基于情感對象識別和情感規則的微博傾向性分析
2022-03-08 11:57:28王澤辰王樹鵬孫立遠張磊王勇郝冰川
北京航空航天大學學報 2022年2期
王澤辰,王樹鵬,*,孫立遠,張磊,王勇,郝冰川
(1.中國科學院信息工程研究所,北京 100193; 2.國家計算機網絡應急技術處理協調中心,北京 100085)
微博作為中文社交平臺,具有強大的影響力和滲透力。微博用戶不斷增加,2020年第1季度財報顯示,微博日活躍用戶達2.41億,月活躍用戶達5.5億。這些用戶在平臺上建立關系、獲取信息及生產大量內容。在微博文本信息中,大量博文包含帶有明顯情感色彩的內容。挖掘這些文本背后用戶的觀點與傾向,可以判斷流行趨勢和熱點,有助于企業分析消費者購買傾向,進行精準化營銷,也使得政府可以對網民的輿論立場變化做出及時反應。因此,對微博文本進行傾向性分析,進而完成對博文立場的判定,是情感分析中一項重要的研究任務。
情感分析以對特定文本進行處理及挖掘其中情感色彩為目的,是自然語言處理的重要分支,近年來受到了廣泛關注。提取情感詞是分析微博所表達情感最直接的方法。微博文本具有長度較短、內容形式多樣、觀點傾向性強、表達方式口語化、普遍缺少上下文信息等特點。針對微博數據有許多情感分析的研究,結合情感詞典對微博進行分析的方法較為直觀。通過對微博中包含的情感詞進行分類,可以簡單地概括其中蘊含的情緒。但是1條微博所表達的信息不僅與其包含的情感詞相關,即使2條微博包含完全相同的情感詞,當情感詞所指向的對象不同時,微博的觀點與傾向性會存在明顯差異。例如,電子產品制造商可能只希望關注用戶與手機、電腦等相關的微博情感信息,而不關心對食品、日用品等的購買傾向;在輿情方面,要分析網民在討論社會熱點問題時的立場,不僅需要辨別微博表達的態度是積極還是消極,還需要確定微博支持或反對的實體是什么。另外,中文詞匯的多義性使得同一詞語在不同語境下指代的實體含義可能不同。隨著網絡語言的發展,用于實體表示的新詞也層出不窮,用戶常常用品牌縮寫、諧音、流行語等進行指代,這些依賴人工標注的實體往往需要很大的工作量。因此,如何針對海量微博數據進行傾向性分析,從而實現立場判定,是目前亟須解決的問題。
為解決微博傾向性分析的問題,本文將深度學習的方法與情感規則相結合,基于句法規則進行博文情感分析,指定相應的情感規則,結合協同學習和主動學習的方法,可以在僅依賴少量標注數據的前提下準確判斷博文對指定類型實體表達的情感。
本文主要有以下3點創新:
1)利用半監督學習的方式,通過協同訓練加主動學習的方式,同時利用半監督學習結合主動學習的模式,確定指向性實體集。
2)不同于傳統的情感規則,本文提出了基于主成分分析的情感規則,通過識別指定方向實體,結合情感詞對博文進行傾向性判斷。
3)生成指定類別實體集,結合情感規則,判斷博文的立場,實現對博文更深層次的分析。
1 相關工作
網絡輿情中的情感識別問題得到了學界廣泛關注。網絡社交平臺數據是情感識別任務的重要數據來源。例如,基于Twitter平臺數據,Giachanou等[1]建立了情感分析方法,訓練、分析推文內容的情感傾向性。類似地,微博作為受眾廣、數據規模大的中文平臺,吸引了許多學者對其數據開展研究。
微博情感分析方法主要有3種:
1)基于語義詞典的方法。該方法需要先構建微博情感分析數據庫,一般包含多個詞典和句法規則庫,再利用知識庫進行聚合計算。例如,王志濤等[2]提出了一種基于詞典和規則集的中文微博情感分詞方法,將詞典和語義規則結合進行情感分析。王燦偉[3]提出了結合情感詞典和感情符號來計算微博情感值的方法,實現主題歸類和情感分類。語義詞典通過構造情感詞典,篩選出微博文本中的情感詞,計算文本片段的情感權值,從而判斷微博的情感傾向。Ebrahimi等[4]提出了將情感極性融入到情感對象和情感立場中的方法,通過對數線性聯合建模實現立場判定。
2)傳統機器學習方法。該方法普遍應用于情感分類,其核心思想是構建特征向量,找到特征與分類結果之間的關聯。樸素貝葉斯(naive Bayes)、最大熵(maximum entropy,ME)、支持向量機(support vector machine,SVM)等方法常用于情感分類[5]。Pang等[6]使用了電影評論作為數據,采用以上3種機器學習方法進行情感分類。奠雨潔等[7]使用SVM、隨機森林和梯度提升決策樹對文本特征進行立場檢測,并利用特征分類器進行立場融合。這些方法具有訓練時間短及特征維度高的特點,但不能充分利用上下文信息和語法信息,且需要大量手工標注。
3)基于深度學習的方法。該方法對微博博文進行分詞,將其表示為詞向量,通過深度神經網絡提取語義信息,構建情感表征向量,并利用微博情感表征完成情感分類任務。深度學習模型在情感分析上取得了很好的效果[8],特別是基于長短期記憶網絡(long and short term memory,LSTM)方法,在長語句分析上取得了很好的結果[9]。除此之外,還有基于雙重注意力模型[10]、監督學習[11]、集成學習[12]的方法。
通過對上述已有工作進行總結和分析,可以將基于語義詞典、傳統機器學習和深度學習的微博情感分析方法的特點進行對比,結果如表1所示。由表1可知,深度學習方法能夠充分利用文本信息,往往具有更好的效果。基于深度學習的情感分析又可細分為無監督學習、有監督學習和半監督學習3種方法。

表1 微博情感分析方法的特點Table 1 Features of Weibo sentiment analysis methods
在無監督學習方法中,所有數據都缺少情感標注。Turney[13]提出了情感傾向性分類的方法,通過選取指定詞匯,分別計算每個詞與情感詞典中積極、消極情感詞的交叉熵,以ME值作為情感詞分類判斷標準。除此之外,還有基于語法分析[14]、句法模式[15]等方法的研究。上述方法可以發掘文本數據中內在的詞匯情感規律,節約人工標注的成本。
有監督學習情感分類問題主要關注特征選擇和分類器設計。例如,文獻[16]中采用了詞性特征,Cambria等[17]引入了符號特征和詞嵌入特征。基于商品評論中產品特征信息的情感分類采用有監督學習方法[18],具有較高的運行效率。但是,如果在有監督學習中出現分類錯誤,那么之后的學習都會受到這個錯誤的影響。為了解決這個問題,有學者提出了半監督學習方法避免準確率的下降。
Sindhwani[19]和Liu[20]等 分 別 提 出 了 采 用 半監督學習方法進行情感分析。半監督學習包括自訓練、協同訓練等方法。自訓練[21]方法是較早提出的一種半監督學習方法,先訓練初始分類器,再使用該分類器對未標注的數據進行標注,選取分類準確度較高的樣本確認標注,直到經過多輪迭代后所有樣本都完成標注為止。半監督學習方法僅需要標記少量數據,適用于數據量大的任務。
對基于深度學習的方法進行總結和分析,將基于無監督學習、有監督學習和半監督學習的深度學習情感分析方法的特點進行歸納,結果如表2所示。
由表2可知,采用半監督學習方法,在情感分析任務上可以取得較好的效果。基于情感分析研究現狀,本文提出了基于情感對象識別與情感規則的傾向性分析(orientation analysis based on sentiment object recognition and sentiment rules,OASOSR)算法,不僅能夠確定博文中的情感詞,還可以分析情感詞指向的實體是否為目標實體。

表2 基于深度學習的情感分析方法特點對比Table 2 Comparison of features of sentiment analysis methods based on deep learning
2 OASOSR算法
OASOSR算法框架如圖1所示,主要分為2個部分:①基于協同訓練和主動學習的實體識別模型;②基于情感詞典和句法分析的微博傾向性分析。

圖1 OASOSR算法總體架構Fig.1 Algorithm architecture of OASOSR
基于協同訓練和主動學習的實體識別模型部分采用半監督學習方法,將少量已標注的微博文本數據集作為初始輸入,協同訓練2個不同的實體識別模型。為了在協同訓練中比較模型訓練效果,基于這2個實體識別模型構建2個分類器,分別包括實體集、情感詞典和情感規則3個部分。在協同訓練的過程中,首先,從未進行實體標注和立場判定的數據集中抽取一定數量的數據,并利用這2個訓練過的實體識別模型對未標注語料進行實體識別。同時,2個實體識別模型通過判斷微博文本中的實體類型,提取指定方向的實體,各形成1個實體集。然后,在這2個實體集的基礎上,構造2個分類器,利用分類器分別結合情感詞典和情感規則來判斷微博立場,并對同一條博文進行傾向性分析。比較2個分類器得到的傾向性分析結果,判斷樣本置信度,從中選擇高置信度(即2個分類器輸出結果完全相同)的樣本,并為此類樣本添加指定類別的實體標記和傾向性標簽,合并到已標記博文數據中。同時,對于低置信度的樣本,采用主動學習模式,將分類器挑選出的分歧大(2個分類器標注結果不同)的樣本添加到已標注的數據集中。將更新擴充后的有標注數據集重新輸入到協同訓練模型,再次訓練上述2個實體識別深度學習模型,不斷迭代直到已標記的博文數據集達到足夠的規模,進而獲取最大的指定方向實體集。2.1節將詳細介紹微博實體識別模型及指定方向實體集的訓練過程。
在基于情感詞典和句法分析的微博傾向性分析部分,首先,模型基于學習得到指定方向實體集。然后,針對需要立場判斷的微博數據,判斷微博是否與指定方向的實體相關。如果微博文本中包含指定方向實體集內的任意實體,則對此類微博根據預先編寫的情感規則和情感詞典進行傾向性分析,實現對微博文本的立場判定。2.2節將重點討論OASOSR算法中基于情感詞典和情感規則的傾向性分析。
2.1 基于協同訓練和主動學習的實體識別模型
本節詳細介紹基于協同訓練和主動學習模型的構造細節、訓練過程及微博情感對象實體集的提取流程。
協同訓練假設數據擁有2個充分且條件獨立的視圖,即每個視圖所包含的信息都可以支持生成最優學習器,且在給定類別標記的條件下2個視圖相互獨立。利用未標記數據在每個視圖上都訓練生成1個分類器,每個分類器選擇置信度最高的樣本生成偽標記,再將這些偽標記作為標記樣本訓練另1個分類器。本文對層疊隱馬爾可夫模型(cascaded hidden Markov model,CHMM)和條件隨機場(conditional random field,CRF)實體識別學習模型進行協同訓練。
隱馬爾可夫模型(hidden Markov model,HMM)是一種在自然語言處理領域中被廣泛應用的統計模型。中文命名實體識別中的人名識別、地名識別、譯名識別及機構名識別等都可以用HMM來解決。本文利用CHMM 在統一的HMM中識別各類實體命名,自底向上分為人名識別HMM、地名識別HMM 和機構名識別HMM 3層。每一層HMM將產生的最好的若干個結果送到詞圖中供高層模型使用,最終實現人名、地名和機構名的實體識別。
CRF模型是一種基于統計的判別式模型,結合了ME模型和HMM 模型的特點。CRF模型根據樣本的特征生成預測,對所有的特征權重進行最優化,進而得到最優解,解決了HMM模型因獨立性假設而導致其不能考慮上下文特征的問題。在本文模型中,從經過分詞的數據中挑選出包含在特定微博主題標簽內的數據實體,形成候選詞集。再利用CRF模型對候選詞集中的候選實體進行實體抽取。
本文采用協同訓練和主動學習的方法訓練以上2個模型。主動學習方法具有在訓練集較少的情況下能夠獲得較高分類準確率的優勢,是對有監督學習方法的一種改進。有監督學習方法在學習過程中被動接受人工標注的樣本集,通過將標注樣本映射到目標函數空間來學習知識。而主動學習方法則試圖從未標注的池中選擇數量盡可能少的、機器無法正確標注的樣本(低置信度的樣本),并由領域專家進行標注后添加到下一次迭代過程中作為訓練集,以提高分類的效率。主動學習通過選擇質量高的少數樣本進行學習以保證分類器的分類性能,同時,也可以減輕樣本的標注復雜度。
情感對象實體集提取流程如圖2所示,采用了半監督學習方法,通過協同訓練和主動學習的方式對2個實體識別學習模型進行訓練。在實體及情感類別已標注數據集中,有少量已標注微博文本分別標注了博文中包含的實體(實體1、實體2等)和博文情感類別(正向、負向)。將有標注的微博文本進行切詞處理,分別輸入到CHMM 和CRF實體識別學習模型,初步訓練這2個模型。
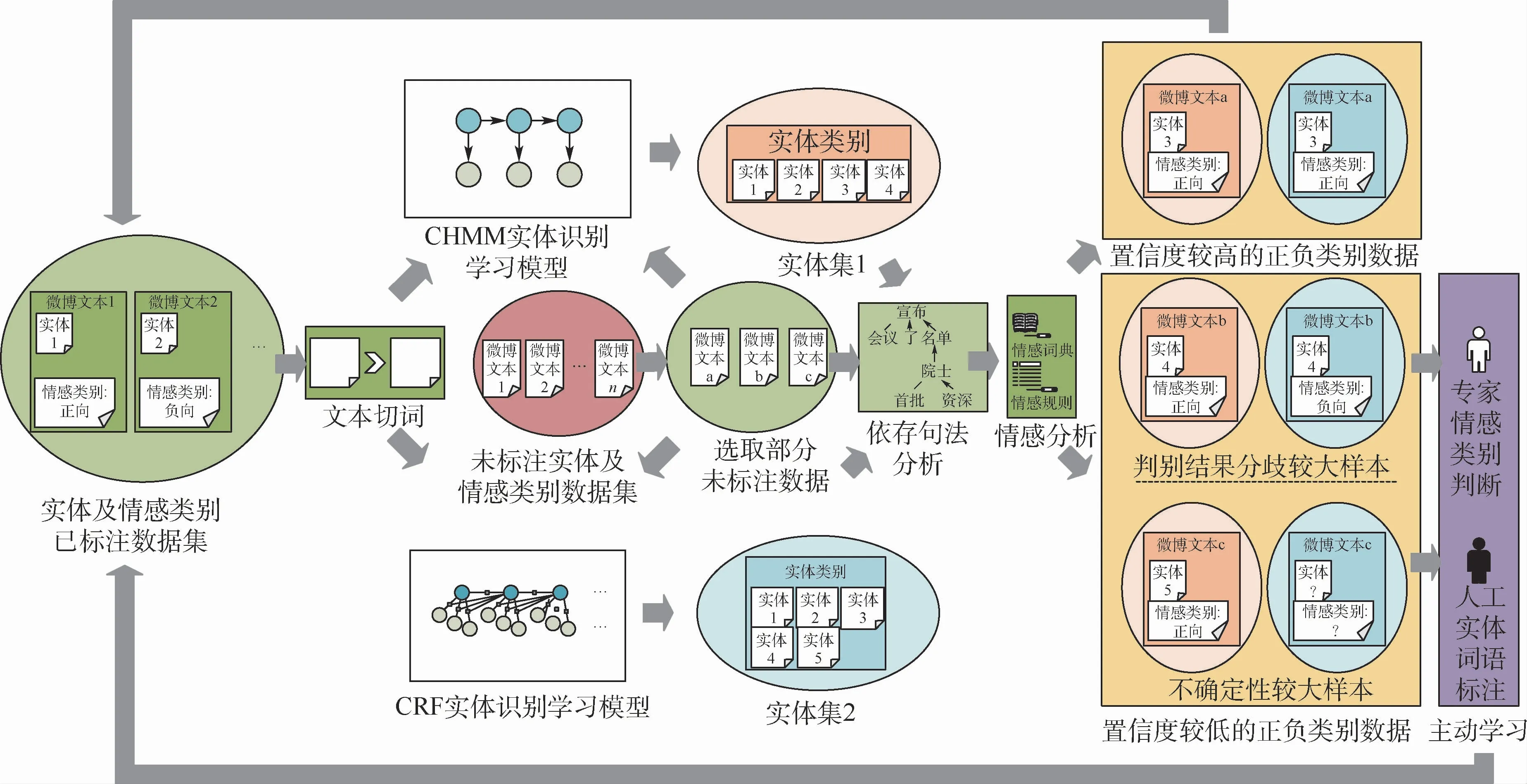
圖2 情感對象實體集提取流程Fig.2 Extraction flowchart of sentimental object entity sets
在對CHMM和CRF實體識別學習模型進行協同訓練的過程中,先從未標注實體及情感類別數據集中選取部分數據(微博文本a、b、c),輸入到經過初步訓練的CHMM 和CRF實體識別學習模型,提取博文中指定方向的實體,分別得到實體集1和實體集2。分別基于2個實體集對相同的未標注數據進行依存句法分析,再基于給定的情感詞典和情感規則進行情感分析,判斷微博文本的情感類別。對于每條微博,都有基于實體集1和實體集2的2個標記結果,每個標記結果都包括微博所含有的實體(實體n)和傾向(正向、負向、無法判斷)。比較基于實體集1和實體集2得到的標記結果,針對同一微博文本,若2個分類器得到的結果中所標記實體和情感類別都完全相同,則判斷該結果為置信度較高的正負類別數據。直接將這條微博文本和對應實體、情感類型標注添加到實體及情感類別已標注數據集;若2個結果中所標記實體或情感類別不完全相同,則判斷該結果為置信度較低的正負類別數據,需要采用主動學習的方法處理。對于這類數據,針對同一微博文本,若2個分類器提取的指定方向實體完全相同,但情感類別相反,則認為該樣本是分歧較大樣本,需要將結果交由領域專家進行情感類別判斷。若2個分類器提取的指定方向實體不同,或有1個分類器沒有提取出指定方向實體,則認為該樣本是不確定性較大樣本,需要進行人工實體詞語標注。同樣地,將經由主動學習得到的微博文本和對應實體、情感類型標注添加到實體及情感類別已標注數據集,這樣就完成了協同學習的第一輪循環。
對這一過程進行迭代,不斷擴充實體及情感類別已標注數據集,直到已標記數據的數據量達到設定的停止閾值。獲取該數據集中的所有標注實體所組成的實體集,作為2.2節中微博傾向性分析的基礎。
2.2 基于情感詞典和情感規則的微博傾向性分析
本節介紹基于情感詞典和情感規則進行句法分析的微博立場判斷算法。該算法通過情感規則識別微博中情感詞所充當的句子成分,分析情感詞與目標實體之間的修飾關系,從而判斷微博的傾向性。然而,情感規則的制定依賴于依存句法分析。漢語語句以詞語為基本單位,在詞語之間擁有依存和支配關系。依存句法分析理論能夠借用各級語言單位的依存關系,清晰地提煉出成分之間的修飾和搭配信息,從而達到解析語句的目的,進而總結句子成分之間的關聯,制定情感規則。
基于情感詞典和情感規則的微博傾向性分析算法包含文檔預處理、條件判斷、實體信息判斷、句法分析及規則判斷5個步驟,輸出結果為對應輸入博文的博文傾向性類別。算法流程如圖3所示。
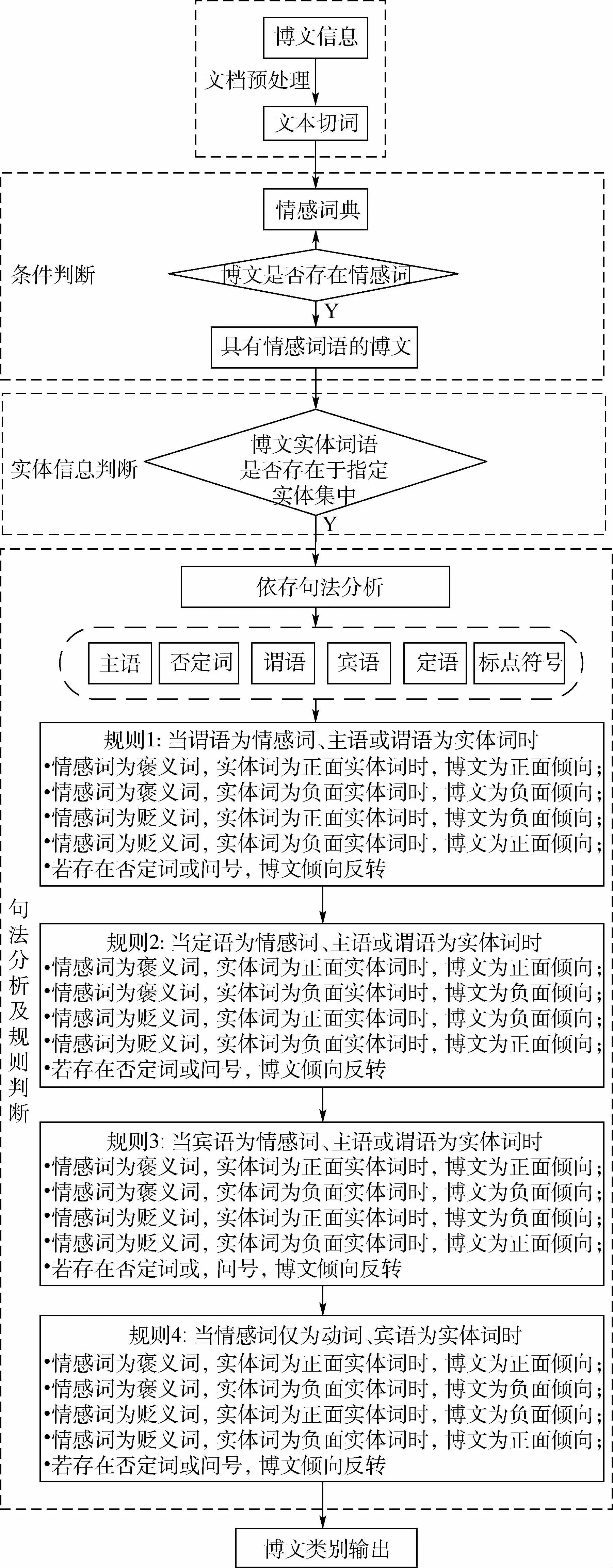
圖3 OASOSR算法流程Fig.3 OASOSR algorithm flowchart
首先,對原始博文進行數據清洗,經過簡化繁體字、刪除無效評論等操作后,得到有效數據,再使用結巴分詞(數據來源:https://github.com/fxsjy/jieba),并去除分詞結果中的停用詞。然后,基于情感詞典,對經過處理的微博文本數據進行情感詞判斷。顯然,只有包含情感詞的微博文本才能表達傾向性,不包含情感信息的微博不具有立場分析的價值。因此,本文采用大連理工大學情感詞匯本體庫DUTIR情感詞典(數據來源:http://ir.dlut.edu.cn)判斷博文中是否存在情感詞,篩選出含有情感詞的微博文本,進行下一步處理。在含有情感詞的微博文本基礎上,進行實體信息判斷,篩選出包含指定方向實體的微博。實體信息判斷基于2.1節中通過協同訓練和主動學習得到的實體集完成。最后,提取微博文本中實體詞語,若實體存在于該指定方向的實體集之中,則篩選出這條微博,對其中的句子進行依存句法分析。通過識別句子的主語、否定詞、謂語、賓語、定語、標點符號等成分,基于句法分析、情感規則將句子分為4種不同的類型:①當謂語為情感詞、主語或謂語為實體詞時;②當定語為情感詞、主語或謂語為實體詞時;③當賓語為情感詞、主語或謂語為實體詞時;④當情感詞僅為動詞、賓語為實體詞時。
情感詞在句子中充當不同成分時,具體分類規則如OASOSR算法所示(見圖3)。經過對應的情感規則判斷,最終輸出該微博文本的立場。
算法1 OASOSR算法。
輸入:微博文本。
輸出:博文類別。
步驟1 文檔預處理。文本切詞。
步驟2 條件判斷。依據情感詞典判斷博文是否存在情感詞,若存在情感詞,則對句子進行下一步處理。
步驟3 實體信息判斷。提取博文中實體詞語,若實體存在于指定實體集之中,則進行下一步處理。
步驟4 句法分析及規則判斷。
步驟4.1 對句子進行依存句法分析,識別句子的主語、否定詞、謂語、賓語、定語、標點符號等成分。
步驟4.2 設定情感判斷規則。
1)規則1:當謂語為情感詞、主語或謂語為實體詞時:
①情感詞為褒義詞,實體詞為正面實體詞時,博文為正面傾向。
②情感詞為褒義詞,實體詞為負面實體詞時,博文為負面傾向。
③情感詞為貶義詞,實體詞為正面實體詞時,博文為負面傾向。
④情感詞為貶義詞,實體詞為負面實體詞時,博文為正面傾向。
⑤若存在否定詞或問號,博文傾向反轉。
2)規則2:當定語為情感詞、主語或謂語為實體詞時:
①情感詞為褒義詞,實體詞為正面實體詞時,博文為正面傾向。
②情感詞為褒義詞,實體詞為負面實體詞時,博文為負面傾向。
③情感詞為貶義詞,實體詞為正面實體詞時,博文為負面傾向。
④情感詞為貶義詞,實體詞為負面實體詞時,博文為正面傾向。
⑤若存在否定詞或問號,博文傾向反轉。
3)規則3:當賓語為情感詞、主語或謂語為實體詞時:
①情感詞為褒義詞,實體詞為正面實體詞時,博文為正面傾向。
②情感詞為褒義詞,實體詞為負面實體詞時,博文為負面傾向。
③情感詞為貶義詞,實體詞為正面實體詞時,博文為負面傾向。
④情感詞為貶義詞,實體詞為負面實體詞時,博文為正面傾向。
⑤若存在否定詞或問號,博文傾向反轉。
4)規則4:當情感詞僅為動詞、賓語為實體詞時:
①情感詞為褒義詞,實體詞為正面實體詞時,博文為正面傾向。
②情感詞為褒義詞,實體詞為負面實體詞時,博文為負面傾向。
③情感詞為貶義詞,實體詞為正面實體詞時,博文為負面傾向。
④情感詞為貶義詞,實體詞為負面實體詞時,博文為正面傾向。
⑤若存在否定詞或問號,博文傾向反轉。
步驟4.3 輸出博文的立場。
在OASOSR算法中,文本切詞的時間復雜度為O(n2),條件判斷、實體信息判斷的時間復雜度為O(n),而句法分析的時間復雜度為O(Kn3),可以得知OASOSR算法時間復雜度為O(Kn3)。
3 實 驗
3.1 實驗設置
為證明OASOSR算法的實用性,本文實現了OASOSR算法的自對比實驗和他比實驗。本文通過網絡爬蟲獲取了38 175條新冠肺炎疫情輿論微博數據(數據來源:https://github.com/Zu-Qin131/Weibo-public-opinion-analysis),并 對 新 冠肺炎疫情輿情言論微博數據進行人工實體標注,分為正面和負面情感博文,用于自對比實驗;并選用weibo_senti_100k(數據來源:https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets)的開源微博情感數據集,從中選取部分數據進行實體標注和人工正面、負面情感標注,應用于自對比實驗和他比實驗。上述數據集的特點總結如表3所示。
實驗中構造的微博情感詞典是在大連理工大學情感詞匯本體庫DUTIR的基礎上,添加與新冠肺炎疫情輿論相關的情感詞得到的。最終構建的情感詞典共有23 651個中文情感詞,包括9 833個正面情感詞和13 818個負面情感詞。
為了測試在數據量變化情況下OASOSR算法的穩定性、魯棒性與準確率變化趨勢,本節設計了基于OASOSR算法的自對比實驗。如表4所示,從新冠肺炎疫情話題數據集中隨機選取485條新冠肺炎疫情輿情言論微博數據,進行人工實體標注,并將博文分為正面情感博文和負面情感博文,其中已標注正面情感博文331條,負面情感博文154條,作為小規模數據集。

表4 對比實驗中選取的數據集大小Table 4 Size of datasets selected for comparative experiment
同時,也在weibo_senti_100k的開源微博情感數據集上使用該方法進行實驗,這是一個開源的大規模數據集,共有119 989條微博情感數據,從中隨機選取4 000條微博數據進行數據標注,并作為大規模數據集,其中標注了正面情感博文2 200條,負面情感博文1 800條。
為證明OASOSR算法在不同規模數據集上的有效性,設計了4組實驗,在不同規模下對OASOSR算法的魯棒性進行了測試。首先,在小規模數據集(新冠肺炎疫情話題數據集)上進行實驗,從新冠肺炎疫情話題數據集中隨機選取200條作為訓練集,剩余的285條博文作為測試集。然后,在大規模數據集上進行實驗,從weibo_senti_100k開源微博情感數據集中選取了2 000條作為訓練集,剩余2 000條作為測試集進行實驗。在2個數據集上分別進行4組實驗,每組實驗分別從訓練集中選取25%、50%、75%和100%的數據用于訓練,生成訓練結果,并對比觀察2個模型在測試集上情感分類的正確率,正確率對比如圖4所示。
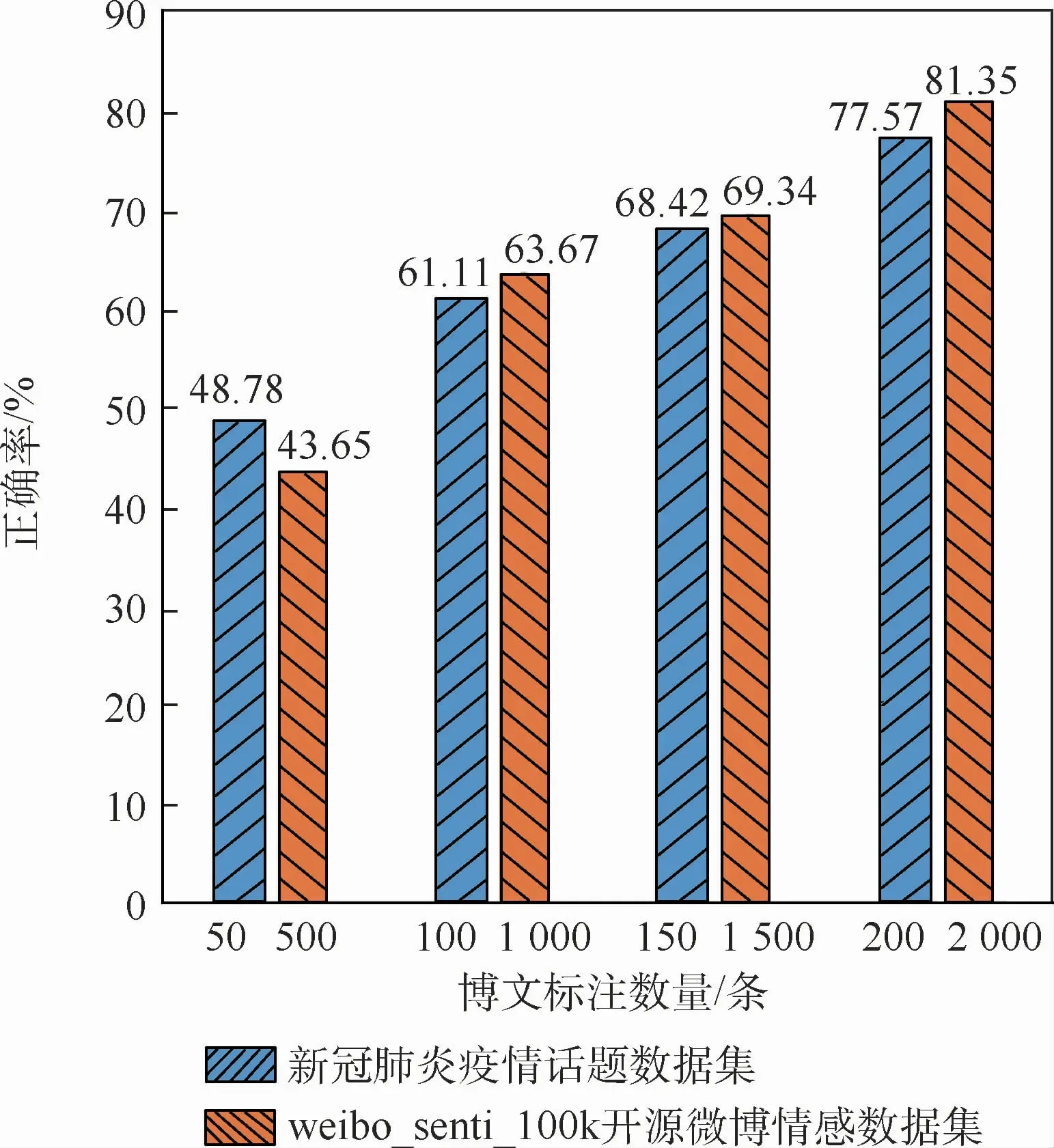
圖4 不同規模數據集上OASOSR算法立場判斷正確率Fig.4 Accuracy of standpoint judgement by OASOSR algorithm on different datasets
在小規模數據集上,當實體標注博文的數量為50條時,標注數據過少,識別出的情感對象實體較少,因此博文情感識別率較低。當實體標注博文的數量為100,150,200條時,正面和負面情感博文的判斷正確率持續提高。相似地,在大規模數據集上,當實體標注博文的數量為500條時,正面和負面情感博文的判斷正確率都比較低,而當情感標注博文的數量為1 000,1 500,2 000條時,正面和負面情感博文的判斷正確率持續提高。
可以看出,隨著訓練數據中標注實體的博文數量增加,在不同規模的數據集上,算法對微博立場的判斷正確率都在逐漸提高。OASOSR算法在數據集規模變化差別較大的情況下,仍具有很好的魯棒性。
3.2 他比實驗
他比實驗選取weibo_senti_100k開源微博情感數據集作為實驗語料。為了驗證OASOSR算法的有效性,本文選取了基于SVM的有監督情感文本分類方法(sentiment classification of texts based on SVM,SCSVM)[22]和基于極性詞典情感分析的無監督情感分類方法(sentiment analysis method based on a polarity lexicon,SAMPL)[23],分別與本文算法進行對比。在SCSVM方法中,先構建情感詞典,并進行情感特征選取及情感特征加權,再使用SVM分類的方法對文本進行情感識別及分類。SAMPL方法則綜合了基礎詞典、領域詞典、網絡詞典及修飾詞詞典,將極性詞和修飾詞組合成極性短語,以極性短語為極性計算的基本單元,進行情感分析。
表5展示了實驗中基于上述2個模型的微博立場判斷正確率和基于OASOSR算法的微博立場判斷正確率。對比表5中正確率可知,在同等數量的訓練集和測試集中,OASOSR算法要優于SCSVM方法和SAMPL方法。這是因為:本文提出的OASOSR算法充分考慮了對情感對象的識別,微博情感識別更有針對性,在立場判斷任務上的正確率相對較高。由對比實驗結果可以證明,相較于有監督學習方法和無監督學習方法,半監督學習方法更適用于指定實體的博文立場判斷。

表5 基于不同模型的微博立場判斷正確率Table 5 Accuracy of Weibo standpoint judgement based on different models
3.3 規則分析實驗
為證明OASOSR算法中不同情感規則在微博文本傾向性分析中會起到作用,本文設計了2組規則分析實驗。在第1組實驗中,設置變量為僅保留情感規則1~4條中的1條,去除其他3條規則;在第2組實驗中,設置變量為去除情感判斷規則1~4條中的1條,按原有順序保留其余3條規則。在新冠肺炎疫情話題數據集和weibo_senti_100k開源微博情感數據集上進行這2組實驗,生成實驗結果,并將結果與去除判斷規則前的實驗結果進行對比。圖5中,“單一”代表僅保留某1條規則,去除其他3條情感規則得到的實驗正確率;“缺失”表示缺失某1條規則,但保留其他3條規則的得到的實驗正確率。從實驗結果對比可以看出,在去除某1條情感規則后,立場判定的正確率均低于原有算法模型。特別是去除規則1后,正確率下降了34.36%。因此,OASOSR算法中4條規則互相支撐且都具有必要性,缺一不可。

圖5 基于不同模型篩選條件的微博立場判斷正確率Fig.5 Accuracy of Weibo standpoint judgement based on filtering conditions of different models
4 結 論
微博情感的分類較為簡單,無法判斷微博對特定方向實體的立場問題。針對微博文本數據信息量大、情感傾向性強的特點,本文提出了使用OASOSR算法解決微博立場判定問題。該算法結合深度學習與情感規則,實現微博立場判定。首先,本文采用半監督學習的方法,分別基于CHMM和CRF模型,對微博文本進行協同訓練,再通過主動學習的方法,提取微博文本中的指向性實體集,并構造了2個分類器。然后,通過分析大量微博文本中的句法特征,構建情感規則,提取句子的主成分,去除與立場判斷不相關的信息,將表達方式較為隨意的微博文本規范化。基于經過處理的博文數據,綜合判斷指向性實體的正面和負面性,結合博文句子中情感詞的褒貶義、分析情感詞充當的句子成分及情感詞修飾的實體類型,進而分析博文的傾向性,確定微博對指定主題所表達的立場。為證明OASOSR算法的實用性,本文實現了自對比實驗和他比實驗。自對比實驗顯示,隨著標注實體的博文數量增加,模型對博文立場判斷的正確率持續提升,證明了該算法可以有效增強立場判斷效果。將OASOSR算法與SCSVM方法、SAMPL方法進行對比實驗,在不同標注數量博文上進行對比的實驗結果顯示,OASOSR算法判斷博文立場的正確率顯著高于對比方法。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
