較為細致,使得原本相似度高的詞計算出的相似度更高,反之原本相似度低的詞計算出的相似度更低;又因為參考了方法3 的層次權重,更好呈現出了符合人為認知判定的實驗結果,比如“男人-父親”相似度沒有重新回到方法1的數值。
5 結語
不同于其他語義詞典,知網采用了上千個義原,通過KDML描述每個義項。為了更好地計算兩個詞語語義表達式相似度,本文將其分解成多個部分語義表達式,在保證義原距離對最終相似度計算結果的主導作用前提下,綜合考慮了義原距離、義原深度、義原密度對義原相似度的影響,構建出一種新的詞語語義相似度計算方法,結合實驗結果對比分析,驗證了該算法更為合理和準確。但由于漢語詞匯本身的復雜性、多義性等因素,詞語語義相似度計算仍有很大的研究空間,今后將側重從信息論的角度深入研究義原樹中擁有的信息量對相似度的影響。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
