基于深度學習的知識追蹤研究進展
2022-01-19 08:49:30劉鐵園古天龍
計算機研究與發展 2022年1期
劉鐵園 陳 威 常 亮 古天龍,3
1(廣西可信軟件重點實驗室(桂林電子科技大學) 廣西桂林 541004)2(桂林電子科技大學電子工程與自動化學院 廣西桂林 541004)3(暨南大學信息科學與技術學院/網絡安全學院 廣州 510632)
近年來,隨著智能輔導系統(intelligent tutoring system, ITS)和大型開放式網絡課程(massive open online courses, MOOCs)等在線教育平臺的發展和普及,數百萬的用戶選擇通過在線平臺學習.相比傳統的線下教育,在線學習系統最顯著的優勢在于其能保留學習者詳盡的學習軌跡,提供了調查不同軌跡下學習者行為效能的條件[1].然而,在線學習平臺上學生與教師人數的懸殊使人工的輔導變得不現實.如何利用在線學習系統的優勢,從學生的學習軌跡中挖掘出潛在的學習規律,以提供個性化的指導,達到人工智能輔助教育的目的,成為了研究者密切關注的問題.
知識追蹤(knowledge tracing, KT)是實現人工智能輔助教育的有力工具,目前已經成為了ITS的一個主要組成部分[2],被廣泛應用于各個在線教育平臺,如edX[3]、Coursera[4]和愛學習[5].KT旨在建立學生知識狀態隨時間變化的模型,以判斷學生對知識的掌握程度.通常情況下,KT的任務可以被形式化為一個有監督的序列學習任務,給出學生的歷史學習交互記錄It={i1,i2,…,it},通過預設的模型從中提取出學生隱式的知識狀態,并追蹤其隨時間的變化.學習交互通常表示為一個題目-答案元組it=(qt,at),意為學生在時刻t回答了問題qt,at則指示了回答的情況.由于很難直接衡量學習者的實際學習狀態,現有的KT模型通常采用一種替代解決方案,使模型預測下一個題目答對的概率P(at+1=correct|qt+1,It).
BKT(Bayesian knowledge tracing)模型[6]是目前最流行的KT模型之一,BKT將學習者的潛在知識狀態建模為一組二元變量,代表是否掌握某個知識成分(knowledge component, KC).KC可以被泛化地理解為知識概念、原理、事實或者技能.對于一個具體的題目qt,KC可以視作答對qt所必須掌握的知識.在單KC模型中(即一個題目對應一個KC),題目與KC可以視為是等價的.
在每一次學習交互后,BKT使用隱Markov模型(hidden Markov model, HMM)更新這些二元變量的概率.在提出后的20年來,BKT一直被視為KT領域的首選方法,其他機器學習模型,如BKT的變體[7]、邏輯回歸的變體[8]以及項目反應理論[9](item response theory, IRT)與BKT的性能差異都很小[10].
雖然BKT在KT領域取得了很大成功,但是其本身也存在著很大的問題.首先,變量與KC之間的對應是模糊的,無法做到一一對應,且二元變量的設置不符合現實中的學習過程[11].其次,對每個KC分開建模的方式使BKT無法捕捉不同KC間的關系,也喪失了對未定義KC和復雜KC的建模能力.
深度學習以其強大的特征提取能力引起了研究者的廣泛關注,許多研究者將其應用到KT領域,稱為基于深度學習的知識追蹤(deep learning based knowledge tracing, DLKT).相對于傳統的機器學習模型,DLKT不需要人工標注的KC信息,且能夠捕捉到更復雜的學生知識表征,還可以發現并利用KC之間的關聯信息.目前,對DLKT的研究已經成為了KT領域的一大研究熱點.
DLKT的開創性工作深度知識追蹤(deep knowledge tracing, DKT)模型[11]于2015年提出,在2015年后,涉及到KT領域的代表性綜述性論文有文獻[1,12-16].其中,文獻[1]從知識點、學習者和數據3方面總結了KT模型在教育領域的應用.文獻[12]側重于討論特定場景下模型的選擇問題.文獻[13]將學習者模型分為知識狀態、認知行為、情感、綜合4類并做了詳細闡述,KT模型屬于其中的知識狀態模型.文獻[14-16]對目前的KT模型從教育角色、教育過程等角度進行了梳理和分析比較,但側重在機器學習,且其中所涉及的模型較少,僅介紹了幾個具有代表性的模型.總體來說,這些文獻涉及到DLKT模型的內容較少,沒有聚焦于DLKT領域.
本文著眼于DLKT領域的相關研究,對該領域的技術演化和最新研究進展進行了系統性的調研與梳理.
1 基于深度學習的知識追蹤DLKT
1.1 DLKT相關研究概覽
我們查閱了近5年半(2015-01—2020-06)DLKT的相關論文.其中,中文文獻來源于中國知網(CNKI),英文文獻來自IEEE Electronic Library,Elsevier Science,EI Compendex,Web of Science,Springer Link,ACM Digital Library等數據庫,并使用學術搜索引擎(谷歌學術、百度學術、必應學術)查漏補缺.在檢索時,中文使用“知識追蹤”和“深度知識追蹤”作為關鍵詞,英文使用“knowledge tracing”和“deep knowledge tracing”為關鍵詞.對獲得的相關文獻進行分析整理,去掉不相關的和沒有使用深度學習方法的文獻,共篩選出69篇文獻,圖1給出了這些文獻的發表情況.
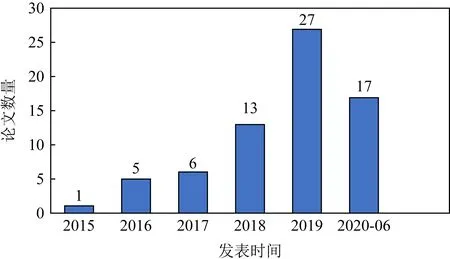
Fig. 1 Publication of DLKT related literatures in recent five and a half years
可以看出,近5年半DLKT相關文獻在國內外發文量呈明顯上升趨勢,在新冠疫情導致許多會議延期的前提下,2020年上半年也有17篇論文發表.
發表僅5年,DLKT的開創性工作DKT就有433次引用(數據來源:谷歌學術),相關研究在NIPS,AAAI,SIGIR,WWW等頂會上均有報道,可見該領域研究被學界的認可和接受.
1.2 符號定義
在本節,我們給出文中常見符號的定義(其他非常見符號以文中說明為準),表1展示了每種符號的代表含義.除特殊說明外,本文使用的符號皆以表1為準.我們使用kt表示知識成分KC,qt代表題目,at代表對應的回答,下標t指示了時刻(如無必要,則省略).兩者的組合(qt,at)構成了一個學習交互xt.通常情況下,KC與題目存在對應關系,兩者可以相互轉化,因此,學習交互同樣可以表示為(kt,at),根據具體的模型選擇.在時刻t,模型的預測值yt表示下一時刻回答正確的概率.使用L表示損失函數,LBCE特指二元交叉熵(binary cross entropy, BCE)函數.使用大寫的粗體字母(如W)表示矩陣,使用小寫的粗體字母(如b)表示向量.特別地,W和b特指權重矩陣和偏置向量.

Table 1 Symbol Definition
1.3 DLKT基本模型
Piech等人[11]提出的DKT模型是DLKT領域的開創性工作,也是DLKT領域的基本模型.DKT的結構如圖2所示,其以循環神經網絡(recurrent neural network, RNN)為基礎結構.RNN是一種具有記憶性的序列模型,序列結構使其符合學習中的近因效應并保留了學習軌跡信息[17].這種特性使RNN(包括長短期記憶網絡[18](long short term memory, LSTM)和門控循環網絡[19](gated recurrent unit, GRU)等變體成為了DLKT領域使用最廣泛的模型.DKT以學生的學習交互記錄{i1,i2,…,it}為輸入,通過one-hot編碼或壓縮感知[20](compress sensing),it被轉化為向量輸入模型.在DKT中,RNN的隱藏狀態ht被解釋為學生的知識狀態,ht被進一步通過一個Sigmoid激活的線性層得到預測結果yt.yt的長度等于題目數量,其每個元素代表學生正確回答對應問題的預測概率.具體的計算過程為

(1)
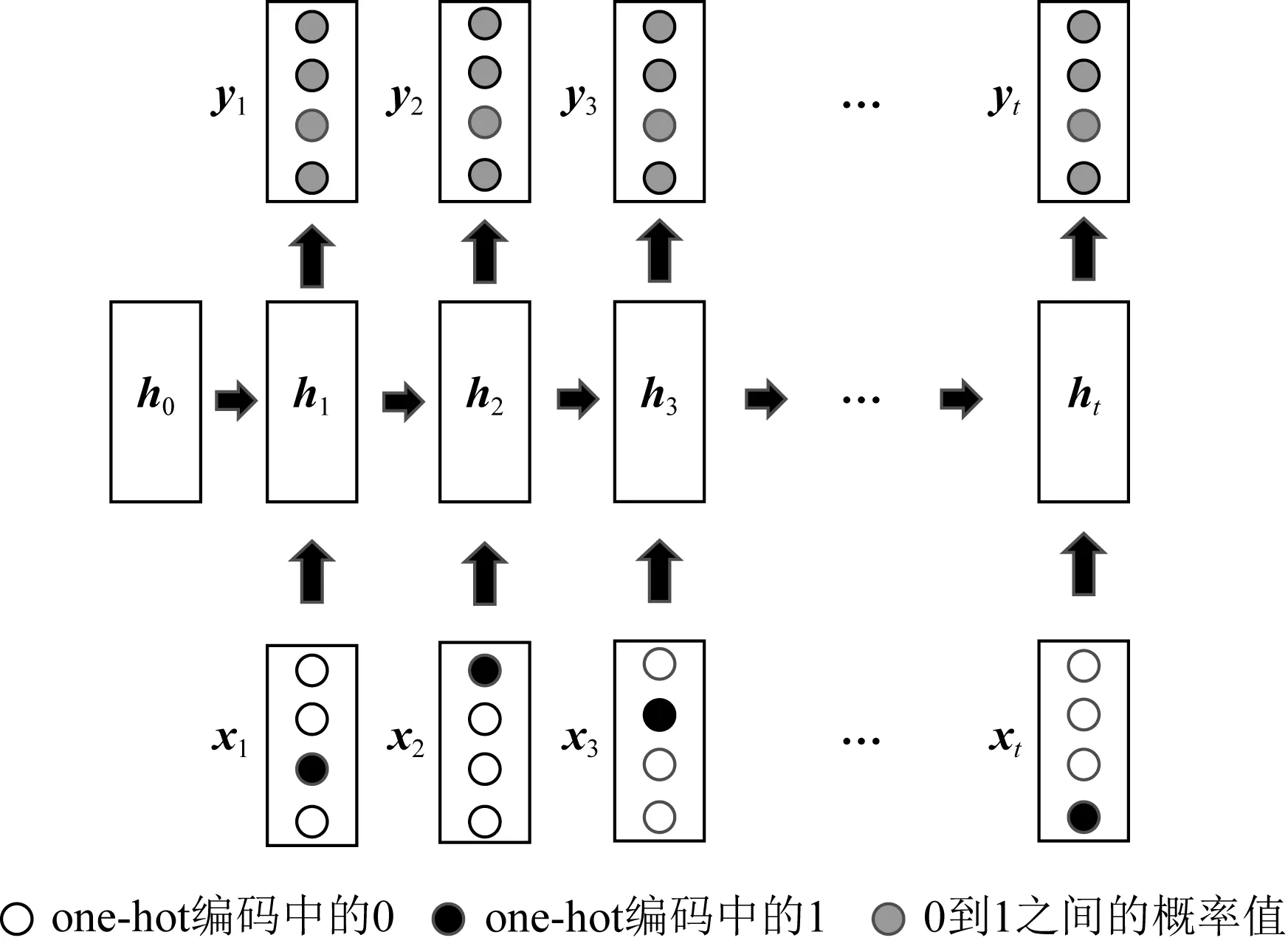
Fig. 2 Architecture for DKT model
DKT的目標函數是觀測序列的非負對數似然函數,用LBCE表示二元交叉熵(BCE),則學生的損失值為
(2)
相對于以BKT為代表的傳統機器學習模型,DKT不需要人工標注的數據就有更好的表現(AUC提高了20%[21]),且能夠捕捉并利用更深層次的學生知識表征[22-23],這使其非常適合以學習為中心的教學評估系統[24].
2 DKT的改進方法
盡管DKT的預測性能優于現有的經典方法,但由于它在教育應用中的實用性還有待提高,而被其他少量學者所批判[25-29].這主要是因為隱藏狀態ht在本質上很難被解釋為知識狀態,而且DKT模型沒有對知識交互進行深入分析[30],導致其可解釋性很差.
RNN存在長期依賴問題,其變體(如LSTM和GRU)僅僅提高了序列學習的容量(對于LSTM來說,容量在200左右[31]),但并沒有解決問題.DKT中以RNN為基礎,因此其同樣存在長期依賴問題.長期依賴問題使DKT無法利用長序列的輸入[32],且會導致重構錯誤和波動準則[33-35].
在DKT中,模型的輸入為one-hot編碼的學生交互序列,而僅用交互序列作為輸入浪費了在線平臺所保留的豐富學習軌跡信息,且輸入的學習特征太少也會影響模型的表現.
可解釋性差、長期依賴問題和學習特征少是DKT模型最顯著的3個問題,許多研究者致力于對其進行擴展和改進,以解決這些問題.我們將各種改進方法梳理為圖3所示:
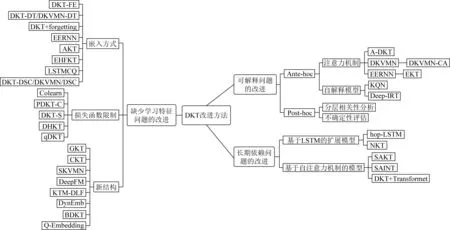
Fig. 3 DKT improved method venation diagram
2.1 針對可解釋性問題的改進
根據使用方法的不同,針對可解釋性問題的改進可以進一步細分為Ante-hoc可解釋性方法和Post-hoc可解釋性[36]方法.
2.1.1 Ante-hoc可解釋性方法
Ante-hoc可解釋性指模型本身內置可解釋性.對于復雜的模型,可以通過構建將可解釋性直接結合到具體的模型結構中的學習模型來實現模型的內置可解釋性,在深度學習中,一種有效的可解釋性模塊就是注意力機制.此外,Ante-hoc可解釋性還可以通過采用結構簡單、易于理解的自解釋模型實現[36].
1) 引入注意力機制
① A-DKT(attention-DKT)
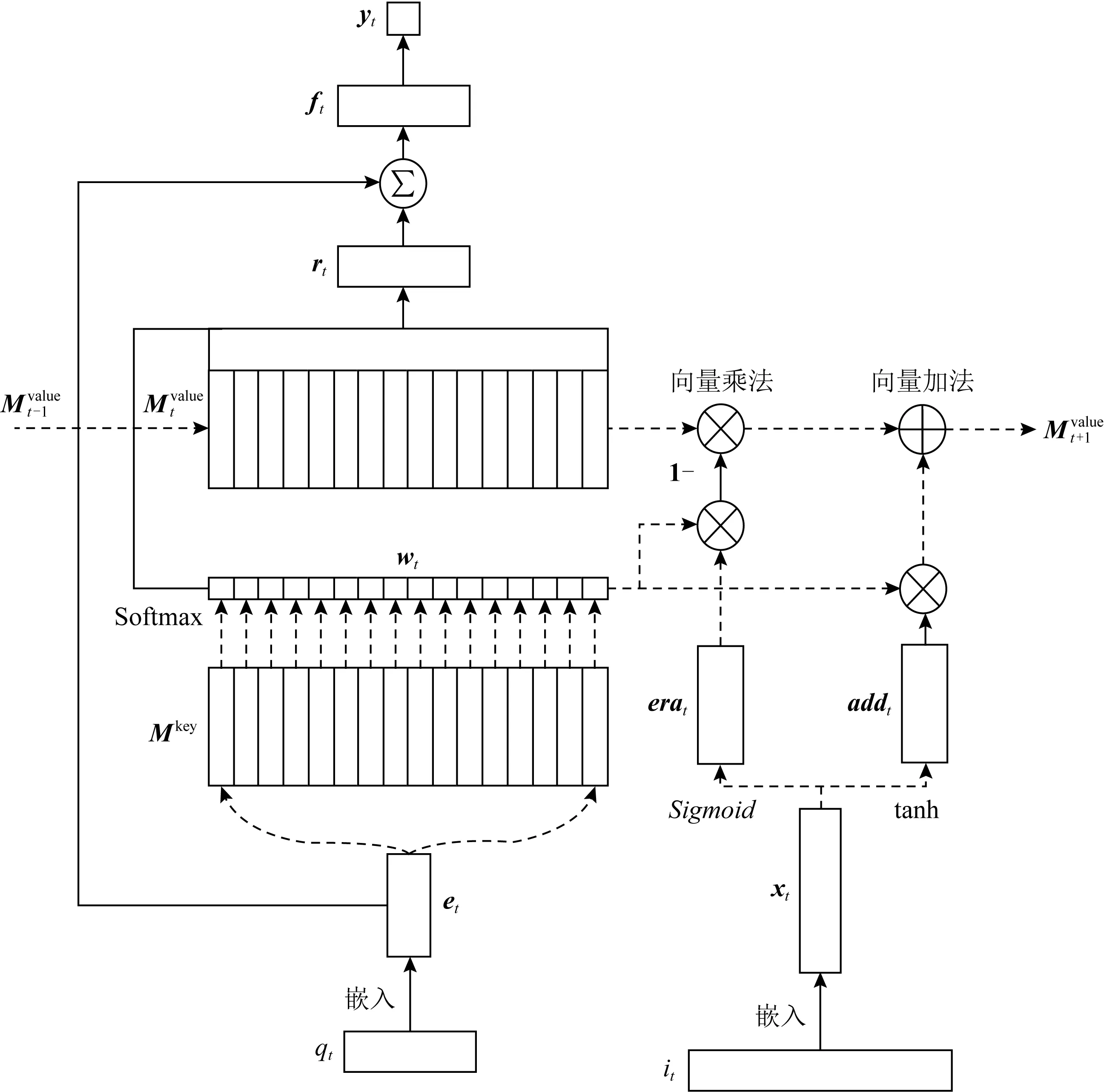
Fig. 4 Architecture for DKVMN model
Liu等人[37]在模型A-DKT中使用了Jaccard系數計算KC之間的注意力權重.設ka,kb為不同的KC,兩者間的權重值為
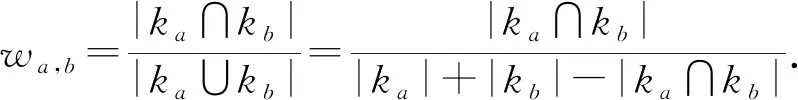
(3)
在時刻t,計算當前KC與之前所有KC的注意力權重,然后相加,得到總的注意力值wt:
(4)
最后,結合LSTM與注意力值得到預測結果:
yt=Sigmoid(Wyhht+by+wt).
(5)
② DKVMN(dynamic key-value memory network)
Zhang等人[38]受到MANN(memory-augmented neural network)的啟發,提出了DKVMN模型.DKVMN使用矩陣Mkey存儲KC,Mkey的每一列代表一個KC;使用矩陣Mvalue存儲知識狀態,Mvalue的每一列表示Mkey中對應KC的掌握程度.DKVMN的結構如所圖4所示.
注意力機制主要體現在wt的計算上:在時刻t,將題目的嵌入向量et與每一個KC(即Mkey的每一列)作內積,經過一個激活函數后得到wt.wt(i)代表題目qt與KCki之間的相關性,即注意力權重:
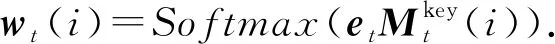
(6)
根據注意力權重計算學生對題目qt的掌握程度rt:
(7)
題目的嵌入向量et隱式地包含了難度信息,將其與rt連接,得到的ft同時包含難度和掌握程度信息:

(8)
最后,ft通過一個Sigmoid激活的線性層得到學生表現的預測值yt:
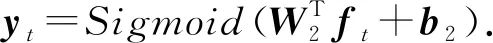
(9)
③ DKVMN-CA(concept-aware DKVMN)
Ai等人[39]進一步擴展了DKVMN模型,使其支持了人工標注的KC信息.即Mkey中的KC由人工定義,而不是機器生成.
④ EERNN(exercise-enhanced RNN)
Su等人[40]在其模型EERNN中使用了余弦相似度計算隱藏狀態之間的注意力權重wt:
(10)
需要注意的是,余弦相似度計算的并不是隱藏狀態之間的相似性,而是題目之間的相似性.EERNN的預測過程為:
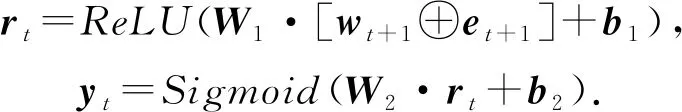
(11)
⑤ EKT(exercise-aware KT)
Huang等人[41]提出的EKT模型綜合了EERNN模型與DKVMN模型,因此擁有雙重注意力模塊.其主要計算過程與EERNN和DKVMN模型相同,此處不再贅述.
2) 自解釋模型
① KQN(knowledge query network)
Lee等人[42]用向量點積來模擬知識狀態與KC的相互作用,提出了KQN模型.假設知識狀態與KC都為2維向量,如圖5所示,在知識狀態由v2轉變到v3的過程中,學生對KCk1的掌握程度由v2·k1=1增長到了v3·k1=2.這種向量化的表示與運算使KQN具有直觀性和可解釋性.
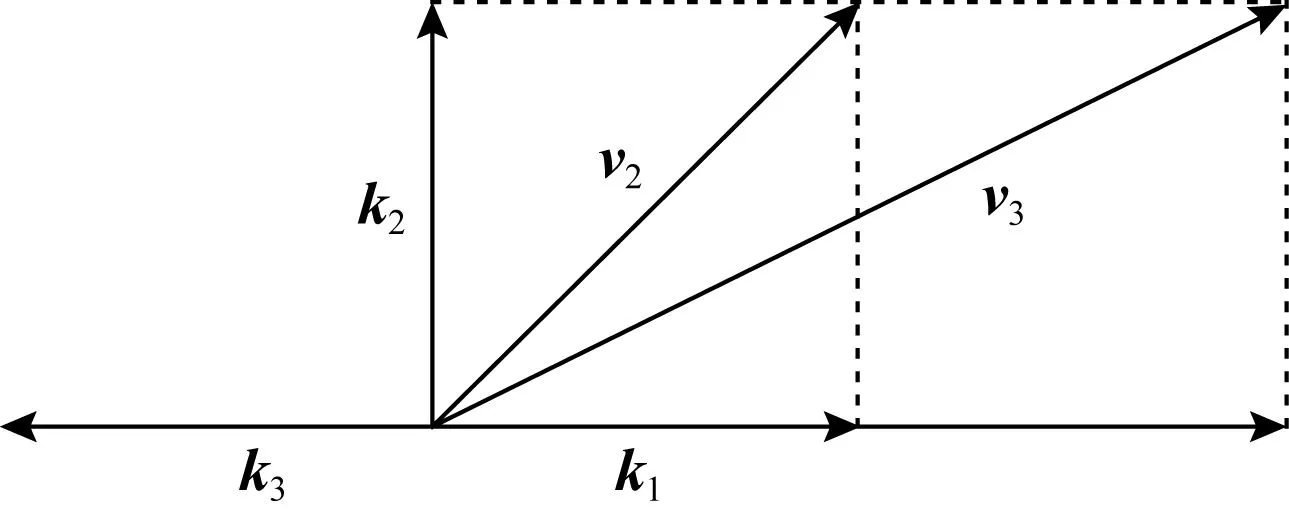
Fig. 5 An example of KQN
在KQN中,學生知識狀態向量vt由RNN的隱藏狀態ht經過一個全連接層得到:
vt=Wvh·ht+bv.
(12)
在時刻t,one-hot編碼的KCkt+1通過一個多層感知機和L2正則化.生成新的嵌入表示:
ot+1=ReLU(W1·ReLU(W0·kt+1+b0)+b1),kt+1=L2-normalize(ot+1).
(13)
KQN用vt與vt+1的內積定義知識交互,并作出預測:
yt=Sigmoid(vt·kt+1).
(14)
② Deep-IRT(deep item response theory)
Yeung等人[43]綜合了IRT理論[9]與DKVMN模型,提出了Deep-IRT模型.Deep-IRT通過2個全連接神經網絡,利用DKVMN中的ft與et(式(8))分別對學生n的能力θt,n和題目難度βt建模:

(15)
最后,通過IRT函數得出預測結果:
yt=Sigmoid(θt,n-βt).
(16)
2.1.2 Post-hoc可解釋性方法
Post-hoc可解釋性也稱事后可解釋性,發生在模型訓練之后,旨在利用解釋方法或構建解釋模型,解釋學習模型的工作機制、決策行為和決策依據[36].在DLKT領域,主要有LRP和不確定性評估方法.
1) LRP(layer-wise relevance propagation)
Lu等人[44]應用分層相關性傳播方法,通過將相關性從模型的輸出層反向傳播到輸入層,來解釋基于RNN的DLKT模型.LRP的核心是利用反向傳播將高層的相關性分值遞歸地傳播到低層直至傳播到輸入層.具體來說,將RNN不同單元之間的連接分為加權連接和乘法連接并分別定義兩者相關性的傳播.如圖6所示,通過計算2種類型連接的反向傳播相關性,就可以對基于RNN的DLKT模型進行解釋.
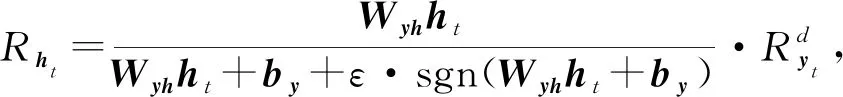
(17)
RCt=Rht,
(18)
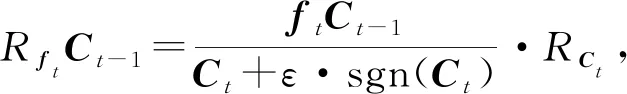
(19)
RCt-1=RftCt-1,
(20)
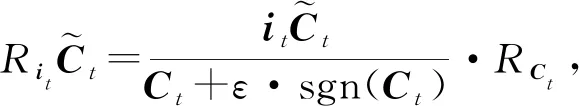
(21)

(22)
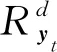

(23)
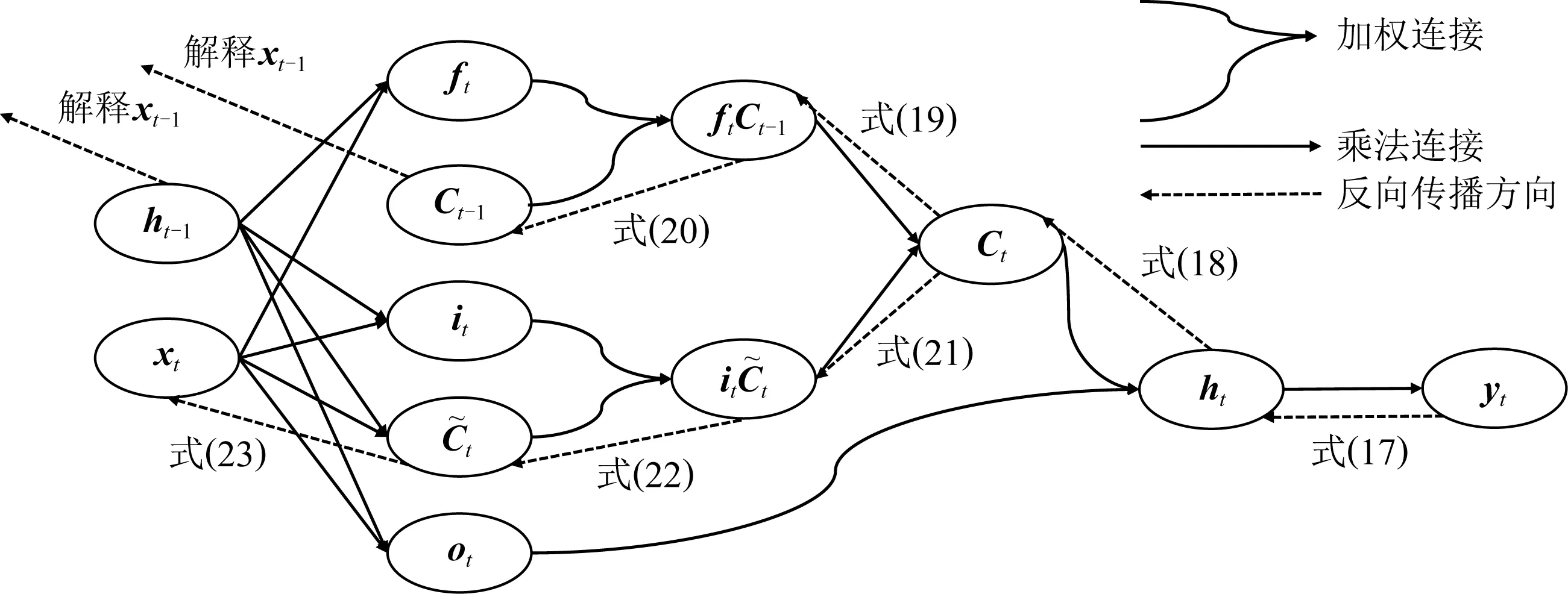
Fig. 6 The feedforward prediction path and the backpropagation path for interpreting its prediction results
2) 不確定性評估
Ding等人[45]和Hu等人[46]都使用不確定性評估方法解決可解釋性差的問題,這里主要闡述前者的方法:通過為模型的每一個預測值y提供一個不確定性評分u(由模型輸出),以減輕預測過程中的不透明性,增加模型的可解釋性.不缺定性分為2種:
① 隨機不確定性(或數據不確定性).由隨機事件或觀測中的固有噪聲導致.由于神經網絡的固定權值,因此輸入x的噪聲會傳播給輸出y.用D表示噪聲,則模型的輸出為
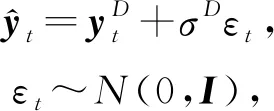
(24)
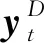
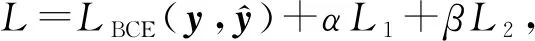
(25)
其中,L1,L2均為優化計算的正則項,由超參數α,β平衡權重.
② 認知不確定性(或模型不確定性).由數據不足導致,這種不確定性可以通過使用更多的數據來降低.針對深度學習模型的不確定性建模的貝葉斯方法是假設這些模型的權重不是固定的,而是從分布中取樣的.最后的預測是通過綜合所有可能的權重得到的.對于分類任務,預測正確的概率可以近似為
(26)
其中,c表示預測正確的題目,S表示取樣總數.不確定性可以用熵概括:
(27)
2.1.3 小 結
本節詳細介紹了DLKT領域針對可解釋性問題的改進方法,主要分為Ante-hoc和Post-hoc.前者對問題的解決程度稍顯不足,無論是注意力機制還是自解釋模型都只能提高某一部分的可解釋性.而后者試圖解釋整個模型,但其方法本身對部分條件要求較高,如LRP需要預測函數有較高的梯度.
2.2 針對長期依賴問題的改進
針對長期依賴問題的改進模型中,根據方法的不同,可以分為LSTM的擴展模型和基于自注意力機制的模型.
2.2.1 基于LSTM的擴展模型
1) Hop-LSTM
Abdelrahman等人[47]使用了Hop-LSTM來進一步擴大LSTM的序列學習容量.Hop-LSTM是一種改進的LSTM,可以根據隱藏單元之間的相關性進行跳躍連接.如圖7所示,Hop-LSTM所基于的順序關系為q1←q4,q2←q3,q5←q3,…,q4←qt,其中ft的計算參考式(8).可以看到,LSTM單元依據順序關系跳躍連接.

Fig. 7 Hop-LSTM schematic diagram
2) NKT(neural KT)
有研究指出,RNN的層層疊加可以減輕LSTM中長期依賴關系的學習困難[48].基于這個結論,Sha等人[49]提出了NKT模型,設計了一種2層堆疊的LSTM,并使用殘差連接減小訓練難度.實驗證明,這種疊加的LSTM可以有效擴大序列學習的容量.
2.2.2 基于Transformer的模型
自注意力機制(self-attention mechanism)是注意力機制的一個變體,由Lin等人[50]提出.后來,Vaswani等人[51]使用自注意力機制代替了RNN搭建了整個模型框架,提出了Transformer模型.由于Transformer模型不依賴RNN框架,因此不存在長期依賴問題.Transformer模型最初用于機器翻譯任務,取得了很好的效果.后來,有研究者將其用于知識追蹤領域,獲得了媲美基于RNN的DLKT模型的效果,且不存在長序列依賴問題.
1) SAKT(self attention KT)
Pandey等人[52]率先在知識追蹤領域使用了Transformer模型,提出了SAKT模型,其結構如圖8所示:
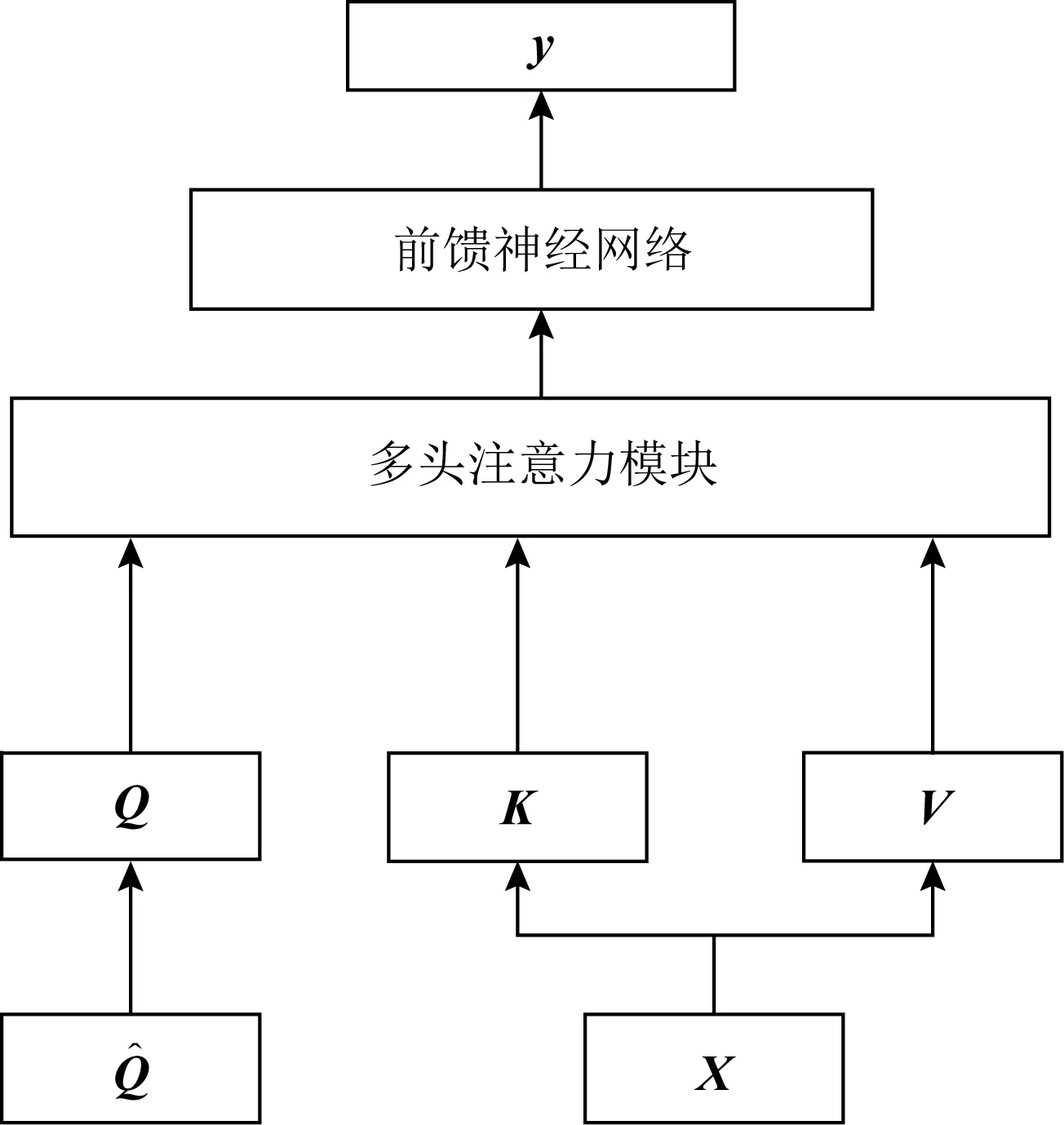
Fig. 8 Architecture for SAKT model
在Transformer中,計算注意力所使用的Q,K,V這3個參數由輸入序列乘以不同的權重矩陣所得.而在SAKT中,Q和K,V分別由題目的嵌入序列和交互的嵌入序列投影得到.

(28)

注意力被計算h次,使得模型能夠在不同的表示子空間中學習相關信息,并將h次的結果連接,稱為多頭注意力(multi-head attention, MHA):
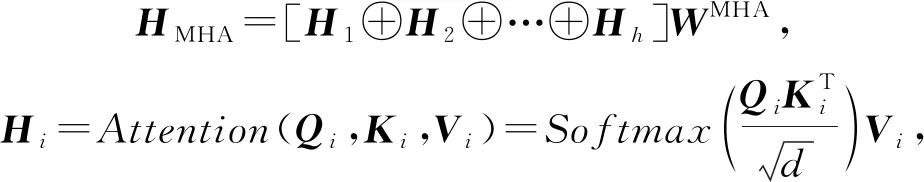
(29)
其中,d為嵌入向量的維度.最終,通過一個前饋神經網絡層和一個Sigmoid激活的線性層得到預測結果:
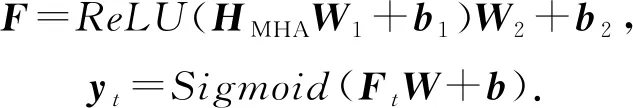
(30)
2) SAINT(separated self-attention neural KT)
Choi等人[53]認為SAKT模型的注意力層太淺,且Q,K,V的計算方法缺乏經驗支持,并提出了SAINT模型以解決這2個問題.
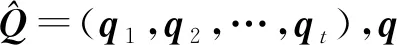
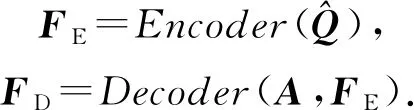
(31)

Fig. 9 Architecture for SAINT model
編(解)碼器的內部實現與SAKT相同,最終,解碼器的輸出FD經過一個Sigmoid激活的線性層得到最終的預測結果.
在SAINT中,編(解)碼器共疊加了4層,實驗結果證明,多次疊加的注意力層可以有效增大AUC的面積,獲得更好的預測性能.
3) DKT+Transformer
Pu等人[54]改進了Transformer的結構,在其中加入了題目的結構信息和答題的時間信息.改進后的Transformer模型結構與SAINT大致相同,都由編碼器和解碼器組成,主要區別在于自注意力的計算.
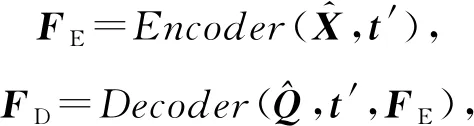
(32)
其中,t′=(t1,t2,…,tn)為時間戳信息,注意力機制的計算為:
(33)
其中,b×(tj-ti)表示時間間隔偏置,目的是通過xj與xi之間的間隔時間來調整注意力權重,在計算時,使i≤j以保證不會學習后面時間的權重.
2.2.3 小 結
本節詳細介紹了DLKT領域針對長期依賴問題的解決方法,主要分為基于LSTM的方法與基于Transformer的方法.前者在一定程度上擴展了RNN序列學習的長度,但是并沒有從根本上解決問題.后者不存在長期依賴問題,但是也喪失了RNN對序列建模的能力,位置嵌入對序列信息的影響更是需要深入研究.
2.3 針對缺少學習特征問題的改進
針對缺少學習特征問題的改進中,根據特征添加方式的不同,可以分為嵌入方式、損失函數、新結構3種方法.
2.3.1 嵌入方式
嵌入方式指將學習特征添加到模型的輸入嵌入向量中,或作為額外的計算因子嵌入到計算過程中的方式.

Fig. 10 Concatenate feature vectors and reduce dimensions
1) DKT-FE(DKT with feature engineering)

2) DKT-DT(DKT with decision trees)


(34)
3) DKVMN-DT(DKVMN with decision trees)
Sun等人[59]基于DKVMN模型添加特征,提出了DKVMN-DT(DKVMN with decision trees)模型.其使用了與DKT-DT相同的方法,不再贅述.
4) DKT+forgetting
Nagatani等人[60]在DKT模型中加入了遺忘特征.作者用3點信息衡量學生的遺忘情況,如圖11所示,分別是相同題目時間間隔、相鄰題目時間間隔和題目歷史練習次數.
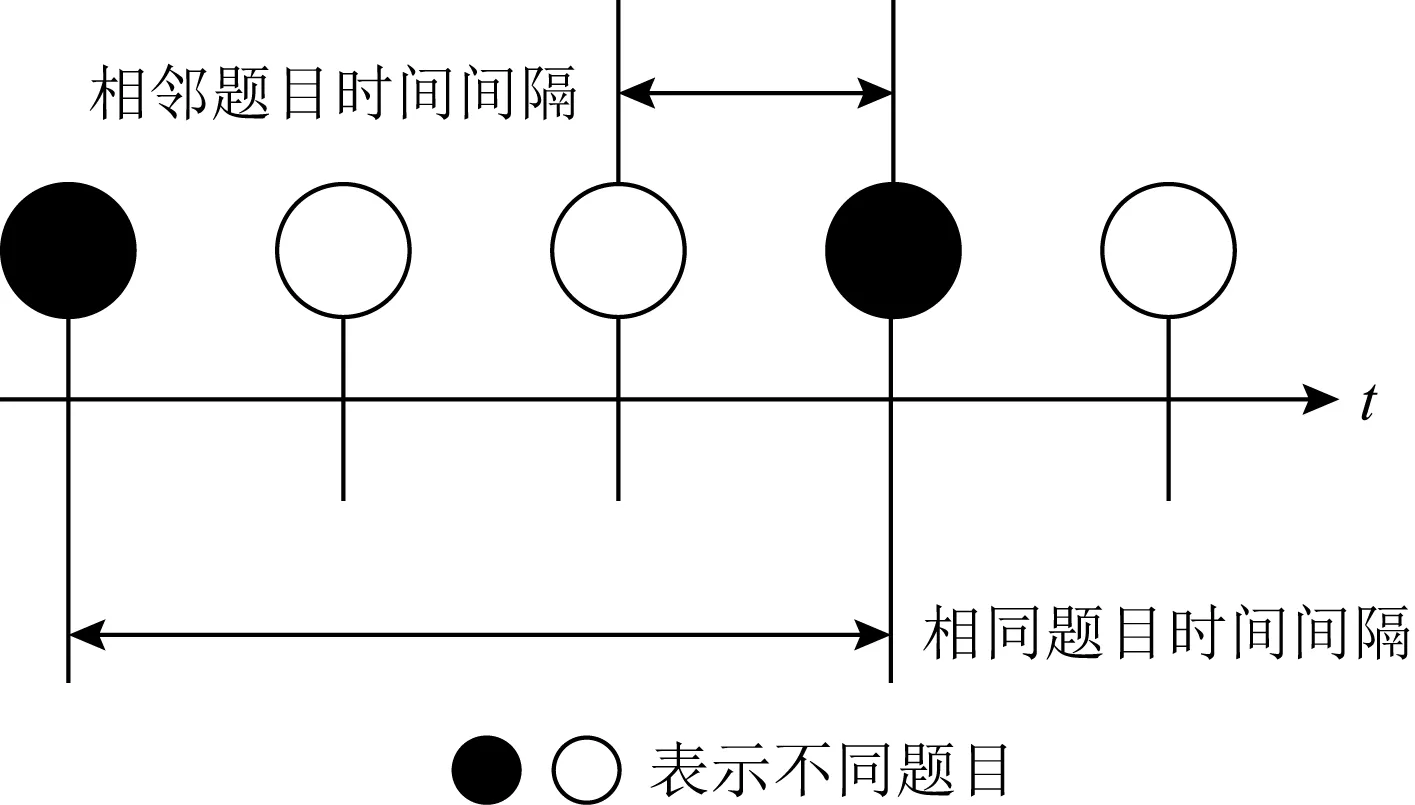
Fig. 11 Three measures of forgetting
使用one-hot編碼衡量遺忘的3種因素,然后連接,得到一個multi-hot編碼的遺忘因子ct.如圖12所示,遺忘因子作為額外的特征,分別與交互嵌入xt和隱藏狀態ht整合.
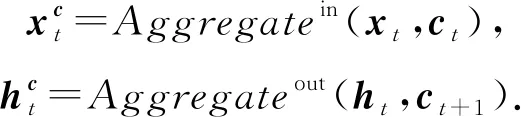
(35)
5) EERNN(exercise enhanced RNN)
Su等人[40]關注到題目文本描述中包含的豐富信息,并使用雙向LSTM提取文本描述的語義特征.如所圖13所示,題目的文本描述被表示為單詞序列并使用Word2Vec[61]將轉化為向量序列(w1,w2,…,wm),作為雙向LSTM的輸入.然后,訓練之后,連接前向狀態和后向狀態,經過一個逐元素的最大池化操作,得到最終的語義表示e.語義表示作為題目的嵌入,與答案組合成新的交互嵌入,作為LSTM的輸入.

Fig. 12 The addition of forgetting features
Fig. 13 The bidirectional LSTM is used to extract semantic features
6) AKT(adaptable KT)
Cheng等人[62]在其模型AKT中使用了與EERNN模型[27]相同的文本特征提取方法,并進一步從提出的語義特征中挖掘出學生的猜測(掌握了KC卻沒有答對題目)和失誤(沒掌握KC卻答對了題目)行為.
在AKT中,猜測gt和失誤st分別用單層神經網絡建模:
st=S(et),gt=G(et).
(36)

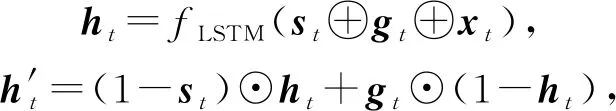
(37)
其中,fLSTM代表LSTM模型,⊙表示逐元素相乘.最后,模型根據知識狀態做出預測.
此外,AKT還利用了遷移學習的思想,通過額外的自適應層一定程度上解決了數據稀疏問題.相比納入專家知識[63],這種方法具有更好的泛化性.
7) EHFKT(exercise hierarchical feature enhanced KT)
Tong等人[5]在其模型EHFKT中使用了BERT[64]從題目的文本描述中提取了知識分布、語義特征和題目難度等信息.如圖14所示,EHFKT首先使用BERT生成文本描述的嵌入向量,然后經過知識分布提取系統(knowledge distribution extraction system, KDES)、語義特征提取系統(semantic feature extraction system, SFES)和題目難度提取系統(difficulty feature extraction system, DFES)分別生成知識分布、語義特征和題目難度.3個特征連接之后經過LSTM的輸入作出預測.
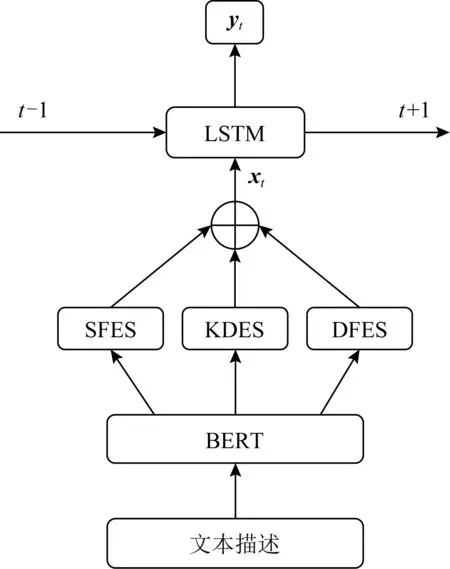
Fig. 14 Architecture for EHFKT
8) LSTMCQ(LSTM based contextualized Q-matrix)
Huo等人[65]在其模型LSTMCQ中提出了一種帶有上下文信息的題目編碼方法.具體來說,首先由領域專家手動創建一個矩陣Q,矩陣Q中存儲了題目與KC的對應關系.迭代更新矩陣Q以附加KC的權重信息,且同一個問題的所有權重相加為1,記為權重矩陣Q.最后,加入學生n在題目m上的表現信息rnm:
(38)
其中,N,M分別為學生和題目的數量.qmk為題目m中KCk所占的權重(即權重矩陣Q第m行第k列的值),δk表示學生在k上的平均表現.將δk與qmk相乘就得到了矩陣CQ(contextualized Q-matrix)對應的值:
CQmk=δk×qmk.
(39)
矩陣CQ包含了上下文信息,其每一行表示一個題目,將矩陣CQ的每一行單獨提取出來,即為帶有上下文信息的題目編碼.
9) DKT-DSC(DKT with dynamic student classification)/DSCMN(dynamic student classification on memory networks)
Minn等人[66-67]提出了一種根據能力分類學生,并將分類后的學生分組訓練的方法,相當于在模型的輸入中隱式地嵌入了學生能力信息.應用于DKT與DKVMN,分別稱為DKT-DSC和DSCMN.
具體來說,首先通過設置一個時間間隔將交互序列分段,在每一個時間間隔,計算學生每個KC的答對率和答錯率,并將兩者之間的差值轉化為數據向量,以代表學生的能力:
(40)

然后,用K均值(K-means)算法將學生按能力分組:
(41)
其中,μl為第l組(共m組)學生Cl的學習能力的均值.最后,將學生數據按照不同的分組放入模型中訓練.
2.3.2 損失函數限制
損失函數限制指將額外的學習特征作為限制條件,編碼到損失函數中的方式.
1) Colearn
Chaudhry等人[68]關注到了學習交互系統中學生的提示獲取(hint-taking)行為,并將其作為知識追蹤的子任務,提出了一個多任務模型Colearn.Colearn基于DKVMN模型,所不同的是,Colearn在更新知識狀態矩陣Mvalue時,額外添加了gt(指示是否使用了提示),新的輸入(qt,at,gt)用one-hot編碼為向量ft.Colearn的輸出有2個,答對的概率y和請求提示的概率yg:
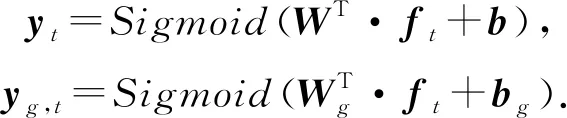
(42)
對應地,模型的損失函數也由知識追蹤任務和提示獲取任務2部分組成,并用超參數α,β平衡權重:
(43)
2) PDKT-C(prerequisite-driven DKT with constraint modeling)
Chen等人[69]將KC之間的先后序關系引入了知識追蹤模型,提出了PDKT-C模型.以P(mi,k,t=1)表示學生i在時刻t掌握KCk的概率,假設k1,k2存在先后序關系,將KC之間的關系建模為有序對,可以表示為
P(mi,k2,t2=1)≤P(mi,k1,t1=1).
(44)
這個有序對很自然地說明了一個事實:一個知識點越先進,學習起來就越困難.在式(45)的約束下,經過正則化后,PDKT-C模型的損失函數為
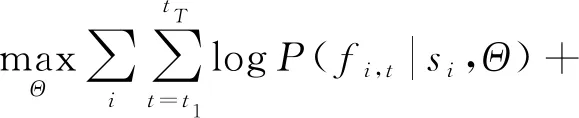
(45)
其中,si表示學生i的練習序列,Θ指代GRU的參數,fi,t指示學生i在時刻t是否回答了問題.第1部分為最大化似然函數.當fi,t1=fi,t2時,δ(*)=1,否則為0,α為平衡先決關系權重的超參數.
3) DKT-S(DKT with side information)
Wang等人[70]提出了DKTS模型,通過在加入一個用來捕獲題目之間關系的Side Layer,將題目之間的關系納入學生知識狀態建模.
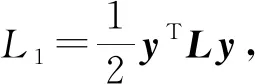
(46)
4) DHKT(deep hierarchical KT)
Wang等人[73]關注到了題目之間的層次結構關系,提出了DHKT模型.其通過KC嵌入和題目嵌入之間的內積鉸鏈損失(hinge loss)來對層次關系建模.題目ei與KCkj之間的鉸鏈損失定義為
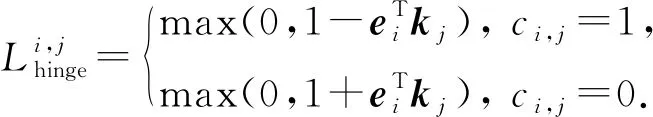
(47)
其中,ci,j=1表示ei與kj相關,反之無關.
在模型的訓練過程中,同時最小化預測損失和鉸鏈損失:
(48)
5) qDKT(question-centric DKT)
包含同樣KC的題目之間存在著差異,解決這些題目對知識狀態的貢獻也是不同的.為了區分這些差異,Sonkar等人[74]提出了qDKT模型,使用正則項對題目之間的差異建模:
(49)
其中,c=(c1,c2,…,cn)包含了所有n個題目的正確率(通過數據集計算),如果qi,qj包含同一個知識點,則1(i,j)=1,否則為0.這個正則項被加到模型的損失函數中作為限制:
(50)
2.3.3 新結構
新結構指通過使用新的模型結構,將額外學習特征納入模型計算過程中的方式.
1) GKT(graph based KT)
Nakagawa等人[75]提出了GKT模型,通過將KC間的關系表示為1個有向圖,知識追蹤任務轉化為了圖神經網絡(graph neural network, GNN)中的時間序列節點級分類問題.有向圖G=(V,E,A)由節點集(表示KC)V={v1,v2,…,vN}、邊集(表示KC之間的關系)E?V×V和鄰接矩陣(定義關系的權重值)A∈N×N定義.

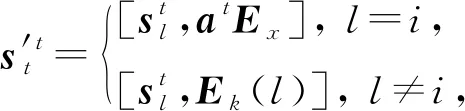
(51)
其中,Ex,Ek分別為交互和KC嵌入矩陣,Ek(l)表示Ek的第l行.根據圖結構更新知識狀態:
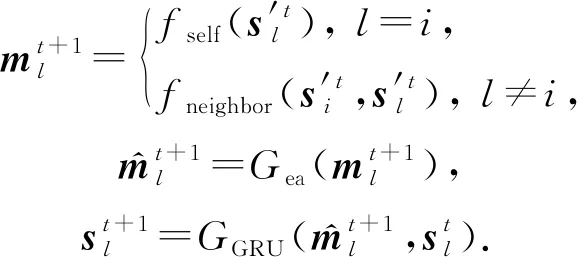
(52)
其中,fself為多層感知機,Gea為DKVMN模型中的刪除-添加機制,GGRU為GRU模型,fneighbor為一個基于圖結構信息向鄰接節點傳播的函數.
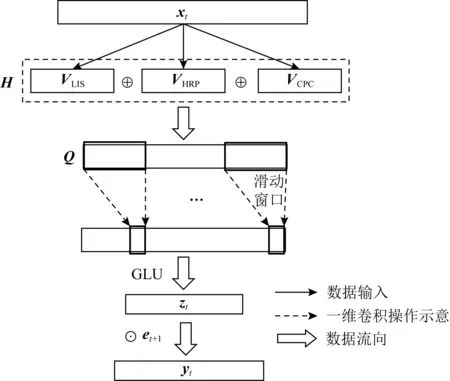
Fig. 15 Architecture of CKT model
2) CKT(convolutional KT)
Shen等人[76]提出了CKT模型,率先在知識追蹤領域使用了卷積神經網絡.如圖15所示,在CKT中,使用1維卷積操作從矩陣Q中提取學習率特征,滑動窗口將d個連續的學習交互映射為單個輸出元素,并使用GLU[77]作為非線性函數,在卷積層的輸出上實現一個簡單的選通機制,控制知識在學習過程中是否會被遺忘.最終的輸出zt作為學生的知識狀態,用于知識追蹤的預測任務.
yt=Sigmoid(zt·et+1).
(53)
矩陣Q由學習交互序列(learning interaction sequence, LIS)、歷史相關表現(historical relevant performance, HRP)和KC的正確率(concept-wised percent correct, CPC)在合并之后經過GLU單元[77]組成:

(54)
其中,?表示逐元素的乘法,VHRP,VCPC計算為
(55)
其中,Masking為掩碼操作,目的是排除后續時刻的學習交互,qk為與KCk相關的題目,count(qk)表示qk被回答的次數.
3) SKVMN(sequential key-value memory networks)
Abdelrahman等人[47]在SKVMN模型中使用三角隸屬度函數(triangular membership function)來計算KC之間的相關性:

(56)
其中,a,c確定三角形的“腳”,b確定三角形的“峰”.
相關性用來進一步計算題目間的順序依賴關系,并作為Hop-LSTM的約束,控制信息在其上的跳躍連接,如圖7所示.
4) DeepFM(deep factorization machines)
Vie[78]率先將DeepFM算法[79]應用到知識追蹤領域,其優勢在于對稀疏特征的添加與利用.DeepFM由FM和DNN(deep neural network)組成,前者的輸出為
(57)
其中,wi為偏置值,N表示特征數量,fi表示第i個特征,vi表示系數矩陣V的第i維向量,表示向量點積.
DNN是一個N層的前饋神經網絡,其輸出為

(58)
其中,c表示類別.DeepFM的預測由2部分組合得到:
y=Sigmoid(yFM+yDNN).
(59)
5) KTM-DLF(knowledge tracing machine by modeling cognitive item difficulty and learning and forgetting)
Gan等人[80]提出了一種結合學習者能力、認知項目難度、學習和遺忘等特征的建模方法,并使用KTM在高維中嵌入這些特征,所提出的模型稱為DKM-DLF.
具體來說,Gan等人[80]認為,題目的難度包括3個方面:題目所包含的KC的難度、學習者的知識狀態、題目的特點.綜合這3個因素,題目難度被概括為認知項目難度(cognitive item difficulty, CID).設βk為KCk的固有難度,δj指代題目特點,KC(j)為題目j中包含的所有知識點,θ為偏置值.則對于學生i在時間t作答的題目j來說,其CID為
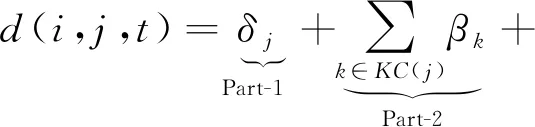
(60)
上述3個因素分別對應Part-1,2,3.其中,Ψ∈[0,c]代表難度,共c+1個等級,用之前交互中的回答錯誤率計算:
Ψi,v,t|v={j,k}=
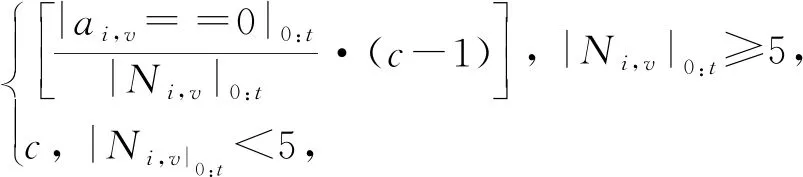
(61)
其中,|Ni,v|0:t表示學生i直到時刻t回答過的題目或KC.學生的學習特征通過其在相同題目Φi,j,t和包含相同KC的不同題目Φi,k,t上的表現計算:
(62)
無論回答的正確與否,都有助于知識的獲得:

(63)
其中,Wi,v,tw與Fi,v,tw分別指代答對次數和答錯次數,Ai,v,tw表示學生i在時間窗口tw的嘗試次數,tw|0:T是跨度不斷增大的時間間隔.
學習某個知識點的間隔越長,遺忘的可能性越大,將遺忘行為定義為
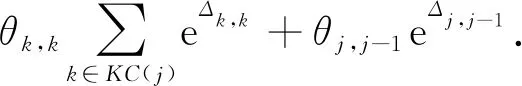
(64)
其中,e為自然對數的底,Δ為衡量遺忘的因素,有3個部分,與DKT+forgetting(圖11)中提到的略有不同,具體如圖16所示:

Fig. 16 Three measures of forgetting
設嵌入維度為0,用αi,j表示學生i在時刻t的能力,KTM-DLF模型可以表示為
Sigmoid(P(Yi,j,t=1))=αi,t-d(i,j,t)+l(i,j,t)-f(i,j,t).
(65)
6) DynEMb
Xu等人[81]結合了矩陣分解和RNN,提出了DynEmb模型,用矩陣分解做嵌入,用RNN對學習過程建模,DynEmb主要分為2部分:.
① QuestionEmb.給出學習交互,用矩陣分解學習題目嵌入矩陣Q和學生嵌入矩陣S:
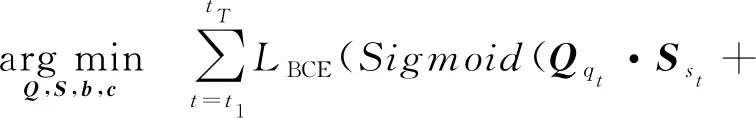
(66)
其中,b,c分別為題目和學生的偏置項,λ為平衡參數.
② StudentDyn.使用RNN生成動態的學生嵌入矩陣St.在時刻t-1,RNN的輸入為題目嵌入Qqt-1和向量(at-1,1-at-1)T的克羅內克積(Kronecker product),RNN的隱藏狀態就是學生st的動態嵌入Sst,t.DynEmb預測下一時刻答對題目的概率:
yt=Sigmoid(Qqt·Sst,t+bqt).
(67)
7) BDKT(Bayesian neural network DKT)
Li等人[82]提出了BDKT模型,使用貝葉斯神經網絡來對豐富的學習特征建模.BDKT的參數設置為分布形式:
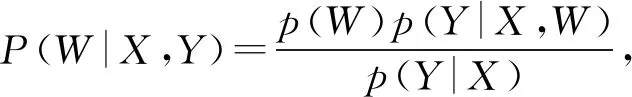
(68)
其中,X,Y分別為輸入和輸出,p(W)為參數W的先驗.由于P(W|X,Y)在訓練集(X,Y)上的概率分布是復雜的,難以用歸一化常數處理,也不能直接計算模型參數的后驗分布.BDKT使用了變分推斷(variational inference)解決這個問題,變分分布q(W)~N(W|μ,σ2)被用來近似真正的后驗分布P(W|X,Y),N(μ,σ2)表示數學期望為μ、方差為σ2的正態分布.p,q之間距離為

(69)
其中,Eq[logp(Y|X)]為常量,Eq[logp(Y|X,W)]可以從訓練集中得到.BDKT的損失由訓練損失和KL項決定:
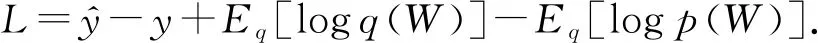
(70)
8) Q-Embedding
Nakagawa等人[83]提出了無需KC標簽信息的Q-Embedding模型,可以自動學習題目與KC的嵌入.

Fig. 17 Architecture of Q-Embedding model
Q-Embedding模型的結構如圖17所示,其中,P為需要學習的題目-KC矩陣,ut與vt為額外的隱藏層,長度分別為2N′和N′,N′為自定義的KC個數,ut,vt,P的定義為
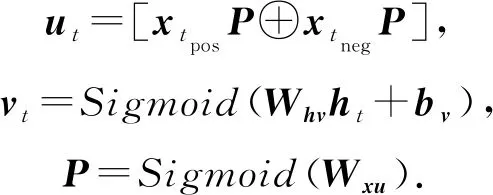
(71)
式(71)中,xtpos,xtneg分別表示xt的前后2部分,ht為RNN的隱藏狀態.使用2個額外的損失函數對模型進行訓練:
(72)
其中,Lref為對題目空間和KC空間的重構正則化,旨在反映以下假設:從學生對KC空間對應的每個KC的理解中,可以估計出學生對題目的回答情況.Ls為題目嵌入矩陣的稀疏正則化,目的是在訓練模型后二值化時使P接近0或1,并抑制信息丟失.Q-Embedding的損失函數分為3部分,預測的交叉熵Lpre,Lref,Lspa,用超參數α,β,γ平衡權重:
L=αLpre+βLref+γLspa.
(73)
2.3.4 小 結
本節詳細介紹了DLKT領域針對缺少學習特征問題的改進方法,主要分為嵌入方式、損失函數限制和新結構.其中,嵌入方式的最為直觀:通過添加更多信息,借助深度學習的特征提取能力,使模型自主地建立特征間的聯系.損失函數將額外信息作為一種限制條件,使模型向指定方向優化.新結構方式則充分利用了其他網絡結構的特點,帶來了許多優點(如預防過擬合[82]、減輕數據稀疏問題[62]等),但新結構的遷移應用研究不夠深入,其可能存在的缺點值得更進一步研究.
3 DLKT模型對比與分析
第2節詳細介紹了DKT模型的改進方法,按照改進側重點的不同,分為可解釋問題的改進、長序列依賴問題的改進、添加特征的改進和其他方面的改進.本節歸納了各類改進方法中所使用的數據集,同時也對DLKT在各公開數據集上的表現做了對比和分析.
3.1 數據集介紹
近年來,用作DLKT模型評估的公開數據集主要有9個,其簡述和下載鏈接如表2所示:

Table 2 DLKT Domain Public Datasets Summaries, Download Links and Models that Use Them
3.2 模型對比與性能概覽
表3總結了各種模型所屬的改進方向類別和其主要的改進方式.表4總結了使用公開數據集的DLKT模型的性能表現(以大多數論文都采用了的AUC指標為基準),表4中的數據皆來自于模型初始論文,取最大值.需要指出的是,深度學習模型受參數設置影響較大,且同一個模型在不同論文中的表現也存在較大差異,因此,表4中的數據參考價值大于實際意義.

Table 3 An Overview of DKT Model Improvement Methods

Table 4 An Overview of DLKT Models

續表4 %
4 DLKT模型的應用
在DLKT領域,除了對DKT模型的改進之外,還有許多研究致力于探索DLKT模型在教育領域的應用.如圖18所示,除了主要用來預測學生下一次答對題目的概率,DLKT模型還有許多其他應用,下面簡單介紹這些應用.

Fig. 18 Other applications of DLKT model
4.1 發現題目的拓撲順序
Zhang等人[84]提出了一種基于規則的方法,利用DKT模型發現知識點之間的拓撲順序.具體來說,在DKT模型中,由于一個題目對應一個知識點,因此,答對題目的概率可以視為掌握題目對應知識點的概率.將輸出概率大于0.5的知識點視為掌握,拓撲順序的發現分為3個步驟:
1) 確定偏序關系.若當前的知識點被掌握,則輸出概率最高的知識點為先決知識點;若當前的知識點未被掌握,則輸出概率最低的知識點為先決知識點.
2) 刪除冗余連接.設ka,kb,kc為存在ka→kb,kb→kc,ka→kc關系的3個KC,刪除其中的冗余連接,得到類似ka→kb→kc的有向無環圖.
3) 用Kahn’s算法[85]把有向無環圖轉化為拓撲順序.
4.2 應用于編程題(主觀題)
Wang等人[86]將LSTM模型應用到編程題上,模型的輸入為學生對單個編程題目的多次提交記錄.提交的代碼被表達成一個抽象語法樹(abstract syntax tree, AST),然后利用遞歸神經網絡對代碼的AST進行向量化[87-88],向量化后的AST作為LSTM的輸入,最后,模型預測學生能夠成功解決同一個知識點的下一個編程題的概率.Wang等人[86]的模型僅支持基于塊的編程語言Scratch,Swamy等人[89]擴展了他們的工作,提出了一種對編程語言沒有限制的模型.在模型的輸入方面,Swamy等人使用了scikit-learn的默認標記方案對學生代碼中的非字母數字字符做分詞,然后計算詞頻-逆文檔頻率(term frequency-inverse document frequency, tf-idf)生成代碼的向量表示.向量的長度為單詞的總數,其中每一項為對應單詞出現的次數.代碼的向量化表示與one-hot編碼的學生編號、問題編號、嘗試次數編號組合,作為LSTM的輸入,模型的預測結果為完成每個知識點對應題目的剩余嘗試次數.
4.3 驗證教育理論
Lalwani等人[90]利用DKT模型驗證改進的布魯姆分類法(revised Bloom’s taxonomy).改進的布魯姆分類法將認知分為6個階段,分別是記憶、理解、應用、分析、評估和創造.這6個階段的復雜度逐漸遞增,且前面的階段是后面階段的先決條件.Lalwani等人[90]將驗證過程抽象為研究掌握前面階段的KC對掌握后面階段知識點的影響.具體來說,通過模型的輸出判斷學生是否掌握KC,然后計算不同階段KC之間掌握程度的差異:

(74)
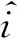
在后續的工作中,Lalwani等人[91]在原始的DKT模型中加入了學生練習之間的時間間隔作為特征,將改進后的模型命名為DKT-t通過比較DKT與DKT-t模型的差異,研究時間間隔對預測的影響,并進一步利用DKT-t模型追蹤遺忘曲線.
4.4 學習路徑推薦
Cai等人[92]提出了一種利用知識追蹤以及強化學習技術的學習路徑推薦方法,并命名為KT-KDM.KT-KDM分為2部分,KTM和DKM,前者是一個基于DKT+模型的知識追蹤模型,后者通過預測知識需求水平(level of knowledge requirements, LKR)來獲得KTM提供的學習者知識掌握程度,并推薦習題.
如圖19所示,推薦過程被建模為一個采用強化學習方法的Markov決策模型.KDM本質上是一個使用KTM建模的學習狀態作為輸入的預測網絡,其輸出為一個向量,其中每個元素表示每個習題的LKR.然后使用隨機加權函數選擇一個習題進行推薦.獎勵函數設計為相鄰2個推薦的習題的掌握度之差,同時,為了避免模型反復推薦相同的高回報習題,對已經推薦的習題進行了懲罰.獎勵函數為
(75)
其中,k表示推薦的最后一個KC,sk,t表示k在時刻t的知識狀態,nk,t表示在k被推薦的次數.

Fig. 19 Markov process model the recommendation learning path
4.5 STEM/Non-STEM職業預測
Yeung等人[93]將DKT+模型預測的結果與從數據集中提取出的學生特征相結合,以預測學生是否會從事STEM類職業.

Fig. 20 Architecture of STEM/Non-STEM career prediction model
如圖20所示,將DKT+模型最后一次預測的結果yt與學生的特征xsp連接得到x′=yt⊕xsp,作為機器學習模型的輸入.機器學習模型學習x′與STEM標簽l∈{0,1}的映射關系,并做出STEM/Non-STEM的職業預測,有GBDT,LAD,LR,SVM這4種實現方式.
4.6 生成試卷
Wu等人[94]提出了一種利用知識追蹤的試卷生成方法.具體來說,假設一張試卷包含nq個題目與nk個知識點,則試卷可以表示為一個矩陣E∈nq×nk.使用每種知識點出現的概率表示試卷中每種知識點的權重,用P(oj)表示KCj出現的概率:
(76)
其中,Eij表示E的第i行第j列.假設有ns個學生,學生的對知識點的掌握程度可以表示為矩陣S∈ns×nk.知識掌握程度來自于深度知識追蹤模型輸出的答對題目的概率,由于一個題目對應一個知識點,所以答對題目的概率可以看作是對知識點的掌握程度.將題目中所有知識點的掌握程度相乘即為答對題目的概率,學生l答對題目i的概率P(ali=1)表示為
(77)
用Scorei表示問題i的總分數,則學生l的試卷成績可以表示為
(78)
將ns個學生的成績聯合,表示為R={r1,r2,…,rn},用P(R)表示R的分布.Wu等人提出,合理的試卷有2個必要條件:
1) 卷中KC分布與課程中的接近,即Φ~W.其中,Φ=(P(o1),P(o2),…,P(onk)),W中每一項表示對應KC的權重.
2) 每一組學生成績的分布應該符合正態分布,即P(R)~N(μ,σ2),其中,N(μ,σ2)表示均值為μ、標準差為σ2的正態分布.
最后,使用動態規劃算法和遺傳算法更新試卷,使其符合上述2個必要條件.
5 總結與展望
本文聚焦教育大數據中的知識追蹤,對該領域內基于深度學習方法的知識追蹤模型進行了全面回顧和系統性的梳理.首先介紹了該領域的開創性工作DKT,然后基于該工作,分針對可解釋問題的改進、針對長期依賴問題的改進以及針對缺少學習特征問題的改進三大主要技術改進方向構建了技術演進脈絡圖、梳理了各模型的技術重難點、分析了各模型的優點和局限性.其中,可解釋性問題作為深度學習領域普遍存在的問題,尚未得到有效解決,DLKT也不例外,目前的方法都只能有限地提高可解釋性.長期依賴問題在自注意力模型上得到了完美解決,但其需要額外的位置編碼才可以維持序列學習能力.對缺少學習特征問題的研究占據了DLKT的主要部分,嵌入方式、損失函數限制和新結構3種方式各有優劣:嵌入方式直觀但是過于依賴模型的學習能力,損失函數限制可以使指定模型優化的方向但需要大量的人工工作,新結構的使用帶來了許多優點,但深入研究的缺乏可能使其中的缺點無法暴露.最后我們還整理了可供研究者使用的公開數據集,對比評估了各模型的性能表現和考察了該領域的主要應用.
基于深度學習的知識追蹤因其優秀的性能而被廣泛關注.對于目前發展迅速的線上教育,其產生的大量教育數據正好對應了深度學習模型對于數據量的需求,而無需標注數據的特性大大提高了數據的利用率,同時,深度學習框架的普及降低了模型構建的門檻.多種因素的共同作用,使得DLKT被廣泛應用于在線教育平臺,也使其成為教育數據挖掘領域新的研究熱點.但是目前該領域尚在起步階段,在實際應用中,仍有許多挑戰和問題亟待解決.基于目前存在的挑戰與問題,我們總結了7個可能的研究方向供研究者參考.
1) 現有DLKT模型大多使用二元變量來表示題目的回答情況,這種建模方式不適合分數值分布連續的主觀題.Wang等人[86]和Swamy等人[89]在處理學生的編程數據時,使用了學習者回答的連續快照作為回答情況的指示器,這提供了一種對主觀題目建模的方式.而其他的對主觀題目的建模方法仍有很大的研究前景.
2) 目前DLKT主要應用于在線教育平臺,如何利用好在線平臺所提供的大量學習軌跡信息,是研究的難點之一.Mongkhonvanit等人[95]提供了一種對教學視頻觀看行為建模的方法,Huan等人[96]則利用了鼠標軌跡信息.而其他學習特征信息的提取、建模亟需更多的研究.與此同時,特征的添加也是一大難點.對于以RNN為基礎的DLKT模型來說,輸入向量的長度會顯著影響模型的訓練速度.這就需要使用降維方法減小向量的長度,或者采用其他的嵌入方式(如LSTMCQ)融合更多特征而不增加向量長度.總而言之,學習特征信息的提取、建模、添加將會是DLKT實際應用中的重點研究方向.
3) DLKT的優秀性能使利用其驗證經典教育理論成為可能.如Lalwani等人[90]驗證改進的布魯姆分類與遺忘曲線.同時,已提出的教育理論也可以為建模提供指導,如Gan等人[80]結合了學習與遺忘理論.經典教育理論在DLKT領域的應用值得更多的研究者加以關注.
4) 利用DLKT模型構建知識圖譜.DLKT模型可以用來發現知識點之間的相互關系,構建出知識點關系圖,這可以看作是簡化的知識圖譜.知識圖譜作為當前人工智能時代最為主要的知識表現形式,如何擴展模型的知識結構發現能力,將知識點關系圖擴展為知識圖譜將會是未來的重點研究方向.
5) 目前的DLKT模型中仍存在許多不確定因素,現有的理論推斷并不足以解釋DLKT模型的訓練過程.在基于Transformer的模型中,掩碼機制被用來屏蔽后面時間的權重,這是為了防止未答的題目影響已答的題目.而Xu等人[97]使用雙向LSTM以融合過去和未來的上下文序列信息.兩者所依據的原理是相悖的,但都獲得了性能提升.如何深入研究,以完整解釋DLKT模型的訓練過程,將會是未來的重點研究方向.
6) 目前DLKT主要使用RNN模型,許多研究已經證明了RNN的優越性.同時,Transformer模型、GNN模型也在知識追蹤領域有著優秀的表現.而其他更多模型的應用仍亟需深度研究,對其他深度學習模型的應用將會是重要研究方向.
7) Transformer相對于RNN的一大優勢就是沒有長期依賴問題,但目前基于Transformer的DLKT模型卻并沒有利用好這個優勢,如SAKT和SAINT,它們都將序列長度設置為100,這個長度并沒有超過LSTM的序列學習容量(200).同時,實驗顯示,位置編碼的有無對最終的結果影響并不大.這似乎說明長期依賴與序列關系對KT任務的影響沒有目前所認為的那么大,以此類推,各種學習特征對于KT任務的影響值得進一步研究.
作者貢獻聲明:劉鐵園、陳威是綜述的主要寫作人,完成相關文獻資料的收集和分析、論文初稿的寫作和校對;常亮、古天龍是項目的構思者及負責人,指導論文寫作.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
核科學與工程(2015年4期)2015-09-26 11:59:03
