基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合算法
2022-02-11 13:33:38莫慧凌鄭海峰馮心欣
計(jì)算機(jī)研究與發(fā)展 2022年2期
莫慧凌 鄭海峰 高 敏 馮心欣
(福州大學(xué)物理與信息工程學(xué)院 福州 350108)
在信息化時(shí)代,海量的邊緣數(shù)據(jù)將給以云計(jì)算模型為核心的數(shù)據(jù)集中化處理模式帶來(lái)許多問(wèn)題,一是將數(shù)據(jù)全部上傳至云端的處理方式,不僅效率低下,而且造成額外的帶寬開(kāi)銷,同時(shí)網(wǎng)絡(luò)延遲也會(huì)增加.二是由于用戶隱私意識(shí)的提高,邊緣設(shè)備的數(shù)據(jù)很有可能在上傳鏈路時(shí)泄密,個(gè)人隱私的安全問(wèn)題無(wú)法得到保障.而分布式數(shù)據(jù)處理模式可以有效地解決傳統(tǒng)云計(jì)算存在的時(shí)延和效率問(wèn)題.同時(shí),針對(duì)“數(shù)據(jù)孤島”問(wèn)題,谷歌公司首次提出了“聯(lián)邦學(xué)習(xí)”這個(gè)概念.通過(guò)在多個(gè)邊緣設(shè)備上利用各自的訓(xùn)練樣本對(duì)模型進(jìn)行單獨(dú)的訓(xùn)練,并通過(guò)模型參數(shù)聚合實(shí)現(xiàn)在不透露用戶隱私的前提下多源信息的共享.
此外,邊緣設(shè)備的多樣性使得設(shè)備采集到的數(shù)據(jù)在標(biāo)注、語(yǔ)義和存在形式等方面都呈現(xiàn)多樣性.多模態(tài)數(shù)據(jù)廣泛存在.不同的模態(tài)數(shù)據(jù)可以從多個(gè)方面描述目標(biāo)對(duì)象,通過(guò)消除冗余數(shù)據(jù)和融合各種數(shù)據(jù)源進(jìn)行關(guān)聯(lián)補(bǔ)充分析,數(shù)據(jù)可以涌現(xiàn)出更多有價(jià)值的新信息,從而實(shí)現(xiàn)1+1>2的效果.從互聯(lián)網(wǎng)和移動(dòng)設(shè)備收集的多媒體數(shù)據(jù)是典型的非結(jié)構(gòu)化數(shù)據(jù),與傳統(tǒng)的易于存儲(chǔ)的結(jié)構(gòu)化數(shù)據(jù)格式存在顯著差異.因此,對(duì)不同邊緣設(shè)備采集到的多源異構(gòu)數(shù)據(jù)處理成為大數(shù)據(jù)研究中亟需解決的問(wèn)題.
在傳統(tǒng)的多源異構(gòu)數(shù)據(jù)融合算法中,數(shù)據(jù)集中化處理在實(shí)際應(yīng)用中存在數(shù)據(jù)隱私泄露的風(fēng)險(xiǎn).因此,對(duì)于不透露用戶隱私前提下的多源異構(gòu)數(shù)據(jù)處理還存在許多難題:首先,由于企業(yè)競(jìng)爭(zhēng)和用戶的隱私保護(hù)意識(shí),使得數(shù)據(jù)互通長(zhǎng)期處于閉塞狀態(tài),無(wú)法實(shí)現(xiàn)信息共享,從而無(wú)法充分發(fā)揮異構(gòu)數(shù)據(jù)的價(jià)值.其次,利用神經(jīng)網(wǎng)絡(luò)對(duì)數(shù)據(jù)進(jìn)行處理,根據(jù)數(shù)據(jù)設(shè)計(jì)的模型一旦確定后就無(wú)法更改.然而在邊緣計(jì)算中,邊緣設(shè)備所采集的數(shù)據(jù)結(jié)構(gòu)和種類數(shù)目存在差異.若針對(duì)各個(gè)網(wǎng)絡(luò)邊緣設(shè)備上的數(shù)據(jù)設(shè)計(jì)適用于各自數(shù)據(jù)特征的神經(jīng)網(wǎng)絡(luò),工作量極大,同時(shí)該模型只能適用于單一節(jié)點(diǎn)或者和該節(jié)點(diǎn)數(shù)據(jù)特征相同的邊緣設(shè)備,普適性不高,也無(wú)法充分發(fā)揮物聯(lián)網(wǎng)中其他的異構(gòu)數(shù)據(jù)的價(jià)值.
為解決邊緣計(jì)算中,在不泄露用戶隱私的前提下實(shí)現(xiàn)多源異構(gòu)數(shù)據(jù)的融合問(wèn)題,本文提出了一種基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合算法.從邊緣設(shè)備采集到的數(shù)據(jù)結(jié)構(gòu)特點(diǎn)入手,結(jié)合張量Tucker分解理論,研究能夠在各異的邊緣設(shè)備上自適應(yīng)處理多源異構(gòu)數(shù)據(jù)模型,解決聯(lián)邦學(xué)習(xí)中由于處理異構(gòu)數(shù)據(jù)的模型不統(tǒng)一帶來(lái)的單一適應(yīng)性問(wèn)題.
1 相關(guān)工作
目前,針對(duì)聯(lián)邦學(xué)習(xí)以及異構(gòu)數(shù)據(jù)融合的研究已經(jīng)取得了眾多的成果.
1.1 聯(lián)邦學(xué)習(xí)
由于移動(dòng)設(shè)備和邊緣設(shè)備的廣泛使用,Yang等人提出的一種人工智能技術(shù)——聯(lián)邦學(xué)習(xí),是由一個(gè)中央服務(wù)器協(xié)調(diào)多個(gè)客戶端在不公開(kāi)數(shù)據(jù)的前提下,協(xié)同完成一個(gè)學(xué)習(xí)任務(wù).
聯(lián)邦學(xué)習(xí)有很多優(yōu)點(diǎn).首先,相比于云計(jì)算模型,聯(lián)邦學(xué)習(xí)只發(fā)送更新的模型參數(shù)進(jìn)行聚合,這極大降低了數(shù)據(jù)通信的成本,提高了網(wǎng)絡(luò)帶寬的利用率.其次,用戶的原始數(shù)據(jù)不需要發(fā)送至云端,這避免了數(shù)據(jù)在上傳鏈路時(shí)泄露用戶隱私的可能.再者,聯(lián)邦學(xué)習(xí)的模型訓(xùn)練可以在邊緣節(jié)點(diǎn)或終端設(shè)備上進(jìn)行訓(xùn)練和實(shí)時(shí)決策,時(shí)間延遲會(huì)比在云端進(jìn)行決策時(shí)得到極大地改善.
在聯(lián)邦學(xué)習(xí)中,數(shù)據(jù)安全是一個(gè)主要研究方面.Mcmahan等人提出了用戶級(jí)的差分隱私訓(xùn)練算法,通過(guò)將隱私保護(hù)添加到聚合算法中,有效地降低了從傳輸模型中恢復(fù)個(gè)人信息的可能.另一方面,Beimel等人提出了差分隱私混合模型,通過(guò)用戶的信任偏好對(duì)用戶進(jìn)行分區(qū),從而減少所需用戶基數(shù)的大小.Dong等人將梯度選擇和秘密分享的算法結(jié)合起來(lái),在保證用戶隱私和數(shù)據(jù)安全的情況下大幅提升了通信效率.
在聯(lián)邦學(xué)習(xí)中的資源優(yōu)化方面,Tran等人考慮通過(guò)無(wú)線網(wǎng)絡(luò)進(jìn)行聯(lián)邦學(xué)習(xí),提出了優(yōu)化能源消耗和全球聯(lián)邦學(xué)習(xí)時(shí)間的問(wèn)題.Wang等人提出了一種控制算法,可以在全局參數(shù)聚合和局部模型更新之間進(jìn)行權(quán)衡,以在資源預(yù)算約束下將損失函數(shù)降至最低.Wang等人提出了一種聯(lián)邦學(xué)習(xí)框架In-Edge-AI,以實(shí)現(xiàn)邊緣計(jì)算中的智能資源管理.
1.2 多源異構(gòu)數(shù)據(jù)融合
數(shù)據(jù)融合系統(tǒng)中的數(shù)據(jù)逐漸多元化且數(shù)量巨大,這迫使人們對(duì)系統(tǒng)效率的提高有了更高的要求.Microsoft研究院的Zheng將異構(gòu)數(shù)據(jù)融合方法分為3種類型:1)基于階段的數(shù)據(jù)融合方法;2)基于特征的數(shù)據(jù)融合方法;3)基于語(yǔ)義的數(shù)據(jù)融合方法.
基于階段的數(shù)據(jù)融合方法是指在數(shù)據(jù)挖掘的過(guò)程中,不同階段利用不同的數(shù)據(jù)進(jìn)行分析.Pan等人首先使用GPS軌跡數(shù)據(jù)和道路網(wǎng)絡(luò)數(shù)據(jù)檢測(cè)交通異常,通過(guò)檢索與交通異常位置相關(guān)的社交媒體信息(例如Twitter),最后分析交通異常的特定事件內(nèi)容.這種融合方法的異構(gòu)數(shù)據(jù)之間沒(méi)有交互作用,失去了異構(gòu)數(shù)據(jù)之間互補(bǔ)的優(yōu)勢(shì),很難實(shí)現(xiàn)真正的內(nèi)在數(shù)據(jù)融合.
基于特征的融合方法通過(guò)提取每個(gè)異構(gòu)數(shù)據(jù)的特征,然后對(duì)特征進(jìn)行分析和處理.因此,提取的特征質(zhì)量以及融合方法都將對(duì)融合效果具有決定性的影響.Liu等人整合不同視圖的面部信息,將不同維度的深度學(xué)習(xí)特征向量融合以實(shí)現(xiàn)基于深度異構(gòu)性特征的面部識(shí)別.Ouyang等人將人類異構(gòu)信息特征的3個(gè)來(lái)源進(jìn)行非線性融合,可以更準(zhǔn)確地估計(jì)身體姿勢(shì).Wang等人設(shè)計(jì)了張量深度學(xué)習(xí)計(jì)算模型,利用張量對(duì)多源異構(gòu)數(shù)據(jù)的復(fù)雜性進(jìn)行建模,將向量空間數(shù)據(jù)擴(kuò)展到張量空間,并在張量空間中進(jìn)行特征提取.Zadeh等人提出了張量融合網(wǎng)絡(luò)用于解決多模態(tài)的情感分析,通過(guò)笛卡兒積的方式將多種模態(tài)進(jìn)行融合,實(shí)現(xiàn)對(duì)情感的分類分析.
基于語(yǔ)義的融合方法了解每個(gè)數(shù)據(jù)集以及跨數(shù)據(jù)集的特征之間的關(guān)系,認(rèn)為提取到的異構(gòu)數(shù)據(jù)的特征是可解釋的.Zheng等人提出了一種基于協(xié)同訓(xùn)練的模型來(lái)預(yù)測(cè)整個(gè)城市空氣質(zhì)量,利用空氣質(zhì)量具有時(shí)間以及空間的依賴性的特點(diǎn),分別針對(duì)時(shí)空數(shù)據(jù)設(shè)計(jì)了2個(gè)分類器,通過(guò)將不同的時(shí)空特征輸入到不同的分類器,從而在不同標(biāo)簽上生成2組概率,最大化地選擇標(biāo)簽.
上述工作主要考慮了單一節(jié)點(diǎn)上的多源異構(gòu)數(shù)據(jù)融合問(wèn)題.而針對(duì)聯(lián)邦學(xué)習(xí)中的多源異構(gòu)數(shù)據(jù)融合問(wèn)題,目前尚未有相關(guān)工作報(bào)道.
2 基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合
本文主要針對(duì)網(wǎng)絡(luò)邊緣設(shè)備由于數(shù)據(jù)隱私性,無(wú)法進(jìn)行數(shù)據(jù)通信情況下實(shí)現(xiàn)多源異構(gòu)數(shù)據(jù)的融合進(jìn)行研究.通過(guò)引入張量分解理論,構(gòu)建一個(gè)具有異構(gòu)數(shù)據(jù)空間維度特性的高階記憶單元,在不透露用戶隱私的前提下,利用記憶單元對(duì)多源異構(gòu)數(shù)據(jù)進(jìn)行有效地融合.同時(shí),能夠在不額外增加模型規(guī)模的條件下實(shí)現(xiàn)對(duì)多源異構(gòu)數(shù)據(jù)的自適應(yīng)學(xué)習(xí).
2.1 聯(lián)邦學(xué)習(xí)系統(tǒng)模型
本文針對(duì)異構(gòu)數(shù)據(jù)在不進(jìn)行數(shù)據(jù)互通前提下的融合問(wèn)題,考慮在邊緣計(jì)算中引入聯(lián)邦學(xué)習(xí),在不暴露用戶自身隱私的前提下實(shí)現(xiàn)對(duì)多用戶潛在特征的學(xué)習(xí),其系統(tǒng)基本架構(gòu)如圖1所示.在該框架中,系統(tǒng)由邊緣節(jié)點(diǎn)、物聯(lián)網(wǎng)和云端服務(wù)器組成,其中邊緣節(jié)點(diǎn)通過(guò)物聯(lián)網(wǎng)(如網(wǎng)關(guān)和路由器)與云端服務(wù)器互聯(lián).

Fig. 1 The system model for federated learning圖1 聯(lián)邦學(xué)習(xí)系統(tǒng)模型
聯(lián)邦學(xué)習(xí)是一種分布式學(xué)習(xí)框架,其中原始數(shù)據(jù)被收集并存儲(chǔ)在多個(gè)邊緣節(jié)點(diǎn)上,并在節(jié)點(diǎn)處執(zhí)行模型訓(xùn)練,然后將模型通過(guò)節(jié)點(diǎn)與云端服務(wù)器的交互逐步優(yōu)化學(xué)習(xí)模型.
基于以上框架,聯(lián)邦學(xué)習(xí)可以從多個(gè)獨(dú)立的邊緣節(jié)點(diǎn)上使用本地?cái)?shù)據(jù)協(xié)同訓(xùn)練一個(gè)泛化的共享模型,通過(guò)模型傳輸替代數(shù)據(jù)傳輸,規(guī)避了用戶隱私泄露的風(fēng)險(xiǎn).
2.2 算法的總體設(shè)計(jì)
如圖2所示,本文所提出的基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合算法主要分成特征提取模塊、特征融合模塊和特征決策模塊.其中特征提取模塊由各種異構(gòu)數(shù)據(jù)對(duì)應(yīng)的特征提取子網(wǎng)絡(luò)構(gòu)成.
在初始化階段,中心控制節(jié)點(diǎn)對(duì)模型中的特征提取模塊、特征融合模塊和特征決策模塊進(jìn)行網(wǎng)絡(luò)參數(shù)隨機(jī)初始化,并下發(fā)至邊緣節(jié)點(diǎn).
在模型訓(xùn)練階段,邊緣節(jié)點(diǎn)接收到中心控制節(jié)點(diǎn)下發(fā)的模型后,根據(jù)本地節(jié)點(diǎn)上的數(shù)據(jù)集結(jié)構(gòu)選擇對(duì)應(yīng)的特征提取模塊,并利用本地?cái)?shù)據(jù)集對(duì)特征提取模塊、特征融合模塊和特征決策模塊進(jìn)行訓(xùn)練.邊緣節(jié)點(diǎn)新一輪訓(xùn)練的終止條件是本地節(jié)點(diǎn)訓(xùn)練輪數(shù)超過(guò)給定的訓(xùn)練輪數(shù).待訓(xùn)練完成后將各自的訓(xùn)練模型返回至中心控制節(jié)點(diǎn)進(jìn)行模型聚合.
在模型聚合階段,對(duì)于特征融合模塊和特征決策模塊采用平均聚合算法,對(duì)于特征提取模塊,則是根據(jù)得到的對(duì)應(yīng)特征提取子模塊進(jìn)行平均聚合,以確保同一模態(tài)的數(shù)據(jù)提取的特征具有相似性.最后,將更新后的模型重新下發(fā)至邊緣節(jié)點(diǎn)進(jìn)行新一輪的訓(xùn)練.

Fig. 2 The overview of the proposed algorithm圖2 算法總體框架
2.3 子模塊設(shè)計(jì)
2.3.1 特征提取模塊
本文假設(shè)待處理的異構(gòu)數(shù)據(jù)分別為音頻、視覺(jué)和文本數(shù)據(jù).在特征提取模塊,本節(jié)根據(jù)不同模態(tài)的特征,采用了不同的特征提取子網(wǎng)絡(luò)分別對(duì)音頻、視覺(jué)及文本信息進(jìn)行特征提取.
1) 音頻、視覺(jué)特征子網(wǎng)絡(luò).針對(duì)音頻信息和視覺(jué)信息,分別采用了COVAREP聲學(xué)分析框架和FACET面部表情分析框架對(duì)MOSI數(shù)據(jù)集進(jìn)行特征采樣提取(采樣頻率分別為100 Hz和30 Hz).

Fig. 3 Text feature sub-network圖3 文本特征子網(wǎng)絡(luò)
2) 文本特征子網(wǎng)絡(luò).口語(yǔ)文本在語(yǔ)法及表達(dá)上不同于書(shū)面文本,例如“我覺(jué)得挺好的……,不過(guò),我覺(jué)得這個(gè)方法還有待改善”這種口語(yǔ)在書(shū)面語(yǔ)言中很少出現(xiàn).處理口語(yǔ)這種具有多變性語(yǔ)言的關(guān)鍵在于建立能夠在不可靠的情況下運(yùn)行的模型,以及通過(guò)關(guān)注重要的詞語(yǔ)來(lái)表現(xiàn)特殊的言語(yǔ)特征.如圖3所示,本文提出的文本特征提取網(wǎng)絡(luò)在編碼部分先采用全局詞向量對(duì)口語(yǔ)詞進(jìn)行預(yù)處理,同時(shí)使用知短時(shí)記憶(long short-term memory, LSTM)網(wǎng)絡(luò)學(xué)習(xí)與時(shí)間相關(guān)的語(yǔ)言表示,并將其作為CNN網(wǎng)絡(luò)的輸入.在卷積層中,通過(guò)卷積核對(duì)文本信息實(shí)現(xiàn)細(xì)粒度更小的局部特征提取.
2.3.2 特征融合模塊


Fig. 4 Heterogeneous data fusion based on Tucker decomposition圖4 基于Tucker分解的異構(gòu)數(shù)據(jù)融合
以圖4為例,當(dāng)待處理的異構(gòu)數(shù)據(jù)特征分別為,,時(shí),記憶單元為一個(gè)三階張量,且此張量的3個(gè)維度分別對(duì)應(yīng)于3種異構(gòu)數(shù)據(jù)特征,,的特征空間.
在本節(jié)提出的異構(gòu)數(shù)據(jù)特征融合中,通過(guò)將異構(gòu)數(shù)據(jù)特征與記憶單元對(duì)應(yīng)的特征空間進(jìn)行模乘,可得到具有該異構(gòu)數(shù)據(jù)特征的記憶單元,并以此進(jìn)行進(jìn)一步的特征融合操作.
融合操作主要分成3個(gè)階段:首先,記憶單元沿著一階與異構(gòu)數(shù)據(jù)特征進(jìn)行模乘,得到具有特征的新記憶單元.
其次,記憶單元沿著二階與異構(gòu)數(shù)據(jù)特征進(jìn)行模乘,得到具有和特征的記憶單元.
最后,記憶單元沿著三階與異構(gòu)數(shù)據(jù)特征進(jìn)行模乘,最終得到具有三者特征的融合張量.
其具體過(guò)程可以表示為=((×)×)×,(1)

.
3.
3 特征決策模塊針對(duì)融合后的數(shù)據(jù),本節(jié)采用了傳統(tǒng)的全連接層在全局特征的基礎(chǔ)上進(jìn)行決策,包括回歸模型的預(yù)測(cè)和分類模型的概率預(yù)測(cè).
在該模塊中,采用了L
1范數(shù)損失函數(shù)L
1Loss
對(duì)目標(biāo)值和預(yù)測(cè)值之間的誤差進(jìn)行了衡量.
其具體表達(dá)式為
(2)
其中l
的表達(dá)式為
(3)

2.4 基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合
假設(shè)有N
個(gè)邊緣節(jié)點(diǎn){E
,E
,…,E
}參與共享模型的訓(xùn)練,且所有邊緣節(jié)點(diǎn)共采集到M
種異構(gòu)數(shù)據(jù).
在初始化階段,云端根據(jù)采集到的M
種異構(gòu)數(shù)據(jù),設(shè)計(jì)對(duì)應(yīng)的特征提取模塊,特征融合模塊,特征決策模塊.
則共享模型可表示為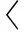
(4)
(5)
其中,表示第i
種異構(gòu)數(shù)據(jù)的特征提取子網(wǎng)絡(luò).
I
(;),=I
(;|),(6)
其中|表示在具有特征的基礎(chǔ)上對(duì)的特征進(jìn)行融合.
在該過(guò)程中,模型首先利用記憶單元對(duì)特征進(jìn)行記憶,得到具有特征的模型,并將此作為特征進(jìn)行融合時(shí)的先驗(yàn)條件,從而在模型訓(xùn)練過(guò)程中,記憶單元不但能對(duì)各個(gè)異構(gòu)數(shù)據(jù)的空間維度特征進(jìn)行學(xué)習(xí),還能對(duì)不同異構(gòu)數(shù)據(jù)之間的潛在聯(lián)系進(jìn)行捕捉.

Fig. 5 Multi-source heterogeneous data fusion based on federated learning圖5 基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合
節(jié)點(diǎn)N
上的訓(xùn)練機(jī)制和節(jié)點(diǎn)1類似.
上述過(guò)程可表示為
(7)

在模型聚合階段,由于各個(gè)邊緣節(jié)點(diǎn)采用特征提取器自適應(yīng)選擇機(jī)制對(duì)特征提取模塊進(jìn)行訓(xùn)練,因此在模型聚合時(shí),需要先將各個(gè)邊緣節(jié)點(diǎn)選擇訓(xùn)練的特征提取子網(wǎng)絡(luò)進(jìn)行歸并,再采用平均聚合算法得到具有全局異構(gòu)數(shù)據(jù)特征的共享模型,該過(guò)程表示為

(8)

(9)

3 實(shí)驗(yàn)結(jié)果與分析
為驗(yàn)證本文算法的有效性,主要從單節(jié)點(diǎn)異構(gòu)數(shù)據(jù)融合和多節(jié)點(diǎn)異構(gòu)數(shù)據(jù)融合2個(gè)方面對(duì)本文算法的性能進(jìn)行評(píng)估.基于Tucker分解的單節(jié)點(diǎn)異構(gòu)數(shù)據(jù)融合實(shí)驗(yàn),主要是通過(guò)單節(jié)點(diǎn)實(shí)現(xiàn)多源異構(gòu)數(shù)據(jù)上的回歸任務(wù)和分類任務(wù)對(duì)本文算法的性能進(jìn)行評(píng)估,并與目前存在的幾種主流異構(gòu)數(shù)據(jù)融合算法進(jìn)行了對(duì)比;基于Tucker分解的多節(jié)點(diǎn)異構(gòu)數(shù)據(jù)融合實(shí)驗(yàn),通過(guò)多節(jié)點(diǎn)實(shí)現(xiàn)多源異構(gòu)數(shù)據(jù)上的回歸任務(wù)和分類任務(wù)對(duì)本文算法的性能進(jìn)行評(píng)估.
3.1 數(shù)據(jù)集設(shè)置和評(píng)價(jià)指標(biāo)
本實(shí)驗(yàn)采用MOSI數(shù)據(jù)集,該數(shù)據(jù)集是YouTube上來(lái)自于視頻影評(píng)的多模態(tài)情感數(shù)據(jù)集,包含了來(lái)自89位評(píng)論者的93個(gè)視頻,每個(gè)視頻的長(zhǎng)度為2~5 min,包含了口語(yǔ)(字幕)、圖像和語(yǔ)音3種信息.對(duì)于該數(shù)據(jù)集中的各個(gè)樣本,均以人工方式對(duì)情緒進(jìn)行評(píng)分,其分值位于[-3,3]之間.
本實(shí)驗(yàn)從回歸任務(wù)和分類任務(wù)2個(gè)方面驗(yàn)證所提算法在多個(gè)任務(wù)上的有效性.在分類任務(wù)中,對(duì)分值量化如表1所示:

Table 1 Quantification of Emotional Score表1 情緒分值量化表
對(duì)于回歸任務(wù),本節(jié)實(shí)驗(yàn)采用平均絕對(duì)誤差(MAE
)和皮爾遜相關(guān)系數(shù)(Corr
)對(duì)本文算法的性能進(jìn)行分析,其對(duì)應(yīng)表達(dá)式為
(10)

(11)

Acc
)和F
1指數(shù)對(duì)本文算法性能進(jìn)行評(píng)估,其中表示類別的數(shù)目,其對(duì)應(yīng)的表達(dá)式為
(12)

(13)
其中TP
,FP
,TN
,FN
分別為真陽(yáng)性、假陽(yáng)性、真陰性和假陰性的樣本數(shù).Acc
越高,模型的分類的精度越高,性能越好;F
1越高,模型對(duì)各個(gè)類別的識(shí)別能力越均衡,性能越好.
3.2 單節(jié)點(diǎn)異構(gòu)數(shù)據(jù)融合實(shí)驗(yàn)分析
本節(jié)實(shí)驗(yàn)對(duì)擁有3種模態(tài)的情感數(shù)據(jù)集MOSI分別進(jìn)行了回歸任務(wù)和分類任務(wù)的訓(xùn)練.
設(shè)置3種模態(tài)的特征提取子模塊的特征輸出數(shù)為R
,其中k
表示為第k
種模態(tài).
考慮到特征提取數(shù)R
對(duì)于訓(xùn)練效率以及實(shí)驗(yàn)性能起到直接的作用.
因此,本實(shí)驗(yàn)首先對(duì)比了不同的特征提取數(shù)的組合(R
,R
,R
)分別對(duì)回歸任務(wù)和分類任務(wù)的性能影響.
在本實(shí)驗(yàn)中,設(shè)置各個(gè)模態(tài)的特征提取數(shù)集合為{8,16,32}.
為驗(yàn)證本文算法的性能,從回歸任務(wù)和分類任務(wù)2個(gè)方面對(duì)比了6種算法在單節(jié)點(diǎn)情況下的多源異構(gòu)數(shù)據(jù)融合上的表現(xiàn)能力.
3.
2.
1 回歸任務(wù)回歸任務(wù)中關(guān)于各個(gè)模態(tài)特征提取數(shù)的定量實(shí)驗(yàn)結(jié)果如表2所示.
觀察可知,本文算法在回歸任務(wù)上的MAE
主要集中在0.
95~1.
05之間.

Table 2 MAE of MOSI Dataset Regression Task表2 MOSI數(shù)據(jù)集回歸任務(wù)MAE
觀察分析可知,對(duì)于回歸任務(wù)來(lái)說(shuō),當(dāng)3個(gè)模態(tài)的特征提取數(shù)的組合為(8,8,16)時(shí),性能更為顯著.
實(shí)驗(yàn)設(shè)置回歸任務(wù)上各個(gè)模態(tài)的特征提取數(shù)分別為8,8,16.表3記錄了本文算法與6種算法在回歸任務(wù)上的性能對(duì)比.由表可知,本文算法與最優(yōu)算法TFN在回歸任務(wù)上性能相當(dāng),優(yōu)于大多對(duì)比算法.雖然本文提出的異構(gòu)數(shù)據(jù)融合算法在單節(jié)點(diǎn)上的回歸任務(wù)性能低于LMF算法,但其旨在應(yīng)用于聯(lián)邦學(xué)習(xí)中對(duì)多源異構(gòu)數(shù)據(jù)進(jìn)行有效地融合,而現(xiàn)有的異構(gòu)數(shù)據(jù)融合算法是在單節(jié)點(diǎn)上實(shí)現(xiàn)的,并不一定適合于聯(lián)邦學(xué)習(xí)中.

Table 3 Performance Comparison of Regression Tasks on the MOSI Dataset
3.2.2 分類任務(wù)
對(duì)于分類任務(wù)來(lái)說(shuō),模型對(duì)各個(gè)模態(tài)特征提取數(shù)的敏感度會(huì)低于回歸任務(wù).
因此,本實(shí)驗(yàn)中設(shè)置分類任務(wù)上各個(gè)模態(tài)的特征提取數(shù)分別為8,8,16.
表4記錄了本文算法與6種算法在分類任務(wù)上的性能對(duì)比.
其中Acc
_2和F
1是二分類任務(wù)評(píng)價(jià)指標(biāo),Acc
_7為多分類評(píng)價(jià)指標(biāo).
由表4可知,本文算法在分類任務(wù)上性能優(yōu)于TFN及大多數(shù)對(duì)比算法,而與LMF算法性能相當(dāng).
Table 4 Performance Comparison of Classification Tasks on the MOSI Dataset
討論:雖然本文算法在單節(jié)點(diǎn)上性能表現(xiàn)并不是最好,但在聯(lián)邦學(xué)習(xí)框架下有3個(gè)優(yōu)勢(shì):1)對(duì)異構(gòu)數(shù)據(jù)具有更強(qiáng)的自適應(yīng)性.與其他算法相比,本算法在訓(xùn)練時(shí)不需要同時(shí)輸入所有類型的異構(gòu)數(shù)據(jù),因此更適合在聯(lián)邦學(xué)習(xí)中的不同類型的邊緣節(jié)點(diǎn)中應(yīng)用.2)更好地保護(hù)了數(shù)據(jù)隱私.本算法避免了將多種異構(gòu)數(shù)據(jù)同時(shí)發(fā)送至同一處進(jìn)行訓(xùn)練而可能存在的隱私泄露風(fēng)險(xiǎn).3)大大降低了傳輸帶寬.本算法只需傳輸提取該邊緣節(jié)點(diǎn)擁有的異構(gòu)數(shù)據(jù)對(duì)應(yīng)的特征提取子網(wǎng)絡(luò)模型參數(shù),而無(wú)需傳輸提取所有異構(gòu)數(shù)據(jù)特征的模型參數(shù).
3.3 多節(jié)點(diǎn)異構(gòu)數(shù)據(jù)融合實(shí)驗(yàn)分析
為驗(yàn)證本文算法在聯(lián)邦學(xué)習(xí)框架下對(duì)多源異構(gòu)數(shù)據(jù)融合的性能,本節(jié)實(shí)驗(yàn)將從2個(gè)方面對(duì)本文算法的性能進(jìn)行評(píng)估:首先通過(guò)對(duì)訓(xùn)練子節(jié)點(diǎn)上的異構(gòu)數(shù)據(jù)的部署來(lái)驗(yàn)證本文算法對(duì)異構(gòu)數(shù)據(jù)的自適應(yīng)能力.如表5所示,對(duì)于訓(xùn)練子節(jié)點(diǎn)上數(shù)據(jù)集的具體部署策略主要分成3類:1)單模態(tài)數(shù)據(jù),即各個(gè)訓(xùn)練子節(jié)點(diǎn)上的數(shù)據(jù)集僅為單一結(jié)構(gòu)的數(shù)據(jù);2)雙模態(tài)數(shù)據(jù),即各個(gè)訓(xùn)練子節(jié)點(diǎn)上的數(shù)據(jù)集為任意2種結(jié)構(gòu)的數(shù)據(jù);3)三模態(tài)數(shù)據(jù),即各個(gè)訓(xùn)練子節(jié)點(diǎn)上擁有所有結(jié)構(gòu)的數(shù)據(jù).其次,通過(guò)同一種多節(jié)點(diǎn)異構(gòu)數(shù)據(jù)部署策略下訓(xùn)練的模型,在不同模態(tài)的異構(gòu)數(shù)據(jù)上的表現(xiàn),驗(yàn)證本文算法的普適性和泛化性.在本實(shí)驗(yàn)中,采用的特征提取數(shù)的組合(R
,R
,R
)=(8,8,16).

Table 5 Multi-Node Heterogeneous Data Deployment Strategy
3.3.1 回歸任務(wù)
對(duì)于回歸任務(wù),評(píng)價(jià)指標(biāo)為MAE
和Corr
.實(shí)驗(yàn)結(jié)果如表6所示,對(duì)于回歸任務(wù)來(lái)說(shuō),根據(jù)何種模態(tài)數(shù)據(jù)訓(xùn)練出的模型在該種模態(tài)數(shù)據(jù)上的性能表現(xiàn)最為顯著.模型的預(yù)測(cè)值和樣本的相關(guān)性隨著訓(xùn)練模態(tài)數(shù)的增加而顯著提升,且多模態(tài)訓(xùn)練模型對(duì)模態(tài)間潛在聯(lián)系的學(xué)習(xí)具有向下兼容性.在回歸任務(wù)上,當(dāng)訓(xùn)練數(shù)據(jù)的模態(tài)數(shù)越高,模型在與訓(xùn)練集模態(tài)數(shù)不同的測(cè)試集上的性能表現(xiàn)越好.這是因?yàn)槎嗄B(tài)模型在訓(xùn)練的過(guò)程中,除了學(xué)習(xí)各個(gè)模態(tài)本身具有的特征以外,對(duì)各個(gè)模態(tài)之間的潛在聯(lián)系也進(jìn)行了學(xué)習(xí),因此,對(duì)于高模態(tài)數(shù)的訓(xùn)練模型來(lái)說(shuō),學(xué)習(xí)到的各個(gè)模態(tài)之間潛在聯(lián)系的組合種類也就越多,回歸任務(wù)的性能就越好.

Table 6 Performance of Regression Tasks on the MOSI Dataset
3.3.2 分類任務(wù)
對(duì)于分類任務(wù),指標(biāo)為Acc
_2,F
1,Acc
_7,其中Acc
_2和F
1為二分類任務(wù)評(píng)價(jià)指標(biāo),Acc
_7為多分類任務(wù)評(píng)價(jià)指標(biāo).實(shí)驗(yàn)結(jié)果如表7所示,根據(jù)何種模態(tài)數(shù)據(jù)訓(xùn)練出的模型在該種模態(tài)數(shù)據(jù)上的性能表現(xiàn)最為顯著.單模態(tài)訓(xùn)練模型對(duì)于多模態(tài)數(shù)據(jù)的融合是通過(guò)云端聚合方式實(shí)現(xiàn)的,模型學(xué)習(xí)到的只是各個(gè)模態(tài)上各自的特征,而學(xué)習(xí)不到各個(gè)模態(tài)之間潛在的聯(lián)系,得到的只是具有本地訓(xùn)練模態(tài)特征的局部最優(yōu)解;而對(duì)于多模態(tài)訓(xùn)練,不論是雙模態(tài)還是三模態(tài),模型訓(xùn)練的過(guò)程中除了各個(gè)模態(tài)本身特征的學(xué)習(xí),同時(shí)還對(duì)模態(tài)之間的潛在聯(lián)系進(jìn)行了學(xué)習(xí),云端聚合也通過(guò)信息共享擴(kuò)大了對(duì)數(shù)據(jù)樣本的學(xué)習(xí).
Table 7 Classification Task Performance on the MOSI Dataset
4 總 結(jié)
本文提出了一種基于聯(lián)邦學(xué)習(xí)的多源異構(gòu)數(shù)據(jù)融合算法,該算法利用了Tucker分解理論,通過(guò)構(gòu)建一個(gè)具有異構(gòu)數(shù)據(jù)空間維度的高階張量,實(shí)現(xiàn)對(duì)多模態(tài)數(shù)據(jù)的融合和記憶.相較于其他算法,該算法能夠在不進(jìn)行數(shù)據(jù)互通的前提下,對(duì)多源異構(gòu)數(shù)據(jù)進(jìn)行有效地融合,從而打破了由于隱私安全問(wèn)題帶來(lái)的數(shù)據(jù)通信壁壘.同時(shí),該算法能夠同時(shí)根據(jù)訓(xùn)練節(jié)點(diǎn)所擁有的異構(gòu)數(shù)據(jù)結(jié)構(gòu),在不增加多余模型訓(xùn)練規(guī)模的前提下自適應(yīng)地對(duì)不同種類的異構(gòu)數(shù)據(jù)進(jìn)行處理,從而在分布式訓(xùn)練中能夠更高效地實(shí)現(xiàn)對(duì)通信帶寬的利用率,減少不必要的傳輸,降低對(duì)網(wǎng)絡(luò)邊緣設(shè)備計(jì)算力和存儲(chǔ)力的要求,同時(shí),模型也具有更高的普適性和泛化性.
作者貢獻(xiàn)申明
:莫慧凌負(fù)責(zé)方案的實(shí)施、實(shí)驗(yàn)結(jié)果整理與分析以及論文撰寫(xiě)與修訂;鄭海峰指導(dǎo)方案設(shè)計(jì),把握論文創(chuàng)新性,并指導(dǎo)論文撰寫(xiě)與修訂;高敏負(fù)責(zé)方案設(shè)計(jì)與實(shí)施,以及論文撰寫(xiě);馮心欣參與方案可行性討論.猜你喜歡
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
湖北經(jīng)濟(jì)學(xué)院學(xué)報(bào)·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機(jī)學(xué)院學(xué)報(bào)(2015年4期)2015-02-28 14:30:00
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
計(jì)算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
