單圖像盲去模糊方法概述
2022-03-13 09:18:46劉利平高世妍
計(jì)算機(jī)與生活 2022年3期
劉利平,孫 建,高世妍
華北理工大學(xué) 人工智能學(xué)院,河北 唐山063210
在現(xiàn)代信息社會(huì),圖像已經(jīng)成為人們獲取事物信息的主要工具,人類獲取的海量數(shù)據(jù)有一半以上來自圖像。近年來隨著科學(xué)技術(shù)的不斷進(jìn)步和圖像采集方法的多樣化,圖像數(shù)據(jù)大多來自手持和手機(jī)攝像頭、衛(wèi)星、閉路電視等圖像資源。由于拍攝和成像過程的不完善,圖像很難避免拍攝的圖片有退化的趨勢(shì)。在拍攝過程中,手機(jī)或者數(shù)碼相機(jī)光學(xué)缺陷或者鏡頭對(duì)焦不準(zhǔn)確難免會(huì)使記錄的照片出現(xiàn)模糊的現(xiàn)象。模糊圖像是在記錄某些時(shí)刻畫面時(shí)經(jīng)常出現(xiàn)的一種現(xiàn)象,圖像去模糊的目的是以盡可能低的代價(jià)從模糊的圖像中恢復(fù)出比較清晰的原始圖像。
近年來,單幀運(yùn)動(dòng)模糊圖像的去模糊問題越來越得到人們的關(guān)注。從二十世紀(jì)六七十年代就被Stockham等人和Oppenheim等人當(dāng)作案例處理卷積問題,從而也證明了是可以通過圖像處理算法對(duì)運(yùn)動(dòng)模糊圖片進(jìn)行盲去模糊的。與此同時(shí),F(xiàn)ergus 等人也通過應(yīng)用自然圖像先驗(yàn)和先進(jìn)的統(tǒng)計(jì)技術(shù),從照片中消除相機(jī)抖動(dòng)效應(yīng),而且采用貝葉斯框架進(jìn)行求解最大后驗(yàn)概率估計(jì)(maximum a posteriori estimation,MAP),從而達(dá)到去除模糊的效果。因?yàn)榛趫D像盲去模糊的問題大都是在估計(jì)模糊核的基礎(chǔ)上進(jìn)行的,所以在接下來的幾年里,學(xué)者大都是在MAP 的框架上拓展研究的。直到Y(jié)ou 等人提出一種新的變分模型來處理模糊核的估計(jì)問題。在后續(xù)研究中,Chan 等人、Krishnan 和Fergus相繼提出了全變分模型和拉普拉斯分布的方法來進(jìn)行運(yùn)動(dòng)圖像的盲去模糊,兩者之間相輔相成,對(duì)模糊核的估計(jì)和還原出清晰的圖像有著較大的影響。
1 傳統(tǒng)的單圖像盲運(yùn)動(dòng)去模糊方法
全局運(yùn)動(dòng)模糊圖像復(fù)原:(1)基于極大后驗(yàn)估計(jì)的方法。2013 年,Pan 等人首次利用圖像梯度的范數(shù)來構(gòu)建正則化先驗(yàn)。2016 年,Pan 等人利用自然圖像的重尾分布提出了一種超拉普拉斯先驗(yàn)。同年,Pan 等人將圖像的強(qiáng)度以及梯度先驗(yàn)進(jìn)行結(jié)合,提出一種針對(duì)文本圖像的正則化先驗(yàn)。接下來,Pan等人在He 等人啟發(fā)下率先提出了在圖像去模糊領(lǐng)域采用暗通道先驗(yàn)方法能夠取得比較好的實(shí)驗(yàn)效果。同時(shí),Yan 等人也提出了一種亮通道先驗(yàn),并將其與暗通道先驗(yàn)相結(jié)合提出了一種極端通道先驗(yàn)去模糊的方法。(2)基于邊緣估計(jì)的方法。Joshi等人從單個(gè)模糊圖像中以邊緣子像素分辨率估算非參數(shù)、空間變化的模糊函數(shù),從而估算出模糊核達(dá)到去模糊的效果。Jia在研究了物體邊界透明度和圖像模糊之間的關(guān)系后,將圖像去模糊分為濾波器估計(jì)和圖像去卷積過程,并提出了一種從alpha 值的角度估計(jì)運(yùn)動(dòng)模糊濾波器的新算法,將濾波器估計(jì)公式轉(zhuǎn)化為解決具有定義的可能性和先驗(yàn)透明性的最大后驗(yàn)(MAP)問題,從而更好去處理模糊圖像。
局部運(yùn)動(dòng)模糊圖像復(fù)原:(1)經(jīng)典單層圖像模型方法。Bar 等人及Sorel 等人分別采用了一層圖像模型和一個(gè)空間變化的點(diǎn)擴(kuò)散函數(shù)(point spread function,PSF)來對(duì)圖像的部分模糊進(jìn)行去除。(2)適度用戶交互的局部估計(jì)技術(shù)去模糊方法。研究人員借鑒摳圖技術(shù)提出了兩層圖像模型,通過消光技術(shù)、強(qiáng)大的圖像先驗(yàn)?zāi)P秃陀脩舻膸椭瑢?shí)現(xiàn)了前景層和背景層的同時(shí)恢復(fù),取得了良好的實(shí)驗(yàn)效果。(3)完全自動(dòng)化的局部估計(jì)技術(shù)去模糊。Bae 等人提出了一種增加圖像散焦的圖像處理技術(shù),以模擬具有較大孔徑的透鏡的淺景深。Dai等人利用光流約束和運(yùn)動(dòng)模糊約束之間的相似性解決了許多空間變化的運(yùn)動(dòng)模糊估計(jì)問題。Joshi 等人從單個(gè)圖像以亞像素分辨率估計(jì)非參數(shù)的、空間變化的模糊函數(shù),用來測(cè)量由有限的傳感器分辨率造成的模糊,即使對(duì)于對(duì)焦圖像也可以通過估計(jì)亞像素、超分辨率的PSF 來實(shí)現(xiàn)。Levin將圖像分割成具有不同模糊的區(qū)域,將模糊部分能用單個(gè)核來建模,并且可以用相同的核去卷積整個(gè)圖像減輕形成的偽影。表1 顯示了更多的傳統(tǒng)的圖像盲去模糊的方法。

表1 傳統(tǒng)的盲去模糊方法Table 1 Traditional blind deblurring methods
2 基于深度學(xué)習(xí)的單圖像盲去模糊方法
卷積神經(jīng)網(wǎng)絡(luò)盲去模糊:使用卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)對(duì)圖像進(jìn)行去模糊并提高其分辨率(超分辨率)已得到廣泛且成功的研究。基于卷積神經(jīng)網(wǎng)絡(luò)的圖像運(yùn)動(dòng)模糊恢復(fù)方法利用了圖像局部權(quán)值共享的優(yōu)點(diǎn)。卷積運(yùn)算可以方便地處理高維數(shù)據(jù),避免特征提取過程中數(shù)據(jù)重構(gòu)的復(fù)雜性。圖像運(yùn)動(dòng)去模糊的早期工作只能滿足整個(gè)圖像的均勻運(yùn)動(dòng)模糊。Fergus 等人提出方法是首先確定模糊核,然后執(zhí)行反卷積以校正相機(jī)抖動(dòng)來避免圖像模糊。Cronje通過使用卷積神經(jīng)網(wǎng)絡(luò)估計(jì)圖像塊的運(yùn)動(dòng)矢量,將所有預(yù)測(cè)的運(yùn)動(dòng)矢量組合起來,以形成密集的非均勻運(yùn)動(dòng)估計(jì)圖,準(zhǔn)確地確定了不均勻的運(yùn)動(dòng)模糊并恢復(fù)模糊的圖像。Xu 等人提出了一種用于圖像去模糊的深度學(xué)習(xí)算法,它能夠?qū)W習(xí)從模糊圖像中提取尖銳邊緣以進(jìn)行內(nèi)核估計(jì),且不需要啟發(fā)式邊緣選擇步驟或在圖像去模糊中廣泛使用的從粗到細(xì)的策略,極大地簡(jiǎn)化了核估計(jì)過程并降低了計(jì)算成本。針對(duì)傳統(tǒng)盲去模糊算法中需要估計(jì)模糊核的問題,Hradi?等人以端到端的方式專門針對(duì)文本圖像訓(xùn)練了一個(gè)深層的CNN 模型,可以直接從模糊的輸入中重建高質(zhì)量的圖像,而無(wú)需假設(shè)任何特定的模糊和噪聲模型。Schuler等人提出了一種神經(jīng)網(wǎng)絡(luò)來估計(jì)模糊核,以進(jìn)行通用圖像去模糊。然而,該方法需要針對(duì)不同大小的內(nèi)核訓(xùn)練不同的網(wǎng)絡(luò),由于實(shí)際情況下的運(yùn)動(dòng)模糊相當(dāng)復(fù)雜而限制了其應(yīng)用的領(lǐng)域。
循環(huán)神經(jīng)網(wǎng)絡(luò)盲去模糊:循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)因其在順序信息處理中的優(yōu)勢(shì)而成為一種流行的去模糊工具。循環(huán)神經(jīng)網(wǎng)絡(luò)同樣也適用于圖像盲去模糊中,其具有記憶功能的神經(jīng)網(wǎng)絡(luò),在某種程度上創(chuàng)新于卷積神經(jīng)網(wǎng)絡(luò),適合序列數(shù)據(jù)的建模,還應(yīng)用于圖像處理領(lǐng)域。Zhang 等人提出了一種用于動(dòng)態(tài)場(chǎng)景去模糊的新型端到端空間變異遞歸神經(jīng)網(wǎng)絡(luò),其中RNN 的權(quán)重是由深層CNN 來學(xué)習(xí)的,通過分析提出的空間變體RNN 與去卷積過程之間的關(guān)系,表明了空間變體RNN 能夠?qū)θツ:^程進(jìn)行建模,得到訓(xùn)練后的模型明顯更小。另外,Tao 等人提出了一個(gè)標(biāo)度遞歸網(wǎng)絡(luò),以及每個(gè)標(biāo)度中的編碼器-解碼器ResBlocks 結(jié)構(gòu),新的網(wǎng)絡(luò)結(jié)構(gòu)比以前的多尺度去模糊參數(shù)具有更少的參數(shù),并且更易于訓(xùn)練,取得了良好的實(shí)驗(yàn)效果,并為后續(xù)的研究提供了新的方向。
對(duì)抗網(wǎng)絡(luò)盲去模糊:隨著人工智能的興起,生成式對(duì)抗網(wǎng)絡(luò)(generative adversarial networks,GAN)也日益廣泛應(yīng)用到圖像處理領(lǐng)域,從低分辨率(low resolution,LR)對(duì)應(yīng)物估計(jì)高分辨率(high resolution,HR)圖像再到現(xiàn)在對(duì)模糊圖像的處理,越來越得到了人們的重視。生成對(duì)抗網(wǎng)絡(luò)被用于去模糊,是因?yàn)樗鼈冊(cè)诒A艏y理細(xì)節(jié)和生成逼真圖像方面具有優(yōu)勢(shì)。2014 年Goodfellow 等人提出一種新型的深度學(xué)習(xí)模型-生成式對(duì)抗網(wǎng)絡(luò)。在圖像去模糊的應(yīng)用中,對(duì)抗網(wǎng)絡(luò)的生成器根據(jù)鑒別器的判別結(jié)果進(jìn)行優(yōu)化,鑒別器嘗試從生成的圖像中判別出清晰的圖像,直到鑒別器無(wú)法從生成的圖像中分辨出清晰的圖像,此時(shí)生成器的去模糊效果達(dá)到最佳。
近年來,GAN 網(wǎng)絡(luò)在圖像領(lǐng)域表現(xiàn)得越來越突出,Ledig 等人提出一種用于圖像超分辨率(superresolution,SR)的生成對(duì)抗網(wǎng)絡(luò),其運(yùn)用的深層殘差網(wǎng)絡(luò)能夠在公共基準(zhǔn)上從大量降采樣后的圖像中恢復(fù)逼真的紋理,且在均值評(píng)分(mean opinion score,MOS)測(cè)試顯示,使用SRGAN(super-resolution generative adversarial networks)可以顯著提高感知質(zhì)量,因此該方法可以很好地應(yīng)用到圖像的去運(yùn)動(dòng)模糊問題當(dāng)中。Chen 等人對(duì)于解決由于天基成像系統(tǒng)抖動(dòng)或觀測(cè)目標(biāo)運(yùn)動(dòng)而導(dǎo)致圖像退化的去模糊問題,結(jié)合WGAN(Wasserstein GAN)網(wǎng)絡(luò)提出了一種利用生成對(duì)抗網(wǎng)絡(luò)實(shí)現(xiàn)端到端圖像處理的無(wú)需在軌核估計(jì)運(yùn)動(dòng)去模糊策略,證明了該方法的可行性和有效性,同時(shí)表現(xiàn)出在定量和定性方面均優(yōu)于現(xiàn)有的遙感圖像盲去模糊算法。2018 年,Kupyn 等人首先根據(jù)條件對(duì)抗網(wǎng)絡(luò)去除相機(jī)抖動(dòng)的模糊,然后提出一種無(wú)核盲運(yùn)動(dòng)去模糊學(xué)習(xí)方法來彌補(bǔ)之前的不足,使用多分量損失函數(shù)進(jìn)行優(yōu)化的條件對(duì)抗網(wǎng)絡(luò)Deblur-GAN,對(duì)不同的模糊源進(jìn)行建模,極大地幫助了對(duì)模糊圖像的檢測(cè)。與此同時(shí),在2019 年,Kupyn 等人首次將特征金字塔網(wǎng)絡(luò)引入去模糊,并提出了一種新的端到端生成對(duì)抗網(wǎng)絡(luò)DeblurGAN-v2,用于單圖像運(yùn)動(dòng)去模糊,大大提高了去模糊的效率、質(zhì)量和靈活性。表2 顯示了更多的深度學(xué)習(xí)圖像盲去模糊方法。

表2 基于深度學(xué)習(xí)的盲去模糊方法Table 2 Blind deblurring method based on deep learning
3 圖像盲去模糊的關(guān)鍵工作
3.1 數(shù)據(jù)集的構(gòu)建
傳統(tǒng)數(shù)據(jù)集中的大部分模糊圖像都是通過一些固定核進(jìn)行模糊處理的,很難模仿自然的模糊圖像。當(dāng)使用機(jī)器學(xué)習(xí)中的算法處理某些問題時(shí),數(shù)據(jù)集的質(zhì)量直接會(huì)影響到算法運(yùn)行的結(jié)果,因此高質(zhì)量的數(shù)據(jù)集在研究后續(xù)問題中占有重要的地位。在當(dāng)下去模糊的工作當(dāng)中,很難在同角度、同位置且光線不變的情況下拍攝出一對(duì)清晰和模糊的圖像,相比于一些局部圖像恢復(fù)的數(shù)據(jù)集而言,對(duì)圖像去模糊的數(shù)據(jù)集的獲取標(biāo)準(zhǔn)更高一些,因此根據(jù)現(xiàn)有技術(shù)可以將數(shù)據(jù)集構(gòu)造方法分為以下三類。
第一類是由圖像處理算法合成數(shù)據(jù)集。數(shù)據(jù)集可以像Levin 等人和Sun 等人由清晰圖像數(shù)據(jù)集圖像與模糊核卷積得到模糊圖像的數(shù)據(jù)集。同樣也可以像Lai 等人和Kupyn 等人一樣利用模擬生成的運(yùn)動(dòng)軌跡算法生成模糊核來構(gòu)造模糊圖像的數(shù)據(jù)集,雖然容易獲得,但是該方式在三維平面上構(gòu)造的運(yùn)動(dòng)模糊中存在很多的不足。
第二類是由攝像機(jī)運(yùn)動(dòng)軌跡綜合的模糊數(shù)據(jù)集,最典型的就是Kohler 等人在2012 年提出的Kohler數(shù)據(jù)集。Kohler數(shù)據(jù)集由4個(gè)圖像組成,每個(gè)圖像有12 個(gè)不同的內(nèi)核,這是用于評(píng)估盲去模糊算法的標(biāo)準(zhǔn)基準(zhǔn)數(shù)據(jù)集。隨著科學(xué)技術(shù)的進(jìn)步,2017 年Nah 等人采用高速攝影機(jī)獲得了當(dāng)前最大的GOPRO 模糊數(shù)據(jù)集。GOPRO 數(shù)據(jù)集是隨著時(shí)間的推移整合清晰的圖像來模糊圖像。而且GOPRO還可以模擬自然場(chǎng)景中的圖像模糊類型,其中包含2 103 個(gè)用于訓(xùn)練的圖像對(duì)和1 111 個(gè)在測(cè)試集中的圖像對(duì)。通過這類方式構(gòu)建的數(shù)據(jù)集雖然比較繁瑣,但是較第一類方式更能真實(shí)地模擬出生成運(yùn)動(dòng)模糊圖片的過程。
第三類是現(xiàn)實(shí)場(chǎng)景中拍攝的模糊圖像數(shù)據(jù)集,不會(huì)進(jìn)行任何的后期算法處理。通過這種方式獲得的圖像數(shù)據(jù)集只有模糊的圖片,無(wú)法使用深度學(xué)習(xí)的算法對(duì)該方式生成的模糊圖像進(jìn)行訓(xùn)練,但依舊可以被用來作為測(cè)試集對(duì)去模糊后的圖片進(jìn)行檢測(cè)評(píng)估。
3.2 圖像去模糊后的質(zhì)量評(píng)價(jià)方法
圖像質(zhì)量的評(píng)價(jià)可分為主觀評(píng)價(jià)和客觀評(píng)價(jià)。主觀評(píng)價(jià)主要是對(duì)人的視覺感官進(jìn)行評(píng)價(jià),而客觀評(píng)價(jià)則采用一種評(píng)價(jià)標(biāo)準(zhǔn)來比較圖像質(zhì)量。常用的客觀評(píng)價(jià)方法有峰值信噪比(peak signal to noise ratio,PSNR)和結(jié)構(gòu)相似性(structural similarity,SSIM)。峰值信噪比反映了估計(jì)圖像和原始清晰圖像的失真程度。一般來說,峰值信噪比越大,圖像恢復(fù)效果越好。它的表達(dá)式為:

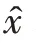

SSIM 是比較全面的圖像評(píng)價(jià)指標(biāo),分別從亮度、對(duì)比度和結(jié)構(gòu)相似度評(píng)價(jià)圖像,其中u、u分別表示圖像和的均值,σ、σ分別表示圖像和的方差,σ表示圖像和的協(xié)方差。SSIM 衡量的是兩幅圖像的相似度,其值在0 到1 之間,越趨近于1說明相似度越高,復(fù)原的結(jié)果越好。
3.3 實(shí)驗(yàn)評(píng)估
為了比較傳統(tǒng)去模糊方法及深度神經(jīng)網(wǎng)絡(luò)去模糊方法的去模糊性能,對(duì)部分去模糊方法在GoPro 數(shù)據(jù)集、Kohler數(shù)據(jù)集、Lai數(shù)據(jù)集中的“face2”公共數(shù)據(jù)集、Helen數(shù)據(jù)集、CelebA數(shù)據(jù)集和實(shí)拍模糊圖像上進(jìn)行了定量和定性的評(píng)估實(shí)驗(yàn)。定量評(píng)估主要是使用不同去模糊方法的峰值信噪比(PSNR)和結(jié)構(gòu)相似性(SSIM)的值來測(cè)試去模糊的效果。定性評(píng)估則是使用視覺圖形來直觀地對(duì)去模糊后的圖像進(jìn)行評(píng)估。
在單圖像盲運(yùn)動(dòng)去模糊實(shí)驗(yàn)中,為了直觀對(duì)比傳統(tǒng)優(yōu)化模型的去模糊性能,本文選擇Kohler 數(shù)據(jù)集上的自然圖像定性評(píng)估算法的優(yōu)劣性能。圖1 顯示了四種傳統(tǒng)優(yōu)化模型在Kohler 的某個(gè)數(shù)據(jù)集上去模糊的效果,其中(a)~(d)的去模糊算法實(shí)驗(yàn)均是在Windows10 系統(tǒng)下的Matlab 2020 中完成。為了使實(shí)驗(yàn)的精度和速度達(dá)到平衡,實(shí)驗(yàn)中設(shè)置步長(zhǎng)為0.1,=5,=10 和一些超參數(shù)==0.004,=2。通過比較這幾種方法,和較先進(jìn)的Pan 等人的方法相比,Li的方法可以生成更清晰的圖像和更少的振鈴偽影。為了評(píng)估深度學(xué)習(xí)技術(shù)對(duì)模糊圖像的去模糊性能,Kupyn等人選擇了Lai公共數(shù)據(jù)集中“face2”圖像進(jìn)行測(cè)試。圖2 展示了幾種傳統(tǒng)優(yōu)化模型和深度學(xué)習(xí)模型在Lai 數(shù)據(jù)集的“face2”測(cè)試圖像的定性比較。其中(a)、(b)、(c)、(d)、(f)的去模糊算法是在Windows10 系統(tǒng)中Python=3.6 搭載PyTorch1.4.0環(huán)境下完成的,(e)、(g)算法是在Windows10 系統(tǒng)的Matlab 2020 中完成的,(h)算法是在Windows10 系統(tǒng)的OpenCV 中完成的。結(jié)果表明,利用DeblurGANv2 算法和SRN-DeblurNet 算法得到的圖像是當(dāng)中表現(xiàn)得較好的兩個(gè)結(jié)果,兩者都在邊緣銳度和整體平滑度之間取得了很好的平衡。但是通過仔細(xì)觀察,發(fā)現(xiàn)SRN 在這個(gè)圖像上仍然會(huì)產(chǎn)生一些鬼影,例如,從衣領(lǐng)到右下面部區(qū)域的白色“侵入”,但DeblurGANv2 算法與其他神經(jīng)網(wǎng)絡(luò)和傳統(tǒng)算法相比,模型無(wú)偽影,圖像表現(xiàn)得更平滑,視覺上更令人愉悅。因此DeblurGAN-v2 無(wú)偽影去模糊性能較圖2 中其他方法更加突出。

圖1 Kohler數(shù)據(jù)集中鐘擺圖像不同方法去模糊后的結(jié)果Fig.1 Results of different methods of deblurring pendulum image in Kohler dataset

圖2 Lai數(shù)據(jù)集的“face2”測(cè)試圖像的定性比較Fig.2 Qualitative comparison of“face2”test images of Lai dataset
為了更好地評(píng)估一些去模糊方法的性能,將傳統(tǒng)的部分去模糊方法與深度學(xué)習(xí)的方法進(jìn)行了定量的比較,其中包括4 種傳統(tǒng)的去模糊模型優(yōu)化方法,10 種深度學(xué)習(xí)的去模糊方法。為了比較不同方法對(duì)圖像去模糊后的復(fù)原程度,在GoPro 和Kohler數(shù)據(jù)集中選擇出設(shè)定好的訓(xùn)練集和測(cè)試集統(tǒng)一進(jìn)行對(duì)比評(píng)估。傳統(tǒng)的去模糊方法在Windows10系統(tǒng)下的Matlab 2020 中完成;深度學(xué)習(xí)去模糊算法在Windows10 系統(tǒng)中Python=3.6 搭載PyTorch1.4.0 環(huán)境下完成,使用ADAM(adaptive moment estimation)優(yōu)化器,設(shè)置學(xué)習(xí)速率為10,每次學(xué)習(xí)150個(gè)歷元,線性衰減至10,保存預(yù)先訓(xùn)練的主干權(quán)重3 個(gè)歷元,然后保存所有的權(quán)重并繼續(xù)訓(xùn)練,最終利用訓(xùn)練好的權(quán)重對(duì)測(cè)試集進(jìn)行評(píng)估。表3 顯示了不同網(wǎng)絡(luò)和優(yōu)化技術(shù)在GoPro數(shù)據(jù)集上的PSNR 和SSIM 結(jié)果。傳統(tǒng)的優(yōu)化技術(shù)模型在GoPro 數(shù)據(jù)集上進(jìn)行定量評(píng)估中,通過比較這幾種方法的標(biāo)準(zhǔn)性能指標(biāo)(PSNR、SSIM),Whyte 等人的參數(shù)化幾何模型較其他方式效果較好;深度學(xué)習(xí)不同網(wǎng)絡(luò)模型在PSNR/SSIM方面定量評(píng)估中,Aljadaany等人提出的Dr-Net 網(wǎng)絡(luò)模型和Tao 等人提出的SRN 網(wǎng)絡(luò)模型較其他方式效果較好。表4 顯示了不同網(wǎng)絡(luò)和優(yōu)化技術(shù)在Kohler 數(shù)據(jù)集上的PSNR 和SSIM 結(jié)果。傳統(tǒng)的優(yōu)化技術(shù)模型在Kohler數(shù)據(jù)集上進(jìn)行定量評(píng)估中,通過比較這些方法的標(biāo)準(zhǔn)性能指標(biāo)(PSNR、SSIM),Xu 等人提出的去模糊優(yōu)化方式在該數(shù)據(jù)集上較其他方式效果較好;深度學(xué)習(xí)不同網(wǎng)絡(luò)模型在PSNR/SSIM 方面定量評(píng)估中,Aljadaany 等人提出的Dr-Net網(wǎng)絡(luò)模型和Tao等人提出的SRN網(wǎng)絡(luò)模型在Kohler數(shù)據(jù)集中較其他方式效果較好。

表3 GoPro 數(shù)據(jù)集上不同方法的PSNR 和SSIMTable 3 PSNR and SSIM of different methods on GoPro dataset

表4 Kohler數(shù)據(jù)集上不同方法的PSNR 和SSIMTable 4 PSNR and SSIM of different methods on Kohler dataset
在Kohler 數(shù)據(jù)集實(shí)驗(yàn)過程中,DR-Net 雖然達(dá)到了很高的峰值信噪比,但在PSNR 方面還沒有達(dá)到最好的水平。Xu 等人獲得了27.47 dB 的高值。盡管如此,DR-Net 在SSIM 方面獲得了最優(yōu)的0.865,Xu等人緊隨其后,為0.811。但是,Xu 等人在GoPro測(cè)試集上獲得了20.30 dB 的低分貝,而DR-Net 獲得了30.35 dB。這可能是因?yàn)閄u 等人需要對(duì)整個(gè)圖像進(jìn)行單一的模糊核估計(jì),同時(shí)也說明了Xu 等人對(duì)于空間上均勻的模糊(如Kohler 測(cè)試集中的模糊)有很好的處理性能。然而,GoPro 是一個(gè)具有空間異質(zhì)模糊的真實(shí)世界測(cè)試集,因此強(qiáng)制對(duì)整個(gè)圖像進(jìn)行單一內(nèi)核估計(jì)不是理想的方法,這導(dǎo)致Xu 等人在GoPro 上表現(xiàn)不佳,這也有助于證明DR-Net 沒有這個(gè)問題,可以很好地處理空間異構(gòu)模糊(它在GoPro測(cè)試集上獲得了最優(yōu)的技術(shù))。
在對(duì)人臉模糊圖像盲去模糊中,人臉等自然圖像的內(nèi)在語(yǔ)義結(jié)構(gòu)是一個(gè)重要的信息,可用于改善去模糊結(jié)果。很少有技術(shù)以語(yǔ)義標(biāo)簽的形式使用這些先驗(yàn)信息,這些方法沒有考慮到與人臉對(duì)應(yīng)的語(yǔ)義圖的類不平衡,與面部皮膚、頭發(fā)和背景標(biāo)簽相比,面部的內(nèi)部部分(如眼睛、鼻子和嘴巴)的代表性較少。表5展示了Helen數(shù)據(jù)集上的PSNR和SSIM 結(jié)果。表6 展示了CelebA 數(shù)據(jù)集 上的PSNR 和SSIM 結(jié)果。其中傳統(tǒng)的去模糊方法在Windows10 系統(tǒng)下的Matlab 2020中完成;深度學(xué)習(xí)去模糊算法在Windows10系統(tǒng)中Python=3.6 搭載PyTorch1.4.0 環(huán)境下,批次大小為16,學(xué)習(xí)率設(shè)置為0.000 2,使用ADAM 優(yōu)化器進(jìn)行訓(xùn)練完成。從表中的PSNR 和SSIM 值可以得出,基于傳統(tǒng)的MAP的方法Cho等人、Krishnan等人、Xu 等人、Shan 等人、Zhong 等人在去模糊人臉圖像方面效果較差,導(dǎo)致了較多的振鈴偽影,而Pan等人基于MAP 的人臉去模糊方法對(duì)噪聲不具有魯棒性,并且高度依賴于參考圖像的相似性。Nah 等人基于CNN 的方法沒有考慮人臉語(yǔ)義信息,從而產(chǎn)生過于平滑的結(jié)果。相比之下,雖然Shen 等人所提出的方法利用全局和局部人臉語(yǔ)義來恢復(fù)具有更多細(xì)節(jié)和更少視覺偽影的人臉圖像,但是Yasarla等人提出的不確定性引導(dǎo)多流語(yǔ)義網(wǎng)絡(luò)去模糊方法還要優(yōu)于Shen 等人提出的語(yǔ)義類方面的性能。此外,還利用Xu 等人、Zhong 等人、Shen 等人方法對(duì)部分真實(shí)模糊圖像進(jìn)行了實(shí)驗(yàn)。不同去模糊方法的結(jié)果如圖3 所示。其中(a)、(b)的去模糊算法是在Windows10 系統(tǒng)中Python=3.6 搭載PyTorch1.4.0 環(huán)境下完成的,去模糊算法(c)、(e)是在Windows10 系統(tǒng)的Matlab 2020 中完成的,去模糊算法(d)是在Windows10 系統(tǒng)的OpenCV 中完成的。從圖中可以看出,與最先進(jìn)的方法相比,Yasarla 等人提出的UMSN(uncertainty guided multi-stream semantic network)可以產(chǎn)生更清晰的圖像。例如,Xu 等人、Zhong等人方法產(chǎn)生包含偽像或模糊圖像的結(jié)果。如圖3的第1~6 張所示,Kupyn 等人、Shen 等人無(wú)法重建眼睛、鼻子和嘴巴。然而,眼睛、鼻子和嘴巴區(qū)域在對(duì)應(yīng)于Yasarla 等人使用的UMSN 方法中的圖像是清晰可見的。

圖3 真實(shí)模糊圖像上的去模糊后的結(jié)果Fig.3 Results of deblurring on real blurred image

表5 Helen 數(shù)據(jù)集上不同方法的PSNR 和SSIMTable 5 PSNR and SSIM of different methods on Helen dataset

表6 CelebA 數(shù)據(jù)集上不同方法的PSNR 和SSIMTable 6 PSNR and SSIM of different methods on CelebA dataset
為了使本文實(shí)驗(yàn)更具有參考價(jià)值,使用iPad 平板設(shè)備相機(jī)在現(xiàn)實(shí)生活中捕獲了一張分辨率為512×512 像素的運(yùn)動(dòng)模糊圖像,然后在Windows10 系統(tǒng)下的Matlab 2020 中用幾種傳統(tǒng)的優(yōu)化技術(shù)對(duì)模糊圖像進(jìn)行去模糊處理,其中設(shè)置步長(zhǎng)為0.1,=5,=10 和一些超參數(shù)==0.004,=2。圖4 顯示了捕獲的帶有星巴克模糊標(biāo)識(shí)圖像在幾種不同去模糊方法下的結(jié)果。從處理后的結(jié)果來看,Pan等人利用正則化強(qiáng)度梯度先驗(yàn)算法和Li 等人采用的基于數(shù)據(jù)驅(qū)動(dòng)判別性先驗(yàn)算法得到的圖像是當(dāng)中表現(xiàn)得較好的兩個(gè)結(jié)果。Krishnan 等人、Xu 等人和Pan 等人處理后的圖像有明顯的偽影,清晰度也很低。直觀對(duì)比來看,Li等人的方法生成的圖像更清晰且偽影更少。

圖4 不同方法對(duì)星巴克模糊圖像處理后的結(jié)果Fig.4 Results of different methods on Starbucks blurred image processing
綜上來說,通過比較這些方法的標(biāo)準(zhǔn)性能指標(biāo)(PSNR、SSIM)和視覺圖形結(jié)果可以很容易得出:傳統(tǒng)的優(yōu)化方法存在嚴(yán)重的振鈴偽影和較大的模糊,這是優(yōu)化方法的一個(gè)關(guān)鍵問題,但不影響深度學(xué)習(xí)方法。深度學(xué)習(xí)方法在小模糊和大模糊上表現(xiàn)出穩(wěn)定的性能,而優(yōu)化方法在從小模糊重建更清晰的邊緣方面做得很好,但在大模糊上表現(xiàn)不好。這些觀察結(jié)果表明,深度學(xué)習(xí)方法在小模糊上的性能仍需要改進(jìn)。
4 趨勢(shì)展望
圖像去模糊在圖像處理領(lǐng)域越來越得到學(xué)者的關(guān)注,無(wú)論是理論研究還是實(shí)際應(yīng)用方面都取得了較多的成果和進(jìn)展,但未來仍有一些待提高的方面有待完善和解決。
4.1 數(shù)據(jù)集的更新
在深度學(xué)習(xí)中,數(shù)據(jù)集的質(zhì)量直接影響著后續(xù)的實(shí)驗(yàn)效果,數(shù)據(jù)集的質(zhì)量和更新對(duì)圖像的去模糊有著較深的意義。現(xiàn)在常用的最大數(shù)據(jù)集為GOPRO 數(shù)據(jù)集,該數(shù)據(jù)集僅僅是擴(kuò)大了數(shù)據(jù)集的數(shù)量,得到的數(shù)據(jù)集多樣性不夠且場(chǎng)景太單一,甚至有的表現(xiàn)得運(yùn)動(dòng)模糊不是特別明顯。同樣其他一些由算法合成的數(shù)據(jù)集,數(shù)據(jù)量較少,在論證時(shí)表現(xiàn)得不夠充實(shí)。因此在當(dāng)前形勢(shì)下,需要對(duì)數(shù)據(jù)進(jìn)行豐富和更新,不僅要保證數(shù)據(jù)量充足,還要充分滿足實(shí)驗(yàn)的要求。
4.2 網(wǎng)絡(luò)結(jié)構(gòu)的改進(jìn)
隨著機(jī)器學(xué)習(xí)在圖像處理領(lǐng)域算法的成熟,深度學(xué)習(xí)的網(wǎng)絡(luò)結(jié)構(gòu)也變得越來越多樣化,因此由不同的需求對(duì)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行不同方向的創(chuàng)新和改進(jìn)變得很有必要。Yan 等人在進(jìn)行圖像去模糊中只是運(yùn)用了簡(jiǎn)單的生成網(wǎng)絡(luò),沒有延伸其網(wǎng)絡(luò)結(jié)構(gòu)。但是隨著網(wǎng)絡(luò)結(jié)構(gòu)的豐富,追求更高的去模糊效果,則需要在原來的網(wǎng)絡(luò)結(jié)構(gòu)模型結(jié)構(gòu)中進(jìn)行拓展和加深,而不再單單滿足于基礎(chǔ)的網(wǎng)絡(luò)結(jié)構(gòu)。
4.3 更客觀的評(píng)價(jià)指標(biāo)的提出
如今廣泛應(yīng)用的峰值信噪比和結(jié)構(gòu)相似性指數(shù)與人們的主觀感受相差甚遠(yuǎn),特別是當(dāng)圖像中存在不均勻運(yùn)動(dòng)模糊時(shí),因此在處理實(shí)驗(yàn)結(jié)果的時(shí)候,一個(gè)可參考的評(píng)價(jià)指標(biāo)能夠很好地對(duì)處理過后的去模糊圖像進(jìn)行評(píng)價(jià)和對(duì)使用算法的合理性進(jìn)行評(píng)估。隨著去模糊技術(shù)的發(fā)展,為了公平公正地對(duì)處理后的去模糊后圖像進(jìn)行評(píng)估,需要在該領(lǐng)域得到一種公認(rèn)的評(píng)價(jià)標(biāo)準(zhǔn),而不再是在論文后面還要附上人們的感知測(cè)試效果。
5 結(jié)束語(yǔ)
本文對(duì)圖像去模糊的傳統(tǒng)優(yōu)化方法以及深層神經(jīng)網(wǎng)絡(luò)方法進(jìn)行了比較、研究和總結(jié)。注意到在用深度學(xué)習(xí)去模糊的過程中,很難獲得包含成對(duì)的銳化和模糊圖像的數(shù)據(jù)集。到目前為止,最好的數(shù)據(jù)集是那些由相機(jī)和對(duì)象運(yùn)動(dòng)產(chǎn)生的高速視頻短序列的數(shù)據(jù)集,但這些數(shù)據(jù)集對(duì)于訓(xùn)練去模糊網(wǎng)絡(luò)仍然不理想。更重要的是,現(xiàn)有數(shù)據(jù)集沒有包含足夠的圖像訓(xùn)練去模糊網(wǎng)絡(luò)來處理不同的自然場(chǎng)景。可以在網(wǎng)絡(luò)上獲得大量的單獨(dú)的清晰和模糊的圖像,而使用未配對(duì)的圖像來訓(xùn)練去模糊網(wǎng)絡(luò)的方法將是一個(gè)突破。兩項(xiàng)開創(chuàng)性的研究最近展示了如何使用模糊特定的表示和特征解決以無(wú)監(jiān)督的方式訓(xùn)練去模糊網(wǎng)絡(luò)。但是,只有在表現(xiàn)出空間不變模糊的人臉圖像上才能取得成功,因此將無(wú)監(jiān)督學(xué)習(xí)擴(kuò)展到廣泛的自然圖像有著很大的潛力。現(xiàn)有的評(píng)估方法在實(shí)驗(yàn)過程中也有很多的不足。首先,合成的模糊圖像往往不能捕捉到真實(shí)運(yùn)動(dòng)模糊退化的復(fù)雜性和特征。對(duì)這些數(shù)據(jù)集的評(píng)價(jià)不能反映真實(shí)圖像上單幅圖像去模糊算法的性能。其次,現(xiàn)有的方法使用PSNR 和SSIM 來量化性能,這在圖像去模糊中不能很好地與人的感知相關(guān)。由于缺乏對(duì)人類感知的研究,很難對(duì)去模糊算法的性能進(jìn)行比較。針對(duì)評(píng)估方法的不足,在未來的實(shí)驗(yàn)中可以選擇許多全參考和非參考的圖像質(zhì)量度量指標(biāo)進(jìn)行評(píng)估,從而更好地量化去模糊的性能。最后,通過本文的論述、評(píng)估和分析,希望能夠?qū)ξ磥淼拿とツ:恼n題研究提供一定的理論基礎(chǔ)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
