YOLO與SAHI模型在建筑外立面表觀損傷檢測中的協同應用*
2022-02-17 08:46:52陳志強陳小杰
施工技術(中英文) 2022年24期
陳志強,楊 霞,陳小杰
(1.上海房屋質量檢測站,上海 200031; 2.上海市房地產科學研究院,上海 200031)
0 引言
近年來,建筑外墻飾面脫落傷人事故時有發生,建筑外立面安全問題成為人們關注的焦點。一般情況下,建筑外墻飾面損傷有一個由輕微到嚴重逐漸發展的過程,在飾面脫落前建筑外墻面常常已存在開裂、滲水等表觀損傷。因此,通過現場檢測盡早發現建筑外立面開裂等表觀損傷,及時采取修繕措施就顯得尤為重要。
建筑表觀損傷的傳統檢測方式是人工目視檢測法,主要包括直接目視檢測和借助望遠鏡、無人機等輔助裝置進行的間接目視檢測[1-2]。直接目視檢測法現場檢測效率低,高層建筑頂部樓層外立面損傷易漏檢。無人機間接目視檢測法存在人工讀片工作量大,不同檢測人員對損傷判別標準不一致等問題。另一種建筑表觀損傷檢測方法是數字圖像處理法。目前,數字圖像處理法相關研究主要集中于建筑表面裂縫檢測[3-4]。數字圖像處理法需手動提取損傷特征,檢測效果受圖像噪聲影響較大,目前無有效解決辦法[5]。近年來,深度學習技術已被廣泛應用于醫療診斷、金融貿易、無人駕駛等領域[6-9],并取得顯著效果。
目前,深度學習技術在建筑損傷檢測領域也有一定的應用。張英楠等[10]利用YOLOv4實現了歷史建筑清水墻風化、泛堿、綠植覆蓋3種典型損傷的智能診斷及區域劃分。馬健等[11]提出利用 YOLOv5 對古建筑木結構裂縫進行智能檢測的方法,相比于傳統的人工檢測方法具有高效、便捷、成本低的優點。王念念[5]對Faster R-CNN,MASK R-CNN算法在古建筑表面損傷檢測中的應用進行了研究,實現了故宮古建筑表面損傷的快速識別、定位、分割、測量與評估。陳墨等[12]對R-CNN算法在建筑表面裂縫缺陷識別中的應用進行了研究,得到了識別效率較高、識別精度較好的結果。林汨圣等[13]對 Faster R-CNN 算法框架在居住建筑外墻面損傷檢測中的應用進行了研究,證明了該方法可有效對外墻損傷情況進行檢測判定,效率較高且效果良好。
當目標物體的像素點數<32×32,或目標物體的尺寸小于原圖尺寸的0.1倍時,目標物體可看作是小目標物體[9]。現有基于深度學習的目標檢測技術對建筑外墻細小裂縫、局部小塊脫落等小目標檢測效果較差,而類似損傷在建筑外立面表觀損傷檢測中大量存在。對圖像進行切片處理是提高小目標檢測效果的有效方法。趙楚等[14]對高分辨率的瓷磚缺陷數據集進行了切片處理,再采用改進的Faster R-CNN算法對瓷磚缺陷進行檢測,試驗獲得較好的檢測效果。陳祖歌[15]對圖像切片后將切片與原圖一起作為模型輸入以放大小目標的輸入信息的方式對SSD模型進行優化,并在PASCAL VOC和MS COCO數據集上進行試驗驗證,驗證結果表明該方法能有效改善多尺度目標的檢測精度。王勝科等[16]對原始高分辨率航拍圖像進行切片處理,然后將裁剪出的小尺寸塊圖通過改進后的CenterNet網絡進行檢測,根據其提出的G-NMS算法聚合檢測結果,該方法在數據集 UAV_OUC 和 VisDrone2019上獲得了較好的試驗結果。
SAHI框架可與各類目標檢測方法集成,顯著提高小目標檢測能力[17-18]。Delhez等[19]使用SAHI對原始分辨率為3 456×6 144的鳥類圖片進行了目標檢測測試,測試結果表明,未使用SAHI時Resnet50和MobileNetv3模型無法正確檢測鳥類,使用SAHI后這些模型甚至能檢測到地平線上非常小的鳥。Keles等[20]使用VisDrone2019Det數據集對小目標檢測的YOLOv5和YOLOX模型進行了基準測試,并研究了SAHI的影響,研究結果表明,SAHI的應用效果對所有模型都有了實質性改進,YOLOv5模型的效果相對更大。
應用SAHI可顯著提高模型的小目標檢測效果,但尚無應用于建筑損傷檢測的案例。為了解SAHI在建筑外立面表觀損傷檢測中的應用效果,本文采用YOLO與SAHI集成框架對2幢高層住宅外墻飾面開裂、滲水、脫落,以及外墻附著物空調機架銹蝕4種表觀損傷的無人機照片進行了訓練與預測試驗。
1 YOLO與SAHI基本原理和模擬使用
1.1 YOLO基本原理與模擬使用
YOLO是一種基于回歸的目標檢測算法,由Redmon等于2016年首次提出[21]。該算法將目標檢測的分類和定位用一個神經網絡實現,在目標檢測領域得到廣泛應用。YOLO 將輸入圖像分成S×S個單元格,單元格借助 anchor boxes 進行邊界框的預測。邊界框的信息采用五元組T(x,y,w,h,c) 表示,x,y表示邊界框的橫坐標與縱坐標,w,h表示其寬度和高度,c表示置信度,它反映當前邊界框是否包含預測目標及其預測準確性的估計概率。
以YOLOv1為基礎,通過不斷改進,YOLOv2[22],YOLOv3[23],YOLOv4[24],YOLOv5[25]算法被相繼提出,算法的檢測精度、速度、小目標檢測能力逐步提升。目前廣泛應用的是由Ultralytics公司發布的YOLOv5。Yolov5s網絡是Yolov5系列中深度最小、特征圖寬度最小、AP精度最低的網絡,但因其對計算機硬件要求較低,仍是目前YOLO系列中應用最廣泛的網絡模型。
本研究采用目標檢測算法YOLOv5s模型進行建筑外立面表觀損傷檢測試驗。
1.2 SAHI基本原理與模擬使用
YOLO檢測算法具有高效、高精度的特點,但對小目標的檢測效果欠佳,特別是對高分辨率圖像小目標的檢測效果很差。建筑外立面表觀損傷檢測工作中,為了提高現場檢測效率或限于現場檢測條件,一般采用高分辨率相機,在保證目標清晰的同時,一次拍攝盡可能大的外立面區域,此時,如何保證裂縫、脫落等大量小目標不漏檢便成為YOLO檢測算法在建筑外立面表觀損傷檢測中應用必須解決的關鍵問題。
為了解決小目標檢測問題,Fatih Cagatay Akyon等提出了名為切片輔助推理(slicing aided hyper inference,SAHI)的框架。首先,將原始圖像切分為M×N個重疊的切片pI1 ,pI2,…,pIl。在保持高寬比的同時,調整每個切片大小,然后對每個重疊的切片都獨立地應用目標檢測正向傳遞。可同時選擇使用原始圖像的全推理檢測較大的目標。最后,將全部切片預測結果與原始圖像的全推理結果使用NMS合并回原始大小后作為最終預測結果輸出。
本研究采用SAHI庫實現圖像切片,調用YOLOv5實現目標預測,最后再通過SAHI庫合成切片預測結果。
2 基于YOLOv5s和SAHI的建筑外立面表觀損傷檢測
為了實現建筑外立面表觀損傷檢測,設計檢測系統流程如圖1所示。檢測流程分為建立數據集、模型訓練和損傷識別3個階段,其中建立數據集階段包括數據采集、損傷標注、圖像切片、圖像增強和數據集切分等步驟。SAHI的作用主要是在建立數據集階段實現高分辨率圖像自動切片,以及損傷識別階段將高分辨率圖像切片后送入YOLO網絡進行目標預測,并將切片圖像上的預測結果組合成全圖目標預測結果后輸出。YOLO的作用主要是在模型訓練階段根據訓練數據集完成模型訓練,得到建筑外立面表觀損傷檢測模型,并在損傷識別階段對SAHI切片后的圖像進行目標預測。

圖1 建筑外立面表觀損傷檢測流程
2.1 試驗配置
采用云服務器,系統配置為RTX 3060,12.6GB顯存GPU,6核E5-2680 v4CPU,30GB內存,操作系統為Ubuntu;編程語言為Python3.8;深度學習平臺為PyTorchv1.10,訓練和預測模型使用Ultralytics公司的YOLOv5s6.0,切片推理框架使用SAHI0.9.2。
2.2 建立數據集
在進行模型訓練之前,需通過人工標注方式建立數據集。數據集的建立包括數據采集、損傷標注、圖像切片、圖像增強、數據集切分等步驟。
1)數據采集 以2幢高層建筑作為研究對象,采集了60張圖片,建立了一個建筑外立面表觀損傷數據集。所有圖片均采用大疆無人機air mini拍攝。受限于無人機硬件性能,無人機無法貼近建筑外立面拍攝。拍攝得到的建筑外立面損傷照片像素分辨率為 4 000× 2 250,每張照片基本占據4個樓層高度。該建筑外立面表觀損傷主要有裂縫、剝落、滲漏、空調支架銹蝕4種類型。典型損傷照片如圖2所示。

圖2 建筑外立面典型表觀損傷類型
2)損傷標注 建立圖像數據集后,需對圖像進行特征提取與標注。損傷標注是由經驗豐富的檢測工程師對采集的建筑外立面損傷照片進行檢查,篩選出存在指定損傷類型的照片,在照片上用矩形框標記出每處損傷位置,并指定損傷類型。可采用labelImg等工具進行標注,如圖3所示。

圖3 在原始照片上標注損傷部位
3)圖像切片 無人機拍攝的原始照片像素分辨率為4 000×2 250,遠高于YOLOv5模型采用的像素分辨率640×640。如直接利用高分辨率照片進行訓練,YOLO會對照片進行預處理,將高分辨率照片轉換為像素分辨率640×640的圖像再進行后續模型訓練,這將造成大量小目標損傷標注丟失,嚴重影響模型訓練效果。因此,需對高分辨率照片進行處理,使之符合YOLO模型的要求。圖片切片可達到這一目的。SAHI可實現高分辨率圖像的自動切片,將每張高分辨率照片分割為多張低分辨率照片,并自動篩選出包含損傷標注的低分辨率照片,舍棄不包含損傷標注的純背景照片。在對高分辨率照片進行分割時,相對應的損傷標注文件也應進行分割處理。60張外立面損傷照片經過圖片切片處理后,得到1 383個帶有局部損傷標注的照片。切片處理后的典型照片如圖4所示。
4)圖像增強 當模型包含多個類別,而各類別樣本數量相差過大時,模型訓練效果較差。因此,對于樣本數量較少的類別,應對樣本數據進行增強處理。常見的增強方式有旋轉、模糊、移位、馬賽克等。本次研究建筑外立面主要損傷類型為裂縫,剝落類型樣本數量明顯偏少。為了平衡訓練樣本數量,對剝落類型樣本進行了數據增強處理,數據增強后,帶有局部損傷標記的照片增加到1 663個。數據增強典型損傷照片如圖5所示。

圖5 旋轉增強處理前后的脫落損傷照片
5)數據集切分 將整個數據集分為訓練集、驗證集和測試集,其中訓練集占80%,驗證集和測試集分別占10%。
2.3 模型訓練
采用經過損傷標注、圖片切片、數據增強處理后建筑外立面損傷照片作為訓練樣本,利用YOLOv5s模型進行訓練。訓練次數預設為600次。模型文件、初始權重文件均采用默認設置。
經過532次迭代訓練后,模型訓練結果如表1及圖6~9所示。
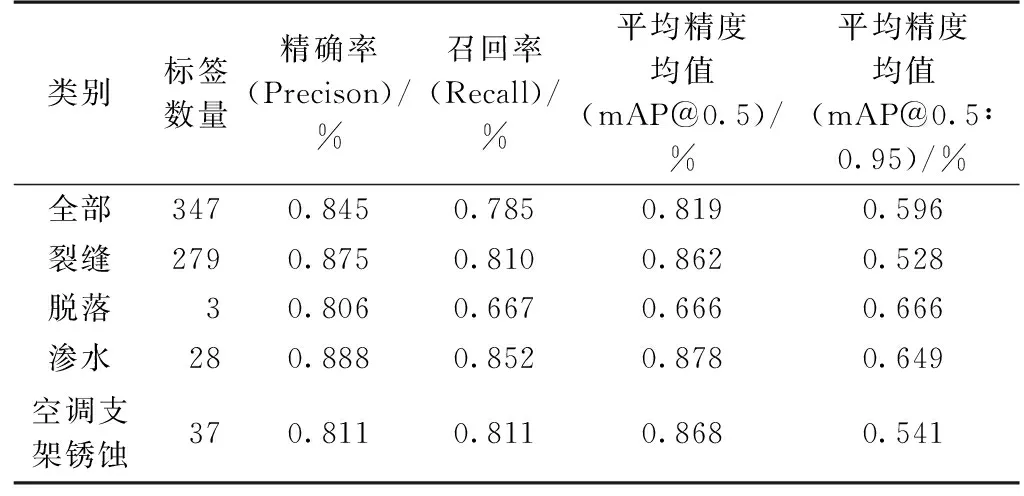
表1 模型訓練結果
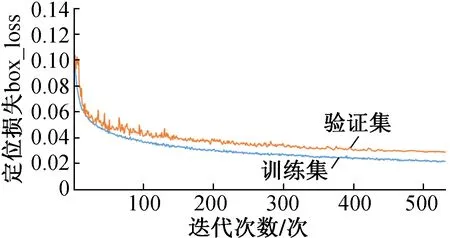
圖6 模型訓練定位損失變化曲線
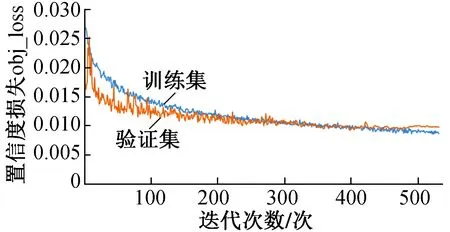
圖7 模型訓練置信度損失變化曲線
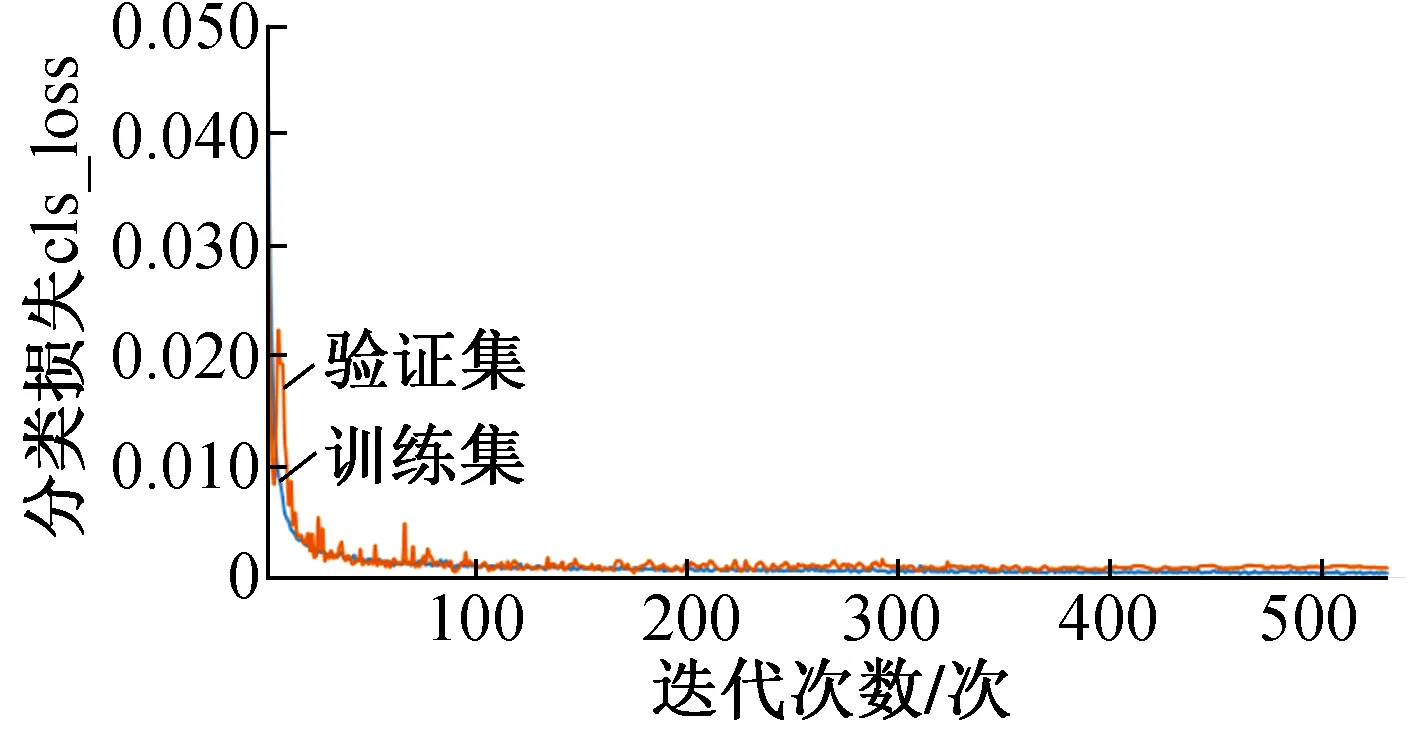
圖8 模型訓練分類損失變化曲線

圖9 模型訓練精度指標變化曲線
圖6~9中各參數解釋如下:①定位損失(box_loss) bounding box的損失均值,數值越小表示預測方框越準;②置信度損失(obj_loss) 目標檢測loss均值,數值越小表示目標檢測越準;③分類損失(cls_loss) 目標分類loss均值,數值越小表示目標分類越準;④精確率(Precision) 指總的目標識別結果中正確識別目標所占的比例,即找對的正類/所有找到的正類;⑤召回率(Recall) 指在總的目標中,被正確識別出來的目標所占的比例,即找對的正類/所有真正的正類;⑥平均精度均值(mAP@0.5) 表示閾值為0.5時的平均精度均值,mAP是用Precision和Recall作為兩軸作圖后圍成的面積,m表示平均,@后面的數表示判定iou為正負樣本的閾值;⑦平均精度均值(mAP@0.5∶0.95) 表示在不同IoU閾值(從0.5到0.95,步長0.05)上的平均精度均值。
2.4 損傷識別
利用已訓練好的YOLO模型對外立面損傷照片進行檢測時,被檢測照片分辨率應與訓練樣本照片分辨率一致,否則檢測效果會變差,甚至完全無法對目標進行檢測。可將被檢測照片切割為像素分辨率640×640的多張小照片后再對每張小照片進行檢測,然后將檢測結果重新拼接為一張完整的照片。上述功能可利用SAHI工具實現。
為了檢驗模型的識別效果,采用訓練得到的模型對測試集中的樣本進行測試。外立面損傷典型檢測結果如圖10所示。

圖10 外立面表觀損傷檢測結果
測試結果顯示,模型對測試集照片中大部分裂縫、脫落、滲水、空調支架銹蝕等外立面表觀損傷都能較好地識別出來,但也存在個別漏檢或誤檢情況。圖11中窗洞頂裂縫漏檢,圖12中空調管道陰影、晾衣架鋼絲繩、墻面污跡被誤檢為裂縫。將誤檢目標圖像作為背景圖像輸入網絡進行模型訓練,可減少誤檢情況發生,但目標漏檢與誤檢主要還是因為本次試驗所采用的訓練樣本量較小,當目標特征與背景特征相似度較高時,模型無法準確區分。因此,本研究下一步工作應擴充建筑外立面表觀損傷檢測的訓練數據集,提高模型對裂縫損傷特征的檢測能力。

圖11 裂縫漏檢(圓圈部位)

圖12 裂縫誤檢(空調管道陰影、晾衣架鋼絲繩、墻面污跡)
3 結語
1)建筑外立面表觀損傷高分辨率照片數據集通過圖像切片、圖像增強處理后,采用YOLOv5s模型訓練可達到較好的訓練效果。利用訓練好的模型,采用YOLO與SAHI集成框架可直接對建筑外立面損傷高分辨率照片進行檢測。
2)為了實現建筑外立面表觀損傷檢測,首先確定建筑外立面表觀損傷的類型,采用無人機采集建筑外立面損傷圖像。然后對圖像進行標注,制作數據集。將數據集輸入網絡進行訓練并驗證,最后得到建筑外立面表觀損傷檢測模型。在進行模型訓練之前,需通過人工標注方式建立數據集。數據集的建立包括數據采集、損傷標注、圖像切片、圖像增強、數據集切分等步驟。
3)本次檢測選取2幢高層建筑,采集了60張圖片,60張外立面損傷照片經過圖片切片處理后,得到1 383個帶有局部損傷標注的照片,該建筑外立面表觀損傷主要有裂縫、剝落、滲漏、空調支架銹蝕4種類型。對樣本數量較少的剝落類型樣本進行數據增強處理后,帶有局部損傷標記的照片增加到 1 663 個。經過532次迭代訓練后,平均精度均值達81.9%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
北方建筑(2021年6期)2021-12-31 03:03:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
文苑(2020年10期)2020-11-07 03:15:36
現代裝飾(2020年6期)2020-06-22 08:43:12
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
