一種支持多數據塊混合處理的FFT優化方法
2022-02-13 14:32:56洪欽智王志君郭一凡梁利平
西安電子科技大學學報 2022年6期
關鍵詞:設計
洪欽智,王志君,郭一凡,梁利平
(1.中國科學院微電子研究所,北京 100029;2.中國科學院大學 集成電路學院,北京 100049;3.北京郵電大學 集成電路學院,北京 100876)
快速傅里葉變換(Fast Fourier Transform,FFT)是一種用來實現時域到頻域轉換的計算方法,被廣泛應用于各種通信系統中。當前許多基于正交頻分復用技術(Orthogonal Frequency Division Multiplexing,OFDM)的通信系統,如4G LTE(Long Term Evolution)/LTE-A[1]、無線本地局域網(Wireless Local Area Network,WLAN)[2],以及正在推廣的5G NR(New Radio)系統[3],都使用了FFT技術。隨著無線通信標準的演進,通信系統對FFT技術的要求也越來越高[4-5]。未來的高質量多模通信系統[6-8]要求FFT處理器適配多種點數模式的FFT處理和離散傅里葉變換(Discrete Fourier Transform,DFT)處理,并且能夠達到極高的吞吐率和處理效率。
傳統的FFT處理器主要包括流水線型和存儲器型兩種實現結構,流水線型結構較難同時滿足高吞吐率和較多點數模式的支持[9],而面向多模通信應用的FFT處理器主要采用存儲器型結構[10-13]。文獻[11]采用素因子算法實現了128~2 048點FFT處理和12~1 296點DFT處理。文獻[12]提出了一種針對任意點數的無沖突地址策略,并通過高基底的方式來減少運算周期。文獻[13]通過設計高效的并行運算部件及改進數據并行訪問策略等方法有效地支持了多點數處理(54種模式)和較高的1R(基1歸一化)吞吐率。但是這些設計依然存在不同模式下吞吐率不均衡、絕對吞吐率較低等問題。
面向以4G/5G為代表的高性能多模通信應用,筆者通過有效的優化設計實現了一種支持60種點數模式的高性能FFT處理器。設計了一種基于WFTA(Winograd Fourier Transform Algorithm)算法的深度流水蝶形運算單元,支持1個基9/ 2個基8/ 3個基5/ 4個基4/ 5個基3的高吞吐率蝶形運算;提出了一種支持多FFT數據塊混合處理的計算方法(REPEAT模式),有效解決了深度流水線氣泡導致的吞吐率降低問題,實現了各種點數模式下的吞吐率均衡;還完成了支持多FFT數據塊混合處理的塊浮點處理電路的設計,并以此為基礎完成了多模高性能FFT處理器的實現。相比現有的設計,筆者設計的FFT處理器實現了更多點數模式的支持,并且在增加有限資源的情況下較大幅度提高了處理器性能。
1 設計思路與理論分析
面向4G/5G小基站芯片中的FFT/DFT運算加速需求,以及需要支持64~4 096點的FFT/IFFT(Inverse FFT,快速傅里葉逆變換)和12~3 240點的DFT/IDFT(Inverse DFT,離散傅里葉逆變換)的運算需求(共計60種點數模式);同時,4G/5G小基站的基帶信號處理需要滿足極高的吞吐率要求。考慮到需要同時滿足高吞吐率和對多種點數模式的支持,筆者設計采用基于存儲器的實現結構。
基于存儲器結構的FFT處理器在完成一個N點FFT的運算過程中,總的周期數由運算周期和數據搬運周期構成,數據搬運周期包括數據搬入(存儲器)周期和數據輸出(存儲器)周期。當存儲器采用2N的乒乓結構時,數據輸入、數據輸出可以流水執行。假設數據輸入、輸出和運算的存儲器訪問并行度為s,則對于一個N點FFT運算,輸入周期和輸出周期為N/s。對于2N結構,數據輸入和數據輸出可以流水執行,總的輸入輸出周期C0=N/s。對于采用混合基算法的FFT運算,N點FFT可以分解成k級的混合基運算L0×L1×…×Lk-1,其中第i級的運算需要執行基為Li的蝶形運算,運算個數為L0×L1×…×Li-1×Li+1×…×Lk-1。假設各級運算過程中,從存儲器中讀出的數據都可以進行蝶形運算,則第i級每個周期可以執行基Li蝶形運算的個數為s/Li。完成第i級所需的周期數如式(1)所示,完成各級運算的總周期為kN/s。
(1)
考慮到蝶形運算單元并不能保證每個周期都滿負荷地完成并行度s的點數計算,假設運算單元的平均資源利用率為p1,則實際的運算并行度為p1s,完成各級的總運算周期C1=kN/(p1s)。另一方面,處理流程中還有許多因素會消耗額外的周期,包括為了確保處理器能在一定的頻率下,數據通路需要插入一定流水級引入的流水周期和在不同的尋址方式下存儲器訪存需要引入的調度周期等。假設每級運算額外引入的周期開銷為Cp,則k級運算引入的額外周期數為C2=kCp。定義額外消耗周期與運算周期比p2=C2/C1,則總周期數為
(2)
FFT處理器的性能指標主要包括吞吐率和1R吞吐率,其中吞吐率表示單位時間可以完成FFT計算的點數,1R吞吐率則是表征電路工作在1 Hz下的吞吐率。由式(2)可得吞吐率的計算公式為
(3)
由式(3)可知,FFT處理器的吞吐率與并行度、運算頻率成正比,還受混合基的分解級數、運算部件的資源利用率p1和表征時序周期效率的因子p2影響。
2 一種支持多數據混合運算的可配置高性能FFT處理器
基于前述對影響FFT處理器性能的因素進行的建模與分析,筆者以面向4G/5G小基站基帶處理的FFT運算加速為目標,通過優化設計提高FFT處理過程的資源利用效率和時序利用效率來優化處理器性能。
設計的FFT處理器整體架構如圖1所示,采用并行度為16的存儲器架構,計算位寬為16I+16Q。FFT運算數據和相應的配置參數通過數據接口進行傳輸。控制通道根據接收到的配置參數來控制FFT運算的整體流程。FFT運算數據首先存入PPmem中(PPmem0/PPmem1,乒乓存儲器),而后根據執行的FFT運算模式從PPmem中尋址出數據并送入蝶形運算單元進行運算。旋轉因子生成模塊根據配置信息尋址出對應的旋轉因子來參與運算。蝶形運算單元基于當前的控制信息配置成相應的運算模式。在完成相應的蝶形運算后,數據通過乒乓選通邏輯寫回到PPmem中。與此同時,塊浮點處理單元用來完成運算過程中FFT指數的更新操作。

圖1 FFT處理器結構圖
2.1 基于WFTA算法的可配置蝶形處理單元
通過對所需支持的60種點數進行分解,需要至少支持基3、基4、基5的蝶形運算,并且對出現較多的多級基3和基4進行合并,通過支持基8、基9來減少級數。WFTA算法[14]是一種能有效控制蝶形運算資源的算法,筆者以統一的WFTA分解來完成基3、基4、基5、基8、基9蝶形運算單元的設計。
根據各種基下的WFTA算法運算流程,抽象出蝶形運算電路的基本結構,如圖2所示,該結構包含了前級加法運算,中間級常數乘法運算和后級加法運算。以級聯計算最復雜的基9 WFTA運算為例,包含了9個輸入數據,前級加法進行了3輪加法運算,中間級進行常數乘法運算,后級加法進行了3輪加法運算,而后并行輸出9個運算結果數據。其它的基8、基5、基4、基3 WFTA蝶形運算的整體運算流程類似,通過控制相應的數據選通,蝶形運算單元將復用這些運算器重構成相應基的WFTA蝶形運算電路。
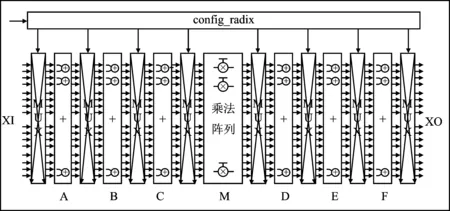
圖2 WFTA蝶形單元結構圖

表1 不同基底運算器資源占用
基于統一的WFTA算法,各種基底下的運算流程統一,實現的電路結構化,可以很好地進行復用和流水化處理。單元電路在復用的運算部件上完成了一路基9、兩路基8、三路基5、四路基4、五路基3的功能實現,并根據延時數據進行較為均衡的流水線化處理,在55 nm工藝下運算電路工作頻率達到500 MHz,確保了較高的運算性能。不同基底(Radix-X表示基X)占用的運算資源如表1所示。從表1可以看出,采用這樣的復用關系,在運算器配置成不同基底的運算模式時,所需的運算資源比較接近。因此,采用這樣的復用結構,可以確保在不同的運算模式下,空間效率因子保持較高的值。表2給出與其它文獻的蝶形單元完成一次蝶形運算(各種基)所需的周期對比。

表2 蝶形單元計算周期對比
2.2 一種支持多數據塊混合運算的FFT計算方法
為了提高處理器的吞吐率性能,通過對蝶形單元數據通路進行流水線化操作來提高整體電路的運行頻率。但是基于混合基算法的FFT處理各級蝶形運算之間存在數據相關性,即后級的蝶形運算需在前一級蝶形運算全部完成后才能進行,這種數據相關性會降低基于存儲結構的FFT處理器運算器的時間利用率,特別是當數據通路的流水級數較多時會引入較多的流水線氣泡而降低處理器性能。
筆者提出了一種新的FFT計算方法,采用多FFT數據塊混合運算來提高FFT處理器的時間利用效率,稱這種計算方法為REPEAT模式。該模式通過實現多個FFT數據的混合計算,解決了傳統計算方法下基于存儲器結構的FFT處理器因為混合基算法不同級間數據運算相關和流水線氣泡導致的吞吐率下降問題。
圖3為REPEAT模式的執行流程,通過同時將多個相同點數的FFT數據塊存入存儲器中,并且順序地完成不同FFT數據塊的混合基中相同級的蝶形運算,解決同一個FFT數據塊不同級間的數據相關導致的流水線氣泡問題。為了支持REPEAT模式,FFT處理器需要對多個FFT數據進行混合蝶形運算。筆者充分利用所支持最大點數(4 096)對應的存儲器MEM空間來提供不同的并行度支持。表3為筆者設計支持的60種模式的點數列表以及相應的REPEAT模式并行度。基于此設計,支持REPEAT模式的FFT處理器不需要增加額外的存儲器MEM空間和運算資源,只需要通過尋址控制來選通相應的數據。

圖3 REPEAT模式執行流程

表3 FFT處理器支持點數及REPEAT模式并行度
以12點FFT運算為例來闡述REPEAT模式的優化過程。圖4(a)為12點FFT數據從MEM讀出,通過數據通路再寫回MEM的流水線圖。12點FFT根據混合基算法分解為基3和基4兩級運算,其中第1級包含了4個基3運算,第2級包含了3個基4運算。蝶形運算單元可以支持5個基3或4個基4的并行運算,因此12點FFT的第1級運算和第2級運算都只需1個計算周期完成。如圖4(a)所示,第1個周期從存儲器取出12個點FFT數據并進行第1級4個基3運算,由于深度流水線的影響,需等到第10個周期,數據才能寫回存儲器,而后數據再次從存儲器讀出,進行第2級的3個基4運算。
從圖4(a)可以看出運算單元的利用率很低,10級流水中只有1個周期處于有效運算狀態,其他周期都處于空閑狀態。基于存儲器結構的FFT處理器,在進行混合基算法處理時,每級運算都需等待上一級運算完成后才能開始;這種數據依賴關系導致了運算單元無法被充分利用,數據通路流水線引入氣泡。
圖4(b)為REPEAT模式的處理流程。在第1個周期讀取第1個FFT數據塊進行第1級蝶形運算后,第2個周期讀取第2個FFT數據塊進行第1級蝶形運算,同樣,順序讀取不同FFT數據塊進行第1級蝶形運算,直到完成所有FFT數據塊的第1級蝶形運算;以此類推,順序讀取不同FFT數據塊進行第2級蝶形運算,以此順序完成所有FFT數據塊的各級蝶形運算。對比圖4(a)的單個點數FFT處理,圖4(b)的REPEAT模式流水線中有效運算周期的占比明顯提升。
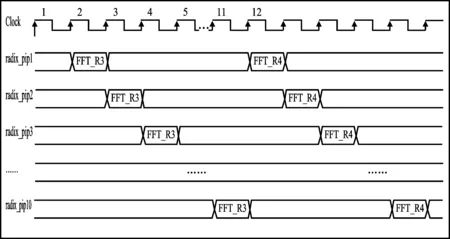
(a) 單數據模式
結合式(2)、式(3)推導可以分析各種點數模式下的普遍情況。對時間效率因子進行分析,p2=C2/C1。對于12點FFT運算,當p1/p2都為最高效率時(p1=1,p2=0),吞吐率為5.3R,而當p2下降到9時(p1=1),吞吐率下降為0.76R。基于式(3)考慮p2對吞吐率的一般性影響,假設p1=1(即空間資源利用率最高),可得
(4)
根據式(4),當p2=0時可得各點數下的理想吞吐率。考慮實際p2值可得p2影響下的吞吐率。如圖5(a)對不同點數的理想吞吐率和受p2影響得到的1R吞吐率進行比較(橫坐標為60種點數,由小到大排列)。可以看出流水線氣泡導致的吞吐率下降,這也是許多已有研究里不同點數吞吐率不均衡,一些點數的吞吐率存在明顯短板的主要原因。并且,隨著流水線深度的加深,流水線氣泡導致的吞吐率下降會越發明顯,導致了基于存儲器結構的FFT處理器難以提升工作頻率。圖5(b)為REPEAT模式和單數據模式下,60種點數FFT運算的1R吞吐率對比;可以明顯看出,REPEAT模式可以很好地均衡各點數下的吞吐率,確保在所有點數模式下硬件處理都具有較高的效率。
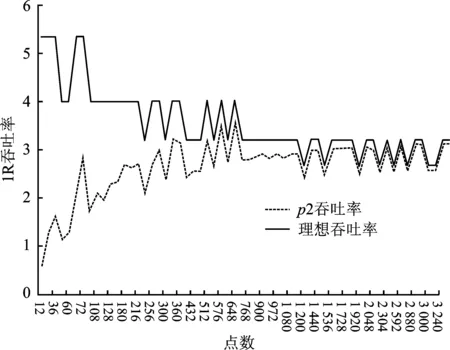
(a) p2對吞吐率的影響
2.3 支持REPEAT模式的快浮點處理電路架構
當前的FFT處理器往往采用塊浮點處理,可以在不需過多增加硬件資源的情況下提高FFT處理的精度。傳統的塊浮點處理系統只能處理同一個FFT數據。筆者提出了一種可以支持不同FFT數據混合運算的塊浮點處理電路架構,以支持REPEAT模式的混合數據處理。
FFT數據從存儲模塊中取出進入蝶形運算單元,完成蝶形運算后寫回存儲模塊。塊浮點處理單元偵測每周期蝶形運算單元的計算結果并進行塊浮點的定標移位值計算,在完成某FFT數據的某級蝶形運算后,塊浮點處理單元將最終計算的定標移位值存入移位值寄存器堆,同時塊浮點處理單元利用計算完成的定標移位值來同步更新指數值,并存入指數寄存器堆。由于塊浮點處理的指數是共用的,只有當完成某個FFT的一級蝶形運算后才能得到該FFT數據的共同移位值(對應指數的更新值),中間的蝶形運算結果直接寫回存儲模塊,只在下一級蝶形運算取數時進行移位處理。基于圖3所示REPEAT模式的執行時序,當采用不同FFT數據進行混合運算時,在同一級FFT運算時會順序地執行各個FFT數據在該級的蝶形運算。筆者設計了相應的移位值更新電路和指數值更新電路來實現FFT數據混合運算下的塊浮點處理

(a) 移位值更新電路結構
如圖6(a)所示,移位值更新電路在混合基運算的每級蝶形運算內,根據當前處理的是第幾個FFT數據來使能移位值寄存器堆中對應的移位值寄存器,并按照更新規則進行移位值運算和更新。每次FFT數據切換時產生相應的片選信號來切換對應的移位值寄存器。在蝶形運算讀數階段,控制單元會根據當前讀取的是第幾個FFT數據來生成蝶形輸入指針,移位值更新電路根據蝶形輸入指針輸出所需移位值。
圖6(b)為指數值更新電路,用來更新和存儲不同FFT數據相對應的指數值。在FFT數據輸入階段,各FFT數據相應的指數值按順序寫入到指數值寄存器堆中。在進行FFT運算過程中,當每次完成一個FFT數據的移位值更新時,相應從指數值寄存器堆中取出該FFT數據對應的指數值,與當前移位值進行運算,而后將運算結果寫回指數值寄存器中。
3 實現結果和討論
采用中芯國際55 nm CMOS工藝對設計進行了流片驗證,圖7為設計實現的物理版圖。FFT處理器的內核面積為1.59 mm2。最高工作頻率達到500 MHz。此外,提出的優化方法已經應用在最新的4G/5G小基站基帶SoC芯片中。

圖7 FFT處理器版圖
筆者對提出的設計在各種點數模式下進行了仿真實驗,收集了執行各種點數FFT運算的周期數,表4給出了典型點數下文中設計與文獻[11]、文獻[13]的周期數對比。從表4中可以看出,文中設計大部分點數所需的計算周期都更少。當采用REPEAT模式進行FFT計算時,等效總周期數明顯降低,特別是對于運算周期數占比較小的點數,性能可以獲得數倍的提升,與理論分析和設計考量一致。表5給出了在典型點數下文中設計的FFT吞吐率與文獻[11]、文獻[13]的對比,可以看出文中設計的吞吐率性能有較大提升,REPEAT模式下各種點數的吞吐率也更為均衡。

表4 典型點數下FFT處理周期比較
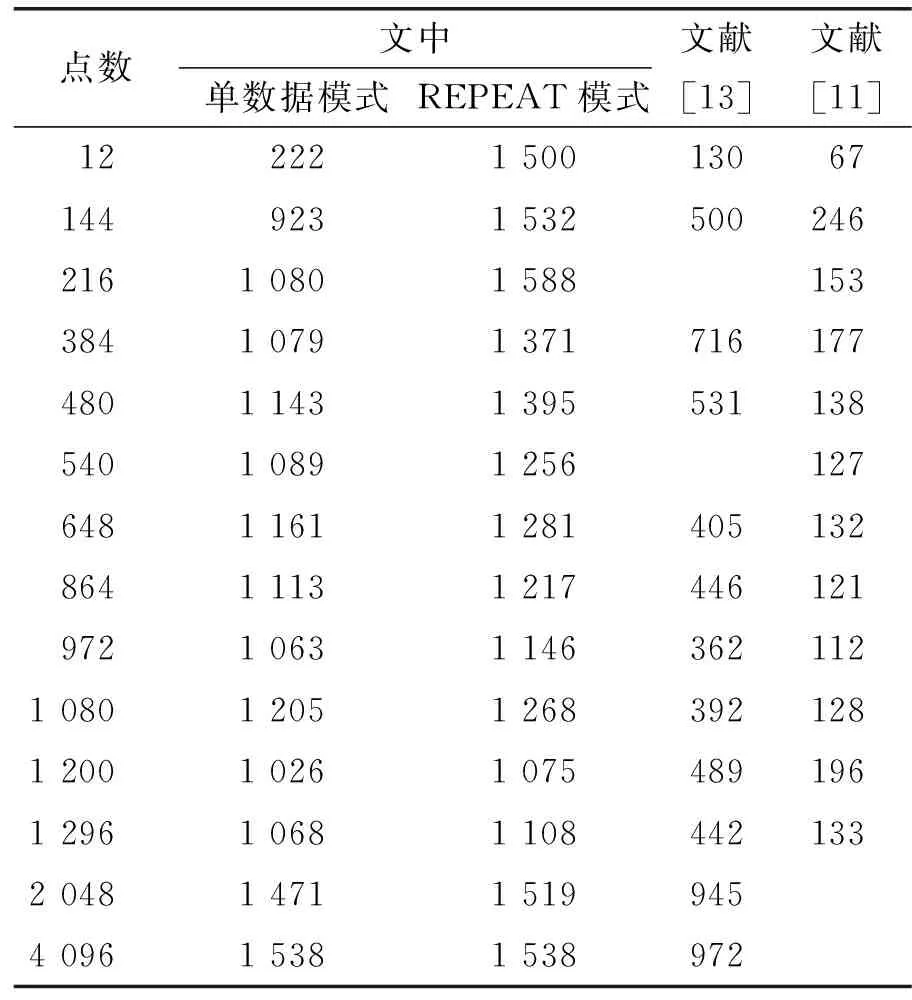
表5 典型點數下FFT吞吐率對比
為了對不同工藝、計算位寬、電壓、運行頻率下的處理器進行對比,筆者采用文獻[13]給出的歸一化方法對吞吐率進行面積、功耗層面上的歸一化處理,分別如式(5)、式(6):
(5)
(6)
表6是文中設計各項指標與文獻[11-13]的設計進行的對比。從表6可以看出,基于筆者提出的優化方法設計的FFT處理器在增加有限資源開銷的情況下,能夠支持更多的計算模式,吞吐率也有較大的提升,且1R吞吐率在各種點數模式下也更為均衡。

表6 FFT處理器實現指標對比
4 總 結
面向4G/5G基帶處理對FFT計算提出的高吞吐率、多模式的應用需求,提出了一種可以同時支持多個FFT數據混合處理的優化方法。該方法可以有效解決基于存儲器架構的FFT處理器因為計算通路流水線氣泡而導致的性能損失以及由此帶來的不同點數的吞吐率均衡問題。在設計了一種高效的深度流水線可配置蝶形處理單元和支持REPEAT模式的塊浮點處理電路的基礎上,實現了一種高性能多模式FFT處理器。在增加較少資源的情況下,比起其他文獻只能在部分模式下達到較高的歸一化性能。筆者設計的FFT處理器實現了各種點數模式下較為均衡的歸一化性能,并且在相同工藝條件下較大幅度提高了吞吐率性能,同時支持更多的點數模式。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
