基于嵌入式特征選擇算法下的抗乳腺癌藥物分子活性預(yù)測(cè)
2022-02-20 00:19:40葉丹胡二琴
電腦知識(shí)與技術(shù) 2022年34期
葉丹 胡二琴


摘要:文章提出在嵌入式特征選擇算法背景下,通過(guò)對(duì)比正則化模型和樹(shù)模型兩種篩選方法下的重要性權(quán)重選取出對(duì)生物活性最具有顯著影響的20個(gè)分子描述符,并分別建立預(yù)測(cè)模型。結(jié)果表明樹(shù)模型下的隨機(jī)森林方法真實(shí)值與預(yù)測(cè)值相對(duì)平均誤為0.0167,相較于正則化方法和樹(shù)模型方法下的梯度提升決策樹(shù)更優(yōu),證實(shí)基于該方法下篩選的模型具有預(yù)測(cè)誤差小、預(yù)測(cè)精度更高的優(yōu)點(diǎn)。
關(guān)鍵詞:抗乳腺癌;嵌入式特征選擇;重要性權(quán)重選擇特征;生物活性預(yù)測(cè)
中圖分類(lèi)號(hào):TP301? ? ? ? 文獻(xiàn)標(biāo)識(shí)碼:A
文章編號(hào):1009-3044(2022)34-0008-03
1 引言
乳腺癌是目前世界上最常見(jiàn),致死率較高的癌癥之一。世界衛(wèi)生組織國(guó)際癌癥研究機(jī)構(gòu)(IARC) 發(fā)布的2020年全球最新癌癥負(fù)擔(dān)數(shù)據(jù)顯示,2020年全球新增癌癥病人約1930萬(wàn)人,其中女性乳腺癌占11.7%,在數(shù)量上已經(jīng)超越了肺癌(11.4%) ,成為全球新診斷人數(shù)最多的癌癥。乳腺癌確診病人超過(guò)226萬(wàn)[1],其中僅中國(guó)就超過(guò)41萬(wàn)人,占比9.1%。其發(fā)病率和死亡率分別位列我國(guó)女性惡性腫瘤的第1位和第4位[2]。雖然乳腺癌發(fā)病率高,但致死率相較于肺癌、腸癌這些常見(jiàn)癌癥要稍低。提高早期乳腺癌及其癌前病變的檢出率并進(jìn)行及時(shí)有效的治療是提高乳腺癌預(yù)后、降低乳腺癌死亡率的重要措施[3]。
近年來(lái),國(guó)內(nèi)外研究發(fā)現(xiàn)雌激素受體α亞型(Estrogen receptors alpha, ERα) 在乳腺發(fā)育過(guò)程中扮演了十分重要的角色[4-5]。在惡性乳腺癌組織中的雌激素受體的濃度一般較高,而大部分良性腫瘤和正常組織都不含雌激素受體[6],因此ERα被認(rèn)為是治療乳腺癌的重要靶標(biāo)。能夠拮抗ERα活性的化合物可能是治療乳腺癌的候選藥物。
不斷地尋找新的手段來(lái)改進(jìn)藥物以最大化藥物的治療效果是科學(xué)制藥發(fā)展的趨勢(shì)。因此,尋找新的抗乳腺癌候選藥物尤為關(guān)鍵,對(duì)于乳腺癌患者精確治療具有積極而重大意義,可以降低乳腺癌患者死亡率。本文提出在嵌入式特征篩選背景下,通過(guò)對(duì)比正則化模型和樹(shù)模型下不同方法的特征選擇,對(duì)1974個(gè)化合物所對(duì)應(yīng)的ERα生物活性數(shù)據(jù)進(jìn)行特征篩選,并利用不同篩選辦法選取的前20個(gè)對(duì)生物活性具有顯著性影響的化合物分子式分別構(gòu)建預(yù)測(cè)模型并對(duì)模型進(jìn)行評(píng)估。
2 數(shù)據(jù)處理及變量篩選
本文數(shù)據(jù)來(lái)源于2021年中國(guó)研究生數(shù)學(xué)建模競(jìng)賽數(shù)據(jù),數(shù)據(jù)包含1974個(gè)化合物的729個(gè)分子描述符信息(自變量)和化合物對(duì)應(yīng)ERα的生物活性值PIC50。PIC50值越大表明生物活性越高,對(duì)抑制ERα活性越有效。本文設(shè)定PIC50為因變量。利用Python、R編程完成對(duì)集中數(shù)據(jù)的預(yù)處理。
2.1 數(shù)據(jù)預(yù)處理
1) 刪除原始數(shù)據(jù)中化合物分子式中缺失值。原始數(shù)據(jù)中有225個(gè)分子描述符取值全部為零,刪除全部為零的分子描述符后剩余504個(gè)分子描述符(自變量)。
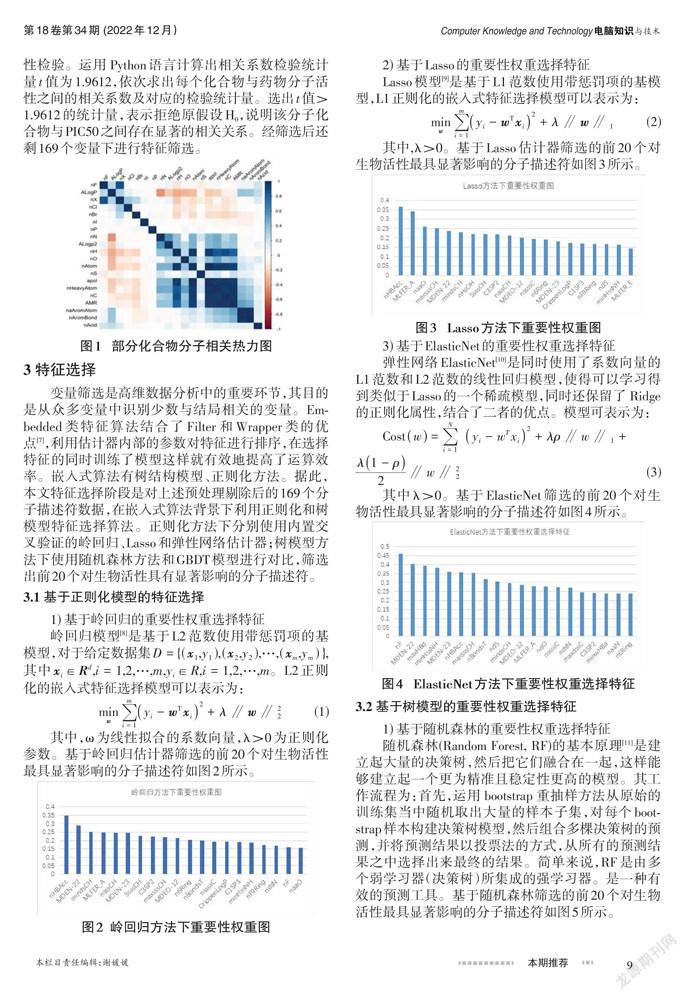
2) 進(jìn)行化合物分子的相關(guān)性分析。去除冗余的化合物分子式,防止過(guò)度擬合。結(jié)合熱力圖1可發(fā)現(xiàn)部分變量相關(guān)系數(shù)絕對(duì)值接近1,此類(lèi)變量的信息高度重疊(本文選取絕對(duì)值大于0.9) 。為解決模型建立復(fù)雜問(wèn)題,本文將信息高度重疊的部分變量進(jìn)行剔除。
經(jīng)過(guò)剔除后還剩222個(gè)有化合物分子,顯然直接應(yīng)用這些化合物分子式不僅浪費(fèi)時(shí)間還可能會(huì)導(dǎo)致模型的過(guò)度擬合,因此還需要篩選出與因變量PIC50具有一定相關(guān)性的自變量。
3) 相關(guān)性顯著性檢驗(yàn)。計(jì)算化合物分子式與藥物分子活性PIC50之間的Pearson相關(guān)系數(shù)并進(jìn)行假設(shè)檢驗(yàn)得到對(duì)應(yīng)的t值,發(fā)現(xiàn)部分化合物分子式與PIC50之間的相關(guān)性較弱。為使數(shù)據(jù)降維,減少原始數(shù)據(jù)對(duì)預(yù)測(cè)模型準(zhǔn)確性的干擾,對(duì)相關(guān)系數(shù)進(jìn)行顯著性檢驗(yàn)。運(yùn)用 Python語(yǔ)言計(jì)算出相關(guān)系數(shù)檢驗(yàn)統(tǒng)計(jì)量t值為1.9612,依次求出每個(gè)化合物與藥物分子活性之間的相關(guān)系數(shù)及對(duì)應(yīng)的檢驗(yàn)統(tǒng)計(jì)量。選出t值>1.9612的統(tǒng)計(jì)量,表示拒絕原假設(shè)H0,說(shuō)明該分子化合物與PIC50之間存在顯著的相關(guān)關(guān)系。經(jīng)篩選后還剩169個(gè)變量下進(jìn)行特征篩選。
3 特征選擇
變量篩選是高維數(shù)據(jù)分析中的重要環(huán)節(jié),其目的是從眾多變量中識(shí)別少數(shù)與結(jié)局相關(guān)的變量。Embedded類(lèi)特征算法結(jié)合了Filter和Wrapper類(lèi)的優(yōu)點(diǎn)[7],利用估計(jì)器內(nèi)部的參數(shù)對(duì)特征進(jìn)行排序,在選擇特征的同時(shí)訓(xùn)練了模型這樣就有效地提高了運(yùn)算效率。嵌入式算法有樹(shù)結(jié)構(gòu)模型、正則化方法。據(jù)此,本文特征選擇階段是對(duì)上述預(yù)處理剔除后的169個(gè)分子描述符數(shù)據(jù),在嵌入式算法背景下利用正則化和樹(shù)模型特征選擇算法。正則化方法下分別使用內(nèi)置交叉驗(yàn)證的嶺回歸、Lasso和彈性網(wǎng)絡(luò)估計(jì)器;樹(shù)模型方法下使用隨機(jī)森林方法和GBDT模型進(jìn)行對(duì)比,篩選出前20個(gè)對(duì)生物活性具有顯著影響的分子描述符。
3.1 基于正則化模型的特征選擇
1) 基于嶺回歸的重要性權(quán)重選擇特征
2) 基于Lasso的重要性權(quán)重選擇特征
3) 基于ElasticNet的重要性權(quán)重選擇特征
3.2 基于樹(shù)模型的重要性權(quán)重選擇特征
1) 基于隨機(jī)森林的重要性權(quán)重選擇特征
隨機(jī)森林(Random Forest, RF)的基本原理[11]是建立起大量的決策樹(shù),然后把它們?nèi)诤显谝黄穑@樣能夠建立起一個(gè)更為精準(zhǔn)且穩(wěn)定性更高的模型。其工作流程為:首先,運(yùn)用 bootstrap 重抽樣方法從原始的訓(xùn)練集當(dāng)中隨機(jī)取出大量的樣本子集,對(duì)每個(gè)bootstrap樣本構(gòu)建決策樹(shù)模型,然后組合多棵決策樹(shù)的預(yù)測(cè),并將預(yù)測(cè)結(jié)果以投票法的方式,從所有的預(yù)測(cè)結(jié)果之中選擇出來(lái)最終的結(jié)果。簡(jiǎn)單來(lái)說(shuō),RF是由多個(gè)弱學(xué)習(xí)器(決策樹(shù))所集成的強(qiáng)學(xué)習(xí)器。是一種有效的預(yù)測(cè)工具。基于隨機(jī)森林篩選的前20個(gè)對(duì)生物活性最具顯著影響的分子描述符如圖5所示。
2) 基于GBDT模型的重要性權(quán)重選擇特征
梯度提升決策樹(shù)[12](GBDT)是以分類(lèi)回歸樹(shù)為基學(xué)習(xí)器Boosting集成學(xué)習(xí)算法。在GBDT的每次迭代中都在殘差減少的梯度方向新建一棵CART決策樹(shù),經(jīng)多次迭代最后的殘差趨近0,最后將所有決策樹(shù)的結(jié)果累加獲得最終的預(yù)測(cè)結(jié)果。基于隨機(jī)森林篩選的前20個(gè)對(duì)生物活性最具顯著影響的分子描述符如圖6所示。
通過(guò)查閱藥物分子研究文獻(xiàn)發(fā)現(xiàn):1) 高效率結(jié)合靶標(biāo)的小分子配體具有更強(qiáng)的疏水性,藥物分子可以通過(guò)其疏水基團(tuán)與機(jī)體內(nèi)的靶標(biāo)相結(jié)合,發(fā)揮藥理活性[13];2) 化合物的親脂性對(duì)化合物的藥理學(xué)活性有重大影響[14];3) 氫鍵作用是藥物與生物靶標(biāo)之間非共價(jià)相互作用中作用力較強(qiáng)的形式之一,往往對(duì)藥效的強(qiáng)弱產(chǎn)生重要影響[15]。本文中篩選的部分變量與藥物分子研究理論吻合,如:XLogp、LipoaffinityIndex、nHBAcc。體現(xiàn)出上述使用正則化方法和樹(shù)模型方法篩選出的分子描述符較為合理,具有可信度。
4 生物活性預(yù)測(cè)模型構(gòu)建與評(píng)價(jià)
構(gòu)建預(yù)測(cè)模型的整體思想:結(jié)合三種特征篩選方法下分子描述符的數(shù)據(jù)作為模型樣本集。正則化篩選變量分別建立嶺回歸、Lasso和ElasticNet彈性網(wǎng)絡(luò)預(yù)測(cè)模型;樹(shù)模型篩選變量分別建立隨機(jī)森林回歸和梯度提升決策樹(shù)回歸模型。模型評(píng)估時(shí)選用相對(duì)平均誤差(MSRE) 作為評(píng)價(jià)模型的指標(biāo)。相對(duì)平均誤差(MSRE) 的定義如下:
從上述分析可以看出基于嵌入式算法下建立的預(yù)測(cè)模型都保持了較高的預(yù)測(cè)精度,而其中所有的樹(shù)模型預(yù)測(cè)結(jié)果較正則化方法下的結(jié)果更優(yōu)。在樹(shù)模型下方法下,隨機(jī)森林方法預(yù)測(cè)結(jié)果優(yōu)于GBDT模型。
5 結(jié)束語(yǔ)
本文從嵌入式特征選擇方法出發(fā),通過(guò)化合物對(duì)ERα的生物活性數(shù)據(jù)進(jìn)行分析,采用特征重要性排序方法進(jìn)行特征選擇建立不同預(yù)測(cè)模型,結(jié)果表明隨機(jī)森林方法在生物活性預(yù)測(cè)方面具有精度更高的優(yōu)點(diǎn)。此外,通過(guò)特征選擇方法篩選出的部分化合物分子式與藥物分子研究吻合,有望成為抗乳腺癌藥物研究的可選標(biāo)志物。嵌入式方法下的特征篩選方法具有可拓展性,未來(lái)可以將該算法推廣到其他類(lèi)型癌癥的藥物篩選上,推動(dòng)未來(lái)不同癌癥的靶細(xì)胞篩選不同的化合物分子事業(yè)發(fā)展。
參考文獻(xiàn):
[1] Sung H,F(xiàn)erlay J,Siegel R L,et al.Global cancer statistics 2020:GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J].CA:a Cancer Journal for Clinicians,2021,71(3):209-249.
[2] 赫捷,陳萬(wàn)青,李霓,等.中國(guó)女性乳腺癌篩查與早診早治指南(2021,北京)[J].中國(guó)腫瘤,2021,30(3):357-382.
[3] 中華預(yù)防醫(yī)學(xué)會(huì),赫捷.中國(guó)女性乳腺癌篩查標(biāo)準(zhǔn)(T/CPMA 014-2020)[J].中華腫瘤雜志,2021,43(1):8-15.
[4] Fuqua S A,Wiltschke C,Zhang Q X,et al.A hypersensitive estrogen receptor-alpha mutation in premalignant breast lesions[J].Cancer Research,2000,60(15):4026-9.
[5] 張桂香,趙學(xué)東.雌激素受體亞型的研究現(xiàn)狀[J].國(guó)外醫(yī)學(xué) 婦產(chǎn)科學(xué)分冊(cè),2002,29(6):352-355.
[6] 趙曉民,徐小明.雌激素受體及其作用機(jī)制[J].西北農(nóng)林科技大學(xué)學(xué)報(bào)(自然科學(xué)版),2004,32(12):154-158.
[7] 周志華.機(jī)器學(xué)習(xí)[M].北京:清華大學(xué)出版社,2016.
[8] Liu J,Ji S W,Ye J P.Multi-task feature learning via efficient l2,1-norm minimization[J].Uncertainty in Artificial Intelligence,2009:339-348.
[9] Keerthi S S,Shevade S.A fast tracking algorithm for generalized LARS/LASSO[J].IEEE Transactions on Neural Networks,2007,18(6):1826-1830.
[10] Zou H,Hastie T.Regularization and variable selection via the elastic net[J].Journal of the Royal Statistical Society:Series B (Statistical Methodology),2005,67(2):301-320.
[11] 方匡南,吳見(jiàn)彬,朱建平,等.隨機(jī)森林方法研究綜述[J].統(tǒng)計(jì)與信息論壇,2011,26(3):32-38.
[12] Friedman J H.Greedy function approximation:a gradient boosting machine[J].The Annals of Statistics,2001,29(5): 1189-1232.
[13] Ferreira de Freitas R,Schapira M.A systematic analysis of atomic protein-ligand interactions in the PDB[J].MedChemComm,2017,8(10):1970-1981.
[14] 王佩利.新型抗腫瘤活性小分子化合物的類(lèi)藥性質(zhì)研究[D].上海:華東師范大學(xué),2018.
[15] 盛春泉.藥物結(jié)構(gòu)優(yōu)化——設(shè)計(jì)策略和經(jīng)驗(yàn)規(guī)則[M].北京:化學(xué)工業(yè)出版社,2018.
【通聯(lián)編輯:王力】

- 電腦知識(shí)與技術(shù)的其它文章
- 基于聯(lián)盟鏈的養(yǎng)老服務(wù)可信追溯系統(tǒng)構(gòu)建研究
- 基于慢特征分析算法的老人跌倒行為檢測(cè)
- 基于創(chuàng)新擴(kuò)散理論的移動(dòng)學(xué)習(xí)研究
- Java程序設(shè)計(jì)課程實(shí)施思政教育的研究與實(shí)踐
- 基于成果導(dǎo)向的物聯(lián)網(wǎng)安全技術(shù)課程教學(xué)方法研究
- 基于OBE理念的“線(xiàn)上+線(xiàn)下”混合式教學(xué)模式在信號(hào)與系統(tǒng)課程中的建設(shè)與應(yīng)用