基于混合語義的圖神經網絡小樣本圖像分類方法
2022-02-07 09:20:04付炳光汪榮貴薛麗霞
智能計算機與應用 2022年12期
付炳光,楊 娟,汪榮貴,薛麗霞
(合肥工業大學 計算機與信息學院,合肥 230601)
0 引言
在計算機視覺的多個領域中,深度神經網絡[1-2]均取得了優異的效果。深層的網絡模型在訓練時通常需要大量的標記數據,昂貴的數據標注成本使得模型訓練成本大幅增加。同時在許多實際應用場景中,也不具備獲得足夠多標注樣本的條件。在這種情況下,如何利用有限的標注樣本獲得性能較好的網絡模型也隨即成為一個亟待攻克的熱點研究方向。基于此,小樣本學習受到了廣泛的關注。研究可知,元學習方法[3-4]在訓練階段和測試階段構造相似的情節(episodes)任務,模擬人類總結任務經驗的能力以使得機器從相似任務中獲取通用知識并快速適應新任務,緩解了過擬合問題,成為了眾多小樣本學習方法的通用機制。
圖神經網絡[5](graph neural networks,GNN)通過構建結構化信息的方式有效地提升深度學習模型的性能,許多研究[6-9]也開始嘗試將圖模型應用到小樣本學習中。Garcia 等人[6]實現圖模型預測值到標簽值之間的后驗推理,基于消息傳遞的想法,利用圖推理將標簽信息傳遞到沒有標簽的樣本上,進而判別樣本類型。Liu 等人[7]使用轉導推理的方法,將所有無標注數據和有標注數據共同構建一個無向圖,然后通過標簽傳播得到所有數據標簽。與前面方法中圖結構僅使用一組邊特征表示類內相似、類間不同的節點關系不同,Kim 等人[8]構造了2 組邊特征,將節點間相似關系和不相似關系分開考慮。Ma 等人[9]使用支持樣本和查詢樣本組合構成關系對并作為圖節點,在傳播和聚合節點信息過程中同時考慮節點間的相似性聯系和節點內支持樣本和查詢樣本關系。現有基于圖神經網絡的小樣本學習方法通過構建出不同的圖結構,雖然取得了優異的分類效果,但未考慮與圖像相關的標簽語義信息。與之不同,人們從少數樣本中學習新概念時,不僅對比不同樣本之間的差異,同時也考慮與之相關的文本知識。因此本文提出的方法嘗試在使用圖神經網絡考慮圖像特征間關系的同時,融入圖像標簽語義信息。
元學習方法的靈活性為學習新概念時引入其他模態提供可能。不同模態蘊含的信息有互補性和一致性[10],不同模態間既含有類似的信息,同時也可能含有其他模態所欠缺的信息。在圖像任務中,引入文本信息可以更全面地描述樣本實例。Frederikd等人[11]為獲得更可靠的原型,通過生成對抗網絡(generative adversarial networks,GAN)將語義特征對齊到圖像特征空間,生成新特征改進圖像類原型特征計算。Peng 等人[12]根據數據集標簽在WordNet 中的關系,由標簽語義特征通過圖卷積神經網絡(graph convolution network,GCN)推理得到基于知識的分類權重,并與視覺分類權重融合得到新類的分類權重。Chen 等人[13]提出了Dual TriNet,通過編碼器將圖像特征映射到語義空間,以隨機添加高斯噪聲等方式對該特征增廣后,由解碼器反解碼形成各層特征圖,由于可以無限增廣,對此擴充訓練特征。Li 等人[14]將標簽語義特征經由多次kNN 聚類得到多層超類語義特征,并構造底層為標簽語義,上面多層為超類語義的樹形結構的分層語義。如此一來,圖像經由分級分類網絡的同時在不同層會進行分類,訓練得到良好的特征提取器。這些方法主要考慮類級別的語義信息,而忽略具體實例間的差異,一定程度上喪失了識別能力。為此,本文方法通過混合語義模塊將實例級的圖像特征對齊到語義空間并與其標簽語義融合,為語義特征添加實例間的差異信息。此外,還通過補充語義信息增強標簽語義的表達能力。
綜上所述,本文提出了基于混合語義的圖神經網絡小樣本分類方法。在常用小樣本數據集上進行試驗,并取得了良好的分類效果。
1 方法
1.1 問題定義
小樣本圖像分類目的是在僅有少量目標類標注樣本的情況下,訓練得到泛化性能良好的分類網絡模型。通常將數據集劃分為類別互不相交的訓練集、測試集和查詢集。同時采用episode 訓練機制[15],分為訓練階段和測試階段,每個階段由許多相似的n -wayk -shot 分類任務組成(現常見5-way 1-shot 和5-way 5-shot 兩種類型)。具體地,訓練階段每個分類任務從訓練集中隨機抽取n個類,每類隨機抽取k +q張圖片,構成當前任務的支持集S ={(xi,yi),i =1,2,…,nk}和查詢集Q ={(xj,yj),j =1,2,…,nq},其中xi,xj表示圖像,yi,yj表示該圖像對應的標簽。模型利用支持集樣本的圖像和標簽信息判斷查詢樣本的標簽信息,并通過最小化已設計好的損失函數,反向傳播更新網絡模型參數達到模型訓練的效果。訓練階段包含模型驗證,從驗證集隨機采樣構造n -wayk -shot任務,檢測模型泛化能力,保存最優的模型參數。最終,測試階段在測試集上驗證泛化性能。由于訓練階段和測試階段構造類似的分類任務,由訓練得到的模型能很好地遷移到訓練集任務上。
1.2 基于混合語義的圖神經網絡模型
本文提出的模型結構如圖1 所示,包含圖像特征信息傳播模塊、混合語義模塊和決策混合模塊。在每個分類任務中,圖像通過圖像特征提取網絡得到圖像特征,標簽由GloVe[16](Global Vector)計算得到標簽語義特征。隨后,圖像特征信息傳播模塊使用圖神經網絡考慮任務上下文關系,更新得到任務相關的圖像特征表示。混合語義模塊利用補充語義信息和特征提取網絡得到的視覺信息,增強標簽特征的表達能力,得到混合語義特征。最后由決策混合模塊組合圖像特征和混合語義特征進行分類。
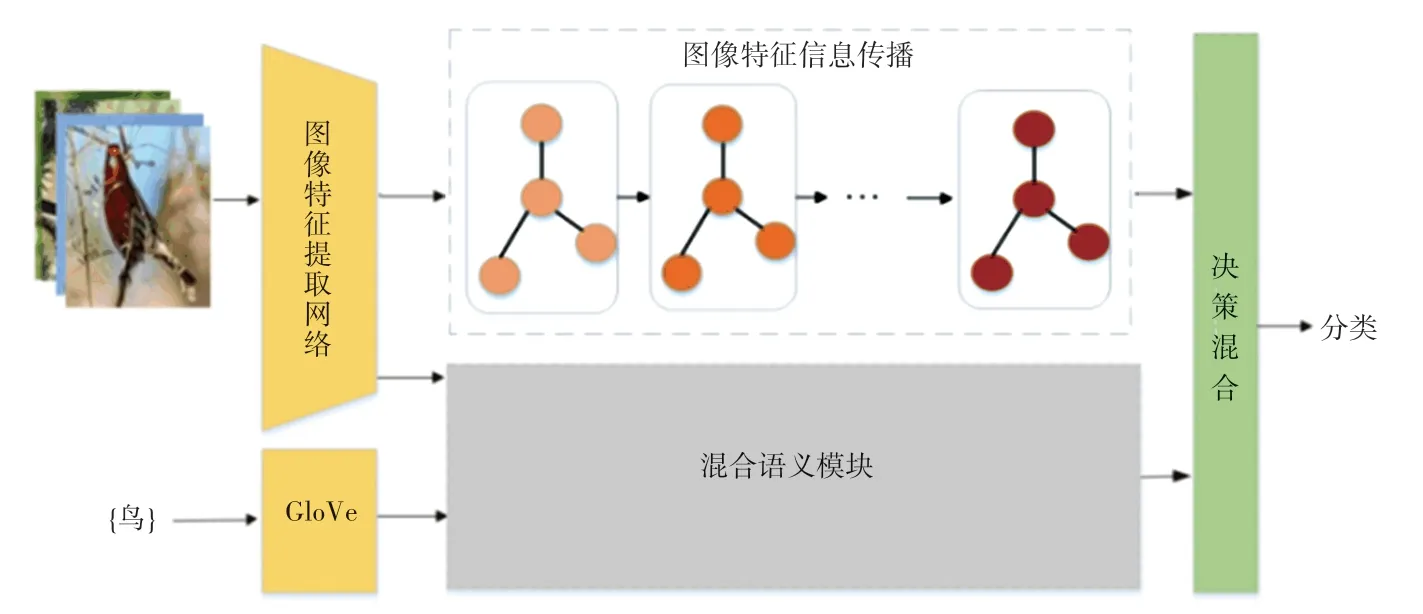
圖1 基于混合語義的圖神經網絡模型Fig. 1 The model of hybrid semantic-based graph neural network
1.2.1 圖像特征信息傳播模塊
圖像特征信息傳播模塊使用圖神經網絡考慮圖像特征上下文關系進而傳播聚合特征信息,并更新特征表示。模塊包含L層圖像關系圖Gl =(Hl,El),l =1,2,…,L。第l層的圖節點Hl由特征節點組成,特征節點與特征節點間的相似度可表示為,兩節點之間的相似度越高,越接近1,反之接近0。該層所有的節點相似關系構成了鄰接矩陣。
對于圖像xi,輸入到特征提取網絡Fex后,經過池化層和拉平層得到獨熱編碼(one-hot coding)形式的圖像特征向量Fex(xi),將其作為圖中初始節點特征(xi)。初始鄰接矩陣E0采用公式(1)進行初始化:

相同標簽的支持集節點間的特征邊設置為1,而不同標簽的支持集節點間設置為0。此外,由于查詢樣本的標簽未知,統一將支持集節點和查詢節點的特征邊設置為1/nk。同時,根據描述節點間相似度關系的鄰接矩陣,節點相互傳播信息并聚集更新得到下一層節點。隨后,更新節點間相似度得到下層的鄰接矩陣。多層更新后得到每個樣本的最終圖像特征。具體地,對于第k層更新過程表示為:


1.2.2 混合語義模塊
GloVe[16]和Word2Vec[17]等文本嵌入方法根據詞語在語料庫中的分布,將詞語轉換為獨熱編碼(one-hot)表示的語義特征。語義特征不僅含有詞語信息,還蘊含語料庫不同詞語間的聯系。“卡車”與“汽車”間相對于“狗”與“汽車”間具有更強的關聯性。換而言之,對于一個與“汽車”關聯性很強的未知詞語,該詞語為“卡車”的概率比為“狗”的概率更大。據此,本節提出混合語義模塊,通過文本嵌入的方法計算得到類別標簽的語義特征,并引入其他詞語作為補充描述,以增強其表達能力。
相比于因有限窗口大小而僅可捕捉局部信息的Word2Vec,本文使用可以捕獲全局信息的GloVe 方法計算標簽的語義特征,并將所有支持集類別作為補充詞語。混合語義模塊如圖2 所示。由圖2 可看到,當前任務類別標簽和補充詞語由GloVe 方法計算得到標簽語義特征集St∈和補充語義特征集Sa∈,這里的dw表示語義特征的維度。運行時,先將St和Sa分別進行線性變換后輸出Q和K,接著將Q和K做矩陣乘法之后再乘以縮放系數經過softmax函數輸出注意力分數矩陣A,由此推得的各數學公式分別如下:
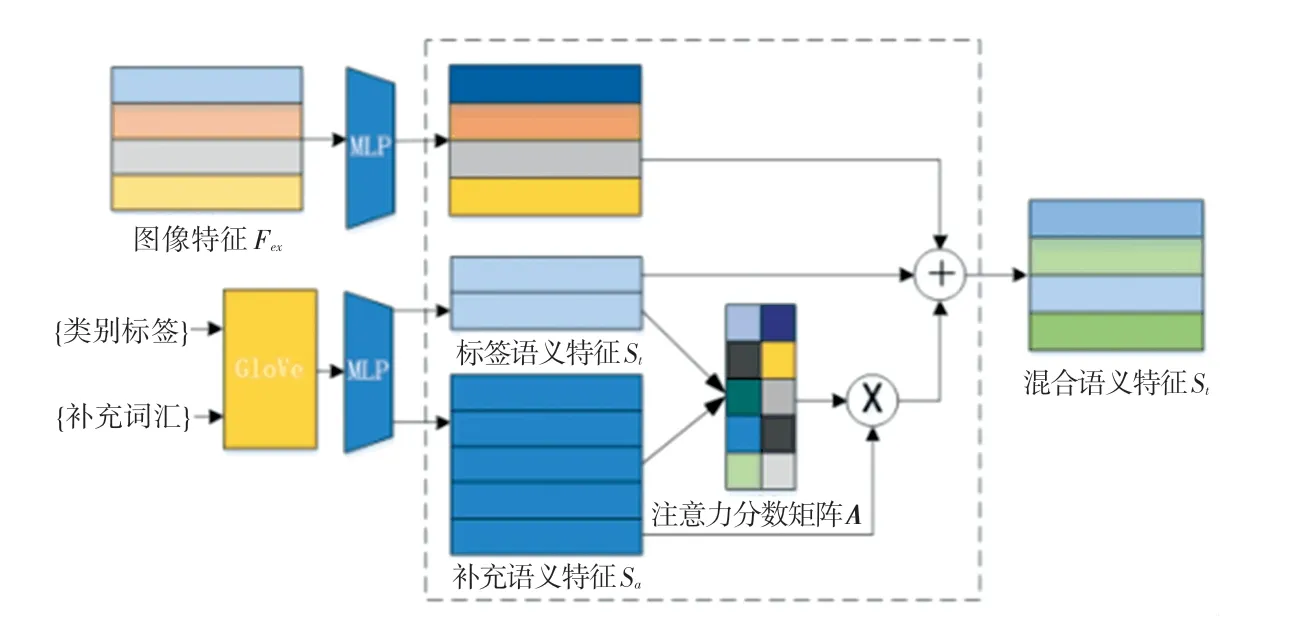
圖2 混合語義模塊Fig. 2 The hybrid semantic module
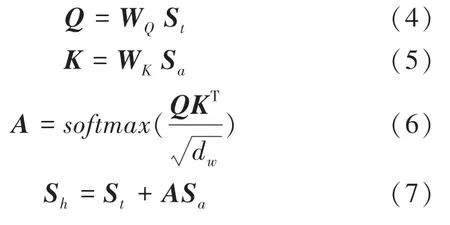
式(4)和式(5)中,WQ,WK∈為權重矩陣,引入縮放系數得到更為平滑的輸出。式(7)將注意力分數矩陣A與Sa做矩陣乘法后,再以相加的方式與標簽語義特征融合,得到增強語義特征集Sh ={sh1,sh2,…,shN}。在理解特定對象時,不同詞語的重要性不同。正如“卡車”與“汽車”之間的聯系比“狗”與“汽車”之間的聯系更強,“卡車”的語義對理解“汽車”更為重要,注意力分數矩陣A起到了相似的作用,反映了Sa中的每個語義特征補充描述St中語義特征時的重要程度。
此外,在n -wayk -shot 任務下可能有多張圖片屬于相同類別,不同圖像特征對應同一語義特征忽略了同類圖像特征之間的差異性。不同模態間往往具有相關的信息[10],本文模型嘗試將圖像特征對齊映射到語義特征空間中,與混合語義特征融合構建實例級的語義特征表示。對于支持集圖像特征Fex(xi),其映射得到的特征為:
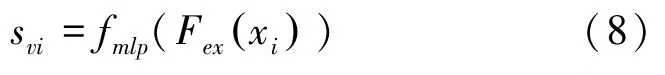
將svi與實例xi標簽的增強語義特征shy融合得到該實例的混合語義特征si:

1.2.3 決策融合
由圖像特征信息傳播模塊可以得到考慮圖像上下文關系的圖像特征,而混合語義模塊得到支持集實例的混合語義特征。不同模態間存在互補性[10],可能包含其他模態所欠缺的信息,利用多個模態的信息有助于更好地描述實例。本方法通過式(10)組合支持集圖像特征和混合語義特征:
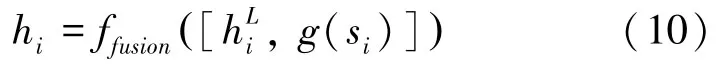
其中,“[,]”表示級聯操作。式(10)中將實例xi的混合語義特征si輸入網絡g后,與其圖像特征,再經由網絡ffusion得到混合模態特征hi,g和ffusion均由多層感知機和ReLu激活函數構成。
1.3 損失函數

其中,i,j分別為支持樣本和查詢樣本下標,onehot(yj) 是支持集樣本j標簽的獨熱編碼。在給定episode 任務下,利用最小化分類損失函數來訓練模型:
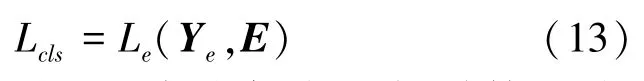
其中,Ye是真實的相似度鄰接矩陣,計算Ye與預測矩陣E之間的二值交叉熵作為分類損失函數。
圖像特征信息傳播模塊的鄰接矩陣同樣也可以預測節點分類,增加式(14)的損失函數用來改善訓練過程中的梯度更新,但僅用E作為查詢樣本的標簽判斷。式(14)的數學表述具體如下:
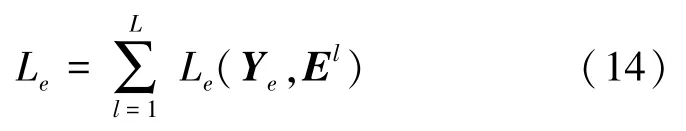
GloVe[16]將語料庫中詞匯X在詞匯Z出現的情況下出現的概率PX|Z與詞匯Y在詞匯Z出現的情況下出現的概率PY|Z的比值,稱為共現概率比。當X與Z的關聯性和Y與Z的關聯性都很強或者都很弱時,共現概率比趨于1,否則共現概率比趨于很大或者趨于零。通過引入第三個詞匯Z,共現概率比很好地描述了詞匯X和詞匯Y間的相似性。受此啟發,為使公式(8)中圖像特征更好地映射到語義空間,通過計算映射后的特征與整體補充語義特征的相似度矩陣Av,a,實例標簽語義特征與整體補充語義特征的相似度矩陣At,a,并計算2 個相似度矩陣之間的相似熵損失:
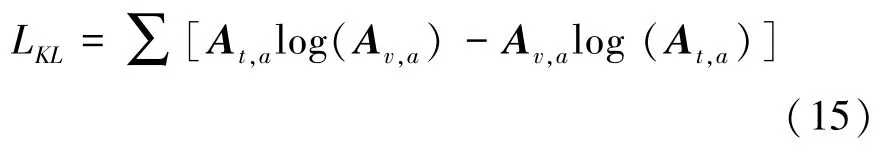
模型的總損失如式(16)所示:
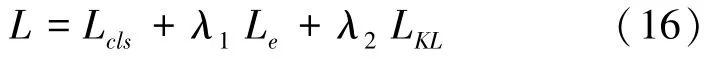
其中,λ1,λ2為超參數,用于調整損失Le和LKL對網絡模型訓練的影響。
2 實驗
2.1 數據集
為了更好地對比分析模型性能,本文在小樣本學習方法常用的Mini-ImageNet 和Tiered-ImageNet數據集上進行了實驗。本節中所有實驗均在搭載NVIDIA GeForce TiTan X 12 GB 顯卡、Intel i7 -9700KF 處理器并具有16 G 運行內存的PC 機上完成,采用Linux 版本的PyTorch 10.2 深度學習框架實現模型的搭建。
Mini-ImageNet 數據集是ImageNet[18]的子集,有100 個類別,每類由600 張圖片組成。有2 種常見的使用方法。一種方法將80 個類別作為訓練集,剩余的20 個類別作為驗證集。另一種方法將數據集劃分為包含64 個類別的訓練集、16 個類別的驗證集和20 個類別的查詢集。本文使用后一種方法。
Tiered-ImageNet 數據集同樣節選于ImageNet數據集。不同的是該數據集比Mini-ImageNet 包含更多的類別,也包含更多的圖片數量。在規模上,包含了608 個小類別,平均每個類別有1 281 個樣本;在語義結構上,是將數據集劃分成34 個父類別來確保類別之間的語義差距。在以往的工作中,將20 個父類別作為訓練集、對應351 個子類別,6 個父類別作為驗證集、對應97 個子類別以及8 個父類別作為測試集、對應160 個子類別。
2.2 實驗配置
本文分別采用2 種流行的網絡Conv4 和ResNet-12[15]作為圖像特征提取網絡,使用GloVe計算語義特征。Conv4 主要由4 個Conv -BN -ReLU塊組成,每個卷積塊包含一個64 維濾波器3×3 卷積,卷積輸出分別輸入到后面的批量歸一化和ReLU非線性激活函數。前2 個卷積塊還包含一個2×2 最大池化層,而末端2 個卷積塊沒有最大池化層。ResNet12 主要有4 個殘差塊,每層殘差塊由3層卷積層接連組成,并在殘差塊后添加了2 × 2 的最大池化操作。遵循大多數現有的小樣本學習工作所用的標準設置,使用5-way 1-shot 和5-way 5-shot 兩種實驗設置和提前結束策略,并將Adam 作為學習優化器。在Mini-ImageNet 上訓練時,使用隨機采樣并構建300 000 個episode,設置Adam 初始學習率為0.001,每15 000 個episode 將學習率衰減0.1。對于Tiered-ImageNet 數據集,使用隨機采樣并構建500 000 個episode,設置Adam 初始學習率為0.001,每20 000 個episode 將學習率衰減0.1。
2.3 模型對比實驗和分析
本文模型與其他使用圖模型和使用語義模態的小樣本學習方法在Mini -ImageNet 和Tiered -ImageNet 數據集上的實驗結果見表1、表2。表中,標注N/A 表示該實驗結果在原文獻中并未展示出來。
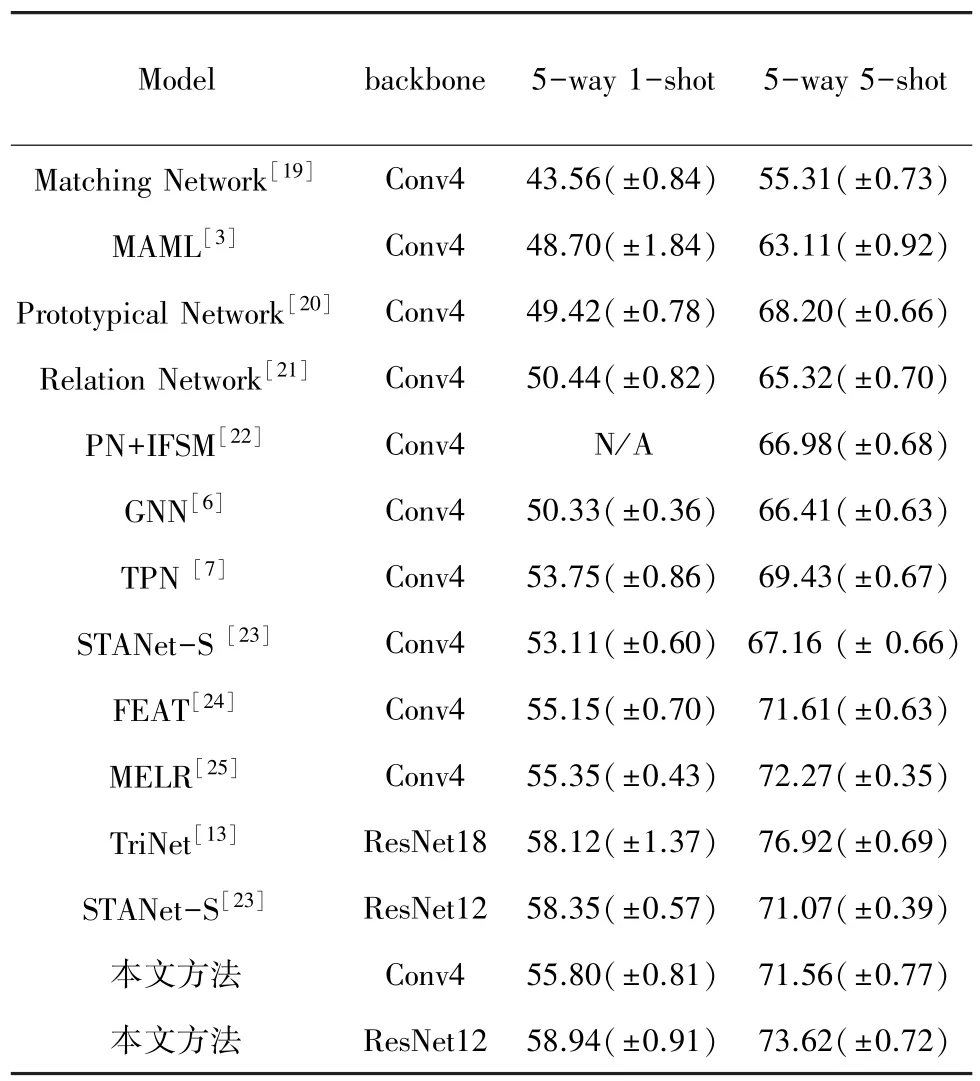
表1 在Mini-ImageNet 數據集上不同模型的準確率Tab.1 Accuracy of different models on the Mini-ImageNet dataset
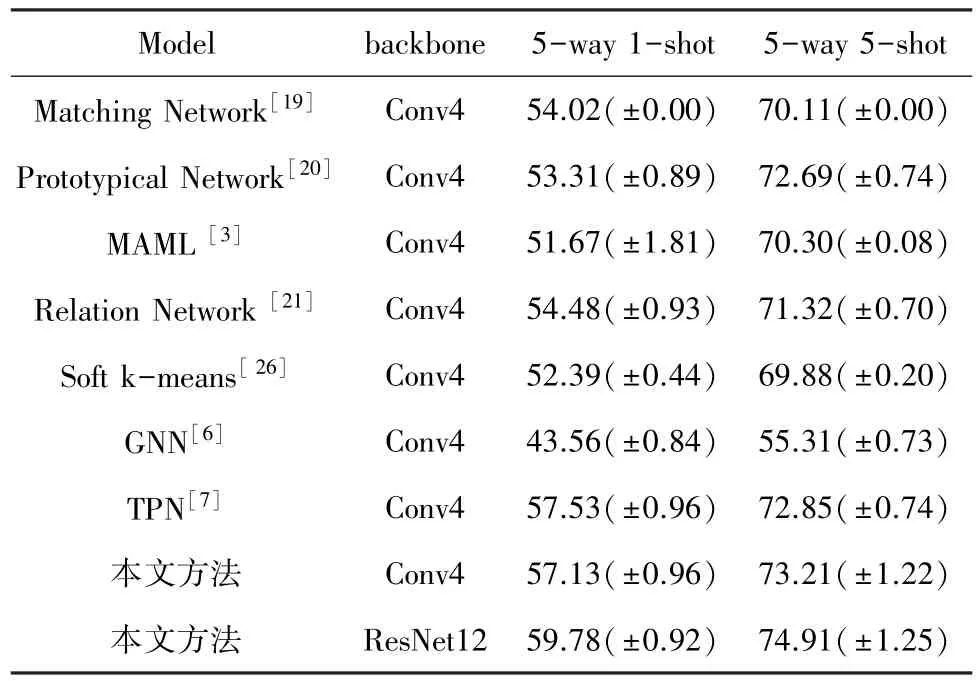
表2 在Tiered-ImageNet 數據集上不同模型的準確率Tab.2 Accuracy of different models on the Tiered-ImageNet dataset
表1 給出了在Mini-ImageNet 數據集上,本文模型與其他小樣本方法在5-way 1-shot 和5-way 5-shot 兩種任務下的實驗結果。從實驗結果中可以看出,本文方法明顯優于當前大多數小樣本學習方法。本文方法與經典小樣本學習方法 Matching Network[19]、MAML[3]、Prototypical Network[20]、Relation Networks[21]相比,準確率有明顯的提升。與基于圖神經網絡的小樣本方法相比,在1-shot 情況下本文方法比GNN[6]準確率高出5.47%,在5-shot情況下高出5.15%,而與TPN[7]相比,本文在1-shot情況下準確率高出了2.05%,5-shot 情況下高出了2.13%。此外,與同樣使用語義信息的TriNet[20]相比,本文模型在1-shot 情況下高出0.82%,但是在5-shot情況下,TriNet[12]的準確率高于本文模型。同樣使用Conv4 特征提取網絡,與近年來最新的FEAT[24]、MELR[25]模型對比,本文模型雖然在5-shot的情況下準確率略低,但在1-shot 情況下準確率仍然高過這些基準參照模型。
表2 給出了在Tiered-ImageNet 數據集上,本文的模型與其他小樣本方法在5-way 1-shot 和5-way 5-shot兩種任務下的實驗結果。從實驗結果中可以看出,本文方法明顯優于當前大多數小樣本學習方法。本文方法與經典小樣本學習方法Matching Network[19]、MAML[3]、Prototypical Network[20]、Relation Networks[21]相比,準確率均有較大提升。與基于圖神經網絡的小樣本方法對比,在1-shot 情況下本文方法比GNN[6]準確率高出11.47%,在5-shot 情況下高出16.4%;與TPN[7]相比,本文方法在5-shot 情況下準確率高出了0.34%,但在1-shot 情況下TPN[9]有著更高的分類準確率。
在Mini-ImageNet 和Tiered-ImageNet 數據集上,將5-way 1-shot 和5-way 5-shot 兩種情況進行對比可以發現隨著支持集的樣本數量增加,分類的效果也更好。將Conv4 和ResNet12 兩種骨干網絡進行對比發現,采用更加深層的特征提取網絡能得到更高的準確率。
2.4 消融實驗
本節通過在Mini-ImageNet 數據集上進行消融實驗證明本文模型的有效性以及檢驗部分參數對模型訓練的影響。
首先,本文探究圖像特征關系傳播模塊迭代更新層數對模型準確率的影響。圖像特征關系傳播模塊使用圖神經網絡充分挖掘圖像特征之間的關聯信息,由多層包含特征節點和相似度鄰接矩陣的相同結構組成,網絡層數影響著模塊的參數,對整體性能起著非常重要的作用,所以有必要對層數進行消融實驗分析。選擇5-way 1-shot 作為任務設定,層數分別選擇1、2、3、4、5,模型準確率如圖3 所示。從圖3 中可以看出,當層數由1 到3 時,模型分類準確率有著明顯提升,說明在層數較少時,增加模型的層數可以提升整體模型的分類效果。當層數從3 到5 時,模型分類效果有些許波動,但整體而言準確率趨于穩定,不斷增加模型層數不能持續提升模型的分類準確率。因此本文在其他所有實驗中,模型層設定為3,既能得到較高的模型分類準確率,同時也避免了過多耗時的計算量。
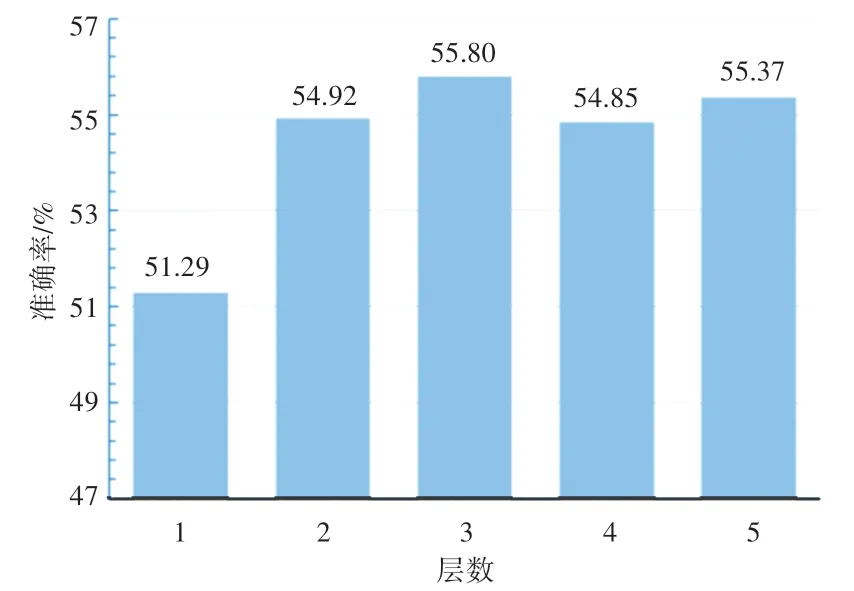
圖3 5-way 1-shot 任務下,圖像信息傳遞模塊層數對模型分類準確率的影響Fig. 3 Influence of image information transfer module layers on model classification accuracy under 5-way 1-shot task
此外,為探究混合語義模塊在模型訓練中發揮的作用,對混合語義模塊進行消融實驗。Mini-ImageNet 數據集上,混合特征模塊消融實驗結果見表3。表3 中,“僅圖像”表示僅使用本文中的圖神經網絡進行訓練分類。“標簽語義”表示混合語義模塊直接使用標簽語義而忽略其他語義信息。“標簽語義+視覺對齊語義”雖然使用補充語義信息,但是補充語義僅使用在損失函數中改進模型訓練。從實驗結果可以看出,引入語義信息能提高小樣本圖像分類的表現效果。此外,使用混合語義模塊在5-way 5-shot 任務下準確率的提高要遜色于5-way 1-shot 任務,主要原因是在5-shot 情況下,圖像信息將更加豐富,而語義信息模型效果的提升就很有限。
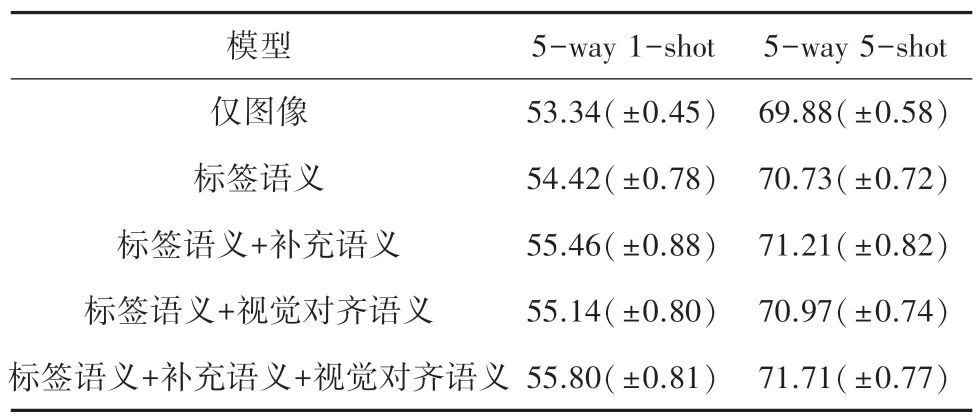
表3 Mini-ImageNet 數據集上混合特征模塊消融實驗結果Tab.3 Ablation experimental results of hybrid feature module on Mini-ImageNet dataset
3 結束語
本文首先提出了基于混合語義的圖神經網絡小樣本分類方法。該方法考慮實例圖像特征和語義特征之間的互補性,由此得到的融合特征,能更全面描述實例信息。其中,使用圖神經網絡模型綜合考慮支持集和查詢集圖像之間的關系,并使用補充語義來增強標簽語義特征的表達能力,以及利用圖像對齊語義特征構造了實例級語義特征。本文模型在Mini-ImageNet 和Tiered-ImageNet 數據集上取得了良好的分類效果。考慮到現有模型面對不同任務時,會遺忘已有的分類知識的災難性遺忘問題,進一步擴展模型應對小樣本增量學習則是未來研究工作的重點。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
外語學刊(2011年1期)2011-01-22 03:38:33
