大規(guī)模物聯(lián)網(wǎng)惡意樣本分析與分類方法
2022-03-08 11:56:52何清林王麗宏羅冰楊黎斌
北京航空航天大學(xué)學(xué)報(bào) 2022年2期
何清林,王麗宏,羅冰,楊黎斌
(1.國(guó)家計(jì)算機(jī)網(wǎng)絡(luò)應(yīng)急技術(shù)處理協(xié)調(diào)中心,北京 100029; 2.北京航空航天大學(xué) 計(jì)算機(jī)學(xué)院,北京 100083;3.西北工業(yè)大學(xué) 網(wǎng)絡(luò)空間安全學(xué)院,西安 710072)
據(jù)世界經(jīng)濟(jì)論壇(WEF)發(fā)布的《2020年全球風(fēng)險(xiǎn)報(bào)告》[1],網(wǎng)絡(luò)攻擊將成為繼氣候?yàn)?zāi)難、極端天氣、核危機(jī)等之后人類面臨的第七大威脅,另?yè)?jù)統(tǒng)計(jì)機(jī)構(gòu)Statista的預(yù)測(cè)報(bào)告[2],物聯(lián)網(wǎng)設(shè)備將成為網(wǎng)絡(luò)中的主流設(shè)備,2025年將超過(guò)750億臺(tái),各類物聯(lián)網(wǎng)設(shè)備已經(jīng)成為網(wǎng)絡(luò)攻擊的重要目標(biāo)。2016年9月,第一個(gè)出現(xiàn)的大型物聯(lián)網(wǎng)僵尸網(wǎng)絡(luò)Mirai,其惡意樣本的功能和結(jié)構(gòu)相對(duì)簡(jiǎn)單,之后各種各樣的物聯(lián)網(wǎng)惡意樣本不斷涌現(xiàn),它們的功能越來(lái)越多,攻擊手法越來(lái)越復(fù)雜,感染各類物聯(lián)網(wǎng)設(shè)備的能力也越來(lái)越強(qiáng),已經(jīng)成為網(wǎng)絡(luò)空間中的重要威脅。物聯(lián)網(wǎng)惡意樣本含有攻擊模塊等漏洞利用相關(guān)的代碼,以及C&C服務(wù)器地址、代碼編寫風(fēng)格等體現(xiàn)作者屬性的信息,對(duì)樣本進(jìn)行分析、分類,可以獲得關(guān)鍵線索,支撐未知威脅發(fā)現(xiàn)、攻擊組織溯源等工作。
傳統(tǒng)惡意樣本一般使用家族標(biāo)簽對(duì)其進(jìn)行分類,但是對(duì)物聯(lián)網(wǎng)惡意樣本來(lái)說(shuō),家族標(biāo)簽并不適用。首先,物聯(lián)網(wǎng)惡意程序現(xiàn)有的家族標(biāo)簽信息并不準(zhǔn)確,目前已知的2個(gè)最大物聯(lián)網(wǎng)惡意樣本家族是Mirai和Gafgyt,但是這兩者都開放了源代碼,后續(xù)的大部分物聯(lián)網(wǎng)惡意樣本都混合使用了其開源代碼,無(wú)法實(shí)際區(qū)分兩者。其次,物聯(lián)網(wǎng)惡意樣本的家族標(biāo)簽信息不夠,無(wú)法精確刻畫惡意樣本的類別,以Mirai和Gafgyt為基礎(chǔ)延伸出多個(gè)分支的惡意樣本,僅使用家族標(biāo)簽無(wú)法對(duì)其進(jìn)行精確刻畫和分類。例如,廣泛傳播的Mozi系列樣本,就是一個(gè)融合了P2P、Mirai、Gafgyt等多種技術(shù)的系列樣本,但是并沒(méi)有明顯的家族標(biāo)簽與之對(duì)應(yīng)。因此,需要一種更精確的物聯(lián)網(wǎng)惡意樣本分類方法,對(duì)樣本的各個(gè)家族分支進(jìn)行追蹤和分析。
為了解決該問(wèn)題,本文開發(fā)了一套物聯(lián)網(wǎng)惡意樣本捕獲與分析系統(tǒng),在2019年5月至2020年5月在某運(yùn)營(yíng)商的網(wǎng)絡(luò)出入口節(jié)點(diǎn)上共捕獲到了157 911個(gè)在野傳播的物聯(lián)網(wǎng)惡意樣本。通過(guò)對(duì)樣本進(jìn)行靜態(tài)逆向和多種維度的統(tǒng)計(jì)分析,結(jié)合分析結(jié)果和關(guān)聯(lián)的威脅情報(bào)數(shù)據(jù),標(biāo)注了一套物聯(lián)網(wǎng)惡意樣本數(shù)據(jù)集,并提出了一種新的物聯(lián)網(wǎng)惡意樣本分類方法。該分類方法能夠?qū)崿F(xiàn)跨平臺(tái)架構(gòu)和高效的物聯(lián)網(wǎng)惡意樣本分類任務(wù),并且在標(biāo)記數(shù)據(jù)集上取得了優(yōu)異的分類效果,平均召回率達(dá)88.1%。
本文的主要貢獻(xiàn)如下:
1)對(duì)在野傳播的157 911個(gè)物聯(lián)網(wǎng)惡意程序進(jìn)行了分類和梳理,對(duì)其CPU架構(gòu)分布、加殼方式、樣本傳播方式等進(jìn)行了分析,給出了物聯(lián)網(wǎng)惡意樣本的最新流行趨勢(shì)。
2)結(jié)合多維度情報(bào)數(shù)據(jù),對(duì)部分物聯(lián)網(wǎng)惡意樣本進(jìn)行了標(biāo)注,形成了一套物聯(lián)網(wǎng)惡意樣本數(shù)據(jù)集。該數(shù)據(jù)集包括 9 個(gè)家族分支,共計(jì)12 278個(gè)樣本,覆蓋X86、MIPS、ARM等3種CPU架構(gòu)。
3)提出了一種新的物聯(lián)網(wǎng)惡意樣本的分類方法。該方法通過(guò)靜態(tài)逆向分析提取屬性函數(shù)調(diào)用圖(attributed functions call graph,AFCG)和字符文本等樣本信息,進(jìn)一步使用圖表示學(xué)習(xí)和文本表示學(xué)習(xí)的無(wú)監(jiān)督學(xué)習(xí)算法,提取高維的向量特征,實(shí)現(xiàn)對(duì)跨CPU架構(gòu)物聯(lián)網(wǎng)惡意樣本的統(tǒng)一表示。
4)對(duì)學(xué)習(xí)到的高維向量特征進(jìn)行了分類實(shí)驗(yàn)驗(yàn)證,使用有監(jiān)督學(xué)習(xí)分類支持向量機(jī)(SVM)算法進(jìn)行分類,在標(biāo)注數(shù)據(jù)集上達(dá)到平均88.1%的召回率。實(shí)驗(yàn)表明,從樣本提取出能表征樣本特征的信息越多,越能夠明顯提高分類的準(zhǔn)確率。
1 相關(guān)研究
2016年,Mirai事件的爆發(fā)讓物聯(lián)網(wǎng)惡意樣本進(jìn)入人們的視野,Antonakakis[3]、de Donno[4]等對(duì)Mirai事件過(guò)程及樣本的機(jī)理進(jìn)行了詳細(xì)描述。Mirai初期主要使用內(nèi)置密碼的密碼表,對(duì)大量具有弱口令的物聯(lián)網(wǎng)設(shè)備進(jìn)行了密碼爆破攻擊,在高峰時(shí)期控制了多達(dá)60萬(wàn)臺(tái)的物聯(lián)網(wǎng)設(shè)備。
物聯(lián)網(wǎng)惡意樣本主要是Linux平臺(tái)下的ELF文件,Cozzi等[5]對(duì)10 548個(gè)ELF惡意文件進(jìn)行了系統(tǒng)性分析,結(jié)合使用靜態(tài)分析和動(dòng)態(tài)分析的方法,分析了惡意樣本的ELF文件頭、持久化、加殼、信息收集、隱藏手法等9類行為特征,并指出同一家族的惡意代碼會(huì)具有明顯不同的行為特征。
Herwig等[6]分析了一個(gè)新的物聯(lián)網(wǎng)惡意程序家族Hajime,使用人工樣本逆向分析和流量分析的方法獲知Hajime的樣本行為,并估算僵尸網(wǎng)絡(luò)的規(guī)模,該僵尸網(wǎng)絡(luò)是披露的第一個(gè)大規(guī)模P2P物聯(lián)網(wǎng)僵尸網(wǎng)絡(luò)。文獻(xiàn)[7]分析了另外一個(gè)2020年新出現(xiàn)的大規(guī)模P2P僵尸網(wǎng)絡(luò)Mozi,病毒檢測(cè)引擎VirusTotal[8]目前把Mozi樣本識(shí)別為Mirai和Gafgyt,還沒(méi)有新的家族標(biāo)簽。
文獻(xiàn)[9-10]提出了基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)深度學(xué)習(xí)的惡意程序判定和分類方法,其中文獻(xiàn)[9]將物聯(lián)網(wǎng)樣本文件直接切割和轉(zhuǎn)換,變成灰度圖片后用CNN的模型進(jìn)行惡意性判定,文獻(xiàn)[10]根據(jù)樣本文件構(gòu)造熵灰度圖后使用CNN深度學(xué)習(xí)模型進(jìn)行分類。這類方法都沒(méi)有對(duì)樣本文件本身進(jìn)行深入的分析,沒(méi)有還原樣本的結(jié)構(gòu)特征和語(yǔ)義特征,可解釋性不足。
物聯(lián)網(wǎng)惡意樣本是編譯鏈接好的二進(jìn)制文件,與傳統(tǒng)的Windows PE樣本及Android APK樣本相比,有很多相似之處,其結(jié)構(gòu)特征一般包括逆向還原的函數(shù)調(diào)用圖(functions call graph,F(xiàn)CG)、控制流圖(control flow graph,CFG)等,語(yǔ)義特征一般包括函數(shù)的反匯編代碼片段等。惡意樣本文件特征提取是一項(xiàng)繁雜的工作,涉及復(fù)雜的靜態(tài)逆向分析,IDA Pro是最常用的靜態(tài)分析工具,文獻(xiàn)[11]對(duì)如何用IDA Pro分析物聯(lián)網(wǎng)惡意樣本給出了總結(jié)。其他常用的逆向分析工具還有Angr[12]、Radare2[13]等。
文獻(xiàn)[14-15]提出使用FCG作為惡意樣本相似性比較的主要參數(shù),其中文獻(xiàn)[14]使用優(yōu)化的圖編輯距離算法計(jì)算2個(gè)FCG圖之間的距離,文獻(xiàn)[15]則使用更多維度的函數(shù)屬性值來(lái)作為FCG的節(jié)點(diǎn)屬性,并采用學(xué)習(xí)優(yōu)化的方法來(lái)計(jì)算FCG的距離矩陣。
可以看出,提取樣本文件本身的復(fù)雜結(jié)構(gòu)特征和語(yǔ)義特征,并對(duì)其進(jìn)行表征和學(xué)習(xí),是惡意樣本研究的主流方向。物聯(lián)網(wǎng)惡意樣本出現(xiàn)時(shí)間不長(zhǎng),與傳統(tǒng)Window樣本和Android樣本相比又有很多新的特性,如支持的CPU架構(gòu)平臺(tái)多樣等,目前專門針對(duì)物聯(lián)網(wǎng)惡意樣本的分類研究還較少。本文借鑒傳統(tǒng)的樣本特征提取方法,同時(shí)考慮到物聯(lián)網(wǎng)樣本多平臺(tái)問(wèn)題,提出一種結(jié)合圖和文本特征,以及結(jié)合無(wú)監(jiān)督學(xué)習(xí)和有監(jiān)督學(xué)習(xí)的樣本分類方法。
2 物聯(lián)網(wǎng)惡意樣本分析
2019年5月至2020年5月,在某運(yùn)營(yíng)商網(wǎng)絡(luò)中一共捕獲到157 911個(gè)傳播的物聯(lián)網(wǎng)惡意樣本。通過(guò)對(duì)這些惡意樣本進(jìn)行大規(guī)模靜態(tài)逆向分析,包括其支持的CPU架構(gòu)、加殼方式、漏洞利用傳播方式等,形成了一套物聯(lián)網(wǎng)惡意程序標(biāo)注數(shù)據(jù)集。分析流程如圖1所示。
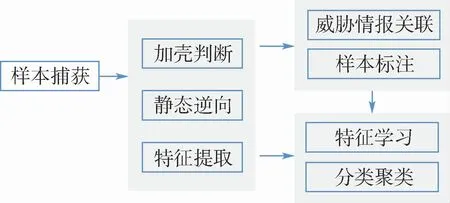
圖1 樣本分析處理示意圖Fig.1 Schematic diagram of sample analysis and processing
2.1 樣本CPU架構(gòu)分布
雖然物聯(lián)網(wǎng)設(shè)備的硬件形態(tài)及CPU架構(gòu)多種多樣,但是惡意程序的主要攻擊目標(biāo)是操作系統(tǒng)基于Linux內(nèi)核的設(shè)備,因此物聯(lián)網(wǎng)惡意樣本的形態(tài)主要為L(zhǎng)inux下的ELF可執(zhí)行文件。黑客在制造惡意程序時(shí),一般都會(huì)交叉編譯成多個(gè)版本的ELF文件同時(shí)發(fā)布,以支持不同的CPU架構(gòu)。根據(jù)所有樣本的統(tǒng)計(jì),其支持架構(gòu)分布如表1所示。

表1 157 911個(gè)惡意樣本CPU架構(gòu)分布Table 1 Distribution of CPU framework of 157 911 malwares
統(tǒng)計(jì)數(shù)據(jù)顯示,物聯(lián)網(wǎng)惡意樣本攻擊最多的為ARM和MIPS設(shè)備。可能因?yàn)樵诨ヂ?lián)網(wǎng)中暴露且經(jīng)常會(huì)出現(xiàn)漏洞的物聯(lián)網(wǎng)設(shè)備主要是路由器和攝像頭兩大類,其CPU架構(gòu)主要也是這2種,容易被黑客所青睞。另外統(tǒng)計(jì)數(shù)據(jù)還顯示,大部分支持Sparc、PowerPC等架構(gòu)的樣本,同時(shí)也有支持ARM、MIPS和X86等架構(gòu)的樣本存在。這說(shuō)明很多的物聯(lián)網(wǎng)惡意程序會(huì)同時(shí)發(fā)布7~8個(gè)版本。發(fā)現(xiàn)某個(gè)CPU架構(gòu)的惡意樣本后,在惡意樣本庫(kù)中快速找到跨平臺(tái)的其他同源惡意程序,也是大規(guī)模樣本分析的一個(gè)基本目標(biāo)。
2.2 樣本加殼
通過(guò)對(duì)惡意樣本加殼進(jìn)而隱藏相關(guān)信息,防止被安全人員逆向分析,是黑客常用的一種對(duì)抗手段。大規(guī)模樣本分析特別是靜態(tài)分析,需先解決樣本加殼問(wèn)題,然而對(duì)惡意程序進(jìn)行脫殼從來(lái)就不是一項(xiàng)容易的工作。Windows平臺(tái)下的PE樣本和Android平臺(tái)下的APK樣本,由于發(fā)展時(shí)間較長(zhǎng),存在各種各樣的加殼方式,脫殼對(duì)抗難度非常復(fù)雜。物聯(lián)網(wǎng)平臺(tái)下的ELF樣本,由于大規(guī)模出現(xiàn)的時(shí)間相對(duì)較晚,情況稍有不同,目前主要采用相對(duì)單一的UPX方式進(jìn)行加殼。
UPX本身是一種開源的文件壓縮方式,惡意程序編寫者們會(huì)通過(guò)改寫UPX文件頭的各種參數(shù)來(lái)防止解壓。文獻(xiàn)[5]中對(duì)2017—2018年捕獲的10 548個(gè)ELF樣本進(jìn)行統(tǒng)計(jì),發(fā)現(xiàn)只有3.8%的惡意程序使用了UPX 加殼。本文對(duì)2019年5月至2020年5月捕獲的157 911個(gè)惡意樣本進(jìn)行分析發(fā)現(xiàn),其中有超過(guò)37%的惡意樣本采用了UPX加殼,詳情如表2所示。
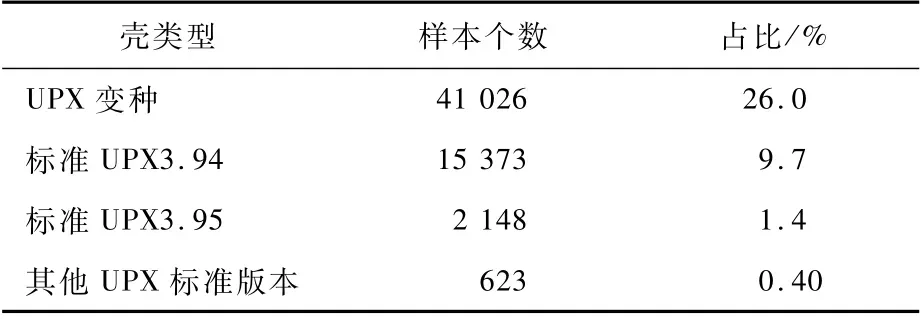
表2 物聯(lián)網(wǎng)惡意樣本加殼方式Table 2 Packers of IoT malware
因此從長(zhǎng)期來(lái)看,黑客會(huì)采用更多樣、更復(fù)雜的方式對(duì)ELF文件加殼,這將是安全人員長(zhǎng)期面臨的一項(xiàng)對(duì)抗與挑戰(zhàn)。
2.3 傳播方式
早期的物聯(lián)網(wǎng)惡意樣本,如2016年在美國(guó)爆發(fā)的Mirai,主要采用SSH密碼爆破的方式進(jìn)行植入和傳播。隨著黑客技術(shù)的演進(jìn)和攻防對(duì)抗的升級(jí),越來(lái)越多的物聯(lián)網(wǎng)惡意程序開始利用設(shè)備的漏洞進(jìn)行植入和傳播。2019年5月披露的Echobot系列樣本[16]使用了多達(dá)70個(gè)已知的漏洞利用進(jìn)行傳播。2020年3月,筆者團(tuán)隊(duì)發(fā)現(xiàn)有Fbot的惡意樣本開始利用0-day漏洞進(jìn)行傳播。
針對(duì)所有捕獲的樣本進(jìn)行漏洞利用分析,在其中的68 648個(gè)樣本中發(fā)現(xiàn)有已知漏洞利用行為,共計(jì)發(fā)現(xiàn)超過(guò)200種物聯(lián)網(wǎng)漏洞利用行為,其中最常用的物聯(lián)網(wǎng)漏洞有CVE-2017-17215等。統(tǒng)計(jì)前10個(gè)利用最多的漏洞,詳情如表3所示。
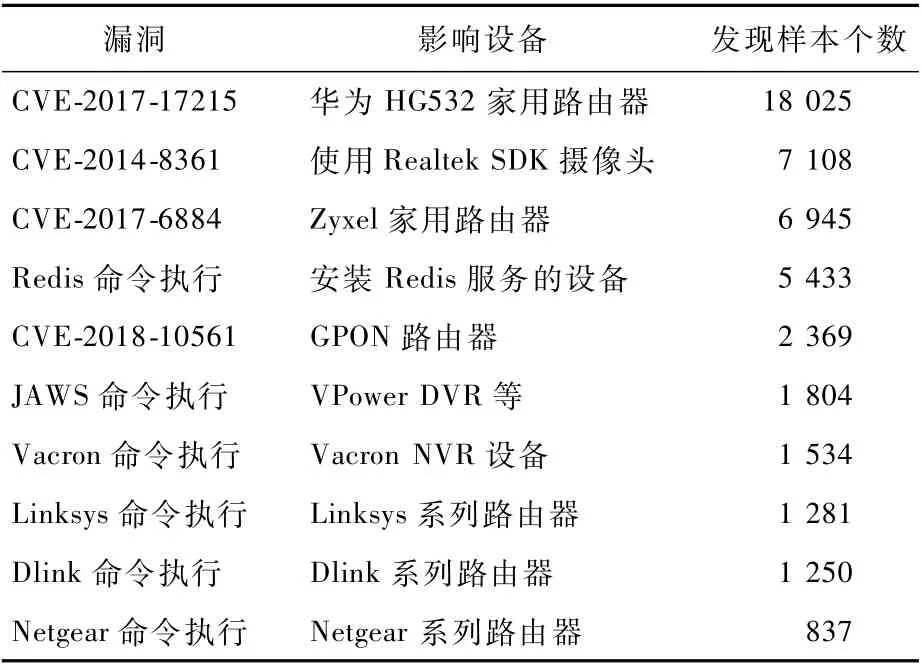
表3 樣本10大漏洞利用統(tǒng)計(jì)Table 3 Statistics of top 10 vulnerability exploited in malware
另外,筆者團(tuán)隊(duì)發(fā)現(xiàn)物聯(lián)網(wǎng)惡意樣本在網(wǎng)絡(luò)中傳播時(shí)會(huì)使用特定的文件名,如Hajime家族[6]主要采用“.i”的文件名進(jìn)行傳播,最新的Mozi系列樣本[7]使用了“Mozi.a”和“Mozi.m”的文件名。圖2顯示了2個(gè)典型Mozi樣本的邏輯結(jié)構(gòu),分別是“Mozi.a”和“Mozi.m”,具有不同的CPU架構(gòu),但是具有相似的邏輯結(jié)構(gòu)。
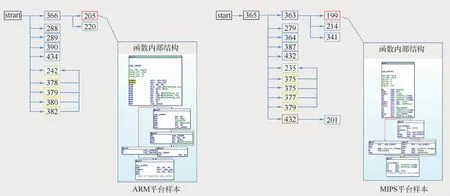
圖2 兩個(gè)Mozi樣本的FCG示意圖Fig.2 Schematic diagram of FCG of two Mozi samples
樣本傳播方式包括傳播文件名和漏洞利用手法,是標(biāo)注數(shù)據(jù)集時(shí)參考的一項(xiàng)主要參數(shù)。
2.4 標(biāo)注數(shù)據(jù)集
在惡意樣本識(shí)別和分類研究中,目前使用最多的數(shù)據(jù)集是2015微軟惡意樣本分類挑戰(zhàn)賽數(shù)據(jù)集[17],其中的惡意程序主要是Windows平臺(tái)下的PE文件,包含9類共21 704個(gè)惡意程序。而針對(duì)物聯(lián)網(wǎng)惡意樣本的研究,目前并沒(méi)有一個(gè)公認(rèn)的數(shù)據(jù)集。
根據(jù)捕獲到的惡意樣本文件,以及相關(guān)的傳播地址、C2地址等威脅情報(bào)信息,同時(shí)參考病毒檢測(cè)引擎平臺(tái)VirusTotal[8]的樣本檢測(cè)結(jié)果和部分人工分析結(jié)果,標(biāo)注了一套物聯(lián)網(wǎng)惡意樣本數(shù)據(jù)集,作為后續(xù)進(jìn)行大規(guī)模樣本分類研究的基礎(chǔ)。如此規(guī)模的數(shù)據(jù)集標(biāo)注,無(wú)法依賴人工分析手動(dòng)完成,須通過(guò)自動(dòng)識(shí)別和關(guān)聯(lián),因此數(shù)據(jù)集的標(biāo)注要求至少滿足以下2個(gè)條件:①樣本能夠通過(guò)程序自動(dòng)脫殼并成功提取到靜態(tài)編譯信息,以滿足后續(xù)的特征處理要求;②樣本有相關(guān)的關(guān)聯(lián)威脅情報(bào)信息,如樣本使用的傳播文件名和傳播地址、樣本在VirusTotal[8]上有檢索結(jié)果等信息,用來(lái)確定該樣本是哪個(gè)具體的家族或者分支。但是在捕獲的所有樣本中,其中有大部分樣本或是無(wú)法進(jìn)行自動(dòng)脫殼,或是無(wú)法關(guān)聯(lián)到相關(guān)信息,因此無(wú)法對(duì)其進(jìn)行標(biāo)注并納入到標(biāo)注數(shù)據(jù)集中。最終從157 911個(gè)物聯(lián)網(wǎng)惡意樣本中成功標(biāo)注了12 278個(gè)樣本,作為標(biāo)注數(shù)據(jù)集進(jìn)行分類實(shí)驗(yàn)。包括9個(gè)類別,覆蓋ARM、MIPS、X86三種CPU架構(gòu),如表4所示。數(shù)據(jù)集中的樣本都是已脫殼并能通過(guò)反編譯工具提取出靜態(tài)特征信息。

表4 物聯(lián)網(wǎng)惡意程序標(biāo)注數(shù)據(jù)集Table 4 Labeled IoT malware dataset
數(shù)據(jù)集中的類別與惡意樣本的家族并不是一一對(duì)應(yīng)關(guān)系,而是某一家族樣本的某類具體分支。即使同一個(gè)樣本,在VirusTotal上不同引擎也會(huì)給出不同的家族標(biāo)簽,而目前物聯(lián)網(wǎng)惡意代碼的家族判定并沒(méi)有統(tǒng)一的標(biāo)準(zhǔn)。本文目標(biāo)不是研究樣本的惡意性判定或者家族判定,而是研究如何對(duì)已發(fā)現(xiàn)的大量IoT惡意樣本進(jìn)行更詳細(xì)的分類,找出具有同類行為的分支,并對(duì)其進(jìn)行更深入的追蹤,從而溯源攻擊組織、發(fā)現(xiàn)具有高級(jí)威脅的未知樣本等。
3 樣本特征提取
惡意樣本分析,一般來(lái)說(shuō)有靜態(tài)分析和動(dòng)態(tài)分析2種方法。靜態(tài)分析主要通過(guò)反匯編反編譯,提取二進(jìn)制文件的語(yǔ)義和語(yǔ)法信息;動(dòng)態(tài)分析則是通過(guò)在虛擬環(huán)境下運(yùn)行可執(zhí)行程序,獲得各類運(yùn)行狀態(tài)行為信息。目前,物聯(lián)網(wǎng)惡意程序支持的設(shè)備種類眾多,缺乏成熟的動(dòng)態(tài)執(zhí)行環(huán)境。本文主要采用靜態(tài)分析的方法提取函數(shù)調(diào)用關(guān)系圖、函數(shù)反匯編代碼、字符文本等特征,主要分析流程如圖3所示。
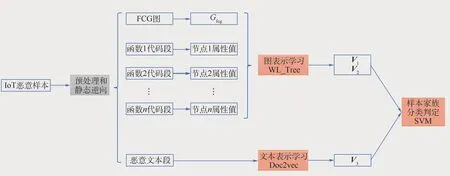
圖3 樣本特征提取與分類方法示意圖Fig.3 Schematic diagram of sample feature extraction and classification method
3.1 函數(shù)調(diào)用圖
FCG是能夠從整體上直接反應(yīng)惡意樣本邏輯結(jié)構(gòu)的一種表示。它是一類典型的圖結(jié)構(gòu)G(node,edge),node表示惡意樣本中的函數(shù),edge表示函數(shù)之間的調(diào)用關(guān)系,edge是有向邊。圖2顯示了2個(gè)同分支的樣本,分屬不同的CPU架構(gòu),但具有相似的FCG結(jié)構(gòu)和函數(shù)結(jié)構(gòu)。圖中:節(jié)點(diǎn)編號(hào)代表了函數(shù)的排列序號(hào),樣本總計(jì)有400多個(gè)函數(shù)節(jié)點(diǎn),為方便表示只標(biāo)記了從起點(diǎn)函數(shù)開始的前3層調(diào)用節(jié)點(diǎn)。
能否成功從樣本中還原出FCG圖,取決于2個(gè)因素:①樣本沒(méi)有加殼或者能夠成功解殼;②樣本沒(méi)有使用外部動(dòng)態(tài)鏈接庫(kù)。本文數(shù)據(jù)集都進(jìn)行了脫殼處理,而且都僅使用靜態(tài)鏈接的樣本。另外,根據(jù)對(duì)物聯(lián)網(wǎng)樣本庫(kù)的統(tǒng)計(jì),目前僅有3.2%的樣本使用了動(dòng)態(tài)鏈接庫(kù)。
對(duì)惡意樣本直接進(jìn)行靜態(tài)逆向得到的FCG圖,通常不是一個(gè)連通圖。例如,很多物聯(lián)網(wǎng)的惡意程序都有一個(gè)初始化函數(shù)init_func,其表示的節(jié)點(diǎn)在圖中是個(gè)獨(dú)立的節(jié)點(diǎn)。根據(jù)對(duì)樣本庫(kù)的統(tǒng)計(jì)數(shù)據(jù)顯示,最大連通子圖中的節(jié)點(diǎn)個(gè)數(shù)占整個(gè)圖的節(jié)點(diǎn)個(gè)數(shù)比率的分布區(qū)間為93.2% ~99.1%,平均值為96.7%。選取G(node,edge)的最大連通子圖作為惡意程序的函數(shù)調(diào)用圖近似表示Gfcg,可以認(rèn)為Gfcg就是惡意程序的邏輯結(jié)構(gòu)表示。
本文針對(duì)數(shù)據(jù)集中的12 278個(gè)不同的惡意程序文件進(jìn)行分析提取,得到1 323個(gè)不同的Gfcg文件。這表明很多惡意樣本具有同樣的Gfcg,樣本的邏輯結(jié)構(gòu)是完全一致的,惡意樣本的編寫者們只是進(jìn)行了一點(diǎn)簡(jiǎn)單修改,如修改C2地址或?qū)δ硞€(gè)函數(shù)的功能進(jìn)行升級(jí)等,再重新編譯作為一個(gè)新的惡意程序發(fā)布。以數(shù)據(jù)集中的第4類Josho樣本為例,有2個(gè)MD5值不同的樣本,其樣本MD5值分別為:“aeb9d28e524694e5ef5eb6275 ef53b05”和“90e2ab9037c9b18cb2ea83c5f3862ee6”(VirusTotal[8]上均可以檢索到樣本相關(guān)信息),文件大小分別為56 584 Byte和58 180 Byte。通過(guò)靜態(tài)分析提取得到的這2個(gè)樣本的函數(shù)調(diào)用關(guān)系Gfcg完全一樣,而這樣的情況在同一類樣本中大量出現(xiàn)。由此可以看出,Gfcg圖是一種能夠快速識(shí)別和分類相似惡意樣本的方法。
進(jìn)一步,如果加上節(jié)點(diǎn)屬性,也就是函數(shù)的屬性,就可以得到惡意程序的邏輯結(jié)構(gòu)及語(yǔ)義表示,形成屬性函數(shù)調(diào)用圖,用Gafcg表示。
3.2 函數(shù)屬性
惡意樣本是一類可執(zhí)行的二進(jìn)制文件,而函數(shù)是二進(jìn)制文件的基本邏輯單元。針對(duì)二進(jìn)制文件中的函數(shù)屬性提取和學(xué)習(xí)是逆向靜態(tài)分析的一個(gè)重要研究方向,尤其是漏洞挖掘樣本關(guān)聯(lián)分析等。很多安全分析人員直接根據(jù)函數(shù)的hash值進(jìn)行分析[18];也有使用函數(shù)控制流圖信息來(lái)進(jìn)行大規(guī)模二進(jìn)制分析[19],如漏洞挖掘固件組件分析等;文獻(xiàn)[20]使用BERT深度學(xué)習(xí)框架學(xué)習(xí)函數(shù)的特征。
與以上方法不同,本文使用一種相對(duì)高效且跨平臺(tái)的方式來(lái)學(xué)習(xí)函數(shù)的向量化表示。先對(duì)惡意程序進(jìn)行靜態(tài)逆向得到函數(shù)的一段反匯編碼。在反匯編代碼中,一般包含API調(diào)用(系統(tǒng)或外部調(diào)用)和本地匯編操作。一個(gè)典型的本地匯編操作包含操作指令和地址或變量。其中地址或變量是動(dòng)態(tài)執(zhí)行相關(guān)的,通過(guò)靜態(tài)逆向分析得到的值參考意義有限,因此重點(diǎn)關(guān)注操作指令。把函數(shù)轉(zhuǎn)換成一段包含操作指令和API調(diào)用的序列。
不同CPU架構(gòu)的指令集規(guī)模不一樣,統(tǒng)計(jì)157 911個(gè)物聯(lián)網(wǎng)惡意樣本用到的指令,按照CPU架構(gòu)類別統(tǒng)計(jì),如表5所示。更進(jìn)一步,為了解決函數(shù)屬性跨平臺(tái)統(tǒng)一表示的問(wèn)題,參考文獻(xiàn)[21-22]的方法,將操作指令統(tǒng)一為中間語(yǔ)言表示。定義20個(gè)不同的操作類型,根據(jù)指令類別和在樣本中出現(xiàn)的頻率,將不同CPU架構(gòu)的指令映射到這20類中,將API調(diào)用映射為另外1類。目前,僅對(duì)物聯(lián)網(wǎng)惡意樣本中最常見的3種CPU架構(gòu),也是樣本集中涉及到的3種CPU架構(gòu),即ARM、MIPS、X86做了映射和統(tǒng)一表示。

表5 惡意樣本中常用的3種CPU架構(gòu)指令集數(shù)量Table 5 Number of instruction set commonly used in malware with three CPU framewor ks
提取的函數(shù)屬性值是一段有序的數(shù)值序列A,序列中的數(shù)值為1~21的數(shù)。通過(guò)對(duì)序列A學(xué)習(xí)的向量作為函數(shù)的屬性值。進(jìn)一步,將函數(shù)與Gafcg中的節(jié)點(diǎn)對(duì)應(yīng)起來(lái),并將函數(shù)屬性值作為節(jié)點(diǎn)的屬性值,得到樣本的Gafcg表示。從樣本中一共提取出了1 323個(gè)不同的Gafcg文件。
3.3 字符串信息
物聯(lián)網(wǎng)惡意程序在編譯連接生成ELF格式的可執(zhí)行文件時(shí),會(huì)將很多字符串一起打包到可執(zhí)行文件中。這些字符串一般包括本地的操作命令、密碼表、遠(yuǎn)程通信命令等信息。通過(guò)反匯編提取惡意程序可執(zhí)行文件的字符信息,從而來(lái)判斷惡意程序的行為,是逆向分析時(shí)的一個(gè)基本手段,如提取惡意程序外聯(lián)的C2地址、惡意程序傳播時(shí)利用的漏洞、使用的爆破密碼表等。字符串包含了豐富的信息,對(duì)其內(nèi)容進(jìn)行表示學(xué)習(xí)和分類,可以更好地對(duì)惡意程序進(jìn)行識(shí)別和分類。
從惡意程序提取出來(lái)的字符串是按行排列的,每一行代表一類操作或者一類命令,行與行之間是上下文無(wú)關(guān)的。對(duì)樣本提取原始的字符串,再進(jìn)一步重排序處理,得到8 590個(gè)不同的字符串文本文件malware_string。
樣本集中的樣本個(gè)數(shù)是12 278個(gè),提取出來(lái)的不同的Gafcg文件是1 323個(gè),不同的字符串文本文件是8 590個(gè)。字符串文本文件和Gafcg文件的數(shù)目并不一致,多個(gè)樣本可能對(duì)應(yīng)同一個(gè)Gafcg文件,卻對(duì)應(yīng)不同的字符串文本文件。因?yàn)橥粋€(gè)樣本進(jìn)行修改再編譯發(fā)布時(shí)可能不改變函數(shù)邏輯結(jié)構(gòu)FCG,卻會(huì)修改字符串文本文件,所以樣本分類時(shí),將主要參考FCG圖和AFCG圖等邏輯結(jié)構(gòu)信息,字符串文本特征作為輔助。進(jìn)一步對(duì)字符串文本進(jìn)行映射和處理后,從樣本集中一共提取到1 323個(gè)不同的字符串文本文件。
4 特征學(xué)習(xí)及分類實(shí)驗(yàn)
從物聯(lián)網(wǎng)惡意樣本中提取出來(lái)的特征是包括圖和文本等信息的復(fù)雜結(jié)構(gòu)特征,無(wú)法直接使用這些特征來(lái)進(jìn)行惡意樣本的分類任務(wù)。因此,使用圖表示學(xué)習(xí)和文本表示學(xué)習(xí)的方法,將惡意樣本的特征轉(zhuǎn)換成統(tǒng)一的向量表示。
針對(duì)實(shí)際場(chǎng)景設(shè)計(jì)了9組分類方法實(shí)驗(yàn),驗(yàn)證從惡意樣本中提取和學(xué)習(xí)到的特征的有效性。
4.1 圖表示學(xué)習(xí)
文獻(xiàn)[14-15]用惡意樣本的FCG圖進(jìn)行分類判定,兩兩計(jì)算2個(gè)圖之間的編輯距離,再以此為基礎(chǔ)構(gòu)建和優(yōu)化相似性模型。本文做法與之前的方法不同,使用圖表示學(xué)習(xí)的方法,將FCG圖通過(guò)表示學(xué)習(xí)直接映射到一個(gè)向量空間中。
圖表示學(xué)習(xí),目前主要有基于核函數(shù)的方法和圖神經(jīng)網(wǎng)絡(luò)方法兩大類。圖神經(jīng)網(wǎng)絡(luò)方法更適合學(xué)習(xí)節(jié)點(diǎn)的特征用于節(jié)點(diǎn)分類任務(wù),而針對(duì)整個(gè)圖的分類任務(wù),則使用圖核函數(shù)的方法更多。目前,常見的圖核函數(shù)有基于隨機(jī)游走的核函數(shù)、基于路徑的核函數(shù)、基于子樹結(jié)構(gòu)的核函數(shù)等。
對(duì)圖的整體結(jié)構(gòu)捕獲和表達(dá)能力最好的是基于子樹結(jié)構(gòu)的WL_Subtree核函數(shù)[23],其是一種快速計(jì)算的子樹核,由多步迭代計(jì)算完成。
圖表示學(xué)習(xí)對(duì)象為:無(wú)節(jié)點(diǎn)屬性的FCG圖和包含節(jié)點(diǎn)屬性的AFCG圖。從樣本數(shù)據(jù)集中一共提取出1 323個(gè)不同的圖,圖的節(jié)點(diǎn)規(guī)模分布區(qū)間為212~3 226,均值為372。對(duì)FCG圖Gfcg和AFCG圖Gafcg分別進(jìn)行圖表示學(xué)習(xí),得到2組特征向量V1和特征向量V2,如式(1)、式(2)所示,其中kWL_SubTree表示W(wǎng)L_Subtree核函數(shù):

4.2 文本表示學(xué)習(xí)
目前,文本學(xué)習(xí)方法主要有輕量級(jí)的TF-IDF、Word2vec[24]等簡(jiǎn)單模型,也包括像BERT[20]深度學(xué)習(xí)框架等較為復(fù)雜的模型。TF-IDF實(shí)現(xiàn)相對(duì)簡(jiǎn)單,較為容易理解,不足在于沒(méi)有考慮特征在樣本間分布情況,難以適用于惡意樣本分類場(chǎng)景。BERT深度學(xué)習(xí)框架能夠梳理出連續(xù)文本的內(nèi)在聯(lián)系和語(yǔ)言結(jié)構(gòu),但對(duì)數(shù)據(jù)規(guī)模及模型大小要求非常苛刻,一般適用于大規(guī)模海量的數(shù)據(jù)場(chǎng)景中。
學(xué)習(xí)對(duì)象為惡意樣本提取出來(lái)的字符串形式的文本標(biāo)記為malware_string,其大小分布一般在5 KByte至50 KByte之間,樣本中需要用來(lái)進(jìn)行下游分類任務(wù)的文本malware_string的數(shù)量為1 323個(gè)。綜合性能和效率考慮,同時(shí)能夠更好地利用隱藏在樣本序列中的語(yǔ)義和語(yǔ)法信息,引入Doc2vec[25]方法進(jìn)行向量特征提取。Doc2vec方法是一種無(wú)監(jiān)督算法,可從變長(zhǎng)的惡意樣本字符文本中學(xué)習(xí)得到固定長(zhǎng)度的特征表示,既可克服詞袋模型中沒(méi)有語(yǔ)義的缺點(diǎn),又能接受不同長(zhǎng)度的惡意樣本做訓(xùn)練,并表征為向量。利用Doc2vec方法進(jìn)行向量特征學(xué)習(xí)過(guò)程,主要包括去噪、訓(xùn)練及推斷等3個(gè)步驟,如圖4所示。在Doc2vec方法中,首先在去噪過(guò)程中通過(guò)預(yù)處理剔除了一些惡意文本中噪聲數(shù)據(jù),將惡意文本庫(kù)的格式修剪統(tǒng)一;其次在訓(xùn)練過(guò)程中,主要期望在已知的惡意文本訓(xùn)練數(shù)據(jù)中得到惡意字符串的詞向量、softmax的參數(shù)、惡意文本段落向量或句向量以進(jìn)行后續(xù)推斷操作;最后在推斷過(guò)程中,主要利用已有信息,推斷后續(xù)新的段落向量表達(dá)形式,得到惡意文本的向量表達(dá)形式。最終通過(guò)Doc2vec方法學(xué)習(xí)到的惡意文本向量表達(dá)記為特征向量V3,如下:

圖4 基于文本表示學(xué)習(xí)的向量特征學(xué)習(xí)Fig.4 Vector characteristic learning based on text representation learning

4.3 二分類學(xué)習(xí)
設(shè)計(jì)的分類實(shí)驗(yàn)是二分類學(xué)習(xí),對(duì)應(yīng)的實(shí)際場(chǎng)景是:如果已知某一物聯(lián)網(wǎng)惡意樣本家族分支的系列樣本后,能否通過(guò)學(xué)習(xí)的方法,快速地從樣本庫(kù)中或者新發(fā)現(xiàn)的樣本找出同類的樣本。將樣本集中的每一類樣本分別標(biāo)記為正例樣本,樣本集中的其他樣本標(biāo)記為負(fù)例樣本,做二分類學(xué)習(xí)和判定。分類算法使用SVM。
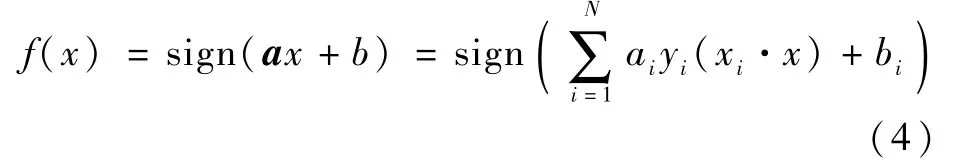
SVM是基于超平面分類線性可分的假設(shè),通過(guò)學(xué)習(xí)和優(yōu)化得到一個(gè)超平面分類器。假設(shè)有N個(gè)訓(xùn)練集{(x1,y1),(x2,y2),…,(xN,yN)},xi∈Rd,yi∈{-1,1}。假設(shè)空間為超平面(a,b),a為權(quán)重向量,b為偏差,對(duì)一個(gè)新輸入的數(shù)據(jù)x可以用如下分類:該分類問(wèn)題是個(gè)不平衡分類問(wèn)題,正例樣本的個(gè)數(shù)遠(yuǎn)小于負(fù)例樣本的個(gè)數(shù),實(shí)際場(chǎng)景中也是如此。因此,更關(guān)注正例樣本是否被正確標(biāo)記,把召回率R作為主要參考的評(píng)價(jià)指標(biāo),同時(shí)參考F1值,指標(biāo)如式(5)和式(6)所示。其中TP表示被正確標(biāo)記正例樣本,F(xiàn)P表示被錯(cuò)誤標(biāo)記的正例樣本,F(xiàn)N表示被錯(cuò)誤標(biāo)記的負(fù)例樣本。

選3種不同的樣本特征作為分類學(xué)習(xí)的算法輸入,分別使用從樣本FCG 圖學(xué)習(xí)到的向量V1(1)、從樣本AFCG圖向量學(xué)習(xí)到的向量V2(2)、V2和從樣本的惡意文本學(xué)習(xí)到的向量V3(3)相結(jié)合。不同的特征選擇,代表了不同的樣本表征能力。實(shí)驗(yàn)中,將訓(xùn)練集和測(cè)試集劃分為0.8和0.2,最終選取多次實(shí)驗(yàn)的平均值作為最終指標(biāo)。實(shí)驗(yàn)結(jié)果如表6所示。
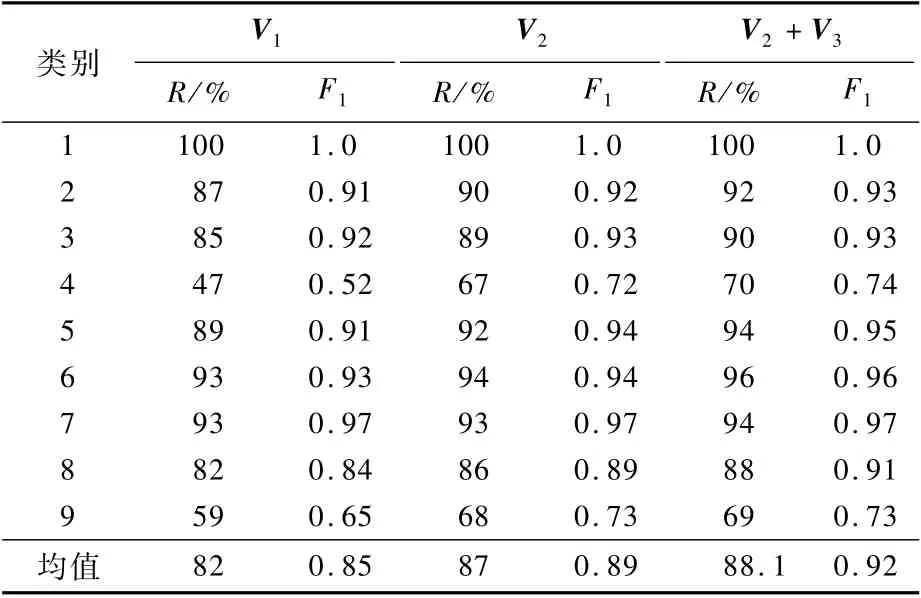
表6 不同特征和類別的分類召回率及F 1 值Table 6 Classification r ecall rate and F 1 value with different features and categories
4.4 實(shí)驗(yàn)結(jié)果分析
實(shí)驗(yàn)結(jié)果顯示,樣本分類平均召回率達(dá)到88.1%,說(shuō)明從樣本中提取的特征是有效的,通過(guò)表示學(xué)習(xí)得到的向量,可以很好地從整體上表征惡意樣本。實(shí)驗(yàn)結(jié)果還顯示,使用的特征越多,分類效果越好,說(shuō)明如果能夠從樣本中提取出更多能表達(dá)樣本邏輯結(jié)構(gòu)和語(yǔ)義信息的特征,更有助于提高分類的效果。
實(shí)驗(yàn)中的9組分類實(shí)驗(yàn),分別對(duì)應(yīng)數(shù)據(jù)集中9個(gè)不同的樣本家族分支類別。其中除了第2組Mozi分支以外,其他8個(gè)分支均由Mirai家族演化而來(lái)。其中第4組和第9組的樣本分類召回率較低,分別是JoSho家族分支的74%和Owari家族分支的73%。對(duì)這2個(gè)家族分支的部分樣本進(jìn)行人工逆向分析,發(fā)現(xiàn)其樣本中大量借鑒了Mirai的開源源碼。例如,屬于JoSho家族分支的MD5值為“aeb9d28e524694e5ef5eb6275ef53 b05”的樣本,和屬于Owari家族分支的MD5值為“46a4cea56dafbfecd0981a7d411508c9” 的 樣 本(VirusTotal[8]上均可以檢索到樣本相關(guān)信息),通過(guò)對(duì)這2個(gè)樣本進(jìn)行人工逆向分析發(fā)現(xiàn),其與Mirai源代碼的差異性不到10%。而這2個(gè)樣本在這2類家族分支具有典型性,在該家族分支中分別存在多個(gè)與這2個(gè)樣本相似的樣本。這說(shuō)明這2個(gè)家族分支在樣本中自己進(jìn)行編碼的部分并不多,也就是說(shuō)沒(méi)有很明顯的樣本分支特征,從而導(dǎo)致分類效果不是很理想。
實(shí)驗(yàn)結(jié)果顯示,其余7組家族分支的樣本檢出率均超過(guò)了0.8,其中1組的檢出率為1.0,說(shuō)明本文樣本分類方法能夠?qū)Υ蟛糠值臉颖炯易宸种нM(jìn)行正確地分類,實(shí)現(xiàn)對(duì)不同家族分支的樣本進(jìn)行追蹤分析的目標(biāo)。
5 結(jié) 論
目前,針對(duì)物聯(lián)網(wǎng)惡意樣本的大規(guī)模分類研究屬于剛剛起步階段,本文根據(jù)實(shí)際工作中捕獲到的物聯(lián)網(wǎng)惡意樣本,進(jìn)行了大規(guī)模分析和分類的嘗試:
1)對(duì)所有樣本進(jìn)行了分析和統(tǒng)計(jì),并結(jié)合外部威脅情報(bào)特征和人工分析,標(biāo)注了一套物聯(lián)網(wǎng)惡意樣本數(shù)據(jù)集。
2)通過(guò)靜態(tài)逆向分析提取特征和學(xué)習(xí)特征,在標(biāo)注的樣本數(shù)據(jù)集上進(jìn)行分類實(shí)現(xiàn),效果表現(xiàn)優(yōu)異,達(dá)到了平均88.1%的召回率。
3)該樣本分類方法在實(shí)際工作中取得了較好的效果,能夠持續(xù)地自動(dòng)標(biāo)注新的樣本。
在實(shí)際工作中,筆者一直在持續(xù)跟蹤Mozi系列的樣本[7],即標(biāo)注數(shù)據(jù)集中的第2類,通過(guò)數(shù)據(jù)集訓(xùn)練生成的分類器,從原來(lái)的樣本庫(kù)中識(shí)別出了數(shù)十個(gè)之前未曾被標(biāo)記的Mozi系列樣本,并通過(guò)后續(xù)進(jìn)一步的人工分析一一確認(rèn),通過(guò)分類器自動(dòng)標(biāo)記的Mozi樣本是有效的。進(jìn)一步,該方法已經(jīng)用在后續(xù)的日常樣本分析中,將每天新發(fā)現(xiàn)的樣本進(jìn)行自動(dòng)分類和標(biāo)注。
惡意樣本分析和分類與其他領(lǐng)域(如圖像識(shí)別分類等)不同,其研究對(duì)象惡意樣本是由黑客制造出來(lái),對(duì)象的性質(zhì)會(huì)由于黑客持續(xù)對(duì)抗而變化。對(duì)樣本的特征提取會(huì)由于加殼等技術(shù)的升級(jí)而變得日益困難,特征的表達(dá)能力可能也會(huì)由于使用代碼混淆等高級(jí)對(duì)抗手法而受到影響。筆者將深入挖掘樣本多個(gè)維度的特征,并結(jié)合安全專家知識(shí),對(duì)物聯(lián)網(wǎng)惡意樣本分類問(wèn)題進(jìn)行持續(xù)研究。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
