基于MapReduce 并行計算的網站日志數據分析處理
2022-02-19 09:19:56劉義卿陳新房
科學技術創新 2022年1期
關鍵詞:用戶
劉義卿 陳新房
(防災科技學院信息工程學院,河北 三河 065201)
Hadoop 是一種具有分布式特點的系統框架,Hadoop 發展到今天已經發展成一個生態系統,其組件之多,使用也是極其復雜,但是根本的目的只有一個那就是解決數據的存儲與分析。本文將在Hadoop 分布式系統下的MapReduce 為處理系統的基礎上進行網站日志的清洗,通過LogMapper 類進行鍵值對的Shuffl 操作、通過LogReducer 類進行合并統計。利用分布式、并行計算的優越性,快速得到數據分析結果。
1 Hadoop 分布式平臺核心技術
Hadoop 主要由兩大核心HDFS 和MapReduce 兩部分組成。
1.1 HDFS。HDFS是一種分布式文件系統,作為Hadoop 核心之一,具有處理超大數據、流式處理、可在廉價的服務器上運行等特點。HDFS在訪問應用程序數據時,具有很高的吞吐率,因此對于超大數據集的應用程序而言,選擇HDFS 作為底層的數據存儲是比較理想的選擇。
1.2 MapReduce。MapReduce 是一種編程模型,通常被用于大規模的數據集的并行運算,對于各個數據分片,都會有一個map 任務對該分片進行處理,這種處理是一種并行的方式。但是對同一個分片,Mapreduce 的map 任務對該分片的<key,value>對的處理是一個串行的處理過程。分布式并行計算指的是對數據分片的并行,對分片內的記錄,則按照順序的串行處理。
Mapreduce 模型的核心是Map 函數和Reduce 函數。二者都是由應用程序開發者負責具體實現的。只需要關注如何實現Map 和Reduce 函數,不需要處理并行編程過程中的其他各種復雜問題。,例如分布式存儲、工作調度、負載均衡、容錯處理等。這些問題都會由Mapreduce 框架進行處理完成。如圖1所示。
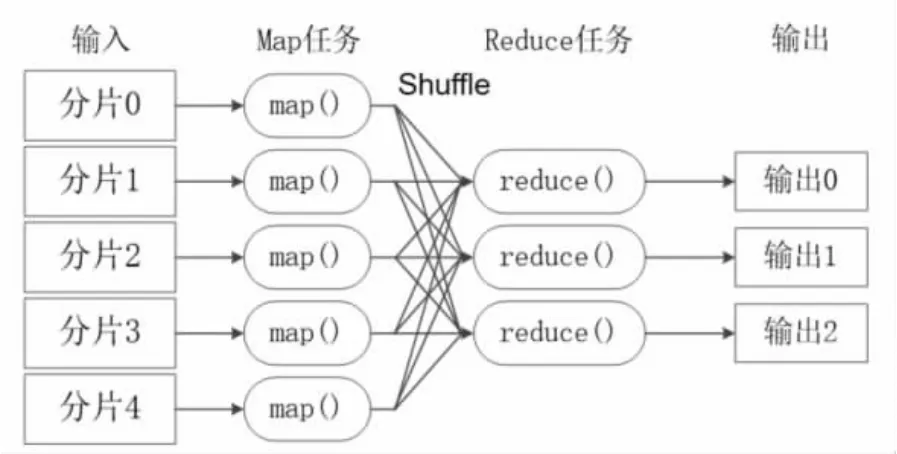
圖1 MapReduce 模型
2 MapReduce 工作原理
MapReduce 將復雜的、運行于大規模集群上的并行計算過程高度的抽象到兩個函數:Map 函數和Reduce 函數。
2.1 Map 函數的輸入來自于分布式文件系統的文件塊,這些文件塊的格式是任意的。類型也是任意的。在Map 讀取之前MapReduce 框架會使用InputFormat 模塊做Map 的預前處理,檢驗其格式是否符合等。講文件邏輯上切分多個InputSplit 在這個過程中還需要RecordReader 記錄相應的處理信息。Map 函數將輸入的元素轉化為<key,value>鍵值對的形式,轉化的過程是根據用戶輸入的映射規則進行轉化的。因此鍵的類型和值的大小,都與用戶定義的規則有關。
2.2 Shuffle 過程分為Map 端和Reduce 端。Map 端的Shuffle 的任務主要分為以下幾部分:首先將輸入的數據按照用戶自定義的映射規則轉換成一批<key,value>,寫入緩存,每個任務都會分配一個緩存一般默認為100MB,溢寫比為0.8 這樣就能保證Map 持續的寫入緩存,即要保證緩存不滿。到達緩存后,在進入磁盤的過程中會先被分區、排序、合并。分區的方式是采用Hash 函數對Key 進行哈希后再對Reduce 任務進行取模,以為了更均勻的分配給Reduce。后臺進程還要根據key的不同進行排序,并根據用戶是否定義了合并操作而選擇合并,以減少寫到磁盤的數據量。合并的根本目的就是將key相同的value 相加起來目的是減少鍵值對的數量。寫入磁盤后,緩存要被清空。輸送到磁盤中要進行文件的歸并,所謂“歸并”就是要將相同的鍵值對的歸并成一個新鍵,待Map 端結束后Reduce端會“領取”屬于它的數據放到自己的磁盤中,期間Reduce 還會通過RPC向JobTracker 查看Map 的狀態,保證任務的傳遞速率。Map 端領過來的數據會先放入Reduce 的緩存中,進行文件的歸并以及合并操作,最后把任務輸送到Reduce。圖2 為Shuffle 過程。

圖2 Shuffle 過程
2.3 在整個Shuffle 結束之后,Reduce 任務會根據Reduce函數中用戶定義的各種映射規則,輸出最終結果,并保存到分布式文件系統中。
3 網站日志數據分析
在此進行一個網站日志清洗的實例,將其上傳到分布式系統中,并利用MapReduce 計算模型進行數據分析。
3.1 將數據上傳集群中

3.2 LogTcl 類實現代碼


System.setProperty ("HADOOP_USER_NAME", "root"); // API 連接高可用時用到


3.3 LogMapper 類實現代碼

3.4 LogReducer 類實現代碼

3.5 查看處理后的結果

總結,本文首先介紹了Hadoop 在大數據技術中的重要地位,并簡單介紹了Hadoop 的兩大核心HDFS 和MapReduce 的概念。進而詳細介紹MapReduce 的組成部分和其各部分的主要功能,尤其是Map 函數的處理過程和Shuffle 的詳細過程。以及各部分組件在工作時的相互作用與協調。在MapReduce 計算模型的處理下,將網站的日志進行了分析處理將其日志進行清洗過濾得到了想要的分析結果。充分體現了Mapreduce 作為Hadoop 生態圈的重要一員,其在處理數據時具有的高效性和優越性。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
