XGBoost 算法在乳腺癌輔助診斷中的應(yīng)用
2022-02-07 09:20:06李佳思
智能計算機與應(yīng)用 2022年12期
李佳思
(上海工程技術(shù)大學(xué) 數(shù)理與統(tǒng)計學(xué)院,上海 201620)
0 引言
目前,高效率的工作追求改變了人們生活方式和飲食習(xí)慣,癌癥成為威脅人們健康的常見疾病之一。對女性而言,乳腺癌則已位于癌癥發(fā)病率的前列,并對國內(nèi)女性的身體健康造成嚴(yán)重危害。隨著醫(yī)療技術(shù)水平的提升,通過藥物、手術(shù)等方式可以使早期癌癥患者的病情得到有效遏制,而晚期患者的治愈率大大降低,因此,早發(fā)現(xiàn)早治療是提高癌癥治愈率的有效手段[1-2]。傳統(tǒng)的乳腺癌診斷方式有X射線檢查、針吸細胞學(xué)檢查、B 型超聲檢查和活組織檢查等,一般需要經(jīng)驗豐富的醫(yī)生根據(jù)檢查結(jié)果判定腫瘤惡良性,癌細胞是否已經(jīng)發(fā)生轉(zhuǎn)移和擴散等[3]。由于受到患者健康意識、各地區(qū)醫(yī)療水平、醫(yī)療資源分配以及醫(yī)生臨床經(jīng)驗等因素的影響,現(xiàn)實中乳腺癌誤診、漏診的情況時有發(fā)生。
近年來,醫(yī)療器械產(chǎn)品的不斷創(chuàng)新推出,能夠幫助醫(yī)生更好地判斷患者病情,但是日益繁多的檢查指標(biāo)也使病情與病因的聯(lián)系更加復(fù)雜。同時,計算機硬件和軟件性能的高速提升使得海量的醫(yī)療數(shù)據(jù)得以儲存,患者病史、生活習(xí)慣、家族遺傳等因素都可能成為需要考慮的因素,海量的信息加重了醫(yī)生診療的負(fù)擔(dān)。隨著人工智能的興起,機器學(xué)習(xí)算法已經(jīng)廣泛應(yīng)用于各個領(lǐng)域并取得了重大突破,這為癌癥診斷提供了新的方向,基于機器學(xué)習(xí)和模式識別的疾病診斷與發(fā)病機制研究成為熱點研究方向。傳統(tǒng)的機器學(xué)習(xí)模型主要有決策樹(DT)、支持向量機(SVM)、K-近鄰(KNN)、樸素貝葉斯(NB)等,雖然在很多疾病分類問題上取得了可觀的進步,但也具有局限性,如泛化能力不強、在不同數(shù)據(jù)集中模型表現(xiàn)差距較大等問題。集成學(xué)習(xí)可以很好地解決上述問題,其主要思想是:訓(xùn)練多個同質(zhì)或異質(zhì)的弱分類器對樣本進行預(yù)測,獲得多個預(yù)測結(jié)果,然后根據(jù)某種規(guī)則將各個弱分類器的預(yù)測結(jié)果進行結(jié)合得到最終預(yù)測[4-5]。這種方法提升了模型的泛化能力,具有魯棒性,通常能夠得到比單個分類器更好的預(yù)測準(zhǔn)確率,在人臉識別、文本分類、疾病輔助診斷等方面得到了廣泛的應(yīng)用。
目前許多學(xué)者將機器學(xué)習(xí)算法用于乳腺癌的診斷中,取得了良好的分類效果。鄧卓等人[6]將集成學(xué)習(xí)算法用于乳腺癌的診斷研究,在美國威斯康星州乳腺癌數(shù)據(jù)集上分別建立了隨機森林和XGBoost診斷模型,并與決策樹算法的分類性能進行比較,結(jié)果表明,集成學(xué)習(xí)算法相比傳統(tǒng)的決策樹分類模型具有更高的分類準(zhǔn)確率。張紅斌等人[7]提出了一種改進的自適應(yīng)提升算法用于乳腺癌圖像識別,從不同角度提取圖像特征并進行特征融合,在CBISDDSM 數(shù)據(jù)集上分別建立了邏輯回歸、隨機森林、AdaBoost、梯度提升決策樹等診斷模型,并將改進的ERGS 算法與傳統(tǒng)算法進行結(jié)合用于乳腺癌診斷。實驗結(jié)果顯示,所提出的ERGS-Ada 算法的預(yù)測準(zhǔn)確率最高,達到了86.24%,對陽性圖像的識別精度達到了99.18%。Khuriwal 等人[8]提出了一種自適應(yīng)集成投票方法進行乳腺癌檢測,在威斯康星乳腺癌數(shù)據(jù)集上驗證了算法的有效性,使用卡方檢驗和遞歸特征消除方法選擇出了影響模型識別準(zhǔn)確率的16 個特征,建立了邏輯回歸和神經(jīng)網(wǎng)絡(luò)模型,采用投票法獲得了最終預(yù)測結(jié)果,實現(xiàn)了98.50%的分類準(zhǔn)確率。Sun 等人[9]提出了基于深度學(xué)習(xí)的集成CNN 模型,對266 例乳腺癌患者的術(shù)前磁共振成像和分子信息進行訓(xùn)練來區(qū)分2 種乳腺癌亞型(管腔型和非管腔型),結(jié)果顯示,所提出的模型在測試集中的識別準(zhǔn)確率達到了85.2%。岳鵬等人[10]提出了一種XLC-Stacking 方法進行乳腺癌診斷,該方法基于XGBoost 算法選擇出影響乳腺癌分類的最佳特征,并使用威斯康星州乳腺癌的診斷數(shù)據(jù)來驗證模型有效性。結(jié)果表明,所提出的XLC-Stacking 方法與單一的XGBoost 和一般的Stacking 方法相比準(zhǔn)確率得到提升,分類準(zhǔn)確率為97.73%。Hou 等人[11]使用四川大學(xué)華西醫(yī)院的數(shù)據(jù)分別建立了深度神經(jīng)網(wǎng)絡(luò)、XGBoost 和隨機森林模型來預(yù)測中國居民患乳腺癌的風(fēng)險,實驗結(jié)果顯示,XGBoost、深度神經(jīng)網(wǎng)絡(luò)和隨機森林模型的AUC值分別為0.742、0.728 和0.728。
為了彌補傳統(tǒng)的乳腺癌診斷方式的不足,提升診斷效率和精度,本文將XGBoost 算法用于乳腺癌診斷,將數(shù)據(jù)的70%作為訓(xùn)練集、30%用于測試,同時建立了決策樹、支持向量機、K-近鄰和樸素貝葉斯分類模型,使用五折交叉驗證準(zhǔn)確率、F1值、AUC值等評估指標(biāo)來評價模型的優(yōu)劣。
1 相關(guān)理論介紹
1.1 XGBoost 算法
XGBoost(Extreme Gradient Boosting)算法在2014 年由陳天奇博士提出,這是對梯度提升算法的一種改進,近年來在各大機器學(xué)習(xí)和數(shù)據(jù)挖掘類的比賽中取得了優(yōu)異的成績。提升算法的思想是從某個弱學(xué)習(xí)器開始,不斷學(xué)習(xí)得到不同的弱分類器,然后將這些弱分類器通過某種策略進行融合得到更加強大的分類器。Boosting 方法中各個弱分類器是相互關(guān)聯(lián)的,每次迭代根據(jù)前一個分類器的結(jié)果來調(diào)整樣本的權(quán)重,通過加大容易被錯誤分類的樣本的權(quán)重使得下階段生成的弱分類器更加關(guān)注被錯誤分類的樣本。Boosting 方法的工作原理如圖1 所示。
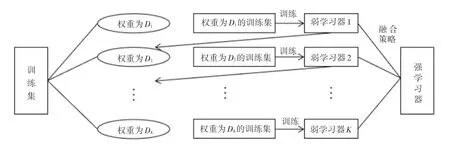
圖1 Boosting 算法原理圖Fig. 1 Schematic diagram of Boosting algorithm
XGBoost 算法由多棵決策樹組成,模型以前k -1 棵樹生成的模型所產(chǎn)生的殘差來建立第k棵樹,從而不斷提升模型的預(yù)測精度。XGBoost 算法的流程如下:
給定二分類數(shù)據(jù)集,每個樣本由特征X和標(biāo)簽Y構(gòu)成:
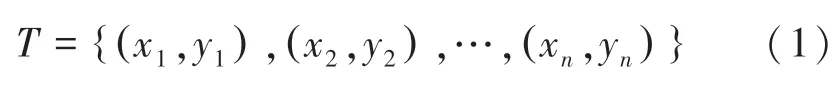
其中,xi∈Rn,yi∈{+1,-1},+1 和-1 分別表示2 個不同的類別。
預(yù)測模型可表示為:
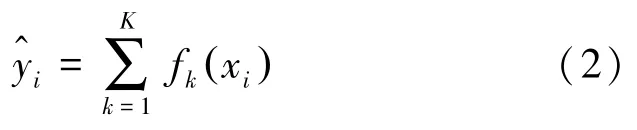
其中,K為樹的個數(shù);fk(xi) 表示第k棵樹;表示樣本xi的預(yù)測值。
XGBoost 的目標(biāo)函數(shù)為:

其中,l(yi,) 表示第i個樣本的訓(xùn)練誤差;n表示樣本個數(shù);Ω(fk) 為第k棵樹的正則項。正則項可以減小模型的過擬合風(fēng)險,降低模型復(fù)雜度。其定義如下:

其中,T為葉子節(jié)點個數(shù),γ和λ為控制參數(shù)。
可將上述目標(biāo)函數(shù)寫為:

其中,C表示常數(shù)。
使用泰勒展開可將上述目標(biāo)函數(shù)近似為:
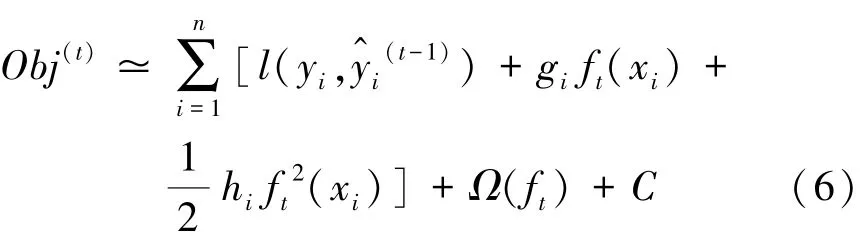
其中,

去掉常數(shù)項可得:

上述目標(biāo)函數(shù)可改寫為:
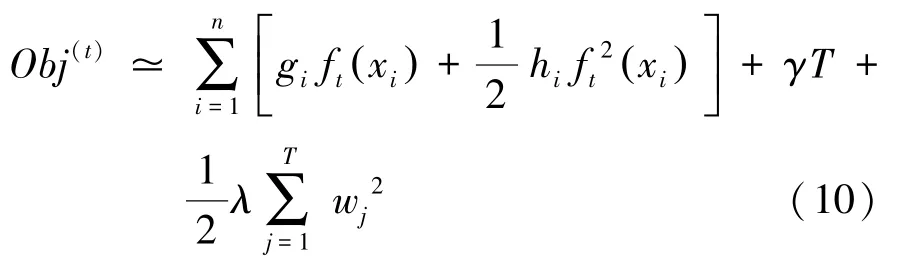
公式(10)可以寫為:
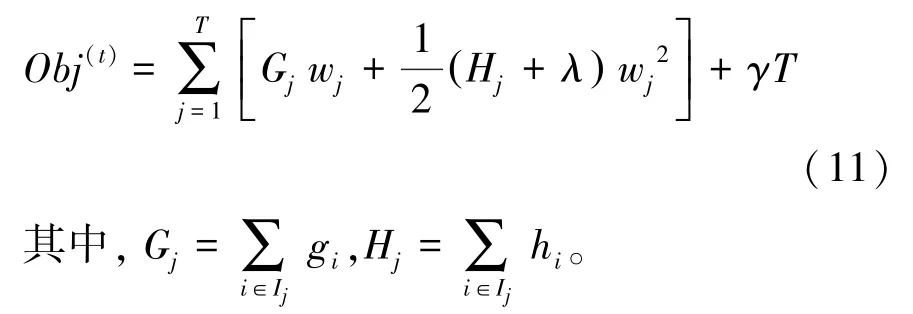
對式(11)求導(dǎo),令一階導(dǎo)數(shù)為零可得:

將式(12)代入目標(biāo)函數(shù)可得:

在此,將Obj*作為評價決策樹結(jié)構(gòu)好壞的函數(shù),取值越低表示模型越好。
1.2 模型評價方法
混淆矩陣[12-13]是分類任務(wù)中常用的評價方法,可以將數(shù)據(jù)的真實情況和預(yù)測結(jié)果清晰地顯示出來,矩陣中Positive表示正例,Negative表示負(fù)例。以二分類模型為例,混淆矩陣見表1。

表1 混淆矩陣Tab.1 Confusion matrix
由混淆矩陣可以計算出準(zhǔn)確率、精準(zhǔn)率、召回率、F1值和AUC值,多角度評估模型性能。對此擬做探討分述如下。
(1)準(zhǔn)確率(Accuracy):表示分類器預(yù)測正確的樣本個數(shù)與樣本總數(shù)之比。通常,模型的準(zhǔn)確率越高,表示模型分類效果越好。準(zhǔn)確率計算公式如下:

(2)精準(zhǔn)率(Precision):陽性病例中正確分類的樣本數(shù)量與所有預(yù)測為陽性的樣本數(shù)量之比。計算公式如下:
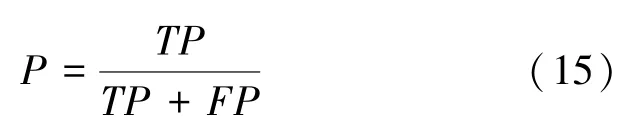
(3)召回率(Recall):陽性病例中正確分類為陽性的樣本數(shù)量與真實為陽性的樣本數(shù)量之比。計算公式如下:

(4)F1-Score:表示精準(zhǔn)率與召回率的調(diào)和平均。計算公式如下:

(5)AUC:表示ROC曲線下面積,值越接近于1表示模型性能越好。
2 數(shù)據(jù)來源及預(yù)處理
2.1 數(shù)據(jù)來源
本文實驗數(shù)據(jù)來自UCI 數(shù)據(jù)庫中的威斯康星州乳腺癌診斷數(shù)據(jù)集。數(shù)據(jù)集共包含569 條數(shù)據(jù)樣本,32 個特征,分別含有212 例惡性樣本和357 例良性樣本。其中,ID 為患者編號,diagnosis為樣本標(biāo)簽,M表示惡性病例,B表示良性病例。除去患者編號和diagnosis兩列后剩余的30 個特征是從患者乳房腫塊的細針抽吸數(shù)字影像中提取的數(shù)據(jù),表示了細胞的10 個細胞核信息(平均值、標(biāo)準(zhǔn)誤差和最大值),分別為半徑(radius)、紋理(texture)、周長(perimeter)、面積(area)、平滑度(smoothness)、密實度(compactness)、凹度(concavity)、凹點(concave points)、對稱性(symmetry)和分形維數(shù)(fractal_demension)。
2.2 數(shù)據(jù)預(yù)處理
探索性數(shù)據(jù)分析是建立模型前的重要步驟,有助于更好地了解數(shù)據(jù)結(jié)構(gòu),發(fā)現(xiàn)數(shù)據(jù)中的異常值及特征之間的相關(guān)關(guān)系,幫助選擇合適的數(shù)據(jù)處理方法和預(yù)測模型。實驗前需要對數(shù)據(jù)進行清洗來提升模型的擬合能力,圖2 展示了數(shù)據(jù)集中前9 個特征的描述性統(tǒng)計,可以看出,不同特征之間存在較大的量綱差異,因此,在建立模型之前對數(shù)據(jù)進行標(biāo)準(zhǔn)化處理。圖3 繪制了前10 個特征的箱線圖,描述了數(shù)據(jù)的分布信息,從箱線圖中可以分析數(shù)據(jù)的對稱性、分散程度、偏態(tài)及異常值等信息。由圖3 可以看出,周長均值和面積均值兩個特征具有相似的分布,由此可以推測二者具有一定相關(guān)關(guān)系。
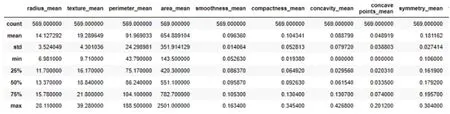
圖2 部分特征的統(tǒng)計性描述Fig. 2 Statistical description of some features

圖3 前10 個特征的箱線圖Fig. 3 Box diagram of the first 10 features
3 實驗過程與結(jié)果
3.1 實驗過程
本文將XGBoost 模型用于乳腺癌患者的診斷數(shù)據(jù)對乳腺腫塊的惡良性進行預(yù)測。實驗過程主要包括數(shù)據(jù)預(yù)處理、模型建立和結(jié)果分析。其中,數(shù)據(jù)預(yù)處理主要通過統(tǒng)計學(xué)方法了解數(shù)據(jù)特性,對數(shù)據(jù)進行清洗;模型建立即是對數(shù)據(jù)的擬合過程,根據(jù)研究目標(biāo),選擇合適的預(yù)測模型和參數(shù),本文使用網(wǎng)格搜索和交叉驗證尋找模型的最優(yōu)參數(shù);結(jié)果分析主要是通過模型評估指標(biāo)對模型性能進行評價和分析。本文實驗步驟如圖4 所示。交叉驗證是建立模型時常用的一種方法,可以獲得更加穩(wěn)定的模型。K折交叉驗證即是將數(shù)據(jù)平均分為K份,每次建模使用其中一份作為測試集,剩余K -1 份作為訓(xùn)練集,共進行K次訓(xùn)練和測試,最后返回K次測試結(jié)果的平均值來增加結(jié)果的可靠性[14]。實驗過程中,將70%的樣本作為訓(xùn)練集,30%的樣本作為測試集,通過網(wǎng)格搜索獲得模型的最佳參數(shù)組合,以五折交叉驗證準(zhǔn)確率、F1值和AUC值來對模型性能進行評價。

圖4 實驗流程Fig. 4 Experimental process
3.2 XGBoost 診斷模型的建立
實驗使用70%的數(shù)據(jù)作為訓(xùn)練集,30%的數(shù)據(jù)作為測試集,在經(jīng)過預(yù)處理后的數(shù)據(jù)上建立XGBoost 模型。合理調(diào)整模型參數(shù)有利于降低模型過擬合風(fēng)險,提升模型預(yù)測能力,實驗過程中使用了五折交叉驗證準(zhǔn)確率作為評價標(biāo)準(zhǔn)確定模型的最優(yōu)參數(shù)。通過學(xué)習(xí)曲線可以直觀地看到模型性能隨著參數(shù)的變化情況,設(shè)置n_estimators的迭代范圍為10 到200,以10 為步長,得到五折交叉驗證準(zhǔn)確率隨弱分類器個數(shù)的變化關(guān)系如圖5 所示。由圖5 可以看出,當(dāng)弱分類器數(shù)量小于50 時,模型五折交叉驗證準(zhǔn)確率隨著弱分類器數(shù)量的增加而升高,在弱分類器數(shù)量達到100 時,模型的分類準(zhǔn)確率最高、為97.72%,隨后再增加分類器數(shù)量,模型的分類準(zhǔn)確率先下降、后趨于平穩(wěn)。
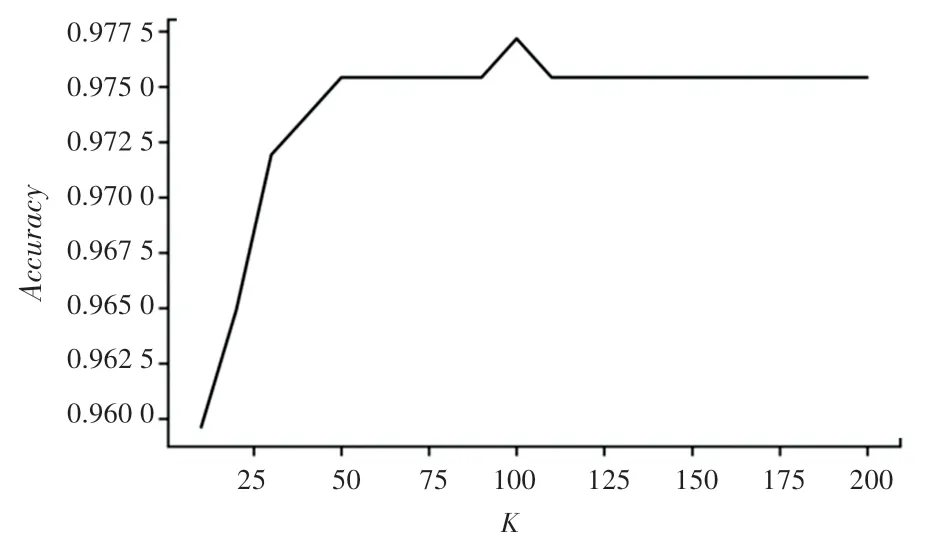
圖5 分類準(zhǔn)確率與基學(xué)習(xí)器個數(shù)的關(guān)系Fig. 5 Relationship between classification accuracy and the number of base learners
經(jīng)過實驗驗證,在random_state =10 的情況下,n_estimators =100,learning_rate =0.65 時模型的五折交叉驗證準(zhǔn)確率達到最高、為97.89%。XGBoost模型在測試集上的混淆矩陣如圖6 所示。

圖6 XGBoost 模型的混淆矩陣Fig. 6 Confusion matrix of XGBoost model
3.3 實驗結(jié)果分析
為了將XGBoost 模型的診斷效果與其他模型進行比較,在威斯康星州乳腺癌數(shù)據(jù)中分別建立了決策樹、支持向量機、K-近鄰和樸素貝葉斯分類模型,得到不同模型的精準(zhǔn)率、召回率、F1值、AUC值以及五折交叉驗證準(zhǔn)確率見表2。
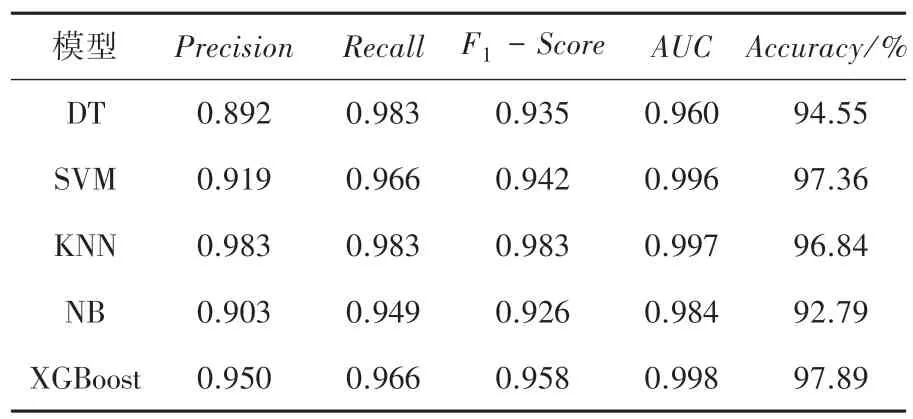
表2 不同模型的分類結(jié)果Tab.2 Classification results of different models
由表2 可知,XGBoost 診斷模型的分類準(zhǔn)確率為97.89%,高于其他4 種單分類器的準(zhǔn)確率,支持向量機的準(zhǔn)確率排名次之,達到了97.36%;緊隨其后是KNN 和決策樹模型,準(zhǔn)確率分別為96.84%和94.55%,樸素貝葉斯的預(yù)測效果最差,準(zhǔn)確率為92.79%。5 個模型中XGBoost 模型的AUC值達到最高、為0.998,KNN 排名次之、為0.997,其次為SVM和NB,分別為0.996 和0.984,決策樹的AUC值最低、為0.960。由結(jié)果可知,整體來看XGBoost 模型的分類效果優(yōu)于其他4 種單分類器,XGBoost 算法在乳腺癌診斷中可以提升模型的泛化能力,將機器學(xué)習(xí)算法應(yīng)用于醫(yī)療數(shù)據(jù)與疾病診斷中,建立疾病診斷輔助系統(tǒng),能夠有效提升診斷效率和準(zhǔn)確率,具有一定現(xiàn)實意義。
建立XGBoost 模型后得到特征重要性排序如圖7所示。由圖7可知,area_se、texture_worst、texture_mean、symmetry_se、symmetry_worst、concave points_worst、perimeter_worst是影響乳腺癌惡良性的較重要特征。這對于找出影響乳腺癌惡良性的因素十分重要,醫(yī)生在為患者進行診斷時可以優(yōu)先關(guān)注這些特征,有利于發(fā)現(xiàn)更加有效的治療方式,對降低乳腺癌死亡率具有一定現(xiàn)實意義。
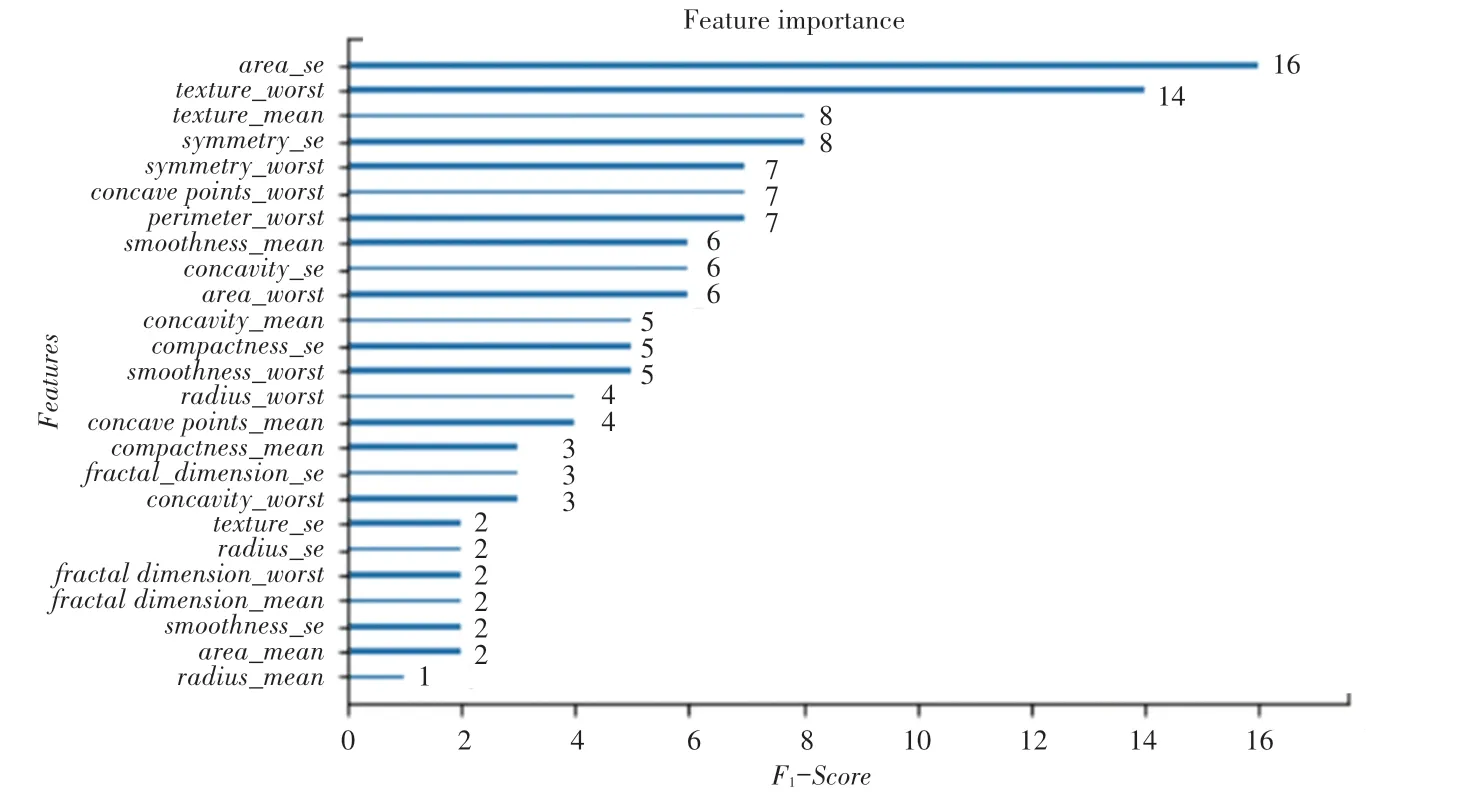
圖7 特征重要性排序Fig. 7 Feature importance ranking
4 結(jié)束語
本文將XGBoost 模型應(yīng)用于乳腺癌診斷,使用UCI 數(shù)據(jù)庫中的威斯康星州乳腺癌數(shù)據(jù)集驗證了模型的有效性,同時建立了決策樹、支持向量機、K-近鄰和樸素貝葉斯分類模型,通過五折交叉驗證準(zhǔn)確率、F1值、AUC值等評估指標(biāo)對比了不同模型的分類性能。由實驗結(jié)果可知,XGBoost 模型的預(yù)測效果優(yōu)于其他4 種分類模型,取得了97.89%的分類準(zhǔn)確率,一定程度上說明集成學(xué)習(xí)相比單分類器具有更好的泛化能力,在今后可以將集成學(xué)習(xí)應(yīng)用于乳腺癌的診斷來提升診斷準(zhǔn)確率。此外,XGBoost 模型給出了特征的重要性排名,可以發(fā)現(xiàn)不同特征對分類結(jié)果的影響,進而為醫(yī)生提供決策指導(dǎo)。此研究對識別早期乳腺癌患者并進行針對性治療具有現(xiàn)實意義,后續(xù)研究中可以將其他集成學(xué)習(xí)方法用于乳腺癌輔助診斷,也可將XGBoost 算法應(yīng)用于其他類型的疾病進一步探究模型的表現(xiàn)及其適用性。
猜你喜歡
中老年保健(2022年6期)2022-08-19 01:41:48
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:11:42
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2019年6期)2019-01-06 09:20:12
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
祝您健康(2018年5期)2018-05-16 17:10:16
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
