基于文獻計量的我國關聯數據研究現狀分析
2022-03-07 06:43:47賈婧怡
蘭臺內外 2022年4期


摘 要:對國內關聯數據領域文獻進行統計計量分析,主要是為掌握該領域的研究現狀、相關熱點和未來趨勢。運用Excel和SATI等軟件,對中國知網(CNKI)收錄的2010~2020年關聯數據的期刊文獻從年度發文分析、核心作者候選人及核心作者確認、來源期刊、研究熱點和研究趨勢等進行了分析,探討了當前圖情領域關聯數據的發展現狀和趨勢,目前研究重點為關聯數據的社會化應用方面,研究關注度日益增高,研究空間較大,值得廣大研究者關注。
關鍵詞:關聯數據;文獻計量;熱點分析
關聯數據(Linked data)的概念是互聯網之父Tim Berners-Lee在2006年的語義網項目會議上首次提出,他指出“關聯數據”是語義網的一種表現形式。其主要以HTTP URI方式表達和存取資源,并通過統一資源標識符來描述發布、共享以及連接互聯網,從而提供數據、信息和知識的方法。
圖情領域對于關聯數據的引入是2008年,Brooks,Terrence A在電子期刊發文,正式在圖情領域引入了Linked open data的概念;隨后在2009年Bradley在紙質期刊上發文并闡述了Linked data的相關內容;同年,國內圖情領域的學者姚小樂、劉煒等將關聯數據(Linked data)一詞正式引入國內,關聯數據研究在行業內開始風靡。
關聯數據在圖書館學、情報學、信息管理學等多個學科領域具有很大的應用和研究價值。本研究擬采用文獻計量方法,對我國在2010~2020年間關于關聯數據領域的相關文獻進行研究現狀、主要研究力量和熱點方面的分析,旨在對國內關聯數據領域的研究現狀做出總結,同時為相關的研究人員提供一些參考。
一、數據來源與分析方法
本文將運用文獻計量的方法,對國內關聯數據研究文獻進行分析,以中國知網(CNKI)的中國學術期刊網絡出版總庫中的相關文獻作為來源,以“主題”為檢索項,檢索式為:主題=“關聯數據”OR主題=“linked data”,檢索年限為2010~2020年,檢索時間為2021年1月1日。通過對檢索結果剔除重復和非相關文獻后得到有效文獻413篇。
二、我國圖情領域關聯數據研究現狀
1.年度發文分析
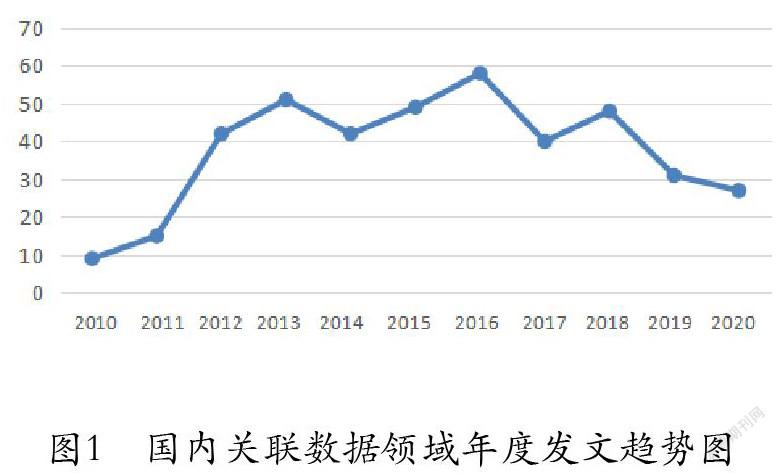
在一定程度上,發文的數量可以反映出某領域學術研究水平和發展速度,2010~2020年,國內共發論文413篇。國內關聯數據研究文獻主要以年為單位描述其在時間上的分布(如圖1所示),根據數據分析可知,2010~2020年國內關聯數據領域的研究大致上可以分為四個階段:
一是研究初始階段(2013年以前),從國內外對關聯數據的關注開始,關聯數據的概念從產生到引入圖情研究領域,與圖情領域的研究深入滲透,這一時期的發文量呈穩定增長態勢。
二是研究平穩階段(2013~2014年),這一時期相關研究進入平穩時期,主要原因可能是受資金、技術等因素的制約,此階段的文獻量出現停滯甚至倒退的情況。
三是研究爆發階段(2014~2016年),上一階段的制約增長因素取得突破,相關發文出現爆發增長的現象。
四是研究相對成熟階段(2016~2018年),此時期,發文量的增長率逐漸變小,其曲線也相對變得平緩,主要體現了文獻壽命長、文獻質量對后期研究發展貢獻大的特點。在2018年以后,該領域的發文量增長再次呈下降趨勢,停滯現象再現的同時,突破也在形成。
圖1 國內關聯數據領域年度發文趨勢圖
2.核心研究作者分析
(1)核心作者候選人的確定
作者發文量可揭示作者對該領域研究的持續性、深度及貢獻大小。核心作者候選人需要綜合考慮該作者的發文量以及文獻被引量,從而避免單一指標偏頗問題。因此,本文針對入選核心作者的標準為最低發文量和最低被引量。文中主要借鑒普賴斯定律來確定這兩個數值,符合兩個標準之一的作者就可以作為核心作者候選人。
在檢索得到的413篇關聯數據文獻中,一共有作者528名(包括第二、第三等合著作者),通過EXCEL軟件進行相關統計,根據普賴斯定律所提出的計算公式進行統計:
其中為該領域發文最多作者的論文數量,而M為該領域核心作者的最低發文量。為所有作者中累積被引頻次最大值,為高產作者累積被引頻次最小值。通過計算得出M的值約等于2.900,因此目前在國內關聯數據研究領域,發文量在3篇以上的作者可以入圍核心研究作者候選人,的值約等于20.621,所以在該領域文獻累積被引頻次在21次及以上的作者可入圍該領域的核心研究作者候選人。核心作者候選人需要滿足兩個條件中任意一個即可。在對上述滿足兩個標準之一的作者進行統計和人工查重之后,本文確定的我國關聯數據核心作者候選人共為123位。
(2)核心作者測評
對于某研究領域核心作者可通過綜合指數法確定,綜合指數法是一種以正負均值為基準,將每項指標折算指數后匯總為綜合指數,然后按照數值大小對該對象進行排序和評價的方法。它表達了不同計數單位的兩個或多個指標的綜合水平,值最大為最優,大者為佳。
發文指標指的是核心作者候選人的發文指數水平,發文平均數指的是左右核心作者候選人計算所得的平均發文量。本文中2010~2020年關聯數據領域中123位核心作者候選人共發文360篇,本文中,發文平均指數。
而被引指標指的是核心作者候選人所著文獻量被引指數,被引平均數指的是所有核心作者候選人文獻量的平均被引頻次,本文中2010~2020年關聯數據領域中的123位核心作者候選人發文被引頻次計算后可得為8766次,人均發文被引平均指數。
本文將引用鐘文娟學者用來測評核心作者的指標:發文量和被引量。發文量代表了作者對研究領域的重要性,被引頻次代表了作者的學術影響力,同時本文將發文量和被引頻次這兩項指標的權重比例設為0.5∶0.5。按照下文所述計算核心研究作者候選人的綜合指數:
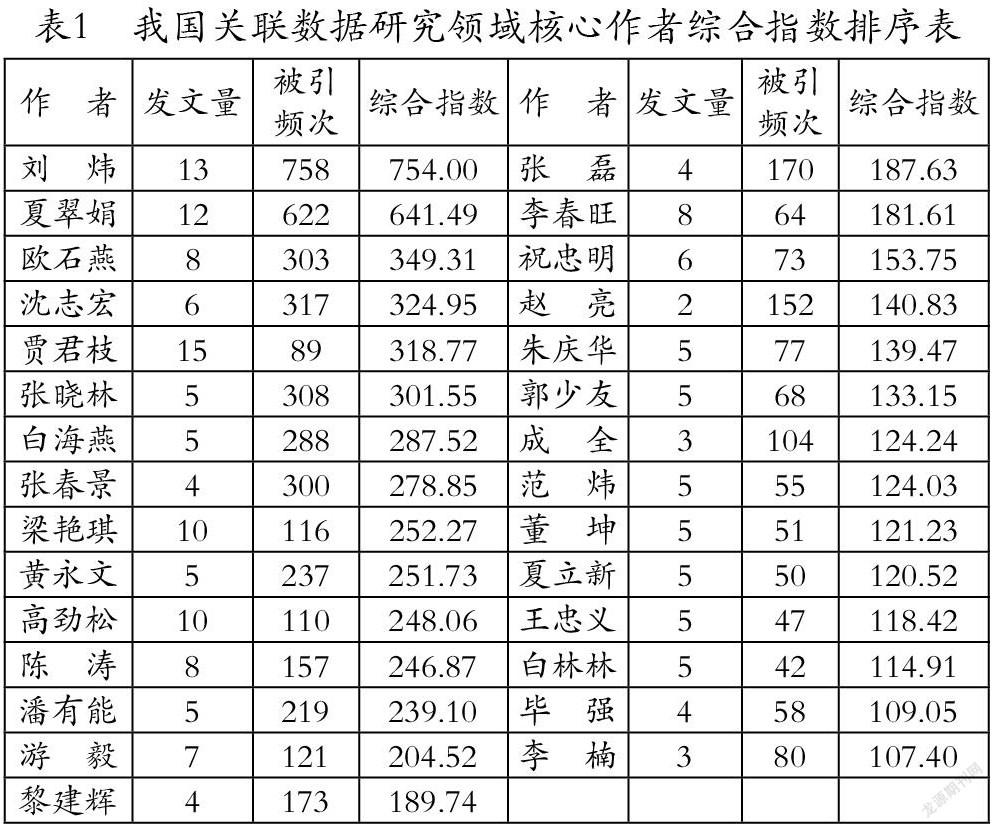
在上述公式中,指的是第i位作者的綜合指數,指第i位核心作者候選人的發文量,表示第i位候選人的被引頻次。運用綜合指數法對2010~2020年我國關聯數據方面的123位核心作者候選人的綜合學術水平值進行計算可得,綜合學術水平值≥100的候選人共有29個(如表1所示),這29位作者即為2010~2020年我國關聯數據研究領域的核心作者。其中,綜合指數位列第一的是劉煒,綜合指數約為754。根據普賴斯定律可得,當核心作者發文量占該領域總發文量的50%及以上時,便形成該領域的核心作者群。通過對相關數據的統計可得,關聯數據領域核心作者候選人共計發文221篇,占關聯數據領域相關發文數的53.51%,已經達到普賴斯定律的形成條件,因此我國關聯數據領域已形成相對較為穩定的核心作者群。
3.期刊貢獻度分析
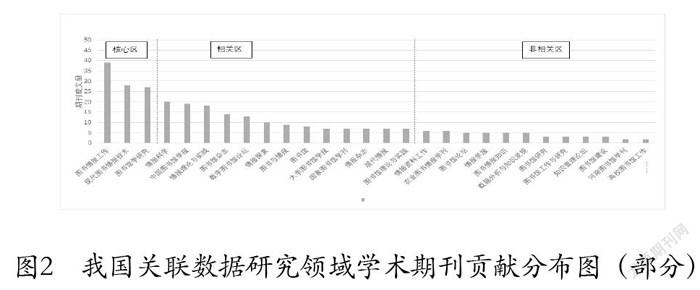
依據布拉德福定律可知,刊載某研究領域等量論文的期刊數量,如果按照遞減的順序進行排序,那么這些期刊區可以分為核心區、相關區和非相關區,其期刊數量關系是1:n:n2(n>1)。把關聯數據研究領域413篇相關論文所屬期刊進行統計去重后排序,可以得到刊載這些期刊的數量為65種,前16種期刊共計發文240篇,占關聯數據領域全部期刊發文量的58%。其中,圖書情報領域的期刊占絕大多數。《圖書情報工作》發文量最多,共計39篇。經過計算后發現,2010~2020年我國關聯數據研究領域核心區、相關區和非相關區的期刊數量都符合布拉德福定律。最終,確定核心區的期刊數量為3種,核心區該領域的相關論文刊載量為94篇,相關區期刊數量為13種,期刊的實際分布情況如圖2所示。
4.關鍵詞分析
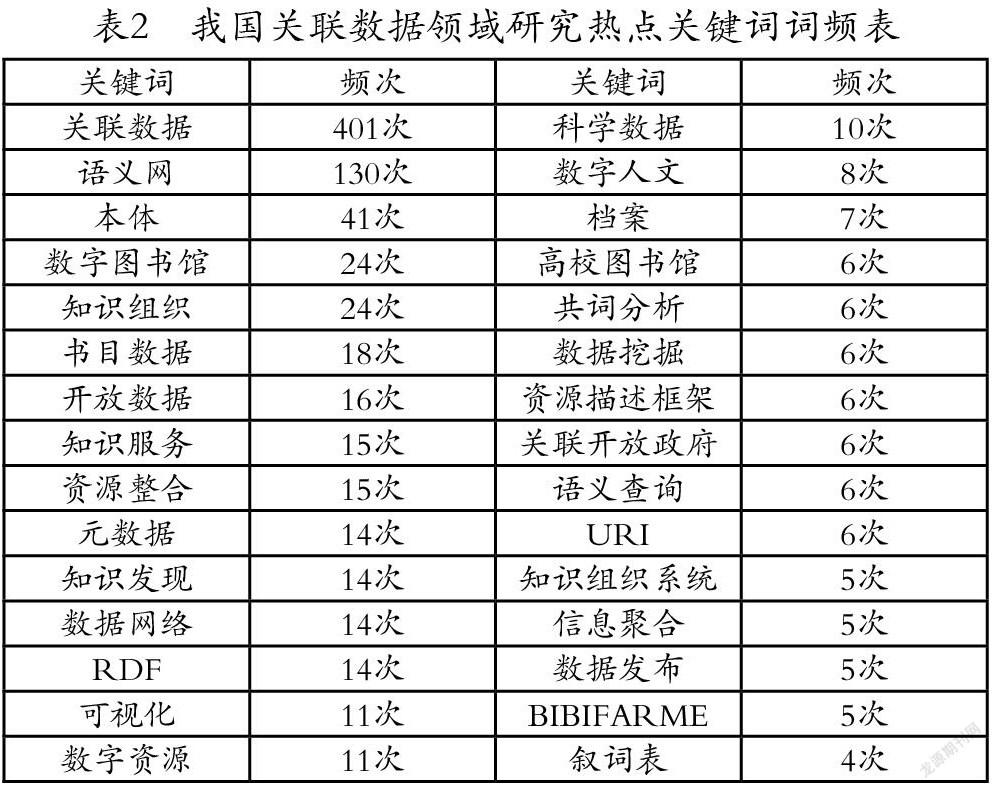
探究學科熱點比較常用的方法是對關鍵詞詞頻的統計,主要是對出現頻次較高的關鍵詞進行統計分析以確定某領域的研究熱點。本文通過SATI對關聯數據領域的735個關鍵詞進行統計分析,在人工合并同義、近義詞,刪除無實際意義的詞匯后,將關鍵詞按頻次降序排序(如表2所示)。
由該表可見,除“關聯數據”為中心詞外,“數字圖書館”“語義網”“本體”“書目數據”“數據網絡”“元數據”“知識組織”“開放數據”“知識服務”等關鍵詞出現的頻次較高,因此這些關鍵詞是關聯數據領域研究熱點。
經過內容分析發現國內關聯數據研究的主題大致可以歸納為3個方面。
(1)關聯數據領域的基礎理論研究
這些文獻主要對關聯數據的概念、基本原則、相關模型、具體應用和前景挑戰等方面進行研究。其主要探究了關聯數據的基本概念以及在國內外該技術的應用實現情況,逐步對信息生命周期各階段關聯數據角色定位展開研究。
(2)關聯數據的技術和工具研究
主要集中在對關聯書目信息處理技術、方法和工具方面。較多立足于關聯數據的描述、組織、存儲、轉化、發布、檢索等進行研究,從關聯數據的語義描述、組織、發布到檢索使用的工具,到解決關聯數據的管理、重用、共享和交互等方面的研究。目前,較多與數字人文領域交叉融合,對數字人文的相關項目進行關系數據的描述和處理。
(3)關聯數據的應用研究
在圖情領域(指圖書館、檔案館、博物館等)的資源與服務上,主要集中在數字圖書館、知識服務、數據挖掘以及數字人文領域。通過對信息資源的創建、組織和發布使用的技術或工具,來引導應用的發展。同時,涵蓋了網絡資源的管理和服務,如開放政府、門戶導航等。其他如名稱規范、語義出版和可視化領域,較為獨特的有機構評價、學者和學術關系發現、家譜等領域。這一類的研究已經拓展到地理學、經濟學、管理學、醫學等相關領域,社會化應用趨勢明顯。
參考文獻:
[1]TIM BERNERS LEE.Linked Data[EB/OL].[2020-01-05].http://www.w3.org/Design Issues/Linked Data.html.
[2]CHRISTIAN BIZER,TOM HEATH,TIM BERNERS LEE.Linking data:The Story So Far[J].In:IJSWIS,2009
[3]劉 煒.關聯數據:概念、技術及應用展望[J].大學圖書館學報,2011
[4]Brooks Terrence A.Watch this:LOD-linking open data[J].Information research-an international electronic journal,2008
[5]Bradley Fiona.Discovering linked data[J],Library Journal,2009
[6]Ed Summers,Antoine Isaac,Clay Redding,Dan Krech,姚小樂,劉 煒.LCSH,SKOS和關聯數據[J].現代圖書情報技術,2009
[7]丁學東.文獻計量學基礎[M].北京:北京大學出版社,1992
[8]鐘文娟.基于普賴斯定律與綜合指數法的核心作者測評——以《圖書館建設》為例[J].科技管理研究,2012
[9]李朝陽,龐弘燊.國內外圖情領域關聯數據研究比較分析[J].圖書館研究,2020
[10]孫玉琦,魏楊燁.我國關聯數據研究的文獻計量分析[J].情報探索,2016
[11]許見亮.基于文獻計量學的我國檔案專業核心期刊分析與評價[D].安徽大學,2007
[12]孫 浩.關于文獻計量服務的研究[J].現代情報,2008
[13]陳文愛,楊 璐,趙瑞剛.專題文獻的計量學研究方法[J].情報資料工作,2007
[14]王建芳,屈寶強,齊向華.我國文獻計量學近十年研究狀況[J].圖書情報工作,2003
[15]曹學艷,胡文靜.我國文獻計量學的發展[J].圖書情報工作,2004
(作者單位:西南大學計算機與信息科學學院)
作者簡介:賈婧怡(1996-),女,漢族,河南洛陽人,碩士研究生,研究方向:數字保存。
