基于XGBoost和改進灰狼優化算法的催化裂化汽油精制裝置的辛烷值損失模型分析
2022-01-14 02:27:48陳延展任紫暢成艾國
石油學報(石油加工) 2022年1期
陳延展,胡 浩,任紫暢,成艾國
(湖南大學 機械與運載工程學院,湖南 長沙 410000)
汽油是小型車輛的主要燃料,其燃燒產生的尾氣排放對大氣環境有重要影響。為此,世界各國都制定了日益嚴格的汽油質量標準。研究法辛烷值(RON)是反映汽油燃燒性能的最重要指標,并作為汽油的商品牌號(例如89#、92#、95#)。現有技術在對催化裂化汽油進行脫硫和降烯烴過程中,普遍降低了汽油辛烷值[1]。辛烷值每降低1個單位,相當于損失約150 CNY/t[2]。以一個1000 kt/a催化裂化汽油精制裝置為例,若能降低RON損失0.3個單位,其經濟效益將達到45×106CNY。因此,研究汽油的辛烷值,對于保護大氣環境和提高工廠經濟效益具有重要意義。
實驗測定是目前獲取汽油辛烷值數據的最有效方法。根據ASTM D2699[3]和ASTM D2700[4]的規定,辛烷值分為研究法辛烷值(RON)和馬達法辛烷值(MON)2種。通過實驗測定來改善調試汽油樣品的辛烷值從而確定其最佳配比,不僅需要昂貴的實驗儀器及設備,還需要花費大量的時間及試劑樣品[5]。因此,有必要開展汽油辛烷值的理論預測研究,建立可靠的理論預測模型,彌補實驗方法的缺陷與不足。
目前,分析化學法是文獻中預測汽油辛烷值的常見方法。Ghosh等[6]通過色譜分析法來預測汽油辛烷值,平均誤差值約為4~7個單位。Kardamakis等[7]則通過近紅外光譜法對汽油辛烷值進行預測研究。分析化學法的缺陷在于同樣需要用到相應分析測試儀器,其運轉、維護費用較高,且耗時耗力。因此,采用各種理論算法來建立汽油辛烷值的預測模型受到廣泛關注。
目前為止,基于各種理論方法的汽油辛烷值的化工過程建模一般是通過數據關聯或機理建模的方法來實現的,取得了一定的成果。但是由于煉油工藝過程的復雜性以及設備的多樣性,它們的操作變量(控制變量)之間具有高度非線性和相互強耦聯的關系,而且傳統的數據關聯模型中變量相對較少、機理建模對原料的分析要求較高,對過程優化的響應不及時,所以效果并不理想。基于此,筆者利用某石化企業催化裂化汽油精制裝置采集的大量歷史數據,通過機器學習技術建立汽油研究法辛烷值(RON)損失預測模型,揭示相應的操作變量及其影響規律;并提出一種改進的差分灰狼優化算法對影響汽油辛烷值損失的操作變量進行優化,以盡量減少汽油精制過程中的辛烷值損失,為石化企業和運營商提供決策分析。
1 模型及算法介紹
XGBoost(Extreme gradient boosting)是由Zhou等[8]提出的一種支持并行計算的梯度提升樹模型,近些年該模型憑借突出的效率和較高的預測精度被廣泛應用于Kaggle機器學習競賽中。實際上XGBoost是一種改進的GBDT(Gradient boosting decision tree)算法[9],兩者本質上均由許多用于回歸和分類的決策樹組成,但是XGBoost在以下方面對GBDT算法進行了改進:(1)對于損失函數,GBDT算法只使用了一階泰勒展開,而XGBoost則增加了二階泰勒展開;(2)XGBoost在目標函數中構造了正則懲罰項[8]以降低模型復雜度,從而防止模型過擬合。XGBoost模型的結構如圖1所示。
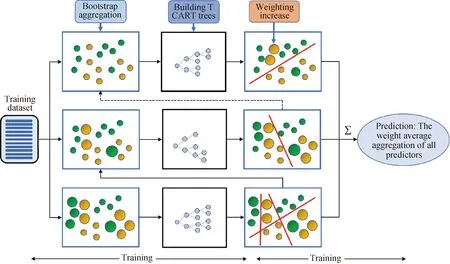
圖1 XGBoost算法示意圖Fig.1 Schematic of XGBoost algorithm
對于一個給定的有n個樣本的數據集D={(xi,yi)}(i=1,2…,n),其中xi表示第i個樣本的特征值集合,yi表示第i個樣本的標簽值,則基于數據集D訓練出的具有K個基學習器的XGBoost預測模型為:
(1)
F={f(x)=ωq(x)}
(2)

(3)
在對訓練數據進行學習時,每次在保留原有模型不變的基礎上,加入一個新函數ft,觀察對應的目標函數J(ft),若加入的新函數能使目標函數盡可能減到最小,則把該函數加到模型中。此時目標函數表示為:
(4)
(5)
式中:L代表損失函數;Ω(ft)則表示模型的復雜度;T表示葉節點數;γ和λ表示懲罰項的權重系數。之后對目標函數進行二階泰勒展開得到如下近似目標函數:Tt為t次迭代后的葉節點數。
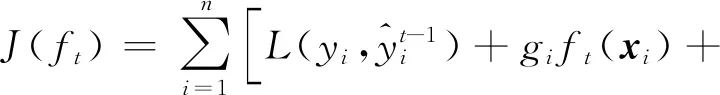
(6)
(7)
(8)
式中:gi和hi是關于損失函數L的一階導數和二階導數。綜上所述,最終求得的目標函數形式如下:
(9)

(10)
(11)
2 特征工程
實驗數據集來源于某石化企業催化裂化汽油精制裝置運行4年所采集到的325個樣本數據,其中每個數據樣本都包含7個原料性質、2個待生吸附劑性質、2個再生吸附劑性質、2個產品性質等變量以及另外354個操作變量,共計367個特征變量。表1中僅列出367個變量中的前30個具體信息(由于變量太多,此次降為30個)。由于367個特征變量中存在大量的冗余變量,不利于汽油辛烷值損失值預測模型的建立和求解,所以利用特征工程篩選出建模的主要變量,特征工程的總體流程如圖2所示。

表1 影響汽油辛烷值損失的特征變量Table 1 Characteristic variables affecting octane loss in gasoline

MIC—Maximum mutual information coefficient method圖2 特征工程的主要變量選取流程圖Fig.2 Flow chart for selection of key variables
由圖2可知:首先需要對數據集進行歸一化處理,由于各特征的數值量綱之間存在較大差異,數據歸一化可以使所有特征具有零均值和同一階數上的方差,以方便后續的機器學習模型訓練;然后運用方差閾值法的思想進行特征的粗略篩選,計算數據特征的方差值,剔除方差較低的特征,得到剔除后的前100個變量特征;然后分別利用Pearson相關系數法、最大互信息系數(MIC)法和基于隨機森林的特征選擇法對各特征進行重要度計算;最終利用3種特征選擇方法的融合進行變量特征的精確篩選。Pearson系數法僅反映不同變量之間的線性關系,最大互信息法能同時反映變量間的線性和非線性關系,基于隨機森林的特征重要度排序方法以包裹式的特征選取方式進行特征重要度計算。考慮到選取的特征應具有獨立性、代表性的要求,因此,按照Pearson系數法權重∶最大互信息系數法權重∶隨機森林法權重比為2∶3∶5進行特征重要度的融合。各類方法對于特征變量的重要度排序如圖3所示。

圖3 各方法的特征重要度排序Fig.3 Feature importance ranking sequence of each method(a)Pearson method;(b)Maxmium mutual information coefficient method;(c)Random forest method;(d)Weight coefficient method
基于權重法融合結果的前25項特征的重要度之和占所有特征重要度之和的95%以上,故從得到的前100個特征中選取前25個特征作為建模的主要特征,其特征變量如表2所示。

表2 建模選取的主要特征變量Table 2 Main characteristic variables
3 模型應用與結果分析
以特征工程后的催化裂化汽油精制裝置歷史運行數據為訓練集,分別采用多個機器學習模型建立汽油辛烷值損失值與25個主要特征變量之間的映射函數,并在測試集上利用各種評價指標進行模型對比,從而驗證XGBoost模型的預測性能。
3.1 模型評價指標

(12)
(13)
(14)
3.2 實驗分析與模型對比
基于催化裂化汽油精制裝置歷史運行數據分別訓練了XGBoost汽油辛烷值損失值預測模型和其他機器學習模型,如線性回歸模型[10]、K近鄰模型[11]、支持向量機(SVM)[12]、決策樹(DT)[13]和隨機森林(RF)[14]等。實驗平臺為AMD Ryzen 74800H with Radeon Graphics(2.90 GHz),配置了16.0 GB的RAM內存和8 GB的GTX 1070Ti顯卡。其中SVM、DT和RF等模型均在python的第三方庫scikit-learn中實現。表3給出了上述10個機器學習模型對于汽油辛烷值(RON)損失值的預測精度、訓練時間和測試時間。
由表3可見,后6個模型的R2均超過0.97而具有很高的預測精度,并且其中模型RF和XGBoost的R2均高達0.99以上,遠超其他模型。表現最為突出的XGBoost模型R2值更是高達0.9981,并且MAE和RMSE均處在所有模型的最低值。然而2種線性模型LR和Linear-SVM的預測精度都很差,其R2均在0.95左右,證明了汽油RON損失值與25 個特征變量之間存在明顯的非線性關系。其他模型DT和KNN的預測精度則處于中等水平。

表3 不同汽油辛烷值(RON)損失值預測模型的對比Table 3 Comparison of different RON loss value prediction models
XGBoost模型預測的汽油辛烷值損失值與真實值的對比曲線如圖4所示。由圖4可以看出XGBoost模型的擬合效果很好,兩條曲線幾乎完全重合。為了進一步說明XGBoost模型的擬合效果,圖5繪制了測試集數據中汽油辛烷值損失的真實值與XGBoost模型預測值之間的散點分布,散點越接近直線則表示模型的預測能力越強[15]。從圖5可以直觀看出該模型具有良好的汽油辛烷值預測能力。

圖4 XGBoost模型汽油辛烷值(RON)損失預測值與真實值對比Fig.4 Comparison of RON loss predicted values by XGBoost model and actual values
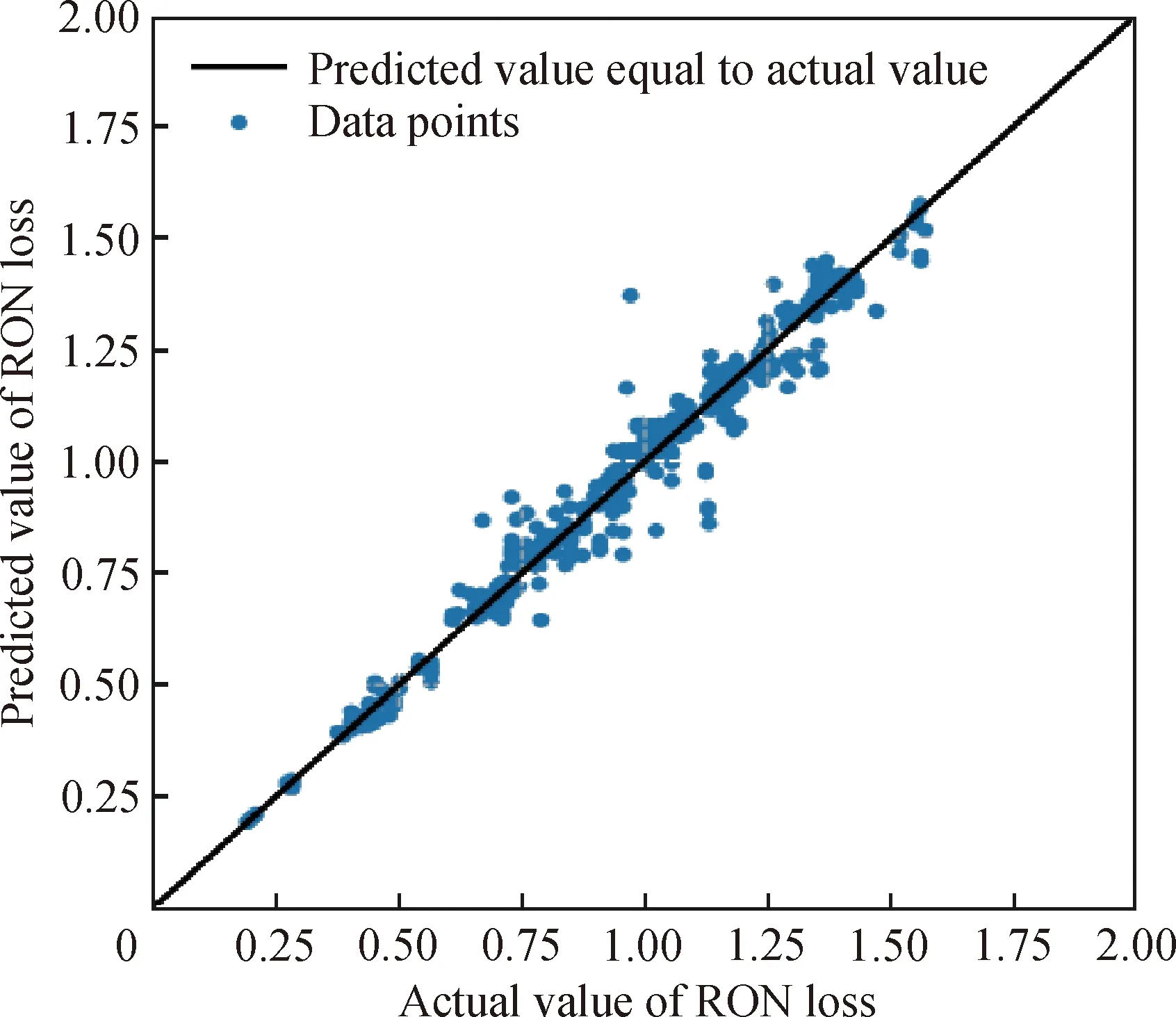
圖5 XGBoost模型汽油辛烷值(RON)預測值與真實值的散點分布Fig.5 Distribution of RON loss predicted values by XGBoost model and actual values
綜上所述,XGBoost模型的R2最高,并且訓練時間、預測時間、MAE以及RMSE均相對較小。所以XGBoost模型在預測汽油辛烷值損失值的問題上比其他模型更加有效,筆者最終采用XGBoost模型預測汽油辛烷值的損失值。
4 基于改進差分灰狼算法的汽油辛烷值損失優化模型
為盡可能降低汽油辛烷值損失,同時由于國六車用汽油標準要求硫質量分數不大于5 μg/g,為了保證汽油產品脫硫效果,對數據樣本的25個特征變量進行優化,建立了一種單目標優化模型。約束條件包括硫含量、操作變量的取值范圍等。為了建立硫質量分數不大于5 μg/g的約束條件,同樣采用XGBoost建立了硫含量與這些操作變量的映射函數關系,并作為限制條件求解。由于該優化模型的變量有25個,維度較高,筆者提出了一種改進的差分灰狼優化算法進行求解,可以較大提高模型的求解精度和效率。結果表明模型的建立與求解過程是合理的。具體的求解思路如圖6所示。
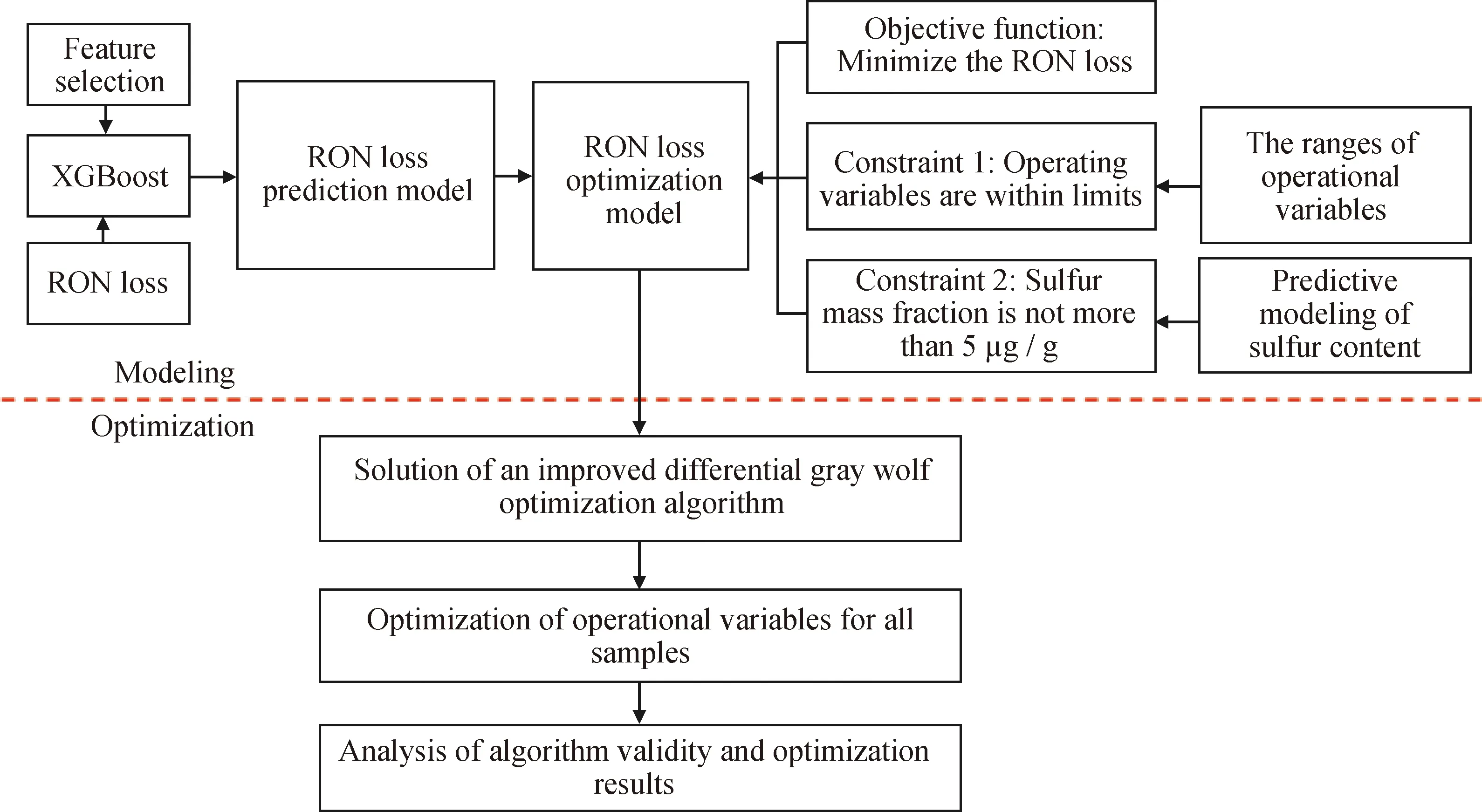
圖6 基于改進的差分灰狼優化算法的汽油辛烷值(RON)損失優化模型的建立與求解過程Fig.6 Establishment and solution of RON loss optimization model
4.1 模型建立
由數據可知,大多數樣本的汽油辛烷值損失還是偏大的,有必要對其特征變量進行優化來減少其損失值。因此,建立了一個優化模型,并在保證硫質量分數不大于5 μg/g的條件下,分別對這325個樣本對應的操作條件進行優化求解。具體的建模過程如下:
目標函數:使辛烷值損失最小,采用XGBoost的汽油辛烷值損失與主要操作變量的映射函數,用f(X)來表示,其中X=[X1,X2,X3,…,XM](M=25),代表影響汽油辛烷值損失的25個主要操作變量,并且下標與表2中的排序一一對應。
min(f(X))
(15)
硫含量的約束條件:利用XGBoost建立硫含量與25個主要操作變量的映射函數,即利用主要操作變量預測硫含量,用g(X)表示,并使得其質量分數不大于5 μg/g。
操作變量的約束條件:每個操作變量的取值范圍如表4所示。于是,最終的優化模型如下:

表4 影響汽油辛烷值損失的25個主要操作變量的取值范圍Table 4 25 main operational variables affecting RON loss
min(f(X))
(16)
4.2 改進的差分灰狼優化算法設計
對于優化問題,傳統的數學規劃方法在求解過程中難以實現全局最優,且收斂性差。目前,基于種群迭代的智能優化算法由于其較快的求解速率在工程上得到了廣泛應用。灰狼優化(Gray Wolf Optimizer,GWO)[16]算法作為一種較新的智能優化算法,憑借其結構簡單、需要調節的參數較少和較好的魯棒性的特點,也得到了許多學者的關注。但是,與其他智能優化算法類似,基本的灰狼優化算法也存在著一些缺點,比如對于高維問題容易陷入局部最優、求解精度不高等。針對此問題,筆者提出了一種改進的差分灰狼優化算法來對模型進行求解。
4.2.1 基本灰狼優化算法
GWO算法是借鑒大自然中狼群捕食行為和社會領導階層分工的思想而提出的一種新型智能優化算法。在一個小型灰狼群體中,有3個最優的個體,分別為α狼、β狼和δ狼,它們處于金字塔的上層,其他狼聽從這些狼的指揮。
這些灰狼在追逐和包圍獵物過程可以抽象為一個數學模型,提出了以下公式:
(17)
(18)
(19)
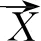
(20)
(21)
(22)
(23)
(24)
式中:umax為最大迭代次數;其他灰狼個體根據α、β和δ的位置分別更新各自的位置。
4.2.2 灰狼算法的改進策略
(1)基于sigmoid函數的收斂因子調整
根據前面灰狼算法的機理分析可知,A值的大小代表灰狼包圍獵物時的范圍,A越大說明包圍圈越大,反之包圍圈越小,即代表了灰狼的全局勘探和局部精細搜索的能力。而A的取值是隨收斂因子a變化的。也就說明了收斂因子影響著灰狼算法的全局搜索和局部搜索能力。然而,在基本的GWO中,收斂因子是線性遞減的,這種搜索策略在實際尋優過程難以適應實際情況。為了使得灰狼在開始階段搜索的范圍較廣,并在結束階段能夠在很小的范圍內進行精細搜索,采用sigmod函數來控制收斂因子的取值,可以使算法的全局勘探和局部搜索能力更強,其收斂因子的更新策略如公式(25)所示,采用這種策略,既有利于加快收斂速率,又能使算法在迭代末期獲得最優值。
(25)
(2)基于差分變異策略的個體更新
在基本的GWO算法中,由式(24)可以看出,群體中其他灰狼個體的更新是由α狼、β狼和δ狼這3種狼的位置決定的。如果這3種狼陷入了局部最優解的周圍,會導致其他狼的個體的多樣性減少,從而使得算法出現早熟現象,無法跳出局部最優的包圍圈,求解效果會變得較差。為了解決這一問題,可以引入變異操作算子,使得算法避免這種陷入局部最優的狀況。常見的變異算子有高斯變異、柯西變異等。
受到差分進化算法的啟發,筆者采用差分變異算子來對其他狼的位置進行調整。即利用當前灰狼個體、最優灰狼個體和隨機選擇的灰狼個體進行隨機差分選擇進行位置更新,其表達式如下:
(26)

4.2.3 改進差分灰狼優化算法的步驟

4.3 模型求解與結果分析
根據325個樣本數據的操作變量的原始值,分別對改進的差分灰狼優化算法進行初始化,通過優化算法的不斷迭代可以求解每個數據樣本對應的主要變量優化后的操作條件。表5列出了第1個樣本優化前后的操作變量和汽油辛烷值損失值的數據,同時還給出了硫含量的值。由表5可以發現硫質量分數在5 μg/g以下,滿足國六車用汽油標準要求的硫含量取值范圍。
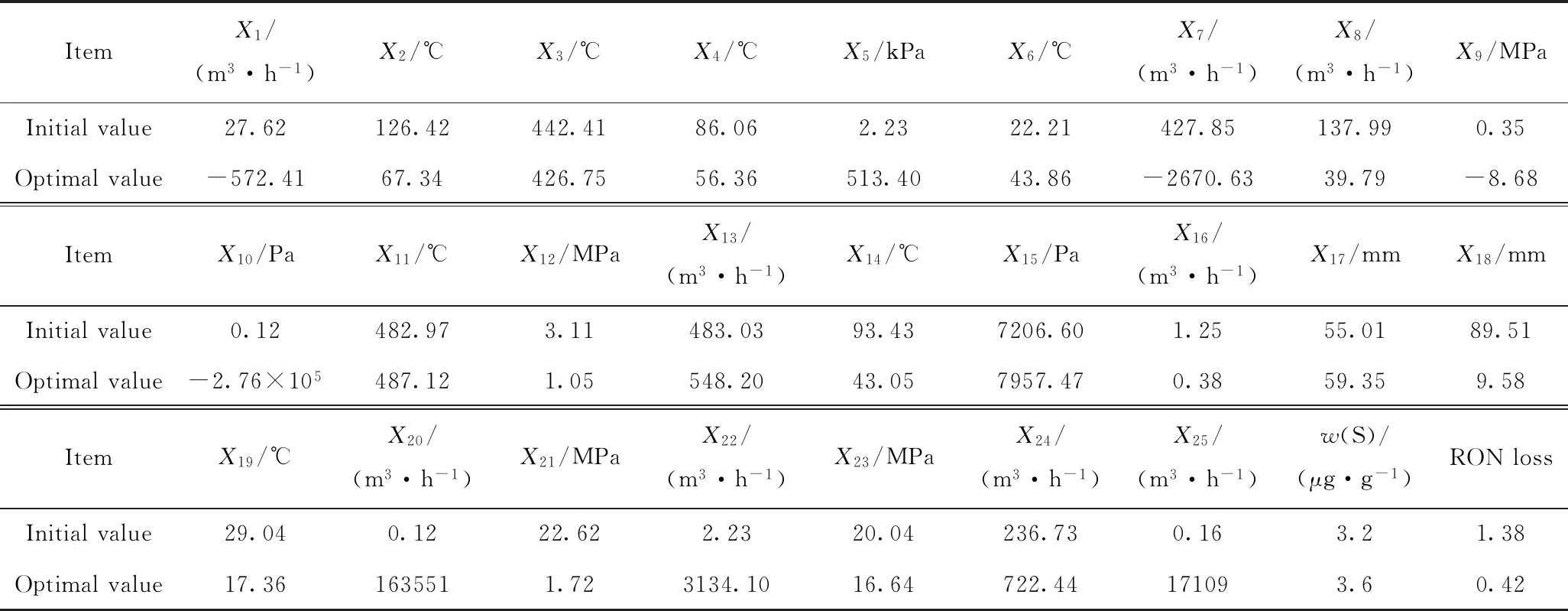
表5 第1個樣本操作變量和汽油辛烷值損失優化前后結果Table 5 Operation variables of the first sample and RON loss before and after optimization
為了進一步驗證改進差分灰狼優化算法的效果,對數據集前325個樣本優化前后的辛烷值損失值大小進行了可視化,如圖7所示。由圖7可知,325個樣本中辛烷值損失值的初始值都較大,大部分超過了1,而優化后的值卻在0.4上下波動,證明了改進的差分灰狼算法很大程度上降低了汽油辛烷值損失值,這進一步說明了所建立的模型和設計的算法的有效性。

圖7 325個樣本辛烷值損失值優化前后結果對比Fig.7 Result comparison before and after optimization of RON loss of 325 samples
除此之外,筆者還計算了優化后的汽油辛烷值損失值的降幅,其計算公式為:
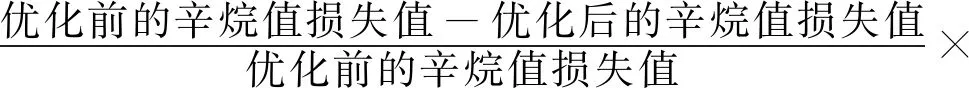
采用上述公式對圖7中所有樣本的降幅進行了計算,表6給出了汽油辛烷值損失值降幅的區間范圍。由表6可以看出,辛烷值損失降幅在30%以下的只有3個樣本,大多數樣本的損失降幅在60%~80%之間,這也證明優化的效果很好

表6 優化后的汽油辛烷值(RON)損失降幅分布Table 6 RON loss range after optimization
4.4 算法有效性分析
為了驗證所提出的改進差分灰狼優化算法的有效性,分別與差分算法(Differential Evolution Algorithm,DE)和灰狼算法進行了對比,結果見圖8。
本實驗采用python編程實現,電腦的處理器為:AMD Ryzen 74800H with Radeon Graphics(2.90 GHz),內存(RAM)為16 GB,優化1個訓練樣本所花費的時間為28 s,效率比較高。
由圖8可知,所提出的改進算法在收斂速率和求解精度上均是最優的,這進一步驗證了算法的有效性。
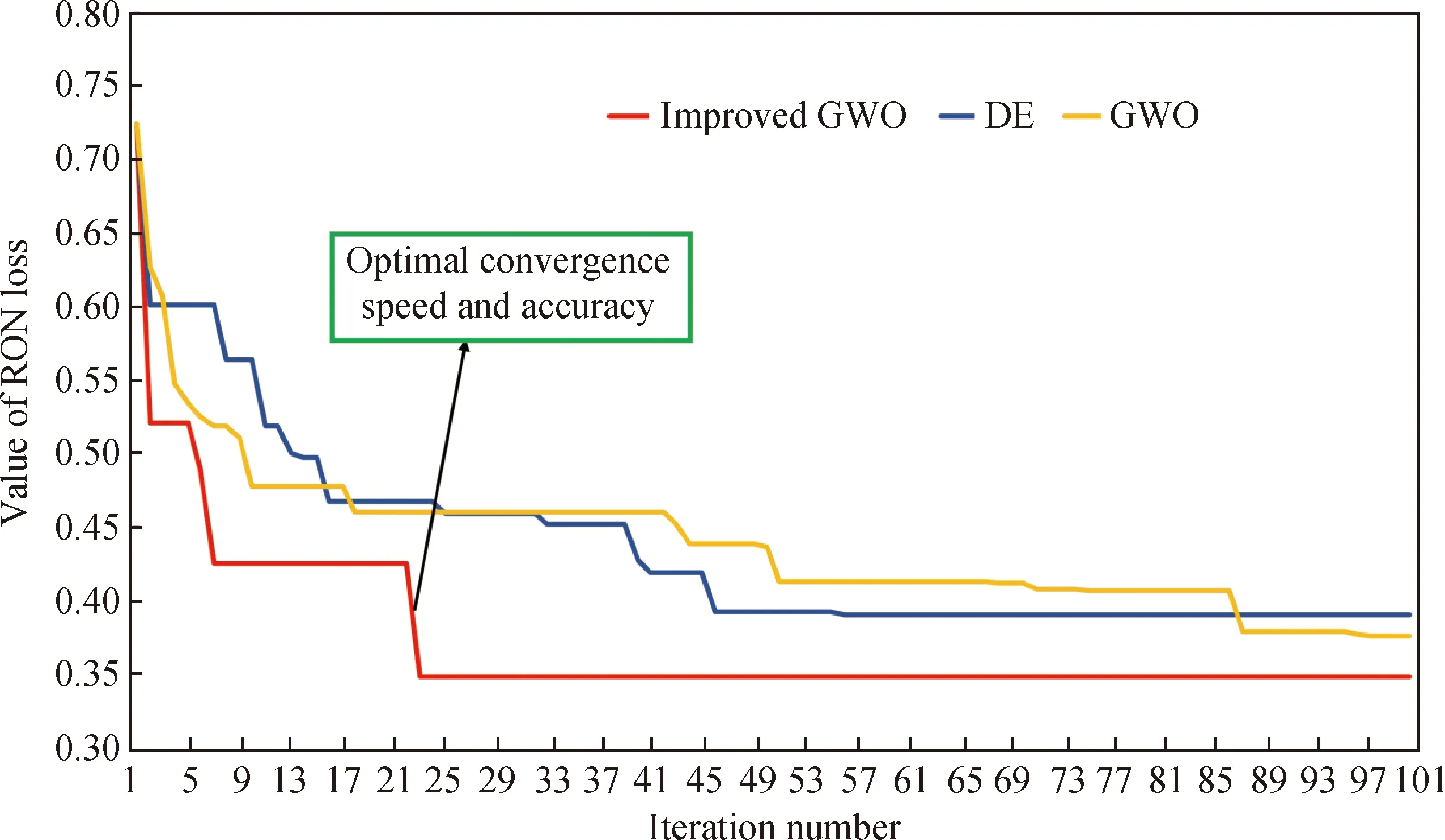
GWO—Gray wolf optimizer;DE—Differential evolution algorithm圖8 3種優化算法的迭代曲線Fig.8 Iterative curve diagrams of three optimization algorithms
5 結 論
基于機器學習算法XGBoost建立汽油辛烷值損失值與主要特征變量之間的映射函數,并提出一種改進的差分灰狼算法建立關于汽油辛烷值損失值最小的單目標優化模型,最終得出的結論如下:
(1)分別采用Pearson系數、最大互信息系數和隨機森林特征選擇法計算來篩選主要特征變量,并利用權重法對各特征重要度進行融合,有效避免了單一特征評價方法的局限性;
(2)采用XGBoost和多種流行的機器學習模型分別預測汽油辛烷值損失,其中XGBoost算法的RMSE值、MAE值和R2系數分別為1.3197、0.3581和0.9981,通過對比分析證明XGBoost算法的預測性能最佳;
(3)針對具有高維變量的優化問題,提出了一種改進的差分灰狼優化算法,利用該算法可以將數據樣本的辛烷值損失降低至0.4左右。分別與差分進化算法和基本灰狼優化算法進行對比,發現改進的算法在求解速率和精度上有了一定的提升。
建立的降低汽油辛烷值損失模型可以盡量減少汽油精制過程中的辛烷值損失,為化工企業和運營商提供決策分析。但是此研究沒有考慮到實際工業生產過程中汽油辛烷值損失預測的實時性,未來的研究可以圍繞在線極限學習機模型對汽油辛烷值進行預測,以提高汽油的生產質量與效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
