基于特征金字塔網(wǎng)絡(luò)的超大尺寸圖像裂縫識(shí)別檢測(cè)方法
2022-03-02 14:32:14舒江鵬李俊馬亥波段元鋒趙唯堅(jiān)
土木建筑與環(huán)境工程 2022年3期
關(guān)鍵詞:深度學(xué)習(xí)
舒江鵬 李俊 馬亥波 段元鋒 趙唯堅(jiān)






摘 要:基于圖像分析的裂縫自動(dòng)檢測(cè)識(shí)別一直是橋梁結(jié)構(gòu)健康檢測(cè)的熱點(diǎn)問(wèn)題之一。深度學(xué)習(xí)作為裂縫檢測(cè)的重要解決方法,需要大量數(shù)據(jù)支持。公開(kāi)數(shù)據(jù)集提供的小尺寸裂縫圖像不足以解決超大尺寸細(xì)長(zhǎng)裂縫圖像的檢測(cè)問(wèn)題。提出一個(gè)基于特征金字塔深度學(xué)習(xí)網(wǎng)絡(luò)的超大尺寸圖像中細(xì)長(zhǎng)裂縫的檢測(cè)方法。通過(guò)對(duì)編碼器提取的4個(gè)不同層次的特征圖分別進(jìn)行預(yù)測(cè),網(wǎng)絡(luò)能夠?qū)崿F(xiàn)對(duì)細(xì)小裂縫的高精度分割。試驗(yàn)使用120張大小為3 264×4 928像素的橋鋼箱梁表面裂縫圖像對(duì)特征金字塔網(wǎng)絡(luò)進(jìn)行訓(xùn)練、測(cè)試;并將獲得的訓(xùn)練模型與通過(guò)雙線性插值方法縮放圖像至1 600×2 400像素和2 112×3 168像素兩種規(guī)格生成的數(shù)據(jù)集訓(xùn)練后的模型進(jìn)行對(duì)比。結(jié)果表明:該方法在對(duì)比測(cè)試中能夠獲得最高的裂縫檢測(cè)交并比(IoU)為0.78,最低的Dice Loss為0.12。測(cè)試中,裂縫檢測(cè)圖像顯示,縮放圖像會(huì)導(dǎo)致部分裂縫信息的丟失,該方法能穩(wěn)定地保留裂縫信息,并實(shí)現(xiàn)復(fù)雜背景下超大尺寸圖像中細(xì)長(zhǎng)裂縫的高精度自動(dòng)檢測(cè)。
關(guān)鍵詞:裂縫檢測(cè);深度學(xué)習(xí);超大尺寸圖像;特征金字塔網(wǎng)絡(luò)
中圖分類號(hào):U446.2?? 文獻(xiàn)標(biāo)志碼:A?? 文章編號(hào):2096-6717(2022)03-0029-08
收稿日期:2021-04-28
基金項(xiàng)目:國(guó)家自然科學(xué)基金(U1709216);國(guó)家重點(diǎn)研發(fā)計(jì)劃(2018YFE0125400)
作者簡(jiǎn)介:舒江鵬(1987- ),男,博士,研究員,主要從事結(jié)構(gòu)智能檢測(cè)和評(píng)估,E-mail:jpeshu@zju.edu.cn。
Received:2021-04-28
Foundation items:National Natural Science Foundation of China (No. U1709216); The National Key Research and Development Program of China (No. 2018YFE0125400)
Author brief:SHU Jiangpeng(1987- ), PhD, professor, main research interests: inspection and assessment of structures, E-mail: jpeshu@zju.edu.cn.
Crack detection method based on feature pyramid network for super large-scale images
SHU Jiangpenga,b, LI Juna,c, MA Haiboa, DUAN Yuanfenga, ZHAO Weijiana
(a. College of Civil Engineering and Architecture; b. Center for Balance Architecture; c. The Architectural Design & Research Institute of Zhejiang University Co., Ltd., Zhejiang University, Hangzhou 310058, P. R. China)
Abstract: Automatic crack detection based on image analysis is a hot issue in bridge structure health inspection. Crack segmentation based on deep learning is a significant solution, which needs lots of database. The small-scale crack images of open datasets are not sufficient for detection of long and thin cracks of super large-scale image. The study proposes an automatic crack detection method for super large-scale images, based on feature pyramid network. Through four different feature maps in various sizes, the proposed network yields predictions, respectively, which means a highly precise crack segmentation. Experiments are carried on 120 steel box girder crack images in a resolution of 3 264 pixels×4 928 pixels. These images are used to train and test the network. The comparison study is conducted between the proposed method and the models trained with crack images resized into 1 600 pixels×2 400 pixels and 2 112 pixels×3 168 pixels with bilinear interpolation algorithm. The results show that our method can achieve the highest crack Intersection over Union (IoU) of 0.78, and the lowest Dice Loss of 0.12 in the comparison study. The predictions of crack images in testing indicate that resizing images sometimes result in the loss of crack information, and our method can maintain the detail of cracks and detect cracks of super large-scale images automatically and precisely.
Keywords: crack detection; deep learning; super large-scale images; feature pyramid network
裂縫作為橋梁早期損傷破壞的重要表征之一,及時(shí)發(fā)現(xiàn)并對(duì)其進(jìn)行檢測(cè)是橋梁維護(hù)工作中的重點(diǎn)[1]。常規(guī)的人工勘測(cè)不僅存在檢查盲區(qū),同時(shí)也需要耗費(fèi)大量的人力物力,有時(shí)還存在安全隱患。隨著攝影、遙感、無(wú)人機(jī)等圖像采集技術(shù)的快速發(fā)展,基于數(shù)字圖像處理技術(shù)的裂縫檢測(cè)方法得到廣泛關(guān)注[2]。通過(guò)使用模糊多級(jí)中值濾波[3]、灰度矯正[4]、非下采樣輪廓波變換[5]等數(shù)字圖像處理技術(shù)去除裂縫圖像上的噪聲并優(yōu)化圖像質(zhì)量,裂縫的幾何特征和尺寸信息能夠被提取出來(lái)。在面對(duì)復(fù)雜光照、背景等外界因素時(shí),傳統(tǒng)的數(shù)字圖像處理技術(shù)不能很好地消除干擾。張維峰等[6]綜合應(yīng)用了不同圖像處理算法開(kāi)發(fā)的適用于橋梁缺陷較遠(yuǎn)距離圖像的檢測(cè)分析軟件,在面對(duì)細(xì)小裂縫的檢測(cè)時(shí)也遇到了瓶頸。
隨著計(jì)算機(jī)領(lǐng)域深度學(xué)習(xí)的興起,橋梁裂縫圖像處理迎來(lái)了新的機(jī)遇和挑戰(zhàn)。眾多學(xué)者從實(shí)際情況出發(fā),對(duì)數(shù)據(jù)方法、智能算法進(jìn)行改進(jìn),提高了模型的分析能力,推動(dòng)了人工智能在橋梁檢測(cè)應(yīng)用中的提高[7]。比如,Zhang等[8]將深度卷積神經(jīng)網(wǎng)絡(luò)(Deep Convolutional Neural Network,DCNN)應(yīng)用到裂縫信息提取研究中,該算法展現(xiàn)出了比傳統(tǒng)方法更高的準(zhǔn)確度。Zhang等[9]提出網(wǎng)絡(luò)CrackNet,能夠?qū)崿F(xiàn)裂縫的自動(dòng)檢測(cè)提取。數(shù)據(jù)集作為數(shù)據(jù)驅(qū)動(dòng)型深度學(xué)習(xí)算法的核心組成部分,也得到了廣泛的關(guān)注。服務(wù)于像素級(jí)別下橋梁裂縫檢測(cè)任務(wù)的公開(kāi)數(shù)據(jù)集[10]包含了超過(guò)一萬(wàn)張的裂縫圖像樣本,但這些圖像的尺寸都只有256×256像素。包括其他的公開(kāi)數(shù)據(jù)集[11],服務(wù)于裂縫檢測(cè)任務(wù)的裂縫圖像尺寸不超過(guò)500×500像素。在工程應(yīng)用中,使用高清相機(jī)或者無(wú)人機(jī)拍攝的圖像一般都會(huì)超過(guò)1 920×1 080(1 080 p)。一般認(rèn)為,4k UHD(3 840×2 160)作為新的工業(yè)標(biāo)準(zhǔn),視為高分辨率(High-Resolution);而超過(guò)這一尺寸則為超大尺寸,或者是超高分辨率(Very High-Resolution)[12]。一些超大尺寸的裂縫圖像甚至?xí)^(guò)4 096×3 112[13]。另外,這些公開(kāi)數(shù)據(jù)集中的圖像一般都是經(jīng)過(guò)挑選的小尺寸、裂縫特征明顯的圖像。在實(shí)際工程應(yīng)用中,高清相機(jī)拍攝獲取的裂縫圖像中的裂縫尺寸遠(yuǎn)小于公開(kāi)數(shù)據(jù)集或者試驗(yàn)條件下拍攝的裂縫。
由Lin等[14]首次提出的金字塔型深度學(xué)習(xí)網(wǎng)絡(luò)(FPN)表現(xiàn)出了強(qiáng)大的圖像分割能力,并贏得了COCO 2016挑戰(zhàn)。其網(wǎng)絡(luò)結(jié)構(gòu)突出體現(xiàn)了對(duì)小目標(biāo)檢測(cè)的優(yōu)勢(shì)。受Lin等工作的啟發(fā),筆者提出一個(gè)基于特征金字塔深度學(xué)習(xí)網(wǎng)絡(luò)針對(duì)超大尺寸裂縫圖像的細(xì)長(zhǎng)裂縫檢測(cè)方法。在金字塔型的網(wǎng)絡(luò)架構(gòu)下,采用特征提取效率更高的Se_resnext50_32×4d[15]編碼器,區(qū)別于傳統(tǒng)的圖像分割網(wǎng)絡(luò),將編碼器提取的不同層次(共4個(gè))特征圖分別進(jìn)行預(yù)測(cè),不同分辨率的特征圖得以保留。對(duì)于細(xì)小裂縫,更大分辨率的特征圖能夠提供更精確的裂縫幾何特征,同時(shí),較小分辨率的特征圖提供了更深層的語(yǔ)義信息,能夠優(yōu)化細(xì)小目標(biāo)的預(yù)測(cè)。不同尺寸裂縫特征圖最后通過(guò)一包含3×3卷積層的W運(yùn)算進(jìn)行疊加輸出統(tǒng)一尺寸的預(yù)測(cè),避免產(chǎn)生混疊效應(yīng)。
該方法包括使用超大尺寸圖像的數(shù)據(jù)集構(gòu)建方法。針對(duì)細(xì)長(zhǎng)裂縫的檢測(cè)特征,創(chuàng)新性利用特征金字塔深度學(xué)習(xí)網(wǎng)絡(luò)具備的多層識(shí)別能力以及識(shí)別小目標(biāo)的優(yōu)勢(shì),通過(guò)充分利用裂縫長(zhǎng)細(xì)幾何特征,實(shí)現(xiàn)了對(duì)超大尺寸裂縫圖像進(jìn)行像素級(jí)的裂縫檢測(cè)。
1 數(shù)據(jù)集構(gòu)建方法
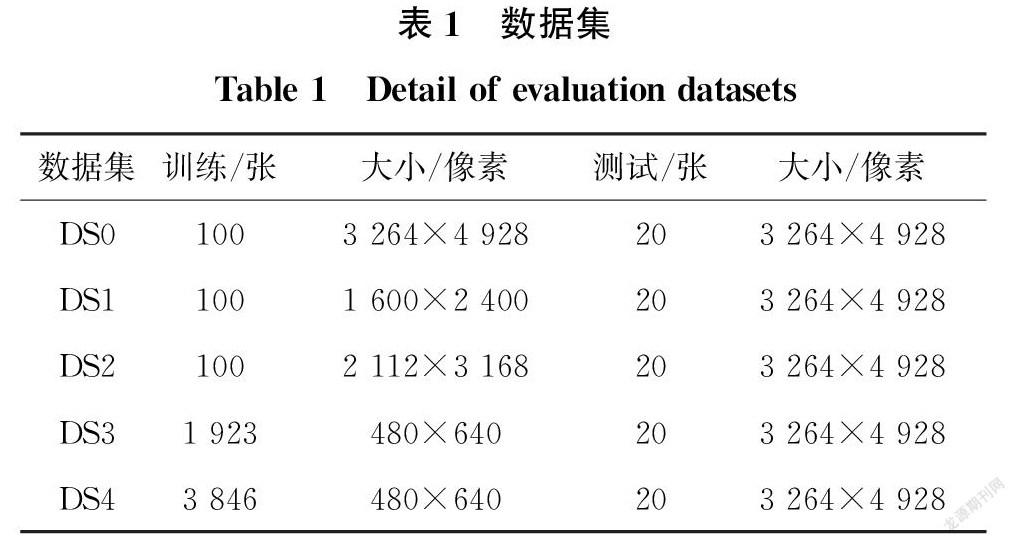
數(shù)據(jù)集是基于深度學(xué)習(xí)的裂縫自動(dòng)檢測(cè)方法的核心之一。為了充分獲取裂縫細(xì)長(zhǎng)的幾何特征以及發(fā)揮深度學(xué)習(xí)網(wǎng)絡(luò)的特征提取能力,提出針對(duì)超大尺寸細(xì)長(zhǎng)裂縫圖像的數(shù)據(jù)集構(gòu)建方法。該數(shù)據(jù)集的構(gòu)建方法包括兩個(gè)關(guān)鍵部分:訓(xùn)練集與測(cè)試集。下文中將分別對(duì)訓(xùn)練集和測(cè)試集的處理、生成和構(gòu)建方法做詳細(xì)介紹。同時(shí),來(lái)自International Project Competition for SHM (IPC-SHM 2020) ANCRiSST[13]的鋼箱梁數(shù)據(jù)集將按提出的數(shù)據(jù)集構(gòu)建方法進(jìn)行處理,以生成后續(xù)試驗(yàn)用的數(shù)據(jù)集。
該鋼箱梁數(shù)據(jù)集中包含120張高清相機(jī)拍攝的鋼箱梁表面細(xì)長(zhǎng)裂縫圖像,這些圖像為三通道RGB圖像,像素為3 264×4 928大小。除這些裂縫圖像外,數(shù)據(jù)集內(nèi)還包含每張裂縫圖像相對(duì)應(yīng)的標(biāo)記圖(label)。標(biāo)記圖由土木工程領(lǐng)域內(nèi)專家對(duì)裂縫圖像中的每一像素點(diǎn)進(jìn)行標(biāo)注分類生成,例如將裂縫像素標(biāo)注為1,背景像素標(biāo)注為0進(jìn)行像素級(jí)別的區(qū)分。
在進(jìn)行處理前,鋼箱梁數(shù)據(jù)集中的120張圖像首先被隨機(jī)分出100張作為初始訓(xùn)練集,其余20張為初始測(cè)試集,命名為DS0。
將超大尺寸的圖像直接放入網(wǎng)絡(luò)中通常需要超大的計(jì)算機(jī)GPU運(yùn)算空間。考慮到計(jì)算機(jī)性能的限制,較為簡(jiǎn)單直接的方法便是縮小圖像尺寸,減小運(yùn)算空間。傳統(tǒng)是使用方法的雙線性插值方法是在保證一定質(zhì)量條件下對(duì)圖像進(jìn)行縮放。
為了與數(shù)據(jù)集構(gòu)建方法相對(duì)比,試驗(yàn)中通過(guò)傳統(tǒng)的雙線性插值對(duì)圖像進(jìn)行縮放處理,構(gòu)建了兩個(gè)數(shù)據(jù)集。將原來(lái)的高分辨率圖像降采樣為1 600×2 400像素和2 112×3 168像素兩種規(guī)格。為討論方便,將圖像大小調(diào)整為1 600×2 400像素的訓(xùn)練集命名為DS1,將圖像大小調(diào)整為2 112×3 168像素的訓(xùn)練集命名為DS2,其具體參數(shù)見(jiàn)表1。對(duì)于驗(yàn)證及測(cè)試過(guò)程,仍然以原規(guī)格圖像作為驗(yàn)證和測(cè)試對(duì)象,但為了和訓(xùn)練過(guò)程相匹配,測(cè)試的裂縫圖像均根據(jù)雙線性插值方法調(diào)整為1 600×2 400像素和2 112×3 168像素大小。模型輸出預(yù)測(cè)結(jié)果(1 600×2 400像素和2 112×3 168像素)后,再利用雙線性插值恢復(fù)為3 264×4 928像素,與標(biāo)注圖像進(jìn)行比較。
由于細(xì)小裂縫占裂縫背景極少,雙線性插值縮放之后,圖像中裂縫像素急劇減小,預(yù)測(cè)難度增加,預(yù)測(cè)準(zhǔn)確度降低。考慮到部分裂縫即可提供足夠信息進(jìn)行識(shí)別,即可以拆分的幾何特性與特征金字塔網(wǎng)絡(luò)對(duì)小目標(biāo)識(shí)別的優(yōu)勢(shì),相應(yīng)地提出了針對(duì)超大尺寸裂縫圖像通用的訓(xùn)練集和測(cè)試集處理方法。
1.1 訓(xùn)練集
針對(duì)實(shí)際工程拍攝中裂縫在圖像中分布不確定、長(zhǎng)細(xì)比例較大、裂縫像素占整體像素比例較低的特點(diǎn),采用多個(gè)步驟對(duì)超大尺寸圖像進(jìn)行處理,以構(gòu)建訓(xùn)練集。
步驟1:獲得一張初始的超大尺寸裂縫圖像(假設(shè)其大小為h×w,其中,h為圖像的高、w為圖像的寬),選取一大小為32m×32n(m、n為大于1的整數(shù))的固定拆分尺寸。該拆分尺寸的取值主要取決于計(jì)算資源。將初始圖像以數(shù)值0進(jìn)行邊緣擴(kuò)增(Padding),將圖像統(tǒng)一為尺寸32m×32n的倍數(shù)。擴(kuò)增后的圖像大小為H×W。H、W的計(jì)算式為
H=h32m+132m(1)
W=w32n+132n(2)
步驟2:使用一個(gè)大小為32m×32n的滑窗,以行、列步長(zhǎng)為16m、16n像素大小對(duì)擴(kuò)充后的圖像進(jìn)行拆分。
步驟3:保留所有k張帶裂縫的拆分圖像,同時(shí),為保證深度學(xué)習(xí)能夠充分獲得背景特征,學(xué)習(xí)背景信息;k張只包含背景的圖像也被隨機(jī)選取,進(jìn)入最終的訓(xùn)練集。最后,一張初始的超大尺寸裂縫圖像經(jīng)過(guò)上述操作共可生成2k張的32m×32n拆分子圖進(jìn)入深度學(xué)習(xí)訓(xùn)練集。對(duì)多張超大尺寸裂縫圖像進(jìn)行該構(gòu)建操作便可構(gòu)建出相應(yīng)的訓(xùn)練集。
對(duì)于試驗(yàn)用鋼箱梁數(shù)據(jù)集,考慮計(jì)算機(jī)的計(jì)算性能,選取m=15、n=20。首先將尺寸為3 264×4 928的圖像(如圖 1(a))填充為3 360×5 120,并置零,保證后續(xù)拆分時(shí)能夠覆蓋到圖像的邊緣,見(jiàn)圖1(b),根據(jù)重疊分割的步驟2,設(shè)定滑窗大小為480×640對(duì)圖像以行/列240、320像素的步長(zhǎng),得到拆分子圖,如圖1(c)所示。一些將子圖像包含0填充部分。利用所有的子圖像作為輸入需要大量的訓(xùn)練時(shí)間。因此,根據(jù)對(duì)應(yīng)的子標(biāo)簽,自動(dòng)篩選出包含裂紋損傷像素的1 923個(gè)子圖像,如圖2(a)所示,即k=1 923。這1 923張裂縫子圖像組成了一個(gè)訓(xùn)練集,命名為DS3,作為缺少背景圖像信息的數(shù)據(jù)集,與本方法進(jìn)行對(duì)比。其余的13 939個(gè)子圖像不包含屬于裂紋損傷的像素,
只表示背景信息,如圖2(b)所示。在13 939個(gè)子圖像中隨機(jī)選取1 923張子圖像。1 923張裂縫子圖像和1 923張背景子圖像構(gòu)成一個(gè)訓(xùn)練集,命名為DS4,見(jiàn)表1,即為本方法提出的數(shù)據(jù)集構(gòu)建方法的最終結(jié)果。
1.2 測(cè)試集
在圖像測(cè)試方法上,同樣針對(duì)細(xì)長(zhǎng)裂縫的位置和幾何特征提出了新的超大尺寸細(xì)長(zhǎng)裂縫圖像的測(cè)試處理方法。該方法包含3個(gè)步驟:
1)輸入測(cè)試圖像(假設(shè)為h×w),將圖像以0進(jìn)行擴(kuò)增,不同于訓(xùn)練集,為了保證邊緣像素能夠被后續(xù)拆分覆蓋,擴(kuò)增后尺寸H×W的計(jì)算式為
H=h32m+232m(3)
W=w32n+232n(4)
式中:m、n的取值同訓(xùn)練集中的取值。
2)使用32m×32n的滑窗以行、列步長(zhǎng)為32m、32n對(duì)測(cè)試圖像進(jìn)行第1次拆分,隨后將分割起點(diǎn)定位于圖內(nèi)的第16m行、第16n列像素,進(jìn)行第2次拆分。通過(guò)此方法,第1次拆分的4張相鄰圖像交點(diǎn)將成為第2次分割圖像的中心。針對(duì)裂縫的位置不確定性對(duì)分割圖像邊緣進(jìn)行多次覆蓋。將步驟2生成的一系列拆分圖一同輸入經(jīng)訓(xùn)練集訓(xùn)練后的特征金字塔深度學(xué)習(xí)網(wǎng)絡(luò),獲得預(yù)測(cè)結(jié)果。
3)最后將該預(yù)測(cè)結(jié)果按照滑窗順序重新拼裝成為帶0增的圖像。去除0增區(qū)域后,便獲得與原測(cè)試圖像大小相同的裂縫預(yù)測(cè)圖。同時(shí),由于預(yù)測(cè)圖中的每一個(gè)像素經(jīng)過(guò)二次分割擁有兩個(gè)預(yù)測(cè)值。本方法從較為安全的角度設(shè)定其中只要有一個(gè)預(yù)測(cè)判斷該像素為裂縫,該像素即可認(rèn)為為裂縫像素,保證盡可能多的裂縫像素被檢測(cè)識(shí)別。
在測(cè)試試驗(yàn)中,m、n的取值同訓(xùn)練中的取值,分別為15、20。其余處理按上述3個(gè)步驟進(jìn)行,與訓(xùn)練集雖然稍有差別,但較為相似。
2 特征金字塔深度學(xué)習(xí)網(wǎng)絡(luò)
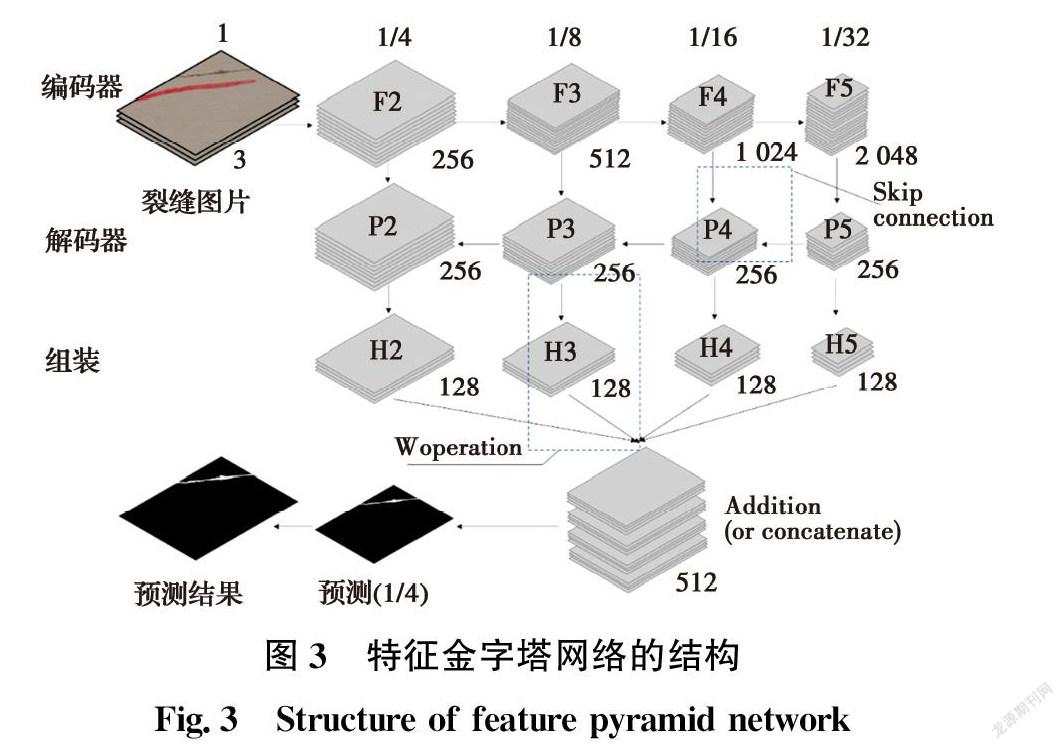
特征金字塔網(wǎng)絡(luò)(Feature Pyramid Network)的結(jié)構(gòu)大致可以分為編碼器(Encoder)、解碼器(Decoder)和組裝(Assembling)3個(gè)部分,如圖3所示。編碼器是卷積神經(jīng)網(wǎng)絡(luò)的前饋過(guò)程,用來(lái)提取不同階段的特征,并不斷降低特征圖分辨率。解碼器是自下而上的特征圖放大過(guò)程。通過(guò)上采樣,頂層特征圖和底層特征圖實(shí)現(xiàn)合并,豐富網(wǎng)絡(luò)獲取的語(yǔ)義信息。在融合完成后,網(wǎng)絡(luò)使用了3×3的卷積核對(duì)每一個(gè)融合結(jié)果并進(jìn)行卷積,目的是消除上采樣中的混疊效應(yīng)(Aliasing Effect)。最后,在組裝部分添加各個(gè)階段的特征圖獲取各層信息,這使得特征金字塔網(wǎng)絡(luò)擁有較強(qiáng)的語(yǔ)義信息獲取能力,同時(shí)也能夠滿足速度和內(nèi)存的要求。特征金字塔網(wǎng)絡(luò)的特別之處在于預(yù)測(cè)是在不同的特征層中獨(dú)立進(jìn)行的,有助于檢測(cè)不同尺寸的裂縫目標(biāo),契合工程獲取裂縫圖像中裂縫大小不確定性的特點(diǎn)。
2.1 編碼器
編碼器是一個(gè)特征提取網(wǎng)絡(luò),一般采用VGG[16]和ResNet[17]作為骨干。在本方法中,為了提高對(duì)裂縫的特征提取效果,采用Se_ResNeXt50_32×4d[15]為編碼器。它包括3個(gè)部分:ResNet,SE(Squeeze-and-Excitation)模塊和X模塊,使網(wǎng)絡(luò)更加深入、更快收斂和更易優(yōu)化。同時(shí),該模型的參數(shù)少,復(fù)雜度低,適合裂縫檢測(cè)任務(wù)。SE模塊采用的是SENet[15]的一個(gè)計(jì)算單元。
壓縮(Squeeze)采用了一個(gè)全局平均池化層,獲取具有全局視野的特征圖。激勵(lì)(Excitation)利用了一個(gè)全連接的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)對(duì)壓縮后的結(jié)果進(jìn)行非線性變換,然后將其作為一個(gè)權(quán)重乘以輸入特征。SENet主要對(duì)通道之間的相關(guān)性進(jìn)行學(xué)習(xí),減弱了對(duì)通道本身的關(guān)注,雖然稍微增加了計(jì)算量,但能夠?qū)崿F(xiàn)更好的分割效果。X模塊來(lái)自ResNeXt[18],一個(gè)更優(yōu)版本的ResNet。ResNeXt的核心創(chuàng)新在于采用了聚合轉(zhuǎn)換(Aggregated Transformations),用相同拓?fù)浣Y(jié)構(gòu)的并行堆疊取代原始的ResNet的3層卷積塊,提高了模型的準(zhǔn)確度,而不顯著增加參數(shù)量。同時(shí),由于拓?fù)浣Y(jié)構(gòu)相同,超參數(shù)減少,模型也較原始的ResNet更易移植。ResNeXt50_32×4d從有50層網(wǎng)絡(luò)深度的ResNet50改進(jìn)而來(lái)。其中,32×4d代表的是32條路徑,每條路徑的通道數(shù)為4個(gè)。SE模塊嵌入到ReNext50_32×4d中,最終獲得Se_resnext50_32×4d。其預(yù)訓(xùn)練參數(shù)通過(guò)imagenet1000得到。
總的來(lái)說(shuō),編碼器是一個(gè)以Se_resnext50_32×4d為骨干的自下而上裂縫特征提取網(wǎng)絡(luò)。在編碼器入口,將大小為裂縫圖像輸入(32m×32n)。后續(xù)中,每一個(gè)階段便是特征金字塔的一個(gè)層次。選取conv2、conv3、conv4和conv5層提取的特征為{C2, C3, C4, C5},這是FPN網(wǎng)絡(luò)的4個(gè)層次。N是batch size,特征向量則分別為F2=(N, 256, 8m, 8n),F(xiàn)3=(N, 512, 4m, 4n),F(xiàn)4=(N,1 024, 2m, 2n),F(xiàn)5=(N, 2048, m, n)。需要注意的是,由于F5是原圖的1/32大小,所以,拆分滑窗的長(zhǎng)度和寬度應(yīng)是32的倍數(shù)。
2.2 解碼器
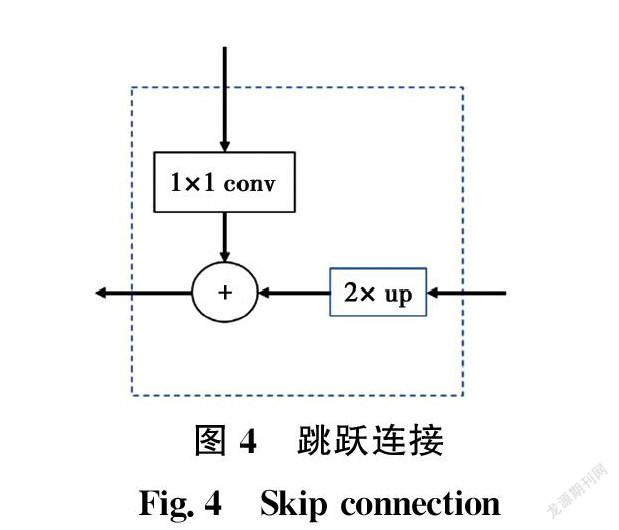
解碼器是一個(gè)自上而下的放大裂縫特征圖的過(guò)程。P5=(N,256,m,n)是通過(guò)1×1卷積層直接從F5得到的。在接下來(lái)的操作中,通過(guò)插值算法將P5放大兩倍為(N,256,2m,2n)。F4經(jīng)過(guò)1×1卷積層,變成(N,256,2m,2n)。將上述兩個(gè)特征向量相加,得到P4=(N,256,2m,2n)。這些操作被稱為跳躍連接(Skip Connection),如圖4所示,繼續(xù)使用這些操作來(lái)獲取P4、P3和P2。跳躍連接的優(yōu)勢(shì)在于它既可以利用頂層的高級(jí)語(yǔ)義特征(有助于裂縫特征分類),又可以利用底層的高分辨率信息(有助于裂縫特征定位)。
2.3 組裝
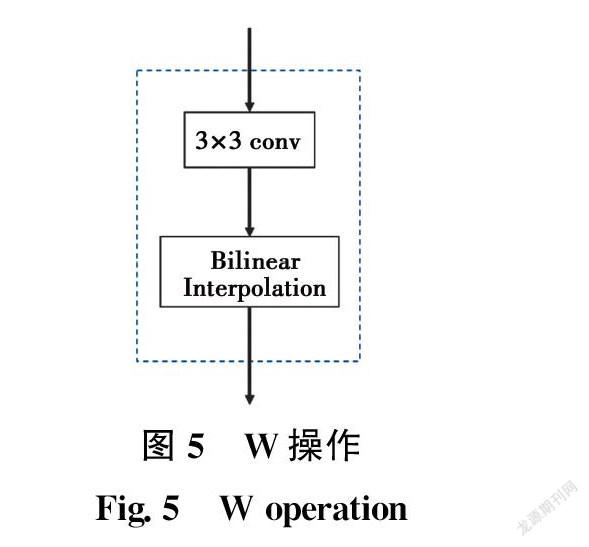
組裝部分要求金字塔每一層輸出的特征圖具有相同尺寸大小,為了實(shí)現(xiàn)該目的,首先選擇包含3×3卷積層的W運(yùn)算,采用雙線性插值放大,如圖5所示。
P5執(zhí)行3次W操作后,H5=(N,128,8m,8n)。以此類推,H4和H3分別進(jìn)行兩次和一次W操作。此外,H2不需要放大。然后直接將Hi(i=2~5)相加,得到一個(gè)向量(N,256,8m,8n)。該向量經(jīng)過(guò)3×3的卷積層和雙線性插值放大到原始裂紋圖像尺寸(N,1,32m,32n)。為了便于預(yù)測(cè)過(guò)程,通過(guò)將激活函數(shù)sigmoid的值改為0~1得到掩碼(N,1,480,640)。如果某點(diǎn)的值大于某一固定閾值,則預(yù)測(cè)該點(diǎn)為裂紋。在試驗(yàn)中,選擇0.5作為閾值。
3 試驗(yàn)
3.1 試驗(yàn)細(xì)節(jié)
所有試驗(yàn)均在Intel(R) Xeon(R) E5-2678 v3 @ 2.50 GHz、64.0 GB RAM和NVIDIA RTX2080TI、11.0 GB RAM的計(jì)算平臺(tái)上進(jìn)行。基于4個(gè)不同的訓(xùn)練集訓(xùn)練了4個(gè)基于特征金字塔網(wǎng)絡(luò)結(jié)構(gòu)的預(yù)測(cè)模型。為了討論方便,用DS1和DS2訓(xùn)練獲得的特征金字塔網(wǎng)絡(luò)稱為Model1和Model2,用DS3和DS4訓(xùn)練獲得的網(wǎng)絡(luò)稱為Model3和Model4。
3.2 試驗(yàn)指標(biāo)
假設(shè)在標(biāo)簽和預(yù)測(cè)中均屬于裂縫的像素?cái)?shù)為I,在標(biāo)簽或預(yù)測(cè)中表示裂縫的像素?cái)?shù)為U,交并比(Intersection over Union IoU)是圖像分割任務(wù)常用的評(píng)價(jià)指標(biāo),通過(guò)式(5)計(jì)算。
IoU=IU(5)
另一評(píng)價(jià)指標(biāo)Dice Loss不僅可以作為深度學(xué)習(xí)訓(xùn)練中的損失函數(shù),也可以在一定程度上評(píng)價(jià)圖像分割的準(zhǔn)確度。假設(shè)在裂紋分割任務(wù)中X為圖像對(duì)應(yīng)的標(biāo)記,Y是裂縫預(yù)測(cè),Dice Loss通過(guò)式(6)計(jì)算。
Dice Loss=1-2|X∩Y||X|+|Y|(6)
4 結(jié)果和討論
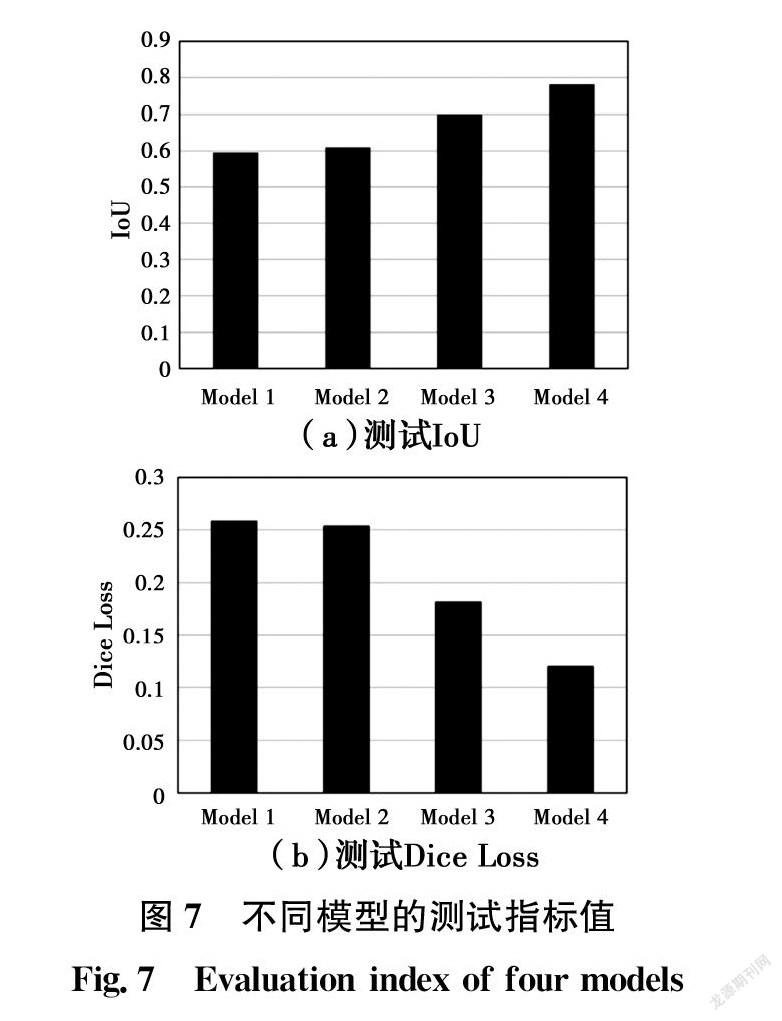
圖6為4個(gè)模型在一些典型測(cè)試圖像上的裂縫檢測(cè)結(jié)果,圖7為基于4個(gè)不同訓(xùn)練集測(cè)試中的評(píng)價(jià)指標(biāo)IoU和Dice Loss的對(duì)比。圖6中展示的IoU值通過(guò)單張預(yù)測(cè)圖片與對(duì)應(yīng)標(biāo)記計(jì)算得到,圖7中展示的IoU和Dice Loss測(cè)試指標(biāo)值為測(cè)試中所有圖片的預(yù)測(cè)同對(duì)應(yīng)標(biāo)記計(jì)算獲得的平均IoU和Dice Loss的值。從圖7可以看出,在IoU和Dice Loss方面,在測(cè)試圖像上,Model2比Model1出性能更好,Model2的IoU高于Model1,同時(shí)Model2的Dice Loss小于Model1。在分析了Model1和Model2的預(yù)測(cè)之后,發(fā)現(xiàn)一個(gè)值得注意的現(xiàn)象,如圖6所示,Model1和Model2的預(yù)測(cè)都忽略了測(cè)試圖像中的部分裂紋,導(dǎo)致預(yù)測(cè)中的裂紋長(zhǎng)度比標(biāo)簽中的短,在預(yù)測(cè)中丟失了部分裂紋。造成這種現(xiàn)象的原因之一是用于調(diào)整圖像形狀大小的雙線性插值算法,雙線性插值考慮已知像素值圍繞未知像素計(jì)算位置的最接近的2×2鄰域,然后取這4個(gè)像素的加權(quán)平均值來(lái)得到最終的插值值。調(diào)整大小的方法
不是對(duì)測(cè)試圖像中的每個(gè)像素進(jìn)行預(yù)測(cè),而是對(duì)像素的統(tǒng)計(jì)值進(jìn)行預(yù)測(cè)。一方面,Model1和Model2的預(yù)測(cè)不能在像素級(jí)上進(jìn)行精確預(yù)測(cè),但另一方面,模型仍然可以指出裂縫的位置。根據(jù)Model1和Model2預(yù)測(cè)的裂紋位置,可以采用一些方法改進(jìn)裂紋預(yù)測(cè),如利用擴(kuò)展閾值算法可以擴(kuò)展裂縫長(zhǎng)度。從圖7(a)可以看出,Model1的IoU僅比Model2的IoU小0.02,但DS1中的圖像大小幾乎是DS2的1/3。這表明,更大的圖像尺寸并不能在很大程度上改善預(yù)測(cè),而作為輸入的大尺寸圖像卻需要大量的存儲(chǔ)和計(jì)算空間。當(dāng)需要縮放圖像以獲得一個(gè)新的訓(xùn)練集時(shí),建議首先考慮計(jì)算效率,而不是圖像大小。
使用該方法構(gòu)建數(shù)據(jù)集時(shí),測(cè)試中評(píng)價(jià)指標(biāo)IoU和Dice Loss都有了明顯提升。Model3和Model4的IoU分別為0.70和0.78。由于Model3只在裂紋子圖像(DS3)上進(jìn)行訓(xùn)練,因此忽略了一些背景信息。
從圖6第3、第4行的預(yù)測(cè)結(jié)果可以看出,Model3錯(cuò)誤地將邊緣上的一些像素點(diǎn)預(yù)測(cè)為裂紋,鋼結(jié)構(gòu)的一些凹槽特征也被預(yù)測(cè)為裂紋。盡管Model3的預(yù)測(cè)不如Model4準(zhǔn)確,但Model3在結(jié)構(gòu)健康監(jiān)測(cè)中可以視為提供了較為安全的估計(jì)。從圖6第5行可以看出,使用Model3對(duì)結(jié)構(gòu)的主裂紋進(jìn)行了預(yù)測(cè),并將一些可疑特征視為裂紋,保證不遺漏裂紋損傷。Model3的IoU雖然不是最好的,但在工程上具有理想的特性。經(jīng)過(guò)DS4的訓(xùn)練,Model4變得比Model3更加優(yōu)秀和準(zhǔn)確。Model4同時(shí)學(xué)習(xí)了背景信息和裂紋信息。在圖6中的預(yù)測(cè)4,Model4的性能最好,很好地處理了背景和溝槽的干擾。較高的精度意味著Model4可以為下一步的研究或測(cè)量提供精確的裂紋信息。在裂紋分割任務(wù)中,Model3和Model4的性能優(yōu)于Model1和Model2。對(duì)于基本訓(xùn)練集的圖像,該方法被證明是比直接調(diào)整超大尺寸圖像大小方法更好的解決方案。部分裂縫便可以提供足夠的檢測(cè)信息。因此,該方法是一種合適的針對(duì)超大尺寸細(xì)長(zhǎng)裂縫的處理方法。此外,該方法對(duì)圖像的分辨率沒(méi)有任何要求,適用于任意的高分辨率和低分辨率圖像。
5 結(jié)論
針對(duì)鋼箱梁內(nèi)部包含復(fù)雜背景和裂縫的超大尺寸圖像,提出了一種基于特征金字塔深度學(xué)習(xí)網(wǎng)絡(luò)的裂縫自動(dòng)檢測(cè)方法,并進(jìn)行了一系列對(duì)比試驗(yàn)。主要結(jié)論如下:
1)基于本方法構(gòu)建的訓(xùn)練集,特征金字塔網(wǎng)絡(luò)能夠在測(cè)試中對(duì)3 264×4 928像素的橋鋼箱梁表面裂縫圖像實(shí)現(xiàn)最大交并比(IoU)為0.78,最小Dice Loss為0.12,表現(xiàn)優(yōu)于將圖像進(jìn)行簡(jiǎn)單縮放構(gòu)建數(shù)據(jù)集訓(xùn)練的模型。
2)采用雙線性插值方法將超大尺寸圖像(3 264×4 928)縮放至1 600×2 400像素或2 112×3 168像素,將會(huì)導(dǎo)致部分裂縫信息丟失,降低裂縫檢測(cè)準(zhǔn)確度。建議采用本方法對(duì)超大尺寸裂縫圖像進(jìn)行拆分,拆分尺寸大小可設(shè)定為480×640。
3)部分裂縫可以為深度學(xué)習(xí)網(wǎng)絡(luò)提供足夠的特征信息。該方法適合于裂縫檢測(cè)任務(wù),并且該方法對(duì)于裂縫圖像的具體分辨率沒(méi)有嚴(yán)格的要求,為今后的裂縫自動(dòng)檢測(cè)提供了一個(gè)較有潛力的解決方案。參考文獻(xiàn):
[1] 李艷霞. 基于深度學(xué)習(xí)的橋梁裂縫圖像信息自動(dòng)提取方法研究[D]. 北京: 北京交通大學(xué), 2020.
LI Y X. Research on automatic bridge crack extraction based on image deep learning [D]. Beijing: Beijing Jiaotong University, 2020. (in Chinese)
[2] 彭玲麗, 黃少旭, 張申申, 等. 淺談無(wú)人機(jī)在橋梁檢測(cè)中的應(yīng)用與發(fā)展[J]. 交通科技, 2015(6): 42-44.
PENG L L, HUANG S X, ZHANG S S, et al. Discussion on UAV application and development in bridge inspection [J]. Transportation Science & Technology, 2015(6): 42-44. (in Chinese)
[3] 陳艷君. 基于特征空間的路面裂縫檢測(cè)與識(shí)別算法研究[D]. 武漢: 武漢工程大學(xué), 2012.
CHEN Y J. Research on detection and recognition method for pavement crack based on feature space [D]. Wuhan: Wuhan Institute of Technology, 2012. (in Chinese)
[4] 孫朝云, 褚燕利, 樊瑤, 等. 基于VC++路面裂縫圖像處理系統(tǒng)研究[J]. 計(jì)算機(jī)應(yīng)用與軟件, 2009, 26(8): 82-85.
SUN Z Y, CHU Y L, FAN Y, et al. Pavement crack image processing system research based on VC++ [J]. Computer Applications and Software, 2009, 26(8): 82-85. (in Chinese)
[5] 馬常霞, 趙春霞, 胡勇, 等. 結(jié)合NSCT和圖像形態(tài)學(xué)的路面裂縫檢測(cè)[J]. 計(jì)算機(jī)輔助設(shè)計(jì)與圖形學(xué)學(xué)報(bào), 2009, 21(12): 1761-1767.
MA C X, ZHAO C X, HU Y, et al. Pavement cracks detection based on NSCT and morphology [J]. Journal of Computer-Aided Design & Computer Graphics, 2009, 21(12): 1761-1767. (in Chinese)
[6] 張維峰, 劉萌, 楊明慧. 基于數(shù)字圖像處理的橋梁裂縫檢測(cè)技術(shù)[J]. 現(xiàn)代交通技術(shù), 2008, 5(5): 34-36.
ZHANG W F, LIU M, YANG M H. Bridge crack detection technology based on digital image processing [J]. Modern Transportation Technology, 2008, 5(5): 34-36. (in Chinese)
[7] 勾紅葉, 楊彪, 華輝, 等. 橋梁信息化及智能橋梁2019年度研究進(jìn)展[J]. 土木與環(huán)境工程學(xué)報(bào)(中英文), 2020, 42(5): 14-27.
GOU H Y, YANG B, HUA H, et al. State-of-the-art review of bridge informatization and intelligent bridge in 2019 [J].Journal of Civil and Environmental Engineering, 2020, 42(5): 14-27. (in Chinese)
[8] ZHANG L, YANG F, ZHANG Y D, et al. Road crack detection using deep convolutional neural network [C]//2016 IEEE International Conference on Image Processing (ICIP). September 25-28, 2016, Phoenix, AZ, USA. IEEE, 2016: 3708-3712.
[9] ZHANG A, WANG K C P, LI B X, et al. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network [J]. Computer-Aided Civil and Infrastructure Engineering, 2017, 32(10): 805-819.
[10] DORAFSHAN S, THOMAS R J, MAGUIRE M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete [J]. Construction and Building Materials, 2018, 186: 1031-1045.
[11] AZIMI M, ESLAMLOU A D, PEKCAN G. Data-driven structural health monitoring and damage detection through deep learning: State-of-the-art review [J]. Sensors (Basel, Switzerland), 2020, 20(10): 2778.
[12] CHENG H K, CHUNG J, TAI Y W, et al. CascadePSP: Toward class-agnostic and very high-resolution segmentation via global and local refinement [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). June 13-19, 2020, Seattle, WA, USA. IEEE, 2020: 8887-8896.
[13] BAO Y Q, LI H. Machine learning paradigm for structural health monitoring [J]. Structural Health Monitoring, 2020: 147592172097241.
[14] LIN T Y, DOLLR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017: 936-944.
[15] HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. June 18-23, 2018, Salt Lake City, UT, USA. IEEE, 2018: 7132-7141.
[16] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. 2014. https://arxiv.org/abs/1409.1556.
[17] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 27-30, 2016, Las Vegas, NV, USA. IEEE, 2016: 770-778.
[18] XIE S N, GIRSHICK R, DOLLR P, et al. Aggregated residual transformations for deep neural networks [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017: 5987-5995.
(編輯 胡玲)
猜你喜歡
中國(guó)教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國(guó)遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(bào)(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時(shí)代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(huì)(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
