分布式存儲系統中自適應糾刪碼的研究綜述
2022-03-07 04:34:52陳歡華
現代計算機 2022年24期
關鍵詞:符號
陳歡華
(廣州軟件學院網絡中心,廣州 510990)
0 引言
為了應對爆炸性的數據增長,如今的存儲系統通常在多個地理位置部署數千個商品存儲節點或服務器,以提供大規模的存儲服務。這些系統通常構建在常見的組件上,這些組件更容易發生故障。軟件故障、機器重啟、維護停機、電源故障也可能使數據隨時不可用,因此這些系統應保證數據的可靠和持久存儲。為了在發生故障時保持數據的可靠性和可用性,傳統的分布式存儲系統通常采用冗余技術,如三副本[1-2]。當數據量較小時,冗余方法直接有效;然而,在大型數據中心,復制帶來的200%的存儲開銷是巨大的,無法接受。作為一種折衷方案,糾刪碼是一種存儲高效的容錯技術,可以提供相同或更高級別的可靠性,同時需要更少的數據冗余[2]。因此,糾刪碼變得越來越流行,并被包括Microsoft[3]和Facebook[4]在內的企業廣泛采用。
為了響應不同的訪問特性[5]和滿足動態可靠性要求[6],現代存儲系統需要糾刪碼具備自適應功能。自適應糾刪碼,指的是編碼參數和編解碼方案隨著各類要求的變化。我們認為自適應糾刪碼在以下場景中是至關重要的。
(1)適應傾斜和動態的工作負載。實際存儲系統中的工作負載是非常傾斜和動態的。傾斜意味著一小部分熱數據被頻繁訪問,而大部分冷數據很少被訪問,而動態屬性意味著數據熱度是隨時間變化的。為了兼顧高訪問性能和高存儲效率,實際的存儲系統可以使用高冗余糾刪碼存儲熱數據以獲得高性能,同時使用低冗余糾刪碼存儲冷數據以獲得低成本持久化。當數據熱度變化時,執行自適應以更新編碼參數或者更改編解碼方案[7]。
(2)適應不同的可靠性。不同生命周期的數據需要不同程度的可靠性,因此存儲系統需要動態調整編碼參數以滿足不同的可靠性需求。此外,磁盤可靠性會隨著磁盤的老化而變化。為了在存儲開銷和容錯之間提供有效的權衡,大型數據中心應該彈性調整編碼參數[6]。
(3)生成寬條帶。最近的工作探索了用于糾刪碼存儲的寬條帶,以抑制條帶中奇偶校驗塊的比例,從而實現極大的存儲節省[5]。為了有效地支持寬條帶,存儲系統可以為新寫入的數據部署具有適度低冗余的窄條帶,然后將老化的數據轉換為具有極低冗余度的寬條帶[8]。
本文將通過介紹一些典型和常用的自適應糾刪碼來展示當前自適應糾刪碼研究的現狀,并從評價這些碼的各項重要指標的角度比較和分析現有的自適應糾刪碼,指出當前存儲系統自適應糾刪碼研究中尚未解決的難題以及未來可能的研究方向。
1 基本概念
為了便于理解,通常將一個服務器稱為一個節點,下面對本文出現的相關概念給出如下說明。
a)數據塊:編碼的最小數據單元。通常,系統將用戶的原始數據劃分成k個數據塊。
b)校驗塊:指原始數據塊經過編碼運算得到的冗余塊,塊的大小與數據塊大小相同。
c)條帶:指多個數據塊與其對應的校驗塊所構成的塊集合。
d)輔助節點:指參與數據修復的可用節點。輔助節點讀取本地數據后通過網絡傳輸給其他節點來參與數據重建。
e)機架:若干個服務器和存儲設備的集合。數據服務器和同一機架中的存儲設備之間的訪問速度非常高,而機架間的訪問速度則較慢。
2 存儲系統中的糾刪碼
2.1 基礎糾刪碼
2.1.1 RS(Reed-Solomon)碼[9]
RS 碼可用兩個可配置的參數k和m構造,用RS(k,m)表示。RS(k,m)將k個數據塊作為輸入進行編碼,生成m個奇偶校驗塊,使得任意k+m個數據和奇偶校驗塊中的k個足以重建原始的k個數據塊。一起編碼的k+m個數據和奇偶校驗塊共同形成一個條帶。一個實際的存儲系統包含多個獨立編碼的條帶。它將k+m個塊的每個條帶分布在k+m個節點上,以容忍任何m個節點故障。圖1 給出了(k,m)=(4,2)的RS示例。

圖1 RS(4,2)示例圖
RS 碼的存儲開銷小,但其修復開銷高。修復任何一個故障塊,均需從其余k個可用節點中讀取k個塊,然后經過計算得到。它的通信開銷是故障塊大小的k倍。
2.1.2 HH(Hitchhiker)碼[10]
圖2 顯示了HH(6,3)碼的示例。在HH(k,m)碼中,每個條帶分為兩個子條帶(a={ai}和b={bi})。每個條帶中有k個數據塊和m個奇偶校驗塊,每個塊分別由a和b中的一個符號共同組成,因此每個子條帶中有k個數據符號和m個奇偶符號。編碼時,對同一子條帶的數據進行RS(k,m)編碼,得到RS 碼的奇偶符號。然后,將子條帶a中的k個數據符號分成m-1 個組,每個組中的數據符號經過按位異或得到組內的校驗符號。然后,將各個組中的校驗符號和子條帶b經過RS編碼得到的奇偶塊進行按位異或,以此得到子條帶b最終的校驗符號。

圖2 HH(6,3)示例圖
當有一個數據塊故障時,HH 碼可以運行快速解碼過程來恢復丟失的數據塊。請注意,子帶b中的一個奇偶校驗符號仍保留為RS 奇偶校驗符號。該符號僅足以恢復子條帶b中丟失的一個數據符號。假設子條a中的丟失符號在對應于奇偶校驗符號bk+i+1的組Gi中。在完整的子帶b的幫助下,可以計算組Gi的XOR 和。這意味著可以只讀取該組中的其他數據符號來恢復子條帶a中丟失的符號。整個過程只需要讀取k+k/(m-1)k個符號。當m>2 時,有k+k/(m-1)=km/(m-1) <k,這意味著與普通解碼過程相比,快速解碼過程可以減少網絡帶寬和磁盤I/O 的使用。
2.1.3 LRC(Locally Repairable Codes)碼[4]
LRC 可用3 個參數(k,l,g)構造,意味著有k個數據塊,l個本地奇偶校驗塊和g個全局奇偶校驗塊。一起編碼的k+l+g個數據/奇偶校驗塊的集合稱為條帶,大型存儲系統通常包含多個獨立編碼的條帶。
在LRC 中,LRC 將k個數據塊分成l個大小相等的組。它根據每組k/l數據塊計算XOR 和以形成l個本地奇偶校驗塊。它還從所有k個數據塊中計算g個全局奇偶校驗塊,計算方法同RS碼。設b是編碼成本地奇偶校驗塊的數據塊的數量,即b=k/l。我們將b個數據塊及其對應的本地奇偶校驗塊的集合稱為本地組。圖3 給出了(k,l,g)=(6,2,2)的LRC示例。

圖3 LRC(6,2,2)示例圖
在修復任何不可用的數據塊時,LRC 檢索同一本地組的其他可用塊,而不是k個塊,故LRC將通信開銷降為故障塊大小的b倍。
2.2 自適應糾刪碼
2.2.1 HACFS[7]
HACFS 使用來自同一碼系列的兩種不同糾刪碼。即,使用具有低恢復成本的快速碼和具有低存儲開銷的緊湊碼,如圖4(a)所示。它利用在Hadoop 工作負載中觀察到的數據訪問偏差來決定數據塊的初始編碼。在初始編碼之后,HACFS 系統通過使用兩種新穎的操作在快速碼和緊湊碼之間轉換數據塊來動態適應工作負載的變化。將最初用快速碼編碼的塊升級為緊湊碼,使HACFS 系統能夠減少存儲開銷。類似地,將數據塊從緊湊碼下編碼為快速碼,使HACFS 系統降低整體恢復成本。上碼和下碼操作非常有效,并且只在兩個碼之間轉換時更新相關的奇偶校驗塊。
2.2.2 HeART[11]
HeART利用異構級別的可靠性來權衡長期的存儲和恢復性能。HeART的基本思想是對高風險數據采用一種恢復速度快的碼,在低風險時期采用另一種存儲效率高的碼,如圖4(b)所示。

圖4 HACFS和HeART方法的基本框架
2.2.3 Repair-Scale[12]
Repair-Scale 考慮了兩組LRC 參數的變化,以響應工作負載的變化。具體來說,Repair-Scale考慮了兩種LRC 結構:①快速LRC,它存儲更多本地奇偶校驗塊以獲得更高的修復性能(例如,用于熱數據),以及②緊湊型LRC,它存儲更少的本地奇偶校驗塊以獲得更高的存儲效率(例如,對于冷數據)。快速和緊湊的LRC都存儲相同數量的數據塊和全局奇偶校驗塊。執行縮放操作以在快速LRC 和緊湊LRC 之間切換,以平衡訪問性能和存儲效率。從快速LRC縮放到緊湊LRC 稱為上編碼,從緊湊LRC 縮放到快速LRC 稱為下編碼。因此,將上行編碼成本和下行編碼成本定義為分別為上行編碼和下行編碼傳輸的跨集群網絡流量。
圖5 描繪了(k,l,g,c)=(12,6,2,20) 的快速LRC 和(k,l,g,c)=(12,2,2,16)的緊湊LRC 的上編碼和下編碼。這兩個碼都部署在分層數據放置下(即,每個塊都存儲在不同的集群中,參數c指機架數)。上編碼操作(從(12,6,2,20) 到(12,2,2,16))將L1和L2跨集群發送到L0以計算新的本地奇偶校驗塊L'0,并將L4和L5跨集群發送到L3計算一個新的本地奇偶校驗塊L'1。因此,上編碼成本為4。另外,下編碼操作(從(12,2,2,16)到(12,6,2,20))將D2和D3發送到另一個集群以計算L1,并且將D4和D5發送到另一個集群以計算L2。然后它將L1和L2發送到持有L'0的集群以計算L0。L3、L4和L5也是如此。總共,下編碼成本為12。

圖5 快速LRC(12,6,2,20)和緊湊LRC(12,2,2,16)的上下編碼示例
2.2.4 SRS[13]
SRS 碼建立在塊到節點映射的解耦之上,通過將RS 碼的k個數據塊存儲在k'個節點中,其中k≤k'。ERS 首先計算k和k'的最小公倍數LCM,即l=lcm(k,k'),并將一個對象劃分為l個數據塊。然后將l個數據塊排列成k個邏輯列,對每k個具有相同邏輯偏移量的數據塊進行編碼,計算出m個奇偶校驗塊。最后將l個數據塊分布在k'個節點上,使得每個節點恰好存儲l/k'個塊,并將奇偶校驗塊分布在m個節點上。請注意,對于l/k個條帶,奇偶校驗塊放在相同的m個節點上,而對于不同的條帶組,則將奇偶校驗塊放在不同的節點上,以平衡奇偶校驗更新的I/O 開銷。由于數據塊現在分布在k'個節點上,當對象從RS(k,m)轉換到RS(k',m)時,SRS 碼不需要數據塊重定位,如圖6所示。
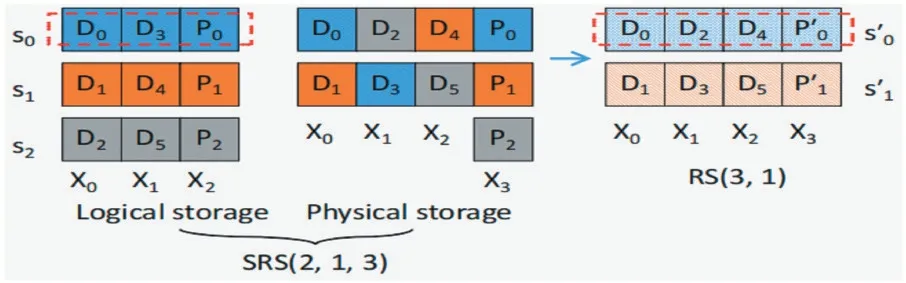
圖6 SRS(2,1,3)示例圖
2.2.5 ERS[14]
ERS 編碼與SRS 編碼在以下方面有所不同。首先,ERS 編碼在邏輯上將l個數據塊按行優先順序分配到k個節點中,因此引入了大量重疊數據塊用于冗余轉換(如圖7)。此外,ERS 編碼使用新穎的編碼矩陣對每k個數據塊進行編碼,并根據新穎的放置策略將l個數據塊物理分布在k'個節點上,以增加重疊數據塊的數量。因此,ERS 編碼只需要少量的非重疊數據塊,并且可以減少奇偶校驗塊更新的I/O。
圖7 顯示了按行優先順序放置的ERS(2,1,3)示例。由于k=2 和k'=3,我們可以推導出l=lcm(2,3)=6。首先將l=6 個數據塊順序排列成k=2 邏輯行主要順序的列。每k=2 個具有相同邏輯偏移量(即圖中相同顏色)的數據塊在邏輯存儲中被編碼為m=1個奇偶校驗塊。然后,l=6個數據塊在物理存儲中也以行優先順序在k'=3個節點上物理拉伸。可以看到,RS(3,1)的數據塊分布被保留了,因此在從RS(2,1)到RS(3,1)的轉換過程中消除了數據塊重定位。我們還可以證明P'0=P0+D2,并且P'1=P2+D3=P2+P1+D2。因此,只需要檢索D2來更新冗余轉換中的奇偶校驗塊。

圖7 ERS(2,1,3)示例圖
2.2.6 LRC-HH[15]
LRC-HH 自適應碼選擇兩類碼來應對訪問傾斜的情況。其中快速碼為LRC(k,m-1,m)碼,緊湊碼為HH(k,m)碼。當快速碼的編碼數據轉換為緊湊碼的形式時,可以將LRC 中的兩個條帶(a和b)視為HH 代碼中的條帶的兩個子條帶(sa和sb),因此LRC 中的所有塊都可以視為符號。所有數據符號都可以保留,a中的所有全局奇偶符號都可以保留為sa中的奇偶符號。在b中,第一個全局奇偶校驗符號可以保留為sb中的第一個奇偶校驗符號,但是sb中的其余奇偶校驗符號是b中的全局奇偶校驗符號與其對應的a中的數據符號組的異或和。為了計算和,不必讀取a中的所有數據符號。相反,a中的原始局部奇偶校驗符號正是應計算的部分和。因此,要計算sb中的奇偶校驗符號,只需讀取a中相應的局部奇偶校驗符號,并將其與b中的原始全局奇偶校驗符號進行異或。圖8 顯示了當k=6 和m=3時這種碼切換過程的示例。

圖8 從LRC(6,2,3)碼到HH(6,3)碼的轉換
當HH(k,m)編碼的數據轉換為LRC(k,m-1,m)形式時,可以將HH 代碼中的條帶的兩個子條帶(sa和sb)視為LRC 的兩個條帶(a和b)。類似地,所有數據符號都可以作為數據塊保留,sa中的所有奇偶校驗符號可以作為a中的全局奇偶校驗塊保留。所有的本地奇偶校驗塊都只能通過數據塊來計算,這部分計算是難以避免的。sb中的第一個奇偶校驗符號可以保留為b中的第一個全局奇偶校驗塊。在這個階段,b中的其余全局塊可以在沒有任何數據塊的參與的情況下計算出來。要計算b中的全局符號,只需將a中的相應局部奇偶校驗塊(剛剛計算)與sb中的原始奇偶校驗符號進行異或。圖9 顯示了當k=6 和m=3時此碼切換過程的示例。

圖9 從HH(6,3)碼到LRC(6,2,3)碼的轉換
2.2.7 EC-Fusion[16]
為了應對動態的工作負載,需要在混合糾刪碼之間進行碼轉換,這是EC-Fusion 的核心模塊。在構造RS(k,m)的基礎上,我們可以將奇偶校驗矩陣分解為幾個大小為m×m的子矩陣。然后校驗塊生成方程可以重寫為
由于RS 碼中奇偶校驗矩陣的任何m×m子矩陣都是可逆的,所以每個中間具有以下性質,
然后可以很容易地建立中間奇偶校驗和MSR 奇偶校驗之間的轉換。其中“Trans1”和“Trans2”可以推導出如下表達:
因此,中間校驗塊可以作為實現RS 和MSR之間高效轉換的橋梁。如圖10(a)所示,對于從MSR 碼到RS 碼的轉換,可以將原始奇偶校驗的k/m組轉換為中間奇偶校驗,然后將它們合并為最終的RS 奇偶校驗。
從RS 到MSR 的轉換可以看作是一個逆過程,其中一組原始RS 被劃分為最終的k/m組MSR。細節如圖10(b)所示,其中(k/m)-1 組數據乘以它們對應的子矩陣。這樣就可以通過所有現有的校驗位得到最后一組的中間校驗位,然后將所有中間校驗位轉化為最終的MSR碼。

圖10 MSR碼與RS碼之間的轉換
3 自適應糾刪碼的比較與分析
3.1 評價指標
我們使用碼的選擇、轉換效率以及擴展性作為自適應糾刪碼的評價指標。
3.2 比較與分析
3.2.1 碼的選擇
自適應碼HACFS,HeART,Repair-Scale,SRS 和ERS 都是同一碼族中的碼之間轉換,其轉換效率高。但是同碼族轉換,無法避免碼族的固有缺陷。比如RS 碼的解碼復雜度高,LRC碼的存儲開銷大等。而LRC-HH 和MSR-RS 是不同碼族中的碼間轉換,其能很好地避開各個碼的缺點。比如MSR 碼的編碼復雜度高,解碼復雜度低,而RS 碼正好相反,二者的結合可以很好地避免碼本身的限制。
3.2.2 轉換效率
自適應是一項重要的任務,主要是因為自適應過程經常導致數據塊重定位和奇偶塊更新,這兩種操作都會帶來大量的I/O 成本。具體來說,傳統的糾刪碼通常將塊映射到一組固定的節點,這樣,對象的數據塊數量就等于存儲對象數據的節點數量。如果自適應改變了數據塊的數量(即k),則需要將一些數據塊重新定位到不同的節點,從而產生額外的I/O。奇偶校驗塊的更新進一步加重了I/O:由于數據塊的布局發生了變化,奇偶校驗塊需要相應的更新附加I/O,包括檢索所有數據塊以重新計算新的奇偶校驗塊,以及將新計算的奇偶校驗塊寫入節點。現有的自適應糾刪碼都盡可能地避免了數據塊重定向,但是校驗塊更新導致的I/O 開銷和數據傳輸開銷依舊很大。
3.2.3 可擴展性
現有的自適應糾刪碼只能在固定的參數之間變化,靈活性不夠強,不能很好地適應時變的網絡環境和不斷變化的用戶需求。故,如何根據網絡環境,以及用戶需求,做對應的自適應操作將是自適應糾刪碼的重要研究方向。
4 結語
本文對目前自適應糾刪碼做了比較全面的總結。首先介紹了糾刪碼的基本概念,隨后介紹了基礎的糾刪碼,接著詳細介紹了現有主流的自適應糾刪碼。最后比較分析了這些糾刪碼的優缺點。我們認為,在當前自適應糾刪碼方法的研究中,進一步的研究重點主要包含兩個方面:①提高轉換效率。當前自適應碼的轉換效率較低,尤其體現在校驗塊的更新上,需要傳輸的數據塊較多,這加重了糾刪碼的帶寬開銷,容易引發網絡擁塞。故,有必要研究轉換效率更高的糾刪碼。②提高擴展性。網絡和用戶需求具有時變性,靈活的糾刪碼能夠更好地節省和權衡存儲開銷和通信開銷。因此,研究擴展更為靈活的糾刪碼具有重要意義。
猜你喜歡
ELLE世界時裝之苑(2024年5期)2024-05-14 16:00:39
中學生數理化·七年級數學人教版(2021年10期)2021-11-22 07:53:00
幼兒園(2021年6期)2021-07-28 07:42:14
小學生學習指導(低年級)(2019年11期)2019-11-25 07:31:48
散文詩(2017年17期)2018-01-31 02:34:20
小學生學習指導(低年級)(2018年3期)2018-01-31 02:19:05
小學生導刊(2017年13期)2017-06-15 20:29:38
哈爾濱師范大學自然科學學報(2015年1期)2015-04-19 06:55:26
天津科技大學學報(2015年4期)2015-04-16 04:55:11
科普童話·百科探秘(2014年5期)2015-03-09 09:07:41
