基于LIME的惡意代碼對抗樣本生成技術
2022-03-08 12:26:04黃天波李成揚劉永志李燈輝文偉平
北京航空航天大學學報 2022年2期
黃天波,李成揚,劉永志,李燈輝,文偉平
(北京大學 軟件與微電子學院,北京 102600)
近年來,惡意代碼檢測技術的研究表明機器學習在代碼檢測問題上被越來越多的研究人員應用,眾多學者提出將機器學習技術作為下一代惡意代碼分類器的關鍵組成部分[1-5]。分類器從惡意代碼中提取特征,使用機器學習算法對良性程序與惡意程序進行分類。根據使用的特征性質,可以將惡意代碼檢測技術分為靜態檢測[6-7]和動態檢測[8]。然而機器學習分類器在多個領域都被證明是不安全的。隨著機器學習越來越廣泛的應用,對抗樣本攻擊和防御的研究也在變得越來越有意義,這一領域通常被歸為對抗機器學習(adversarial learning)。在惡意代碼檢測問題上,基于機器學習的分類器在面對對抗樣本攻擊時也可能是非常脆弱的。因此,研究在惡意代碼檢測問題上的對抗樣本生成技術可以增加對這種攻擊方法的了解,避免將分類器暴露在這種攻擊之下,從而針對該攻擊提出針對性或者普適性的防御方法。同時,研究人員可以通過攻擊方法攻擊其所研究的分類器,對分類器的魯棒性進行評估。
本文提出了一種基于模型無關的局部可解釋(local interpretable model-agnostic explanations,LIME)[9]的對抗樣本生成方法。該方法可針對未知算法和參數細節的分類器生成有效的對抗樣本,并且通過引入擾動常量,使該方法具有了適用范圍廣泛、靈活控制擾動大小的優點。同時,在實驗中驗證了該方法的健全性。
1 相關研究
為使提出的對抗樣本生成方法不僅可攻擊分類器,同時有助于評估防御[10]、提供具體級別的安全產品[11],針對對抗樣本相關技術、攻擊者對抗能力的描述和樣本修改進行了相關的研究。
1.1 惡意代碼對抗樣本相關技術
對抗樣本攻擊意為通過微小地修改機器學習分類器的輸入樣本,誘導分類器對修改后的輸入產生錯誤的輸出結果。2014年,Szegedy等[12]在神經網絡模型背景下給出了嚴謹的問題描述,之后出現了基于梯度的白盒解決方案[13]。但是因為現實中的大部分分類器都是閉源的,相較于白盒方法,黑盒更具有廣泛的使用價值。
2017年,Hu和Tan[14]提出了MalGAN,其是一種針對惡意代碼分類器的黑盒對抗樣本生成方法。使用該方法可以對一些使用One-Hot型(只有0和1兩種取值)特征的黑盒分類器生成對抗樣本。
2017年,Chen等[15]提出零階優化(zeroth-order optimization,ZOO)方法,其是一種基于零階優化估計目標分類器梯度進而生成對抗樣本的方法。由于不需要梯度,ZOO也是一種黑盒方法,使用ZOO無需額外訓練模型。
2016年,Ribeiro等[9]提出LIME方法,其是一種與模型無關的方法(model-agnostic)。原理是:使用可解釋的簡單模型在局部逼近目標模型,無論目標模型有多復雜,其在局部(可理解為切點)的趨勢(可理解為切線)都可以用一個簡單模型來刻畫,從而通過簡單模型解釋局部的特征權重。對于給定的目標模型f和輸入向量x,LIME方法可以在f的局部使用簡單模型模擬目標模型的局部性質,從而判斷x各分量對分類結果的影響權重。局部模擬需要一組與x相近的特征,使用z代表臨近特征。LIME對特征的解釋ξ(x)通過下式表達:

式中:g∈G,G為用于模擬目標模型的簡單模型集合,通常包括線性模型和決策樹;Πx(z)用于度量局部特征z和x的接近程度;Ω(g)用來衡量g的復雜性(不利于解釋的程度),通常取決于選用的簡單模型,如選用決策樹,決策樹的深度就是影響Ω(g)的主要因素;L為損失函數,用來描述g在x附近模擬f的效果,模擬效果越好,則L的值越小,L的一種實現如下:
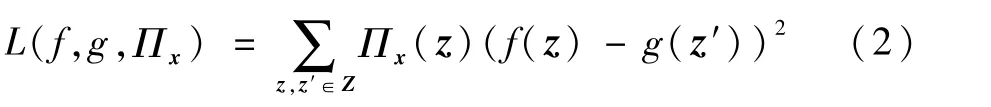
在L中,z和x的距離越小,則Πx(z)越大,也就是說,離x越近,誤差權重越大,通過最小化,這樣的損失函數使g在x局部獲得較好的模擬效果,而L(f,g,Πx)+Ω(g)最小,意味著使局部模擬和可解釋的綜合效果最好。Ribeiro等[9]用KLasso算法選擇k個特征(通過正則化路徑),基于對x的隨機擾動生成一組數據,通過最小化L(f,g,Πx)+Ω(g)學習到最優的簡單模型g,通過對g的參數w分析即可得到特征權重,如當g是線性模型時,g的參數w就對應了每個特征的權重。如果k被設置為特征的總數,那么將得到所有特征的權重。由于LIME方法在設計時沒有對目標模型做任何假設約束,使用時無需知道目標模型的算法和參數,理論上可用于解釋任意黑盒模型。因為只在局部用簡單模型模擬,效果好速度快,所以這也是本文所設計的對抗樣本方法選用LIME的原因。
1.2 對攻擊者能力的描述
精確的描述攻防場景,需要對攻擊者的攻擊能力做出合理的預估[16]。本文采用Stokes等[11]的方法,將特征分為正特征(positive feature)和負特征(negative feature),正特征表示樣本中有利于使分類器判斷為惡意代碼的特征,這些特征往往代表惡意行為,負特征表示樣本中有利于使分類器判斷為良性代碼的特征。Crandall等[17]指出,攻擊者通常采取變構策略,使用替代代碼的方式來達到所需的惡意目標,攻擊者有能力刪除正特征或添加負特征。在MalGAN方法中,假設攻擊者只能添加特征,不能刪除特征,從而保證不影響原樣本的程序特征,但該方法不對添加特征的數量進行限制,本身的假設存在低估攻擊者對抗能力的可能。Incer等[18]使用了特定的對抗能力來描述其所提供的安全機制的安全邊界,通過分析一系列特征的修改,并評估每種類型的修改是否簡單廉價,從而確定攻擊者的對抗能力。但是在對這些類別的修改進行評估時,評估的標準缺少靈活性。事實上,對于攻擊能力較強的專業黑客,即使是被認為困難的修改,也是可以完成一定數量的,而對于被認為是簡單廉價的修改,在現實場景中,攻擊者也不一定會不計數量的大量修改,大量未使用的特征可能增大被檢測為對抗樣本的概率,如Xu等[19]提出一種檢測對抗樣本的方法,篩選被添加到原樣本中卻未使用到的修改作為檢測標準之一。
基于上述分析,可以明顯看到這些假設容易低估或者高估一些攻擊者,導致只能用于特定研究背景,具有一定的局限性。為了尋找適合衡量對抗能力的方法,需要進一步分析攻擊者修改樣本的過程。
1.3 樣本修改過程
攻擊者在其能力和成本范圍內對原樣本進行修改,在保證新樣本可執行的前提下,要確保新樣本與原樣本主要程序功能相同,即保證對抗樣本的有效性。一般修改的過程分為2個部分:逆提取和逆預處理。逆提取中,針對新舊樣本的差異特征r和中間層表示的對應關系,通過直接修改中間層文件或者樣本的源代碼以滿足在不影響其他特征的基礎上添加新特征。逆預處理實現修改后的中間層文件到可執行文件的轉變,可以通過逆向工程的方式從中間文件轉換為可執行文件,甚至若在逆提取階段中直接修改源碼,則可編譯得到可執行文件。
通過對攻擊過程進行分析可知,修改樣本的難度和成本主要體現在逆提取過程中。因此引入擾動常量的概念,用于描述攻擊者的對抗能力,并提出基于LIME的擾動方式的實現。
2 對抗樣本生成方法設計
2.1 基于LIME的惡意代碼對抗樣本生成過程
對抗樣本的生成過程主要包含4個部分:探測(A部分)、擾動算法(B部分)、逆向過程(C部分)和驗證部分(最下方虛線部分),如圖1所示。

圖1 基于LIME的惡意代碼分類器對抗樣本生成過程Fig.1 Adversarial sample generation process of malicious code classifier based on LIME
本文對抗樣本生成方法所解決的問題可描述為

式中:mal(malicious)為惡意代碼分類標簽;ben(benign)為良性代碼分類標簽;x為目標分類器f的輸入,表示惡意代碼中提取的特征;r為對x的擾動(perturbation);函數g為獲取樣本的主要程序功能,g(x)為x原本的主要程序功能,g(x+r)為修改后的主要程序功能。在保證代碼語義的前提下,誘使目標分類器將惡意代碼標識為良性代碼。對圖1的4個模塊做出具體闡述如下:
1)探測。通過特征工程獲取樣本特征,探測目標分類器f的分類結果,當結果為ben時結束方法,否則進行下一步。
2)擾動。使用基于LIME的擾動方法生成一個擾動r,滿足f(x+r)=ben,生成成功則進入下一步,失敗則方法以失敗結束。
3)逆向過程。根據擾動r修改相應樣本程序,生成最終可逃逸檢測的對抗樣本,使用該對抗樣本再次進行步驟1的探測,應能夠正常結束方法,否則可能是在逆向過程出錯,檢查錯誤后重試方法。
4)驗證過程。如果修改后的樣本滿足式(4),且能夠按照探測模塊的方法再次探測,并能得到探測結果ben,則驗證通過,結束方法。
2.2 擾動算法設計
擾動模塊的實現包括2個方面:擾動常量和擾動方式。擾動常量形式化地描述了攻擊者在有限成本內修改樣本,且保持樣本主要功能不變的能力。擾動常量越大,攻擊者能力越強;擾動方式指定了對于具體特征的修改,不同于使用雅可比算法[20]等白盒方法,使用LIME模擬黑盒分類器在惡意樣本處的局部表現,從而確定影響樣本分類的關鍵特征,然后使用一個擾動算法,在保證不影響輸入樣本主要程序功能的同時,修改部分關鍵特征。
2.2.1 擾動常量
擾動常量R,用于描述在特定攻擊場景下攻擊者的成本和能力邊界,也就是對抗能力——攻擊者在有限成本內修改樣本,且使修改后的樣本保持原樣本主要程序性質不變的能力。以下是R的一般形式:

式中:k為正整數;di、si1和si2均為實數。R為一個k×3的向量,包含k個擾動規則;i-th表示第i個擾動規則,通常用1個或2個擾動規則描述一種特征,對應添加和刪除規則。不妨假設i規則描述一種A特征,則攻擊者使用i規則對A特征所能修改的維數比例的最大值用di表示,di取值在[0,1]之間,如果A特征在特征向量中一共m維,攻擊者真實修改的A特征維數應不大于m×di;用s描述對具體某維特征的修改能力,允許對某個特征在初始值的基礎上加s,這里的si1和si2用來描述s的取值范圍。當si1與si2確定時,區間[si1,si2]表示對所有A特征,s取值應在[si1,si2]范圍內。這個區間往往由特征的性質、攻擊者的攻擊成本和能力所決定。這樣k個擾動規則綜合起來,就描述了R表示的范圍。攻擊者能力越強或越不計成本,R表示的范圍就越大;特征越容易修改,R表示的范圍也越大。
2.2.2 基于LIME的擾動方式實現
擾動方式指定了對于具體特征的修改。首先使用LIME方法求解出逼近真實情況的ω。在LIME方法中,需要選擇簡單模型g來模擬目標分類器,這里以線性模型為例,那么g(x)可以表示為

式中:ω={ω1,ω2,ω3,…,ωm}為g的參數。使用K-Lasso算法選擇k個特征(通過正則化路徑),然后基于對x的隨機擾動生成一組臨近x的數據,在這組數據基礎上最小化損失函數L(f,g,Πx),可以得到此時g的參數ω,用ω近似表示特征x的權重,即令w=ω,從而求解出w,如果k被設置為特征的總數,那么將得到所有特征的權重。
當攻擊者獲取權重w之后,需要根據w和擾動算法生成一個符合式(3)、式(4)的擾動r,且攻擊者可以在對抗能力范圍內對惡意樣本做出r對應的修改。不妨設分類器給出的置信度在[0,1]區間內,以0.5為分界,0表示百分之百確定是ben樣本,1表示百分之百確定是mal樣本。創建擾動r的過程如算法1所示。
算法1 創建擾動r的算法。
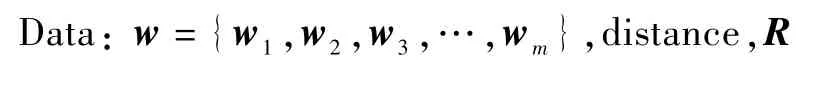
Data:w={w1,w2,w3,…,w m},distance,R

1 r←{Δx1,Δx 2,Δx3,…,Δx m},Δx i=0 2 U←{(1,w1),(2,w2),(3,w3),…,(m,w m)}3 sum←0 4 list←sortw(U)//根據w i的絕對值進行遞增排序5 if not list then 6 return fail//list為空7 end 8 while list do 9 i,w←list.remove(0)//移除第1個元素10 Δx i←arg minΔx,Δx∈RΔx·w 11 sum←sum+Δx i·w 12 if sum<distance then 13 break 14 end 15 end 16 f(x+r)←ben?return r:distance←distance×2,go 5
攻擊者首先探測到分類器f檢測惡意樣本x的置信度confidence=f(x),對于惡意樣本,confidence在(0.5,1]之間。由于w是已經求得的,攻擊者需要在x中選擇一些維度,在使confidence減少的方向上,做一些能力和成本范圍之內的改變。考慮g取線性模型的情況,此時有g(x)=w·x,且g(x+r)=g(x)+g(r),因為g(x)是對f(x)的局部模擬,攻擊者可以通過g近似計算confidence,所以一般滿足g(r)=w·r<-0.2即可。在具體選擇r的維度時,由于w已經用LIME方法求得,可以使用貪心法,按權重由大到小,依次判斷能否對相應特征做出符合R要求的修改,從而挑選合適的維度,用Δx∈R表示對某個特征進行Δx的變動是符合R要求的修改,如果符合,就加入候選維度。
3 實驗評估
為了驗證本文所提出的基于LIME的對抗樣本生成方法的效果,分別進行攻擊實驗和對比實驗。攻擊實驗用于測試本文方法在目標分類器上的攻擊效果;對比實驗用于和同類方法做比較,增強結論的說服力。本節將介紹實驗環境、數據集、評估指標、目標分類器設置以及實驗設計。
3.1 實驗環境
實驗的軟硬件環境信息如表1所示,實驗代碼主要使用Python3.6.3實現,在數據集準備環節借助了IDA pro 7.0提供的Python 2.7.17腳本執行接口,在IBM 提供的adversarial-robustness-toolbox 1.1.1包中,封裝了許多應用于機器學習分類器的攻擊與防御方法,這包括本文要使用的ZOO方法,此外本文所要使用的LIME方法被封裝在lime 0.1.1.37包中。
表1 實驗的硬件、軟件環境Table 1 Hardware and software environment of experiment
3.2 數 據 集
本文收集了2組不相交的Win32 PE文件,這2組文件的收集方式借鑒于文獻[21],對于每個PE文件,都使用其IDA pro反匯編生成的ASM文件來代表PE文件。良性樣本源于系統鏡像中使用ninite[22]安裝的50多個供應商的應用軟件,進而有效避免學習和識別與特定供應商相關聯的文件[23]。惡意樣本包含來自Ramnit、Lollipop等9個惡意代碼家族的10 868個Win32 PE惡意程序對應的ASM 文件,這些文件來自2015年微軟舉辦Kaggle比賽[24]時公開的數據。
3.3 評估指標
因為攻擊者希望原本被識別的惡意樣本,經改變為對抗樣本后,被標識成良性樣本,攻擊前后的真陽性率TPR之差就是有效對抗樣本的比例。為了直觀考慮,將攻擊前后的TPR之差與攻擊前的TPR之比稱為攻擊成功率,表示為ASR,則有ASR=1-TPRafter/TPRbefore;除上述2個指標外,為了保證說服力,本文采用準確率ACC來評估自建的目標分離器,僅保留那些準確率90%以上的分類器納入實驗。采用的評估指標如表2所示。表中:TP為真陽性樣本數量,FP為假陽性樣本數量,FN為假陰性樣本數量,TN為真陰性樣本數量。

表2 評估指標Table 2 Evaluation indicators
為充分測試方法的效果,目標分類器根據使用的算法或特征差異,可分為18個,如表3所示。算法涵蓋線性、樹形和深層神經網絡類算法,包括LR、RF、SVM、MLP算法,特征包括API、opc-2gram、opc-3gram。
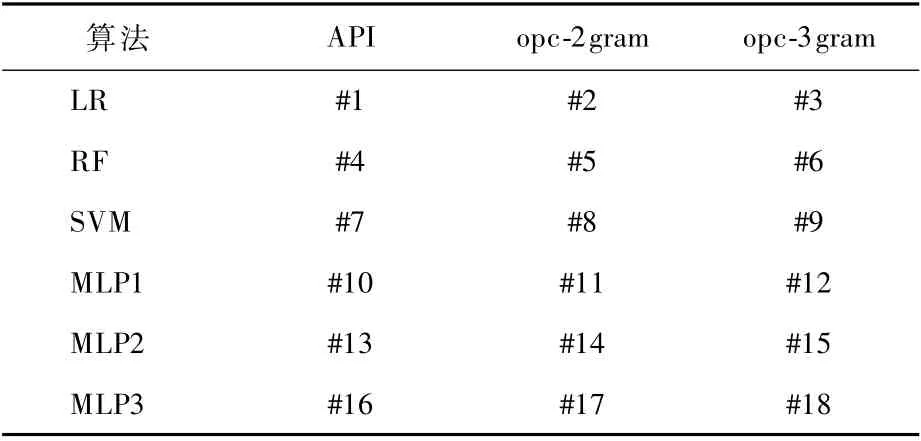
表3 目標分類器設置Table 3 Target classifier setting
將算法用集合alg表示,特征用集合fea表示,alg與fea做笛卡兒積,則有12個有序對組合(表3的#1~#12),用一個數字編號表示一種組合,例如,#1表示(API,LR),代表使用API特征和LR算法訓練的一個分類器。考慮到基于MLP的模型根據隱層數不同可能存在較大的性質差異,對#10~#12分類器額外設置了2組不同層數的分類器,因此共有18個目標分類器。
3.4 實驗設計
攻擊實驗中,惡意樣本數據集有60%用于目標分類器的訓練,在剩余的40%中,在9個惡意代碼家族各隨機選取了20個樣本,將這180個樣本稱為攻擊樣本,用于生成對應的對抗樣本。
使用本文的對抗樣本生成方法,生成上述180個攻擊樣本的對抗樣本來攻擊每一個目標分類器。用擾動常量控制擾動大小[25],繪制擾動大小-TPR圖、擾動大小-ASR圖,以獲得不同擾動強度下的攻擊效果。為進一步增強說服力,本文設計了對比實驗:復現MalGAN和ZOO這2個先進的黑盒對抗樣本生成方法,生成攻擊樣本的對抗樣本,攻擊#1、#4、#7、#10、#13、#16分類器,記錄TPR攻擊前后的變化,并與本文方法進行對比分析。
3.5 實驗與結果
圖2為基于不同擾動維度(Dr)生成對抗樣本,攻擊各目標分類器產生的TPR和ASR的變化圖。查看TPR圖可以發現,18個分類器的TPR均降到了接近0的水平,即在較高擾動代價情況下,本文方法幾乎100%成功地攻擊任意惡意代碼分類器。
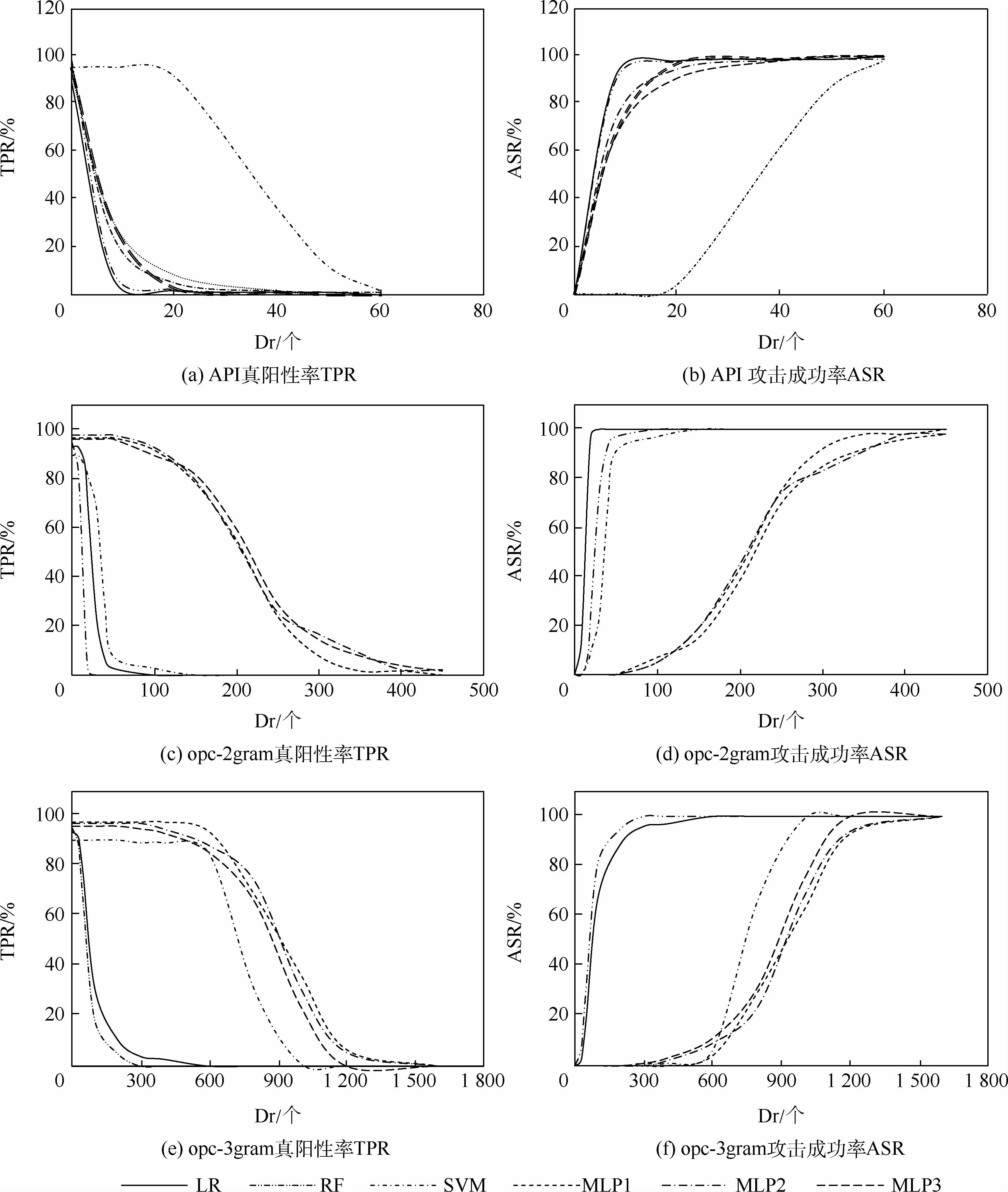
圖2 三種特征的Dr-TPR圖和Dr-ASR圖Fig.2 Dr-TPR and Dr-ASR of three characteristics
對比實驗中,使用MalGAN和ZOO生成攻擊樣本的對抗樣本,攻擊#1、#4、#7、#10、#13、#16分類器。每個分類器性質不同,選用參數也有差異,本文傾向于選擇使對抗樣本更有效的參數,經過多次實驗,結合本文方法匯總如表4所示。
從表4可以看出,MalGAN和本文方法都具有較好的效果,且攻擊效果相似(將TPR降到更低,且降幅相似)。ZOO在實驗中表現不佳,攻擊后的TPR 都 在50%以 上;MalGAN 將#1、#10、#13、#16分類器的TPR降到0,#4、#7分類器的TPR降到1.67%和0.56%;本文方法將#1、#4、#10、#16分類器的TPR降到0,而#7、#13分類器的TPR分別降到1.67%和1.11%。為了進一步對比這3種方法,比較了3種方法生成的對抗樣本本身的差異。

表4 API特征分類器的真陽性率對比Table 4 API feature classifier and TPR compar ison
實驗中的API特征是One-Hot型的,對應取值應該是0或者1,而ZOO在特征中可能出現-3、-1、2等值,只能通過篩選來獲取符合要求的對抗樣本,這將導致有效對抗樣本進一步減少;MalGAN適用于One-Hot類型的特征,主要對比其生成的對抗樣本的擾動維度。表5為MalGAN和本文方法在對各分類器取得較好攻擊效果時的平均擾動維度Dr。其中,攻擊效果相似的情況下,本文方法比MalGAN生成的樣本平均擾動維度小,這可能因為本文方法有針對擾動大小的設計。

表5 兩種方法生成的對抗樣本平均擾動維度Table 5 Average perturbation dimension of adversarial samples generated by two methods
4 結 論
1)本文方法是一種有效的黑盒對抗樣本生成方法。使用該方法生成的對抗樣本測試黑盒的惡意代碼分類器,能顯著降低分類器的真陽性率。
2)本文方法適用范圍廣泛。使用該方法攻擊18個不同算法或特征的目標分類器,均有不錯的攻擊成功率。目標分類器的算法涵蓋了線性算法、樹形算法和深度神經網絡算法,而特征既有One-Hot型也有數值型。
3)本文方法能有效控制擾動的大小。可以通過設置不同的擾動常量來控制對抗樣本的擾動維數和擾動范圍。
4)本文方法具有健全性。隨著擾動的增大,攻擊成功率是嚴格遞增的;隨著擾動持續增大,攻擊成功率接近或達到100%。雖然過大的擾動可能會使對抗樣本失去意義,但可以說明該方法是健全的。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
