基于改進圖節點的圖神經網絡多跳閱讀理解研究
2022-01-14 03:02:02歐陽智杜逆索
計算機工程 2022年1期
舒 沖,歐陽智,杜逆索,,何 慶,魏 琴
(1.貴州大學計算機科學與技術學院,貴陽 550025;2.貴州大學貴州省大數據產業發展應用研究院,貴陽 550025)
0 概述
隨著深度學習技術的不斷發展,機器閱讀理解(Machine Reading Comprehension,MRC)成為自然語言處理領域的熱門研究課題,受到了越來越多的關注。機器閱讀理解需要根據給定的上下文來回答與其相關聯的問題,因此要求模型既要理解上下文的語義語境等信息,又要能夠識別出哪些信息與問題相關,從而進行最終的問題推斷。早期的機器閱讀理解工作[1-3]主要針對的問題是答案在單個段落的單個句子或多個句子中。然而,在實際應用中大量問題的答案不能僅由單個段落進行推斷,而應由多個段落進行整合后回答。因此,多段落閱讀理解的研究開始受到廣泛關注。
多段落推理的傳統方法主要是單獨對每個段落進行答案抽取,最終輸出可能性最大的答案。CHEN 等[4]基于Wikipedia,采用文章檢索模塊提取與問題相關的文章并切分成為段落,再利用文章閱讀模塊從提取文章的每個段落中進行答案搜索。CLARK 等[5]從文檔中抽取多個段落,分別計算每一個段落的置信度分數,選擇置信度分數最高的段落,從中進行答案提取,在多個數據集中取得了不錯的效果。萬靜等[6]提出多段落排序BiDAF(PR-BiDAF)模型,通過對多個段落與問題之間進行相關度匹配,選取相關度最高的段落進行答案提取。然而,這些方法都只是將段落看成單獨的個體,忽視了段落與段落間的關聯,無法得到段落間更復雜的信息。
針對多段落之間的信息交互問題,還需要一種可以更好地獲取段落與段落之間交互信息的方法,以實現多跳信息連接。吳睿智等[7-8]通過實驗證明圖神經網絡可以很好地運用在自然語言處理任務中,并且能夠有效提升網絡性能。針對多跳問題,基于圖神經網絡的相關研究[9-11]主要通過構建實體圖來聚合信息實現多跳閱讀理解。實體圖一般由多個節點以及節點之間相連的邊所構成,而節點的選取則是模型取得優良效果的關鍵。CHEN 等[12]通過抽取支撐文檔中的句子構建多條推理鏈,將支撐文檔中的句子作為圖中的節點,通過聚合句子中的相關信息進行問題推理回答。TU 等[13]抽取問題中的實體與候選詞在文章中對應的實體以及每個支撐文檔作為圖的節點,構建包含多種節點與邊關系的異質文檔實體圖(HDE),在實體圖中聚合多粒度信息實現節點信息傳遞進行答案推理。然而,聚合多種信息往往會導致實體圖中信息量過多,使得模型容易受到不相關信息的干擾。DE CAO 等[10]僅將在支撐文檔中出現過的候選詞作為實體,建立實體關系圖并通過候選詞節點之間的信息傳遞進行問題推理。CAO 等[14]在文獻[10]的基礎上引入雙向注意力機制用于問題與候選詞節點之間的雙向信息交互,生成問題感知節點表示用于最終結果推斷。這些方法相對提取的實體種類更少,雖然效率較高,但也會導致實體圖在初始階段缺乏關鍵信息,或是所得到的信息量不足,使得模型在推理過程中無法得到正確的結果。
現有研究在實體提取方面大多數基于簡單的字符串匹配來查找文中的相關實體,這樣會使不少隱含在文中的實體無法被提取出來,導致相關信息的缺失。此外,已有模型很少關注疑問實體與候選詞實體之間的信息交互,而通常疑問實體所在的支撐文檔包含的信息量會遠遠大于其他文檔,提取該支撐文檔中出現的所有疑問實體作為新的節點類型加入到實體圖中,可以使得實體圖中包含更多與問題相關聯的信息,從而使得模型可以更加準確有效地得到最終的推斷結果。
本文提出基于改進圖節點的圖神經網絡多跳閱讀理解模型。首先,采用基于指代詞的實體提取方法進行實體提取,增加更多的相關節點參與到實體圖中進行信息傳遞。然后,將疑問實體作為實體圖中新的節點類型,參與到圖卷積操作中豐富節點的種類。對于不能直接與候選詞節點相連的疑問實體,提取出疑問實體所在支撐文檔中的所有實體,將這些實體經過篩選后,作為疑問實體關聯實體參與到實體圖中進行信息傳遞。通過將疑問實體、關聯實體與候選詞實體相連使得疑問實體間接與候選詞實體相連。最后,對實體圖中的節點進行圖卷積操作,計算圖卷積網絡(Graph Convolutional Network,GCN)輸出結果與問題的雙向注意力,并通過與其他模型的對比實驗驗證本文模型的有效性。
1 本文模型
本文提出的基于改進圖節點的圖神經網絡多跳閱讀理解模型如圖1 所示,主要包括實體圖構建模塊、上下文語義信息嵌入模塊、GCN 推理模塊、信息交互模塊、預測模塊等5 個模塊。
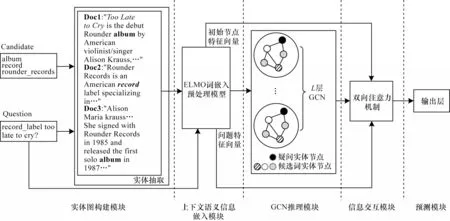
圖1 基于改進圖節點的圖神經網絡多跳閱讀理解模型框架Fig.1 Framework of multi-hop reading comprehension model based on graph neural network with improved graph nodes
1.1 實體圖構建模塊
1.1.1 基于指代詞的實體提取方法
傳統字符串匹配提取實體的方法在實際提取實體的過程中,會導致大量相關實體的缺失。例如,英文人名中可能將名稱簡寫或者是使用別名等,如問題句“participant of juan rossell”,其 中“juan rossell”為疑問實體,但是在支撐文檔中,“juan rossell”對應的全名是“Juan Miguel Rossell Milanes”,如果此時采用傳統的字符串匹配方法直接進行字符串匹配,那么將無法提取到這些實體或者遺失掉某些實體其他支撐文檔中的對應實體。因此本文針對這一問題,提出基于指代詞的實體提取方法,該方法從支撐文檔中提取出更多的相關實體,增加更多相關實體節點參與實體圖中進行信息交互,使得實體圖可以包含更多的信息量,有利于最終的問題推斷。
1.1.2 基于問題關聯實體的實體圖構建
通過基于指代詞的實體提取方法獲得在文章中所出現的候選詞節點與疑問實體節點,再用提取出的節點構建實體圖,如圖2 所示。然而,在實際構建實體圖的過程中,由于不是每個疑問實體都能與候選詞實體相連,導致疑問實體不能參與到最終的圖卷積網絡中,使得實體圖中缺乏包含問題的關鍵信息。對于不能與候選詞實體相連的疑問實體,提取出該疑問實體所在支撐文檔中的所有實體,經過篩選后作為疑問實體關聯實體參與實體圖的構建。通過加入新的節點類型使得疑問實體節點與候選詞節點間接相連,從而使疑問實體節點中的信息在實體圖中進行信息傳遞,最終得到的實體圖如圖3 所示。
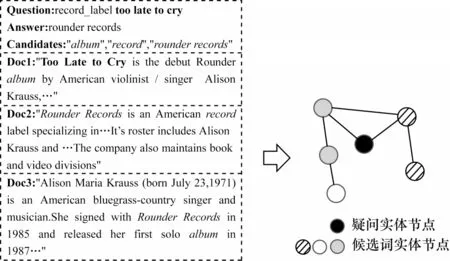
圖2 WikiHop 樣本實體圖構建Fig.2 Construction of WikiHop sample entity graph
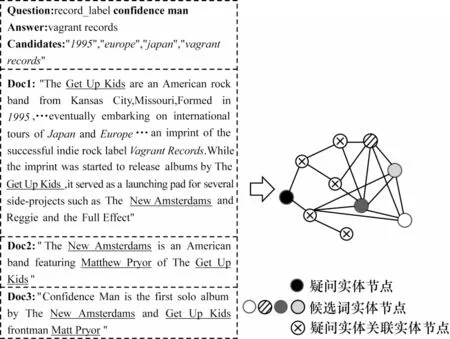
圖3 基于問題關聯實體的實體圖構建Fig.3 Construction of entity graph based on problem-related entities
實體圖中邊的定義如下:1)出現在同一支撐文檔中的實體相連;2)出現在不同文檔中,屬于同一個實體的節點相連。值得注意的是,這些邊都是無向邊,沒有在邊上賦予特殊的權值。通過構建實體關系圖,將支撐文檔的上下文語義信息轉換成圖關系節點。最終得到N個節點{Ni},1≤i≤N,這些節點都是通過上述邊的定義方式來進行連接。
1.2 上下文語義信息嵌入模塊
通過使用ELMO 詞嵌入預處理模型[15]對提取到的候選詞實體、疑問實體、疑問實體關聯實體進行編碼,得到這些實體節點與上下文語義相關的信息,從而將支撐文檔中所包含的信息轉化成文檔中各個實體節點的信息。此外,ELMO 模型還可以根據上下文特征動態地調整詞嵌入,能夠有效地解決大規模文本數據集下一詞多義的現象。由于每個實體節點中可能包含的單詞數量不止一個,因此對每個節點中所包含的單詞向量都進行最大池化與平均池化操作,再將獲得的特征向量進行拼接,得到最終的每個節點信息表示向量,如式(1)所示:

其中:dnode表示節點最終的特征向量;dmax-pool表示經過最大池化操作后的節點特征向量;dmean-pool表示經過平均池化操作后的節點特征向量。
1.3 GCN 推理模塊
通過將經過上下文語義信息嵌入模塊編碼后的特征向量輸入至圖神經網絡中,得到圖中節點的原始向量。由于每個節點都會與多個節點相連,因此要求節點有選擇性地獲取相鄰節點的信息,在進行信息傳遞時可以在實體圖中傳遞最為相關的信息,模型采用門機制的圖卷積網絡(G-GCN)來進行推理操作。
在圖神經網絡中,節點之間的信息按照式(2)進行傳遞:

在各個節點進行信息傳遞后,使用Sigmoid 激活函數對各個節點進行激活,如式(3)所示:
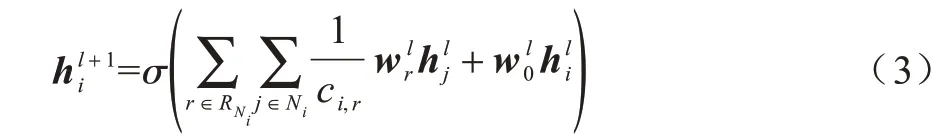
門機制使得節點在獲取其鄰居信息時更有選擇性,通過式(4)計算得到門更新單元,再把門更新單元代入式(5)可以得到使用門機制后的關系權重矩陣:
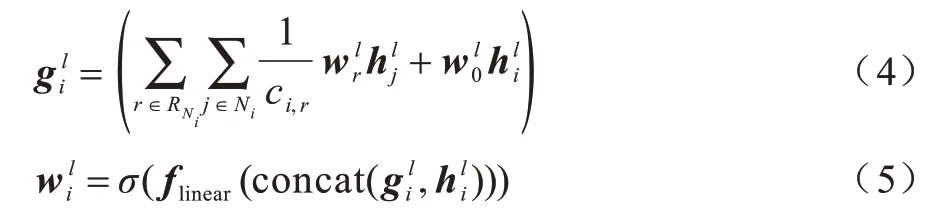
其中:flinear表示向量經過一層全連接層后進行線性轉換;表示門更新單元,用于更新同一個節點在圖神經網絡中下一層隱藏層的權重矩陣。
基于門機制的GCN 節點信息傳遞如式(6)所示,因此在經過門更新單元處理后,得到最終的節點隱藏層狀態。
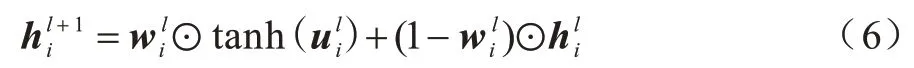
其中:⊙表示矩陣對應元素相乘。
在L層的圖卷積網絡中所有的參數都是共享的,每個節點的信息都會經過L個節點的傳播,從而使節點完成L次跳躍的推理過程,并獲得這L次跳躍后的節點信息關系表示。
1.4 信息交互模塊
模型通過在問題與節點的信息交互上使用雙向注意力機制,可以更好地獲取節點與問題之間更多相互有關聯的信息,最大限度地豐富模型最終輸出向量的信息量。CAO 等[14]在BAG 模型中引入了雙向注意力機制,取得了不錯的實驗效果,證明了雙向注意力機制可以很好地運用在圖神經網絡中節點與問題之間的信息交互。因此圖神經網絡最終的輸出向量為Hl∈RM×d,初始節點特征向量為fl∈RM×d,M為節點數量,d為隱藏層維度,通過ELMO 編碼的問題輸入向量為fq∈RN×d,N為問題數量。通過式(7)求得相似度矩陣S∈RM×N:
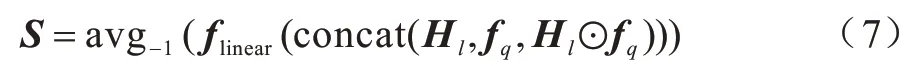
其中:avg-1表示對flinear最后一維求平均值。
通過對問題與圖神經網絡中的節點進行一次反向注意力運算,得到節點-問題的注意力表示,如式(8)所示:

其中:·表示矩陣相乘。
在得到節點-問題的注意力表示后,計算問題-節點的注意力表示,如式(9)所示:
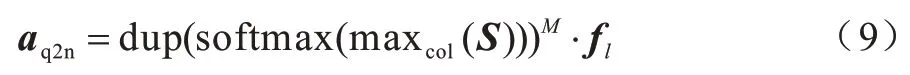
其中:maxcol表示取相似度矩陣S中每一列的最大值,從而將相似度矩陣維度轉換為R1×N;dup(·)表示經過M次復制后將S的維度轉換為RM×N。
最終將經過這一模塊處理后的輸出向量輸入至預測模塊,進行最后的答案預測,如式(10)所示:
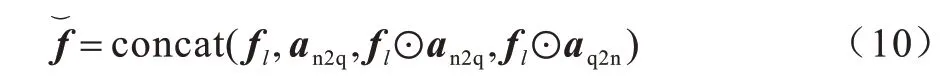
1.5 預測模塊
通過將最終信息交互模塊的輸出經過兩層全連接層的轉換之后,得到每個節點作為答案的概率值,每個節點都對應一個候選詞,將每個候選詞所對應的所有節點的概率相加,就是該候選詞作為答案的概率。由于答案選擇實際是一個多分類問題,因此選擇多分類交叉熵損失函數作為模型的損失函數,即:

當答案預測正確時yi為1,否則為0,pi為預測候選詞所對應的概率,如式(12)所示:

值得注意的是,由于在構建實體圖時加入了很多非候選詞節點,因此在實際計算答案概率時只會計算相關候選詞實體節點作為答案的概率,而不會計算疑問實體節點與疑問實體關聯實體節點作為答案的概率。
2 實驗結果與分析
為驗證本文模型的有效性,在WikiHop 數據集的unmasked 版本中對其進行驗證測試。WikiHop 數據集是一個需要跨越多個文檔進行多跳推理的閱讀理解數據庫。每一個WikiHop 的樣本有一個問題Q,多個支撐文檔S={s1,s2,…,sn}和一個候選答案集C={c1,c2,…,cn},候選答案可以是單個單詞,也可以是多個單詞組成的名詞短語,需要模型根據給定的問題從中選出正確的答案。其中,訓練集有43 738 條數據,驗證集有5 129 條數據,測試集有2 451 條數據,支撐文檔來自WikiReading[16]。
實驗環境設置如下:操作系統為Ubuntu16.04,采用2 塊GTX Titan Xp 進行數據并行處理,服務器運行內存為96 GB。在參數選擇上:ELMO 模型默認選擇1 024 維;本文模型除了最終的輸出層神經網絡維度為256 維外,其余的隱藏層維度均為512 維,圖卷積網絡層數L為5;訓練集batch_size 設置為32,驗證集batch_size 設置為16;初始學習率設置為2×10-4,為了防止模型過擬合,Dropout 設置為0.2。本文模型所需的實體圖數據與ELMO 詞向量嵌入均已在線下提前訓練好,可以有效減少實際模型的訓練時間。如表1 所示,實體圖中節點數量主要集中于小于500 這一區間,因此每個實體圖設置最大節點數為500。
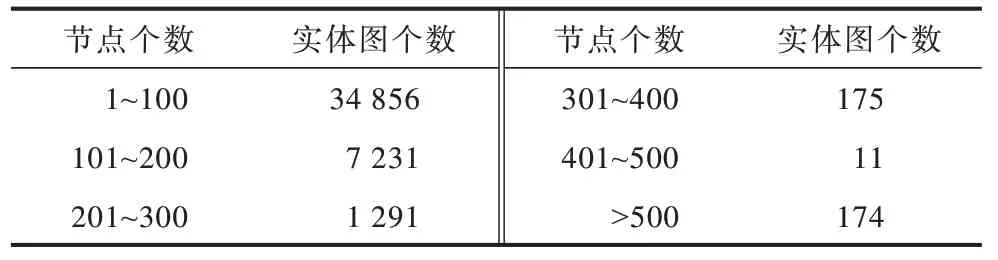
表1 實體圖節點數量統計Table 1 Statistics of node number in entity graph
為驗證本文模型的效能,分別通過在驗證集和測試集上與基于圖神經網絡的多跳閱讀理解模型(Entity-GCN[10]、MHQA-GRN[11]、HDE[13]、BAG[14]、Path-based GCN[17])、基于循環神經網絡(Recurrent Neural Network,RNN)的多跳閱讀理解模型(Coref-GRU[9]、EPAr18])、基于注意力機制的多跳閱讀理解模型(BiDAF[1]、CFC[19]、DynSAN[20])進行比較,結果如表2 所示。由于本文模型是單模型,因此僅與已有單模型進行比較,而不與融合模型進行比較,評價指標為準確率。
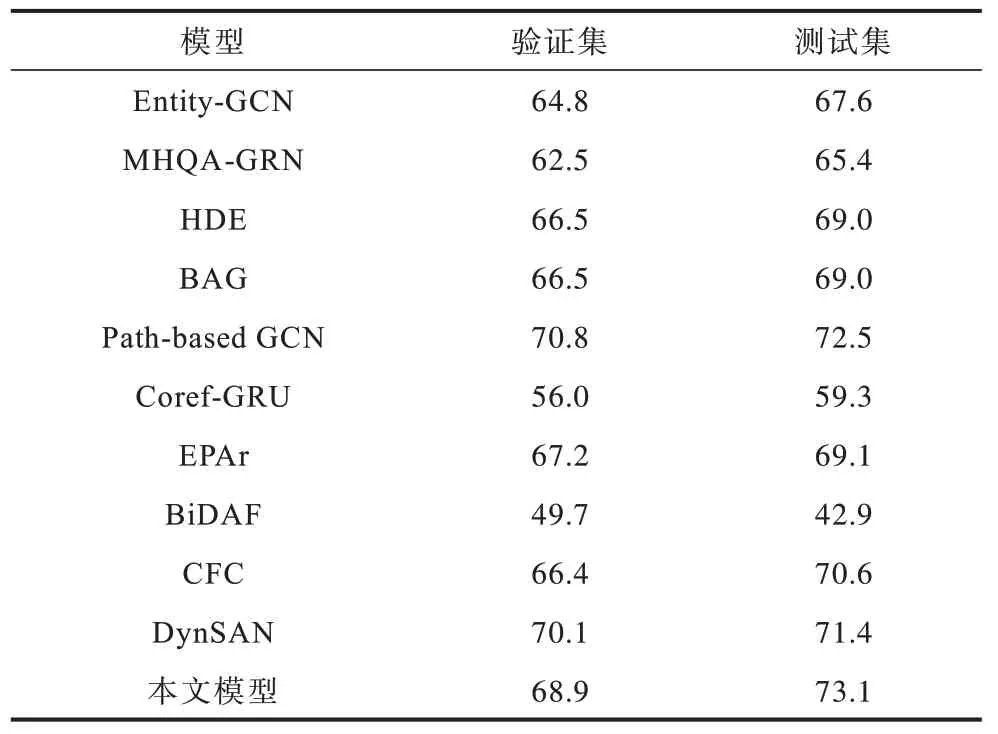
表2 多跳閱讀理解模型準確率比較Table 2 Comparison of accuracy of multi-hop reading comprehension models %
從表2 中的結果可以看出,與基于圖神經網絡的多跳閱讀理解模型相比,本文模型在驗證集中僅低于Path-based GCN 模型,但是在測試集上優于所有基于GCN 的多跳閱讀理解模型,與其中準確率最高的Path-based GCN 模型相比在驗證集上提高了0.6 個百分點,這表明了本文模型的可泛化性較強。在與其他非圖神經網絡模型進行比較時,本文模型在驗證集上準確率僅低于DynSAN 模型,但在測試集上準確率高出DynSAN 模型1.7 個百分點。以上比較結果表明:使用基于指代詞的實體提取方法提取出實體以構建新型實體關系的實體圖可以有效地增加實體圖中所含的關鍵信息量,最終提升模型性能。
為驗證本文模型中各模塊的有效性,在驗證集上進行模型消融實驗來驗證基于指代詞的實體提取方法與基于問題關聯實體的實體圖構建對于模型效果的影響,結果如表3 所示。由表3 中的結果可以看出:去除基于指代詞的實體提取模塊后,準確率下降了1.9 個百分點,說明使用傳統方法在提取實體時會造成部分相關實體的缺失,導致模型推理效果下降;去除基于問題關聯實體的實體圖模塊后,準確率下降了1.5 個百分點,證明了實體圖內缺乏關鍵問題信息會影響多跳推理的結果;去除GCN 模塊后,準確率下降達到了4.8 個百分點,說明了圖卷積網絡能夠有效地促進實體圖內各個節點之間的信息交互;去除雙向注意力模塊后,準確率下降了3.5 個百分點,這證明了雙向注意力機制可以有效提升模型性能。

表3 多跳閱讀理解模型消融實驗結果Table 3 Results of ablation experiment for multi-hop reading comprehension models %
3 結束語
為解決實體圖內缺乏關鍵問題信息以及信息量冗余的問題,本文提出基于改進圖節點的圖神經網絡多跳閱讀理解模型。采用基于指代詞的實體提取方法從支撐文檔中提取與問題相關的實體,并將提取到的相關實體基于問題關聯實體構建實體圖。通過對圖節點進行ELMO 編碼后使用G-GCN 模擬推理,最終計算推理信息與問題信息的雙向注意力并進行最終答案預測。實驗結果表明,該模型相比現有多跳閱讀理解模型準確率更高、泛化性能更強。后續將添加更多類型的節點和邊到實體關系圖中,使得實體關系圖可以包含更多的相關信息,進一步增強模型推理能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
