基于無線傳感網絡分簇策略的分布式數據庫加密存儲研究?
2022-02-05 06:01:22段曉聰
傳感技術學報 2022年12期
段曉聰
(廣州華商學院數據科學學院,廣東 廣州 511300)
在一個開放性網絡環境中,分布式數據庫是其必不可少的一部分,它主要用來對采集的各類數據實行數據分享,將其輸送到各個客戶端中供給用戶使用[1]。所有的數據庫都具備數據共享的特點,但由于分布式數據庫所處的環境具有公開性,導致分布式數據庫極易出現安全問題,遭受到外界的攻擊[2]。除了遭受到黑客攻擊及病毒攻擊外,分布式數據庫還存在安全系統脆弱、網絡協議脆弱的缺陷,針對分布式數據庫潛在的劣勢,需要加強分布式數據庫的安全性及存儲性。所以為了解決上述存在的問題,需要對分布式數據庫加密存儲方法實行研究。
陳曉琳等人[3]提出分布式數據庫Greenplum 在地震前兆數據存儲中的應用方法,由于分布式數據庫具有數據共享服務,所以在發生地震前會先采集地震數據,并根據采集到的數據設計出分布式數據庫存儲方案,利用該方案構建出分布式數據庫環境,用其對數據處理后再加密,最終將加密后的數據存儲到分布式數據庫,該方法處理的數據存有欠缺,存在加密效率差的問題。孫僖澤等人[4]提出基于可搜索加密機制的數據庫加密方法,該方法優先在數據庫中建立了一個可查詢框架,便于查詢加密數據,再設計出一個數據庫加密方案,將其引入到數據庫中防止數據泄露,大大提升了數據的安全性,以加密方案為基礎引入安全索引結構,采用密碼技術加密數據庫內的數據,并存儲加密數據,從而實現數據庫的加密存儲,該方法設計的可查詢框架不夠完善,存在解密時間長的問題。
為了解決傳統方法中存在的分布式數據庫加密效率差,數據解密耗時長的問題,本文在上述研究方法的基礎上,提出基于無線傳感網絡分簇策略的分布式數據庫加密存儲方法。通過無線傳感網絡分簇策略降低網絡能耗,實現網絡節點分簇,以提高計算機網絡的加密存儲效率。構建分布式加密存儲模型,通過分布式數據庫加密、存儲、解碼等操作,實現分布式數據庫加密存儲。
1 分布式數據庫
為研究分布式數據庫加密存儲方法,對分布式數據庫結構體系及無線傳感網絡分簇做出研究。分析得出分布式數據庫在數據傳輸過程中會出現服務器分布負載高的問題,導致數據庫的容錯性低、安全性差。構建能量損耗模型獲取無線傳感網絡適當的分簇數,對無線傳感網絡中的節點分簇,采用加權傳輸距離代價函數計算節點及原始聚類中心的距離,有效均衡無線傳感網絡分簇過程中的節點能耗,達到改善計算機網絡節點能量及網絡生命周期的目的。
1.1 分布式數據庫結構體系
一般情況下分布式數據庫是通過一組數據組合而成的,這些數據都來自不同的計算機網絡中,且全部都分布在不同的計算機上,在各個計算機網絡內,每個數據的結點都存有獨立性,這樣有利于人們對數據的應用。應用數據時,需要利用計算機網絡的通信系統將數據輸入到全局應用中,令其執行,而該應用就是分布式數據庫[5]。
在分布式數據庫中包含兩種系統,其中DDBMS管理系統是可以構建、管理及維護數據庫的一個軟件,也是分布式數據庫必不可少的一部分。
由于應用于分布式數據庫開放性網絡,根據這一特點,分布式數據庫就適用于較分散的部門,這樣該部門可以把需要存儲的數據存放在本地數據庫中,以此減少通信費用,加快數據響應時間,降低數據冗余[6]。
但因為分布式數據庫內潛存的數據較多,極易導致數據在傳輸過程中出現服務器分布負載高的問題,導致數據庫的容錯性低、安全性差。所以針對分布式數據庫存在的問題,需要對分布式數據庫的加密存儲實行研究。
1.2 無線傳感網絡分簇
提升分布式數據庫的加密存儲效果前,首先需要利用無線傳感網絡分簇策略改善計算機網絡的節點能量及網絡生命周期,以此改善網絡的能耗,使計算機網絡的能耗達到均衡的效果,增強分布式數據庫在計算機網絡中的加密存儲效率。
①確立分簇數
在無線傳感網絡分簇算法中成簇是該算法的關鍵部分,確立適當的分簇數也是設立分簇策略的核心。
通常來說,當分簇數量過多時,就會導致分簇開銷大;當分簇數量過少時,各個簇中的節點就會增多,因此增加了簇首的負擔,導致簇首會消耗大量的能耗,直至死亡。所以確立適當的分簇數可以提高計算機網絡鏈路的輸送效率,以此達到能量損耗均衡的目的[7]。
為了能夠更好地確立無線傳感網絡的分簇數,構建一個能量損耗模型,以此獲取適當的分簇數,實現分簇數的確立。因為建立的模型主要組成部分為電路、功率及接收電路[8],所以在構建模型時所耗損的能量就用下述方程描述:

式中,ETx描述的是耗能,b描述的是發送端,d描述的是接收端,Eelec描述的是電路在發送及接收時產生的能耗,u1、u2均描述的是不同輸送距離下的能耗系數。
根據式(1)可知,數據在接收期間的耗能標記為:ERX=b+Eelec。式中,ERX描述的是接收數據時的耗能。
數據在發送和接收時所產生的距離臨界值表達式為:d0=。根據設定的臨界值方程表達式,設定簇內節點輸送數據時產生的耗能通過Eno-CH描述,那么建立的能耗損耗模型方程表達式就可以標記如下:
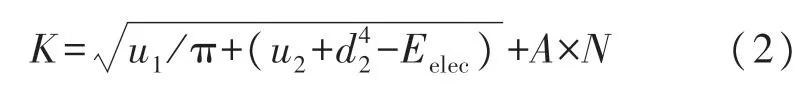
式中,K描述的是分簇數量,A描述的是分布區域長度,N描述的是節點總數量。
根據式(2)可得,當無線傳感網絡的A及N的數據確立后,就可以將網絡中的損耗參數引入到式(2)中,以此確立出合適的分簇數K,完成對分簇數K的確立。
②確立原始聚類中心
根據設定的分簇數K,采用K-均值算法對無線傳感網絡中的節點分簇[9]。由于在節點分簇時需要利用K-均值算法對數據實行聚類,而原始聚類中心會對聚類的結果造成影響,所以為了確保聚類效果,需要確定原始聚類中心。具體步驟如下:
1)優先計算數據集合X中的兩個節點,以此獲取兩個節點之間的距離D(xi,xj),從中得出兩個距離最近的節點,通過集合Sm描述。獲取到Sm后需要在X中消除其余兩個節點。
2)重新建立一個集合X,從中取得新的Sm后將其引入到步驟1)中的Sm,同時消除X內的節點。
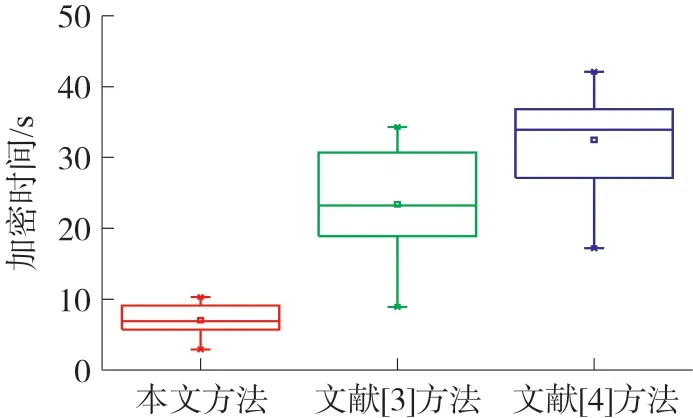
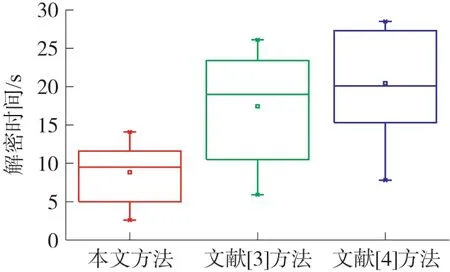
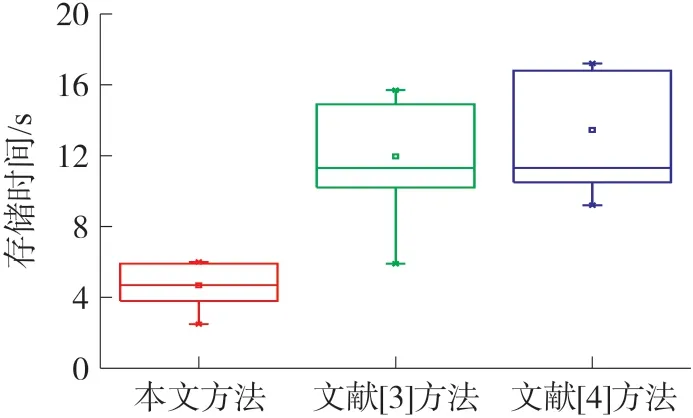
3)重復步驟2),直至節點數量低于N/K為止;若節點個數n 4)經過上述步驟后,直至取得最終形成K個集合的節點,對其計算后得到原始聚類中心,完成確立。 構建的無線傳感網絡能量損耗模型主要用來對數據實行發送、傳輸及融合處理等,從而產生能量損耗。為了提升無線傳感網絡分簇效率,需要均衡損耗的能源。因此采用加權傳輸距離代價函數[10]表示節點及原始聚類中心的距離,用方程表達式定義如下: 式中,D(xi,cj)描述的是傳輸距離的代價函數,d1(xi,cj)描述的是距離,cj描述的是聚類中心,Sink描述的是匯聚節點,d2(cj,Sink)描述的是cj與Sink之間的距離,Rnode描述的是通信半徑,Darea描述的是直徑。φ1與φ2描述的是權重因子。 式(3)可以有效均衡無線傳感網絡中的節點能耗。因而根據均衡后的無線傳感網絡,對其實行節點分簇,從而實現無線傳感網絡分簇,達到改善計算機網絡節點能量及網絡生命周期的目的[11],那么具體分簇流程如圖1 所示。 分析圖1 可知,部署無線傳感網絡節點,計算最佳分簇數目,計算節點與聚類中心的距離,或取得節點距離最近的兩個點,并通過加權傳輸距離代價函數重新計算其原始聚類中心,均衡無線傳感網絡中的節點能耗,確定節點分簇。 圖1 無線傳感網絡分簇流程 基于上述無線傳感網絡分簇流程,實現分簇,均衡了計算機網絡中的分布式數據庫能耗,提升了分布式數據庫的加密存儲效率。在此基礎上構建加密存儲模型,利用該模型對分布式數據庫進行存儲、加密、解密、明文獲取等過程,實現分布式數據庫的加密存儲。 為了能夠更好地實現數據存儲,首先構建一個分布式加密存儲模型,構建的模型如圖2 所示。 根據圖2 可知,在構建的模型中主要具備用戶及管理員、SS 存儲服務器、AA 屬性服務器及CAA中心授權服務器等。而構建的模型總共由加密、存儲及解密三個部分組成。 圖2 構建的分布式加密存儲模型 利用構建的模型加密存儲分布式數據庫,具體流程如下所示: ①首先需要利用該模型對分布式數據庫中的數據實行初始化,優先在數據庫中選取兩個p階群的數據,分別表示為G和G1。利用該模型對G和G1實施雙線性映射,即e:G×G→G1。其中還包含由G生成的數據元g,再通過模型生成主密鑰y0∈,而模型中的屬性服務器AA 則可以生成與AA 相對應的私鑰,即。 ②根據設立的密鑰,對分布式數據庫中的數據加密。在AA中確立數據屬性集,即Ac,而與Ac相對應的則是第w個AA 的分管屬性集。隨機選取一個AA 中的門限值dw∈,以此用作解密用戶的屬性交集個數。再利用屬性l對AA 中的數據編碼,從中得到數據的加密消息集,定義為:{M1,M2,…,Mk}。并從{M1,M2,…,Mk}中確立一個統一的消息標識hID,通過模型內的主公鑰Y=gyo計算{M1,M2,…,Mk}后,就能夠得到分布式數據庫內的消息密文[12]。 ③獲取到密文后,用戶就可以在z個SS 中選擇想要加密的服務器,并把取得的密文輸送到想要加密的服務器中,完成加密分發。 ④加密完服務器后,需要用戶對想要查看的服務器解密,所以用戶需要向服務器發出解密請求,利用模型中的屬性服務器AA 對用戶的ID 識別后即可解密。 通過接收用戶發出的解密請求Aj及CAA 給予的密鑰Dc,由AA 將部分密鑰發送給用戶手中,該部分密鑰用方程表達式定義如下: 用戶取得部分密鑰后,就可以對部分密鑰計算,以此取得最終解密結果,完成解密。 若想在解密后獲取最原始的分布式數據庫明文信息,就需要對解密后的數據解碼,以此獲得數據明文。 進行無線傳感網絡分簇后,改善了計算機網絡的生命周期,均衡了網絡的能耗,提升了分布式數據庫的加密存儲效率,通過構建分布式加密存儲模型對分布式數據庫實行加密、存儲、解碼等操作,最終實現分布式數據庫加密存儲的研究。 為了驗證基于無線傳感網絡分簇策略的分布式數據庫加密存儲方法的有效性,需要對該方法實行仿真分析、對比測試。 采用基于無線傳感網絡分簇策略的分布式數據庫加密存儲研究方法(本文方法)、云實驗室數據庫資源云存儲屬性基加密仿真(文獻[3]方法)和基于可搜索加密機制的數據庫加密方案方法(文獻[4]方法)實行測試對比。分布式數據庫在加密存儲時,若需要加密存儲的數據屬性集數量過大,那么耗費的加密存儲時間就長。所以為了確保分布式數據庫在加密存儲時的效率,需要采用本文方法、文獻[3]方法和文獻[4]方法分別對分布式數據庫進行加密、解密、存儲測試。本次仿真分析選擇的數據集為Non-local Neural Networks[13],在該數據集內共選取750 個數據屬性集,利用三種方法對屬性集開展加密時間測試。測試平臺為MySQL5.5,運行環境為Muntul4.04LTE.Proxy。加密、解密、及存儲時間結果如下: ①設立測試時間共為60 s,其中最佳加密時間為15 s,若在最佳時間內完成對屬性集的加密,那么該方法的加密效率最優,表明了該方法的加密效果好,具體測試結果如圖3 所示。 圖3 三種方法的加密時間測試 圖3 中,本文方法加密750 個數據屬性集時,所用時間均不超過15 s,表明了本文方法在最佳時間范圍內完成了對屬性集的加密。文獻[3]方法加密時間逐漸升高,最終達到34.3 s,與本文方法相比,文獻[3]方法的加密效率較差。 ②以上述設定參數為基礎,在60 s 內對加密的數據屬性集實行解密,同時設置的最佳范圍時間為20 s,利用三種方法對屬性集實施解密時間測試,依據測試結果驗證解密效率。測試結果如圖4 所示。 圖4 三種方法的解密時間測試 圖4 中,本文方法的解密時間要小于文獻[3]方法和文獻[4]方法,可見本文方法的解密效率最高,而文獻[4]方法的解密效率最低。本文方法對750 個數據屬性集的解密時間均不超過12 s,屬于最佳解密時間,由此可見本文方法的解密時間最快。 ③根據上述加密數據,利用本文方法、文獻[3]方法和文獻[4]方法對加密后的數據屬性集實行存儲時間測試,選取600 個需要存儲的加密數據屬性集,本次測試時間為60 s,設定最佳存儲時間為10 s,那么測試結果如圖5 所示。 圖5 三種方法的存儲時間測試 分析圖5 可知,在整體測試中,本文方法的存儲時間都屬于最佳存儲時間,在3.8 s~6.0 s 之間,且沒有超出設定范圍。但與其相反的是,文獻[3]方法和文獻[4]方法在6 組測試中,僅在第一組測試時處于最佳存儲時間內,因而判定本文方法的存儲效率最高。 綜上所述,本文方法的加密、解密、存儲效率都要優于其余兩種方法,這主要是因為該方法分簇了計算機網絡節點,以此均衡了網絡能量,提升了分布式數據庫的加密存儲效率,使該方法對數據的加解密、存儲效果最佳。 在計算機網絡中,由于分布式數據庫所處的環境為公開環境,所以會導致分布式數據庫受到黑客攻擊,使數據遭受到篡改,針對分布式數據庫加密存儲方法存在的問題,提出基于無線傳感網絡分簇策略的分布式數據庫加密存儲方法。該方法以分布式數據庫結構體系為基礎,利用無線傳感網絡分簇策略對計算機網絡節點實行分簇,以此均衡網絡節點能量,再構建一個加密存儲模型,對分布式數據庫加密存儲,實現分布式數據庫的加密存儲。仿真結果表明,該方法對750 個數據屬性集的加密時間均不超過15 s,數據存儲時間都在3.8 s~6.0 s 之間,較對比方法均有較大的提升。由此可見,本文方法對分布式數據庫加密存儲有效性極高,具備長遠的發展前景。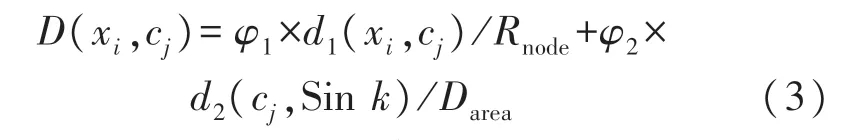

2 分布式數據庫加密存儲
2.1 構建加密存儲模型

2.2 分布式數據庫加密存儲流程
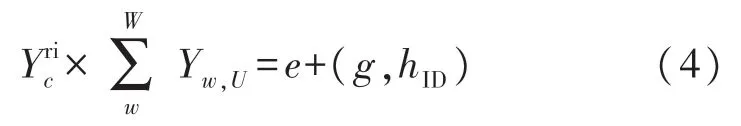
3 仿真分析
4 結束語
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
