遷移學習在天基紅外目標識別中的應用
2022-03-01 06:30:56毛宏霞肖志河
激光與紅外 2022年1期
關鍵詞:模型
劉 浩,毛宏霞,肖志河,劉 錚
(1.北京環境特性研究所,北京 100039;2.光學輻射重點實驗室,北京 100854)
1 引 言
火箭在飛行過程中,溫度極高的尾噴焰能夠被星載紅外傳感器探測、跟蹤和識別[1]。由于距離遠、空間分辨率低,紅外圖像中幾乎沒有尾噴焰形狀和輻射空間分布相關的信息。因此,提取出尾噴焰所占像素的總輻射強度隨時間變化的序列后,轉化為對時間序列的特征提取和識別問題,實現基于總輻射變化特性的火箭識別,是一種合理可行的方法。但是受火箭本身的發射試驗次數和紅外傳感器覆蓋范圍等條件的影響,能夠用于識別的紅外輻射強度序列數據不僅數量少,而且不同類別的樣本數量不平衡,甚至會出現部分火箭只有一條序列用于訓練模型的情況。
單樣本學習(One-Shot Learning)是指每類只有一個樣本,大多數機器學習算法在這種情況下容易出現過擬合,訓練效果不好,特別是層數較多的深度神經網絡[2]。孿生神經網絡(Siamese Neural Network)可以接收兩個輸入樣本,分別將它們輸入到完全相同的子網絡進行特征提取,映射到高維空間并輸出對應的特征向量,最后通過計算特征距離比較兩個樣本的相似程度[3]。孿生神經網絡可以用于小樣本或單樣本的學習問題。
近年來,遷移學習的研究一直是機器學習領域的熱點,遷移學習旨在解決傳統機器學習方法在遇到樣本數量不足、缺乏標注等情況時的局限性,是一個非常有前途和實用價值的研究方向[4]。因此本文嘗試通過遷移學習技術,借助其他時間序列數據集作為源域,將學習到的知識遷移到火箭相似度比較的任務中。在完全不相似的兩個領域進行遷移學習,屬于遠領域遷移學習問題,楊強團隊[5]在2017年首次提出了這一概念,并借助傳遞式遷移學習的方法利用中間域實現了用人臉數據集識別飛機的效果。
在基于圖像的目標檢測和識別方面,研究者已經認識到較淺的二維卷積層提取出的特征往往是通用的低水平的特征,而較深的卷積層提取的特征失去了一般性,更針對特定的任務[6]。與圖像類似,對時間序列使用多層的一維卷積也具有相同的原理。針對時間序列進行遷移學習的研究相比于圖像方面少很多。Hassan等人[7]在UCR數據集上進行了大量的實驗,將其中85個數據集兩兩相互組成源域和目標域,在源域上訓練模型,然后在目標域上微調模型并識別,比較模型遷移和不遷移的性能差異,結果表明遷移學習可以提高預測的準確率,但是與所選擇的源數據集有關,從某些數據集進行遷移學習反而會達到相反的效果。
本文首先建立了一個孿生神經網絡,其子網絡采用多個一維卷積層堆疊而成,利用UCR中的數據集對網絡進行預訓練;然后從火箭序列中每一類別選擇一個序列,兩兩組成序列對組成訓練樣本,對網絡進行遷移和微調。在實驗部分,使用本方法得到了火箭輻射強度序列之間的相似度,并比較了UCR中部分數據集的訓練情況和遷移效果,最終的識別結果與傳統的相似度比較算法進行了比較。
2 數據集介紹
2.1 箭尾噴焰輻射序列
本文所采用的火箭助推段尾噴焰表觀總輻射強度序列,分為實測數據和仿真數據兩部分,分別來自文獻[8]和文獻[9]:其中實測數據包含4型,分別為3條Thor ICBM序列、2條Titan II ICBM序列、1條Titan IIIB以及1條Titan IIIC序列,分別如圖1(a)、(b)、(c)所示;仿真數據包含1型,為3條Atlas II序列,如圖1(d)所示。圖中的縱坐標軸輻射強度以對數坐標的形式給出。為了統一采樣時間間隔,以及提高數據率,采用保形分段三次插值對數據進行加密,時間間隔統一為0.1 s。
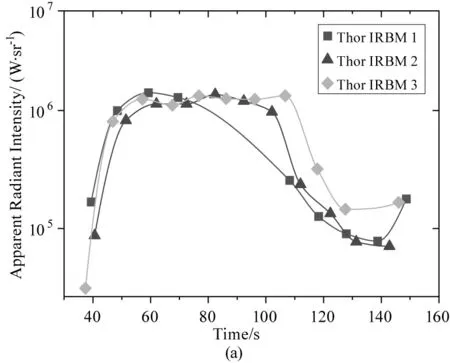
圖1 5型火箭尾噴焰紅外輻射強度隨時間變化的序列
實測數據均來自美國導彈探測和警報系統(Missile Detection and Alarm System,MIDAS),星載短波紅外傳感器的波段為2.65~2.80 μm。仿真數據的飛行軌跡、環境參數、仿真方法等均完全相同,唯一的不同在于設定的傳感器響應波段。
雖然能夠收集到的數據很少,對于機器學習問題屬于單樣本學習的范疇,但是這些少量的輻射強度序列數據也能夠反映火箭尾噴焰紅外輻射的很多特性。總體來說,火箭的發動機類型、飛行高度和速度、大氣透過率、觀測視向角、傳感器特性等都是影響測量到的紅外輻射強度序列的重要因素,這種多元的、非線性的映射也使我們難以對目標和環境特性等先驗知識建模,得到識別問題的解析解。因此本文不考慮目標特性先驗知識,將其作為一個針對時間序列的分類任務。
2.2 UCR數據集
UCR數據集最早由加州大學河濱分校在2002年建立,是一個時間序列數據集的集合,并且持續進行擴充,到2018年為止已經包含了128個數據集,涵蓋了醫學數據處理、行為識別等領域,成為時間序列分類算法進行性能比較的標準數據集[10]。
UCR數據集被廣泛應用于時間序列數據挖掘的研究,針對時間序列進行分類的算法中,一般將動態時間規整(Dynamic Time Warping,DTW)算法作為性能度量的基準[11]。
3 模型和訓練
3.1 一維全卷積特征提取網絡
本文將UCR集合中的部分數據集作為源領域數據集,所以可直接采用文獻[5]中的一維全卷積網絡結構,并使用其經過預訓練的權重。
該網絡的結構如圖2所示,輸入層的尺寸是(batch_size,sequcence_length,feature_dim),由于UCR數據集和火箭數據均為單變量的時間序列,所以此處特征維度均為1。輸入樣本依次經過3個堆疊的一維卷積層,濾波器數量即輸出空間的維度分別為128、256、128,卷積核尺寸分別為8、5、3,步長均為1,在序列的時間維度上滑動執行卷積操作。每個卷積層后均跟隨一個批歸一化層和relu激活函數。經過3個卷積層后,輸入樣本被映射至高維度的隱空間中。為了能夠適應不同長度的時間序列,對高維特征執行一個全局平均池化操作,沿時間維度對特征進行壓縮,得到相同維度的特征,便于后續分類或相似度比較。

圖2 一維全卷積神經網絡的結構示意圖
圖2中網絡最后的全連接層和softmax層是為了分類任務而設計的,為了適配本文整體的相似度比較網絡,只截取圖中網絡的特征提取部分,即輸入層至全局平均池化層,作為孿生神經網絡的主體結構。
3.2 孿生神經網絡
網絡結構如圖3所示,兩個輸入序列分別經過相同權重和偏置的一維全卷積網絡后,得到高維度特征,然后計算它們之間的L1距離(Manhattan Distance)[12]:
(1)
其中,p和q分別為兩個輸入序列對應的特征,維度為N=128。兩個特征的距離經過一個激活函數為sigmoid的全連接層,將其映射為p∈[0,1],以概率值的形式表示兩個輸入序列的相似度:p=0表示兩個輸入序列完全不相似(不同類別),p=1表示非常相似(相同類別)。
模型的損失函數使用二值交叉熵:
log(1-p)]+λ‖w‖2
(2)
式中,N為樣本數;t∈{0,1}為訓練數據的標簽;0表示不同類別;1表示相同類別;第二項為參數L2距離的正則項。
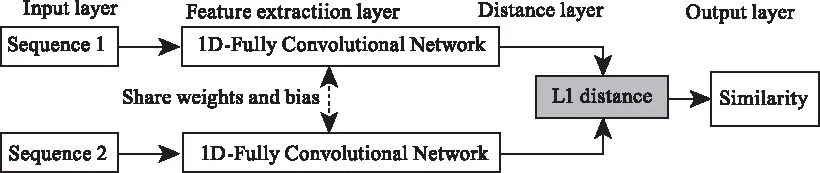
圖3 孿生神經網絡結構示意圖
3.3 訓練過程
模型的訓練共分兩個階段。第一階段在UCR數據集上對孿生神經網絡進行訓練;第二階段在火箭輻射強度序列數據上進行訓練。
在第一階段,利用文獻[7]中提供的UCR數據集的模型預訓練權重。首先如第3.1小節所述,建立與文獻中完全相同的一維全卷積網絡,加載UCR集合中某個數據集的所有預訓練權重,然后刪除不需要的全連接層,根據第3.2小節所述構建完整的孿生神經網絡。
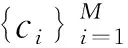
4 結果與分析
在UCR集合中選擇了3個數據集,分別為Car、Trace和OliveOil,作為遷移學習的源域數據集。基本信息如表1所示。在第一個訓練階段,比較預訓練權重對孿生神經網絡在源域訓練結果的影響。分別在隨機初始化權重和使用預訓練權重的情況下進行訓練孿生神經網絡,提高預測數據集中序列相似度的能力。
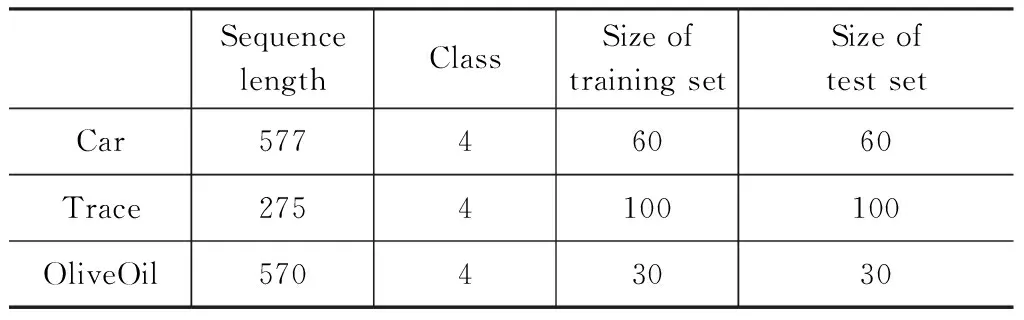
表1 UCR集合中3個數據集的基本信息
圖4和圖5分別展示了兩種情況下50輪內的訓練集和驗證集的準確率。可以看出,預訓練權重對不同數據集的效果不同。對于Car和Trace兩個數據集的影響不大,特別是Trace數據集的收斂效果較好。模型在Car數據集上均出現了過擬合。兩種情況下的模型訓練情況在OliveOil數據集上產生了顯著差異,在不加載預訓練權重直接訓練的情況下,孿生神經網絡的損失無法下降,導致無法收斂。
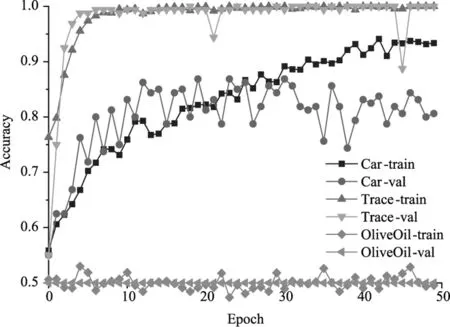
圖4 不使用預訓練權重時的準確率變化
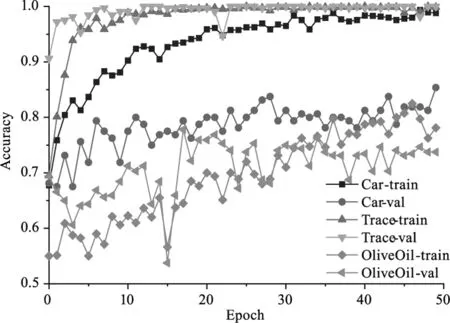
圖5 使用預訓練權重時的準確率變化
接下來對第二個訓練階段中遷移學習的影響進行分析。以Car數據集作為源域為例,測試集的火箭輻射強度序列的相似度如表2和表3所示,Thor的第1條數據簡寫為Thor-1。此時的訓練集為每個類別的第1條序列,訓練數據對應的相似度(如Thor-1和TitanII-1)已經從表中刪除。在這個案例中,不利用Car數據集的預訓練權重時,孿生網絡已經能夠正確識別火箭,但是不同類別和相同類別對應的相似度差異不大,區分度不大。表3中利用Car數據集在孿生數據網絡中的預訓練權重,然后通過少量火箭數據對模型進行微調,得到了更好的序列相似度度量的性能。

表2 無遷移學習下的不同輻射強度序列的相似度
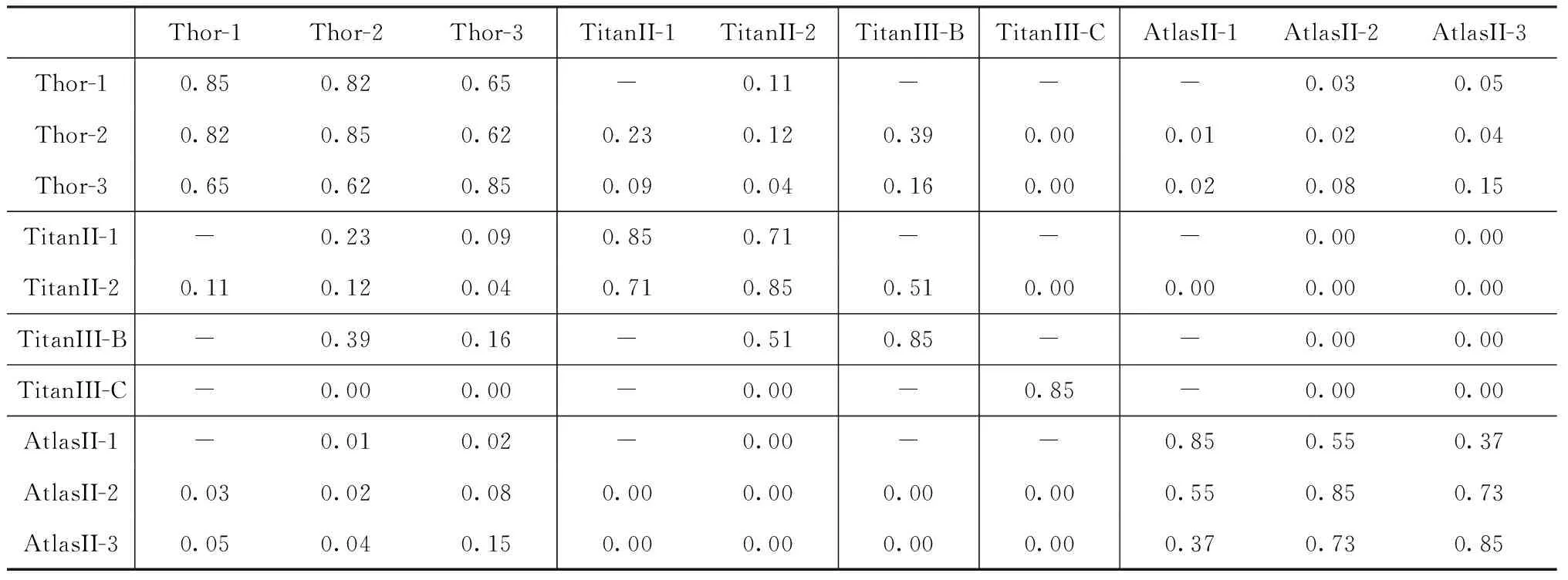
表3 遷移學習下不同輻射強度序列的相似度
為了比較模型的總體性能,與經典的DTW算法進行對比。DTW算法基于路徑動態規劃的原理,不需要訓練,可以計算不同長度的兩條序列之間的距離,距離越小表示相似度越高。DTW算法的結果如表2所示。對于每條待比較序列,計算與其他所有序列的距離,如果距離最小序列的標簽與待比較序列標簽相同,則標記正確;否則標記錯誤。最后統計所有待比較序列的平均正確率。由表2可知DTW算法對Thor和Titan II兩類火箭無法正確區分。
最后,根據交叉驗證的思想,遍歷所有的訓練集和測試集劃分可能,對模型的平均識別正確率進行驗證。從每個類別中選擇一個組成訓練集,共18種劃分方式。對每個劃分進行訓練和測試,得到正確率。最后統計所有劃分的平均正確率。DTW算法和孿生神經網絡的平均正確率如表2所示。

表4 DTW算法下不同輻射強度序列的距離
表5 不同方法的識別正確率
可以看出,不經過任何預訓練的孿生神經網絡已經可以得到較高的準確率。經過Car數據集的預訓練,模型的性能得到了微小的提升;經過Trace數據集的預訓練,模型的性能提升顯著,能夠很好地通過輻射強度序列完成對火箭的識別;而OliveOil數據集對模型產生了負遷移效果。這個結果支持了前面對第一階段訓練情況的分析,結論是不同的數據集在孿生神經網絡結構下的表現不同,遷移效果不同,這可能與數據集本身的特性或文獻中的預訓練權重有關。通過上面的實驗結果可知,我們能夠從UCR集合中找到某些數據集,使得它對于訓練一個用于比較相似度的孿生神經網絡起到積極的作用,提高識別正確率。
5 結 語
本文建立的用于比較序列相似度的孿生神經網絡,在星載紅外傳感器識別火箭的任務中取得了較好的結果。通過遷移某些其他時間序列數據集的知識,可以進一步提高模型的性能,對火箭輻射強度序列的相似性度量效果更好。本模型對于解決極少量數據下的時間序列分類問題有一定的借鑒意義。
此外,對于給定的目標域,源域數據集的選擇方法一直是遷移學習領域需要解決的問題。如何設計一種能夠比較不同數據集之間相似度的算法,借此選擇合適的源域數據集以取得較好的遷移效果,是值得研究的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
