基于能源分解的用戶用電行為模式分析
2022-03-08 11:56:12盧瑞瑞于海陽楊震賴英旭楊石松周明
北京航空航天大學學報 2022年2期
關鍵詞:用戶
盧瑞瑞,于海陽,楊震,賴英旭,楊石松,周明
(北京工業大學 信息學部,北京 100124)
近年來,大數據技術給人們的生活帶來了很多便利,而智能電網被看作是大數據技術的應用之一,吸引了很多學者利用用戶數據挖掘數據中潛在價值方面的研究。
能源問題是當今社會面臨的最大挑戰之一。在美國,建筑消耗的能源占總能耗的40%,其中73%是電力消耗[1]。研究表明,有效的能源管理可以減少建筑物的10% ~15%電力消耗[2],用戶對家用電器用電量的掌握有助于調節用電行為,實現能源優化調度。而能源分解可以獲得用戶的詳細用電信息,讓用戶對自己的用電狀態更加了解,在一定程度上也可以誘導用戶用電行為達到節能的目的。另外,能源分解后的數據可以反映詳細的能源使用情況,給用戶提供改進的依據。詳細的能源分解可以實現對家庭用戶電力消費行為分析,實現配電的雙向交互、信息交換、信息處理等環節的智能控制,提高供電側的可靠性和安全性,從而實現用戶方和供電方的利益最大化。
由于智能電網是直接面向用戶的,網絡結構復雜、類型繁多,如何深入分析用戶的用電行為,挖掘出用戶用電行為潛在價值,成為該領域的研究重點和難點。20世紀80年代,麻省理工學院提出了非侵入式負載監測(NILM)[3]方法,該方法首次從智能電表端采集用戶的聚合用電信號并從中推斷出每個電器的用電信號。隨后,研究人員在這些方法的基礎上尋找更有效的電信號特征,如穩態功率的諧波、電流消耗和瞬態噪聲[4-7],這些方法都稱為基于事件的方法,其依賴于通過捕獲特征來識別設備[8];另外一種方法不依賴于事件檢測分類設備,而是綜合考慮所有的樣本建立預測模型,是基于非事件的方法。2010年,Kolter等[9]使用稀疏編碼算法來學習每個設備在一周內的功耗模型,再結合這些學習模型,僅使用其聚合信號來預測以前未知家庭中不同設備的功耗。Kim[10]和Parson[11]等 使 用 因 子 馬 爾 可夫模型(FHMM)將用戶的聚合用電信號分解成單個電器的用電信號,并且隱藏設備的狀態。2012年,Kolter和Jaakkola[12]在FHMM框架的基礎上,提出了基于凸規劃的近似算法。隨著深度學習的發展,一些研究人員提出使用深度神經網絡的方法通過分類來識別設備從而進行能源分解[13-15]。除了這些單通道源分離工作外,研究人員還致力于利用其他信息來進行能量分解。2016年,Batra等[16]提出了單個設備的功耗可以通過具有相似特征家庭的數據估計得出。然而,所有這些技術大部分都需要高分辨率的數據,而大多數智能儀表的采樣率都達不到這個要求。另外,這些方法需要復雜且耗時的分解過程,難以在普通家庭中快速投入使用。
2005年,李培強等[17]基于模糊聚類原理提出了模糊C均值算法和模糊等價關系2種算法對變電站的綜合負荷進行分類的方法。2009年,王璨和馮勤超[18]提出從當前的市場價值、潛在市場價值和區域貢獻價值等角度來對用戶的用電行為進行聚類研究。這2種聚類角度都過于宏觀,未考慮到用戶的用電負荷特征,不能實現用戶電力負荷的精細化管理。2010年,李欣然等[19]提出使用模糊C均值算法對用戶的日用電負荷曲線進行分析來對用戶所屬的行業進行分類。2018年,Zhong等[20]提出使用K-Means算法對用戶添加標簽,實現用戶畫像為電力公司了解用戶的電力消耗習慣、了解用戶需求、提高服務質量提供數據支撐。2019年,Nordahl等[21]提出使用K-Medoide方法來分析和理解家庭的用電量數據,通過提取的知識為每個特定家庭創建正常用電行為模型用于異常行為檢測。
綜上分析,在眾多的能源分解方法中,稀疏編碼方法相對簡單有效,根據相似用戶預測能耗的方法有一定的合理性但是不完全據此預測,而智能電網用戶用電行為分析方法仍過于粗糙,需要進一步精細化分析。如何提高能源分解的準確性,并合理利用分解結果對用戶的用電行為進行分析是一個有趣且充滿挑戰的問題。
本文針對現有能源分解系統分解準確率不高、難以應用到普通用戶、用戶用電行為聚類分析特征欠缺等問題,首先,提出基于稀疏約束的能源分解方法,在不丟失信號特征的前提下更簡單地獲取信號中蘊含的主要信息,同時也方便對信號做進一步的加工處理。其次,提出基于同質性約束的能源分解方法,在能源分解的過程中把用戶之間同質性考慮進去,來提高分解系統的準確性。最后,通過對基于用電模式的用戶行為聚類分析,完成智能電網用戶的分類,并分析每類用戶的用電特點。
1 系統描述
1.1 系統架構流程
本文的整體結構可以表述為如圖1所示的四元結構圖,普通用戶家庭、智能電網、數據分解系統和聚類分析系統是整個結構的4個組成部分。普通用戶家庭從智能電網獲取電能,從數據分解系統獲取一段時間內的用電反饋。智能電網給用戶提供電能,并采集用戶的用電數據反饋給數據分解系統和聚類分析系統。數據分解系統將總用電數據分解成單類用電器的用電數據反饋給用戶,或者提供給聚類分析系統分析用戶的用電行為。聚類分析系統通過數據分解系統提供用戶的詳細用電數據對用戶用電行為進行聚類分析應用于網絡規劃、需求響應和信息推薦等。

圖1 系統四元結構Fig.1 System quaternion structure
系統首先從智能電網采集數據集,對數據集進行篩選和預處理,選擇用電數據多的用戶,統一數據格式,把數據處理成結構化的矩陣數據為使用做準備;其次能源分解模塊把用戶單類電器用電數據作為訓練集訓練模型,用戶總的用電數據作為測試集,把用戶總的用電數據分解成單類用電器的用電數據輸出;然后評測能源分解模塊的性能,能源分解模塊分解出來的單類用電器的用電數據也可以提供給其他第三方應用;最后使用能源分解前的總用電數據和能源分解后的單類電器用電數據對用戶進行聚類,并對比分析其聚類結果。
1.2 系統主要模塊
1.2.1 數據預處理模塊
本文采用Pecanstreet數據集進行實驗,該數據集中包含69個電器,每個用戶的單類用電器是每小時采集一次用電量,如果采集500個家庭一個月的用電量可達到2億多條數據。數據規模龐大,用戶用電器類別不一致,并且包含很多無效的數據。因此,本文對原始數據集進行預處理。首先,篩選可用的數據,選擇部分用電器和用戶的用電數據進行研究;其次,處理缺失數據,對鄰近時間段的數據求均值進行插入來完善數據集;再次,處理異常數據,把長時超出電器負荷的值作為異常數據,用鄰近時間段的數據來替代;最后,把數據轉換成本文需要的數據格式為實驗做準備。其中,數據篩選部分選取數據的準則為:對于電器類別,選擇大部分家庭中都有的用電器作為主要研究對象,不常見或者只存在部分家庭中的用電器的用電數據對其求和作為雜類;對于用戶,選擇用電數據較多的用戶,丟棄連續多天不用電或用電異常的用戶。最終得到5類電器(空調、電爐、洗衣機、冰箱和其他電器)的總和,264個用戶2周內的用電數據用于本文的實驗。
1.2.2 能源分解模塊
本文的能源分解模塊把用戶的總用電數據分解成單類用電器的用電數據。非負矩陣分解(nonnegative matrix factorization,NMF)是處理盲源分離問題的一種有效方法,其可以通過一些線性組合來近似混合信號。2010年,Kolter等[9]提出判別式稀疏編碼的能源分解方法,認為用電數據存在稀疏性,在用非負矩陣進行能源分解時,優化目標中加入了L1正則化項來進行稀疏約束。本文基于稀疏非負矩陣分解這個研究方向來改進原有的算法,提升能源分解的準確率。首先,收集數據并對數據預處理,把數據稀疏表示,生成稀疏約束正則項L1;其次,計算不同家庭特征和用電量之間的相關性進行相關性分析,建立同質性正則項L2;然后,基于非負矩陣分解算法、同質性約束和稀疏約束建立模型;最后,繼續優化模型并進行模型求解。
1.2.3 聚類分析模塊
本文的聚類分析模塊利用能源分解模塊得到的分解結果對用戶的用電行為進行聚類分析。首先,總結了傳統的智能電網用戶聚類方法,然后,選擇基于K-Means聚類算法的智能電網用戶聚類方法對其改進應用于本文提出的方法。
2 能源分解和聚類分析設計
2.1 基于L 1/2范數和同質性約束的能源分解方法
2.1.1 基于非負矩陣分解的能源分解模型
NMF是由Lee和Seung[22]于1999年在Nature上提出的一種矩陣分解方法[23],該方法分解后的所有分量都是非負的,并且可以實現降維的目的。具體地,NMF方法主要解決如下問題:給定非負矩陣X,找到非負矩陣B和A使得X≈BA,目標函數可以建模為

式中:X為待分解矩陣;B為特征矩陣,每一列是一個基向量即特征,矩陣A是代表特征重要程度的權重矩陣,即A的行表示每個基向量的貢獻大小。優化式(1),找到最優的B和A使得式(1)最小。式(1)在求解時,如果只考慮B或者A一個變量時是凸函數,但是同時考慮2個變量時就是非凸問題,對于非凸函數想要找到全局最優解是不切實際的。Lee和Seung[22]提出使用乘性迭代法進行求解,對2個變量交替迭代尋找最優,迭代如下:
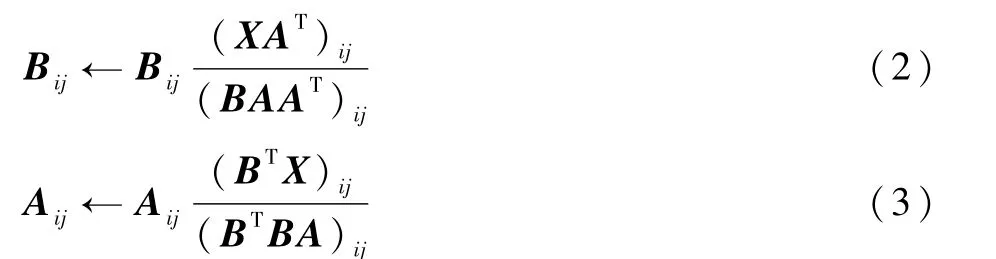
對于NMF方法進行優化求解時,是一個非凸優化問題,最終得到的是一個局部最優解,也就是說基本NMF方法的最優解不唯一。因此,在實際應用中,研究者通常會加入一些數據的先驗知識,縮小解的范圍并且使求解結果更加合理。而這些先驗知識則是通過給NMF添加正則項約束的方法加入,添加正則化后的NMF方法模型如式(4)所示:
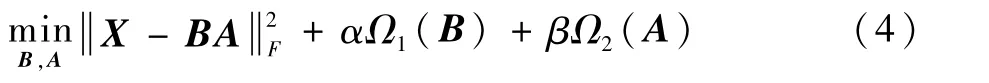
式中:函數Ω1和函數Ω2表示正則化項,對矩陣B和矩陣A進行約束;α和β為正則項系數,來控制該正則項約束的強弱。正則化的NMF方法因其加入了先驗知識,使矩陣分解的結果具有了一定的實際意義,更具有可解釋性,因此越來越受到關注。本文提出的能源分解方法即建立在正則化的NMF方法基礎之上。



式中:L為損失函數用來描述真實值與預測值之間的誤差;Ω為正則項。正則項可以把先驗知識加入到模型的學習中去,讓學習到的模型具有指定的特性,讓經驗風險和模型復雜度同時最小。正則化還可以縮小解的范圍,加快模型的求解速度,常見的正則項有L2范數、L1范數、L0范數等。其中L2范數可以防止模型過擬合,L1范數和L0范數正則項對參數懲罰可使參數稀疏。
L0范數、L1范數和L2范數的定義如下:
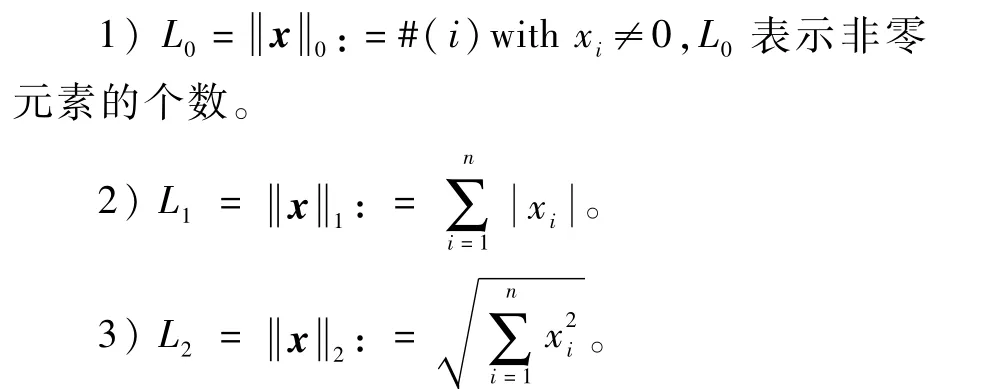
范數表示的是某個向量空間或者矩陣中每個向量的長度或者大小。因此,范數正則項可以理解為對模型參數解空間添加限制,L2范數把參數的解限制在一個圓形的球體內,L1范數把參數的解限制在錐形體內,L0范數則把參數的解限制在坐標軸上。L2范數正則項使模型的解取圓內的參數,縮小解的范圍以防止模型過擬合,提升模型的泛化能力。而L1范數與L2范數不同之處在于L1范數把解約束在錐形體內,等直線最先和解空間相交的地方總是在錐角即坐標軸上,而坐標軸上的點其他維坐標是零。因此,L1范數正則項使解中出現零更多,從而達到稀疏約束的目的。
近年來,對L1正則化性能的研究已經取得了很大的突破,然而,在實際應用中L1正則化產生的性能往往小于L0正則化,但是對L0正則化的求解又是一個NP難問題。本文通過對范數正則項的分析提出L1/2范數正則項來解決L1范數稀疏約束效果不好,L0范數不易求解的問題。基于L1/2范數稀疏約束的非負矩陣分解能源分解目標函數定義為

式中:Xi為第i類用電器的用電數據矩陣,i=1,2,3,4,5分別為空調、洗衣機、電爐、冰箱和其他電器的總和;Bi為特征矩陣;Ai為特征重要程度的權重矩陣;β、γ為L1/2范數正則項的系數,用來控制正則項的強弱。對于L1/2正則項定義如下:

式(10)和式(11)可以通過如下所示的乘性迭代來求解:
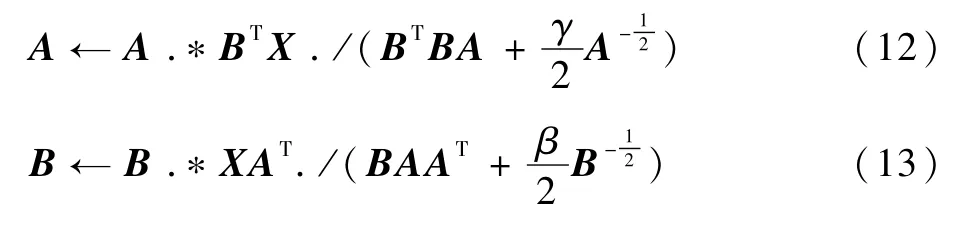
式中:符號“.*”和“./”表示矩陣的點乘和點除。如果矩陣A或者矩陣B中的元素為0,可以在0元素上加上一個很小的數進行平滑,避免分母為0。
2.1.3 用戶用電模式同質性建模
在社交領域中,同質性表示不同用戶之間的相似性[25]。本文利用家庭用電模式之間的相似性進行建模。
1)用戶用電模式的相似性
利用相似的家庭相似耗能預測,可能得到錯誤的結論。因此,本文只考慮把相似性作為基礎模型分解能源時的一個影響因素,來提高能源分解的準確率。
受此啟發,本文通過對不同的數據集進行研究分析發現,總用電量和單類用電器能耗之間也存在著相似性。用電量較高且用電量比較相似的用戶在對空調等大功率電器使用上具有一定程度的相似性。用電量較低且用電量比較相似的用戶在對照明設備等小功率電器的使用上有著一定的相似性。同樣,家庭住宅面積相似的用戶在空調設備的用電上存在著相似性。
2)同質性模型
總用電量相似的家庭在空調等大功率電器的用電量更相似,家庭住宅面積相似的家庭在空調、照明設備等用電器的用電量更相似。本文利用這一先驗知識,構建同質性系數,通過添加與同質性系數有關的正則項,來提高模型的分解性能。
首先,本文定義用戶i和用戶j之間的同質性系數為ε(i,j)并且滿足:
①ε(i,j)∈[0,1]。
②ε(i,j)=ε(j,i)。
③同質性系數的值越大,用戶之間的相似度就越大,即用戶在某一用電器使用量上越相似。
用戶在某一用電器用電量的相似性在本文提出的能源分解模型中,可以表示為非負矩陣分解后權重矩陣的相似,因為在特征矩陣確定后權重矩陣決定用戶的用電量。因此,在提到用戶的用電量相似和權重矩陣相似時表達的意思相同。
對于整個模型可以添加正則項式(14)來約束權重矩陣,從而提高模型的性能。

式中:W(:,i)和W(:,j)分別為矩陣W 的第i列和第j列,表示用戶i和用戶j對于某類特定設備的權重向量。對于2個不同的用戶,某個電器的用電量越相似,在潛在空間中wi和wj的距離也會越近,同時調節它們之間的相似度的同質性系數的值也會越大。
對某一用戶wi,其在潛在空間中的同質性正則項可以表示為
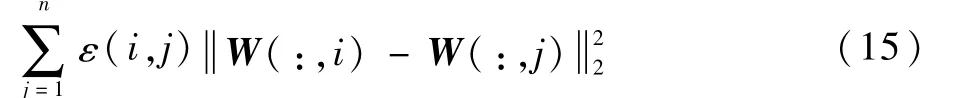
式中:同質性系數ε(i,j)控制著用戶wi和其他用戶之間的關系。對式(15)進行推導,可以得到正則項Tr(WLWT),推導過程如下:

同質性系數ε(i,j)表示相似度,常用的計算相似度的方法有歐氏距離、曼哈度距離、閔可夫斯基距離、余弦距離等。本文使用余弦距離相似度公式來表示用戶i和用戶j之間的同質性系數,對于第k類用電器,用戶i和用戶j之間相似性ε(i,j)定義如下:
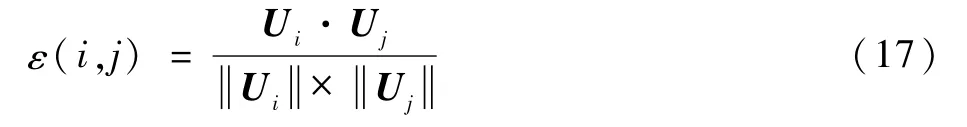
式中:Ui為用戶i對第k類用電器的用電量向量。
2.1.4 基于用戶用電模式相似性建模
由于同質性不能完全代表一個相似家庭的用電數據,本文只考慮把這一性質作為約束項加入基于非負矩陣分解的能源分解模型來改進基礎模型,提高模型的性能。從數據出發,本文只考慮加入總用電量同質性和面積同質性。總用電量相似的家庭在單類用電器上存在著相似性,面積相似的家庭在空調的用電量上更相似。首先,計算總用電量同質性系數矩陣,對每類電器單獨計算一個用戶同質性系數矩陣。對于智能電網用戶間的同質性系數通過用戶的用電數據計算,訓練數據和預測數據采用不同的計算方法。對于訓練數據集,因為用戶的單類用電數據是已知的,很容易通過余弦相似度公式得到同質性系數矩陣。而對于測試數據集,單類電器的用電量是未知的,此時采用近似計算方法來計算待預測家庭中每類電器的同質性系數,在訓練數據集中找到總用電量最接近的3個用戶,取這3個用戶對應電器同質性系數的均值來計算。然后,計算面積同質性系數矩陣。對于面積同質性系數,采用相同的計算方法。最后,針對不同類型的電器,本文通過一個系數矩陣來控制同質性正則項的強弱。最終生成基于同質性約束的非負矩陣分解能源分解模型如下:

2.1.5 能源分解方法建模
在本節中,將提出本文最終的能源分解方法,再進一步優化,并給出求解過程。
1)基于L1/2范數稀疏約束和同質性約束的能源分解方法,建立的能源分解訓練模型如下:


對于訓練數據集,使用目標函數式(19)求解得到每類電器最優的特征矩陣Bi。對于測試集,用式(20)為每類電器找到最優的權重矩陣Ai,最終用式(21)預測每類電器的用電量。
2)模型優化與求解。如果訓練過程和分解的過程能夠同步進行,那么在求解過程中這2個結果會相互影響,對預測結果會有正向促進作用。因此,本文繼續改進模型得到最終能源分解模型如下:

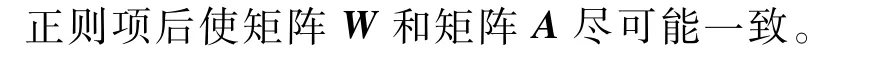
在上述內容中,已經得到了本文提出的最終的能源分解模型,如式(22)所示,但是該公式無法直接給出W、B、A的解,本文將采用乘性迭代法交替更新W、B、A來找到其最優解,具體過程本文不再贅述,迭代規則如下:

2.2 基于能源分解的用戶用電行為聚類分析方法
2.2.1 基于改進K-Means聚類算法的用戶聚類模型
選擇K-Means聚類算法來輔助驗證本文提出的觀點。首先,介紹傳統的基于用電行為的KMeans聚類算法。
假設數據集I={x1,x2,…,xn}∈RT,xn是T維的向量,表示用戶n在T段時間內的總用電量,具體算法描述如下:
步驟1 隨機初始化k個聚類中心u1,u2,…,uk∈RT。
步驟2 針對每個樣本點,計算其與每一個類中心的距離,離哪個類中心近就劃分到哪個類中,這樣完成一次聚類。
步驟3 用類均值更新聚類中心。
步驟4 判斷新計算出的類中心和原來的類中心之間的距離是否小于設定的閾值(表示重新計算的類中心位置變化不大,趨于穩定),如果小于閾值,算法終止,否則返回步驟2。K-Means聚類算法中通常選擇歐氏距離來計算點到類中心的距離,對于樣本點到類中心的距離計算如下:

式中:xit為用戶i在t時刻的用電量;ujt為聚類中心j在t時刻的數據。
為了避免總用電特征對用戶聚類結果不夠準確及不能反映用戶的詳細用電行為的問題。本文提出用能源分解后的單類用電器的用電特征來代替總用電特征,計算用戶間的距離提升聚類效果,改進傳統的K-Means聚類算法。
具體地,對于一個用戶i,傳統的方法是用一個向量來表示,該向量中的值是用戶的總用電特征,現在我們用一個矩陣來表示用戶i,矩陣中每一列是一個單獨用電器的用電向量,K列就有K個用電器。在計算距離之前用Z-Score消除不同類電器量級不同帶來的影響,改進后的算法的距離計算為
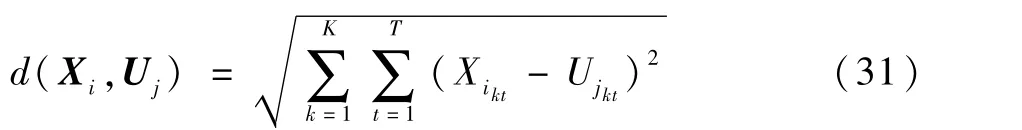
式中:Xi為用戶i的特征矩陣;Uj為聚類中心j的特征矩陣;Xikt為用戶i用電器k在t時刻的用電量;Ujkt為聚類中心j對于用電器K在t時刻的類中心數據。
2.2.2 初始聚類中心和K值的選擇
K-Means聚類算法的第一步也是最重要的一步,即選擇聚類數目K值和選擇初始聚類中心。K值決定聚類結果的數目,K值不同聚類結果也不同,聚類結果對K值的依賴性在一定程度上影響著聚類分析。而聚類中心的選擇影響聚類結果的穩定性,并且容易使算法陷入局部最優解。基本的初始聚類中心的選擇是隨機的,會使目標結果偏離最優結果,從而陷入局部最優解。因此,合適的K值和初始聚類中心對于智能電網用戶的聚類結果至關重要。
本文采用最大距離法選擇初始類中心。選取的初始類中心對象之間的距離應該盡可能離得遠。首先,隨機選取一個樣本作為第一個類中心,然后,選擇與第一個類中心最遠的樣本作為第二個類中心,接著用同樣的方法選擇其他的類中心。
本文選擇聚類有效性指標來計算合適的聚類數目。常用的評測指標有手肘法、輪廓系數(silhouette coefficient,SC)、戴維斯-布爾丁指數(Davies-Bouldin index,DBI)、卡林斯基-哈拉巴斯指數(Calinski-Harabaz index,CHI,也被稱為方差比標準)及權變矩陣。本文選擇手肘法、DBI這2種內部有效性指標來選擇最優的K值。這2種指標的計算方式如下:
1)手肘法。手肘法的核心指標是誤差平方和(sum of the squared errors,SSE)計算如下:
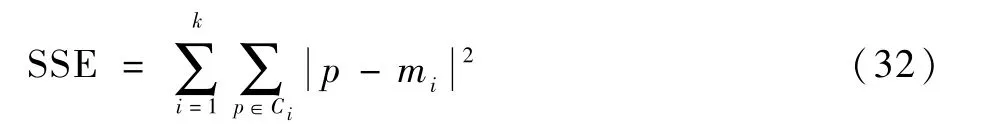
式中:Ci為第i個簇;mi為Ci的簇質心;p為Ci中的樣本點;SSE為所有樣本的聚類誤差,代表著聚類效果的好壞。
手肘法的核心思想是:隨著聚類數目K值的增多,每個簇的聚合程度也會逐漸增加,而SSE則會逐漸減小;并且當K值在小于最優聚類數目范圍內增加時,SSE的下降幅度會比較大,當K值增加到最優聚類數目時,SSE的下降幅度則會驟減,然后隨著K值的繼續增大SSE會慢慢趨于平緩。SSE和K值的變化關系類似于手肘的形狀,并且在肘部取得最優的K值,因此稱為手肘法。
2)DBI。DBI有效性指標定義如下:

3 實驗結果與分析
3.1 基于L 1/2范數和同質性約束的能源分解方法實驗
3.1.1 不同方法對比實驗結果分析
對基本的非負矩陣分解的能源分解方法(NMF)、L1范數約束的稀疏編碼方法(NMF+L1)、基于L1/2正則項約束的能源分解方法(NMF+L1/2)、本文方法4種方法做實驗。使用同一數據集,在參數最優的情況下經過多次重復實驗,性能取均值的結果如表1和圖2所示。
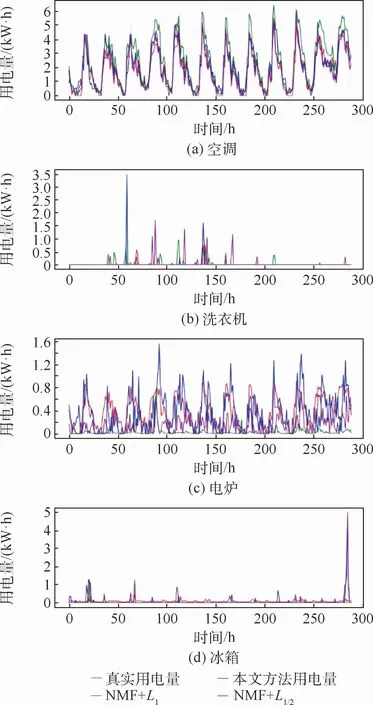
圖2 真實結果和分解結果對比Fig.2 Comparison of real results and decomposition results
從表1中可以看出,在基本的非負矩陣分解模型上加入約束項之后,算法的性能都有很大的提升,并且模型的訓練時間沒有太大的波動。加入L1范數稀疏約束的模型相比于L1/2范數的稀疏約束的模型在訓練集上效果要好,但是在測試集上沒有L1/2范數的稀疏約束效果好,總體上L1/2范數的稀疏約束效果更好。本文所提出的方法,在NMF的基礎上加入L1/2范數稀疏約束項、同質性約束項和一致性約束項,模型的性能在訓練集和測試集上都取得了相對較好的結果。
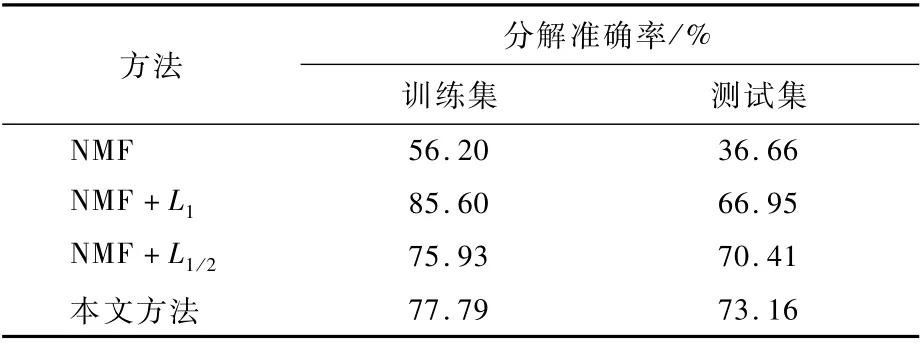
表1 實驗結果Table 1 Experimental results
如圖2所示,對于能源分解后空調的用電量3種對比方法都能很好的擬合,但是洗衣機、電爐、冰箱這3類電器本文提出的方法擬合效果更好。
3.1.2 同質性對實驗結果的影響
1)總用電量同質性
總用電量同質性對實驗結果的影響如圖3所示,其中x軸為小功率電器參數El,y軸為大功率電器參數Eh,z軸表示分解準確率(Acc)。分解準確率隨著參數Eh和El的變化呈現明顯的規律性。參數Eh變化時對分解準確率影響較大,當參數的取值大于0.01分解性能急劇下降,當參數小于0.01時分解準確率相對穩定且較高,在0.001附近取得最優值。而分解準確率在參數El的影響下并沒有呈現這種規律,參數El對分解準確率影響相對較小,隨著El的增大模型的性能先增大后減小,在0.1附近取得最優值。

圖3 不同參數對比Fig.3 Contrast diagram of different parameters
2)面積同質性
面積同質性對實驗結果的影響如表2所示。可以看出,空調的同質性參數Ef取不同值時,模型的分解性能呈規律性變化,參數小于0.1時模型的性能相對較好,在0.001附近取得最優。

表2 參數E f對比結果Table 2 Par ameter E f contrast results
為了清晰地顯示面積對空調分解性能的影響,隨機選取一個用戶分別畫出空調2周內和1天內真實電量和預測電量之間的變化趨勢,如圖4所示,2條線變化趨勢相同并且基本重合,預測值接近真實值。

圖4 2周內和1天內真實電量和預測電量分布Fig.4 Predicted distribution of real power consumption in two week and predicted distribution of real power consumption in one day
3.2 基于能源分解的用戶用電行為聚類分析方法實驗
3.2.1 最優聚類數目K的選擇實驗
1)傳統的K-Means聚類算法K值確定
基于傳統的K-Means聚類算法使用的是用戶總用電特征進行聚類分析,即進行能源分解之前智能電表直接采集到的總用電特征數據集進行實驗,采用歐氏距離計算用戶之間的距離。聚類數目K取[2,10],DBI和SSE這2種有效性指標在不同聚類數目K下的結果分別如圖5和圖6所示,圖中橫軸表示聚類數目K,縱軸表示有效性指標。
從圖5中可以,看出當K=4時到達SSE的變化曲線的肘部,因此在SSE有效性指標下最佳聚類數目為4。從圖6中可以看出,DBI最小值為3,這表示在DBI指標下最佳聚類數目為3。但是,值得注意的是當K取4時DBI的值還非常大,而K=3或K=4時SSE差別并不大,因此本文選擇K=3為傳統的K-Means聚類算法的最佳聚類數目。

圖5 傳統的K-Means聚類算法有效性指標SSE評測結果Fig.5 Traditional K-Means clustering algorithn evaluation results of effectiveness index of traditional clustering SSE
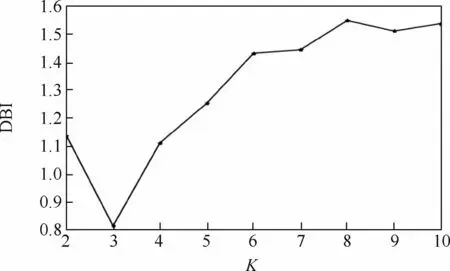
圖6 傳統的K-Means聚類算法有效性指標DBI評測結果Fig.6 Traditional K-Means clustering alorithm evaluation results of effectiveness index of traditional clustering DBI
2)改進的K-Means聚類算法K值確定
本文提出的聚類算法使用的是用戶單類用電器的用電特征進行聚類分析的,即能源分解之后得到的數據,同樣采用歐氏距離計算用戶之間的距離,使用SSE和DBI這2種有效性指標選擇最優的聚類數目K。隨著K值的變化,SSE和DBI的變化曲線如圖7和圖8所示,圖中橫軸表示聚類數目K,縱軸表示有效性指標。
從圖7中可以看出,當K=4時SSE曲線到達肘部,在SSE有效性指標下最佳聚類數目K為4。
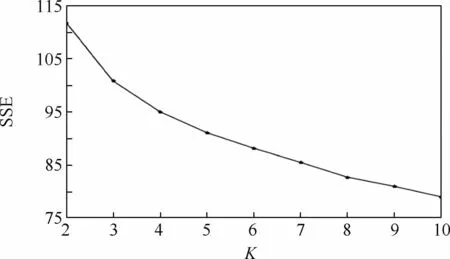
圖7 改進的K-Means聚類算法有效性指標SSE評測結果Fig.7 Improved K-Means clustering algorithm evaluation result of effectiveness index of improved clustering SSE
從圖8中可以看出,DBI在K=2時取得最小值,即最佳聚類數目K為2,但是在K=2時SSE還非常大,這不具有合理性。因此,本文退而求其次選擇第二小DBI值處的聚類數目K,即K=4。綜合分析,改進的K-Means聚類算法最佳聚類數目K應為4。
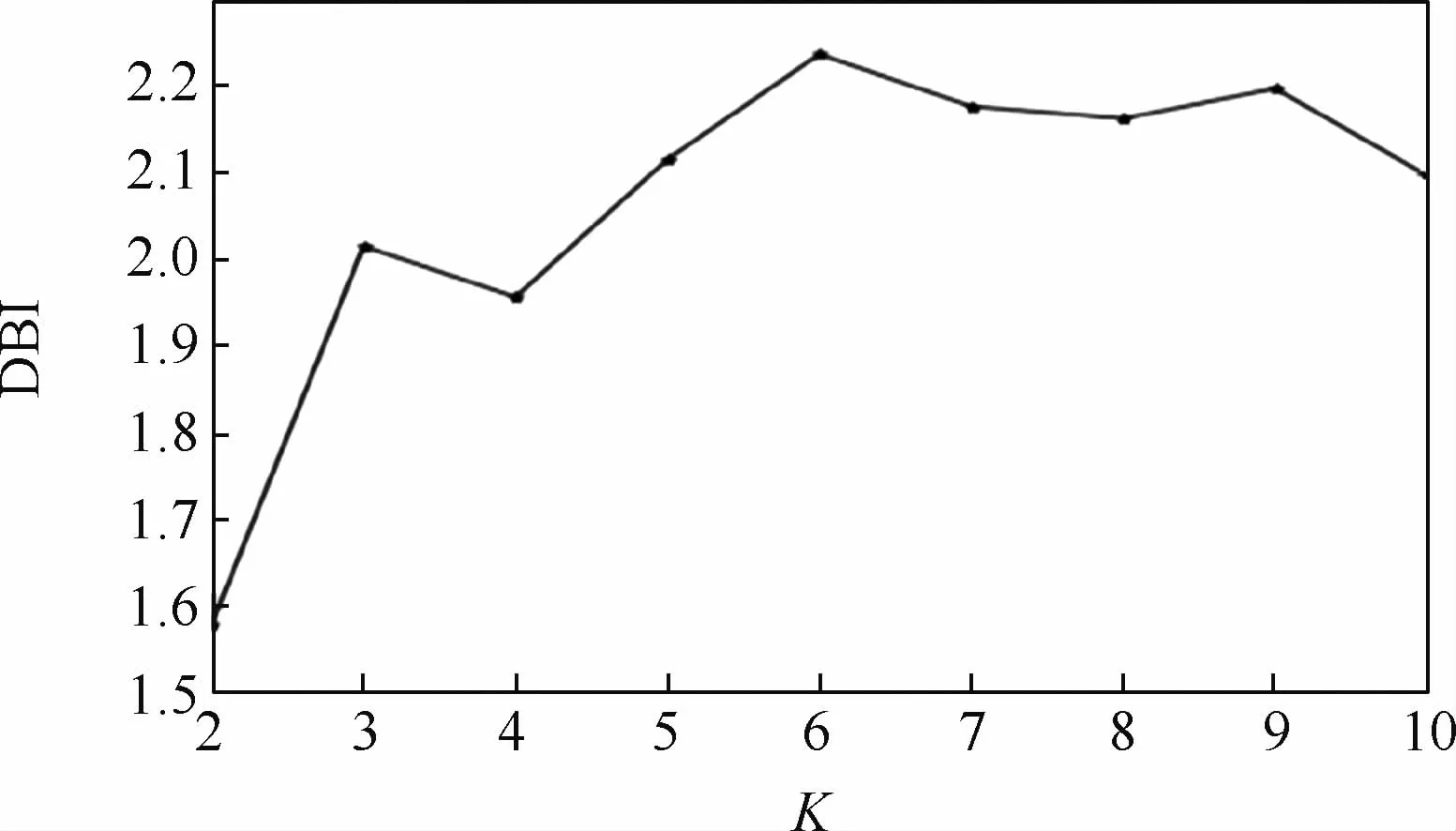
圖8 改進的K-Means聚類算法有效性指標DBI評測結果Fig.8 Improved K-Means clustering algorithm evaluation result of effectiveness index of improved clustering DBI
3.2.2 不同方法對比實驗
1)傳統K-Means聚類算法實驗分析
當K=3時,傳統的K-Means聚類算法的聚類結果如圖9所示,紅綠藍3條線分別代表3個類的類中心。圖中:cluster0_139表示類0,clusterl_91表示類1,cluster2_34表示類2。從圖中可以看出,藍線代表的類中心變化幅度比較小,幾乎趨于平穩,紅線和綠線變化趨勢相同,都是在5:00之后用電量慢慢上升,19:00用電量開始下降,但是變化幅度不同,綠線代表的用戶變化幅度比較大,用電量比較多。對總用電數據聚類能反映用戶的總體用電趨勢,而每個分電器的用電特點無從得知,用電峰值也不突出,這在一定程度上會影響聚類結果的準確性。
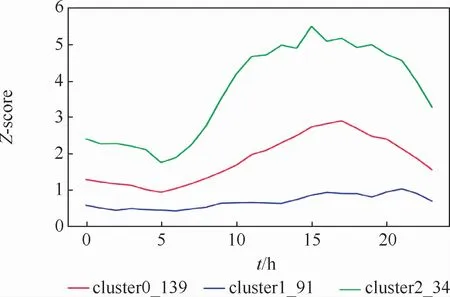
圖9 總用電量用戶聚類結果Fig.9 Clustering results for users with total electricity consumption
2)改進的K-Means聚類算法實驗分析
當K=4時,對用戶的單獨電器進行聚類算法的聚類結果如圖10所示,圖中每一行表示一類用戶,從上到下依次為第1類、第2類、第3類、第4類用戶。圖10(a)~(d)分別代表4種用電器(空調、洗衣機、電爐、冰箱)的日用電特點。從圖中可以看出,空調和電爐的用電趨勢比較相似;洗衣機的日用電量,每個家庭使用時段不同,呈現出不同的特點;冰箱的日用電量,也可以通過電量分析,大致了解到每類用戶冰箱的使用情況。實驗中的4類用戶中,后面3類用電都很平穩,第1類變化波動比較大并且相對用電量比較高,可能第1類用戶更注重家庭飲食品質,冰箱存放食物更多。第1類和第4類用戶洗衣機日用電量波動比較大,在上午和下午出現2次波峰,第2、3類用戶無明顯波動,這一天可能沒有使用洗衣機。從圖中也可以看出,第3類用戶的4種用電器電量基本上沒有浮動,都處于關閉狀態,可以認為這類用戶在這一天沒有使用電器。
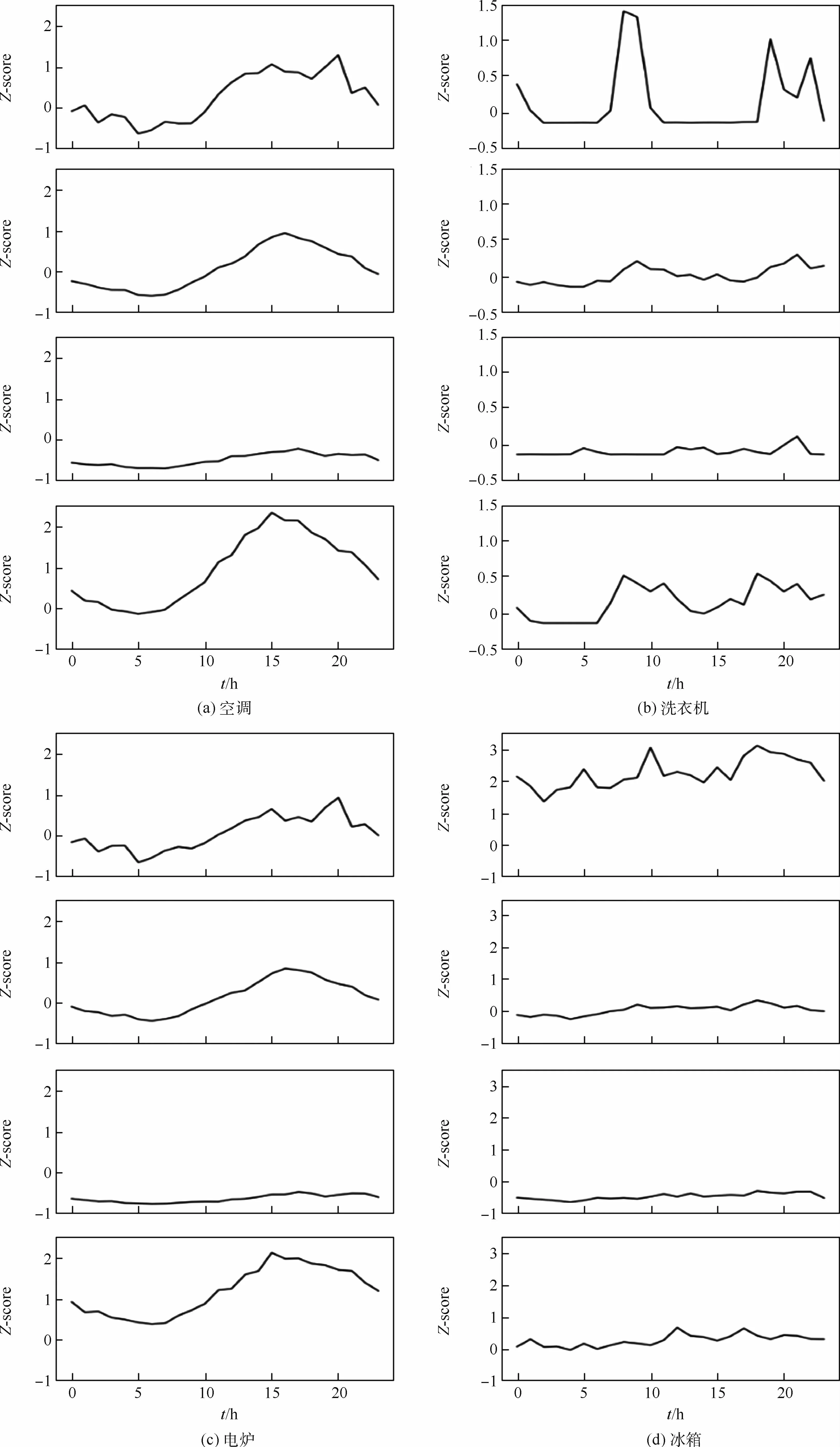
圖10 單類用電器用戶聚類結果Fig.10 Clustering result for users with single-type electrical appliances
3)對比分析
從2種對比方法的實驗結果中可以看到,本文提出的聚類方法更能準確分析用戶的行為,識別每類用戶中單獨電器的用電特點。針對每類用戶的單類用電器的用電特點做出更有數據支撐、更合理的電網規劃、需求響應和信息推薦等決策。由于數據集的局限本文只分析了4類電器,如果能夠獲得更多單類電器的用電數據,聚類結果將會有更大的應用價值。
4 結 論
隨著智能電網和大數據技術的快速發展,大量用戶的用電數據被記錄和存儲,如何合理、有效地利用這些數據挖掘出數據中潛在的價值越來越受到關注。能源分解和用戶用電行為分析作為智能電網應用之一,能夠用于節約能源、故障檢測、電網規劃、需求響應和信息推薦等。因此,對用戶的電能分解并對其用電行為進行聚類分析具有重要價值,而如何提高能源分解的準確率和用戶用電行為聚類效果變得極為重要。基于此,本文提出了一種基于能源分解的用戶用電行為模式分析方法。采用非負矩陣分解的能源分解方法(NMF)結合L1/2范數的稀疏約束、同質性約束項及一致性約束項方法訓練數據,得到的模型在訓練集和測試集上都具有很好的效果,克服了傳統采用NMF+L1方法得到的模型在測試集上效果不好的問題及克服了采用NMF+L1/2方法精度不高的問題。本文在傳統方法NMF+L1/2上加入同質性約束項及一致性約束項訓練的模型,一定程度上提高了模型在訓練集和測試集上的性能。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
