解耦表征學習綜述
2022-03-10 11:03:48文載道王佳蕊王小旭
自動化學報 2022年2期
關鍵詞:模型
文載道 王佳蕊 王小旭 潘 泉
自動化系統,大到復雜的導彈制導、自動駕駛、飛行控制等運動系統,小到人臉圖像識別、行人流量檢測、視頻跟蹤監控等圖像/視頻解譯系統,均在國家、國防等重大生產、生活與管理進程中起到了不可替代的作用[1].隨著人工智能技術最近幾年的迅速發展,采集數據的自動、精準智能感知對整個系統的智能辨識與控制預測能力至關重要,備受研究者的廣泛關注[2].
人類作為目前最為智能的生物系統,能夠通過各類生物傳感器(眼睛、鼻子、耳朵等)接收周圍環境的視覺、嗅覺、聽覺等數據信號,并將這些數據送入大腦進行融合處理,挖掘出數據內部隱含的各類有效信息,通過持續性學習將其匯總為簡單的語義屬性,形成概念,建立起抽象的邏輯關聯規則,最終結合自身具備的常識形成完整知識體系,實現對各類復雜環境的智能化感知[3-4].例如,將圖1 (a)中從不同視角下拍攝得到的三幅不同交通圖像作為視覺數據輸入到人眼中,人類便能夠自主完成如下的層次化數據智能感知:
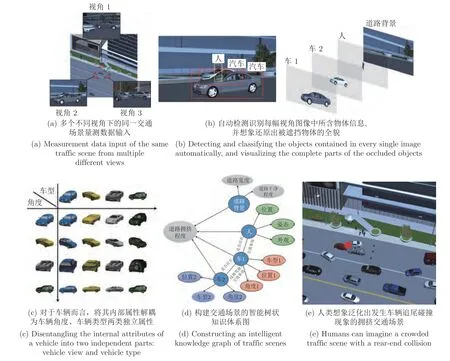
圖1 人類對于交通場景量測數據的層次化智能感知示意圖Fig.1 Humans' hierarchical intelligent perception of a traffic scene
1) 檢測并識別出圖像中不同姿態、不同風格的物體,并具有抗遮擋能力,能夠毫不費力地想象還原出被遮擋物體的全貌,如圖1 (b)所示;
2) 能夠全面有效剖析出每類物體的各個內在屬性并對該類物體進行全方位想象關聯.例如對于圖1 (c)中的車輛而言,假設將其內在屬性認知為車型、角度兩類,人類便可按照這兩類屬性對已有圖像進行相應的分組關聯,并能夠通過組合不同的屬性值想象出并未見過的車輛圖像.如此,面對存在車輛的各類未知新場景,人類能夠不受大差異性視角或新型車輛的影響,檢測并識別出各類不同的車輛,并能夠精確推理出每輛車的內在屬性值;
3) 能夠結合一些常識推理(例如兩輛車相對位置過近或人躺在車輛行駛正中間的馬路上時往往代表著交通事故的發生)構建出代表不同對象間交互關系的樹狀知識體系圖,如圖1 (d)所示.利用該知識體系圖,人類能夠通過對知識的改造重組想象泛化出各類符合因果邏輯關系的新場景,例如圖1 (e)中道路擁堵狀態下的交通事故新場景.該能力有助于人類對各類復雜場景進行因果知識關系梳理與認知更新,從而輕松完成類似智能知識問答等復雜圖像理解任務.
為了使現有系統真正實現對數據的自主智能感知,借鑒人類這種層次化數據智能感知思想,構建從數據、信息、語義、規則再到知識的多尺度、多層次、具有可解釋性的數據表征至關重要.
傳統模式識別主要依據特定領域的專家經驗知識進行顯式的特征設計與推理,從而完成相應任務.隨著誤差反向傳播(Back propagation,BP)人工神經網絡的提出,將傳統專家知識驅動的顯式特征提取方法替換為復雜數據驅動的神經網絡隱式特征提取方法逐漸引起了學術界的關注.尤其在Hinton等[5]提出以深度神經網絡為代表的深度學習技術后,相關以深度學習為主的隱式特征提取理論開始蓬勃發展,逐漸在語音識別[6-8]、自然語言處理[9-11]、人臉識別[12-14]、目標檢測[15-18]等領域取得突破性進展.截至目前,深度學習技術已被廣泛應用于多種復雜非線性系統的預測任務中[19].這類以提升特定預測任務性能指標為目的的判別式深度學習算法通過堆疊多層神經網絡來構建從原始的輸入數據到最終預測目標(如物體類別、位置、姿態等)的端到端非線性映射函數,使機器能夠從數據中自適應地進行學習,有效緩解傳統模式識別中手工設計選擇顯式特征的繁瑣低效問題[20].
然而現有以有監督深度網絡為代表的端到端黑箱判別式學習方法是一種捷徑學習(Shortcut learning)策略[21-22],即網絡學習得到的判別性隱式抽象特征往往沒有朝著人類所期望的方向進行泛化.如圖2 所示,對于圖2 (a)中所顯示的人類所具有的泛化能力并未被網絡所學到.與此相反,在圖2 (b)中,網絡學習得到的泛化能力又不能為人類所理解.發生這種現象的本質原因在于現有判別式網絡做出決策的評判標準僅僅為了提高訓練樣本數據的預測準確性.在這種評判標準下,網絡會自主選擇一條最容易、最精準地對訓練集擬合的方向進行學習,而這一方向并不一定是人類所期望網絡學習的方向.如圖3 所示,網絡學到得是所有決策空間中在訓練集上展現出良好性能的一部分決策,在這一部分決策內,僅有一小部分決策能夠泛化到服從獨立同分布特性(Independent and identically distributed,i.i.d) 的測試集上,即圖3 中的藍色區域.然而人類真正期望網絡做出的決策不僅能夠泛化到i.i.d 測試集上,而且能夠泛化到其余該分布以外(Out-of-distribution,o.o.d)的測試集中[23],即圖3中的紅色區域部分.現有大多數判別式網絡僅旨在尋找藍色區域內適應于i.i.d 測試集的決策空間,難以自主學到同時適應于o.o.d 數據集的紅色區域決策空間.例如圖2 (a)中,當網絡學習判斷圖像類別是否為貓時,很容易聚焦于圖像的紋理特征,而忽略整體的形狀特征,這使得一幅具有貓的形狀、大象紋理的圖像會被網絡判定為大象而不是貓;又如圖2 (b)中,網絡對于一把吉他類別的判斷可能僅在于評判其是否具有彎曲的紋理與線段等,這使得該網絡很容易將人類認為明顯不是吉他的圖像判定為吉他.因此現有深度網絡經常因為穩定性差、可解釋性弱、易受欺騙攻擊等飽受詬病[24-27].

圖2 深度網絡的捷徑學習(Shortcut learning)現象示例圖[21]Fig.2 Examples of “Shortcut Learning” in DNNs[21]
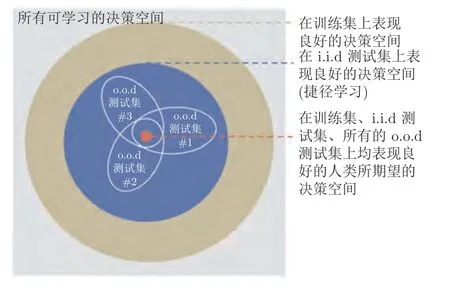
圖3 決策空間示意圖[21]Fig.3 Taxonomy of decision rules[21]
為了緩解上述問題,對網絡學習方向施加一定的歸納偏好約束,促使網絡挖掘數據中所蘊含的常識推理與因果邏輯關系[28-31],將有助于網絡像人類一樣學習從數據到信息到語義到規則再到知識的多尺度、多層次化數據表征.基于此,結合認知科學原理和視覺信息處理機制的解耦表征學習逐漸成為深度學習領域重要的研究方向[32-36].解耦表征學習旨在按照人類能夠理解的方式從真實數據中對具有明確物理含義的生成因子(如類別、位置、外觀、紋理等)進行解耦,并給出其所對應的獨立潛在表示,引起國內外大量學者的廣泛關注.
鑒于解耦表征學習深刻的理論意義,所蘊含的應用價值以及可觀的發展潛力,本文對解耦表征學習的研究進展進行了系統性的綜述,為進一步深入研究解耦表征學習機制、開發解耦表征學習應用潛力確立了良好的基礎.文中第1 節對解耦表征學習基本概念、發展歷史等進行了概述;第2 節著重介紹了從非結構化表征先驗正則角度分析解耦表征學習最初的幾種典型解決思路;第3 節則從結構化模型先驗歸納偏好的角度挖掘模型架構設計對于現有解耦表征學習的啟發;第4 節結合實際數據中所蘊含的物理知識對現有解耦表征學習研究進行進一步深入探索;第5 節則對前三節的模型算法進行對比分析論證.最后,在第6 節指出了解耦表征學習未來的可能發展方向并對全文進行總結.
1 解耦表征學習
在表征學習中,通常將真實數據x的生成過程建模為兩部分:從先驗分布p(z) 中采樣得到潛在變量取值z;從條件數據生成分布p(x|z) 中采樣得到數據觀測值x[37].該模型背后的關鍵性假設在于將真實數據x視作由一系列物理語義可解釋的因素{v1,v2,···,vn}通過復雜未知的非線性系統映射函數Sim(·) 作用相互耦合產生[37-38],即x=Sim(v1,v2,···,vn) .例如從宏觀上看,圖1 (b)中的交通場景圖像數據可看作由車1、車2、人、道路背景四個可解釋的對象通過交通成像系統耦合而成,圖1 (c)中的車輛數據可看作由車型、角度兩個可解釋的生成因子通過車輛成像系統耦合而成.從微觀上看,物質均由分子、原子等微觀粒子耦合而成.表征學習模型中的潛在變量z即為對這些物理可解釋因子{v1,v2,···,vn}的近似表征,條件似然分布p(x|z)即為從概率角度對未知非線性系統映射函數Sim(·)的近似.在此基礎上,解耦表征學習旨在學習可分離的潛在變量表示z={z1,z2,···,zn},且p(z)=,使得該表示下每個潛在變量子集zk能夠對數據內部相對應的生成因子vk進行有效表征控制.
傳統解耦表征類研究可以追溯到獨立成分分析(Independent component algorithm,ICA)方法[39-40],旨在表示量測信號是如何由多種獨立成分線性疊加而成.據此構建的數學模型為:

其中x為真實量測數據;z為服從統計獨立特性且非高斯分布的獨立成分表示,可視作潛在變量,用于捕獲影響線性系統輸出的生成因子;W為混合轉換矩陣,可近似為線性系統中將多輸入生成因子線性疊加轉換為量測輸出數據的系統函數.
然而ICA 一般僅適用于線性系統量測數據的解耦表征中,對于復雜非線性系統量測數據的解耦表征類研究可通過將式(1)中用于近似線性系統函數的轉換矩陣W替換為由多層參數化深度神經網絡定義的復雜非線性轉換函數,如此便引申出自編碼(Auto-encoders,AE)模型.在自編碼模型中,由神經網絡構成的編碼器h對輸入數據x進行編碼形成潛在編碼量z,即z=h(x) ;另一個神經網絡構成的解碼器f則負責將這些潛在編碼量z解碼,重構出原始數據x,即x=f(z)=f(h(x)) .通過最小化重構誤差,自編碼模型能夠逐漸挖掘到對重構數據更有效的相關特征,舍棄無關特征[41].該表征模型被Schmidhuber[42]于1992 年用于非線性數據的解耦表征中,他們建立的自適應預測器通過最小化可預測性原理懲罰每個潛在編碼量所包含信息被其余潛在編碼量預測出的概率來完成自編碼模型中潛在編碼量z的解耦任務.
現有大多數表征學習網絡都是基于Kingma 等提出的變分自編碼(Variational auto-encoders,VAE)模型[43],該模型從極大似然的角度對真實數據進行表征建模.其中針對潛在變量z的推斷過程,VAE 采用將真實數據輸入到深度編碼網絡fφ的方式進行變分近似后驗推斷qφ(z|x) ;針對真實數據x的生成過程,VAE 采用將變分推斷得到的潛在變量z輸入到深度解碼網絡gθ來近似數據生成建模pθ(x|z),其中z~qφ(z|x) .對于整體VAE模型中的網絡參數θ,φ的求解優化方式采用極大對數似然思想,如式(2)所示.式中第一項為變分后驗分布qφ(z|x)與真實后驗分布p(z|x) 間的KL 散度(Kullback-Leibler divergence).由于此項非負,第二項L(θ,φ;x,z)被稱為真實數據x的變分下界,代替式(2)成為VAE模型中新的優化目標函數,如式(3)所示.式中第一項 l npθ(x|z) 稱為數據的條件對數似然項,反映的是潛在變量z對于真實數據x的表征能力,第二項KL(qφ(z|x)||pθ(z)) 常稱為KL項,反映的是變分后驗分布qφ(z|x) 與先驗分布p(z) 間的相似性.在VAE模型中,由于人為選擇的先驗分布p(z) 通常滿足獨立特性,如高斯正態分布等,因此式(3)中的第二項KL 項相當于對網絡施加了一定程度的獨立性約束,通過該優化函數訓練出的模型具備一定的解耦性能,但實際應用過程中發現該約束能力還遠不能實現對數據的有效解耦.基于此問題,目前大量學者通過在原始VAE 中增添各類隱式或顯式的歸納偏好促使網絡學會數據內部各個可解釋生成因子的有效解耦表征.

與VAE 從貝葉斯的角度對真實數據進行生成分布建模不同,Goodfellow 等[44]于2014 年提出生成對抗網絡(Generative adversarial nets,GAN)模型,運用對抗學習思想在無需假設數據全概率生成分布模型的情況下正向模擬真實數據的生成過程.具體而言,該模型首先從人為假設的潛在先驗分布p(z) 中采樣,近似復雜系統內影響數據輸出的各個隱含生成因子;隨后將這些采樣值送入用于模擬未知復雜系統函數的生成器G中,輸出生成的數據G(z) ;最后采用判別器D對生成數據的真實性進行打分.與VAE 不同,GAN 不直接以數據分布與模型分布的差異作為目標函數,而是采用對抗的方式,先通過判別器去學習生成數據與真實數據的差異,再引導生成器去縮小這種差異,如式(4)所示,逐漸尋找這種類似零和博弈中的納什均衡解[45].相較于VAE,GAN 不用對數據的分布模型進行顯式設計,避免了人為設計的復雜繁瑣且賦予了網絡更強大的生成數據能力.然而GAN 缺乏有效的推理機制,只著重于數據的生成過程估計,更適用于潛在因子已知情況下系統數據的近似生成問題,而不是潛在因子的變化規律探索問題,因此GAN 模型難以直接應用到挖掘數據內部未知潛在生成因子的解耦表征研究中.針對此,目前大量學者提出GAN與VAE 相結合的思想進一步開展對于真實數據的解耦表征學習研究.
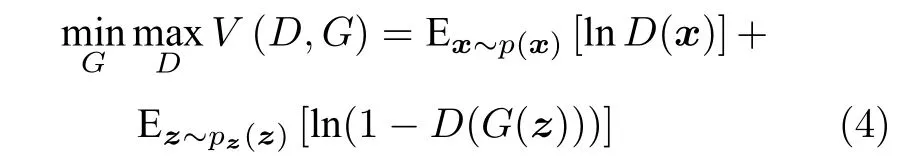
這兩類生成式模型為解耦表征學習研究提供了許多新的思路.然而在模型與數據都不存在歸納偏好(Inductive bias)的情況下,網絡無法自主無監督地學習出良好的解耦表征[37].對此,大量學者針對表征變量、模型架構等提出了不同的歸納偏好設計,促使模型擁有良好的解耦表征能力.本文接下來將分別從非結構化表征先驗歸納偏好、結構化模型先驗歸納偏好、物理知識歸納偏好三方面對現有解耦表征學習的研究進展進行綜述.
2 基于非結構化表征先驗的解耦表征學習
在對真實數據進行解耦表征學習過程中,對于潛在變量z的歸納偏好設計形式至關重要.2016 年~2019 年,大量解耦表征學習研究通過在原有生成式模型目標函數的基礎上增添各類無監督正則項歸納偏好來為潛在變量z施加額外的獨立性元先驗約束,促使網絡偏向于學習滿足獨立統計分布特性的潛在變量表征.本節將主要從獨立性先驗正則歸納偏好的角度出發,對現有基于非結構化表征先驗歸納偏好的解耦表征學習研究進行歸納整理分析.
對于VAE 而言,式(3)中的第二項KL 項通過設計滿足獨立特性的先驗分布p(z) 能夠對網絡學習到的變分后驗分布qφ(z|x) 施加一定程度的獨立性約束.基于此,Higgins 等[46]于2017 年提出β-VAE模型,直接對式(3)中的KL 項施加大于一的罰項系數β,進而加強對近似后驗分布的獨立性約束,鼓勵網絡著重學習潛在變量z的可分離性.此時構成的新的優化函數如式(5)所示.

其中β≥1 .
然而,來自高β值的額外壓力往往會使潛在變量所含的有效信息在經過解碼器的過程中由于受約束的潛在瓶頸導致高頻細節丟失,對數據的表征能力下降,難以達到數據的有效表征與解耦表征之間的最佳權衡.基于此,后續多項研究提出進一步的改進策略,期望能夠在不丟失過多數據表征能力的同時盡量提升潛在變量的解耦性能.Burgess 等[47]于2018 年從信息瓶頸理論分析的角度認為式(5)的對于近似后驗分布的約束項為第一項重構項的信息瓶頸,提出在訓練過程中采用漸進策略逐漸增加潛在變量的信息容量,如式(6)所示,將有助于達成強表征能力與強解耦能力之間更好的權衡,給予潛在變量更大的表示空間.

其中C為隨著網絡訓練不斷線性增大的超參數.
除了上述將式(3)中的第二項KL 正則項看作一個整體進行改動以提高網絡解耦表征的能力外,Makhzani 等[48]提出對抗自編碼(Adversarial autoencoders,AAE),對式(3)中的KL 項進行更加細致化與規范化的推導,如式(7)所示.他們認為式(7)中第三項互信息項反映的是潛在變量z與輸入數據x間的相關性.若懲罰該項,將有可能導致潛在變量z無法對輸入數據x進行有效表征.而式中第二項有關累積后驗分布與先驗分布的KL 項則是真正有助于提升解耦效能的關鍵項.基于此,他們采用對抗約束的方式僅懲罰式(7)中第一項重構項與第二項KL 項.該分解相較于β-VAE將式(7)中后兩項看作一個整體進行懲罰,更好地達到數據解耦性能與表征性能間的平衡.Kumar等[49]認為AAE 在運用對抗思想的同時會面臨對抗訓練所存在的鞍點等問題[50].他們提出的DIP-VAE (Disentangled inferred prior variational auto-encoders)
模型將潛在變量后驗累積分布qφ(z) 與先驗分布p(z) 均假設為高斯分布,利用矩估計思想設計了兩種矩匹配項來對后驗分布的協方差矩陣進行約束來促使二者分布達到一致,其設計形式如式(8)、(9)所示.該方法相對于AAE 而言大大簡化了訓練過程,避免了對抗訓練中所可能出現的鞍點等問題.


然而當潛在變量先驗分布p(z) 設計有偏差時,采用上述方法對后驗累積分布qφ(z) 與先驗分布p(z)施加強一致性約束會導致數據表征學習的有效性減弱.基于此,Kim 等[51]與Chen 等[52]先后于2018 年提出能夠直接鼓勵后驗累積分布q(z) 服從因式階乘分布的懲罰項:項.其中Kim 等[51]所提出的Factor-VAE 直接在原始VAE 優化函數中增加該懲罰項,如式(10)所示,用于提升模型的解耦性能.Chen 等[52]所提出的β-TCVAE (Total correlation variational auto-encoders)從理論推導角度將式(7)中第二項 K L(q(z)||p(z)) 進一步分解,如式(11)所示.進而通過對不同項賦予不同的權重值構成新的優化函數,如式(12)所示.兩種方法對于項的相似性度量均采用對抗方式求解.

除了上述基于表征獨立分布特性設計先驗正則用于解耦表征學習外,還有部分學者從其余表征分布特性的角度出發對上述方法進行了進一步的補充.以下將分別從離散型潛在變量分布特性、與數據相關的潛在變量解耦特性、序列圖像中潛在變量的時空一致性以及潛在變量的稀疏性四個角度進行展開描述.
用于捕捉數據內部生成因子的潛在變量除了類似位置、外觀等連續型潛在變量外,還存在著類別等離散型潛在變量.這類離散型潛在變量的存在會使得深度網絡在進行梯度回傳時出現無法有效求微的難解問題.基于此,Dupont 等[53]提出JointVAE,使用連續的Concrete 分布[54]來對離散型潛在變量進行建模,并采用連續型潛在變量z與離散型潛在變量c聯合分布建模qφ(z,c|x) 的方式,將式(6)中的目標函數擴展為式(13) 形式,為涉及到離散型潛在變量的解耦問題提供了一個很好的思路.
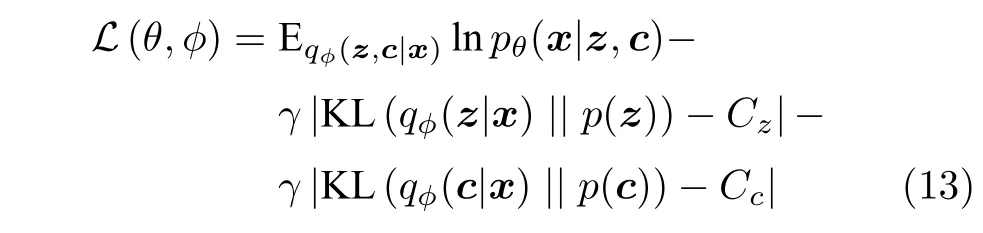
此外,在潛在變量子集中還會存在著一些無關噪聲干擾.對此,Chen 等[55]于2016 年提出生成對抗網絡的信息論擴展網絡InfoGAN (Information maximizing generative adversarial nets).該網絡旨在將潛在變量解耦為不可壓縮噪聲源z與有效信息源c兩部分.考慮到有效信息源c應該在數據生成過程中發揮主要作用,InfoGAN 提出最大化有效信息源c與生成數據G(z,c) 間的互信息I(c;G(z,c)) .該文獻使用變分后后驗分布Q(c|x) 來近似真實后驗分布P(c|x),設計出一種可以有效優化的互信息目標下界LI(G,Q),將難解問題可解化.其定義如式(14)所示.將其并入GAN 的優化目標函數中,如式(15)所示,旨在鼓勵網絡學習更具可解釋性和有意義的表征形式.
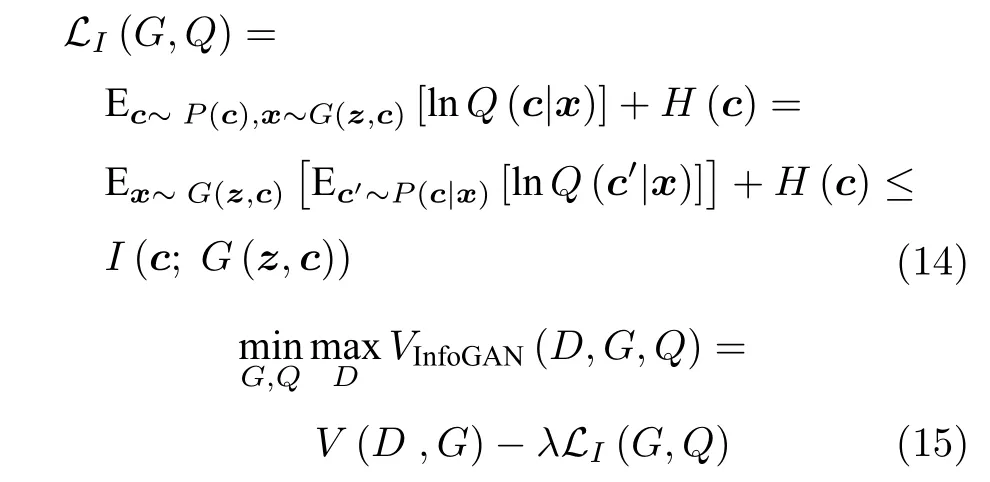
除此之外,Kim 等[56]認為對于這些無關噪聲干擾間的解耦程度并不需要額外約束,于2019 年引入相關性指標r對Factor-VAE 進行改進,提出RFVAE (Relevance factor variational auto-encoders).如式(16)所示,旨在使式(10)中的最后一項僅作用于對數據有用的相關潛在變量.

對于序列型數據而言,時空一致性是其本征重要物理特性之一,若在潛在變量分布建模時融入該特性將有助于網絡學習到更符合真實物理規律的表征形式.基于此,Grathwohl 等[57]于2016 年針對視頻序列中相對靜止的背景場景與隨時間平緩運動的前景目標間的解耦表征問題,提出采用式(17)的形式對背景表征分布進行建模,采用式(18)的形式對前景目標表征分布進行建模.此種建模方式模擬了真實世界中背景時空不變性與前景運動目標時空平緩變化的特征,更為有效合理.

除了上述提及的幾個特性外,還應注意到數據內部潛在變量表征往往是具有稀疏特性的,即不是每個潛在變量都需要對數據進行表征.傳統變分自編碼模型對于潛在變量的先驗建模大多采用高斯正態分布,難以反映其內有稀疏特性,而學生t分布、拉普拉斯分布等厚尾分布則可以很好地體現變量的稀疏分布特性.基于此,Kim 等[58]于2019 年提出分層貝葉斯深度變分自編碼模型,BF-VAE (Bayes factor variational auto-encoders).同InfoGAN[55]一樣,將潛在變量分為相關潛在變量與干擾潛在變量兩類.他們認為厚尾分布更適用于相關潛在變量的分布建模,而傳統高斯分布則適用于干擾潛在變量的分布建模.利用此思想,在傳統高斯先驗的方差上引入超先驗的同時保持傳統VAE 的易學性與推理性,將VAE 擴展為分層貝葉斯模型.
因此針對具體問題,應具體分析其背后所具備的物理分布特性,并基于此選擇適用的表征分布模型,將有助于提升整體網絡的解耦表征學習能力.此外,對于本節所涉及的各類先驗正則化歸納偏好方法的匯總如表1 所示.從表1 中可看出,本節所涉及的各類算法雖然一定程度上能夠實現數據的有效解耦表征,但這類算法的學習過程依舊缺乏明確的物理語義導向.這將進一步引出本文后兩節基于結構化模型先驗歸納偏好與基于物理知識先驗歸納偏好的解耦表征學習類研究算法探討.

表1 非結構化表征先驗歸納偏好方法對比Table 1 Comparison of unstructured representation priori induction preference methods
3 基于結構化模型先驗歸納偏好的解耦表征學習
對于第2 節中基于非結構化表征先驗的解耦表征學習方法,Montero 等[59]于2021 年設計實驗,調整數據集中的部分屬性取值范圍,分別測試了原始VAE,β-VAE,Factor-VAE 三類方法在相應測試集上的泛化性能,發現這類單純施加非結構化表征先驗正則歸納偏好的方法對于模型學習方向的約束能力隱形且較弱,不足以支持復雜情境設計下的組合泛化性.他們認為設計模塊化、結構化、融合實際物理機理的模型尤為重要.本節將從順序深度遞歸網絡、層次深度梯形網絡以及樹形網絡三個由人類認知過程所啟發的高度顯式結構化網絡模型來對現有基于結構化模型先驗歸納偏好的解耦表征學習類研究進行歸納探討,對于融入實際物理機理的模型設計將在本文第4 節中進行探討.
3.1 順序深度遞歸網絡
目前,大多數基于深度學習進行圖像理解的方法往往傾向于一次性理解整幅場景.在生成式神經網絡的背景下,這通常意味著所有像素都受單次潛在分布的約束,且網絡無法進行迭代自校正.然而人類進行場景感知時往往不傾向于同時處理整幅場景.相反,人類會利用連續的中心凹運動進行 “主動感知”:在給定的時間內,有選擇地將注意力集中在中心凹的高分辨率視覺空間中,并隨著時間的推移將來自不同注視點的信息結合起來,指導未來的眼球中心凹運動序列(旋轉和平移)決策,逐漸建立起整幅場景的全面表征,如圖4 所示.受到該人類感知方法的強烈驅動,許多學者逐漸發現 “一次性感知”表示方法從根本上很難擴展到大圖像或目標占比過小的圖像場景.與此相比,通過一系列的局部瞥視或顯著區域捕捉可以更好地捕獲視覺結構[60-62],這種思想可以通過使用遞歸神經網絡執行概率迭代推理來實現,使得網絡每次只關注部分圖像進行處理,最終整合至整幅圖像.這種順序遞歸模型的明顯優點是,通過將復雜數據分布映射到一系列更簡單的問題中,反復生成以先前狀態為條件的輸出,簡化了建模復雜數據分布的問題.然而該方法的難點在于如何選擇注意機制以及如何將顯著區域的位置與提取的特征相結合,如何選擇遞歸次數等.
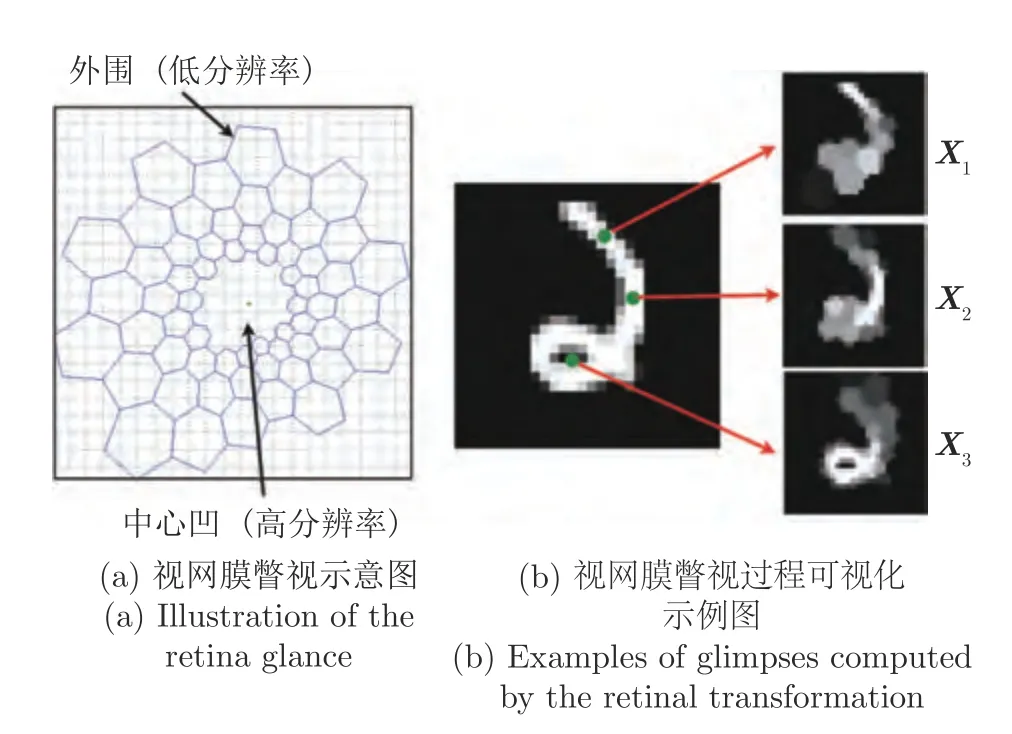
圖4 人類視網膜瞥視過程圖[60]Fig.4 Illustration of the retinal transformation[60]
Larochelle 等[60]于2010 年首先提出一種特殊的模擬人眼中心凹特性的受限玻爾茲曼機模型,該模型在可見單元(瞥視),隱藏單元(累積特征)以及控制可見單元與隱藏單元連接的位置相關單元間建立三階連接,學習如何在多個固定點上累積有關單個目標形狀的信息.基于此思想,Mnih 等于2014年[61]將注意機制問題看作是以目標為導向的智能體與視覺環境交互的順序決策過程.他們提出基于遞歸神經網絡的循環注意機制模型,為每次決策設計計算一個標量獎勵的反饋,從而結合強化學習的訓練策略,促使最終決策的總和最大化.該模型隨后被Gregor 等[62]擴展為深度遞歸視覺注意模型(DRAW)用于生成圖像,在VAE 的框架下采用遞歸循環網絡來構建編碼器與解碼器,每次循環通過解碼器發出的修改累積迭代地構造場景,同時嵌入空間二維高斯濾波器來產生位置、縮放平滑變化的局部圖像 “塊”充當每次迭代過程中網絡所選定的注意區域.而對于如何選擇迭代次數,他們將其視為人為提前設定的固定超參數.
目前該思想被廣泛用于解決復雜場景多目標解耦問題.對于場景的認知,Henderson 等[63]給出了以下定義:“場景是真實世界環境的語義連貫(通常是可命名的)視圖,包含背景元素和以空間特定方式排列的多個離散對象.” 基于此,許多學者將循環遞歸網絡每次的迭代過程視為新目標的形成過程,并在每次形成新目標后通過一組特定的仿射函數將其與之前場景相復合.其中,Eslami 等[64]于2016年提出的基于VAE 的結構化圖像模型AIR (Attend-infer-repeat)引起人們的廣泛關注,后續被大量引用于復雜多目標場景的解耦表征研究中.該模型可理解為基于對象的解耦表征,通過將編碼推理網絡構建為遞歸神經網絡的形式促使網絡迭代學習關于場景中存在的每個對象的解耦表征.且由于該模型將對象表示為 {存在概率、特有屬性、坐標} 三類,該模型可被用于目標檢測、識別等下游推理任務中.后續被Crawford 等[65]改進為適用于較多目標場景的檢測模型SPAIR (Spatially invariant attend-infer-repeat).AIR 的整體架構設計如圖5 所示,通過平攤、迭代推理的方式來逐目標地實現多對象場景的理解,并結合空間仿射變換對坐標這一潛在表征施加強物理約束,有效指引了網絡的學習方向.除此之外,AIR 將網絡的迭代次數,即前景目標個數也視為一個隱變量,服從特定的分布,這一方法對于可變數量的前景目標檢測具有更強的魯棒性與泛化性.然而該方法只能處理簡單背景下少量前景目標的檢測等問題,且并未進一步考慮不同目標間的語義關聯關系.

圖5 模型架構設計圖[64]Fig.5 AIR framework[64]
為了擴展AIR 在連續視頻場景下的使用,Kosiorek 等[66]于2018 年提出的SQAIR (Sequential attend-infer-repeat)將視頻中所具有的時空一致性加入原始AIR 模型中進行改進.具體而言,該模型將視頻數據的生成過程分為兩支路實現:傳播支路(Propagation,PROP)用于負責更新(或遺忘)前一時間步中所含對象的潛在變量觀測(圖像),且結合關系RNN[67]來對物體間的關系進行捕獲;發現支路(Discovery,DISC)在傳播支路(PROP)的基礎上進一步檢測是否有新對象出現.該模型能夠實現簡易視頻數據集中的目標檢測跟蹤問題,為具有時序變化性的變分自編碼架構設計提供了前瞻性的解決思路.此外,Massague 等[68]于2020 年提出視頻部分幀缺失情況下的解耦表征問題.他們認為人類在視頻幀突然缺失或突然受到干擾的情況下自然而然地認為之前幀中的物體依舊存在,且其運動軌跡遵循之前的規律.基于此,他們在潛在空間設計中多考慮了一組代表缺失狀態的潛在變量子集用于判別當前幀數據的缺失狀態,若缺失,則通過在過去幀的潛在空間采樣來插補近似缺失幀的潛在表征.此設計促使網絡自監督地學習缺失數據的插補表征方式,一定程度上解決了視頻部分幀缺失數據的解耦表征問題.
3.2 層次深度梯形網絡
除了第3.1 節中利用循環遞歸網絡實現順序迭代逐步處理特定任務外,考慮到現實世界中許多自然信號本身所特有的成分分層特性,本節集中于層次深度梯形網絡的設計搭建,賦予深度網絡不同語義特征提取過程中顯式層次結構的歸納偏好,即通過組合較低層的語義特征來獲得較高層的語義特征表示.例如在現實世界中,邊緣的局部組合形成圖案,圖案組裝形成零件,零件組裝形成對象.
S?nderby 等[69]于2016 年提出梯形變分自編碼網絡(Ladder variational auto-encoders,LVAE).與傳統VAE 所使用的推理模型與生成模型間無交互作用的純自底向上推理過程(如圖6 (a)所示)不同,該文獻提出推理與生成模型中共享自頂向下的依賴結構,如圖6 (b)所示,使得模型的推理過程只用簡單修正生成分布,將優化過程變得更加容易.
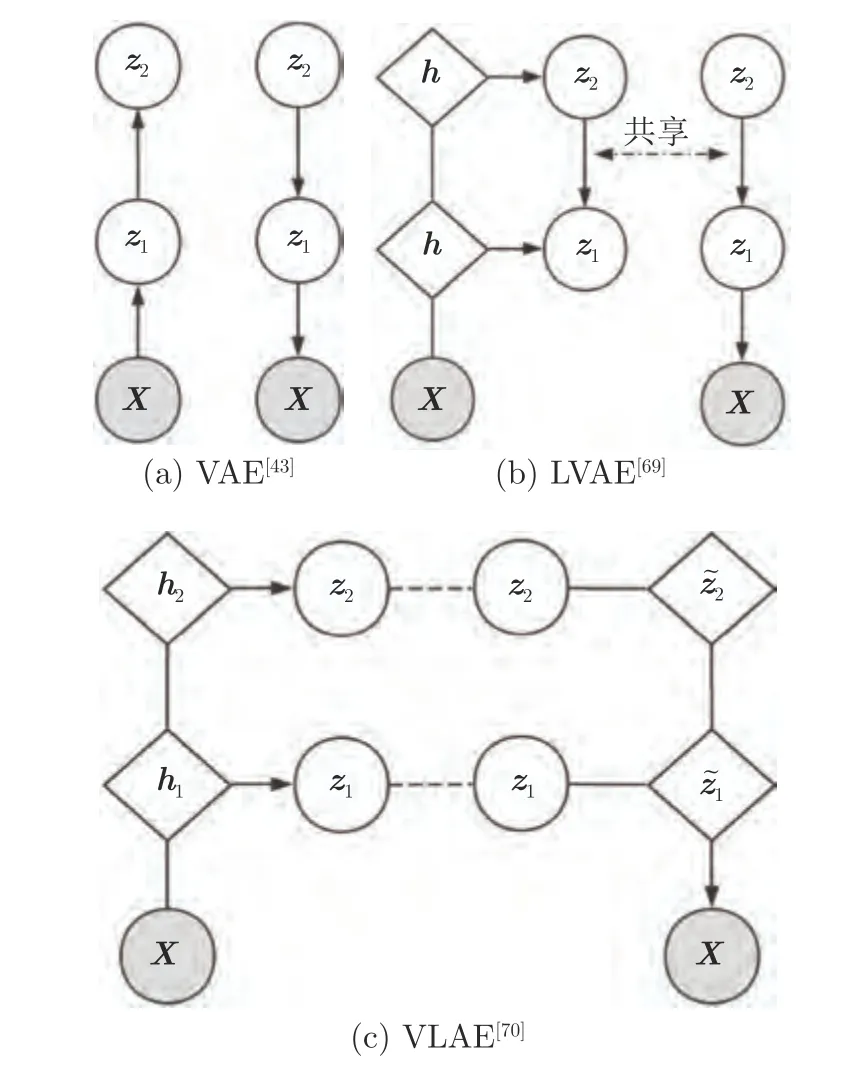
圖6 深度梯形網絡模型圖Fig.6 Deep ladder network models
然而Zhao 等[70]認為LVAE[69]在訓練到最優的情況下,僅底層潛在變量包含足夠的信息用于重建數據分布,其余層則很容易被忽略.且通常用于構建層次生成模型的許多構建塊不太可能幫助學習解耦特征.基于此,他們于2017 年提出變分梯形自動編碼網絡(Variational ladder auto-encoders,VLAE),通過在每一層潛在變量與圖像之間映射所需的計算程度來分離圖像的潛在變量子集.將不同層次的潛在變量與具有不同表達能力(深度)的網絡連接起來;鼓勵模型在頂部放置高層次、抽象的特征(如身份特征等),在底部放置低層次、簡單的特征(如邊緣特征等).該模型設計如圖6 (c)所示,其中條件生成模型p(x|z1,z2,···,zL) 被隱式定義為式(19)的形式.推理網絡定義為式(20)的形式.這種模型設計使得越高層、越抽象的潛在表示需要越復雜的網絡來捕獲,在不需要特定任務規則化或先驗知識的情況下,能夠學習到高度可解釋的、解耦的層次特征.該模型隨后被Willetts 等[71]用于促使網絡在不同層解耦代表不同屬性的潛在表征,從而基于該表征在各個層次實現按照不同屬性區分的聚類任務,他們稱其為解耦聚類.除此之外,Esmaeili等[72]于2019 年從多級隱變量角度出發,將潛在變量分為組間潛在變量與組內潛在變量兩級來對KL項進行進一步分解,如式(21)、(22)所示,提出了基于VAE 的兩級分層HFVAE (Hierarchically factorized variational auto-encoders)模型.該模型可以通過控制兩級隱變量不同的權重系數來控制組間隱變量與組內隱變量的相對解耦程度,如式(23)所示.

其中fl,gl均為非線性神經網絡映射.

3.3 樹形網絡
除了第3.2 節中所展示的層次深度梯形網絡架構的設計,樹形模型的結構設計更是將第3.2 節中深度層次梯形網絡與高層超潛變量間的橫向連接思想相融合,如圖7 所示,構建出更符合現代神經科學在視覺皮層中觀察到的橫向連接現象.將此結構歸納偏好再次加入模型結構設計中,通過引入更深層的超潛變量父節點可以在達到子節點中潛在變量解耦效果的同時結合更深層父節點語義間的交互性特征,實現更科學的解耦性能.
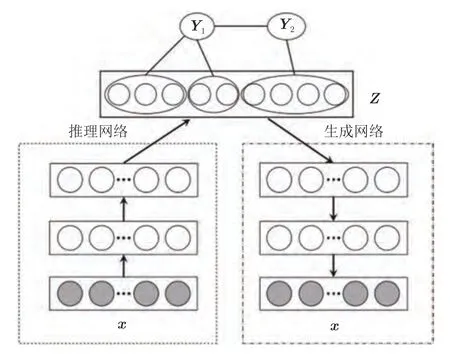
圖7 簡易樹形變分自編碼模型示意圖[73]Fig.7 Structure of a simple latent tree variational auto-encoders[73]
George 等[74]于2017 年所提出的遞歸皮層網絡(Recursive cortical network,RCN)便搭建出一種類似人類大腦皮層處理方式的組合性樹形結構網絡,如圖8 (d)所示.該網絡將目標對象解耦為輪廓表征與外觀表征,如圖8 (a)所示,使模型能夠識別具有明顯不同外觀的對象形狀,在復雜場景下的文本識別中展示了出色的泛化和遮擋推理的能力.其中外觀表征使用條件隨機場(Conditional random field,CRF)建模來反映外觀表面平滑變化的物理特性.輪廓表征的建模方式如圖8 (b)所示,通過多層特征池、橫向連接、組合的設計,實現高層次特征間相互獨立,又同時共享底層特征彼此交互的特性.其中池化結構的設計使得頂層特征節點能夠表示具有一定平移、縮放和變形不變性的對象;橫向連接的設計能夠實現同一層次不同組特征間的彼此交互作用,其直觀展示如圖8 (c)所示.該網絡設計為組合式模型提供了更多的概率圖模型中所涉及的高級推理與學習算法.
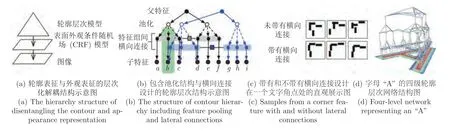
圖8 RCN 模型示意圖[74]Fig.8 Structure of the RCN[74]
Li 等[73]于2019 年提出潛在樹形變分自編碼器(Latent tree variational auto-encoders,LTVAE),其表示結構是由多個超潛變量組成的樹結構,與Willetts 等[71]類似旨在生成多種按照數據不同指標方式的聚類結果.該模型假設數據是通過神經網絡從潛在特征生成的,而潛在特征本身被另一層次的超潛變量通過樹型貝葉斯網絡生成,每個超潛變量都代表著一種聚類方式.該方法能夠自主選擇每個超潛變量的潛在特征子集,并學習不同超潛變量間的依賴結構.
4 基于物理知識歸納偏好的解耦表征學習
除了第2和3 節基于非結構化與結構化先驗歸納偏好的解耦表征學習研究外,在模型中融入真實數據內所蘊含的物理本征機理和復雜邏輯關系將有助于進一步發展內嵌底層邏輯與物理內涵的解耦表征學習新體系.因此本節將從輸入數據間的物理關聯與基于對象的場景空間組合兩種物理語義理解層面著手,研究當下融入物理知識歸納偏好的解耦表征學習.
4.1 基于輸入數據間物理關聯的多輸入解耦表征學習
第2和3 節所述有關解耦表征學習的研究均默認輸入數據服從獨立同分布特性,然而在弱監督分組觀測的情況下,組內數據間蘊含著一定的共性特征(如各種視角下的同一物體共享身份特征;同一顏色下的不同物體共享顏色特征等),如圖9 中遙感艦船圖像組數據示例,此時組內數據間具有一定的相關性,該假設不再成立.因此本節旨在研究如何將組內數據間的弱監督相關性信息加入到網絡歸納偏好的設計中,實現針對分組數據的相關因子與不相關因子的解耦表征學習.除此之外,本節也會涉及到成對輸入圖像中感興趣因子的差異比較,這種比較與醫生根據兩個病人的疾病對比程度來量化他們的疾病嚴重程度思想類似,旨在能夠對相關感興趣因子進行更好的量化.
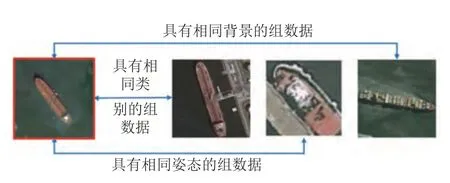
圖9 遙感艦船圖像組數據示例圖Fig.9 Samples from remote sensing ship group images
針對具有部分完全相同屬性的分組數據而言,大量研究學者提出通過在組內數據間共享或交換部分潛在變量的方法[75-79],促使網絡學習到代表組內數據間特定相關生成因子所對應的潛在變量,通過該舉措能夠從施加強結構偏好的角度有效完成組內數據相關因子與不相關因子的解耦表征學習任務.
Bouchacourt 等于2018 年[75]提出多級變分自編碼器(Multi-level variational auto-encoders,MLVAE),在組內數據共享相關因子潛在表示CG的同時,認為不相關因子的潛在表示SG服從獨立階乘分布,二者共同參與圖像的生成過程.其中值得注意的是,該架構構建了兩組完全分離的編碼網絡,φc,φs分別為這兩組分離的編碼網絡的變分參數,對兩組隱變量語義表示進行源頭性的阻斷隔離解耦,同時可以通過交換潛在表示生成新的類型圖像對解耦表征進行可視化展示.其整體的優化函數如式(24)所示.
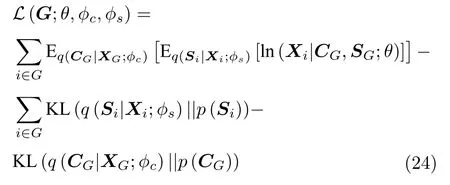
與ML-VAE 組內數據共享相關因子的表示不同,Szabó等[77]于2018 年提出組內圖像對間通過交換不相關因子的潛在變量表示來重構出其所對應的另一幅圖像,而不是原圖像本身,通過這種操作達到解耦相關因子與不相關因子的目的.除此之外,他們提出對于分組數據的解耦表征學習往往存在退化映射問題,即圖像的所有信息均集中在某一部分的特征表示中.為了緩解這一問題,他們引入與輸入圖像對{x1,x2}均完全無關的圖像x3,運用對抗思想再次將潛在變量進行交換來保證相關因子的潛在變量表示一定包含部分圖像信息,有效避免了退化映射現象的發生.Ge 等[78]于2021 年提出組監督學習模型GSL (Group-supervised learning),在結合上述交換潛在變量表示進行回歸匹配思想的同時融合Cycle-GAN[80]的思想,將交換隱變量表示后的圖像再次通過同樣的網絡將其交換回來進行與原圖像間的回歸匹配.該思想相較于上述方法優勢在于保證上述方法性能的同時,通過再次交換回傳可以進一步施加原轉換問題的逆約束,使得屬性值不一樣的相關因子(如都含有顏色相關屬性但屬性值不同的組圖像)的解耦進一步明朗化.以圖9 中的遙感艦船圖像組數據為例,若使用GSL 模型,則該模型對應的網絡設計如圖10 所示.

圖10 GSL 模型[78]用在遙感艦船圖像組數據集中對應的網絡架構示意圖Fig.10 The structure of GSL model[78] when it is used in the remote sensing ship image group data set
除了上述通過共享或交換潛在變量來達到相關屬性與其余屬性的解耦表征外,從互信息相關性角度對分組數據內潛在表示間進行相關性度量,也可以進一步對分組數據輸入施加正則約束,從而促進分組數據潛在表示的挖掘與解耦.Sanchez 等[81]便于2020 年采用局部互信息與全局互信息相結合的方式衡量圖像對內相關因子潛在表示的相關性,讓其值盡可能大,促使分組數據間不同數據的相同屬性表示盡可能相似.同時為了達到解耦目的,運用對抗思想來使同一數據內共享表示和互斥表示間的互信息盡可能小.
將上述共享或交換隱變量表示與互相關信息的思想相結合,Esser 等[82]構建分離的姿態編碼器與外觀編碼器,從目標姿態所對應的圖像中學習姿態表示,從目標外觀所對應的圖像中學習外觀表示,隨后共同送入解碼網絡中生成新的圖像.該網絡在訓練過程時與Sanchez 等[81]類似也采用判別器約束外觀表示與姿態表示間的互信息大小.Lorenz 等[83]在Esser 等[82]的基礎上,將前景目標看作由一系列部件通過一定的空間組合規律組成,每個部件都具有外觀與姿態特性,除此之外他們還利用物理變換的方式人為將一幅圖像擴充為姿態發生變化但外觀未變的圖像與外觀未發生變化但姿態發生變化的圖像來取代組標簽信息,從而設計分離的編碼網絡,從外觀變化的圖像中學習姿態信息,從姿態變化的圖像中學習外觀信息.該網絡設計能夠在無監督條件下利用自監督思想有效實現部件間姿態與外觀的解耦表征,將分組數據間的解耦表征研究思想應用到通過數據增強等有效物理轉換方式的獨立數據解耦表征研究中.此后這種通過物理變換構造分組數據以及姿態,外觀的解耦方式還被Liu 等[84]用于無監督部件分割的任務研究中.Dundar 等[85]則是將上述方法擴充到視頻信息中隨時空變化與隨時空不變的信息間的解耦表征.他們認為相鄰幀中除了背景信息隨時間推移穩定不變外,前景紋理信息在前景目標還未消失前也同樣保持不變,隨時間變化的僅為前景目標的形態姿勢信息.基于此,他們利用相鄰幀之間前景目標姿態信息各異而外觀信息與背景信息共享這一組內的弱監督信息出發,創建出一種新穎的模型架構旨在將視頻幀中前景與背景分離,且前景信息中姿態信息與外觀信息分離.
以上研究都是基于相同的指標屬性進行分組解耦表征,然而現實數據集中大多紛雜錯亂,如何綜合利用按照各種不同指標的分組數據變成了一個新的挑戰.Vowels 等[86]于2020 年提出了Gated-VAE,期望在網絡訓練過程中能夠加入任何可用領域的先驗知識,使得模型的適用性更廣.他們提出一種新穎的訓練方式,在梯度前向傳播過程中,所有潛在空間的分區共同合并在一起,即在整個潛在空間上進行優化函數的計算;但在誤差反向傳播過程中,梯度將根據不同的圖像對來選擇特定的潛在空間分區進行傳播.通過這種獨特的訓練方法,他們認為如果整個數據集中所需的分區與人為所劃分的圖像對一致,則各個分區將包含不同的因素.即使在分區內存在糾纏現象,分區間也會實現解耦,為解耦學習的研究注入了新思路.
4.2 基于對象空間組合歸納偏好的解耦表征學習
正如第3.1 節所述,場景圖像可看作由背景元素和以空間特定方式排列的多個離散對象組成,而單個對象又可以看作是由外觀與形狀耦合而成.因此本節注重于考慮如何將一幅復雜場景解構為多個簡單對象的組合,并據此理解/生成這些簡單對象的組合關系.
人類天生具有組合泛化的能力,如圖11 所示,對于一幅多物體復雜場景,人類可以將其解構為多個簡單對象,并可以在腦海中按照空間位置重新排列組合這些對象,構成一幅新的場景圖.除此之外,對于單個簡單對象而言,人類也可以將其解構為具有多組共通屬性與各異屬性的多個簡單部件.正是依靠這種組合泛化能力,人類智能才能夠從一些最基礎的元素出發,一步一步創造出復雜甚至無限的語義世界.從這個角度出發,越來越多的研究工作開始研究探索數據集中內在的組合性規律,旨在促使深度神經網絡擁有像人類一樣的組合泛化能力.

圖11 人類想象泛化能力示意圖[87]Fig.11 An example of human imagination generalization ability[87]
要擁有像人類一樣的組合泛化能力,首先應學會對各類輸入數據進行內在分組解耦,例如在解決雞尾酒會的問題時,應對不同說話人的語音進行解耦;在自動駕駛中,應對道路上各種不同對象的類別、位置和速度進行解耦.在現實世界中,這些信息或多或少相互糾纏,隱藏在可見數據背后,本小節將著重于解耦隱藏在真實數據背后的豐富物理結構,完成不同對象不同特性的解耦表征任務.
Greff 等[88]于2016 年提出一種能夠有效進行分組解耦的迭代推理框架(TAGGER).該框架對數據輸入類型不設約束,結合期望最大化(Expectation-maximum,EM)聚類算法,對數據背后的潛在分組以及每個分組所對應的潛在表示進行迭代攤銷推理:給定分組的條件下推斷各個組內特征;給定各個組內特征的條件下推斷分組,如此迭代優化地完成對組分配以及各個組內對象表征的估計任務.然而正是由于該方法對數據類型以及網絡設計不施加任何其他約束,僅能夠對存在明顯分組偏差的簡單數據集進行解耦表征,并未泛化到各類復雜任務場景中.
對于單目標場景的組合泛化能力而言,Li 等[89]于2020 年提出條件生成模型MixNMatch (Mixand-match),旨在將單目標場景解耦為背景、前景目標的形狀、姿態、外觀四類表征.他們對于場景生成過程的理解借鑒Singh 等[90]的FineGAN 模型,分離為三個獨立作用的階段:背景提取階段、父場景前景形狀提取階段和子場景外觀提取階段.其中背景提取階段利用控制背景圖像生成的潛在變量進行背景建模.父場景前景形狀提取階段利用控制對象的輪廓(形狀)的潛在變量生成前景目標的形狀掩模.子場景外觀提取階段則利用控制對象外觀紋理的潛在變量進行前景外觀建模.三個獨立的生成網絡間首尾相連將每個網絡生成的圖像拼接耦合在一起生成最終的細粒度圖像.盡管這類模型在單域數據集下能夠達到很好的解耦表征性能,具有一定的聯想組合泛化能力,但對于多個跨域數據集的解耦性能卻不盡如人意.Ojha 等[91]認為其原因在于源域屬性信息在單域數據集下并未多做考慮,導致其耦合在形狀、外觀等表征中.對此,他們在FineGAN 的基礎上提出一種基于可學習的物體外觀特征直方圖表示,從而消除跨域情況下域信息對于物體解耦表征的影響.
除了將前景目標視為一個整體解耦其姿態與外觀紋理屬性外,Lorenz 等[83]認為前景目標可解耦為不同部件的外觀表示與姿態表示.如此則應保證原部件施加外觀轉換干擾時其所對應的姿態表示不應發生變化,反之亦然.他們便將這種真實世界存在的物理約束加入模型設計中,從部件外觀變化的圖像中學習部件姿態表示,從部件姿態變化的圖像中學習部件外觀表示這種強邏輯結構.但他們并未進一步考慮部件與整體間的邏輯映射關系.對于此類問題,Kosiorek 等[92]于2019 年提出的堆棧膠囊自編碼網絡(Stacked capsule auto-encoders,SCAE)則巧妙運用自然語言處理領域內Set transformer[93]思想,將部件組成整體的任意組合方式考慮進去.該模型首先將圖像分割為多個部件,再將部件組合為多個連貫的整體,整個邏輯圖如圖12 所示,不僅能夠解決單目標場景的部件解耦問題,還能夠泛化到多目標場景的目標級解耦以及每個目標多對應的多部件解耦中,為解耦問題注入了新思想.此外,Yang等[94]認為解耦后的潛在變量在通過解碼網絡生成原圖像的過程應服從一定的因果關系,他們提出的CausalVAE 在網絡解碼過程中加入了一層用于挖掘潛在變量間因果關系的因果層,促使整個網絡的生成過程更服從人類對于世界因果關系的認知過程,為構建因果結構化的解耦表征學習模型提供了重大的參考意義.
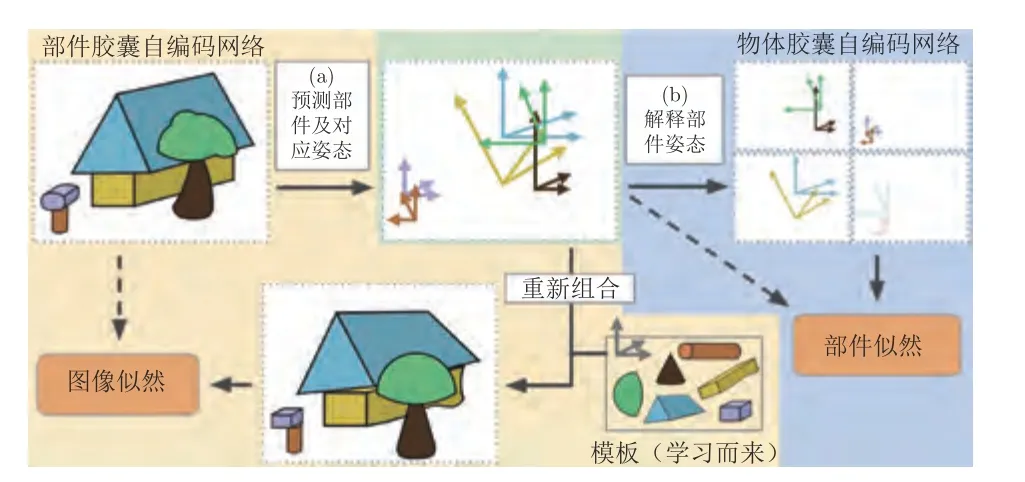
圖12 堆棧膠囊自編碼網絡(SCAE)模型架構圖[92]Fig.12 Architecture of stacked capsule autoencoders (SCAE)[92]
針對多目標場景的對象級解耦表征理解,除了上述的SCAE 模型外,2019 年,Greff 等[95]提出的迭代對象分解推理網絡(Iterative object decomposition inference network,IODINE) 與Burgess 等[96]提出多對象網絡(Multi-object network,MONET)均將多目標場景圖像理解為由多個物體級別的抽象塊按照一定的空間映射關系組合而來.基于此假設,二者均將多目標場景圖像分布視為由多個服從單高斯分布的物體級抽象塊按照一定的概率組合而成的混合高斯分布.其中對于推理網絡的設計,IODINE 采用迭代變分推理的方式[97]得到每個物體級抽象塊所對應的潛在表征,隨后利用解碼網絡得到每個物體級抽象塊所對應的高斯分布似然圖以及空間掩碼概率圖.而MONET 則使用遞歸空間注意力網絡得到每個物體級的抽象塊所對應的空間掩碼概率圖,隨后將該概率圖與原圖一起輸入自編碼網絡中得到每個物體級抽象塊的高斯分布似然圖.然而這兩個網絡僅能處理簡單多目標場景,并不能解決復雜多目標場景的目標級解耦表征.
針對復雜多目標場景的解耦表征理解,Zhan等[87]于2020 年提出了一種自監督的場景遮掩算法,用于學習物體間相互遮擋的空間關系.如圖13 所示,該算法從前景目標間的空間排列組合方式提出了構建有向圖進行表征的新角度,通過目標間的空間邏輯樹狀圖的構建實現了對多目標場景圖像的空間想象.

圖13 多目標場景去遮掩實現過程示意圖[87]Fig.13 The framework of the de-occlusion completion for multi-objective scene[87]
除此之外,Prabhudesai 等[98]于2021 年提出從3D 特征圖的角度進行二維圖像解耦的新思想.他們認為對于一個前景目標而言,三維本征立體結構是目標本身的內稟不變屬性,據此他們提出將二維圖像投影到三維空間中,在三維空間中進行對象級別的解耦更加能夠符合人類對于二維圖像數據的認知過程,且通過此方式不僅能夠解決目標遮掩與視角大差異性問題,而且能夠從任意視角想象泛化出新場景圖像,為真正從三維角度看待二維圖像解耦表征問題提供了良好的解決思路.
5 模型對比分析
上文描述的有關解耦表征學習算法被歸納為三類:基于非結構化表征先驗的解耦表征學習、基于結構化模型先驗歸納偏好的解耦表征學習與基于物理知識歸納偏好的解耦表征學習.本節將對這三類方法進行對比分析,討論其各自的適用范圍,并選取部分模型進行實驗性能的可視化展示,突出解耦表征學習對各類下游任務以及可解釋性深度學習的貢獻.
解耦表征學習的真正內核在于將數據內部各個具有可解釋性的生成因子采用盡可能獨立的潛在變量子集進行捕獲表征,并不拘泥于特定的數據類型與具體的下游任務.從表2 中可以看出,本文各類算法的適用場景以及對應的下游任務不盡相同,所選用的數據集也各有側重.因此對于解耦表征學習而言,各類算法的評價指標并未有統一標準,應根據實際情況具體分析所需解決問題的特定數據集,從主觀的角度出發設定能為人類所理解的特定評價指標.基于此,本節僅選取幾類典型算法的特定測試性能進行展示以輔助讀者結合表2 內容對解耦表征學習進一步深入思考.
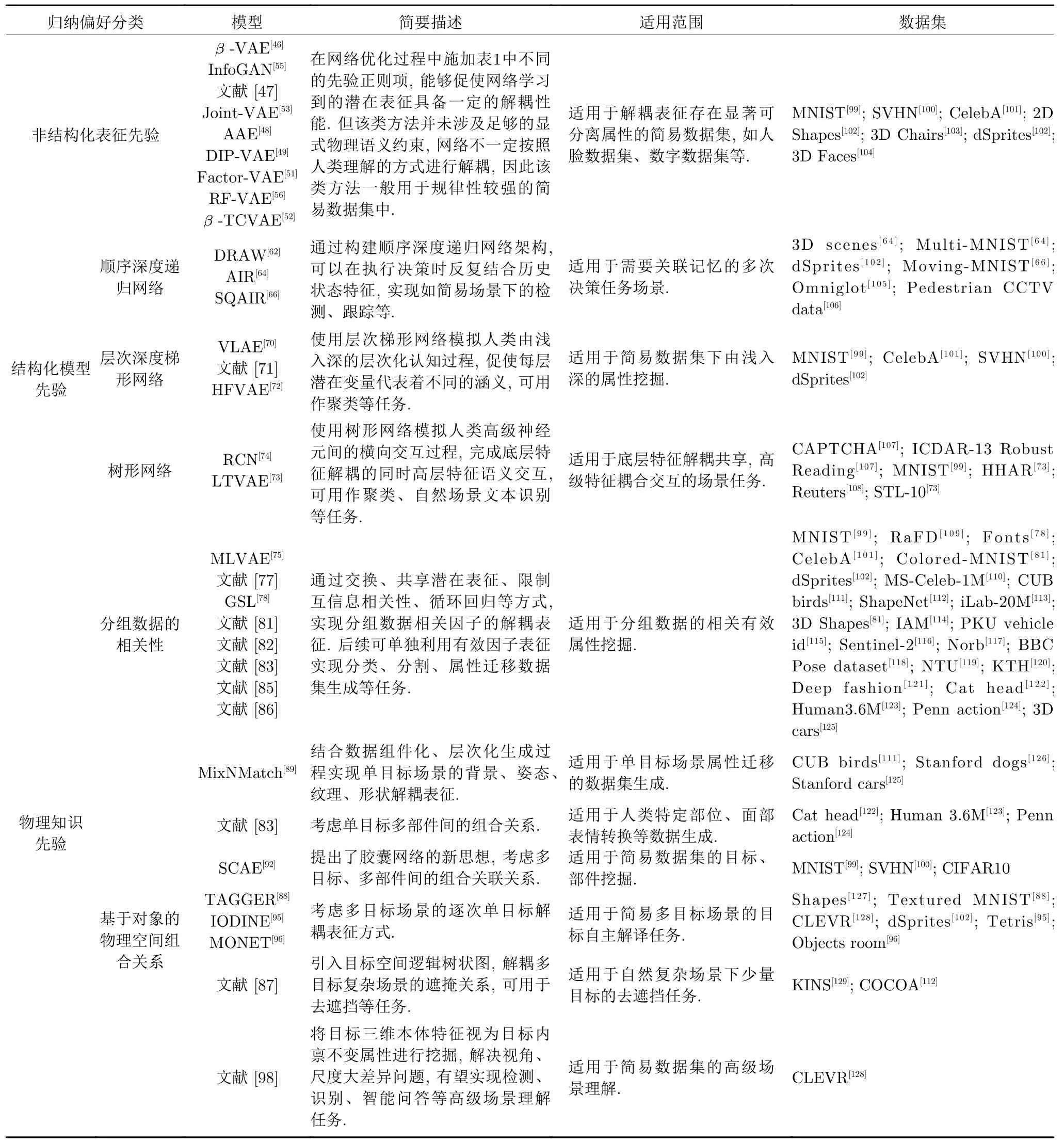
表2 不同歸納偏好方法對比Table 2 Comparisons of methods based on different inductive bias
首先針對第一大類基于非結構化表征先驗的解耦表征算法而言,該類算法大都屬于無監督學習范疇,通過在網絡優化過程中對潛在表征施加獨立性、稀疏性等歸納偏好,約束網絡學習可分離的潛在表征.對于這些可分離表征的物理意義驗證,大多文獻采用控制變量重構法進行直觀可視化驗證,即在保持其余潛在表征不變的情況下,依次單獨變換某一特定潛在表征的取值,通過分析重構圖像所發生的可視化改變來對這一特定潛在表征所代表的具體物理含義進行人為分析理解,如圖14 所示.除此之外,Higgins 等[46],Kim 等[51],Kumar 等[49],Chen 等[52],Eastwood 等[130]先后提出一系列有關潛在表征解耦性能的度量方法,然而這些方法只是單純探究潛在表征的可分離性,對其背后所捕捉的可解釋性因子并未進行評判.而解耦表征學習的本質重在挖掘數據生成背后復雜耦合的物理機理,并非單純地學習一堆未知含義但擁有獨立統計特性的潛在表征集合.因此本節并未同Locatello 等[37]一樣根據這些獨立性指標對該類算法進行量化對比,只是單純列舉其中典型算法AAE[48],Factor-VAE[51]在一些數字、人臉等簡易數據集上的可視化解耦表征結果,分別如圖14、15 所示.

圖14 Factor-VAE[51]算法在3D chairs[103]以及3D faces[104]數據集上的解耦性能展示圖.每一行代表僅有左側標注的潛在表征取值發生改變時所對應的重構圖像變化Fig.14 The disentangled performance of Factor-VAE[51] for 3D chairs[103] and 3D faces[104] data sets.Each row represents the change in the image reconstruction when only the specific latent marked on the left change
其次針對基于結構化模型先驗歸納偏好的解耦表征學習算法而言,這類算法的獨特之處在于模仿人類大腦的功能性區域構建可解釋的網絡架構.這類由網絡架構引起的模型結構化歸納偏好能夠在很大程度上調整網絡學習的方式,其中順序遞歸網絡架構促使網絡每做出一次決策的時候都會與之前學習的內容進行關聯;深度梯形網絡架構促使網絡由淺入深地逐層挖掘數據特征;樹形網絡架構則會促使網絡對高層高級特征進行橫向語義關聯.因此這類由人類大腦結構啟發的網絡架構設計形式不盡相同,所對應的人為任務偏好也千差萬別.為了形象化展示這類算法在解耦表征以及下游任務中所展現的優秀性能,本節挑選出三類典型的模型架構代表算法SQAIR[66],RCN[74],LTVAE[73],驗證解耦表征學習對于一些下游檢測、識別、聚類等任務的有效性,如圖16~ 18 所示.

圖15 AAE[48]算法對于MNIST[99]和SVHN[100]數字數據集中類別與風格屬性的解耦表征結果展示圖.圖中每一行代表風格類潛在表征保持不變的情況下,改變類別類潛在表征取值所對應的重構圖像變化;每一列代表類別類潛在表征保持不變的情況下,改變風格類潛在表征取值所對應的重構圖像變化Fig.15 The disentangled performance of AAE[48] in the MNIST[99] and SVHN[100] data set.Each row represents the change of the reconstructed images corresponding to the category latent while the style latent remains unchanged;when each column represents the change of the reconstructed images corresponding to the style latent while the category latent is unchanged

圖16 SQAIR[66]用于視頻目標檢測、跟蹤實驗結果圖.其中不同顏色的標注框代表網絡遞歸過程中所檢測、跟蹤到的不同目標Fig.16 The video target detection and tracking results of SQAIR[66],where the bounding boxes with different colors represent different objects
最后針對基于物理知識歸納偏好的解耦表征學習算法而言,該類算法更是將前兩類算法與真實世界的物理知識相結合,進一步提高了解耦表征學習的科學性.本文將目前已有的相關類研究算法分為分組弱相關物理知識與對象空間組合關系物理知識兩類,其中前者旨在利用弱監督組信息去挖掘組內數據相關性特征,這類算法的直觀可視化驗證主要通過屬性遷移圖像生成來驗證相關性特征提取的好壞,對此本節以文獻GSL[78]為例,直觀展示其在屬性遷移圖像生成中所展現出的實驗性能,如圖19所示.對于后者基于對象空間組合關系的物理知識運用而言,現有文獻主要從多目標間的組合關聯關系、目標內多部件間的組合關聯關系兩層面入手進行研究,因此本節以文獻[83]為例展示目標部件間的解耦表征學習性能,如圖20 所示,以文獻[87]與文獻[98]為例展示多目標場景下目標關系的重組化以及需要高級語義理解所支撐的智能問答任務性能,分別如圖21、22 所示.

圖17 RCN[74]用于字符分割識別的實驗結果展示圖.其中左側圖像中黃色輪廓線為字符分割結果,右側第一列為輸入遮掩數字,第二列為網絡預測的去遮掩掩碼圖Fig.17 Scene-text parsing results with RCN[74].The yellow outline in the left image shows segmentations,the first column on the right is the occlusion input,and the second column shows the predicted occlusion mask

圖18 文獻[73]所提算法的聚類實驗結果圖Fig.18 The clustering results of the algorithm proposed in the reference [73]

圖19 GSL[78]算法所實現的圖像屬性遷移實驗結果圖Fig.19 The image synthesis qualitative performance by GSL[78]

圖20 文獻[83]所提算法在人類關節動作識別以及部分關節風格轉換后生成圖像的實驗結果圖Fig.20 The human action recognition and swapping part appearance results of the algorithm proposed in the reference [83]

圖21 文獻[87]所提算法在自然場景下按照人類偏好重組目標位置以及遮蓋順序后的實驗結果圖Fig.21 The generation results of the algorithm proposed in the reference [87] after reorganizing the target position and the masking order in a natural scene

圖22 文獻[98]所提方法應用在CLEVR[128]數據集上的智能知識問答實驗結果圖Fig.22 The VQA results on the CLEVR[128] data set using the method proposed in the reference [98]
6 研究重點和技術發展趨勢
與人類相比,目前的深度學習網絡大多僅對與特定任務相關的樣本特征進行訓練,而不考慮產生這些特征的內在物理屬性,因此在面對之前未見過的糾纏圖像特征時表現出較弱的概括性與泛化性.若深度網絡能夠學習到可概括的公共屬性,即帶有實際物理語義屬性的解耦表征學習,將能夠幫助神經網絡想象各類具有不同屬性的物體,將已知耦合的圖像特征轉換為新的耦合圖像特征,例如,可以對紅船和藍車的圖像進行分解和重組,合成新的紅車圖像等,這將更有利于深度學習對數據內在本身物理特性進行挖掘,增強對各類下游任務的遷移性與魯棒性.解耦表征的目的便是挖掘數據中潛在的相互作用因子,并賦予其相互分離的數據表征,屬于可解釋性的深度表征學習范疇,能夠很大程度上提高深度學習的可解釋性,增強其內在邏輯性,在當今深度學習盛行的時代具有廣闊的研究前景.本文將目前有關解耦表征學習的研究大致概括為三類:
1)基于非結構化表征先驗的解耦表征學習,如β-VAE,InfoGAN,FactorVAE 等.通過將潛在變量的先驗分布的獨立性約束傳遞給后驗分布,促使模型學習可分離的潛在變量表示,從而達到解耦表征的效果.然而該類方法并未考慮真實世界的復雜語義信息,賦予潛在變量明確的物理含義,導致其只能應用于手寫數字體MNIST 數據集、人臉CelebA數據集等簡單數據集的解耦表征.
2)基于結構化模型先驗歸納偏好的解耦表征學習.該類模型架構歸納偏差的設計主要基于類腦的思想構建深度層次化結構表征,各個不同深度的層次代表不同語義信息,如深度梯形網絡、深度遞歸網絡、樹形網絡等.這類結構化歸納偏好的設計旨在挖掘自底向上、逐層遞進的數據表征,能夠處理復雜場景大規模數據集以及數據流信息的解耦表征.然而這類架構若僅僅模擬人腦結構,并未賦予其更強的邏輯語義約束,便不能真正達到符合人類理解的解耦表征學習.
3)基于物理知識歸納偏好的解耦表征學習.該類解耦表征學習旨在將強先驗物理語義信息與邏輯關系加入模型設計中,如多輸入數據間的物理關聯性、部件-個體間的邏輯拓撲關系,個體-整體間的空間物理關系等,能夠同時融入上述兩類歸納偏好的設計構成最終的解耦表征模型,完成數據內部語義空間的挖掘,能夠處理復雜自然場景的數據.
本文對目前的解耦表征學習研究進行歸納總結后,認為該研究領域依舊面臨著許多嚴峻的挑戰,具有著廣泛的研究前景.以下是對該領域技術發展趨勢的展望:
1)建立世界的因果模型,以支持解釋和理解,而不只是解決模式識別問題;
2)物理和心理學的直觀理論基礎學習,以支持和豐富所學習的知識;
3)利用組合能力學習快速獲取知識,并將知識推廣到新的任務和情況;
4)提出能夠量化由不同模型實現的解耦程度非常重要.但是,為此設計度量標準并不容易.除了主觀解釋之外,盡管有大量學者提出各種指標,如分離屬性可預測性[49]、互信息差異[52]、FactorVAE度量[51]、β-VAE 度量[46]、解耦性/完整性/信息性(Disentanglement/Completeness/Informativeness,DCI)度量[130]、屬性依賴關系(Attribute dependency,AD)度量[131]等,但目前還沒有就定量衡量解耦性能的最佳標準達成共識,這些指標中是否有任何一個能像人們通常想象的那樣衡量解耦程度尚不清楚.
在當今深度學習快速發展的背景下,泛化性與可解釋性成為制約其進一步突破的關鍵問題,受到社會各界的廣泛關注.解耦表征學習旨在挖掘數據內部潛在生成因子,并利用可分離的潛在表示分別對其進行表征控制,對數據進行深入理解,揭示數據內部的生成作用機理,逐漸成為提高深度學習泛化性、可擴展性與可解釋性的重要手段.本文對當前解耦表征學習研究進行了歸納總結,該研究作為一門快速發展的開放性學科領域,在內涵外延、模型理論、技術方法及實施策略方面還需要大量學者繼續投入更多的研究與實踐.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
