時頻掩碼優化的兩階段語音增強算法
2022-02-27 03:27:04鄭莉李鴻燕
電子設計工程 2022年4期
關鍵詞:優化
鄭莉,李鴻燕
(太原理工大學信息與計算機學院,山西榆次 030600)
近年來,深度學習方法廣泛應用在語音增強[1]中,用來解決傳統語音增強方法在非平穩噪聲環境下性能不穩定和泛化能力弱的問題,取得了較好的效果[2-3]。文獻[4]更新了基于DNN 語音增強算法的目標函數,從而減輕估計語音的過平滑度。文獻[5]同時將干凈語音和干擾噪聲的特征作為訓練目標,利用DNN 和深度循環神經網絡(Deep Recurrent Neural Network,DRNN)分別訓練,相比單獨對干凈語音進行預測的網絡結構,該方法具有更好的分離效果。文獻[6]在DNN 結構中添加了具有感知掩蔽效應的部分,有效地減少了語音失真并去除了干擾噪聲。以上這些研究在訓練目標和網絡架構的選擇上各有不同,但都以均方誤差作為損失函數。文獻[7]在損失函數中將相鄰幀網絡之間進行關聯,并設計感知系數反映語音存在情況,顯著地提高了語音質量和語音可懂度。此外,近幾年的研究工作表明,將語音幅度和相位估計結合起來有利于語音增強,相位估計可提供準確的幅度譜信息[8-9]。文獻[10]驗證了在提高純凈語音頻譜估計中相位信息估計量發揮的顯著作用。基于此,文中提出采用信噪比信息來優化損失函數的兩階段語音增強方法,利用信噪比信息計算增益系數和相位偏差,增益系數用來平衡語音失真和噪聲殘留之間的關系,相位偏差可以利用相位信息來更準確地預測幅度,從而優化損失函數。實驗證明該優化算法可有效提高語音可懂度,增強語音質量。
1 常規深度神經網絡語音增強算法
傳統的基于深度神經網絡的語音增強算法[5]如圖1 所示,該方法分為訓練和增強兩個階段。在訓練過程中,將純凈語音和背景噪聲疊加,生成帶噪語音,并提取帶噪語音的特征用于DNN 訓練,在語音增強訓練任務中,逐步進行有監督地調優,時頻掩碼[11]作為網絡學習的隱目標,通過使用DNN 網絡估計該掩碼,然后將估計的掩碼應用于帶噪語音幅度譜特征,得到純凈語音幅度譜特征估計,最終網絡優化的目標是該估計純凈語音幅度譜與參考干凈語音幅度譜之間的均方誤差。損失函數定義如下:
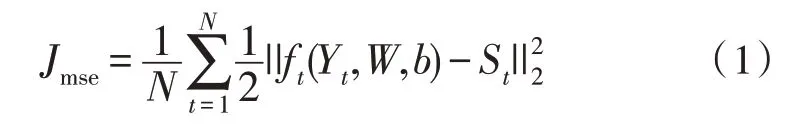
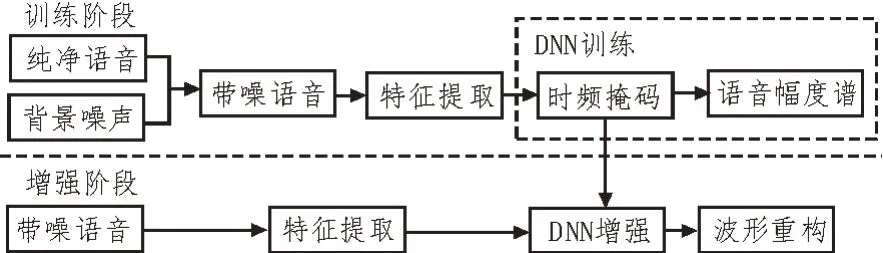
圖1 常規深度神經網絡語音增強算法框圖
其中,Yt表示第t幀的輸入帶噪語音幅度譜,ft代表時頻掩碼函數,ft(Yt)代表預測的純凈語音幅度譜。St表示參考的純凈語音幅度譜,N代表抽取的樣本數目。W、b分別是網絡的權重矩陣和轉置向量,利用誤差反向傳播算法來更新網絡權值,經過一系列迭代更新,得到訓練好的網絡。
在增強階段,將帶噪語音輸入訓練好的網絡,輸出即為估計的純凈語音幅度譜特征,根據人耳對相位變化不太敏感這一特性,將帶噪語音的相位與估計的純凈語音幅度譜合成并進行短時傅里葉逆變換,得到增強的語音信號。
2 優化的兩階段網絡語音增強算法
在傳統深度神經網絡語音增強算法中,將語音增強作為回歸任務設計損失函數,取得了顯著效果,但未考慮不同信噪比時,帶噪語音中語音和噪聲所占比重的不同。當SNR 較低時,噪聲占比較大,導致增強后語音中殘留噪聲能量較多,語音信息被屏蔽,語音可懂度降低;當SNR 較高時,語音占比大,增強后容易造成語音失真,導致語音質量較差。針對此問題,文中提出利用信噪比信息優化損失函數的兩階段語音增強算法[12]。第一階段從帶噪語音中初步預測純凈語音幅度譜和噪聲幅度譜,用來提供SNR信息;第二階段,利用SNR 信息生成增益系數和相位偏差,優化時頻掩碼函數,輸出增強的語音幅度譜。訓練階段算法框圖如圖2 所示。
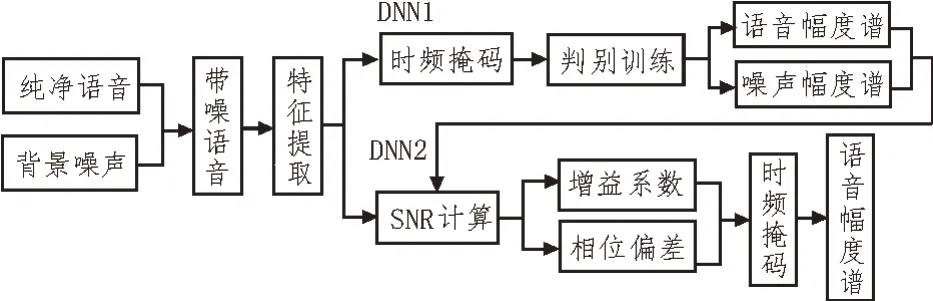
圖2 時頻掩碼優化的兩階段語音增強算法框圖
2.1 信號模型
在實際中,同時測得帶噪語音和純凈語音比較困難,因此通過疊加來獲得目標帶噪語音,用y(t)、s(t)、n(t)分別表示t時刻生成的帶噪語音、純凈語音以及不相關的背景噪聲,則帶噪語音可以表示為純凈語音信號及其不相關的背景噪聲的疊加。用以下模型來表示帶噪語音:

2.2 特征提取
語音信號在非特定范圍內是非平穩時變信號,截取其10~30 ms 范圍內的短時平穩狀態,對式(2)作短時傅里葉變換,得到頻域中的噪聲表示如下:
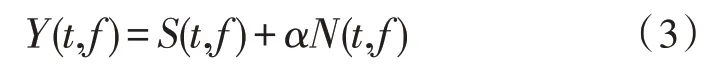
其中,Y(t,f)、S(t,f)、N(t,f)分別表示帶噪語音、純凈語音和背景噪聲在第t幀、第f頻帶的頻譜分量,通過設置不同α得到目標信噪比的帶噪語音。
2.3 DNN1階段
對于給定的帶噪語音,該階段對語音譜和噪聲譜同時建模,將帶噪語音的幅度譜特征輸入網絡,將純凈語音和噪聲的幅度譜作為參考目標,最終輸出估計的語音幅度譜和噪聲幅度譜,定義時頻掩碼函數:

在損失函數中添加參數γ,通過網絡訓練來提高語音預測準確度。假設語音和噪聲相互獨立,同時最小化語音與預測語音、噪聲與預測噪聲之間的均方差,最大化語音與預測噪聲、噪聲與預測語音之間的均方差。損失函數定義為:
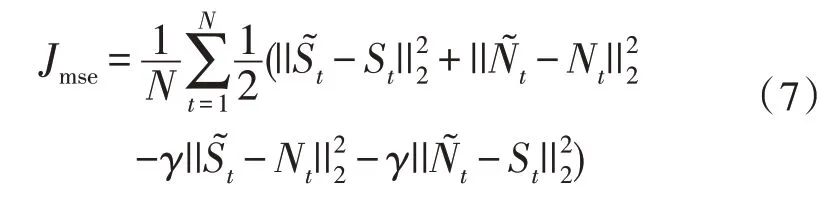
2.4 DNN2階段
該階段利用信噪比信息計算增益函數和相位偏差來共同優化時頻掩碼函數,參與網絡訓練過程,最終生成純凈語音幅度譜。
2.4.1 增益系數
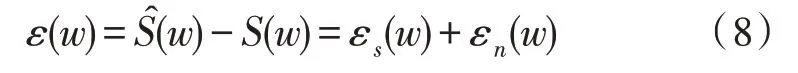
為了減小語音失真,引入濾波函數[13],最小化語音失真同時將殘留噪聲限制在某一預設閾值水平下,定義為:
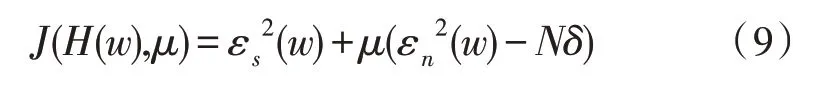
其中,δ代表預設閾值,用于限制噪聲強度;μ代表增益系數,用于控制語音失真和殘留噪聲之間的平衡。
H(w)的第k個對角元素H(wt)為:

根據以下分段函數計算可得到μ的值,SNRdB=10 log10SNR;μt是由實驗計算得到的最佳值,μ0=(1+4μt)/5;k=25/(μ0+1)。
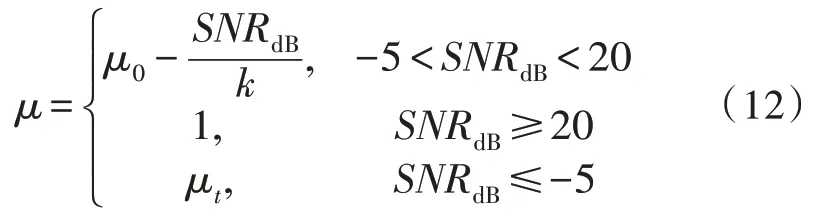
2.4.2 相位偏差
相位偏差定義為φdev=φy-φs,即帶噪語音相位與純凈語音相位之間的差異,相位偏差取決于信噪比[14],利用信噪比信息可計算得到相位偏差。由幾何三角關系式變換可得到相位偏差公式如下:
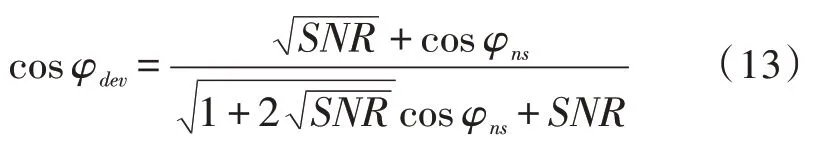
其中,φns=φn-φs,φn、φs分別代表背景噪聲的相位和純凈語音的相位,由幾何關系式可得到Y2=S2+N2+2SNcosφns,求解cosφns,可得:

2.4.3 損失函數
使用增益系數和相位[15]偏差來優化最初的時頻掩碼函數ft:
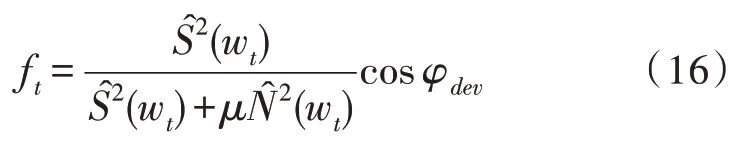
損失函數定義為:
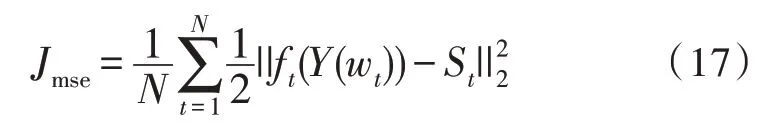
其中,Y(wt)表示第t幀的輸入帶噪語音幅度譜,ft表示時頻掩碼函數,ft(Y(wt))表示預測的純凈語音幅度譜。St表示參考的純凈語音幅度譜,N代表小批量樣本數目。利用誤差反向傳播算法來更新網絡權值,網絡經過一系列迭代更新,得到訓練好的網絡。
3 實驗仿真
3.1 實驗設置
采用TIMIT語料庫中的純凈語音數據,選取10個說話人,男女各5 人,每人10 條語音,共100 條語音,從Noisex-92 噪聲庫數據中選取5 種噪聲,將語音和噪聲按照不同信噪比(-5,0,5)隨機挑選一種,共合成500 條帶噪語音,選取400 條作為訓練集,100 條作為測試集。語音和噪聲的采樣頻率均為16 kHz,使用64 ms 的漢明窗和32 ms 的窗移對信號進行分頻,幅度譜作為網絡的輸入特征,對于每個時間幀,采用具有50%重疊的1 024 點短時傅里葉變換提取頻譜表示,得到512 維幅度譜特征。
在DNN 訓練中,將輸入數據歸一化為零均值和單位方差,激活函數選擇relu 函數。網絡中包含隱藏層2 層,每個隱藏層中有1 000 個隱藏單元,輸出層有1 026 個單元。網絡采用隨機初始化,使用L-BFGS 梯度下降法,minibatch 的大小為100,訓練網絡總的迭代次數設置為20 次。
3.2 評價指標
為了比較文中算法的語音增強性能,采用語音質量感知評估(Perceptual Evaluation of Speech Quality,PESQ)指標和短時客觀可懂度(Short Time Objective Intelligibility,STOI)指標對不同方法增強后的語音進行評價。PESQ 用來比較干凈參考信號和分離信號的響度譜,其得分范圍為(-0.5 4.5),得分越高,語音質量越好;STOl 主要用來衡量干凈語音和單獨話語的短時時間包絡之間的相關性,其得分范圍為(0 1),可以理解為正確的百分比,得分越高,語音可懂度越好。
3.3 實驗結果及分析
將文中所提算法與傳統算法進行對比,為了保持相同的網絡深度,均使用具有4 個隱藏層的DNN,特征提取和參數設置均一致。使用語音質量感知評估指標和語音可懂度指標對增強語音進行評價,對比結果如表1 所示。語音信號的波形圖和語譜圖可以顯示去噪的細節信息,圖3 給出了在-5 dB Train 噪聲時純凈語音、帶噪語音、優化前算法以及文中所提算法處理的時域波形圖,圖4 給出了兩種算法的語譜圖。
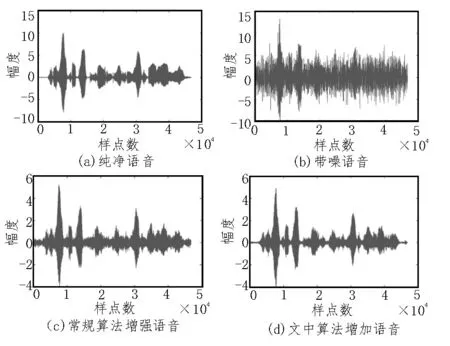
圖3 不同算法增強語音的波形圖
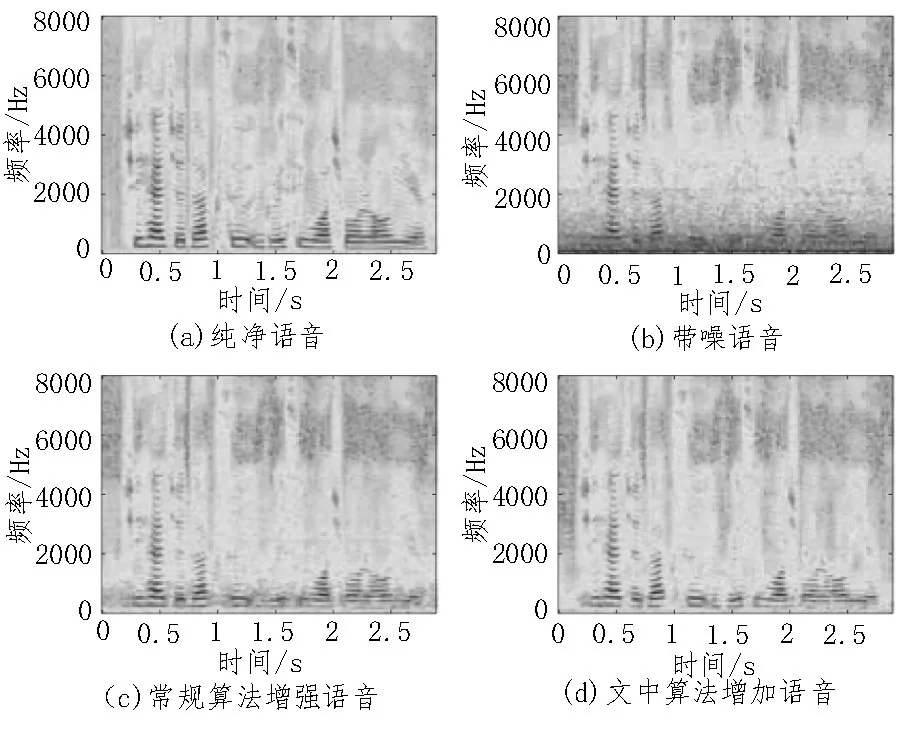
圖4 不同算法增強語音的語譜圖
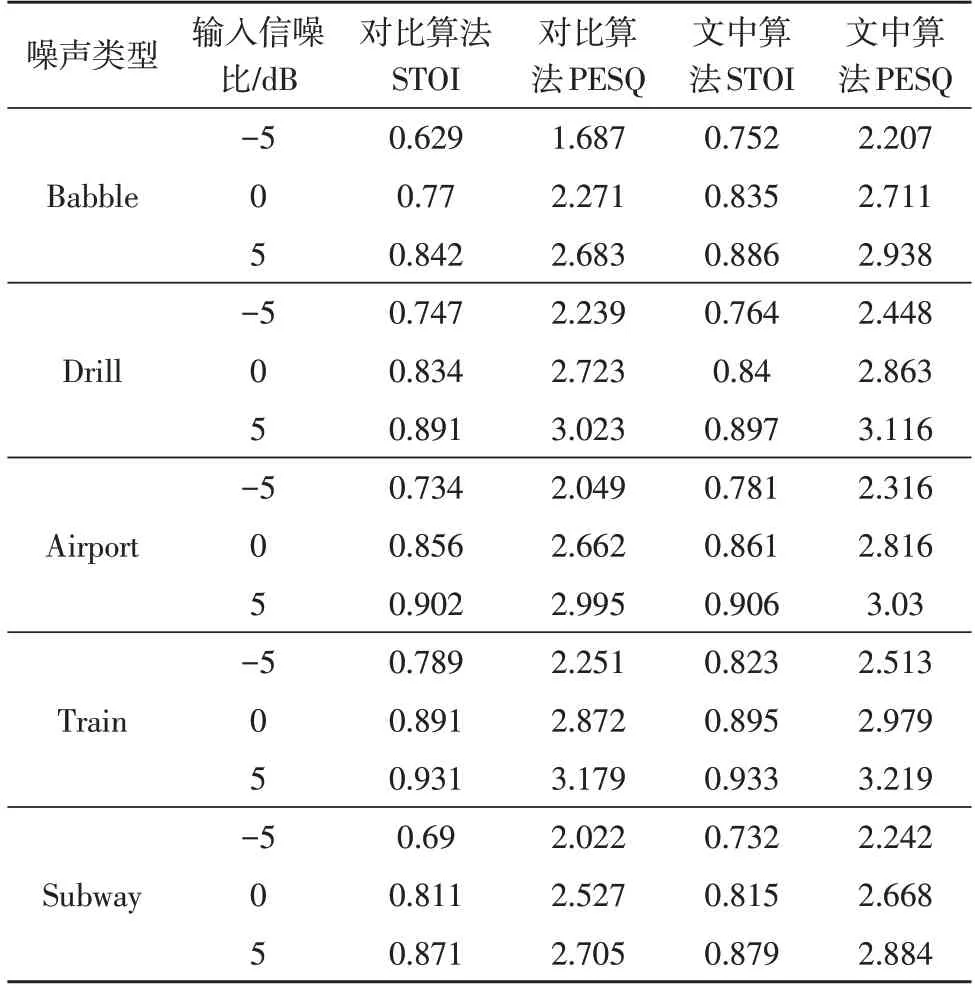
表1 語音可懂度與語音質量評估結果
對比圖3、圖4 可以看出,優化前算法保持了較好的語音結構,但仍存在不少殘留噪聲;改進的語音增強算法不僅能保持語音信號的諧波結構,減少語音失真,而且更加有效地去除了低頻殘留噪聲,使增強后語音波形更接近純凈語音波形。另外,表1 結果表明,文中提出的算法增強后語音的感知質量評估指標和可懂度在各種信噪比及不同的背景噪聲下均有提高,與優化前算法對比,語音質量感知評估指標平均提高了0.22;語音可懂度評估指標平均提高了0.027。尤其是在-5 dB 低信噪比條件下,各種噪聲下的增強語音質量和語音可懂度均有較大幅度提升,表明所提改進算法可以去除殘留噪聲,減少語音失真并較好地重構語音。
4 結束語
文中提出利用信噪比信息優化時頻掩碼函數的兩階段語音增強算法,利用DNN 估計信噪比信息,通過引入增益系數,最大程度減小增強后語音的失真并盡可能地去除殘留噪聲;同時引入帶噪語音和純凈語音的相位偏差信息來提供更準確的幅度譜信息。通過對不同信噪比下噪聲進行的實驗驗證表明,該算法有很好的增強效果,尤其是在低信噪比條件下,能夠較好地去除噪聲并保留語音結構。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
