輕量級可形變卷積神經(jīng)網(wǎng)絡DPCNs研究
2022-02-15 02:48:32通信作者周錄慶
信息記錄材料 2022年12期
趙 錁,賈 可(通信作者),李 航,周錄慶
(成都信息工程大學計算機學院 四川 成都 610225)
0 引言
目前,基于深度學習的目標檢測算法包括兩階段目標檢測算法和單階段目標檢測算法兩大類。兩階段目標檢測算法首先對輸入的圖像進行候選區(qū)域的選擇,然后對候選區(qū)域進行分類和定位。典型的兩階段目標檢測算法有:R-CNN、Fast R-CNN、Mask R-CNN等。而單階段目標檢測算法沒有候選區(qū)域選擇這一階段。典型的單階段目標檢算法有:YOLOv1、YOLOv2、SSD等。隨著科技的發(fā)展,目標檢測技術在生活中被廣泛使用[1-2]。然而卷積神經(jīng)網(wǎng)絡由于其構建模塊固定的幾何結構天然地局限于建模的幾何變換,導致檢測效果不理想,而可形變卷積可以提高模型對發(fā)生形變物體的建模能力。黃鳳琪等[3]提出一種基于可形變卷積的YOLO檢測算法。張善文等[4]在VGG的基礎上提出一種可形變VGG模型,應用于害蟲檢測。
雖然可形變卷積網(wǎng)絡在檢測精度上相較于普通卷積網(wǎng)絡有很大提升,但是可形變卷積會產(chǎn)生巨大的計算開銷,導致檢測速度降低。本文提出了一種方法:采用可形變逐點卷積來提升檢測速度。通過實驗證明,可形變逐點卷積同樣能夠增強卷積核對感受野的適應能力,來適應不同形狀和大小的幾何形變。除此之外,結合使用深度卷積和可形變逐點卷積所帶來的計算量相對較少,從而降低計算開銷,提升檢測速度。
1 本文方法
1.1 可形變逐點卷積
普通的卷積操作使用固定的卷積核,感受野范圍也相對固定,因此難以適應目標的非規(guī)則幾何形變。可形變卷積通過引入可學習的像素偏移量,使得卷積核不受固定位置的限制,可以進行伸縮變化,尋找最合適的感受野。但與普通卷積相比,可形變卷積引入了較高的額外計算量,主要用于其中所需的形變插值計算。針對以上問題,本文提出可形變逐點卷積,能有效地縮減計算量,降低計算消耗,在保持非規(guī)則感受野特性并獲得精度提升的同時,有效提高檢測速度。
在普通卷積中,設輸入特征圖為x,卷積核為w,x上任意一點P0的一個3×3采樣區(qū)R={(-1,-1),(-1,0),…,(0,1),(1,1)},則P0點對應輸出特征圖y上的操作如式(1)所示:
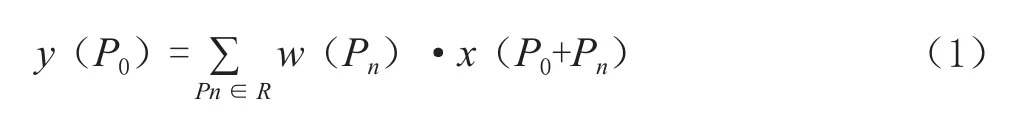
其中Pn枚舉了R中的每一個位置,最后對采樣點進行加權運算。
在可形變卷積中,引入偏移量{ΔPn|n=1,2,…,N},N=|R|,將經(jīng)過卷積計算得出的像素偏移量與原始像素位置相加后得到偏移后的位置,同時引入權重Δmn,那么同樣位置P0點的操作變?yōu)槿缡剑?)所示:
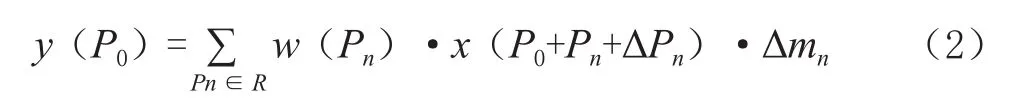
其中偏移量一般是小數(shù),因此可形變卷積是針對不規(guī)則區(qū)域進行卷積計算,需要進行如式(3)所示的雙線性插值:
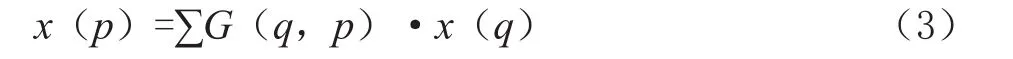
其中p=P0+Pn+ΔPn代表位置,q列舉了輸入特征圖x中的點,G為二維雙線性插值的核函數(shù),可以被分為兩個一維線性插值核函數(shù)如式(4)所示:
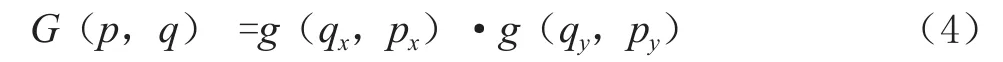
其中g(a,b)= max(0,1-|a-b|)。
與普通卷積式(1)相比,可形變卷積引入了較多的額外計算量,主要來自于式(2)中所含的雙線性插值計算。對于典型的ResNet-101主干網(wǎng)絡而言(如圖1(a)所示),常見的方式是將多個殘差塊中的3×3卷積替換為可形變卷積,即圖1(b)所示的結構。在此情況下,對每一次卷積滑窗的計算而言,3×3可形變卷積會進行3×3×C次雙線性插值,其中C為該特征圖的通道數(shù),而每一次插值計算會進行4次乘加運算,那么總共會額外進行3×3×C×4次乘加運算,帶來顯著的速度損失。
由于可形變卷積引入的額外計算主要來自于對特征圖進行插值,且計算量與卷積核大小呈二次方關系,因此在可形變逐點卷積中,將形變計算移動至殘差塊中的最后一個1×1卷積上進行,即如圖1(c)所示。將其放置于殘差塊中的第一個1×1卷積之上也可以達到類似的效果,但研究人員實驗證明放在最后效果會稍好。在可形變逐點卷積中,由于每次滑窗只需要對一個特征點進行采樣插值,其產(chǎn)生的偏移量和進行雙線性插值的次數(shù)更少,只會進行1×1×C次插值運算,總共進行1×1×C×4次乘加運算,因此其引入的額外計算量僅僅只有傳統(tǒng)可形變卷積的1/9。此外1×1卷積核在特征圖上進行滑窗卷積時不會因為特征被重復使用而產(chǎn)生額外的計算量。
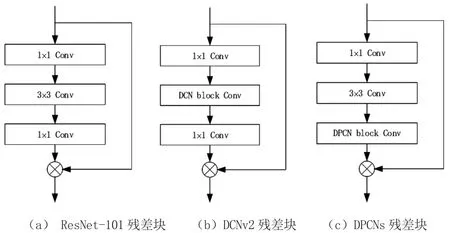
圖1 不同類型殘差塊
將可形變卷積作用于1×1卷積,帶來的問題在于每次只表達了一個特征點的整體偏移,是否能夠帶來足夠的形變適應性。對此,研究人員認為,在可形變卷積網(wǎng)絡中,可形變卷積一般并不是只用一次,而是在每一個殘差塊,或是每一尺度的卷積網(wǎng)絡階段中都會引入一個可形變卷積層。雖然每次的形變計算只作用于一個特征點上,但經(jīng)過前后多次的偏移變換后,這些偏移量幾乎不會重復或呈簡單線性關系,因此仍然具有足夠的形變適應性,能夠計算出足夠復雜的變形感受野,并因此獲得比普通卷積更高的檢測精度,研究人員的實驗結果也證明了這一方式的有效性。
1.2 深度卷積與可形變逐點卷積
深度可分離卷積是一種常用的輕量級卷積神經(jīng)網(wǎng)絡結構,其主要特點是將普通卷積分解成深度卷積和逐點卷積。相對于普通卷積,這種方式可以在精度損失有限的情況下,減少計算量和參數(shù)量,從而提升檢測速度。深度可分離卷積的矩陣分解優(yōu)化方式,與本文所提出的可形變逐點卷積具有天然良好的結合性。通過將深度可分離卷積中的逐點卷積替換為可形變逐點卷積的方式,不僅可以有效保持輕量級卷積神經(jīng)網(wǎng)絡快速敏捷的優(yōu)點,同時又能改善其性能并提高檢測精度。
設定輸入特征圖為C×H×W,與N個C×k×k大小的卷積核進行卷積得到的輸出特征大小為H×W×N,所產(chǎn)生的計算量為C×H×W×k×k。經(jīng)過深度卷積的輸出大小為C×H×W,產(chǎn)生的計算量為C×H×W×k×k。而經(jīng)過逐點卷積產(chǎn)生的計算量為C×H×W×N。那么總體來說深度可分離卷積和普通卷積的總計算量之比如式(5)所示:
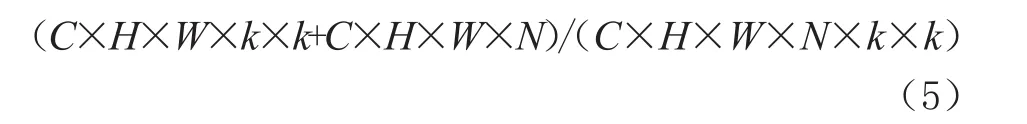
由于一般情況下N取值較大,如果采用3×3卷積,由式(5)可以得出深度可分離卷積相較于普通卷積可以降低大約9倍的計算量。
由于逐點卷積實際上就是卷積核大小為1×1的普通卷積,而可形變逐點卷積同樣可以有效適應不規(guī)則物體,讓感受野發(fā)生形變使得檢測的精度得到提升。因此研究人員在深度可分離卷積中引入可形變逐點卷積替代普通的逐點卷積。通過實驗證明,在速度損失有限的情況下,精度得到了進一步的提升。
2 實驗
2.1 實驗設置和數(shù)據(jù)集介紹
本文實驗基于Pytorch深度學習框架,測試平臺GPU型號為Nvidia GeForce RTX 2080 Ti,CPU型號為Intel Xeon E5-2678 v3。本文實驗采用COCO數(shù)據(jù)集,包含91種類別、32.8萬張圖像和250萬個標注[5]。
2.2 評價指標
本文實驗主要使用平均精度(average precision,AP)和幀率(frames per second, FPS)來評價模型的有效性。另外FLOPs是指浮點運算數(shù),param表示模型的參數(shù)量。
2.3 實驗結果和分析
表1展示了選取Mask-RCNN作為基本檢測框架,ResNet-50和ResNet-101分別作為主干網(wǎng)絡,常規(guī)卷積神經(jīng)網(wǎng)絡、DCNv2以及本文提出的DPCNs在COCO數(shù)據(jù)集上的性能表現(xiàn)情況。
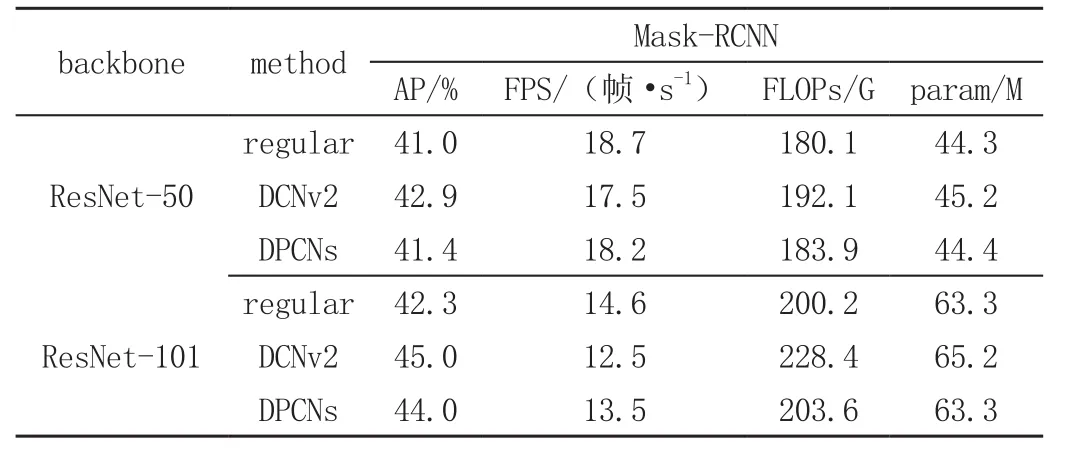
表1 三種方法檢測性能對比
可以看出,以ResNet-101作為主干網(wǎng)絡,使用可形變逐點卷積,雖然精度相比3×3可形變卷積有所下降,但是仍然高于普通3×3卷積1.7%,這在數(shù)值上說明使用可形變逐點卷積可以通過改變感受野的形狀提升檢測精度。可形變逐點卷積在FPS上比3×3可形變卷積有所提升,這從數(shù)值上表明可形變逐點卷積能有效地提升檢測速度。由于整個計算過程除了插值計算還有其他卷積計算,所以可形變逐點卷積達不到減少大約9倍的計算量。在參數(shù)量上,可形變卷積最多,其余兩個相對較少。圖2(a)(b)則分別展示3×3可形變卷積和可形變逐點卷積的特征點感受野,可以看出可形變逐點卷積同樣可以自適應的學習感受野的采樣位置來符合物體的形狀和大小,從而更有效的提取特征。

圖2 特征點感受野
表2展示了選取Mask-RCNN作為基本檢測框架,MobileNetv2和本文提出的dw-DPCNs在COCO數(shù)據(jù)集上的性能表現(xiàn)。可以看出,使用本文提出深度卷積結合可形變逐點卷積倒殘差塊的dw-DPCNs的精度達到了35.6%,相較于使用普通深度可分離卷積倒殘差塊的MobileNetv2的精度提升了1.3%。此外dw-DPCNs的FPS略微下降,F(xiàn)LOPs則略微上升。這是由于可形變逐點卷積需要進行插值計算,增加了額外的計算量,從而導致檢測速度的下降。而這兩種模型的參數(shù)量一致,能體現(xiàn)出本文提出的dw-DPCNs與MobileNetv2有相同輕量化的優(yōu)點。

表2 兩種方法檢測性能對比
3 結語
本文針對使用3×3可形變卷積計算開銷過大而導致檢測速度變慢的問題,提出一種輕量級可形變卷積神經(jīng)網(wǎng)絡結構,使得模型在檢測的速度上有所提升。通過實驗證明,可形變逐點卷積相較于3×3可形變卷積同樣可以自適應的學習感受野的采樣位置來符合物體的形狀和大小,從而更有效的提取特征,并且所產(chǎn)生的計算量更少,提高了檢測的速度。尋找其他方法來減少可形變卷積的計算消耗是下一步繼續(xù)研究的方向。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
