一種實值深度置信網絡在人體血壓預測中的應用
2022-01-28 03:00:46劉少陽馮云霞
計算機應用與軟件 2022年1期
關鍵詞:模型
宋 波 劉少陽 衣 鵬 馮云霞
(青島科技大學 山東 青島 266100)
0 引 言
高血壓是我國乃至世界發病率最高的慢性病之一,它的發生往往會并發心肌梗死、心力衰竭、腦出血等一系列心腦血管疾病,嚴重危害人體健康。雖然高血壓患病幾率高、發病危害大、難以根治,但其仍然屬于可控疾病。文獻[1]指出:高血壓患者可以通過服用降壓藥物、生活方式干預等途徑降低血壓水平,進而減少高血壓及其并發癥的發病幾率,提高患者的生存質量。
人體血壓水平不僅與用藥策略和生活方式有關,還受其他因素影響,如季節、溫度等環境因素,年齡、BMI指數及腰圍等生理指標因素。將影響血壓水平的多方面因素納入人體血壓預測模型中,定量分析相關因素對于血壓未來變化的影響,有助于提高人體血壓預測的準確性,并且血壓預測模型的建立還可以輔助醫師為高血壓患者及高危人群制定個性化的降壓策略,預測患者采取降壓策略一個隨訪周期后的血壓水平,對于高血壓疾病的控制具有重大現實意義。
1 相關工作
現階段對于血壓預測的研究主要分為兩個方向,一種是狹義上的,即實時預測,通過挖掘血壓與某些人體生理信號之間的關聯關系,從而獲得更加準確的人體血壓水平值;另一種是廣義上的,即對未來血壓進行預測,根據影響血壓的相關因素數據預測血壓的未來值,構建血壓與其相關影響因素之間的關系模型。
在實時預測中,研究者們通常采用脈搏傳導時間(Pulse Transit Time,PTT)、心電圖(Electrocardiogram,ECG)、光電容積脈搏波(Photoplethysmograph,PPG),以及血壓儀示波等人體生理信號為基礎實現血壓預測。如文獻[2]采用長短期記憶神經網絡模型根據PTT數據預測得到收縮壓和舒張壓的值;文獻[3]通過小波神經網絡算法將PPG信號重建成完整的血壓波形的方式獲得收縮壓和舒張壓;文獻[4]以血壓儀示波信號作為輸入,通過深度波爾茲曼機學習示波信號與人體血壓之間復雜的非線性關系;文獻[5]將PPG和ECG數據作為輸入,應用支持向量機模型進行血壓預測。以上研究均需借助醫學設備獲取相關的人體生理指標來實現對血壓的實時預測,通常用于血壓的輔助測量,并不具備提前預測的能力。
目前,對于未來血壓預測的研究還相對較少,大部分工作只涉及單一方面的影響因素。如文獻[6]提出了一種基于遺傳算法優化的貝塔分布模型,用以預測隨著持續用藥時間的增加人體收縮壓的變化曲線;文獻[7]根據血壓值的歷史數據,采用多模糊函數模型來預測人體平均動脈血壓;文獻[8]以BMI指數、年齡、飲酒情況及吸煙情況等血壓影響因素作為輸入,通過BP神經網絡和徑向基神經網絡構建人體血壓預測模型。以上方法分別從用藥情況、歷史數據、生活習慣等不同方面出發進行血壓預測,未能充分考慮血壓是由多方面因素共同影響的結果,預測準確度方面也有較大的提升空間。
針對當前血壓預測方法中存在的問題,本文提出一種基于RDBN的人體血壓預測模型。該模型由多個GG-RBM單元和一層線性神經網絡組成,是一種接受實數型數據輸入,返回實數型輸出的深度網絡模型。模型采用無監督與有監督混合學習的方式,在無監督階段,通過多個GG-RBM單元組成的深層結構進行連續的非線性變換獲得血壓相關數據的最優低維表示。在有監督階段,通過線性神經網絡獲得血壓預測值,根據血壓預測值與真實值的誤差進行網絡參數的有監督微調,并采用Adam算法加速這一過程。
2 基于RDBN的人體血壓預測模型
2.1 RDBN網絡整體架構
傳統DBN網絡[9]由多個伯努利-伯努利結構的受限波爾茲曼機(Bernoulli-Bernoulli Restricted Boltzmann Machine,BB-RBM)單元組成,其只能接受二值型的輸入,但實際血壓影響因素中包括實值類型的數據,使用傳統結構難以實現血壓數據的特征學習。針對該問題,本文采用將原雙層伯努利結構連續化為高斯結構的GG-RBM單元組建成的RDBN網絡構建血壓預測模型。不僅能夠克服傳統結構中輸入僅可為二值型數據的局限,還將輸出連續化,減少了模型提取連續型數據特征時所產生的誤差,提高了網絡整體的泛化能力。
本文所提出的血壓預測模型結構如圖1所示,包含一個輸入層、多個隱藏層和一個輸出層。輸入層接受影響血壓水平的相關因素數據;隱藏層通過逐層非線性變換,自動弱化與未來血壓相關性小的輸入因子,強化對未來血壓影響大的輸入因子權值,形成影響未來血壓的相關因素數據的最優低維表示;輸出層將隱藏層特征提取的結果作為輸入,通過線性激活函數映射得到人體血壓的預測值。
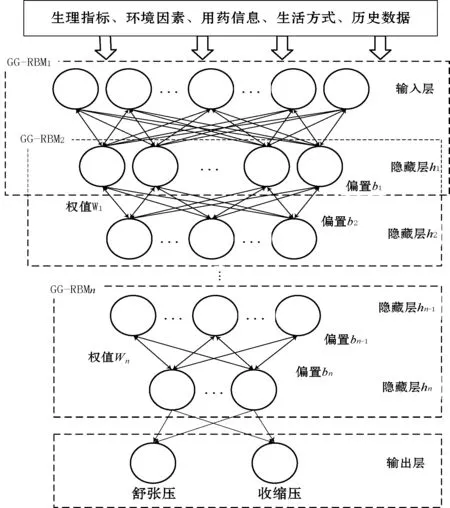
圖1 血壓預測模型的網絡結構
2.2 無監督學習階段
如圖2所示,無監督學習是RDBN網絡內部GG-RBM單元從上至下依次進行無監督預訓練的過程。本文提出的基于RDBN的血壓預測模型能夠通過這一過程自動地完成對作用于未來血壓相關因素的特征學習,不需要人為設計和參與較為復雜的血壓影響因素的特征過程。
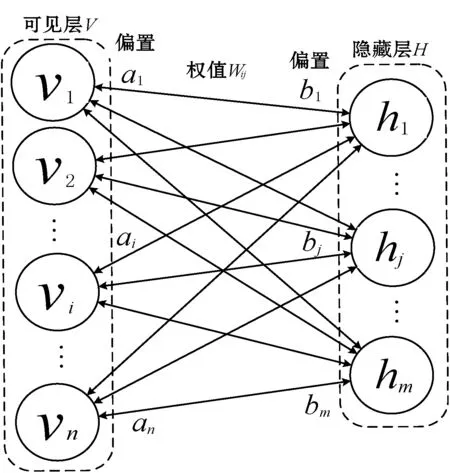
圖2 GG-RBM結構
本文采用的GG-RBM單元與傳統RBM[10]的區別就是在可見層和隱藏層加入高斯噪聲使輸入、輸出為[0,1]區間的實值類型,故其能量關系函數可表示為:
(1)
式中:θ=[wij,ai,bj]表示需要通過訓練求解的參數空間;c是高斯函數中的標準方差。根據能量函數,GG-RBM單元可見層和隱藏層之間的條件概率函數同樣服從高斯分布,可分別表示為:
(2)
(3)
對于上述GG-RBM單元,本文采用對比散度(Contrastive Divergence,CD)[11]算法實現快速訓練,求解參數空間θ的最優解。由于高斯噪聲的引入,相應修改隱藏層神經元的狀態信息、可見層神經元重構狀態信息和隱藏層神經元重構狀態信息分別表示為:
(4)
(5)
(6)
式中:σ表示Sigmoid函數。
根據重構信息與原始信息之間的差值,更新參數空間θ,將上一個單元的輸出作為下一個單元的輸入,逐層完成整個網絡的預訓練。從能量關系的角度看,整個預訓練過程實際上就是求解使得每個GG-RBM單元能量最低的參數空間θ的過程,單元中蘊含能量越低,表示該狀態越穩定,其出現的概率也越大。因此,當預訓練完成時,即獲得了由影響未來血壓的相關因素組成的原始輸入向量至最后一層隱藏層的最優非線性映射。
2.3 有監督學習階段
無監督學習階段完成時,即完成了參數空間θ的初始化。還需根據血壓的實際值與模型的預測值之間的差值對整個RDBN的網絡參數進行有監督微調,使其收斂至全局最優點[12]。為衡量模型預測與實際數據之間的差距程度,本文將血壓的預測值與實際值之間差值的平方和作為模型的損失函數,其表達式為:
(7)
式中:n表示訓練樣本容量;youtput,i和yfact,i分別表示第i個樣本血壓的預測值和真實值。
通常采用梯度下降(Gradient Descent,GD)[13]算法完成深層網絡的參數尋優,使模型的損失函數取得極小值。但該方法對于網絡中的各參數使用的是相同的學習率,不僅影響梯度下降的效率,還容易陷入局部最優。故本文基于能為不同參數設計自適應性學習率的Adam算法[14]設計梯度下降過程,加速人體血壓預測模型的有監督學習。該算法能根據梯度的一階矩估計和二階矩估計微調網絡,參數的更新規則如下:
(8)
式中:mt和vt分別表示第t次迭代參數梯度的一階矩估計和二階矩估計;ε是一個用于防止分母為0的極小常量;α表示網絡權重更新的步長因子。
雖然Adam算法能根據梯度的矩估計實現步長因子的自動退火,但步長因子α的設置仍會影響網絡最終的收斂狀態[14],當其初始值設置較大時,可能會導致梯度下降過程中直接跳過最優點,造成模型的欠擬合;當其初始值設置較小時,收斂速度又無法保證,容易造成過擬合。因此,本文在每次迭代過程均對步長因子α進行衰減處理,規則如下:
(9)
式中:t表示迭代次數。基于優化步長因子的Adam算法進行梯度下降過程,能夠讓網絡參數的更新過程更加平穩,避免了由于步長因子過大導致的損失函數震蕩,提高了人體血壓預測模型有監督學習的效率。
2.4 人體血壓預測流程
本文構建的RDBN網絡模型對于人體血壓預測的流程如圖3所示,具體步驟如下。
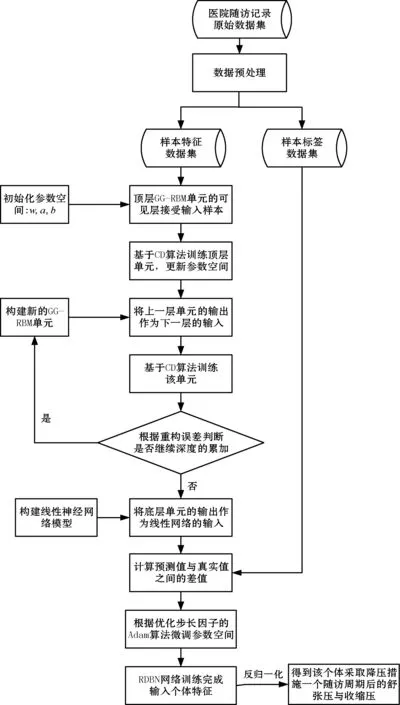
圖3 人體血壓預測流程
(1)以醫院高血壓隨訪記錄作為原始數據集,進行數據的預處理,將影響未來血壓的相關因素數據歸一化,形成未來血壓影響因素的樣本特征數據集:
(10)
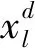
Y=[y1,y2,…,yl,…,yL]T
(11)
式中:yl表示第l條樣本數據所對應個體由舒張壓和收縮壓組成的二維向量。人體血壓預測模型就是為了構建從樣本特征數據集X到樣本標簽數據集Y的映射關系。
(2)層層堆疊GG-RBM單元組成深層網絡,根據重構誤差[15]確定網絡的深度。將步驟(1)中處理好的樣本特征數據集作為第一個GG-RBM單元的輸入,從上至下進行無監督的逐層訓練,得到人體血壓預測模型網絡參數的初始值。
(3)構建線性神經網絡與步驟(2)中底層GG-RBM單元的隱藏層相連,將隱藏層的輸出作為線性神經網絡的輸入,根據線性網絡的輸出值與對應樣本標簽數據之間的差值,通過優化步長因子的Adam算法迭代更新人體血壓預測模型的網絡參數。
(4)參數空間更新完成后,給定某個體的一組輸入數據后,可以得到該個體采取降壓措施一個隨訪周期過后的血壓情況。
3 實驗與結果分析
3.1 實驗數據與實驗環境
實驗數據采集自某市160多家社區服務基層衛生中心2014年8月至2017年4月對于高血壓患者及高危人群的追蹤隨訪記錄,選擇其中數據完整的80 162條記錄作為本文的實驗數據。將同一患者連續兩次的隨訪記錄進行整合,并根據指南[1]中影響未來血壓變化的相關因素確定模型輸入,結果如表1所示。

表1 血壓預測模型輸入特征定義表
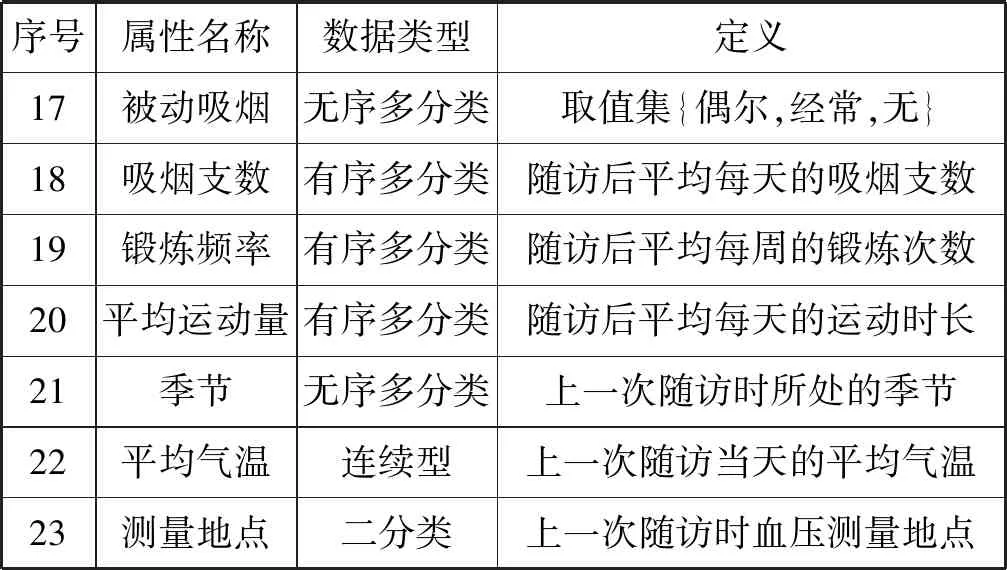
續表1
對于實驗數據中不同類型的屬性特征,本文采用不同方式進行處理。對于連續型特征,本文采用Z-score[16]完成歸一化;對于二分類型特征,本文將兩種類別分別映射為0和1;對于無序多分類型特征,本文先將其轉換為多個二分類型特征,再分別對其編碼,以季節特征為例,用是否為冬天、是否為夏天、是否為秋天、是否為春天表示原特征,1對應是,0對應否;對于有序多分類型特征,本文根據其取值集依次將其映射至[0,1]區間,以鍛煉頻率為例,將其取值集{從不,每周3次以內,每周3~6次,每天}分別映射為{0,0.333,0.667,1}。
實驗硬件環境為i7處理器3.60 GHz,32 GB內存,GeForce 1080Ti獨立顯卡;軟件環境為Windows 10操作系統,PyCharm集成開發環境,TensorFlow 1.4開源框架及Python 3.6。
3.2 性能評價指標
為了能更好地分析人體血壓預測模型的準確度,使用絕對平均誤差(Mean Absolute Error,MAE)和相對平均誤差(Mean Relative Error,MRE)作為模型的性能評價指標,定義如下:
(12)
(13)
式中:youtput,i和yfact,i分別表示第i個樣本血壓的預測值與真實值。MRE與MAE的值越小,表示人體血壓預測模型預測效果越準確。
3.3 參數設置與選擇
由于本文所構建的人體血壓預測模型采用深層RDBN網絡結構,其隱藏層層數和每層中神經元個數會影響最終的預測效果及運算時間。因此,著重對這兩個參數的選擇過程進行分析。其他參數的設置參考文獻[10-11,14]。
本文采用枚舉法與重構誤差法[15]相結合的方式確定隱藏層數目及每層神經元個數。首先,設置重構誤差閾值,若當前GG-RBM單元的重構誤差小于該閾值,那么就停止網絡深度的累加;然后,枚舉出頂層單元隱藏層神經元個數的可能值,選擇使其可見層重構誤差最小的神經元個數;再將頂層單元的隱藏層作為下一個單元的可見層,以同樣方式確定下一個隱藏層的神經元個數;以此類推,直至根據閾值判斷網絡深度停止累加,從而獲得最優網絡結構。
實驗設置如下:在樣本數據集中隨機抽取5 000個樣本用于無監督訓練,1 000個樣本用于有監督微調,剩余1 000個樣本用于測試。根據人體血壓預測模型輸入向量維數和實驗設備的性能,重構誤差閾值設置為5×10-4;隱藏層神經元個數取值范圍設置為[10,60],取值間隔為10。表2中給出不同網絡結構下人體血壓預測模型的表現,各指標均為重復實驗10次后得到的平均值,其中粗體表示最佳結果。
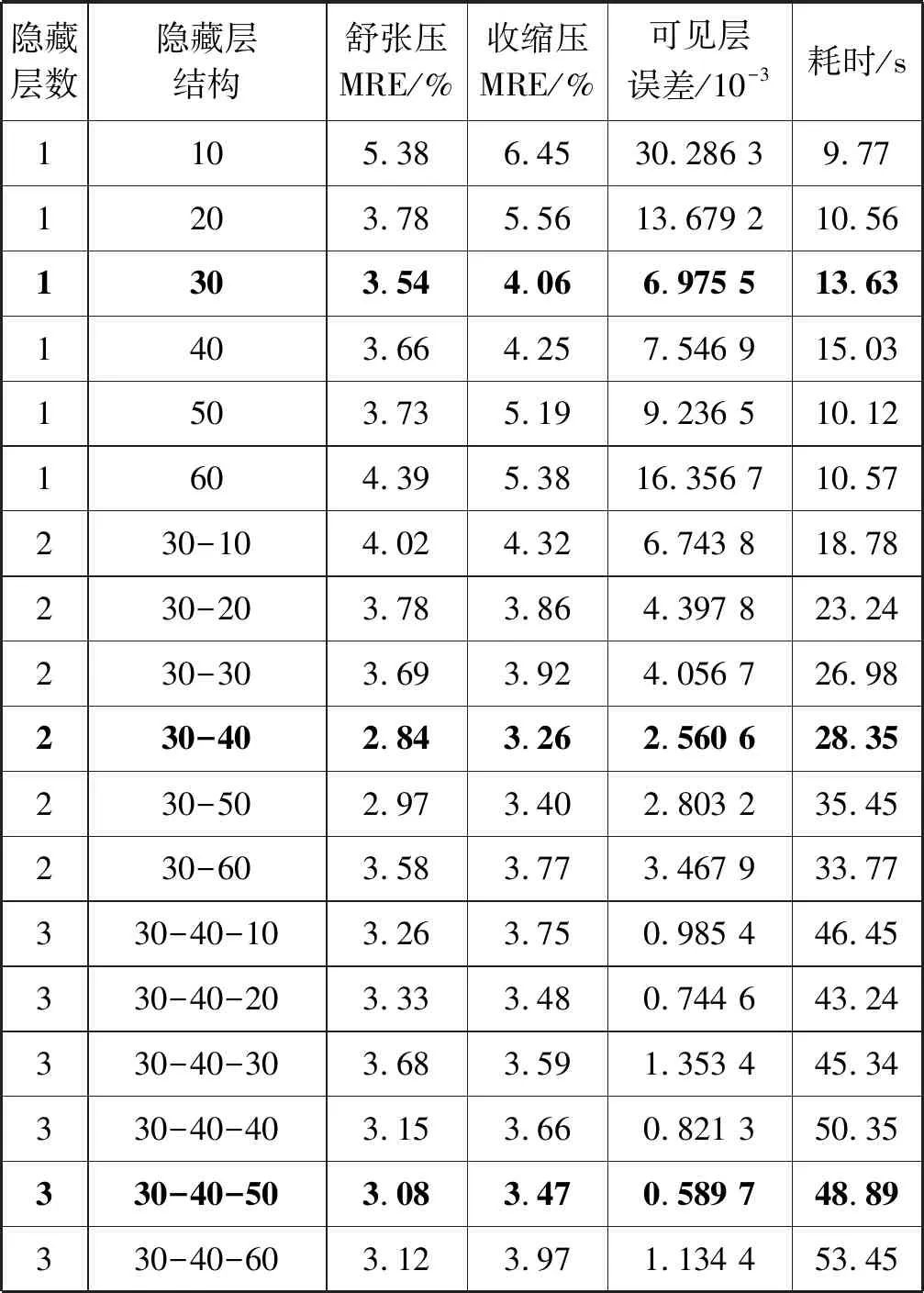
表2 不同網絡結構的實驗結果
可以看出,隨著網絡深度的不斷增加,GG-RBM單元的可見層重構誤差在不斷減少,這是因為深層單元學習了低層單元對數據分布的先驗知識,提高了重構信息的準確度;當隱藏層層數為2,神經元個數分別為30、40時,人體血壓預測模型對于舒張壓、收縮壓預測的相對平均誤差均達到最小,當網絡繼續加深時,誤差反而變大。因此,基于RDBN的人體血壓預測模型網絡結構確定為4層,兩個隱藏層的神經元個數從輸入層向輸出層方向依次為30和40。
3.4 不同模型對比分析
為進一步驗證本文提出的基于RDBN人體血壓預測模型的科學性與有效性,分別構建以下三種模型作為對比:傳統 BP神經網絡模型,定義為BP;頂層采用高斯-伯努利單元,其余各層采用BB-RBM的深層網絡,梯度下降過程采用基于優化步長因子的Adam算法,定義為DBN-Adam;由GG-RBM單元組成的深層網絡,梯度下降過程采用GD算法,定義為RDBN-GD。將樣本數據集以6∶1的比例分為訓練集和測試集,表3給出執行10次實驗不同模型的性能指標。

表3 不同模型性能指標對比
可以看出,本文提出的RDBN模型在挖掘多因素與患者未來血壓值的復雜關系上表現優異,無論是舒張壓預測還是收縮壓預測,均比其他三種模型誤差小,具有較好的預測精度。
同時,考慮到模型應用于實際血壓預測的過程中必然需經過海量數據訓練,遵循控制變量唯一的原則,比較RDBN模型與RDBN-GD模型隨著訓練集迭代次數的增加損失函數的變化情況,結果如圖4所示。可以看出,本文提出的基于優化步長因子的Adam算法進行參數尋優的RDBN網絡收斂速度較快,經過30次迭代后已接近最優解,能夠大幅度節約建模的時間成本,而采用GD算法的RDBN-GD網絡則需經過更多輪數的迭代。
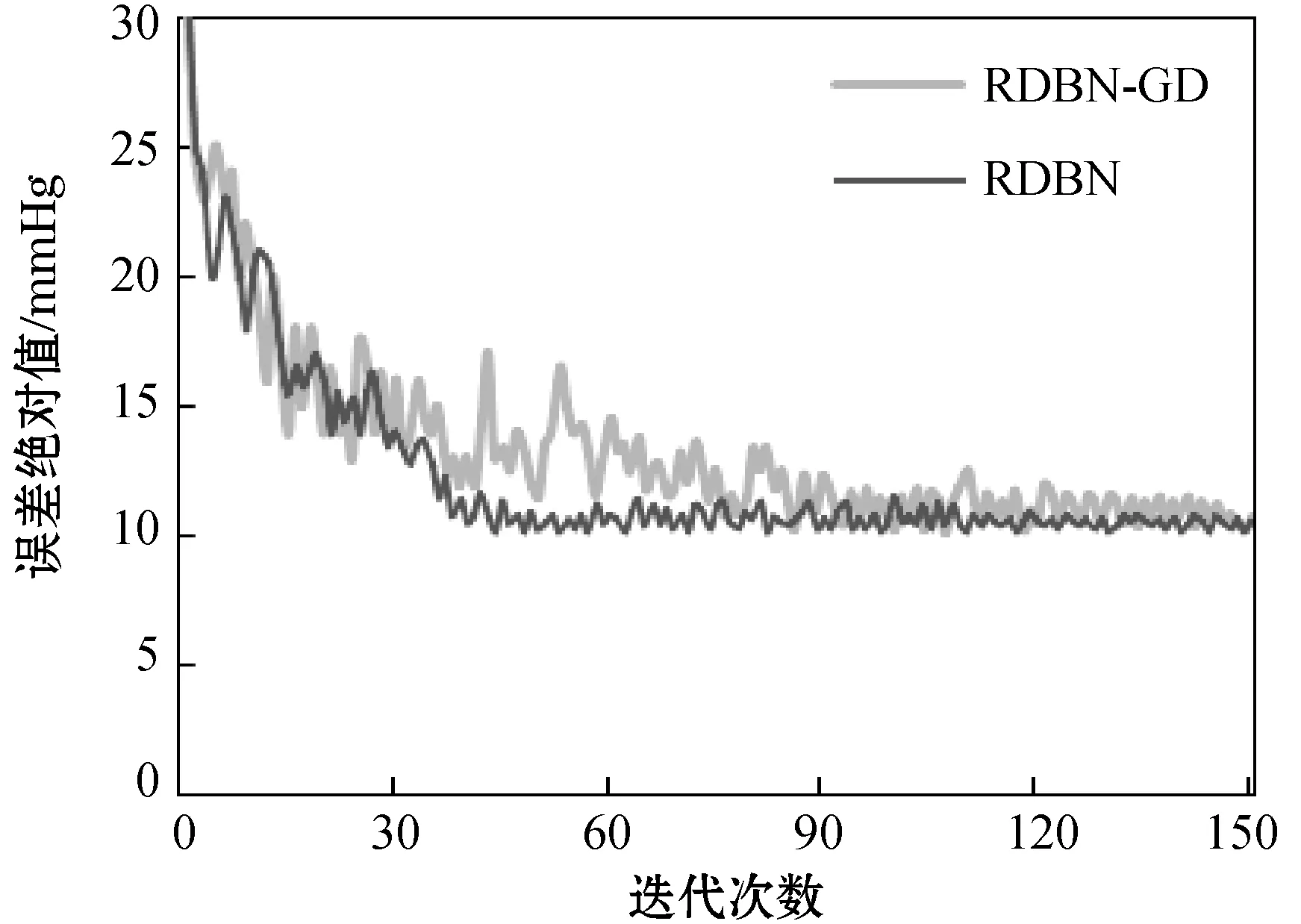
圖4 訓練誤差迭代對比圖
在不同模型性能對比的過程中,考慮到樣本數據集中醫生根據患者情況為其制定不同的隨訪周期,長期采取降壓措施可能會影響患者的血壓情況發生根本性改變,影響網絡模型對數據的擬合,故按隨訪周期長短將樣本數據集分為三類:周期在兩周以內的、周期為兩周至一個月的、周期在一個月以上的。圖5和圖6分別為四種模型在不同隨訪周期下對于患者舒張壓、收縮壓預測的平均絕對誤差對比圖。可以看出,隨著預測時間跨度的增加,四種模型的預測精度均有所下降,但RDBN 模型相比其他模型更加穩定,符合患者對于采取降壓措施一個隨訪周期后預測血壓變化的需求。
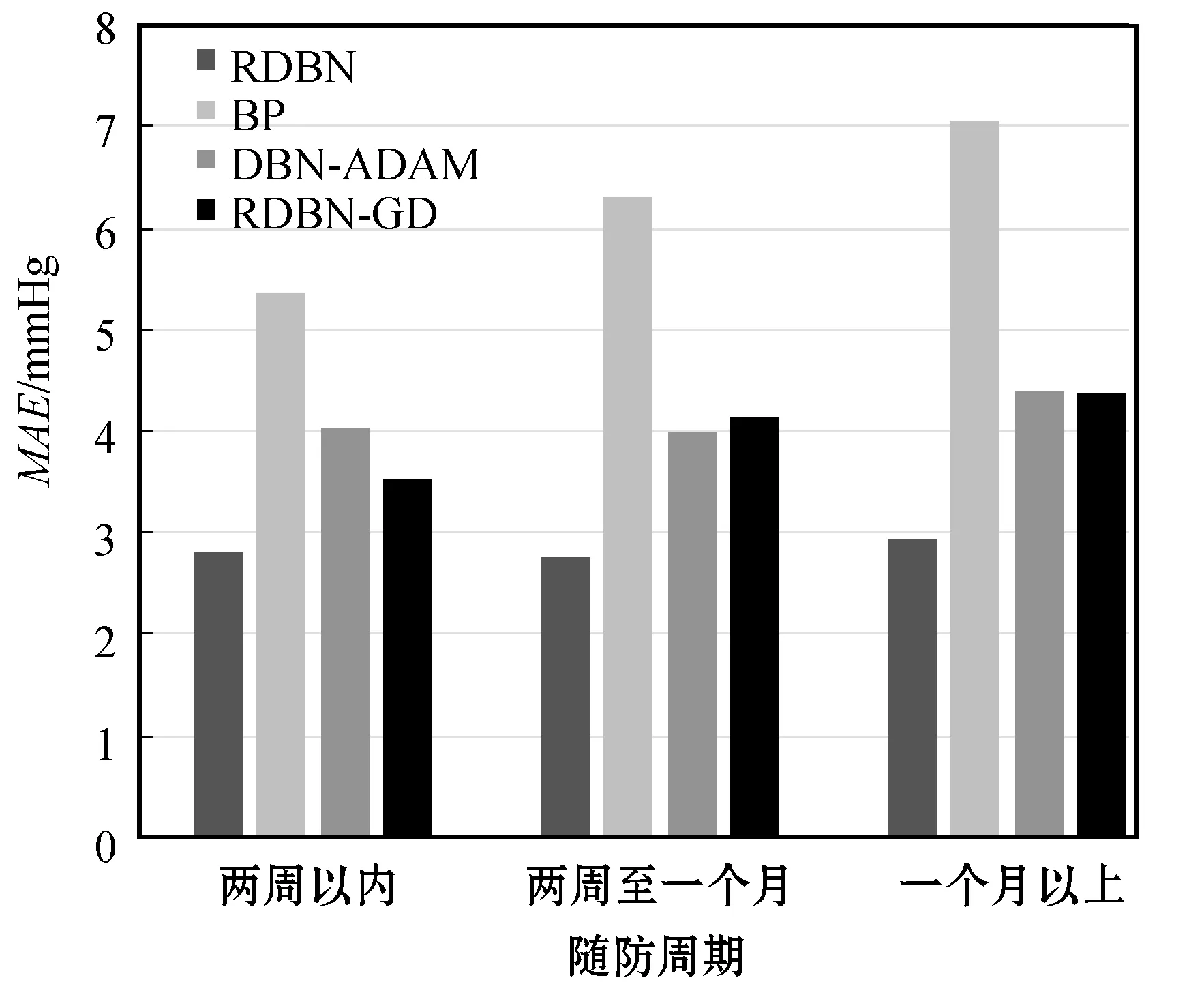
圖5 不同模型舒張壓預測絕對誤差對比圖
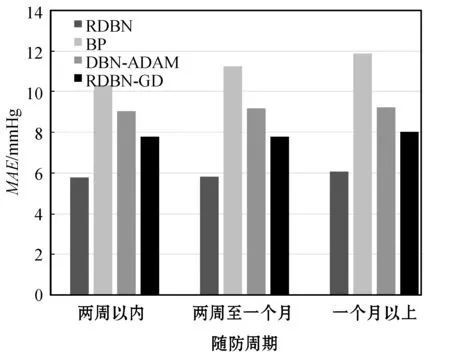
圖6 不同模型收縮壓預測絕對誤差對比圖
上述實驗結果表明,本文提出的RDBN模型相較于其他網絡結構,具有較優的訓練效率與預測精度,能夠表征人體未來血壓情況與其多方面影響因素之間復雜的非線性關系,適用于醫師為患者開具個性化降壓策略的科學依據。
4 結 語
本文將實值深度置信網絡應用于復雜環境下的人體血壓預測問題中,根據患者的生理指標特征、所處環境因素特征、血壓歷史數據特征、采取的降壓措施等多方面信息預測其未來血壓狀況。針對傳統RBM只能接受二值型輸入返回二值輸出無法處理連續性數據的問題,提出能夠接受實值輸入返回實值輸出的GG-RBM單元,以及采用了基于優化步長因子的Adam算法進行網絡的有監督學習,加速了網絡參數的尋優過程。通過實驗證明本文提出的RDBN人體血壓預測模型得到的預測值與實際值吻合程度較好,是一種科學有效的血壓預測方法。在下一步工作中,期望能進一步完善模型,在定量分析相關因素對患者未來血壓影響作用的同時,能夠給出個性化的降壓策略,實現對于高血壓患者的精準醫療。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
