智能網卡綜述
2022-01-19 08:49:18馬瀟瀟元國軍安學軍
計算機研究與發展 2022年1期
關鍵詞:設計
馬瀟瀟 楊 帆 王 展 元國軍 安學軍
1(中國科學院計算技術研究所高性能計算機研究中心 北京 100190)2(中國科學院大學 北京 100190)
隨著網絡技術、存儲技術、芯片設計制造技術的不平衡發展,目前,計算機網卡的設計面臨新的問題.網絡速度在2020年已經邁向400 Gb/s以太網大關,并正向著更快的800 Gb/s,甚至1.6 Tb/s發展[1],而后摩爾時代意味著CPU的頻率已經趨于穩定,在這種不平衡的現狀下,使用傳統的CPU來進行網絡處理已經顯得不盡如人意.在速度上,現代CPU需要用10~15 ns來訪問L3 Cache,而400 Gb/s的網絡僅需1.2 ns便可傳送64 B的消息[2];在計算能力上,CPU適合于處理串行的復雜指令操作,對大量并行的固定模式的計算并不適用;再者,在云環境多租戶的情況下,開放虛擬交換(open virtual switch, OVS)等網絡功能虛擬化將占用更多的CPU資源[3-4].此外,通過CPU訪問內存進行數據搬移的開銷在很多應用中占據了極大的比例,如在快速傅里葉變換(fast Fourier transform, FFT)計算中,數據搬移占據了40%的開銷[5],旁路CPU已經成為一種重要的解決方式.因此,能夠滿足高速的網絡處理需要、卸載CPU不適合的網絡處理任務、提供一定編程靈活性的智能網絡終端設備——智能網卡(smart network interface card, SmartNIC),應運而生,并且在協議處理[2,6-7]、網絡功能[8-10]、數據中心云服務[11-14]、人工神經網絡加速[6,15-17]、科學計算[5,18]等諸多場景中發揮了重要作用.
在學術界,智能網卡的雛形是微軟亞洲研究院在2014年提出的基于現場可編程門陣列(field programmable gate array, FPGA)的Catapult設計,一種用于加速大規模數據中心服務的可重構網絡[19],并在后續的一系列研究[3,20-22]中逐漸發展,且已經部署到Azure云中;在產業界,智能網卡的產品最初主要由有一定市場和技術儲備的成熟網絡設備生產商Mellanox[23],Netronome[24],Broadcom[25],Cavium[26]提供,Netronome公司于2016年9月在公司網站發文,對智能網卡的需求和定義進行了闡述,提出智能網卡必須具備實現復雜網絡數據平面功能的能力,可以靈活地更改數據平面,并且與現有生態無縫銜接[27].而Mellanox公司則于2018年8月發文,借助PC Magazine對智能網卡的定義——能夠卸載CPU通用處理任務的網卡[28],介紹了該公司推出的3種基于不同處理器架構的智能網卡產品[29].此外,近幾年陸續出現了許多推出智能網卡的小公司,如BittWare[30],Ethernity[31]等,而Amazon[32]、華為[33]這樣的大公司在近5年里也陸續收購小公司或者研發智能網卡用于自身部署,甚至推向市場.綜合以上學術界和產業界的觀點,本文認為智能網卡至少應當具有4個特性:
1) 滿足現有數據平面網絡處理需求;
2) 兼容現有網絡協議生態;
3) 能夠靈活卸載通用CPU不適合的處理任務;
4) 提供用戶友好的可編程性.
本文將從智能網卡的基礎架構設計、編程框架、重點應用、未來研究熱點4個方面進行綜述,系統介紹智能網卡在產業界和學術界的發展過程和現狀,分類對比不同設計的優勢和不足,列舉典型的智能網卡應用場景和潛在問題,為今后智能網卡的軟硬件協同設計提供參考和思路.
本文的主要貢獻包括4個方面:
1) 對基于FPGA、多核處理器(multi-core pro-cessors, MP)、特定應用集成電路(application specific integrated circuit, ASIC)的不同處理器架構和基于On-Path,Off-Path的不同數據通路設計架構進行分類,明確不同設計思路的優勢和不足;
2) 對可用于智能網卡的多種編程框架進行總結,權衡分析數據流驅動、控制流驅動的設計思路;
3) 對智能網卡在數據中心、科學計算中的典型應用場景進行總結,明確智能網卡的使用價值和設計目標;
4) 對當前智能網卡的設計缺陷和使用瓶頸進行總結,指出未來智能網卡軟硬件協同設計的研究方向和值得思考的問題.
1 智能網卡基礎架構
目前,產業界和學術界中智能網卡的硬件設計架構多種多樣,在性能、成本、使用靈活性等方面亦表現得參差不齊.本節我們將從核心處理器選擇和數據通路設計2個維度對智能網卡的基礎架構設計進行分類綜述.
1.1 按核心處理器分類
從核心處理器角度來分析,目前智能網卡的設計主要有三大類,分別為基于FPGA,MP,ASIC的設計.下文將依次對基于不同處理器智能網卡的研究和商業產品進行介紹.
1.1.1 基于FPGA的設計
在學術界,以FPGA作為智能網卡核心可編程處理器的研究主要以微軟研究院為代表[3,19-22].圖1描述了微軟一系列設計架構的演進.2014年,微軟提出了基于高端FPGA——Altera Stratix V D5[34]的Shell(通用邏輯)+Role(可重構處理邏輯)的可重構數據中心云服務加速方案,用于解決商用服務器滿足不了飛速增長的數據中心業務需求、定制化加速器成本開銷大且靈活性不足的問題[19].如圖1(a)所示,其中Shell為可重用的通信、管理、配置等通用邏輯,包含2個DRAM(dynamic random access memory)控制器(管理FPGA上的2塊DRAM)、4個10 Gb/s輕量級FPGA間串行通信接口SerialLite3、管理DMA通信的PCIe核、路由邏輯(用于管理來自PCIe,Role,SerialLite3的數據)、重新配置邏輯(用于讀、寫、配置Flash)、事件翻轉邏輯(用于階段性的監督FPGA狀態以減少錯誤);而Role則位于FPGA芯片的固定區域中,是跟用戶加速應用緊密相關的邏輯,文中以加速Bing搜索為例,將排序邏輯映射到Role中進行加速.在Catapult設計中,考慮到FPGA的管理和使用,同機架下的所有FPGA以6×8的2維Torus網絡拓撲的形式組成一套新的網絡進行連接,可以將同機架下的所有FPGA作為加速資源使用.但是,使用第2套網絡的設計方式:一方面,增加了網絡的開銷和容錯管理;另一方面,對于網絡流、存儲流、分布式應用僅能提供有限的加速.此外,機架內的2維Torus直連使得用戶對跨機架的FPGA資源無法得到有效的使用.

Fig. 1 The evolution process of Microsoft SmartNIC architecture[19-22]
微軟在2016年的研究工作中對Catapult進行了改進,將FPGA網絡與數據中心網絡融合,提出了新的云加速架構設計[20].如圖1(b)所示,在Stratix V D5 FPGA板卡上設計了2個40 Gb/s的QSFP(quad small form-factor pluggable)端口,分別與主機端已有的普通網卡和架頂交換機(top-of-rack, ToR)相連接,對應地,在新的Shell設計中,原來Catapult的4端口SerialLite3被替換為輕量級傳輸層(lightweight transport layer,LTL)引擎用于處理2個40 Gb/s端口.這樣,所有的網絡數據都要經過FPGA的以太網端口,FPGA便可以更直接、高效地對網絡數據流、存儲數據流進行加速,在可擴展性上也有很大提升.文中除了加速網頁搜索應用,還對傳輸中的網絡數據加密進行了FPGA加速,以體現該設計的加速效果.此時,微軟初代智能網卡已成雛形,只是FPGA和通用網卡還未集成在一塊板卡上.同年,微軟提出了針對該FPGA智能網卡的一套高級編程語言——ClickNP[21](類似C語言),實現FPGA和CPU之間的協同編程,使用模塊化的實現方法,向用戶提供友好的編程接口.文中以多種網絡功能為例進行了實驗評估驗證,一定程度上解決了權衡FPGA高性能和編程復雜的問題.
微軟在2018年的研究中將軟件定義網絡(software define network, SDN)棧卸載到其二代智能網卡[3],用以更好地支持單根I/O虛擬化(single root I/O virtualization, SR-IOV)[35].如圖1(c)所示,此時,二代智能網卡已將通用網卡和高端Intel Arria 10[36]FPGA集成到1個板卡上,對外的ToR端口已經達到50 Gb/s,但從架構上而言并無實質的變化,仍然采用將FPGA放置在通用網卡和ToR數據通路之間的設計,用于高效地處理數據流,提供路徑上的網絡功能、特定應用加速.微軟在后來的研究中指出,鑒于當前可編程網卡、可編程交換機的硬件條件支持,充分利用可編程網絡設備組成高效的全網可編程云將成為一種趨勢[22].
在產業界,近些年,涌現出眾多基于FPGA設計智能網卡的小公司,如BittWare,Ethernity等.同時,部分老牌公司如Mellanox,Intel,Xilinx也相繼推出基于FPGA的智能網卡類產品.
BittWare[30]公司推出了基于FPGA的100 Gb/s智能網卡Shell.支持網絡功能虛擬化(network function virtualization, NFV)、網絡監控(network monitoring)、預防DDoS(distributed denial of service)攻擊等功能.此外,用戶可以自定義對數據包的處理,其中自定義IP的設計支持Xilinx SDNet編譯器,因此滿足P4[37]編程,可以通過Match-Action[38]的方式對數據包進行用戶自定義處理.Netcope[39]于2017年推出的基于Xilinx Virtex UltraScale+[40]FPGA的NFB(Netcope FPGA board)系列智能網卡亦支持P4編程.Eynx[41]公司亦推出了與BittWare類似的基于FPGA的1~40 Gb/s智能網卡產品.Ethernity[31]推出ACE-NIC系列基于Xilinx Ultrascale+FPGA智能網卡,主要提供網絡功能虛擬化的卸載、OVS的卸載.Reflex CES[42]推出了基于Intel FPGA和Xilinx FPGA的兩大類PCIe終端網絡設備.其中XpressGX S/A**系列分別基于Intel的4款FPGA產品:1)帶有2塊HBM(high bandwidth memory)的Stratix 10[43];2)無HBM的Stratix 10;3)Arria 10;4)Stratix V.XpressV***系列則分別基于Xilinx的4款FPGA產品:1)分別使用帶有HBM的Virtex UltraScale+;2)無HBM的Virtex UltraScale+;3)Kintex UltraScale+[44];4)Virtex 7.其中XpressGX S10-FH800G板卡使用Intel Stratix 10 FPGA,可以滿足800 Gb/s以太網需求,可用于數據中心、云計算、安全、高性能計算、軍隊安防、視頻廣播等領域.Silicom[45]同樣推出基于Intel FPGA和Xilinx FPGA的可編程網卡.帶寬分為1 Gb/s,10 Gb/s,40 Gb/s,100 Gb/s這4個級別.基于Xilinx FPGA的設計中,分別有基于Virtex 6,Virtex 7,Virtex UltraScale,Kintex UltraScale,Kintex UltraScale+的產品;基于Intel FPGA的設計中,分別有基于Airra 10,Stratix 10的產品.
Mellanox推出了Innova系列[46]基于Xilinx Kintex UltraScale高端FPGA的智能網卡,包含Innova和Innova-2 Flex共2代產品.最新的Innova-2智能網卡中內嵌其ConnextX-5[47]網卡控制器,提供40 Gb/s,100 Gb/s雙端口以太網或者InfiniBand網絡,ConnextX系列ASIC已經滿足基本的智能網卡卸載功能,如RoCE(remote direct memory access over converged Ethernet)網絡協議、vSwitch/vRouter、I/O虛擬化的硬件卸載,而高端的可編程FPGA則可以為用戶提供更高效的特定應用加速服務,例如安全、存儲、機器學習等方面的應用加速.
Intel則推出了基于兩大類可編程PCIe加速卡,其中基于Arria10/Arria10 GX FPGA的可編程加速卡Intel FPGA PAC(Intel FPGA programmable acceleration card) N3000[48],用于加速協議棧處理、NFV等應用;此外,另有基于Stratix 10 SX的可編程加速卡Intel FPGA PAC D5005[49],面向數據流分析、視頻編碼轉換、金融、人工智能、基因分析等領域.
Xilinx于2019年4月收購Solarflare[50]公司,其實,自2017年Xilinx便與Solarflare合作,其推出的網卡含有XtremeScale X2和8000共2個系列以太網卡.其中X2系列產品是面向數據中心的設計,帶寬達到10 Gb/s,25 Gb/s,40 Gb/s,100 Gb/s,其Cloud Onload[51]旁路內核技術、TCP-Direct技術與X2的結合可以在負載均衡、數據庫緩存、容器應用、網頁服務方面減輕操作系統的開銷,提高性能;其中8000系列產品,帶寬達到10 Gb/s,40 Gb/s,延時小于1 μs,提供用戶自定義功能的軟件接口,可用于特定應用加速,以及網絡包抓取、監控、分析、過濾等.2020年3月,Xilinx將已有技術進行整合,將XtremeScale以太網控制器與高端Zynq UltraScale+XCU25 FPGA結合,推出其最新的Alveo U25[52]智能網卡一體化平臺,應對業界的挑戰性需求與工作負載,如 SDN,OVS,NFV,NVMe-oF(non-volatile memory express over fabric)[53],以及電子交易、AI 推理、視頻轉碼和數據分析等,在編程框架方面,Alveo U25支持高級綜合語言(high level synthesis, HLS)、P4高級編程抽象,同時支持Xilinx的Vitis[54]統一軟件平臺計算加速框架,方便Xilinx及第三方應用加速.
小結:總體而言,基于FPGA的智能網卡產品設計大多數與Catapult中的設計方案類似,即FPGA分為Shell+Role,再與網卡芯片集成到一個板卡上.在具體的設計細節中,部分設計將逐漸趨于成熟的卸載技術轉移到ASIC網卡中,FPGA的使用也逐漸向高端產品邁進.基于FPGA的設計方式,在產業界得到了一定的認可,因為可以極大地利用FPGA豐富的邏輯單元實現對數據快速地并行處理,并且引入較小的能耗開銷;但是,FPGA對應的硬件編程語言在編程復雜度上較繁瑣,需要高效的編程框架(如ClickNP)支持,其次,FPGA的價格相對昂貴,在數據中心中大量部署需要具備雄厚的經濟實力.
1.1.2 基于MP的設計
另一種得到業內認可的智能網卡的設計方式為采用片上多核的方式來進行網絡數據的可編程加速處理,多數使用片上系統(system on chip, SoC)的實現方案,使用的處理器核可以是專用的網絡處理器(network processor,NP),如Netronome NFP系列[55]、Cavium Octeon系列[56],也可以是通用處理器(general processor,GP),如ARM.下文將從通用處理器和網絡處理器2個方面進行介紹.
1) 基于NP-SoC的智能網卡
Netronome早期在2016年推出了NFE-3240系列用于網絡安全相關應用的智能網卡,對數據包可達到20 Gb/s的C語言可編程線速處理.在2018,2019年,Netronome陸續推出了三大系列Agilio[24]智能網卡:①面向計算節點的Agilio CX,基于NFP-4000或者 NFP-5000網絡處理器,可以完全卸載虛擬交換機對網絡功能中數據平面的處理、卸載典型的計算密集型任務;②面向Bare-Metal服務器的Agilio FX,基于NFP-4000網絡處理器和4核ARM v8 Cortex-A72 CPU(可運行Linux OS);③面向服務節點的Agilio LX,基于NFP-6000網絡處理器,主要用于虛擬化、非虛擬化的X86服務節點和廣域網網關.Agilio系列產品支持靈活的包解析和Match-Action處理,可以進行eBPF,C,P4編程.
Cavium推出基于cnMIPS III網絡處理器的LiquidIO[26]系列智能網卡.其中cnMPIS III是Cavium公司實現的基于MIPS64指令集架構(instruction set architecture,ISA)的Octeon系列第3代產品,此外,Octeon系列產品中還有基于ARM的產品.cnMPIS III 中的CN7***系列產品頻率可達2.5 GHz,集成48個處理器核,cnMPIS III系列處理器面向智能網絡相關應用(從Layer2到Layer7)的可編程需求,吞吐可滿足100 Mb/s到200 Gb/s的網絡,以此為核心處理器設計的LiquidIO,LiquidIO II智能網卡,可進行C語言編程,可以用于OVS、NFV、安全、存儲、應用加速等智能網絡服務.
華為[33]推出了IN系列三大類智能網卡:早期2012年的iNIC系列、2017年的SD100(基于ARM通用處理器,含16個2.1 GHz Cortex-A57處理核心)、2018年5月的IN500系列(IN200基于海思Hi1822芯片,IN300 FC HBA基于海思高性能Fibre Channel HBA芯片).此外,SolidRun[57]推出基于NXP LX2160A通信處理器的智能網卡,Silicom[58]推出基于NetLogic XLP316和RMI XLS416網絡處理器的2類智能網卡,Kalray推出基于第3代MPPA[59](massively parallel processor array) 架構Coolidge處理器的KONIC200[60]系列智能網卡,其中每個Coolidge處理器含有80個64 b超長指令字核、80個協處理器、其他加速部件及外圍連接邏輯.
2) 基于GP-SoC智能網卡
Mellanox除了推出基于FPGA的Innova系列可編程智能網卡,還推出了基于BlueField IPU(I/O processing unit)系列可編程智能網卡[23],支持Ubuntu,Centos系統.其中BlueField初代產品集ConnectX-5控制器、ARM v8 A72處理器陣列(最多16核,0.8 GHz)、8 GB,16 GB DDR4內存控制器于一體,最大支持雙端口25 Gb/s,50 Gb/s,100 Gb/s的以太網或者Infiniband網絡連接.BlueField-2則集成了最新的ConnectX-6控制器,仍然使用ARM處理器陣列,可支持單口200 Gb/s以太網或者Infiniband網絡連接,該系列智能網卡可用于加速數據中心或者超算中的安全、存儲、網絡協議及功能的卸載和加速.
Broadcom推出Stingray系列智能網卡產品[25],其PS410T,PS225,PS250產品分別定位為4×10 Gb/s, 2×25 Gb/s, 2×50 Gb/s高性能數據中心智能網卡,支持數據平面加速和軟件定義存儲(software defined storage, SDS),如NVMe-oF.以PS250為例,Stingray SoC集成了NetXtreme E系列100 Gb/s以太網卡控制器、TruFlow可配置流加速器、8個ARM v8 Cortex-A72處理器核(3.0 GHz)及多種加速引擎,支持RoCE v1/v2,SR-IOV,使用標準的Linux系統、GNU工具庫,定位用于Bare Metal和虛擬化服務器平臺(OVS卸載)、存儲服務器場景.
Amazon于2015年初收購以色列芯片制造商Annapurna,次年,Annapurna實驗室發布Alpine系列[32]基于ARM v7或者ARM v8架構的芯片,可用于網絡存儲、虛擬化、云服務等場景,并在AWS中得到使用.在此基礎上,Amazon相繼推出幾代Nitro系統,并于2018年發布Graviton處理器,雖然并未公開Nitro系統的架構,但其中應當存在基于ARM的智能網卡的影子.
小結:基于MP的智能網卡設計框架如圖2所示,均含有5個重點模塊:①多種已經成熟的加速部件,如Hash計算、加解密(Crypto)等;②用于與主機通信的PCIe接口,多數支持SR-IOV;③多種與外設通信的接口,如I2C,JTAG等;④訪問智能網卡板上內存的控制器;⑤ 片上NP或者GP多核,用于OVS,RSS(receive side scaling)等網絡功能,以及用戶自定義功能.NP或者GP多核的具體片上布局會有差異,多數設計采用Mesh方式,但也有例外,如MPPA[59]則采用多個Cluster的方式,Cluster內部共享內存.此外,有的NP內部含有多種處理器核,如Netronome NFP系列[55]NP內部有包處理器核和流處理器核兩大類,分別用于包的解析、分類和數據流的處理.
基于NP和GP的SoC具體設計上略有差異:①如圖2中左斜陰影部分所示,基于NP-SoC的設計,會將網絡協議如TCP、遠程數據直接訪問(remote direct memory access, RDMA)放在NP核上處理,如華為智能網卡[33];②如圖2中右斜陰影部分所示,基于GP-SoC的設計,其內部多數會集成專門的網絡控制器,用于網絡協議的處理,甚至部分典型的網絡功能卸載,而將更復雜的任務放在GP核上處理,如Mellanox BlueField智能網卡內部集成了ConnectX控制器[23],而Broadcom Stingray智能網卡內部集成了NetXtreme E控制器[25,61]專用于網絡協議處理;③如圖2中網格陰影部分所示,部分基于NP-SoC設計,除了集成眾多NP核用于實現可編程功能,還有可能集成幾個GP核,可運行Linux系統,用于Bare-Metal服務器場景,如Netronome Agilio FX智能網卡[24]同時集成了NFP-4000和ARM v8 Cortex-A72.
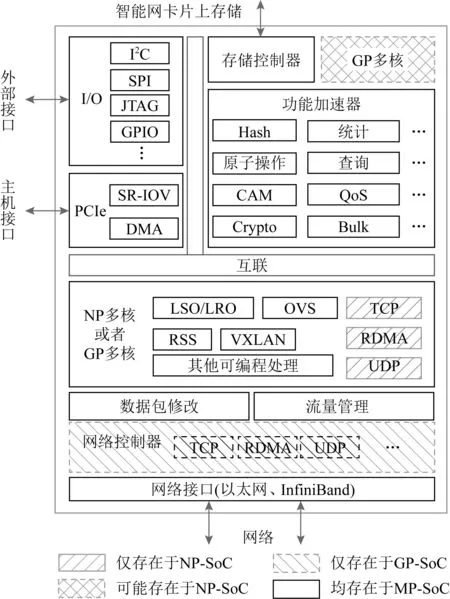
Fig. 2 MP-based SmartNIC block diagram
在性能方面,基于NP-SoC的智能網卡會略勝于基于GP-SoC的智能網卡,因為在并行性上,NP相比GP更占優勢,但基于MP的性能均不及基于FPGA的性能;在成本方面,基于NP-SoC的智能網卡會低于基于GP-SoC,FPGA的智能網卡;在編程方面,基于NP-SoC的編程復雜度居于FPGA和GP-SoC之間,基于GP-SoC的智能網卡在編程方面最友好.
1.1.3 基于ASIC的設計
目前,基于ASIC的智能網卡并不多,ASIC芯片主要以網絡控制器的角色出現在智能網卡中,如Mellanox的ConnectX系列[47]、Broadcom的NetXtreme系列[61]、Cavium的FastLinQ系列[62].此類ASIC網絡芯片除了能夠滿足傳統的網絡協議(如TCP,RoCE)處理需求,又具備一定的卸載CPU處理能力和可編程性.以Mellanox最新的ConnectX-6產品為例,其在一定程度上提供對數據平面的可編程處理和硬件加速,提供虛擬化、SDN的支持,可硬件卸載網絡虛擬化中的VxLAN(virtual extensible local area networks),NVGRE(network virtualization use generic routing encapsulation)等協議,卸載網絡安全中的部分加解密運算,支持NVMe-oF等用于存儲場景的存儲協議處理,支持GPU-Direct等機器學習應用場景中數據零拷貝的低延時通信.
小結:1)在性價比方面,基于ASIC的智能網卡,基本上可以滿足多數通用網絡處理的應用場景,可以在預定義的范圍內對數據平面進行可編程處理,并提供有限范圍內的硬件加速支持,如果是批量使用,在性價比上會有較大的優勢;2)在編程復雜度方面,基于ASIC的智能網卡雖不及基于MP的智能網卡那么簡單,卻也遠易于基于FPGA的智能網卡;3)在使用靈活性方面,基于ASIC的智能網卡相比于其他的智能網卡靈活性最差,對于更復雜的應用場景則顯得力不從心,更明確地來說,單純基于ASIC的智能網卡應該稱之為卸載網卡,因為其可編程性并不完全.從長遠的角度分析,其定制化的邏輯,對于已經成熟的應用場景雖然能夠提供顯著的性能提升,但是隨著時間的推移,新的應用場景對智能網卡將會提出新的功能要求.目前,很多廠家采用ASIC+GP的設計方式來解決這一問題,類似前文Mellanox的BlueField產品(集成了ConnectX-5和ARM).同時,商家不斷地更新ASIC產品,將成熟的技術定制化到網卡中,如ConnectX系列已更新到第6代.可見,體系結構中靈活性和性能之間的斗爭依然在繼續著.
1.2 按數據通路分類
從核心處理器與數據通路的關系來分析,目前智能網卡的設計主要有On-Path,Off-Path兩大類設計[13].其中On-Path架構如圖3(a)所示,核心處理器在數據發送、接收的路徑上,直接對數據包進行處理;Off-Path架構如圖3(b)所示,核心處理器并不在數據發送、接收的路徑上,而是通過網卡上的交換部件(圖3(b)中的SmartNIC Switch)決定將數據直接送往主機端還是由核心處理器做處理.下文將依次對On-Path,Off-Path智能網卡的研究和商業產品進行綜述.
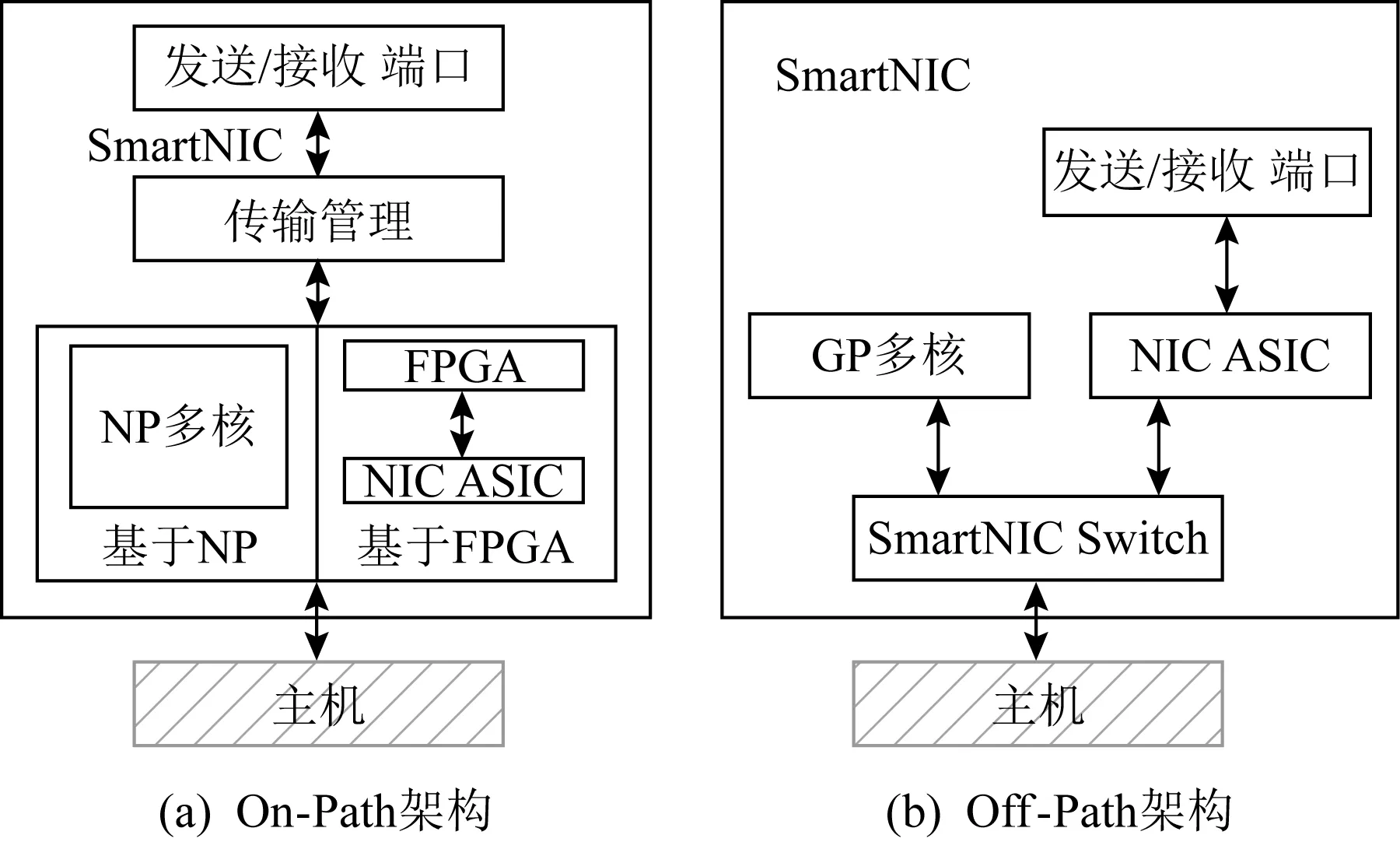
Fig. 3 On-Path,Off-Path SmartNIC architecture
1.2.1 On-Path設計
如圖3(a)所示,基于FPGA,NP-SoC,ASIC的智能網卡一般采用On-Path的設計架構,NP處理器核、FPGA、ASIC位于數據通路上,便于處理器直接對數據進行預定的處理.基于NP-SoC的智能網卡,如華為的IN系列、Cavium的LiquidIO系列、Netronome的Agilio系列,基于FPGA的智能網卡,如微軟Catapult系列、Mellanox Innova系列,基于ASIC的智能網卡(卸載網卡),如Mellanox的ConnectX系列、Cavium的FastLinQ系列,均屬于On-Path架構.當主機端服務器需要發送數據時,主機端處理器向網卡下達發送請求,一般包括具體的處理指令(如發送、原子操作等普通指令,或者用戶自定義的其他操作)和包地址,網卡中的DMA引擎從主機端內存中取出數據到網卡中的緩沖區,然后由核心處理單元(FPGA/ASIC/NP)進行對應的數據處理,處理完的數據再由發送端口發出.反之,當主機端服務器接收數據時,接收的數據經網卡緩沖區,直接由處理器核進行對應的數據處理,處理完成后通過DMA引擎將數據存入主機端對應的內存中.
On-Path架構的設計方式優點在于處理器可以直接對數據通路上的網絡數據進行處理,而使用該架構的處理器(FPGA/ASIC/NP)一般具有較高的并行度,可以提供低時延、高帶寬的服務;缺點則是,在編程靈活性和易用性方面不及基于GP-SoC的智能網卡.因此,On-Path架構在大多數普通需求的應用場景下能夠提供較好的性能,而在較為復雜的情況下,如Bare -Metal、以智能網卡為中心搭建加速平臺等情況[4,6]下,該架構的智能網卡則略顯遜色.
1.2.2 Off-Path設計
如圖3(b)所示,基于GP-SoC的智能網卡一般采用Off-Path的設計架構,GP處理器核與數據通路松耦合,位于網卡上的可編程交換部件根據預先設定的規則決定數據流的轉發對象是否為GP處理器核.基于GP-SoC的智能網卡,如Broadcom的Stingray系列、Mellanox的BlueField系列,均屬于Off-Path架構.當主機端服務器需要發送數據時,主機端處理器向網卡下達發送請求,一般包括具體的處理指令(如發送、原子操作等普通指令,或者用戶自定義的其他操作,包含網卡中交換機用于轉發的標志)和包地址,網卡中的DMA引擎從主機端內存中取出的數據經過網卡中交換機的轉發,或者流向通用網卡ASIC邏輯直接由發送端口發出,或者流向GP處理器核,由GP處理器核進行對應的處理,最終再由發送端口發出.反之,當主機端服務器接收數據時,數據先通過網卡ASIC,然后經網卡中交換機轉發,或者直接通過DMA引擎存入主機端對應的內存中,或者進入GP處理器核處理并根據處理結果進行后續操作.
Off-Path架構的設計方式優點有:1)數據通路與網卡處理器松耦合,對于無需特定處理的普通數據流可以直接旁路GP處理器;2)使用該架構的處理器一般具有較高的編程靈活性和易使用性,可以運行獨立的Linux操作系統,能夠應對復雜的應用場景.缺點則有:1)網卡上用于數據轉發的交換部件需要具備靈活的可編程性和高效的轉發能力,如果設計不合理將很有可能成為性能瓶頸,因而使用Off-Path架構的Mellanox BlueField和Broadcom Stingray分別研發了ASAP2(accelerated switching and packet processing)技術[63]和TruFlow技術[64]用于提高網卡交換部件的可編程性及轉發能力;2)使用該架構的GP處理器在處理并行性方面較差,相比于其他架構,對于固定模式的數據流處理性能略差.因此,Off-Path架構更適用于較為復雜的應用場景下,如Bare-Metal服務器、以智能網卡為中心的加速平臺等[4,6],可以充分利用GP的易用性和靈活性,而對于較為成熟的應用場景,如NFV卸載、網絡協議卸載等,則Off-Path架構并非最優選擇.
1.3 基礎架構小結
表1從智能網卡的核心處理器和數據通路架構2個維度,對智能網卡基礎架構部分內容進行總結,對比了不同基礎架構設計的特性.圖4以相關公司官網站發布的產品簡介和公開的論文為時間節點,從核心處理器和數據通路架構2個維度,列舉了近10年典型智能網卡相關設計成果.
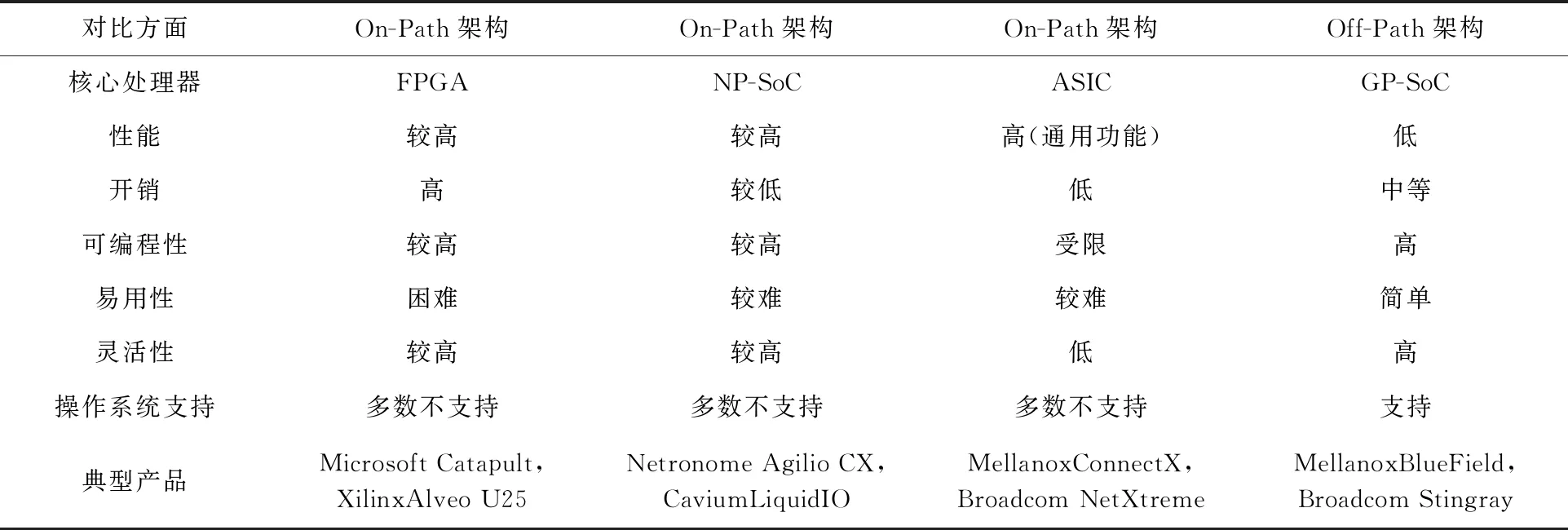
Table 1 The Comparison of Different SmartNIC Designs
從核心處理器分析,總體而言,目前,產業界對核心處理器的選擇仍眾說紛紜,基于FPGA的設計除了被Microsoft和Xilinx采用外,因FPGA產品逐漸成熟,并有Catapult作為設計框架參考而受到很多小公司青睞;而基于MP,ASIC的設計則需要較成熟的網絡技術積累,因而只有少數典型的網絡設備供應商推出對應的產品.從技術發展的角度分析,已經成熟的網卡卸載技術(如協議處理、特定加解密計算等)將被逐漸定制化到網卡ASIC芯片中;趨于成熟且需要一定編程靈活性的功能(如Match-Action操作)則使用NP處理可以獲得更高的性價比和易用性;對于涌現出來更為復雜的新需求(如Bare-Metal服務器)則需要GP來做更通用的處理.智能網卡的設計將根據應用的需求走向多元化、異構化,如Netronome Agilio系列網卡分為CX,FX,LX三大類產品,分別對應計算節點、Bare-Metal、服務器節點3種應用場景,其Agilio FX智能網卡中已集成了NetXtreme網卡控制器ASIC、NFP網絡處理器、ARM通用處理器3種處理器,是異構化的典型代表.

Fig. 4 SmartNIC milestone list
從數據路徑分析,On-Path架構更適合數據密集型應用場景,尤其適合傳輸路徑上的流式處理,這也與此架構對應的FPGA,ASIC,NP處理器特性相符合;Off-Path架構則更適合控制密集型應用場景,這也與此架構對應的GP處理器特性相符合.后文將對數據密集型和控制密集型的編程框架進行綜述.
2 智能網卡編程框架
智能網卡的處理器架構是設計智能網卡的硬件基礎,智能網卡的編程框架則是設計和使用智能網卡的軟件基礎,軟硬協同是設計智能網卡的重要方法.在此,將智能網卡的編程框架設計分為面向數據密集型和面向控制密集型兩大類設計,分別偏向于對數據流和控制流提供更友好的支持.
2.1 數據密集型
網絡帶寬發展迅速,正向著Tbps時代邁進,尤其是在云環境、虛擬化的情況下,出現了大量的應用需要對數據流進行模式固定、運算簡單的可編程操作,如防火墻、網關、深度包檢測等網絡功能,以及Hash計算等,我們稱這種計算相對簡單、模式固定、控制相對較少的應用為數據密集型應用.智能網卡作為一種可編程網絡終端設備,具備高效的I/O處理能力、內存讀寫能力、可觀的軟件處理開銷,是智能網卡設計的必然需求[2,7],而智能網卡編程框架是其中的重要一環.我們把智能網卡編程框架中,對數據密集型應用提供良好的編程支持和性能加速的編程框架,稱為數據密集型編程框架.
數據密集型智能網卡編程框架至少要具備3個特點:1)盡可能減少主機服務器在數據通路上對數據搬移的開銷;2)向用戶提供具備一定編程能力的接口,滿足可編程應用的需求;3)將軟件編程和硬件架構之間進行合理的映射,以實現對數據流進行高效的流水處理.
RDMA作為一種在高性能計算中常用的通信方式,近些年逐漸被廣泛應用到數據中心網絡中[65-70],使用RDMA通信可以旁路主機端操作系統、減少通信中數據拷貝的開銷,提供低延時、高帶寬的通信性能,是進行數據通路優化的一種重要方式.Mellanox的OFED[71]提供了標準的RDMA支持,Portals 4[72]也提供了類似RDMA的通信接口,FlexNIC[7]和sPIN[2]則在支持RDMA的基礎上對網卡進行了可編程功能的強化和流水處理的設計.此外,基于FPGA的ClickNP[21]和基于MP的Floem[73]也是典型的數據密集型智能網卡編程框架,后文將對以上提到的典型究進行介紹.
如圖5所示,FlexNIC[7]的設計繼承了RMT(reconfigurable match table)可編程交換機架構[38],對數據包的處理分為入口流水線和出口流水線2部分,每一部分都包含包解析、Match-Action(匹配包頭字段并執行對應的操作)、數據包整合3個處理階段,可編程的功能以Match-Action的形式映射到多核處理器中,對數據包中自定義的域進行流水處理,由于智能網卡需要與主機端進行數據交互,如圖5中左斜陰影部分所示,FlexNIC的設計中增加了DMA操作流水線和DMA引擎.FlexNIC使用P4[37]語言進行編程,并且增加了部分原語用于簡化編程.這種設計方法,對于簡單的操作,經過一次流水便可以完成處理;但是,對于復雜的操作,需要的Match-Action操作數量大于流水線中Match-Action單元總數n時,未處理完的數據包需要重新進入流水線進行新一輪流水處理,這樣將大大增加處理延時.
sPIN[2]的設計則是在Portals 4[72]的基礎上進行了數據通路的進一步優化和可編程功能的強化,充分利用了智能網卡片上內存和處理單元,在數據到達接收端網卡后,網卡直接向發送端返回響應,然后由網卡進行數據處理并搬移到對應的應用存儲空間,減少了接收端對數據包的響應時間,將RDMA的性能進一步提高.如圖6所示,sPIN將每個消息的多個數據包處理劃分為3部分,即包頭handler、負載handler、完成handler,由智能網卡上的1個或者多個邏輯處理單元(handler processing unit,HPU)進行流水處理,HPU可以映射到智能網卡的多核處理器上.在編程方面,為了方便對智能網卡進行管理和對3種handler進行編程處理,sPIN對Portals 4 編程接口進行了擴充,提出了P4sPIN編程接口,提供了智能網卡片上內存管理、HPU管理、handler處理的多種原語.
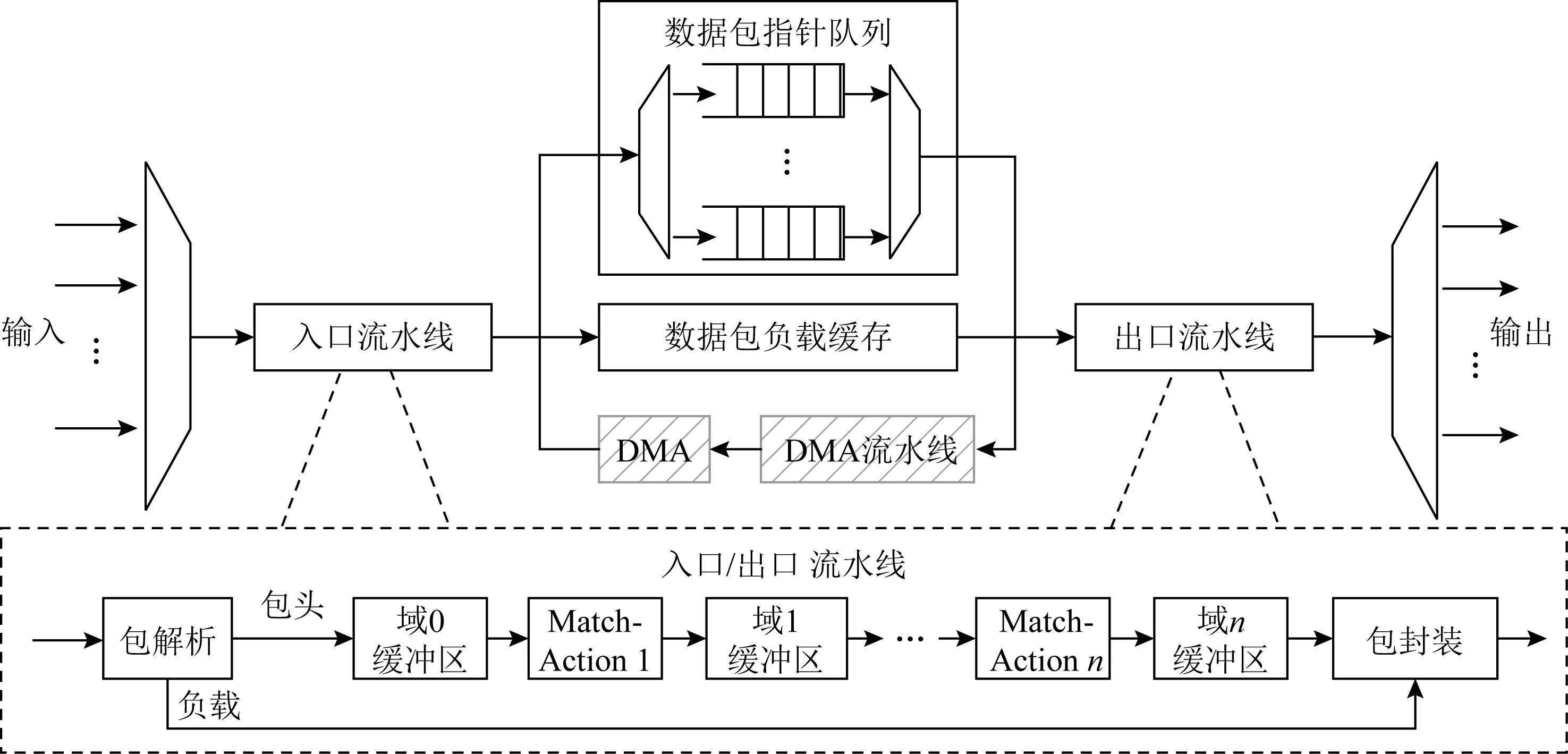
Fig. 5 FlexNIC (RMT-enhanced DMA architecture)

Fig. 6 sPIN SmartNIC network interface design
微軟針對基于FPGA的智能網卡——Catapult架構提出了ClickNP[21]編程框架,用于商用服務器中,以提供高性能的網絡功能,如防火墻、網關、負載均衡器等.ClickNP向用戶提供了類似C語言語法、面向對象的編程語言,并且提供了近100個處理單元(elements)庫,解決FPGA編程困難的問題,用戶將各個功能模塊以elements為對象進行編寫,如圖7所示,編寫的程序經過編譯器的預編譯后得到中間C文件,然后由FPGA廠商提供的后端編譯器和C編譯器分別對運行在FPGA和主機CPU的程序進行編譯處理,將不同的任務分配到FPGA和CPU中,達到FPGA與主機端CPU協同工作的效果.FPGA內部采用了模塊化設計,映射到FPGA的多個elements可以異步并行處理數據,類似于多核處理器,elements之間通過緩沖通道連接,而非共享內存.ClickNP的設計主要面向商用服務器中網絡功能加速的應用場景,在后續工作AccelNet[3]中,微軟使用智能網卡卸載了SDN協議棧,向虛擬機提供高效的SR-IOV功能,均是典型的數據密集型設計,對控制復雜的應用邏輯則并非最佳選擇.
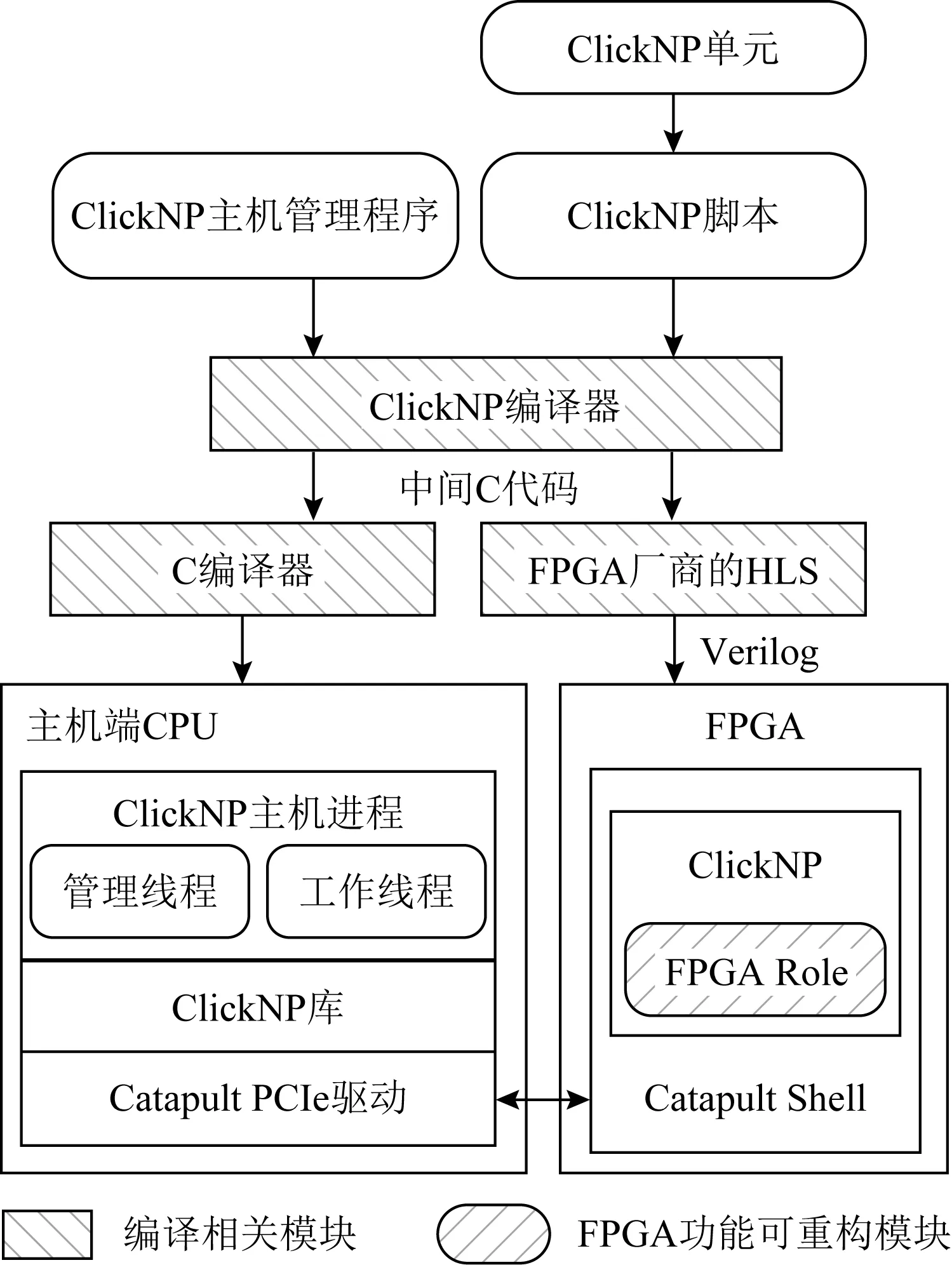
Fig. 7 ClickNP architecture(used in Catapult)
華盛頓大學研究團隊提出基于數據流的CPU-SmartNIC協同編程框架——Floem[73],運用類似于ClickNP模塊化設計的思想,將數據包模塊化處理邏輯組件——elements(C語言實現的Python類),映射到智能網卡的硬件資源上,并設計了通用的elements庫便于用戶編程,向用戶提供了編程語言、編譯器、運行時管理一整套技術支持.通過編程抽象用戶可以完成硬件資源訪問、邏輯映射、數據包元數據訪問、計算卸載、應用加速等操作,編譯器負責維護CPU和網卡之間的數據傳輸和緩存機制,運行時則負責DMA數據通路的優化.文中使用基于多核網絡處理器的智能網卡——Cavium LiquidIO作為硬件平臺,實現了鍵值存儲(key-value store, KVS)、分布式實時數據分析(real-time analytics, RTA)系統的智能網卡應用加速.
2.2 控制密集型
數據密集型智能網卡編程框架設計注重對數據流提供高效的數據通路和流水處理,與網絡功能、協議處理應用場景更加匹配;而控制密集型的編程框架則更注重對數據進行控制相對復雜的處理,卸載到智能網卡的計算模式一般相對簡單,通信模式并不固定,有一定的延時敏感要求,因此,控制密集型設計在調度策略、性能隔離、操作系統支持等方面更有優勢,與分布式應用、Bare-Metal場景更加匹配.控制密集型編程框架的典型設計有iPipe[13],NICA[74-75],INCA[76],λ-NIC[4].
鑒于actor[77-79]編程模型支持異構硬件、并行處理、獨立內存、動態遷移的特點,華盛頓大學研究團隊在actor編程模型的基礎上進行設計,提出面向多核SoC硬件平臺的iPipe[13]編程框架,iPipe的貢獻主要包括調度器、分布式內存抽象和安全隔離3個方面.iPipe的核心是將FCFS(first come first serve)和DRR(deficit round robin)調度策略進行結合的混合調度方案,用來協調調度CPU和智能網卡之間開銷不斷變化的執行任務,最大化智能網卡資源的利用率;分布式內存抽象是指各個actor之間不共享內存,每個actor擁有獨立的ID,actor可以進行靈活的遷移;安全隔離是指維護多個actor在智能網卡上可以并發執行、互不影響,并對意外狀況作出反應.由于靈活的調度策略和編程抽象,與Floem相比,iPipe更適合復雜邏輯的分布式應用加速,如RTA,KVS等,對于描述狀態簡單甚至stateless的網絡功能卸載,基于FPGA的設計更合適,文中實現了防火墻、網關、深度包檢測等網絡功能,其性能均不及ClickNP.
Mellanox研究團隊提出了基于FPGA智能網卡加速數據平面應用的軟硬件協同框架——NICA[74-75],并用于自身的Innova系列智能網卡,與微軟的ClickNP框架不同,NICA框架突破了基于FPGA智能網卡在支持操作系統、虛擬化方面的障礙, 適用于Bare-Metal、多租戶的應用場景.NICA通過新的ikernel(inline kernel)抽象,動態管理智能網卡上的一個或多個專用的硬件加速部件——AFUs(accelerator functional units)[80],同時,NICA集成了VMA內核旁路協議棧[81],實現了KVM hypervisor中AFU的虛擬化,滿足云環境下對網絡數據流進行靈活的自定義處理需求.其中,一個ikernel抽象即是一個OS對象,代表用戶程序中的一個AFU,對進程來說是私有的,可以保護AFU的應用和網絡狀態.AFU可以由用戶自定義,亦可以由云產商提供,根據需求部署,AFU支持I/O通道的虛擬化和細粒度的時分復用來實現NICA對虛擬化的支持.文中實現了KVS和IoT身份認證2種應用的加速.
在網計算的搶占式處理編程框架INCA[76]則在Portals 4的基礎上,實現了優于sPIN的在網計算處理模式,解決了sPIN流式處理中智能網卡的處理能力受計算復雜度(指令數量)、數據包速率、計算單元數量限制的問題.INCA以搶占式的觸發機制對智能網卡的計算資源進行更高效的調度,實現deadline-free的處理效果,即對每一個到達的包都能進行及時的處理,將已處理且未能完成處理的包的處理狀態保存并發往下一節點做后續處理,支持更加復雜的計算.此外,網絡空閑時,智能網卡中的包處理引擎(packet processing engine,PPE)可以用于非網絡數據的處理.
基于NP多核智能網卡的編程框架λ-NIC[4]則面向云計算模式中的serverless負載(諸多細粒度的定制化小程序,如Lambdas),在P4語言Match-Action編程抽象[37]的基礎上,設計了基于事件的Match-Lambda編程抽象,支持更加復雜的操作,數據包通過Match之后被發往主機端CPU或者智能網卡上對應的Lambda處理單元(NP核)進行處理.同時,該工作使用遠程過程調用(remote procedure calls,RPC)技術和RDMA技術加速通信,并對智能網卡存儲空間訪問和Lambda任務分配進行了優化,實現了數據隔離和性能隔離.
2.3 編程框架小結
根據數據密集型和控制密集型的分類,我們對編程框架面進行總結,得到表2.數據密集型和控制密集型的設計分別強調對數據流和控制流處理,數據密集型的設計在流水處理和并行度上表現更好,更適合模式較為簡單的應用,如網絡功能;控制密集型的設計則在靈活性、資源調度、性能隔離,以及面向Bare-Metal,Serverless的OS支持方面更好,更適合云計算、控制略顯復雜的分布式計算應用.2種編程框架的設計均有基于Portal 4,P4 Match-Action的研究,在硬件方面對多核和FPGA方式都有實現,但從性能上看,面向數據密集型的設計更適合FPGA,面向控制密集型的設計更適合多核架構.
根據以上工作的分析,我們發現編程框架的設計過程中需要注重5點:1)模塊化設計,如ClickNP,NICA均采用了模塊化設計思想;2)智能網卡與主機端CPU協同設計,這一點在基于Click包處理編程抽象[82]的許多編程框架中皆有體現,如Snap[83-84],NBA[85],ClickNP[21],UNO[86],在λ-NIC,INCA的設計中也有實現;3)良好性能隔離和虛擬化的支持,這一點成為了近些年研究中的一個熱點問題,如性能隔離在iPipe[13],NICA[74-75],λ-NIC[4],FairNIC[70]中皆有體現,對網絡虛擬化的研究也受到業內的重視,如AccelNet[3],Freeflow[68],MasQ[87]等;4)優化調度策略,提高智能網卡的資源利用效率,如PIEO[88],Loom[89],在包調度方面提供更加靈活高效的硬件支持,iPipe[13],λ-NIC[4],FairNIC[70]則在網卡資源方面進行更加合理的調度管理;5)簡潔的編程接口,兼顧易用性和靈活性,這一點在ClickNP,NICA,λ-NIC等工作中皆有體現.
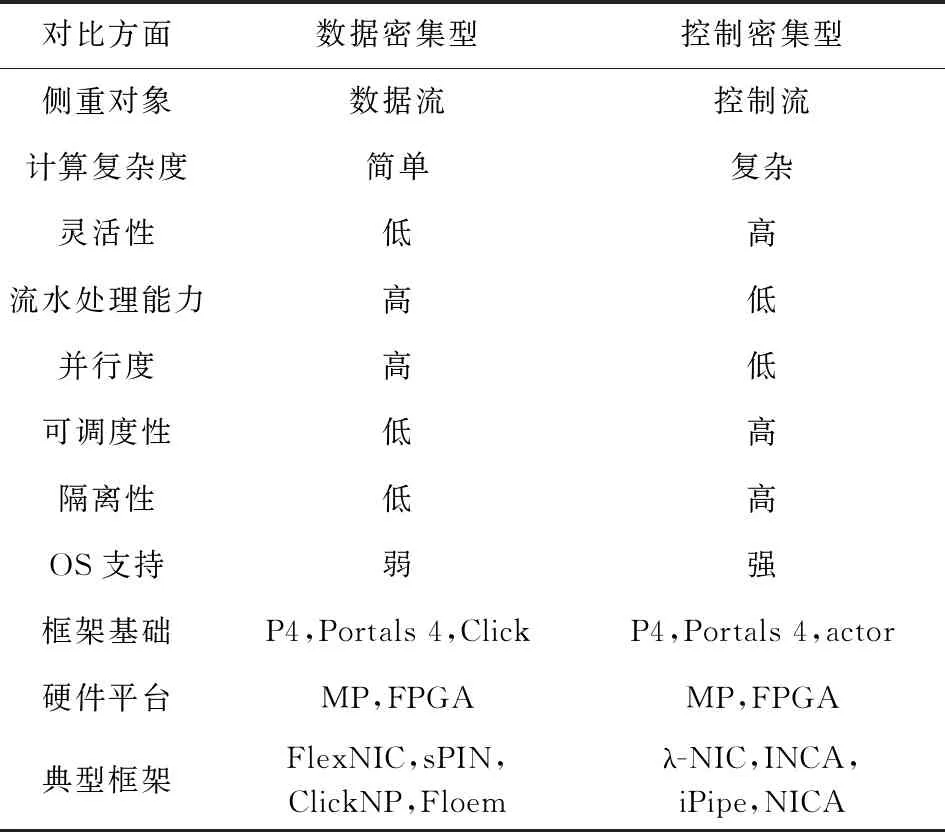
Table 2 Comparison of Different SmartNIC Programming Framework
3 應用方向
更快的網絡速率、更加復雜的處理場景、更高昂的網絡處理開銷催生了智能網卡,智能網卡作為一種應用驅動的產物,在眾多場景中得到應用.本節將從網絡協議處理、網絡功能、數據中心應用、科學計算應用4個方面介紹智能網卡的典型應用場景.
3.1 網絡協議處理
智能網卡作為一種具備一定編程能力的網卡,其最基礎的功能就是快速處理網絡協議,提供高效的網絡I/O.
在網絡協議種類方面,傳統的網卡多是僅支持一種網絡,標準的以太網,或者標準的Infiniband,或者自定義的網絡協議.部分智能網卡(如Mellanox網卡)則可以根據用戶設置,兼容以太網和Infini-band,除了傳統的TCP/IP協議,智能網卡大多支持RDMA協議或者其他加速數據通路的協議,如Portals 4,RoCE v1/v2,iWARP,在數據中心或者高性能計算機集群中提供低延時、高帶寬的網絡服務;智能網卡甚至支持存儲方面的協議,如NVMe-oF[53].此外,如Mellanox產品還支持MPLS(multi-protocol label switching)協議、GPU-Direct,迎合當下虛擬化、人工智能的應用場景.
在網絡協議處理方面,以微軟為例,早期的工作中已經將TCP/IP協議中模式固定、計算簡單的處理卸載到網卡,如TCP校驗(chueksum)、IPsec(Internet protocol security)的卸載[90];之后,逐漸有更多的網絡協議處理卸載到網卡上,如RSS卸載[91]、VMQ(virtual machine queues)卸載[92].近些年,為加速虛擬化的云場景的網絡處理,如NVGRE,VxLAN的處理也在網卡中得到卸載處理[93],進一步釋放主機端CPU.此外,智能網卡對多種加解密方法提供加速,如Stringray智能網卡,可以卸載Hash計算、SHA、MD5、PKA(public key accelerator)等.在學術界,不斷有智能網卡卸載網絡協議的新方式提出,如TriEC[94]對現有智能網卡卸載糾刪碼(erasure coding, EC)的方式進行了改善,提出3分圖式糾刪碼卸載模式.1RMA[95]則對現有RDMA網絡可靠連接高開銷的通信模式進行改善,提出Connection-free的網絡連接模式,同時通過軟件保證連接的可靠性,并且對安全方面提供了網卡卸載支持.
3.2 網絡功能卸載
網絡功能的作用是通過一系列方式對數據包進行檢測和修改,典型的網絡功能有防火墻(firewall)、網關(gateway)、入侵檢測(instruction detection system,IDS)、負載均衡器(load balancer)、域名服務(domain name service,DNS)等.微軟基于Catapult[19]硬件架構的ClickNP[21]編程模型一文中主要對卸載網絡功能進行了實現和評估,iPipe[13]中也對卸載網絡功能進行了實現和評估,文獻[14]則對DNS進行了卸載,從網絡功能的性能上看基于FPGA的ClickNP優于基于多核處理器的iPipe,可見,相比于數據中心中的其他復雜應用,邏輯相對簡單的網絡功能更適合流式處理的實現方法.
此外,智能網卡在卸載SDN協議棧、加速SR-IOV[3]、卸載NFV、卸載OVS[96]方面也有很好的應用場景,在微軟的AccelNet[3]工作中得到了充分的體現,NetBricks[97]也對NFV進行了卸載.在產業界,Mellanox則將加速OVS的ASAP2[63](accelerated switching and packet processing)技術應用到新一代的智能網卡產品中.
3.3 數據中心應用
智能網卡在數據中心應用的十分廣泛,在此總結為5類:
1) 卸載一致性協議.如對Paxos[98-99]一致性協議進行卸載,其中有在交換機端的卸載工作,如文獻[100]中使用P4交換機完成了Paxos一致性協議的卸載,也有在網卡端完成一致性協議的卸載,如文獻[14]中的P4xos、文獻[101]均在網卡上完成了一致性協議的卸載工作.
2) 卸載KVS相關的應用.如KV-Direct[11], Lake[12],加速分布式共享內存(distributed shared memory,DSM)[102-103],如FaRM[104],Grappa[105].在智能網卡軟硬件設計的相關研究中,如iPipe,Floem,FlexNIC,sPIN,NICA等,皆以KVS作為性能評測的重要指標,在商業智能網卡產品中,KV加速部件也已成為重要的組件.
3) 加速搜索引擎.在文獻[19-20]中,微軟加速了Bing搜索引擎業務,將吞吐提高了95%.
4) 加速人工智能應用.如Lynx[6],搭建了以智能網卡為中心來調度管理異構AI加速器的神經網絡訓練、推理加速平臺,將CPU從任務中釋放出來做其他事務的處理;而文獻[15-17]則把網絡設備作為一種神經網路加速器來使用,卸載神經網絡模型中的某些層甚至整個模型,數據在網絡傳輸中被計算,降低延時的同時減輕終端加速器的負載.
5) 提供虛擬化、云環境支持.如微軟在AccelNet[3]中加速SR-IOV、卸載OVS,Freeflow[68], MasQ[87]則對RDMA網絡進行了虛擬化,向多租戶提供接近物理網卡性能的虛擬RDMA接口.而FairNIC[70],PIEO[88],Loom[89],1RMA[95]則對云環境下的包調度、性能隔離和數據加密方面進行了研究.Pythia[106]則對RDMA數據安全性方面進行了側信道攻擊的嘗試,對網卡安全提出了更高的要求.
3.4 科學計算應用
智能網卡在科學計算中的應用首先表現在通信加速上,如利用RDMA的特性進行非連續數據通信的加速[5,18,107]、集合通信加速[108-110]、MPI加速[5,107,111-112].其次,智能網卡在科學計算的應用中也可以起到卸載計算的作用,如集合通信加速時Allreduce操作中的計算、MPI Tag-Matching[112]均可卸載到網卡處理.再者,針對科學計算應用中存在大量的矩陣計算的特點,在INCA[76]中,作者使用網卡進行了矩陣轉置、卷積、矩陣乘等與應用緊耦合的計算任務的卸載,可將高性能計算應用加速11%.
3.5 應用方向小結
智能網卡在分布式應用中幾乎無處不在.在傳統的網絡通信方面,智能網卡可以滿足RDMA,TCP/IP等協議下,基本的網絡數據傳輸甚至部分網絡協議的硬件卸載,在如今數據中心網絡虛擬化的大趨勢下,智能網卡可以提供網絡功能的卸載、SR-IOV的支持、虛擬交換機的卸載等,將部分CPU的資源從網絡處理中釋放出來.E3[113]研究表明,高效利用智能網卡中的低功耗處理器處理合適的數據中心任務可以將能效比提高3倍;在用戶應用方面,智能網卡在加速一致性協議、KVS相關應用、搜索引擎、分布式共享存儲、神經網絡等數據中心應用方面皆有優秀表現,在科學計算領域的集合通信加速、MPI加速、矩陣計算中也表現出重要價值.
相信在未來,依然會有各色的新應用驅動智能網卡向更強大的方向發展,如何適應新的應用需求將是智能網卡設計中的一個重要問題.在此,我們從應用場景的專用性和通用性2個方面做簡單的總結:1)專用性.智能網卡是應用驅動的產物,在應用相對固定的情況下,如網絡功能卸載、機器學習模型訓練、KV處理、特定算法的加解密,可以針對特定的一類或者幾類應用,做針對性的加速設計,如采用FPGA架構、ASIC的加速部件.2)通用性.在應用場景相對復雜的情況下,如云環境、多租戶場景,需要通用性強的智能網卡,可以采用基于網絡處理器、甚至通用處理器的多核架構,提供靈活性更友好的編程接口,滿足新應用場景下的可用性.
4 熱點問題
目前,在產業界和學術界中,涌現出各種智能網卡相關的熱點問題,在本節將分為架構及編程框架、應用、協議三大類進行介紹.
4.1 架構及編程框架探索
目前智能網卡的硬件架構主要分為三大類,分別是基于FPGA,MP,ASIC的設計,如1.3節中表1中所示各種架構在性能、成本、功耗上各有千秋.此外,近幾年,粗粒度可重構架構[114](coarse-grained reconfigurable architecture, CGRA)作為一種使用多個可重構單元解決領域專用的處理器設計方案,以優于FPGA 1~2倍的能效比、更接近ASIC的性能、優于FPGA的編程靈活性,得到業內的認可和關注.在智能網卡的設計中,ClickNP雖是基于FPGA的設計,但是其模塊化的設計與CGRA有異曲同工之妙;GP-SoC的多核設計思路成為部分廠家的選擇,但是GP的通用性和易用性在另一方面則限制了專用性和能效比;NP-SoC的設計更像CGRA,但CGRA具備更短的功能重構時間,支持配置流和數據流同時驅動.目前,CGRA的技術還不夠成熟,如何設計智能網卡中的可重構單元、如何建立可重構單元之間的拓撲關系(Mesh,Torus等)、是否增加其他處理器進行功能輔助、有異構處理器存在的情況下是否采用共享內存的設計、可重構單元之間使用類似于RMT[38]架構的流水處理還是類似于dRMT[115]的獨立處理,各種問題需要進一步的探索.
近5年,涌現出諸如ClickNP,Floem,FlexNIC,sPIN,NICA等多種出色的智能網卡編程框架[2,7,21,73-76],定制與硬件結構協同優化的編程框架、功能調度機制[13]、任務切分機制[21,82-86,116]十分重要,新的硬件架構需要配套的編程框架作為支撐方可最大化發揮智能網卡的通信、計算能力.
4.2 應用探索
如本文第3節所介紹,智能網卡在網絡協議處理、網絡功能卸載、數據中心應用、科學計算應用中均表現出強大的加速能力.可見,智能網卡正在逐漸將成熟的加速部件模塊化集成,同時,卸載的任務與用戶應用的關系越來越緊密,如今已有使用智能網卡卸載神經網絡模型的運算[15-17]、矩陣計算[76]的探索.在Bare-Metal和云環境中,智能網卡在提供虛擬化支持、性能保障、性能隔離等方向也將繼續發揮重要作用[3,70,74-75,87,89,117].而使用智能網卡為中心搭建加速器互聯平臺——Lynx[6]的探索更是讓人耳目一新,可見,智能網卡正在盡可能卸載更多力所能及的CPU處理任務,將CPU資源釋放出來用于處理控制邏輯更加復雜的任務.
4.3 協議接口探索
智能網卡的可編程特性使其在通信協議的處理上具備一定的靈活性,為滿足不同應用的需求,部分研究工作對已有的協議或者接口進行了拓展.sPIN[2]對 Portals 4[72]進行拓展,增加了智能網卡對加速通信和計算的支持;P4[37]則完全定義了以Match-Action為基礎的協議無關的可編程包處理模式;StRoM[118]則對RDMA語義進行了拓展,增加了網卡進行可編程處理的的支持,如設計了RDMA RPC verb用于支持對RPC的加速處理;RIMA[69]針對Infiniband協議中的共享接收隊列(shared receive queue, SRQ)造成的內存浪費問題,設計新的append queue verb及處理架構,在保證吞吐和時延的情況下實現了對SRQ的緩沖區更高效的管理;1RMA[95]則設計了Connection-free的連接模式,解決RDMA在數據中心中擴展性差的問題.在應用需求更加靈活的情況下,拓展更豐富的智能網卡協議接口,甚至是制定標準化的面向智能處理的通信協議也將成為可能.
5 智能網卡設計與測試
5.1 設計方法
基于第1~3節對智能網卡相關工作的認識和理解,我們總結出一種系統的智能網卡設計方法,主要由圖8所示的設計步驟組成:

Fig. 8 SmartNIC design method
1) 明確應用場景.智能網卡是一種典型的應用驅動產物,因此,確定欲設計的智能網卡使用的底層協議(以太網、Infiniband,或者其他自定義協議)、卸載應用的主要類型(數據密集型、控制密集型)、虛擬化的支持情況等,是進行架構設計之前必要的工作.
2) 明確智能網卡設計的基礎處理單元.根據明確的應用場景和成本預算,確定使用FPGA,ASIC,MP,還是CGRA 作為基礎處理單元.在應用場景相對固定的情況下,需要采用專用性強的設計,可以針對特定的一類或者幾類應用,做針對性的加速設計,可以優先考慮FPGA,ASIC,CGRA作為基礎處理單元;在應用場景相對復雜的情況下,如云環境、多租戶場景,需要采用通用性強的設計,可以優先考慮基于網絡處理器、甚至通用處理器的MP架構,提供靈活性更友好的編程接口,滿足復雜的應用場景.此外,可以考慮使用模塊化開發的思想,對智能網卡進行完全異構化的設計,比如通用處理器搭配卸載成熟應用的專用加速部件和處理器網絡協議的專用網絡控制器,這一步可以參考1.3節、3.5節、4.1節.
3) 明確數據通路架構.根據設定的的應用場景和選擇的基本處理單元選擇On-Path或者Off-Path的數據通路設計.一情況下,On-Path架構對應的基礎架構一般為FPGA,ASIC,NP,更適合數據密集型應用場景,可以對數據直接進行傳輸路徑上的流式處理;Off-Path架構對應的基礎架構一般為GP處理器,更適合控制密集型應用場景,可以對數據進行更為復雜的通用處理.這一步可以參考1.3節及2.3節.
4) 設計軟硬件協同編程框架.根據明確的應用場景、處理單元、數據通路設計編程框架,同時考慮編程框架的調度策略、資源使用效率、靈活性、易用性、可擴展性、虛擬化下的性能隔離以及智能網卡與CPU的協同工作問題,這一步可以參考2.3節表2.
5) 仿真驗證.對智能網卡進行軟硬件協同設計開發周期漫長,尤其是硬件開發更為繁瑣,確定合適的設計架構和設計參數是提高網卡設計效率的重要環節,因此,在設計的不同階段,通過適當的軟件模擬、硬件仿真驗證是解決部分設計問題的重要方式,然而目前通用模擬器GEM5,NS-3等在網卡仿真方面依然存在適用性、準確性等問題,需要開發者自行開發對應的模擬器來進行系統級的仿真實驗.
6) 對接應用.將智能網卡系統平臺與真實應用對接,優化應用、充分發揮智能網卡的性能特性,由于智能網卡的設計周期較長,面對新的應用場景,需要及時發現、總結、解決智能網卡的設計問題,迭代新的設計版本.
5.2 測試方法
該部分對智能網卡的測試分為3個階段進行介紹,涉及到開發階段的軟件仿真測試分析、硬件驗證測試分析和商業產品測試分析.
1) 模擬器模擬測試分析.很多軟硬件協同設計在具體設計方案以及相關參數確定之前需要進行細致的模擬分析,因此模擬器分析在芯片設計,尤其是復雜應用場景下的網絡設計中十分重要.在智能網卡的模擬器測試分析中,需要重點關注4個方面:① PCIe讀寫效率;②網卡SRAM,DRAM的開銷和使用效率;③調度情況是否達到預期;④在吞吐、延時、使用規模方面是否達到預期.目前,雖然有GEM5,NS-3等系統仿真工具或者網絡仿真工具,但是在網卡仿真,尤其是智能網卡仿真方面,沒有較成熟的網絡芯片微體系結構模擬器,進行細致的仿真需要很大的工程量,但是成熟的模擬測試分析會大大提高智能網卡的設計效率.
2) FPGA驗證測試分析.經過模擬分析、修正獲得相對成熟的設計框架和設計參數之后,進而可以使用FPGA進行RTL(register transfer level)驗證,以獲取更貼近真實設計的測試效果,FPGA開發、芯片后端驗證是一個復雜的過程,需要花費大量的人力和物力,并且需要相當的集成電路設計經驗.在此,不做詳細的介紹.
3) 智能網卡產品測評.對于商業智能網卡產品,可以從5個方面進行測評分析:①吞吐量、時延、線速處理能力,這3個方面是一個網絡產品的基礎性能指標;②支持的規模,如支持RDMA的智能網卡可以支持到多少QP連接;③卸載性能,對于相同應用的卸載場景,測試網卡資源使用效率情況、主機端CPU開銷占比情況;④編程接口的靈活性、編譯器的編譯效率,比如測試從用戶編寫的特定的智能網卡應用程序到網卡發揮卸載作用的配置時間(如Loom[89]中,測試了Mellanox ConnectX-4網卡配置QoS的時間)、對比使用純硬件語言編寫應用加速與使用編程接口經過編譯器編譯獲得的硬件綜合效果以及應用加速效果等;⑤核心處理器的處理能力,比如測試基于NP智能網卡的單核處理能力[13]、基于FPGA智能網卡的模塊間并行處理吞吐等.
6 總結展望
本文總結了自智能網卡興起之后相關的重要學術研究和產業界典型產品.對基礎架構設計進行了基本處理單元、數據通路2維分類,分析對比了不同基礎設計架構的優缺點;對編程框架進行了數據密集型和控制密集型分類,并結合基礎架構進行了對比分析;對智能網卡的重點應用方向進行了歸類總結;此外,本文指出了目前智能網卡相關的熱點研究問題.最終本文根據總結和分析,提出了一種系統的智能網卡設計思路和測試方法.
目前,基于不同基礎架構的智能網卡幾乎都有產業界的商業產品,其內部微架構的具體實現方法對外均是不透明的,至今,業內沒有較為一致的評價標準.因此,無論從學術角度還是產業發展的角度,對基礎架構的分析依然需要做很多細致的工作,通過不斷的架構探索、更加細粒度的測試來比較分析不同微架構實現智能網卡的詳細差異,對性能、能效比、應用場景展開細致的討論,提出可靠的數據分析,這對智能網卡的設計將產生重要的指導作用.此外,高效的軟硬件協同編程框架和不斷涌現出來的應用需求對智能網卡的系統化設計也提出了更高的要求,甚至,面向智能網卡的網絡協議、面向在網計算的智能化網絡處理模式也需要進行標準化的嘗試.
作者貢獻聲明:馬瀟瀟負責搜集、整理產業界和學術界的智能網卡研究工作,以及文章整體架構設計、撰寫和修改;楊帆負責智能網卡基礎架構部分的分類和特性分析,以及智能網卡軟硬件協同設計部分的指導;王展負責相關研究現狀的補充和未來研究熱點的指導;元國軍負責智能網卡應用場景相關內容的補充,尤其是智能網卡在機器學習中的應用;安學軍負責文章分類邏輯的調整、整體思路的指導,以及文章最后的總結.
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
