面向國產平臺的LLVM 自動向量化移植與優化
2022-01-14 03:02:12李嘉楠柴赟達
計算機工程 2022年1期
關鍵詞:指令
李嘉楠,韓 林,柴赟達
(1.鄭州大學信息工程學院,鄭州 450000;2.國家超級計算鄭州中心,鄭州 450000)
0 概述
高性能計算可用于開發解決全球性問題的科學應用程序,如疫苗研制、氣候建模等。如今,提高處理器的性能變得越來越重要,而電子器件的更新已不能滿足日益增長的計算需求,在此情況下,微型的向量并行部件SIMD(Single Instruction Multiple Data)擴展得到迅速發展,并被廣泛應用于各種科學計算類程序的加速優化任務。
基于SIMD 擴展部件的向量化已成為程序并行的重要手段,其向量寄存器和SIMD 指令是程序員以及處理器廠商的研究重點[1]。目前,ICC、GCC、LLVM(Low Level Virtual Machine)等編譯器已相繼支持了SIMD 的自動向量化編譯,面向SIMD 擴展部件的自動向量化編譯已逐漸成為程序向量化變換的主要方式。
LLVM 是對任意編程語言提供一種基于SSA(Static Single Assignment)[2]的靜態與動態編譯的現代編譯技術,與其他主流編譯器相比,LLVM 具有如下優勢:統一的IR(Intermediate Representation)與模塊化[3],能夠以庫的形式抽取其組件并用于其他領域;編譯器中的優化和分析被組織成遍(Pass)結構,通過不同遍完成不同的優化算法[4];開源License 的優勢使其被各大公司廣泛采用。在LLVM 編譯器中,已實現了循環級與基本塊級的自動向量化方法[5]。
申威系列處理器是我國自主研發、面向高性能計算的通用微處理器,該處理器主要針對計算密集型程序,如科學計算、數字信號分析、多媒體處理等。申威系列處理器包含豐富的向量運算指令和完善的向量重組指令,為程序的向量化提供了良好的硬件基礎。
LLVM 編譯器中自動向量化部分主要由Intel 團隊開發推進,算法以及向量指令的應用更適用于X86 平臺[6]。目前,LLVM 編譯器還未支持面向國產平臺的自動向量化。由于指令集的差別,申威處理器與X86 處理器的自動向量化實現方法有所不同,如AVX 指令集兼容256 位與128 位的向量長度,而國產處理器一般只支持單一的向量長度,導致向量化后生成不支持的向量類型,從而產生段錯誤、結果錯誤等問題。
本文針對申威1621 處理器平臺進行自動向量化移植研究,從循環級與基本塊級2 個方面提高自動向量化適配能力,以完善向量化所需的指令代價信息,并在精準代價模型的指導下生成后端支持的向量指令。同時,針對循環級向量化中控制流向量化進行算法改進,以解決后端不支持掩碼訪存指令的問題。
1 LLVM 自動向量化框架
1.1 循環級向量化
循環級向量化主要是在迭代間尋找并行機會以進行向量化,其主要流程如圖1 所示。
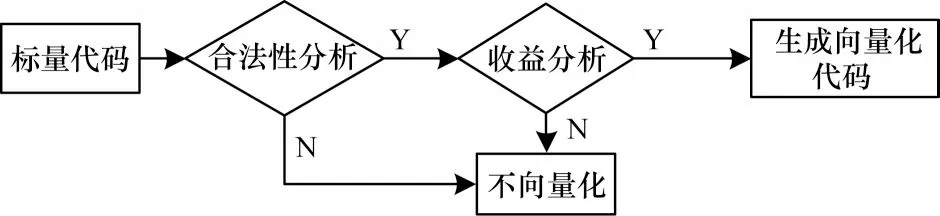
圖1 循環級向量化流程Fig.1 Procedure of cyclic vectorization
合法性分析步驟為:首先檢查是否為嵌套循環,排除不能向量化的循環形式,如多出口多回邊結構;然后對包含控制流的循環進行分析,收集分支掩碼以用于后續向量代碼生成[7];接著對phi 指令以及調用指令進行分析,判斷其是否符合向量化格式要求;最后調用循環訪存信息,分析訪存指令是否具有阻止向量化的依賴關系。依賴分析就是根據循環內的數據依賴關系構造語句依賴圖,在語句依賴圖上求解強連通分量,不具有強連通分量的語句就是可以進行向量執行的語句[8-9]。
通過調用代價模型,首先對基本塊中訪存指令進行分析,連續訪存可直接獲取指令代價,非連續訪存需要對比不同策略下的收益,選出訪存指令向量化的最佳執行方案[10-11];然后將該指令與基本塊內其他指令一起,以2 的整數冪在[2,IMaxVF]范圍內進行收益比較;最終將其與標量代價進行對比,選出最優的向量化因子。
向量代碼生成是在原始標量循環結構之前創建一個新的循環,使其成為向量指令的載體。標量循環中不同類型的指令分別調用不同的轉換函數以進行向量指令生成,最后將生成的向量指令逐一添加到新的循環中,更新支配關系,原始的標量循環將作為新向量循環的“標量尾循環”處理[12]。
1.2 基本塊級向量化
緊跟在循環級向量化后的是基本塊級向量化,其主要在基本塊內尋找同構語句以發掘并行機會。基本塊級向量化流程如圖2 所示。
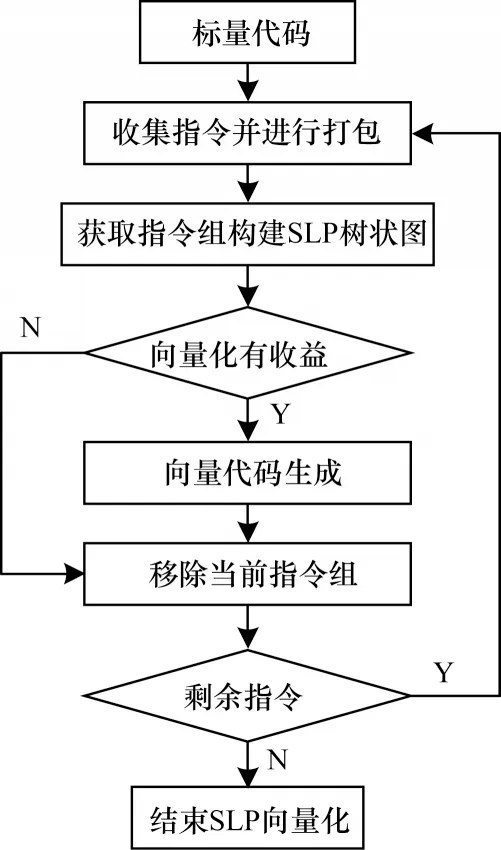
圖2 基本塊級向量化流程Fig.2 Procedure of basic-block level vectorization
在基本塊級向量化中,首先找到函數中所有的內存引用,收集指令并進行打包[13],包是一個同構語句的集合,將多個同構語句組成包的過程稱作打包,相反則稱為拆包[14];然后SLP 利用相鄰地址的存儲指令作為種子進行打包,通過“定義-使用鏈”和“使用-定義鏈”啟發式地擴展包[15],若循環中的每一個操作都可以被目標平臺以向量形式支持,則進行語法樹的代價分析,在有收益的情況下構建向量化樹,從上到下掃描基本塊的所有語句,在需要向量化的標量語句前插入向量語句,以完成向量代碼生成[16];最后移至下一組指令重復以上分析,直至完成基本塊內所有指令的向量發掘。
2 自動向量化移植
近年來,作為編譯優化領域的研究熱點,SIMD擴展部件不斷發展。申威系列處理器的SIMD 向量長度在持續增長,指令集功能也越來越豐富,因此,需要針對每一種處理器實現其自動向量化功能移植。移植主要包含自動向量化優化遍、后端相關轉換信息2 個方面。自動向量化可分為識別、優化、指令生成3 個部分。識別方法在循環級向量化與基本塊級向量化中通用,最重要的是考慮SIMD 部件差異與指令集特征,其中,寄存器信息、跨幅因子、基本指令代價的精確描述是自動向量化的基礎條件。另外,本文提出一種掩碼指令轉換方法,使得申威平臺支持包含控制流結構的向量化。
2.1 寄存器信息
完善SIMD 向量化的寄存器基礎信息包含RegisterInfo 文件中向量寄存器數量、特征信息以及TargetTransformInfo 文件中寄存器寬度描述,必要時數據類型長度也需要根據指令集信息進行修改[17],否則會生成后端不支持的向量長度或向量類型,增加后端指令降級工作從而導致向量代碼生成效率降低。
2.2 跨幅因子
跨幅因子即循環級向量化中的“Interleave Count”,為基本塊中單條語句的展開數,默認值為1。結合向量指令特征,將TargetTransformInfo 中最大跨幅因子設置為4,向量化階段調用代價模型從[1,4]范圍內分析出最佳跨幅因子,與原始默認值1 相比,提升了向量化性能。以TSVC(Test Suit for Vectorizing Compilers)測試集中的vpvts 函數為例,移植后進行收益分析,選擇出最佳跨幅因子為4,以此進行向量代碼的局部展開,相比原始向量化其性能提升了70%。
2.3 基本指令延遲信息
基本指令包含邏輯運算指令、類型轉換指令、比較指令、內建函數指令、訪存指令等。根據硬件提供的指令延遲表,在后端TargetTransformInfo 文件中對指令代價進行精確描述,包含數據類型、操作碼識別、指令延遲數補充。將后端不支持的向量指令代價調高,防止向量化后產生倒加速問題。對于復雜指令如混洗指令,結合后端指令降級中自定義的指令拆分組合情況進行精確描述。
X86 平臺支持128 位的向量寄存器[18],在自動向量化中最小向量化因子限制為2,但這在申威平臺不適用,原因是會造成數據處理過程中讀取錯誤信息,在程序運行時引發段錯誤。基于上述原因,本文分別在循環級向量化與基本塊級向量化中修改最小向量化因子。
2.4 掩碼內建指令
掩碼內建函數是對LLVM 基本指令集的補充,由特定目標平臺的特殊指令組合而成,但并不是所有目標架構指令集都具備全面的掩碼指令[18-19]。在申威平臺下進行SIMD 編譯時,自動向量化并不支持掩碼訪存指令,導致大量包含控制流的循環錯失向量化機會。在循環級向量化時將掩碼訪存指令替換為select 向量指令,可解決目標平臺不支持掩碼訪存指令的問題,核心轉換算法描述如算法1 所示。
算法1掩碼指令轉換算法

3 收益評估模型
循環或函數被向量化后的基本收益就是基本塊中減少的指令周期數,收益評估用于衡量向量化是否有利于提高程序效率[7]。自動向量化移植使得收益評估更加精準與完善,可以在收益評估的指導下判斷是否需要進行向量化以及如何進行向量化,從而生成最符合申威后端需求的向量或標量代碼。
3.1 面向循環級向量化的收益評估
循環級向量化收益分析流程如圖3 所示。
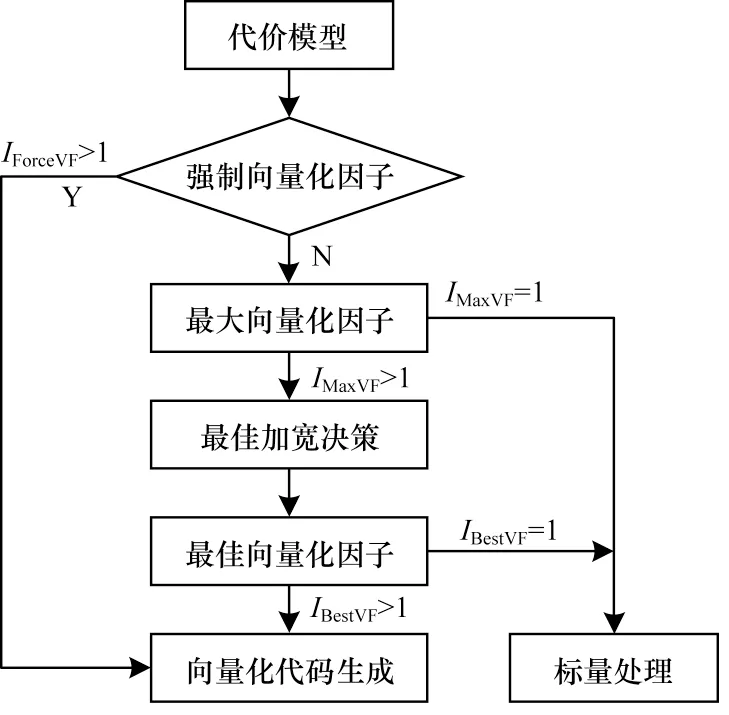
圖3 循環級向量化收益分析流程Fig.3 Procedure of cost analysis in cyclic vectorization
收益分析主要集中在2 個部分:針對訪存指令的最佳加寬決策;針對循環基本塊的最佳向量化因子選擇。具體步驟如下:
1)計算可行的最大向量化因子IMaxVF,獲取后端向量寄存器長度DWidthRegister以及數據寬度DWidthType信息,對于只支持單一向量長度的后端:
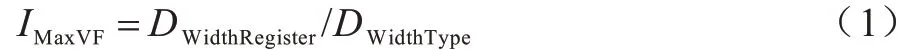
2)訪存指令對程序的向量化或性能提升起決定性作用,對于訪存指令,循環級向量化具有專屬的決策分析以求得最大收益。對于連續訪存代價,直接從后端指令延遲表獲取;對于不連續訪存,比較跨幅訪存、聚合訪存、標量化訪存3 種方案下的收益以選取最佳方案進行執行。
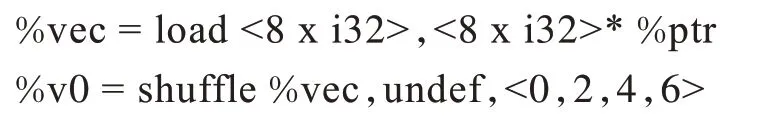
額外代價來源于從<8 x i32>向量中的0、2、4、6 位抽取數據并插入到<4 x i32>向量過程中的插入抽取指令,設GGroupNums為跨幅訪存組指令數量,其額外代價為:
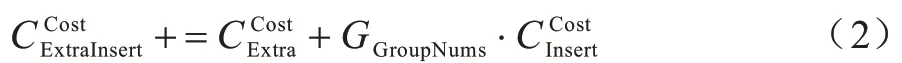
跨幅store 指令是從子向量中提取所有元素,并將它們插入到目的向量中,例如:
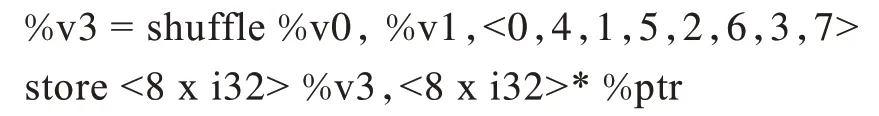
額外代價來源于從2 個<4 x i32>向量中抽取8 個元素插入到<8 x i32>向量過程中的插入抽取指令代價,設跨步為SSteps,其額外代價為:
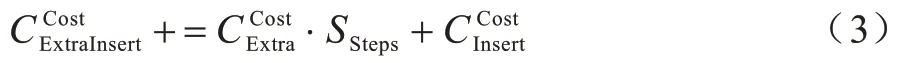
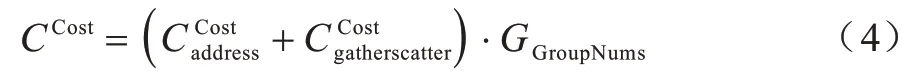
(3)標量化訪存代價首先獲取標量存儲指令和地址計算:

包含控制流的循環屬于不連續訪存,掩碼指令轉換算法將包含控制流的循環進行select 指令轉換,改變包含控制流訪存收益分析的計算方式,如下:

在更新包含控制流的代價計算后,根據基本塊執行的概率來擴展代價[20],循環級向量化認為每個基本塊執行的概率均為50%,因此,分支基本塊的代價為CCost=CCost/2。
3)將循環中所有指令進行累加,對比以上3 種不連續訪存的收益,選擇最優收益方案進行下一步向量因子的收益分析。
最后對比標量與向量形式下的收益,選擇進行向量代碼生成或保持原有的標量執行。
3.2 面向基本塊級向量化的收益評估
SLP 向量化收益開銷計算算法以抽象語法樹為基礎,滿足E≥VVF條件后以存儲指令為根節點遍歷樹形結構,通過“使用-定義鏈”自下而上進行打包,其中,每個節點都包含可并行處理且數目相同的同構語句[21-22]。
代價模型獲取寄存器信息計算向量化所需的同構語句數,根據指令代價選擇收益最大的進行向量化。首先確定同構語句長度(即同構語句數量)與向量化因子:設同構語句長度為E,向量化因子為VVF(設向量寄存器長度為256 位,標量元素double 為64 bit,則向量化因子VVF等于4)。假設標量指令代價為Si,向量指令代價為VCost,則每條向量指令的收益為:

該基本塊向量的收益總和為:

考慮寄存器溢出與指令重組對向量化性能存在影響,因此,自底向上遍歷語法樹以計算額外開銷,其值在理想狀態下為0,則總體收益為:

另外一些計算如標量的規約計算、向量化指針指令的索引計算,沒有被基于同構store 組的自底向上的遍歷過程所捕獲,因為它們不包含這樣的存儲指令,此類收益分析需考慮插入/抽取指令以及索引信息的代價(從后端相關指令延遲表中獲取,默認值為0),則總體收益為:

4 測試分析
本文采用申威1621 處理器為測試平臺,進行LLVM 編譯器自動向量化移植功能測試,編譯器版本為7.0。分別采用SPEC2006 與TSVC 測試集以及向量化應用測試,從正確性與向量化性能2 個方面進行對比分析。
4.1 功能測試與分析
SPEC2006 標準測試集是SPEC 組織推出的CPU 子系統評估軟件。為驗證本文方法改進下編譯器的健壯性,對SPEC2006 標準測試集中的29 道題進行測試,結果如表1 所示。
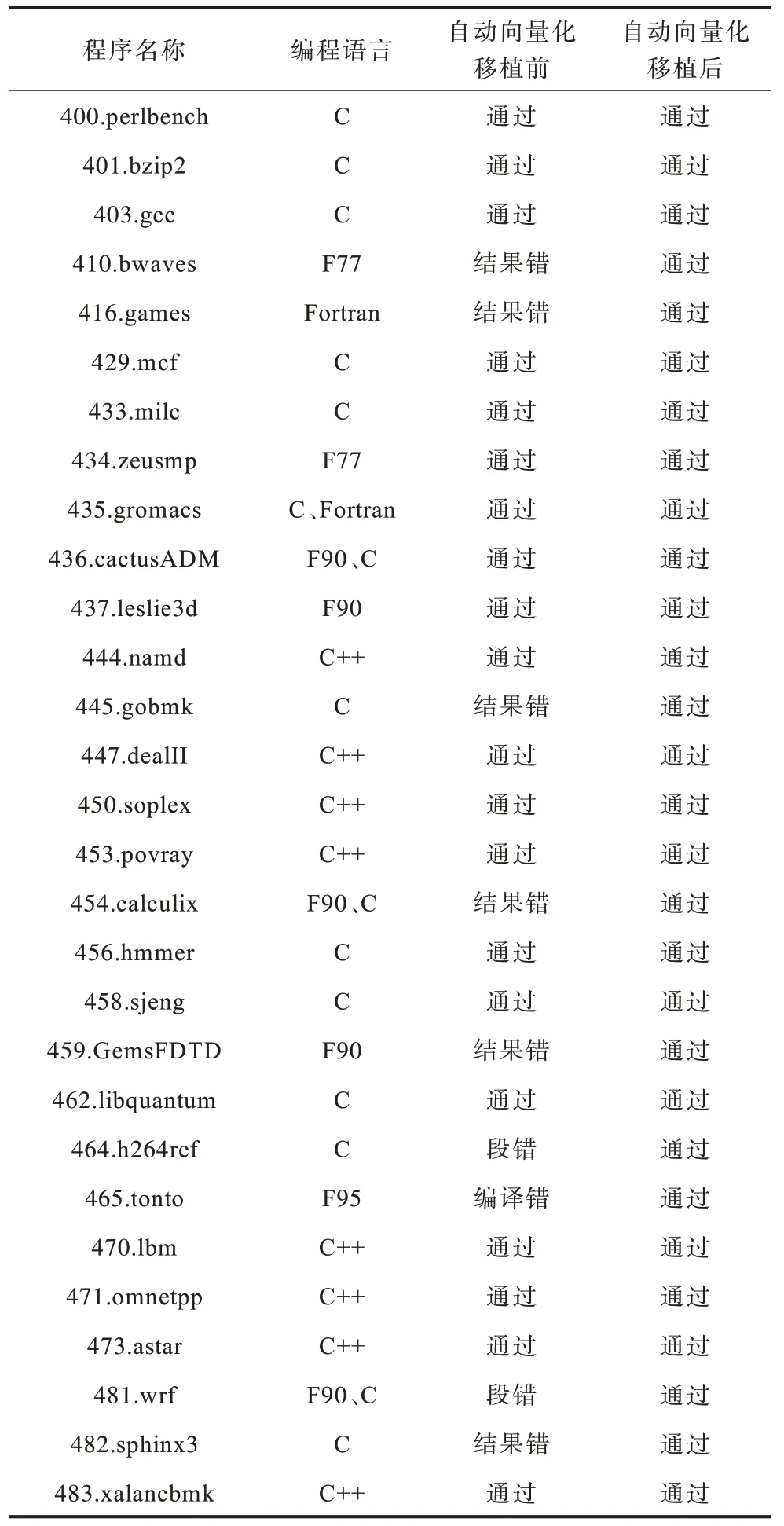
表1 SPEC 測試結果Table 1 SPEC test results
移植前中間表示代碼在自動向量化階段生成了后端不支持的向量類型,在后端指令降級過程中找不到匹配的降級方法與指令模板,導致測試題出現段錯誤以及結果錯誤的問題。從表1 可以看出,移植優化后410、416、454 等測試題依靠后端信息的精準描述以及收益分析的正確引導,向量化程序在test、train、ref 規模下正確運行。
4.2 精準代價指導下的測試分析
基本運算指令代價的精準描述,可以使得自動向量化做出符合后端要求的向量化決策,生成簡潔高效的向量匯編指令。本文采用TSVC 測試集中的典型例題,對比移植優化前后的加速性能,結果如圖4 所示,從圖4 可以看出,相對移植前,移植優化后平均加速比提升42%。
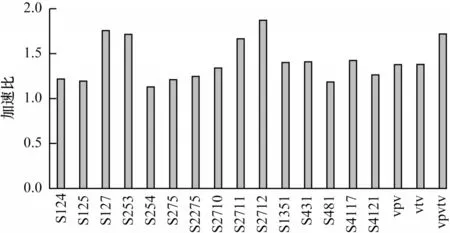
圖4 精準代價指導下的加速性能Fig.4 Accelerated performance under precise cost guidance
當后端對不支持的向量指令進行降級處理時,會生成冗余標量指令導致倒加速。精準代價模型指導下的自動向量化可排除后端不支持的向量類型,防止向量化倒加速產生。從圖5 可以看出,使用精準代價指導后,選擇與后端匹配的向量化因子以及向量化方法,可以使倒加速情況得到明顯改善,在原有移植的基礎上平均加速比提升28%。
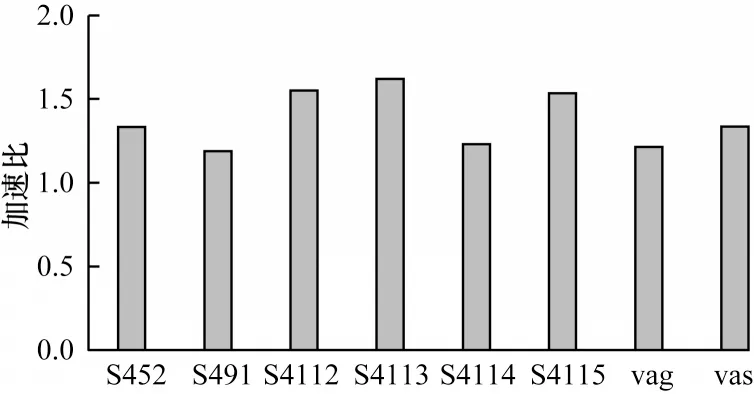
圖5 精準代價指導下的倒加速改善結果Fig.5 Reverse acceleration improvement results under precise cost guidance
4.3 性能測試與分析
本文分別采用SPEC CPU2006 測試題、TSVC 測試集以及被廣泛應用的矩陣運算測試題進行性能測試。
4.3.1 SPEC 測試分析
本次實驗對SPEC 測試集的29 道題進行性能測試分析,編譯優化選擇-O3-static,ref 規模,單進程運行。選取代表性測試題進行分析,對比X86 平臺與國產平臺的向量化能力,從而驗證移植的有效性。測試結果如圖6 所示,其中,X86 選用與申威SIMD長度相同的AVX 指令集。
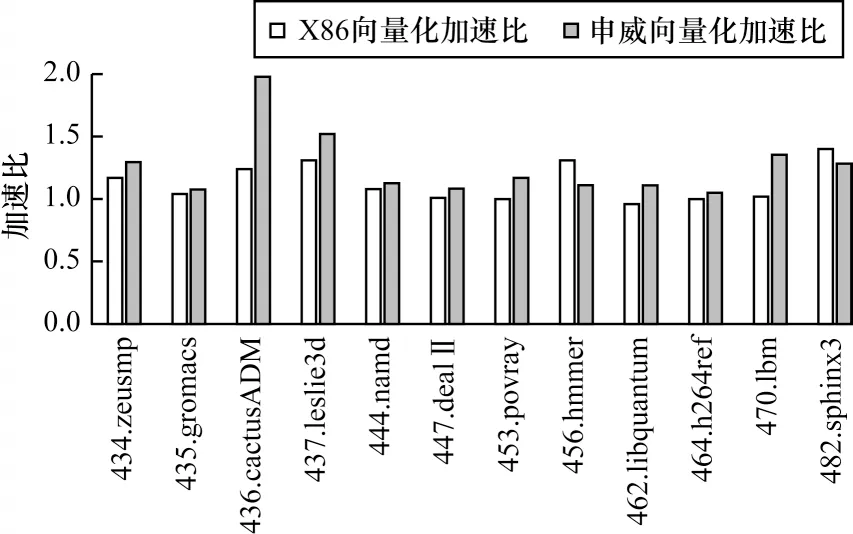
圖6 SPEC 測試分析結果Fig.6 SPEC test analysis results
前端將測試題解析為中間表示代碼,自動向量化在此基礎上進行向量代碼優化生成,然后由后端進行降級處理,生成特定指令集的匯編碼。從圖6 可以看出,移植優化后的向量代碼簡潔高效且符合后端指令集特征需求,移植后SPEC 整體性能提升10.8%,國產平臺的向量化能力優于X86,其中,436 加速效果最為明顯,提升了97%,437 加速比提升52%,434、470、482 加速比平均提升21%。由于指令集存在差異,國產處理器不支持一些特殊的向量指令,導致其對456 與482 的加速性能低于X86。
4.3.2 TSVC 測試分析
TSVC 測試集主要用來對編譯器的自動向量化能力進行性能測試,本文采用TSVC 測試集對比移植優化前后的加速性能,測試結果表明,移植優化后整體加速比提升16%。對掩碼內建指令進行相關修改,可以使得后端兼容原本不支持的向量化實現方法,從而充分利用申威后端的向量指令。從圖7 可以看出,在控制流優化下,循環識別率提升48%,平均加速比提升51%。
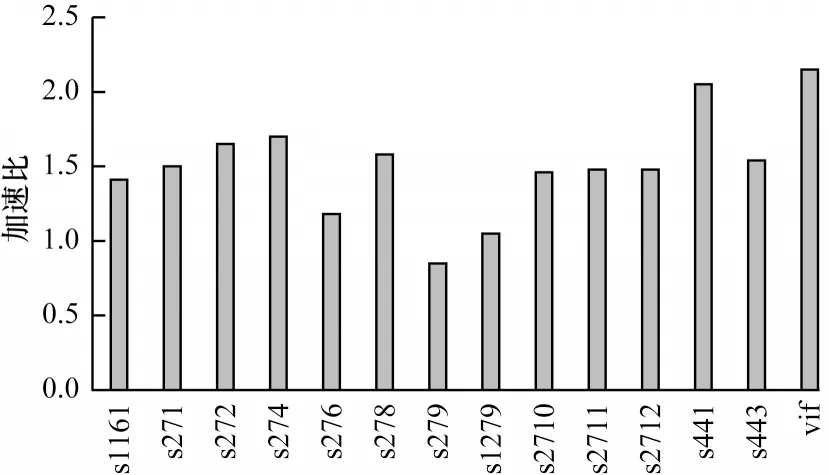
圖7 控制流優化下的加速比結果Fig.7 Acceleration ratio results under control flow optimization
4.3.3 應用測試分析
快速傅立葉變換被廣泛應用于信號分析任務,其性能提升離不開矩陣運算優化,另外,圖形處理、游戲開發、科學計算中包含了大量的矩陣運算,因此,本次實驗以矩陣乘為代表,進行應用程序測試分析。實驗采用3 層循環,以3 種N×N規模的矩陣進行測試,每個規模運行3 次并取平均值,以對比移植優化前后的運算性能,結果如圖8 所示。從圖8 可以看出,矩陣乘運算總體性能提升了72%,矩陣規模為1 024×1 024、2 048×2 048、4 096×4 096 時,加速比分別提升了77%、79%、59%。矩陣乘性能收益主要來源于合適的跨幅因子與向量化因子,其能夠最大程度地發揮SIMD 向量指令的優勢。
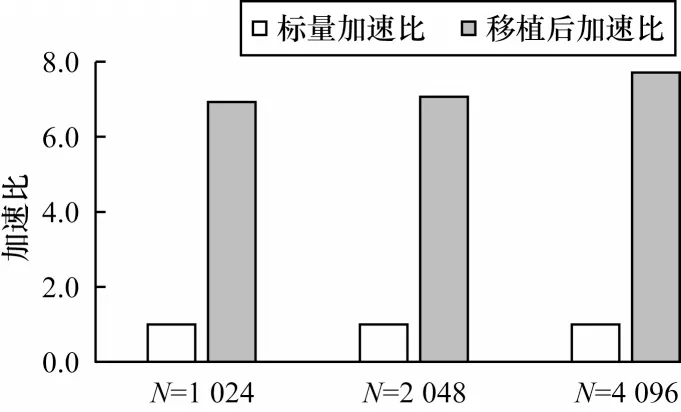
圖8 矩陣乘運算性能分析Fig.8 Performance analysis of matrix multiplication operation
5 結束語
本文針對申威1621 處理器進行LLVM 自動向量化功能移植,以解決自動向量化過程中后端信息不匹配和向量化實現方法不兼容的問題。實驗結果表明,移植優化后不再生成后端不支持的向量類型以及不合法的向量指令,控制流向量化程度顯著提升,在TSVC 測試集中,相對自動向量化移植前,移植優化后平均加速比提升16%。通過對自動向量化移植進行研究可以看出,在申威后端存在不支持某些相對重要的向量指令的情況,這將嚴重影響向量化的效果。因此,下一步將綜合考慮申威指令集與自動向量化后代碼生成的關系,將申威指令集中的基本向量指令進行拼接與重組,從而提高向量指令的適用性。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
