基于ImageNet預訓練卷積神經網絡的圖像風格遷移
2022-01-19 10:17:02趙衛東施實偉
成都大學學報(自然科學版) 2021年4期
關鍵詞:模型
趙衛東,施實偉,周 嬋
(1.成都大學 計算機學院,四川 成都 610106;2.西南大學 教育學部,重慶 400715;3.西北師范大學 教育技術學院,甘肅 蘭州 730070)
0 引 言
隨著社會經濟的不斷發展,人們對各類藝術作品有了更多的喜好和追求.相關應用表明,圖像風格遷移技術能夠將各種藝術畫作的風格遷移到普通圖像中,從而能夠較為快速地生成不同藝術風格的作品.目前,在實際的應用場景中,人們可以通過利用如Prisma、Ostagram及Deep Forger等相關的應用處理軟件,使作品實現圖像風格遷移的效果[1].
圖像風格遷移技術主要分為傳統風格遷移技術和卷積神經網絡風格遷移技術2類.傳統的圖像風格遷移技術主要通過分析特定風格的圖像,并為其建立相應的數學統計模型,其局限性主要體現在一個模型只能做特定風格的轉換且難以提取圖像的高層抽象特征,使得其實際應用場景非常有限.而隨著計算機視覺技術中深度學習技術的發展,借助卷積神經網絡強大的特征提取能力,圖像風格遷移技術已實現了突破性進展[2].相關從業者可以借助該技術,不再局限于建構特定藝術風格的數學統計模型,而可將更多的精力投入到新的藝術作品創作中去.
基于卷積神經網絡技術,圖像在進行風格遷移的過程中,需要將風格圖像和內容圖像作為卷積神經網絡的2種輸入,并隨機初始化一張白噪聲圖像作為目標圖像.與此同時,還需要構建風格損失函數和內容損失函數,并將這2種損失函數結合起來作為總的損失函數來對卷積神經網絡模型進行評估.此外,在網絡模型的訓練過程中,還需要根據網絡模型所提取到的特征圖來計算損失,并通過不斷迭代訓練來降低生成圖像的損失,從而得到理想的目標圖像.基于此,本研究采用ImageNet[3]中預訓練好的卷積神經網絡來對風格圖像和內容圖像分別提取卷積層特征,并根據對風格圖像和內容圖像提取到的特征來生成風格遷移的目標圖像.同時,網絡也會對隨機初始化生成的一張白噪聲目標圖像并提取相同的特征,通過與風格圖像和內容圖像所提取的特征進行對比,并通過融合風格損失函數和內容損失函數構成整個模型的損失函數,在不斷訓練優化后,生成最終所需要的目標圖像.
1 ImageNet預訓練卷積神經網絡
1.1 ImageNet簡介
事實上,ImageNet項目是一個巨大的可供視覺訓練的大型可視化圖像庫,旨在提供較為全面和多樣的圖像數據.ImageNet就像一個網絡,其擁有多個節點,每一個節點相當于一個類別,一個節點含有至少500個對應物體的可供訓練的圖像.
1.2 人工神經網絡
神經元是人工神經網絡的基本處理單元,一般情況下其是多輸入單輸出的單元[4].一個神經元可以接收n個輸入,x=(x1,x2…xn),并對應n個權值,w=(w1,w2…wn),同時,還有一個偏置項b.神經元將所有輸入參數與對應權值進行加權求和,得到的結果經過激活函數變換后進行輸出,其計算式為,
y=f(w×x+b)
(1)
通常,人工神經網絡由多個神經元及其之間的連接構成.通過學習訓練,對網絡中的參數賦予不同權重值,使其對網絡輸出結果產生較大的影響.而實現這種權重的函數是一種非線性激活函數,常用的激活函數有Sigmoid、Tanh及ReLu 等[5].此外,在神經網絡的學習訓練過程中,通過反向傳播算法得出的輸出結果,能夠進行反向修改人工神經網絡中的參數,從而更大概率地輸出希望獲得的目標結果.
1.3 卷積神經網絡
卷積神經網絡是人工神經網絡的一種,其計算方式從輸入到輸出層層遞進,而訓練時用反向神經網絡進行學習,可使用在圖片的學習過程中.而連接的權重為待訓練參數,可通過反向傳播過程進行訓練調整.
卷積神經網絡也是利用反向傳播算法在訓練過程中,經過網絡模型各層的計算后,對網絡權重進行更新調整.卷積神經網絡的結構包含卷積層、池化層及全連接層等.其中,卷積層可以學習到圖像的特征;池化層在盡可能保留圖像特征的基礎上,可進一步減少計算量,常用的池化方法包括最大池化和均值池化;全連接層中的每個神經元與其前一層的所有神經元進行全連接,可以整合卷積層或者池化層中具有類別區分性的局部信息.
1.4 預訓練網絡
一般而言,預訓練可提供較好的模型初始化,這通常會帶來更好的泛化性能,并加速對目標任務的收斂.預訓練可以看成是一種正則化過程,以避免少量數據引起的過擬合現象,同時也可節約大量的時間成本去訓練網絡模型.故本研究采用在ImageNet中預訓練好的VGG-16和VGG-19 2種網絡模型完成對內容圖像風格的轉換.
VGG-16和VGG-19 模型都屬于經典的VGG網絡模型,VGG-16網絡模型包含13 個Conv layer 卷積層與3 個fully connectedlayer全連接層,而VGG-19網絡模型則是16個Conv layer 卷積層與3 個fully connectedlayer全連接層[6].VGG網絡模型全部使用的是3×3的卷積核,網絡中還使用5個2×2的max pooling池化層進行分割.
在實驗中,本研究采用了VGG-16和VGG-19 2種在ImageNet中預訓練好的網絡模型,其中VGG-16網絡模型的結構如圖1所示.VGG-19網絡模型比VGG-16網絡模型多出來的3層卷積層,conv3_4、conv4_4及conv5_4,用紅色部分進行了標注,其結構如圖2所示.
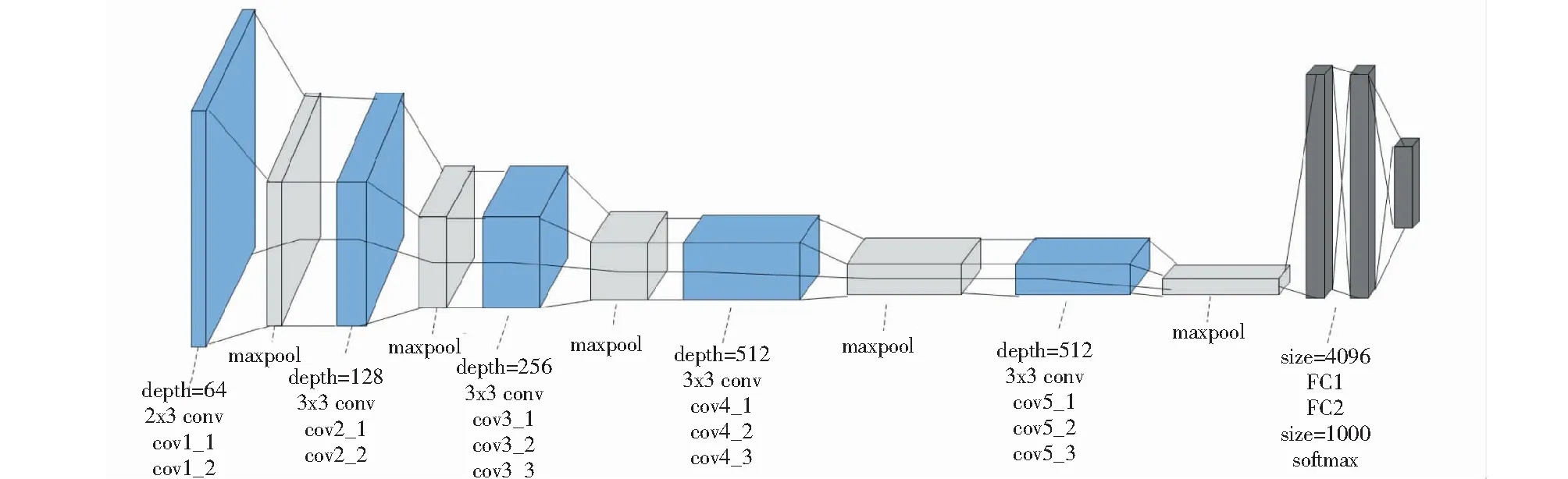
圖1 VGG-16網絡模型結構圖
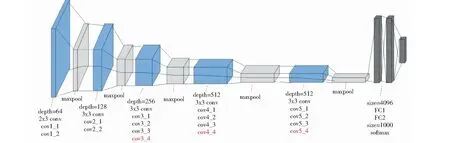
圖2 VGG-19網絡模型結構圖
2 損失函數構建
2.1 損失函數簡介
卷積神經網絡的反向傳播主要基于梯度下降方式向訓練誤差減小的方向進行調整,整個模型的訓練目標就是使得模型總損失函數的值實現最小化[7].損失函數能夠衡量當前模型生成的圖像效果與預期效果之間的誤差,即損失函數的值越小,生成的目標圖像效果就越好,而損失函數的值較大,其最終生成的目標圖像的效果則會較差.通常,網絡模型在最開始訓練時的損失函數的值都會相對較大,對此,本研究通過使用Adam優化算法[8]不斷在網絡模型訓練的進行過程中,逐漸降低損失函數的值,從而得到目標圖像輸出效果較好的模型.
2.2 內容損失函數
本研究采用的內容損失函數[2]的計算式為,
(2)
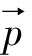
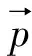
2.3 風格損失函數
圖像風格的本質是在各種空間尺度中圖像的紋理、顏色及視覺圖案等特征,而不同卷積核所提取到的圖像特征也不同.隨著網絡層數的深入,卷積核提取到的特征也會變得更加復雜和抽象.而深層網絡特征的提取也需要綜合底層網絡提取到的邊緣、形狀與顏色等信息.這些不同卷積層提取到特征結合起來才能表示圖像的風格.
研究表明,Gram 矩陣可計算在卷積過程中多維特征圖下不同維度之間特征向量的相關性,其可將目標圖像和風格圖像的差異進行量化,并把圖像特征之間隱藏的聯系提取出來,即各個特征向量之間的相關程度[2].如果2個圖像的特征向量的Gram矩陣的差異較小,就可以認定這2個圖像的風格是相近的.利用Gram矩陣計算風格圖像的紋理等特征信息的計算式為,
(3)
在第l層中,卷積特征的通道數為Nl,卷積的高與寬的乘積為Ml,對應第l層的Gram矩陣分別為Al和Gl,則第l層的總損失[2]的計算式為,
(4)
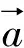
(5)
2.4 總損失函數
本研究的網絡模型總損失函數是由內容損失函數和風格損失函數進行加權求和而成,其中α和β2個超參數是用來調整內容損失函數和風格損失函數在總損失函數中各自權重的比重,其目的是實現調整目標圖像的風格轉換程度更接近于內容還是更接近于風格[9].總損失函數的計算式為,
(6)
3 實驗與結果
3.1 實驗環境
本研究的實驗運行環境為python3.7、tesorflow2.3和cuda10.2,實驗硬件平臺為Intel(R)Core(TM)i7-8700K CPU ,主頻為3.70 GHz,內存為16 GB.其中,為本實驗提供計算資源的是NVIDIA GeForce GTX 1080Ti GPU,使用cuda10.2作為GPU計算平臺的底層加速框架.實驗測試表明,此架構為網絡模型的優化過程節省了大量的計算時間.
3.2 數據預處理
首先,在網絡進行訓練之前,將內容圖像、風格圖像及隨機初始化白噪聲圖像的寬度修改為450 px,高度修改為300 px,圖像默認通道數為3.因為本實驗中訓練權重使用的是ImageNet數據集上的平均值與標準差,所以在對輸入圖像進行歸一化處理時,也使用相同的值.
3.3 實驗過程
本實驗采用4幅不同的原始風格圖像與2幅不同的原始內容圖像,具體如圖3、圖4所示.

圖3 4幅不同的原始風格圖像

圖4 2幅不同的原始內容圖像
實驗選擇在ImageNet中預訓練好的VGG-16網絡模型與VGG-19網絡模型對圖像特征進行提取,同時舍棄其中的全連接層,Adma作為優化器,使用@tf.function修飾符,將訓練過程轉化為圖執行模式,從而加快訓練速度.因為α與β2個參數是用來調整目標圖像效果更接近于內容還是更接近于風格,所以本研究分別對α/β為10-1、10-2與10-3進行了測試.
在計算過程中,由于收斂速度趨勢的重復性較高,故選取VGG-16網絡模型與VGG-19網絡模型在圖3(a)與圖4(e),且α與β參數比值不同情況下模型的訓練過程進行展示,模型總損失值(loss value)隨迭代次數(epoch)的收斂過程如圖5所示.
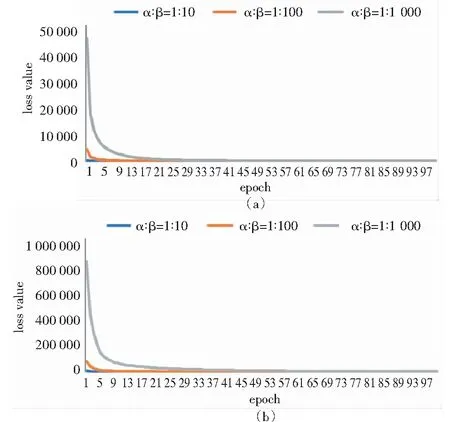
圖5 VGG-16網絡模型與VGG-19網絡模型在圖3(a)與圖4(e)且α與β權重比值不同情況下的訓練過程結果
本研究根據收斂速度與損失值,最終將α/β的參數比設定為10-1,其余參數設置見表1.

表1 VGG-16網絡模型與VGG-19網絡模型訓練參數設置
在實驗測試中,使用VGG-16網絡模型與VGG-19網絡模型提取圖像特征,其損失值都能夠快速達到收斂,并且都能得到效果較為不錯的目標圖像.同時,將2種網絡模型在不同迭代次數生成的目標圖像進行對比,結果如下:
1)當原始內容圖為(e)時,與4幅不同的原始風格圖像(a)、(b)、(c)與(d)進行結合,選取第100、1 000、10 000次迭代生成的目標圖像,結果如圖6所示.

圖6 原始內容圖(e)生成的不同風格目標圖像
2)當原始內容圖為(f)時,與4種不同的原始風格圖像(a)、(b)、(c)與(d)進行結合,選取第100、1 000、10 000次迭代生成的目標圖像,結果如圖7所示.

圖7 原始內容圖(f)生成的不同風格目標圖像
3.4 結果分析
為了將內容圖像(e)、(f)與4幅不同風格圖像(a)、(b)、(c)與(d)在VGG-16與VGG-19 2種在ImageNet預訓練好的網絡模型生成的目標圖像效果進行量化評價,本研究將實驗過程中2種網絡模型的總損失值進行了輸出,結果如表2所示.
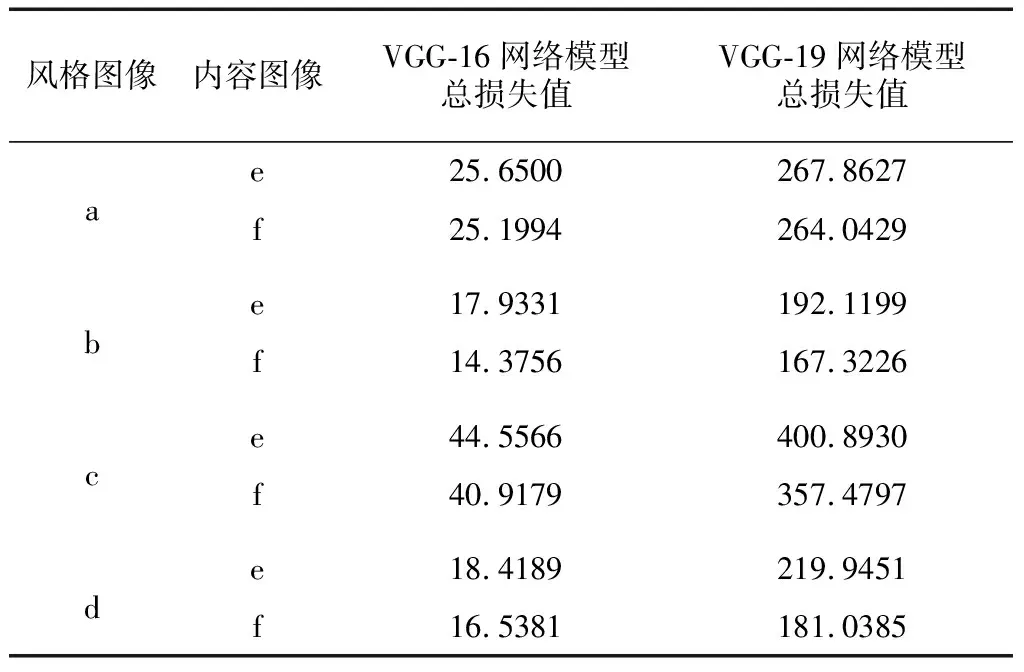
表2 內容圖像與不同風格圖在VGG-16網絡模型與VGG-19網絡模型迭代10 000次時的損失值
由表2數據可以看出,風格圖像(b)和內容圖像(e)、(f)的結合,經過10 000次迭代后,風格圖像(b)使用2種預訓練的網絡模型與不同的內容圖像進行結合后損失值最小的.因此,相同的網絡模型下,影響最終生成的目標圖像效果也與原始風格圖像自身的藝術紋理特征相關.而從2種不同類型的預訓練網絡模型對比來看,VGG-16網絡模型的總體損失值都比VGG-19網絡模型低,反映在最終生成的目標圖像的效果上也是使用預訓練模型為VGG-16的網絡模型更好.
同時,由圖6與圖7中第1 000次迭代生成的目標圖像可以看出,在訓練過程中,VGG-16網絡模型生成的目標圖像能夠更快地接近原始風格圖像的風格特征.反映在對應圖中的損失值可視化效果圖中,VGG-16網絡模型達到收斂的速度快于VGG-19網絡模型,即在相同的迭代次數和相同的原始內容圖像與原始風格圖像情況下,VGG-16網絡模型的風格遷移效果較VGG-19網絡模型具有更為豐富的風格圖像細節特征.
此外,由于卷積神經網絡采用的是ImageNet中預訓練好的模型,所以在訓練過程中直接通過tf.keras.applications加載預訓練模型即可,其中最為重要的工作是進行損失函數的構建與模型總損失值進行不斷優化.最終2種網絡模型都達到收斂之后,在α/β參數比為10-1的基礎上,2種網絡模型生成的目標圖像都具有不錯的風格遷移效果.
4 結 論
本研究通過使用基于ImageNet中預訓練好的卷積神經網絡VGG-16網絡模型與VGG-19網絡模型,實現了對原始內容圖像的風格遷移,通過使用了2幅不同的原始內容圖像和4幅不同的原始風格圖像對網絡模型進行訓練,同時,分析了不同的網絡模型在保持各項訓練參數與權重相同的情況下,生成目標圖像過程的差異性.
實驗結果表明,基于ImageNet中預訓練好的卷積神經網絡,利用深度學習卷積神經網絡的特征提取能力與Gram矩陣計算圖像風格差異,并基于現有圖像風格進行藝術創作過程中,具有節省訓練時間,從而更高效地推廣應用等更多的優勢,促進了計算機視覺技術在不同的領域的實際應用與發展.事實上,除了在專業的影視娛樂與游戲設計等領域外,在用戶的日常創作場景中,圖像風格遷移技術也擁有廣泛的具體應用前景.
此外,針對圖像風格遷移算法,如果使用生成對抗網絡(generative adversarial networks,GAN)[10]完成這項工作或許會有令人驚艷的效果.因為在GAN中,可以使用多個判別器分別來約束圖像風格、圖像結構和圖像細節等要素.這項工作有待今后去做更多的探究與驗證.同時,在人工智能教學課程中,以本實驗項目為基礎單元,將GAN用于風格遷移項目可以作為學習者后一個單元的學習材料,從而在人工智能教學過程中使得學習者能夠更好地掌握相關知識.此外,另一個值得探究的問題是,通過計算機技術生成的藝術作品是否具有美學與藝術價值,以及其評價指標與體系如何構建等相關問題,也是未來人工智能技術應用于藝術創作領域亟待思考的重要課題.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
