基于VGGish 網絡的音頻信息情感智能識別算法
2022-02-27 03:27:06張志超李曉燕
電子設計工程 2022年4期
張志超,李曉燕
(1.延安大學魯迅藝術學院,陜西延安 716000;2.延安大學數學與計算機科學學院,陜西延安 716000)
音樂是人類情感交流的一種方式,移動互聯網的普及,使得人們能夠隨時隨地享受音樂。音樂中蘊藏著豐富的情感,作為人類精神生活的重要部分,借助計算機和人工智能技術實現對音樂所表達的情感進行智能化分析、識別及分類,對音樂數據的深度應用具有重要意義[1-3]。然而目前對音頻情感的研究仍相對較少,缺乏一套完整的體系對其進行智能化處理。
針對上述問題,文中設計了一種對音樂情感自動分析和識別的算法,該算法主要由音頻信息采集、數據標注、數據轉換等模塊組成。其中,音頻信息采集模塊主要用于獲取原始的音頻信息;數據標注模塊用于對獲取到的音頻信息進行二次情感劃分;數據轉換模塊則是將原始數據轉換為VGGish 網絡可用的數據。該算法可用于對海量音頻數據的智能化自動分類,并形成音頻數據庫。同時,可以將各類音頻文件片段分類存儲,用于輔助創作。
1 VGGish網絡
VGG(Visual Geometry Group)網絡是英國牛津大學提出的一系列以VGG 開頭的卷積網絡模型,也稱為VGGish 網絡[4]。目前已被廣泛應用于圖像識別等人工智能領域,在音頻情感分析領域仍應用較少。但有研究表明,VGGish 網絡能夠提取到數據更全面、復雜的特征,這能為智能分析音頻信息情感奠定良好的基礎[5]。
截至目前,VGGish網絡共推出了6種網絡結構[6-8],分別是VGG11(A)、VGG11(ALRN)、VGG13(B)、VGG16(C)、VGG16(D)和VGG19(E)。VGG16(D)是其中應用最為廣泛的網絡結構,也是被認為架構層次最深的一種網絡結構,但是在加深卷積網絡深度的同時,算法所涉及的參數也會相應增加。VGGish 網絡模型為了降低這一問題帶來的影響,在卷積層采用多個小的卷積核代替大卷積核,同時將卷積步長設置為1。這樣不但有效減少了網絡訓練所需的參數,而且等效于在網絡中增加了非線性映射,可以有效提高網絡的綜合性能[9]。6 種VGGish 網絡的具體結構如圖1 所示。
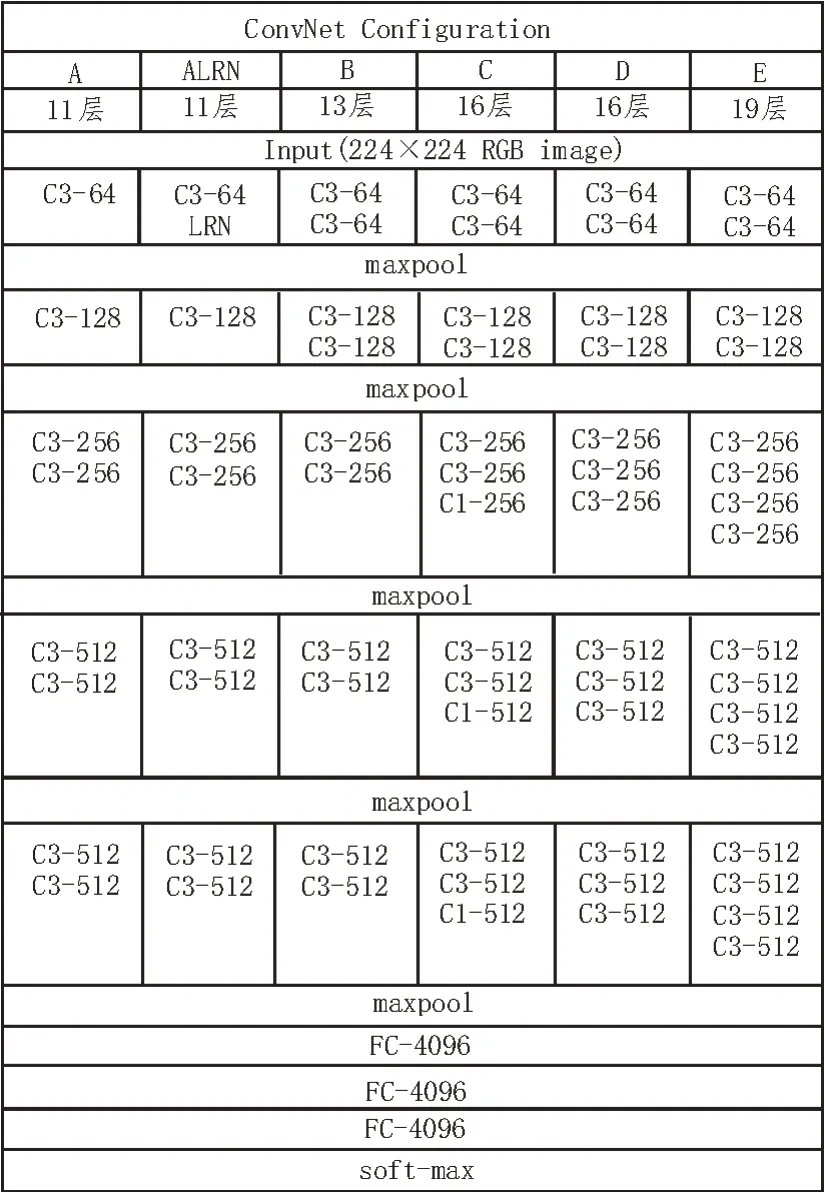
圖1 VGGish網絡結構
VGGish 網絡根據不同的層數進行區分(層數=卷積層數+全連接層數),以VGG19(E)為例,該網絡由16 個卷積層和3 個全連接層組成。每種網絡均包含了5 個池化層(maxpool),并合理置于卷積層之間。但是,并非所有的卷積層都需要搭配池化層,具體位置也要根據實際情況來確定[10]。在圖1中,C3-64 的全稱是Conv3-64,表示該卷積層有64個大小為3×3 的卷積核。FC 代表全連接層,后面的4096 表示該全連接層的大小。但無論是哪種網絡模型,其最后一層均為soft-max 層[11]。該層是實現分類功能的關鍵,通常被置于網絡的最后,起到歸一化的作用。在VGGish 網絡的訓練過程中,通過對訓練集的學習,不斷對該層中的損失函數(代價函數)進行求導。同時,對卷積層中的相關參數進行微調,從而得到使損失函數達到最小值的最優解,因此該過程也可看作是對損失函數不斷擬合的過程。
得益于上文所述小卷積核的設計,雖然6 種網絡結構的深度不同,但其所包含參數數量的差異卻不大,具體如表1 所示。

表1 VGGish網絡參數數量
雖然VGGish 網絡解決了卷積神經網絡深度不能超過10 層的問題,但其深度也不能無限加深,在超過一定的閾值后會出現梯度爆炸、模型訓練效果急劇降低等問題。因此在加深網絡深度的同時,也需要兼顧模型的應用效果。
VGGish 網絡所具有的特點主要包括:
1)結構簡單、層次分明:整個結構只有較小的卷積核,連續的卷積層通過5 個池化層隔開,雖然層數較多但功能明確;
2)小卷積核:卷積層中用較小的卷積核來代替大核,這樣做的優勢在于減少訓練所需參數,增加非線性映射的強度[12],同時還能夠降低感受野;
3)通道數更多、特征度更寬:通道代表著特征,VGG 網絡最多提供512 個通道,可以挖掘出數據中更多的深層次特征,增強結果的準確度。
2 識別算法設計
2.1 算法架構
該文利用VGGish 網絡所設計的音頻信息情感智能識別算法,用于實現對海量音頻數據的智能化分類。算法設計結構及算法工作流程如圖2 所示。

圖2 算法設計結構及工作流程
該算法流程:首先是音頻信息收集,收集的內容除了最重要的音頻數據之外,還包括其平臺原有的情感化劃分信息,便于該文進行初步篩選;然后是數據標注,其是對獲取到的音頻信息進行二次情感劃分,由于原有的劃分種類有一定的重合與包含關系存在,因此還需要進一步調整;接下來是數據轉換,音頻初始信息不能直接輸入VGGish 網絡,需要對原始數據進行處理,通常采用梅爾頻率倒譜頻率(MFCC)對信息進行轉換,得到符合網絡模型要求的輸入數據[13];VGGish 網絡通過不斷學習與訓練可以得到音頻數據的Embedding 特征;此外,為了避免人為標注帶來的誤差還需要將提取到的音頻特征進行降維可視化,不斷調整不同情感音樂數據集分布,從而達到縮小組內差異,增加組間差異的目的,使得模型更加準確;最終經支持向量機(SVM)[14]和長短記憶模型(LSTM)[15]兩種方式對Embedding特征進行分類,得到最為符合該首音樂的情感。下面將對其中涉及到的關鍵過程進行進一步深入分析。
2.2 算法關鍵過程
1)數據標注
文中采用的音頻信息來源于國內某音樂網站,選取了9 個大類共計1 442 首音頻數據,具體數據集如表2 所示。

表2 音頻數據原始數據集
可以發現,原始的情感分類有些界限比較模糊,有些則是籠統地包含了其他分類,例如懷舊。因此需要將原始數據進行重新分類,使其具有相對明確的界限,分類標準:第一類為激動興奮類,主要為氣勢磅礴、令人慷慨激昂、節奏感強的音頻;第二類為快樂類,主要是小清新、令人高興快樂、節奏輕快的音頻;第三類為輕松類,是令人心情放松舒暢、節奏舒緩的音頻;第四類為傷感類,以令人傷感、節奏沉悶的音頻為主;第五類為恐懼類,以奇怪詭異和令人感到不適的音頻為主。經重新調整后,各類別對應的音頻數量如表3 所示,同時按6∶2∶2 的比例將數據集分為訓練集、測試集和驗證集。

表3 經調整后的各類情感音頻數據集
2)數據轉換
該文利用MFCC 方法對數據進行轉換,具體步驟如下[16]:
①預處理:將原始音頻數據重新采樣為16 kHz的數據格式;
②加窗:將每一幀數據乘以漢明窗,以增加連續性;
③快速傅里葉變換(FFT):對每20 ms 的數據片段進行FFT,得到頻譜數據;
④頻譜映射:將得到的頻譜數據映射到75~7 500 Hz窗口區間;
⑤分幀:將音頻信息按照每480 ms 為一幀,幀內再以每10 ms 進行細分,從而得到48×64 的MFCC 特征數據。
3)VGGish 網絡
該文采用VGG11(A)網絡進行模型的訓練,具體設計結構如圖3 所示。
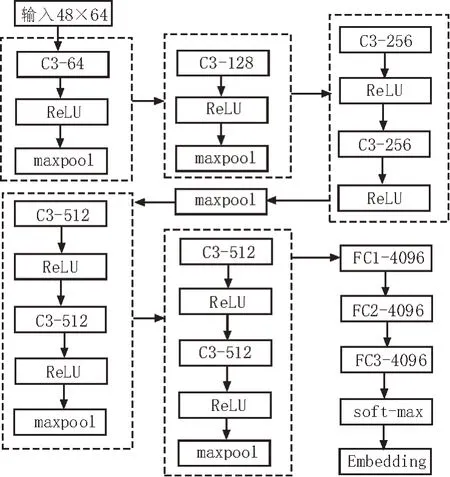
圖3 VGG11(A)設計結構
該模型的作用是將輸入到模型中的48×64 MFCC特征數據轉換為128 維的Embedding 特征。
4)降維可視化
目前對數據進行降維可視化的方法主要包括鄰接圖法、LDA法、PCA法、基于切空間法和t-SNE法等,該文選用其中處理效果最優的t-SNE 法進行處理。t-SNE(t-distributed Stochastic Neighbor Embedding)由傳統的SNE 發展而來,適用于將高維數據降為二維或三維,再進行可視化展示。
3 算法測試
為了測試該文所提算法在音頻信息情感智能識別中的表現,在完成對VGGish 網絡模型的訓練后,利用測試集對算法性能進行測試。測試分為兩組,兩組的區別在于分類器的選擇,第一組采用傳統的支持向量機(SVM),第二組采用長短記憶模型(LSTM)。
首先,利用傳統的SVM 算法對VGGish 網絡所得到的Embedding 特征進行分類,SVM 算法的各參數設置如表4 所示。
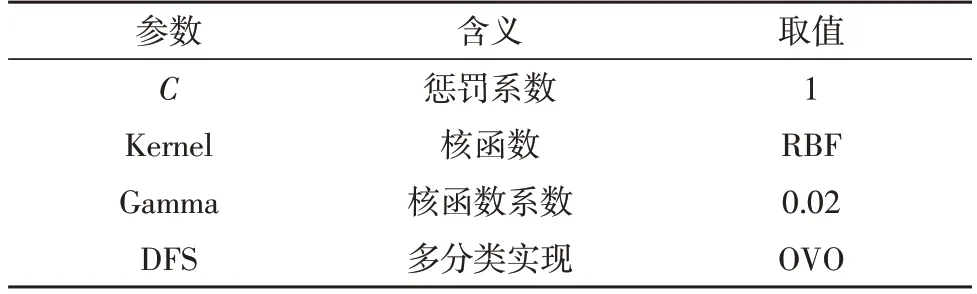
表4 SVM參數設置
其中,C代表懲罰系數,用來對損失函數進行一定控制,通常取值范圍為[0.000 1,10 000],C值越大,雖然可以使訓練出的模型在對訓練集進行測試時的準確度有所提高,但對測試集進行測試時的準確度不足,因此僅適用于特定數據集,其泛化能力欠缺,容易形成過擬合;C值過小則會增強模型的容錯率,因此泛化能力較強,但容易形成欠擬合,所以文中將C值設置為1;根據可視化的結果確定核函數Kernel為RBF 高斯核,同時在將Gamma 設置為0.02 時得到的模型效果最優,文中選用了一對一的OVO 方法。最終的試驗結果如表5 所示。
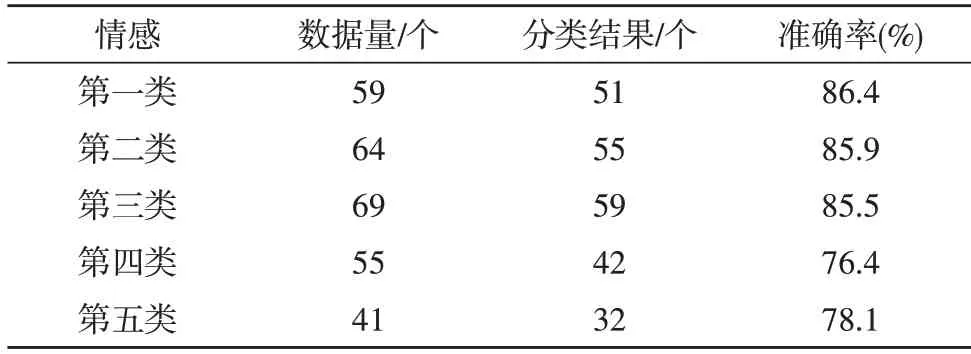
表5 SVM分類試驗結果
從結果可以看出,傳統的SVM 方法總體表現良好,能夠達到82.46%的平均準確率。從單一類別來看,對第一類(激動興奮類)的情感分類效果是最優的,準確率能夠達到86.4%。但對于第四類(傷感類)的準確率卻較低,僅為76.4%。
然后采用LSTM對VGGish網絡得到的Embedding特征進行分類,分類試驗結果如表6 所示。

表6 LSTM分類試驗結果
從結果可以看出,LSTM 分類方法總體表現優秀,平均準確率能夠達到90.12%。同時,從單個類別來看,對第五類(恐懼類)的情感分類效果最優,準確率可達92.7%;而對于第三類(輕松類)的處理效果相對較差,但仍能達到88.4%。由上述結果可知,該文所提算法能夠進行音頻信息情感的智能識別。尤其是當采用LSTM 分類方法時,其分類的平均準確率可達到90%以上,具有良好的識別效果。
4 結束語
該文通過介紹和分析VGGish 網絡,提出了基于VGGish 網絡的音頻信息情感智能識別算法。算法主要由音頻信息采集、數據標注、數據轉換、VGGish模型訓練、降維可視化、分類等模塊組成,各模塊之間相互配合共同完成對音頻信息情感的智能識別。兩項算法測試結果充分驗證了文中所提算法的可行性與有效性,兩種分類方法中,SVM 方法表現良好,平均準確率能夠達到82.46%;LSTM 分類方法則表現優秀,平均準確率可達90.12%。為海量音頻信息的智能化分析與情感識別分類提供了解決方案。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
