面向軍事領域的土耳其語術語自動抽取研究
2022-01-12 02:35:01張貴林易綿竹李宏欣閆丹輝孫玥瑩
中國科技術語 2022年1期
張貴林 易綿竹 李宏欣 閆丹輝 孫玥瑩






摘 要:文章以土耳其語軍事領域術語語言特征研究為基礎,提出一種規則與統計相結合的術語抽取方法,先后通過關鍵詞、停止詞、形態分析序列模式、點互信息、左右信息熵和臨接詞綴等特征對單語文本中的候選項進行篩選,在W-data和N-data大小兩組單語文本中進行實驗,結果表明該方法能夠有效地從實驗數據中抽取土耳其語軍事術語。
關鍵詞:土耳其語軍事術語;過濾詞典;自動抽取方法
中圖分類號:H512;H083;E91? 文獻標識碼:A? DOI:10.12339/j.issn.1673-8578.2022.01.003
Research on Auto-Extraction of Turkish Terminology in Military Field//ZHANG Guilin, YI Mianzhu, LI Hongxin, YAN Danhui, SUN Yueying
Abstract: Based on the analysis on the linguistic features of Turkish military terminologies, we proposed a terminology extraction method using combination of rules and statistics algorithm, and experimentally verified this method on monolingual W-data and N-data. The candidate items in the monolingual text are filtered through keywords, stop words, morphological analysis sequence pattern, pointwise mutual information, left and right information entropy and adjacency suffixes. Our results show that the proposed method can effectively extract Turkish military terminologies from the experimental data.
Keywords: Turkish terminology extraction; filtering dictionary; automatic extraction methodologies
引言
當今世界各學科發展迅速,術語規模也隨之不斷增量擴容,完全依靠人工抽取術語非常耗時耗力。為了快速高效構建或維護術語詞典,人們提出了很多術語自動抽取方法,如左右信息熵與互信息算法、word2vector相似詞算法、BERT-BiLSTM-CRF融合方法等[1-2],這些方法雖然能夠取得一定的效果,但遠非完美,自動獲取的術語仍然需要人工檢查和驗證,在本質上,術語自動抽取仍是一個半自動實現的過程。因此,如何利用知識庫來改善術語抽取性能而減輕人工篩選的工作量是術語自動抽取研究的一個重要方向。
術語學家或翻譯人員先前編制的術語詞典,其本身詞法、語法和語義等領域屬性對動態發展的術語具有天然的指導作用,在自動抽取術語過程中,對相關特征的提取和利用有助于提高術語抽取的效果。基于這一前提,本文提出根據現有土耳其語軍事術語詞典中術語的語言學特征,構建術語抽取關鍵詞、停止詞和形態分析序列模式列表,采用語言學規則與統計方法相結合的策略,利用背景語料中的點互信息、左右信息熵和臨接詞綴來實現土耳其語軍事領域術語的自動抽取。
論文第一部分簡要介紹了術語的定義和術語自動抽取的常見方法;第二部分主要闡述了軍事術語自動抽取的具體方法、策略及相關算法,分析了土耳其語軍事術語特有的語言學特征,構建了用于術語自動抽取的相關知識庫;第三部分基于背景語料進行了土耳其語軍事術語自動抽取實驗,通過實驗結果評測和分析,驗證了本文所提方法的有效性;第四部分對全文進行總結,并對今后的研究方向進行了展望。
1 術語定義及術語自動抽取方法概述
1.1 術語的定義
術語是表示科學、藝術、專業或學科等領域知識相關特定概念的詞匯,在句子中一般作主語和謂語[3]。術語通常與特定的單一概念、對象、事件或狀態相對應,多為復合型名詞結構,在某一特定學科范圍內具有單義性特點,是確保領域專家之間有效溝通的基本信息承載單元,也是翻譯質量評估中被廣泛使用的多維質量度量標準的核心范疇之一[4]。軍事術語可視為軍事領域的專門用語,與一般詞語相比,在軍事領域使用的頻率較高,在其他領域使用的情況則很少,具有十分明顯的領域流通性。
1.2 術語自動抽取常見方法
術語自動抽取方法歸納起來可分為基于規則、基于統計、規則與統計相結合的方法三大類。基于規則的方法主要是利用現有術語資源的語言學特征,總結設置術語抽取的規則模板,然后通過模式匹配的方式完成候選術語的識別和抽取,如文獻[5]。這類方法對受限領域特定類型的術語抽取效果較好,且在準確率方面具有一定的優勢,但缺點是規則的制定通常需要一定規模的受限領域標記語料的支持,且要求規則制定者具備較強的語言功底和背景知識,當規則設置出現偏差時,容易出現覆蓋面不全和規則之間相互沖突的情況。基于統計的術語抽取方法又可分為基于統計學的方法和基于詞向量機器學習的方法[6-8],其主要思想是根據統計特征,通過概率判斷出多詞字符串是否為穩定的語言結構,并衡量組成成分與領域特征之間的關聯程度。相比于規則方法,統計方法的領域適應性較強,自動化程度較高,但容易受到測試語料規模和質量的影響。規則與統計相結合的方法,主要利用兩種方法各自的優點,通過先抽取、后篩選的步驟來完成候選術語的抽取,其中統計和規則的使用順序并不固定,通常取決于研究內容的具體需要。混合方法從理性主義和經驗主義融合角度出發,可有效提高術語抽取的準確率和召回率,是領域術語抽取研究最為主流的方法,也是目前研究的重點和熱點。
2 基于混合方法的術語抽取策略
識別詞語搭配和抽取關鍵術語的一種常見方法是通過詞性標記序列(句法模式)來過濾或篩選候選術語,繼而找出與序列模式相匹配的可能成為術語的詞組。本文結合土耳其語自身的特點,將土耳其語形態分析序列模式作為語言學規則,通過關鍵詞、常見停止詞、形態分析序列模式、點互信息、左右信息熵和臨接詞綴等篩選方法來實現術語抽取。其中,關鍵詞、停止詞和形態分析序列模式的確定均以術語詞典中術語的詞法、語法和語義特征為基礎,系統主要包括基于末尾關鍵詞的候選項抽取、基于常見停止詞的候選項篩選、基于形態分析序列模式的候選項篩選、基于點互信息閾值的候選項篩選和左右信息熵閾值篩選五大模塊,術語抽取過程和整體框架如圖1所示。
2.1 軍事術語詞典的選取
軍事領域術語的意義較為寬泛。在一篇典型的軍事領域文本中,通常不僅會包括軍事領域的特定術語,一定也會出現其他領域的相關術語。目前領域術語知識庫的構建大多在領域屬性已知的數據集上完成,術語領域屬性嚴重依賴數據集領域屬性本身,術語領域屬性會跟隨數據集變化而發生改變。為了盡量保證術語的軍事領域屬性,本文主要以土耳其外交部2013年3月發布的英-土雙語軍事領域術語詞表(第2版)為研究對象,并對比分析不同領域的術語詞典,選取并確定術語抽取關鍵詞、篩選停止詞和形態分析序列模式。對比分析數據還包括土耳其國家機場管理局航空術語詞典(2011版)和土耳其信息與通信技術管理局發布的《信息與通信技術術語指南》,用以驗證不同領域術語之間的異同點。
2.2 土耳其語軍事術語的語言學特征分析
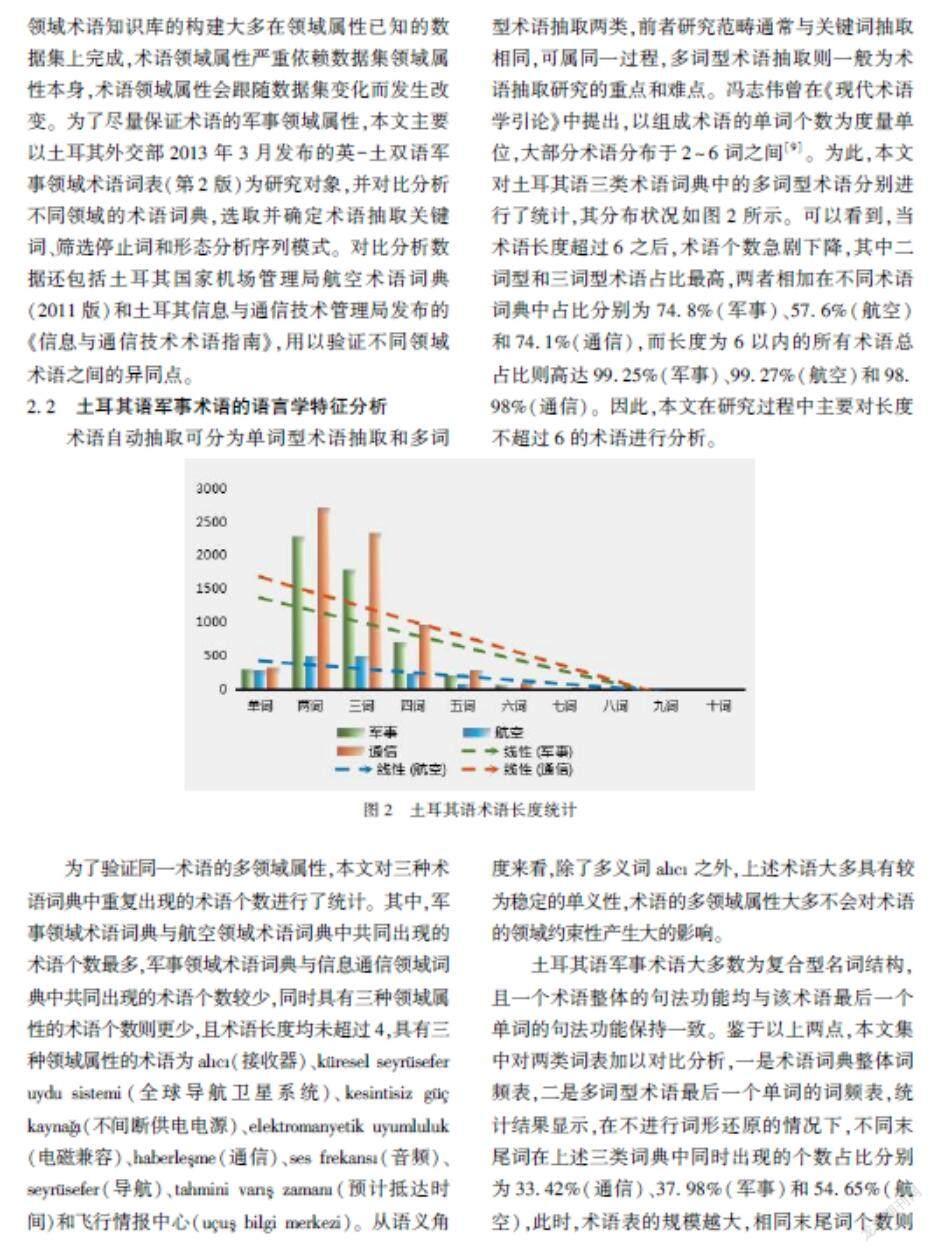
術語自動抽取可分為單詞型術語抽取和多詞型術語抽取兩類,前者研究范疇通常與關鍵詞抽取相同,可屬同一過程,多詞型術語抽取則一般為術語抽取研究的重點和難點。馮志偉曾在《現代術語學引論》中提出,以組成術語的單詞個數為度量單位,大部分術語分布于2~6詞之間[9]。為此,本文對土耳其語三類術語詞典中的多詞型術語分別進行了統計,其分布狀況如圖2所示。可以看到,當術語長度超過6之后,術語個數急劇下降,其中二詞型和三詞型術語占比最高,兩者相加在不同術語詞典中占比分別為74.8%(軍事)、57.6%(航空)和74.1%(通信),而長度為6以內的所有術語總占比則高達99.25%(軍事)、99.27%(航空)和98.98%(通信)。因此,本文在研究過程中主要對長度不超過6的術語進行分析。
為了驗證同一術語的多領域屬性,本文對三種術語詞典中重復出現的術語個數進行了統計。其中,軍事領域術語詞典與航空領域術語詞典中共同出現的術語個數最多,軍事領域術語詞典與信息通信領域詞典中共同出現的術語個數較少,同時具有三種領域屬性的術語個數則更少,且術語長度均未超過4,具有三種領域屬性的術語為alc(接收器)、küresel seyrüsefer uydu sistemi(全球導航衛星系統)、kesintisiz gü kayna(不間斷供電電源)、elektromanyetik uyumluluk(電磁兼容)、haberle
瘙 塂
me(通信)、ses frekans(音頻)、 seyrüsefer(導航)、tahmini var
瘙 塂
zaman(預計抵達時間)和飛行情報中心(uu
瘙 塂
bilgi merkezi)。從語義角度來看,除了多義詞alc之外,上述術語大多具有較為穩定的單義性,術語的多領域屬性大多不會對術語的領域約束性產生大的影響。
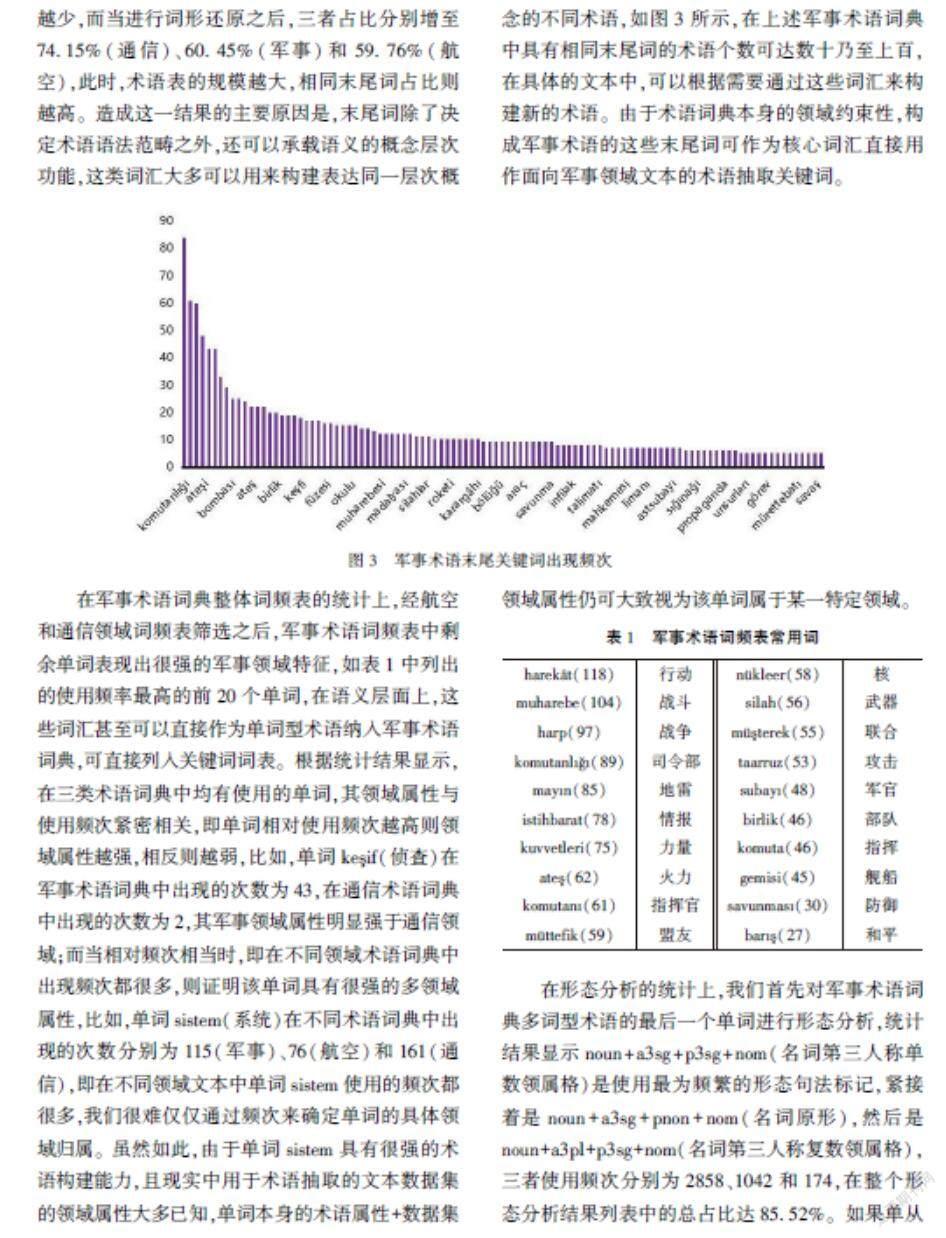
土耳其語軍事術語大多數為復合型名詞結構,且一個術語整體的句法功能均與該術語最后一個單詞的句法功能保持一致。鑒于以上兩點,本文集中對兩類詞表加以對比分析,一是術語詞典整體詞頻表,二是多詞型術語最后一個單詞的詞頻表,統計結果顯示,在不進行詞形還原的情況下,不同末尾詞在上述三類詞典中同時出現的個數占比分別為33.42%(通信)、37.98%(軍事)和54.65%(航空),此時,術語表的規模越大,相同末尾詞個數則越少,而當進行詞形還原之后,三者占比分別增至74.15%(通信)、60.45%(軍事)和59.76%(航空),此時,術語表的規模越大,相同末尾詞占比則越高。造成這一結果的主要原因是,末尾詞除了決定術語語法范疇之外,還可以承載語義的概念層次功能,這類詞匯大多可以用來構建表達同一層次概念的不同術語,如圖3所示,在上述軍事術語詞典中具有相同末尾詞的術語個數可達數十乃至上百,在具體的文本中,可以根據需要通過這些詞匯來構建新的術語。由于術語詞典本身的領域約束性,構成軍事術語的這些末尾詞可作為核心詞匯直接用作面向軍事領域文本的術語抽取關鍵詞。
在軍事術語詞典整體詞頻表的統計上,經航空和通信領域詞頻表篩選之后,軍事術語詞頻表中剩余單詞表現出很強的軍事領域特征,如表1中列出的使用頻率最高的前20個單詞,在語義層面上,這些詞匯甚至可以直接作為單詞型術語納入軍事術語詞典,可直接列入關鍵詞詞表。根據統計結果顯示,在三類術語詞典中均有使用的單詞,其領域屬性與使用頻次緊密相關,即單詞相對使用頻次越高則領域屬性越強,相反則越弱,比如,單詞ke?if(偵查)在軍事術語詞典中出現的次數為43,在通信術語詞典中出現的次數為2,其軍事領域屬性明顯強于通信領域;而當相對頻次相當時,即在不同領域術語詞典中出現頻次都很多,則證明該單詞具有很強的多領域屬性,比如,單詞sistem(系統)在不同術語詞典中出現的次數分別為115(軍事)、76(航空)和161(通信),即在不同領域文本中單詞sistem使用的頻次都很多,我們很難僅僅通過頻次來確定單詞的具體領域歸屬。雖然如此,由于單詞sistem具有很強的術語構建能力,且現實中用于術語抽取的文本數據集的領域屬性大多已知,單詞本身的術語屬性+數據集領域屬性仍可大致視為該單詞屬于某一特定領域。
在形態分析的統計上,我們首先對軍事術語詞典多詞型術語的最后一個單詞進行形態分析,統計結果顯示noun+a3sg+p3sg+nom(名詞第三人稱單數領屬格)是使用最為頻繁的形態句法標記,緊接著是noun+a3sg+pnon+nom(名詞原形),然后是noun+a3pl+p3sg+nom(名詞第三人稱復數領屬格),三者使用頻次分別為2858、1042和174,在整個形態分析結果列表中的總占比達85.52%。如果單從詞性角度來看,名詞性單詞占比高達98.34%,符合術語大多數為復合型名詞結構的這一論斷,在確定關鍵詞和抽取術語時,充分利用這一特點在一定程度上將有助于提高術語抽取的效率。在三類術語詞典中,軍事術語形態分析序列模式總數為1306,通信術語形態分析序列模式總數為1987,航空術語形態分析序列模式總數為591。通過軍事/通信、軍事/航空、軍事/通信+航空三種形式兩兩對比發現,三者中均有的形態分析序列模式總數為430,其中,與使用最頻繁的前十位形態分析序列模式相符的軍事術語個數為2246,占術語總數的44.31%;軍事術語獨有形態分析序列模式總數為876,單個模式最高使用頻次為15,使用頻次為1的獨有序列模式總數為760,占術語總數的14.99%。對比結果顯示,基于軍事術語詞典構建的形態分析序列模式具有一定的領域特征,但與領域屬性較強的獨有模式相比,使用頻次高的通用形態分析序列模式對術語抽取的影響會更大。在進行候選術語篩選時,形態分析序列模式對術語領域屬性具有一定的約束性,但效果有限。
2.3 關鍵詞選取
在關鍵詞的選取上,本文從功能角度將關鍵詞分為末尾關鍵詞和非末尾關鍵詞兩大類,末尾關鍵詞作為核心詞直接用于術語抽取索引詞,而非末尾關鍵詞則作為領域關鍵詞用于新關鍵詞的發現。語言學家約翰·加斯特森(John Justeson)提出一種通過選擇頻率最高的雙詞詞組,結合詞性模式過濾“可能短語”進行短語和關鍵詞識別的方法[10]。本文借鑒這一方法,首先通過頻次獲得候選詞組,之后基于形態分析序列模式過濾出符合條件的候選短語,然后再使用非末尾關鍵詞進行篩選并保留具有軍事領域屬性的候選短語,最后通過這些短語篩出術語詞典中沒有的末尾關鍵詞。需要指出的是,軍事術語詞典中多詞型術語名詞性結構的占比高達98.34%,因此,名詞短語對于識別關鍵詞更加有用,在某種程度上多詞型術語的抽取可視為對名詞短語的抽取,本文在關鍵詞的設置上也以名詞為主。
2.4 停止詞的選取
自然語言領域泰斗肯尼斯·丘吉(Kenneth Church)在其研究中曾提到,最常見的詞通常會帶來最大的麻煩[11]。通過這些常見詞選取的停止詞,在被用于篩選術語時往往可以起到事半功倍的效果。本文在軍事領域術語停止詞的選取上遵循上述理念,通過軍事領域術語詞典和大規模單語數據集來構建一種常見停止詞詞表,在選取常見停止詞時,數據集中出現次數很少或較少的單詞不納入停止詞范圍之內。
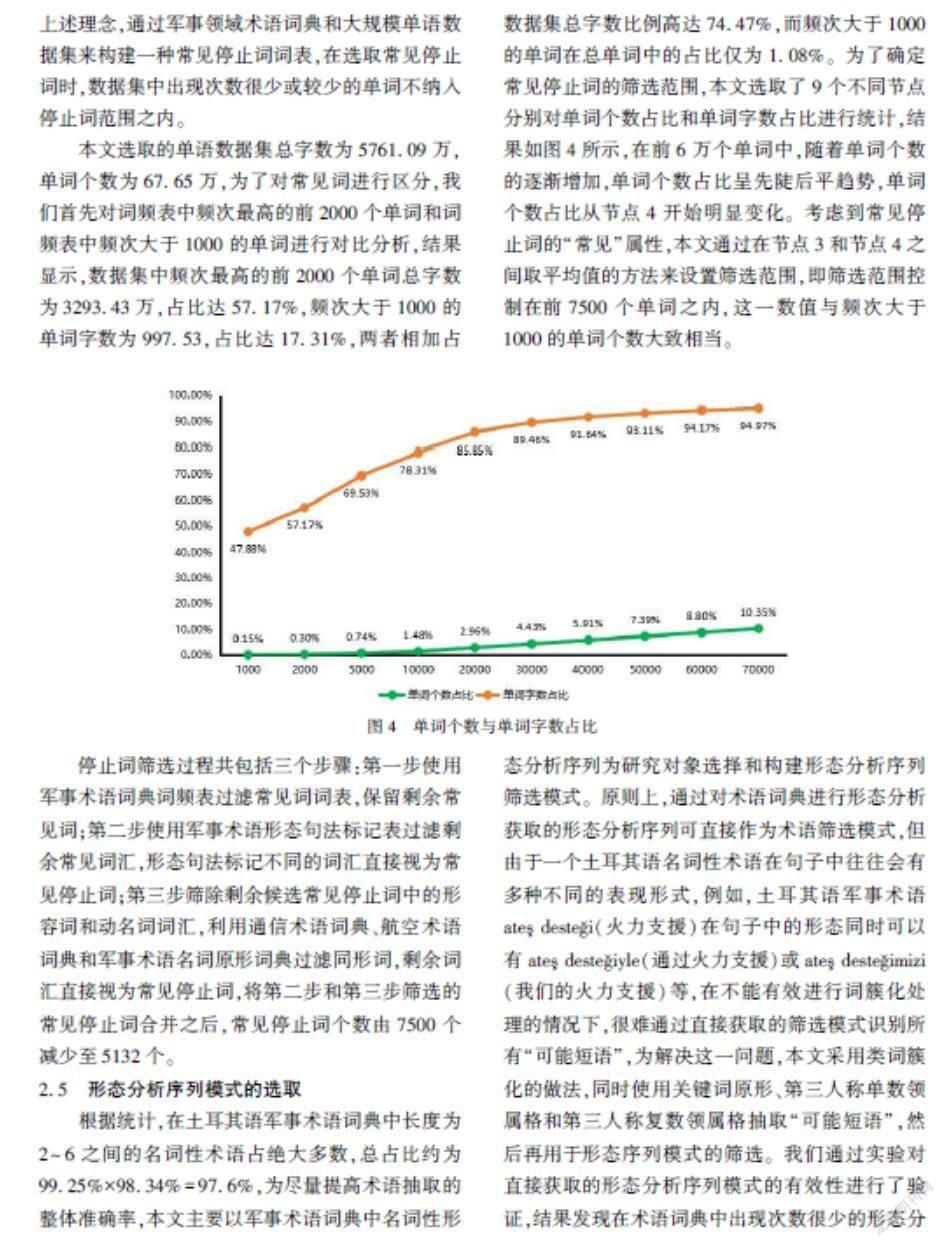
本文選取的單語數據集總字數為5761.09萬,單詞個數為67.65萬,為了對常見詞進行區分,我們首先對詞頻表中頻次最高的前2000個單詞和詞頻表中頻次大于1000的單詞進行對比分析,結果顯示,數據集中頻次最高的前2000個單詞總字數為3293.43萬,占比達57.17%,頻次大于1000的單詞字數為997.53,占比達17.31%,兩者相加占數據集總字數比例高達74.47%,而頻次大于1000的單詞在總單詞中的占比僅為1.08%。為了確定常見停止詞的篩選范圍,本文選取了9個不同節點分別對單詞個數占比和單詞字數占比進行統計,結果如圖4所示,在前6萬個單詞中,隨著單詞個數的逐漸增加,單詞個數占比呈先陡后平趨勢,單詞個數占比從節點4開始明顯變化。考慮到常見停止詞的“常見”屬性,本文通過在節點3和節點4之間取平均值的方法來設置篩選范圍,即篩選范圍控制在前7500個單詞之內,這一數值與頻次大于1000的單詞個數大致相當。
停止詞篩選過程共包括三個步驟:第一步使用軍事術語詞典詞頻表過濾常見詞詞表,保留剩余常見詞;第二步使用軍事術語形態句法標記表過濾剩余常見詞匯,形態句法標記不同的詞匯直接視為常見停止詞;第三步篩除剩余候選常見停止詞中的形容詞和動名詞詞匯,利用通信術語詞典、航空術語詞典和軍事術語名詞原形詞典過濾同形詞,剩余詞匯直接視為常見停止詞,將第二步和第三步篩選的常見停止詞合并之后,常見停止詞個數由7500個減少至5132個。
2.5 形態分析序列模式的選取
根據統計,在土耳其語軍事術語詞典中長度為2~6之間的名詞性術語占絕大多數,總占比約為99.25%×98.34%=97.6%,為盡量提高術語抽取的整體準確率,本文主要以軍事術語詞典中名詞性形態分析序列為研究對象選擇和構建形態分析序列篩選模式。原則上,通過對術語詞典進行形態分析獲取的形態分析序列可直接作為術語篩選模式,但由于一個土耳其語名詞性術語在句子中往往會有多種不同的表現形式,例如,土耳其語軍事術語 ate
瘙 塂
destei(火力支援)在句子中的形態同時可以有ate
瘙 塂
desteiyle(通過火力支援)或ate
瘙 塂
desteimizi(我們的火力支援)等,在不能有效進行詞簇化處理的情況下,很難通過直接獲取的篩選模式識別所有“可能短語”,為解決這一問題,本文采用類詞簇化的做法,同時使用關鍵詞原形、第三人稱單數領屬格和第三人稱復數領屬格抽取“可能短語”,然后再用于形態序列模式的篩選。我們通過實驗對直接獲取的形態分析序列模式的有效性進行了驗證,結果發現在術語詞典中出現次數很少的形態分析序列模式并不一定能夠起到術語篩選的效果,例如,軍事術語kar
瘙 塂
ate
瘙 塂
(火力反擊)的形態分析序列模式為后置詞+名詞(Postp Noun),后置詞nce和sonra與關鍵詞ate
瘙 塂
同時出現的概率也很高,通過上述形態分析序列很難過濾掉類似的字符串,但考慮到符合這一模式的術語總體占比很小,且大部分類似術語已在詞典中給出,因此,直接從列表中刪除具有類似特點的形態分析序列,可有效提高形態分析序列模式篩選效果。
2.6 基于統計方法的候選術語篩選
經過關鍵詞、停止詞和形態分析序列模式等方法過濾篩選之后,為進一步提高剩余候選術語的準確率,本文采取設置點互信息和左右信息熵閾值的方式,排除一些單詞間凝合度低的“候選短語”。
1)點互信息
在語言信息處理領域,通過點互信息和平均點互信息來度量單詞間相關度是一種非常常見的方法[12]。互信息(MI)來自于信息論,表示兩個隨機變量X,Y共享的信息量,是針對隨機變量計算得出的一個平均值,在已知任一變量的情況下,對另外一個變量的不確定性會相應減少,互信息的計算公式為:
MI(X,Y)=∑x∈X,y∈Yp(x,y)log2p(x,y)p(x)p(y)
相對互信息的隨機變量,點互信息(PMI)則是計算兩個具體事件之間的互信息,其計算公式為:
PMI(X,Y)=log2p(x,y)p(x)p(y)
為了更加直觀地理解上述公式,在點互信息計算公式中,本文將x,y直接視為文本中相鄰出現的兩個單詞,p(x,y)指的是單詞x和單詞y相鄰出現的概率,p(x)和p(y)分別為單詞x在文本中出現的概率和單詞y在文本中出現的概率。根據統計結果,可直接通過公式計算得出單詞x和單詞y之間的互信息,當單詞x和單詞y相互獨立的情況下,單詞x和單詞y相鄰出現的概率p(x,y)=p(x)p(y)=0,PMI=0。p(x,y)相比于p(x)p(y)越大,表示兩個單詞之間的聚合程度越高。據此,在需要對兩個以上單詞間的聚合程度進行計算時,公式中的分子則變為多詞串在文本中出現的概率,分母則變為多詞串全部拆分形式出現概率之和的平均值,此時計算結果即為平均點互信息,其計算公式如下:
PMI(w1…wn)=log2(p(w1…wn)Avp)
Avp=1n-1×∑n-1i=1p(w1…wi)p(wi+1…wn)
上述公式中,n代表多詞串中單詞的總個數,p(w1…wn)是詞串w1…wn在本文中出現的概率;i為非負整數,i從1開始取值,一直到n,p(w1…wi)p(wi+1…wn)表示拆分后字符串p(w1…wi)和字符串p(wi+1…wn)在文本中相鄰出現的概率。本文研究對象針對長度為2~6之間的名詞性術語,因此,i和n的取值范圍分別為6>i≥1,6≥n≥2。
2) 左右信息熵
通常判斷一個多詞字符串可以成詞的一個條件是這個字符串會在很多語境中出現。信息熵就是用來衡量字符串所處語境豐富程度的一個指標,熵越大則無序程度越高,字符串越具有獨立性。對于任一字符串X,其信息熵可表示為:
H(X)=-∑x∈Xp(x)log2(p(x))
其中,p(x)是字符串x出現的概率。我們設任意字符串S=w1w2…wi,稱w1為字符串w2…wi-1的左鄰接詞,wi為字符串w2…wi-1的右鄰接詞。如果字符串w2…wi-1的左右鄰接詞豐富多樣,即在很多語境中出現,那么該字符串成為一個術語的概率就大,如果左右鄰接詞單調貧乏,即出現語境不夠豐富,那么該字符串成為一個術語的概率就小。基于上述原理,本文通過字符串w2…wi-1的左右鄰接詞出現頻次來計算左右信息熵,設左信息熵為Hl,右信息熵為Hr,兩者的計算表達式則可表示成:
Hl(w1w2…wi-1)=-∑x∈Xp(w1w2…wi-1)log2(p(w1w2…wi-1))
Hr(w2…wi-1wi)=-∑x∈Xp(w2…wi-1wi)log2(p(w2…wi-1wi))
其中,p(w1w2…wi)≈f(w1w2…wi)/∑f(wl),且w1∈wl;p(w2…wi-1wi;f(w2…wi-1wi)/∑f(wr),且wi∈wr。如果左右信息熵達到一定的閾值,則我們認為字符串w2…wi-1可以是一個完整的術語。
3 實驗與評測
3.1 實驗數據
為了保證實驗數據具有更強的軍事領域屬性,我們首先利用網絡爬蟲從多家網站抽取了500萬土耳其語單語語句,然后,再以軍事領域術語詞典為基礎從上述語句中篩選了9.5萬個相關語句,并將其定義為對比實驗熟語料(W-data)。其次,為了增加實驗驗證效果,我們還通過土耳其國防工業網構建了一個包含3400個單語語句的小規模生語料文本(N-data),內容主要涉及武器裝備研發現狀與未來發展方向,用于對比不同文本對術語抽取效果造成的具體影響。
3.2 評價指標
為了驗證篩選術語的效果和性能,論文采用查全率(precision)、查準率(recall)和F值(F-Measure)三個常見指標來進行評測:
查準率(P)指的是通過算法選定的候選術語(TP+FP)中,預測正確的術語(TP)所占百分比:
P=TPTP+FP×100%
查全率(R)指的是通過算法預測正確的術語(TP)個數,在真實情況下所有正確術語中(TP+FN)所占的百分比:
R=TPFP+FN×100%
F值(F)是查準率和查全率之間的加權調和平均值,這一數值越大,篩選方法的效果就越好:
F=2×P×RP+R×100%
3.3 結果分析
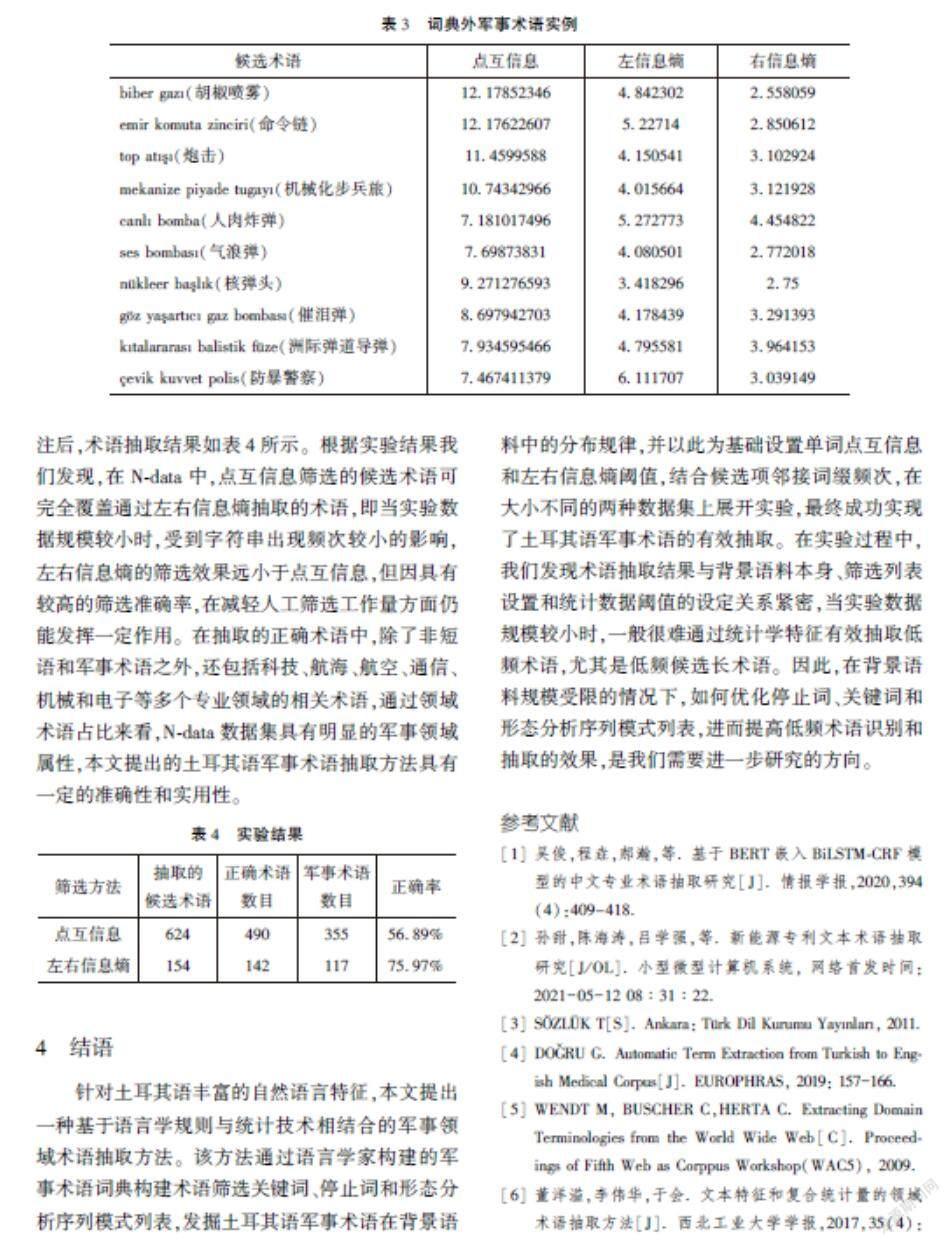
在自動抽取術語時,受背景文本的影響,查全率和查準率經常會產生動態變化,為盡量減輕人力負擔并保持術語的領域屬性,本文將軍事術語詞典的查全率視為隨點互信息閾值變化的近似查全率,F值的大小僅由點互信息閾值和查準率決定。在W-data測試集中,統計結果顯示軍事術語的點互信息值最小值為-2.11,最大為19.45,隨著點互信息數值的不斷增大,召回率呈先平穩后急劇下降的趨勢,而準確率則呈逐漸上升趨勢,根據計算,當點互信息閾值超過5時召回率與準確率乘積最大,閾值為10時F值達到峰值;左信息熵最大值為8.03,右信息熵最大值為7.49,當左右信息熵閾值為3時召回率與準確率乘積最大,同時F值也達到峰值。考慮到右臨接詞綴的影響,我們將點互信息閾值設置為10,左右信息熵閾值設置為2.5,兩者取交集時共篩選出151個候選項,其中116個為詞典內術語,23個為詞典外術語,術語自動抽取實際正確率達92.05%,抽取的部分詞典外術語實例如表3所示。
術語抽取本質上是一項檢索任務,在面向此類任務時,通常需要在保證召回率的情況下盡量提升準確率。為了盡可能快速全面地獲得術語,一般做法是根據不同參數的閾值各抽取一次候選術語,合并之后去重再進行人工篩選。考慮到互信息、左右信息熵和右臨接詞綴之間的互補性,本文在合并前分別篩除右信息熵小于0和右臨接詞綴頻次為1的候選項,在通過點互信息閾值提取的候選術語中篩除了485個候選項,其中包含11個軍事術語,根據計算此時召回率為31%,F值為0.27,相較未刪除前F值提高了4.4個百分點;在通過左右信息熵閾值提取的候選術語中篩除了76個候選項,其中包含11個軍事術語,此時召回率為39.95%,F值為0.27,相較未刪除前F值提高了0.8個百分點。兩者合并之后,共抽取候選術語1636個,術語抽取召回率增至57.47%,這一結果很好地證明了點互信息和左右信息熵的功能互補性。
在不同數據集中,點互信息和左右信息熵的閾值會伴有一定的變化,由于N-data數據集規模較小,因此在設置閾值時我們仍選擇參考詞典術語的分布規律,以盡量保證實驗具有較好的召回率,根據統計結果,我們將點互信息閾值設置為4,左右信息熵閾值設置為2.5,同時在點互信息篩選結果中刪除左信息熵小于0.5和右相鄰詞綴小于0的候選項,對經閾值篩選得到的候選術語進行人工標注后,術語抽取結果如表4所示。根據實驗結果我們發現,在N-data中,點互信息篩選的候選術語可完全覆蓋通過左右信息熵抽取的術語,即當實驗數據規模較小時,受到字符串出現頻次較小的影響,左右信息熵的篩選效果遠小于點互信息,但因具有較高的篩選準確率,在減輕人工篩選工作量方面仍能發揮一定作用。在抽取的正確術語中,除了非短語和軍事術語之外,還包括科技、航海、航空、通信、機械和電子等多個專業領域的相關術語,通過領域術語占比來看,N-data數據集具有明顯的軍事領域屬性,本文提出的土耳其語軍事術語抽取方法具有一定的準確性和實用性。
4 結語
針對土耳其語豐富的自然語言特征,本文提出一種基于語言學規則與統計技術相結合的軍事領域術語抽取方法。該方法通過語言學家構建的軍事術語詞典構建術語篩選關鍵詞、停止詞和形態分析序列模式列表,發掘土耳其語軍事術語在背景語料中的分布規律,并以此為基礎設置單詞點互信息和左右信息熵閾值,結合候選項鄰接詞綴頻次,在大小不同的兩種數據集上展開實驗,最終成功實現了土耳其語軍事術語的有效抽取。在實驗過程中,我們發現術語抽取結果與背景語料本身、篩選列表設置和統計數據閾值的設定關系緊密,當實驗數據規模較小時,一般很難通過統計學特征有效抽取低頻術語,尤其是低頻候選長術語。因此,在背景語料規模受限的情況下,如何優化停止詞、關鍵詞和形態分析序列模式列表,進而提高低頻術語識別和抽取的效果,是我們需要進一步研究的方向。
參考文獻
[1] 吳俊,程垚,郝瀚,等. 基于BERT嵌入BiLSTM-CRF模型的中文專業術語抽取研究[J]. 情報學報,2020,394(4):409-418.
[2] 孫甜,陳海濤,呂學強,等. 新能源專利文本術語抽取研究[J/OL]. 小型微型計算機系統, 網絡首發時間:2021-05-12 08∶31∶22.
[3] SZLK T[S]. Ankara: Türk Dil Kurumu Yaynlar, 2011.
[4] DORU G. Automatic Term Extraction from Turkish to Engish Medical Corpus[J]. EUROPHRAS, 2019: 157-166.
[5] WENDT M, BUSCHER C,HERTA C. Extracting Domain Terminologies from the World Wide Web[C]. Proceedings of Fifth Web as Corppus Workshop(WAC5), 2009.
[6] 董洋溢,李偉華,于會. 文本特征和復合統計量的領域術語抽取方法[J]. 西北工業大學學報,2017,35(4):729-735.
[7] CHATZITHEODOROU K, KAPPATOS V. Hybrid extraction of multi word terms: an application on vibration-based condition monitoring technique[J]. Mathematical Models in Engineering. 2021,7(2):1-9.
[8] SONG X Y, FENG A, WANG W K, et al. Multidimensional Self-Attention for Aspect Term Extraction and Biomedical Named Entity Recognition[J]. Mathematical Problems in Models in Engineering. 2020: 1-6.
[9] 馮志偉.現代術語學引論[M].增訂本. 北京:商務印書館,2011.
[10] JUSTESON J S, KATZ S M. Principled Disambiguation: Discriminating Adjective Senses with Modified Nouns[J].Computational Linguistics. 1995,21(1):1-27.
[11] GALE W A, CHURCH K W. A Program For Aligning Sentences In Bilingual Corpora[J]. Proceedings of the 29th Annual Meeting of the Association of Computational Linguistics.1993,19(1):75-102.
[12] 耿升華.新詞識別和熱詞排名方法研究[D]. 重慶:重慶大學計算機學院碩士論文,2013.
作者簡介:張貴林(1982—),男,博士研究生,戰略支援部隊信息工程大學洛陽校區學員,研究方向為語言信息處理,主要從事形態學、術語學、語料資源構建和機器翻譯等方面的研究。通信方式:guilin_1982@163.com。
易綿竹(1964—),男,戰略支援部隊信息工程大學洛陽校區教授、博士生導師、語言信息處理方向研究生教學指導組組長,兼任中國中文信息學會理事、國家社會科學基金項目和教育部學位與研究生教育發展中心學位論文通信評審專家等職,曾在俄羅斯伊爾庫茨克國立大學和普希金俄語學院訪學,獲俄聯邦語文科學博士學位,享受博士后待遇,主要從事計算語言學、本體語義學及術語學研究,主持完成國家級和部委級重點科研課題10余項,在國內外學術期刊發表論文近百篇,出版著作、譯作和辭書8部,獲省部級以上學術獎勵和榮譽稱號10余項。通信方式:13373781261@163.com。
李宏欣(1983—),男,博士,戰略支援部隊信息工程大學洛陽校區副教授,研究方向為量子信息與基礎數學,在國內外學術期刊發表論文數十篇。通信方式:lihongxin830@163.com。
