基于相關度分析的分布式能源發電能力預測模型構建
2022-01-10 10:28:24劉春樂
通信電源技術 2021年13期
楊 鴿,劉春樂,王 瑩
(1.四川水利職業技術學院電力工程系,四川 成都 611231;2.山東泰開電力電子有限公司,山東 泰安 271000)
0 引 言
近年來,隨著分布式能源的新增并網及電力儲能設備的使用,可以預見在能源互聯網這個概念范圍內的各類相關數據將會呈現指數級增加,這種情況下就需要對所涉及的海量數據根據實際需要進行有效分析,最大限度地提取有價值的信息,優化能源的利用效率。因此,使用大數據技術對能源互聯網所涉及的分布式發電系統進行應用建模研究,能夠為能源互聯網大數據技術在現實層面的應用提供一定的借鑒[1]。
對于分布式電站發電量預測所使用的數據,特點是數據量大、新數據產生快,當積累的數據量時間跨度變大,使用傳統模型(逆變器模型、光照模型等)進行預測則會受到影響。目前,很多預測方法采用不同的機器學習算法,如模糊神經網絡、灰色算法、灰色馬爾科夫模型以及支持向量回歸等[2]。這些方法在預測上都取得了一定的成功,但它們不能處理大數據,也不一定高效,因此急需一種有效的方案處理大體積復雜度高的數據集。
本文提出基于相關度分析的分布式發電能力預測方法,利用大數據技術,以影響分布式場站發電能力因素的相關度為切入點,通過算法根據歷史數據做出預測。將影響因素進行分類,形成以相關度為分類根據的不同數據組,將分類好的數據組分別作為學習組進行神經網絡訓練,得到各組的學習模型。上述不同的數據組和學習模型再進行交叉融合學習,得到最終的預測模型,然后通過預測模型進行發電能力預測[3]。
1 影響因素確定
對分布式能源來說,定量因素(線性關系因素)包括氣象情況、設備能量轉化效率、設備溫度損耗以及電纜線損等,是有據可查的數據,根據這些定量的數值可以直接得出較為準確的發電出力情況。而具體到分布式能源的某一個發電站來講,發電設備和配套設備的故障時間、不同班組的生產運營管理能力、遮陰和逆變器及組件匹配不合理等設備安裝因素、影響發電設備的環境因素等是固定存在的,并且對發電站發電能力有較大的影響,但此類因素對發電出力的影響是以概率形式存在的,無法準確地進行計算。
2 相關因素處理
2.1 定量因素處理
定量因素的處理根據具體場站積累的數據量不同分為兩種情況,一種是新并網的分布式能源電站,另一種是運行超過一定時間(以一年為參考時間)的分布式能源電站。兩種情況由于并網的時間不同,從而積累產生的數據量就有了區別,對于大數據分析來說,數據的量對于分析和決策有較大影響,故此兩種情況都要考慮。
針對上述存在的兩種情況,本文所使用的方法為在同一個模型中進行上述兩種情況的分析,即在建模時將所有的相關因素都考慮到其中,在使用模型進行發電能力預測時,根據實際情況調整影響因素權值。
對于新并網的電站,統計其各個生產環節的設備,可根據能量轉化效率或能量的損耗設定系數。在分布式能源場站中,單位數量的發電設備根據其說明書及銘牌參數,能夠計算出固定的自然能源A轉換為電能的效率,記為η。η即可認定為出力定量因素系數,作為新并網的電站,其設備因環境產生的損耗可忽略不計,故將相應的定量因素系數權值設置為0。
對于已積累了大量數據可供使用的場站,除了需要計算設備發電效率等系數,還要考慮因設備和線纜長時間運行所產生的出力效率影響。將現有數據進行整理,采用大數據技術中的相關性多因素影響分析模型,對每個因素進行分析后確定其系數。
2.2 定性因素處理
定性因素需要使用到大數據技術中的非線性數據擬合進行處理。在對上述定量因素進行處理之后,分析相同定量條件下不同時段所產生不同出力的原因。
3 分布式能源發電原理模型
對分布式能源電站進行定量因素和定性因素處理的發電出力模型預測功率P為:
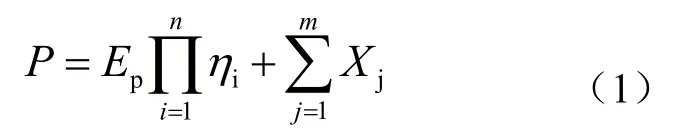
式中,Ep為當前外部環境條件下的理論功率,ηi為各線性影響因素的系數,Xj為非線性因素對系統的影響常數。等號右邊的兩部分和即為模型的預測出力。第一部分為定量因素,根據其對發電出力的影響特性,為各系數的乘積,各因素的系數是通過大數據技術中的線性回歸求得;第二部分為定性因素,由于實際應用中各發電廠站情況不同,經過神經網絡學習后可對其影響程度進行分析[4,5]。
4 大數據模型建立
本文所使用光伏實驗數據的時間范圍為24 h,步長5 min,但實際中在光照功率達不到發電閾值時,記錄中的數據沒有參考意義,需要根據光照量、發電量等判斷條件進行清洗。提取記錄中氣象條件經過聚類分析所得的相關性強的因素作為數據集,Rapid Miner中K-Means聚類分析模型如圖1所示。

圖1 Rapid Miner中K-Means聚類分析模型
在上述基礎上,以過去每個月的歷史氣象數據作為輸入集,通過BP神經網絡訓練建立預測模型,將氣象數據給出的溫度、風向、風速以及光輻射量等信息作為輸入量,得到所需的預測功率曲線。本文使用RapidMiner進行各因素的影響分析,加入相關性權重的神經網絡模型如圖2所示。
圖2 Rapid Miner中神經網絡聚類分析模型
5 具體場景分析
5.1 無歷史數據的出力預測
對于無歷史數據的出力預測,需要將其出力值假定為只受定量因素影響的理想模型,出力功率PI可表示為:

式(2)為式(1)忽略定性因素后的簡化,其中各部分的意義與式(1)相同,為精確進行預測,將Ep的當前時間段細化為15 min,ηi為各線性影響因素的系數,根據線性影響因素對發電功率的影響進行乘積處理,其具體值可以通過術語大數據分析工具SPSS進行線性回歸分析求得,對于數據較少的分析,也可通過簡單的線性回歸求得。
5.2 使用歷史數據的出力預測
5.2.1 算法功能
基于相關度分析的分布式能源出力預測算法主要有以下功能。一是使用大數據工具Rapid Miner從歷史數據中驗證理論模型相關因素的相關度,即光照、溫度以及設備維護周期等。二是根據相關度對因素進行分類,并針對性地分階段對數據進行學習、預測,然后與實際值進行比對,接著再進行學習,生成預測。三是數據分析與學習細分為年、季度、月、天、時,針對不同的時間段有最適合的預測方法。四是發現理論模型中未包含的影響因素,如人員等。五是通過步驟2得出的經驗參數,對另外的分布式發電站進行預測。
5.2.2 算法實施
本文采用某光伏電站的數據記錄作為實驗數據。在實驗數據中,光伏站固定區域發電量以天為單位收集起來。不同區域的發電量和氣象因素分類程度高,格式規范,且存放在本地CSV或類似XLS表格文件中,故使用體量小的Rapid Miner進行預測,可節約時間和軟件部署成本。這些原始數據保存在分布式光伏電站的本地磁盤中,其分時環境數據和發電量數據可使用Rapid Miner輕易讀取,即使用軟件中的一個低級語言去提取數據特征。
具體預測過程如圖3所示。首先,原始數據進行窗口化,生成窗口1和窗口2。其次,兩個窗口再進行聚類和回歸分析,生成相關度系數組1、2、3、4。最后,進行梯度神經網絡的訓練,生成的模型1、2、3、4和抽取結果的原始數據預測集一起進行融合學習優化最終生成發電能力預測結果。
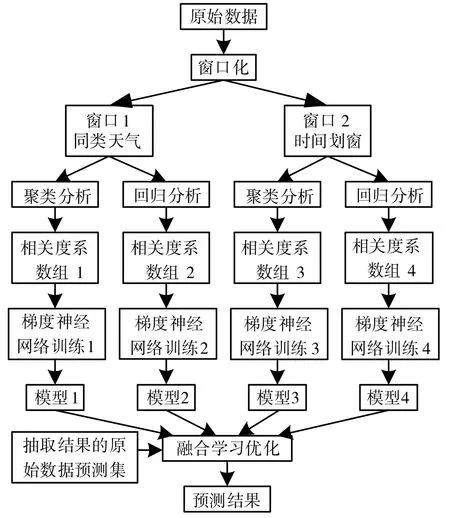
圖3 發電能力預測過程
5.2.3 算法評估
在歷史數據較為豐富的情況下,使用式(1)對分布式能源進行出力預測,其右側的線性相關部分可根據式(2)的方法進行求解,但要注意的是,所選數據盡量根據每年相似時段進行分組,以排除因時間積累所產生的誤差。另外,對設備進行保養、維護或清理等工作,也需計入到模型中。
Xj為非線性因素對系統的影響常數,其值通過建立模型、分析歷史數據、排除線性因素影響后得出,在數據較為豐富的情況下,可對線性因素基本相同的數據分組,然后多次清除已確定的相關值后可得出。
評估算法的性能,比較2017年的發電量預測值與實際值,分別對分布式光伏電站各區域進行測試,評估算法的有效性。區域1和區域2的短時預測值與實際值如圖4、圖5所示,區域3的長時預測值和實際值如圖6、圖7所示。
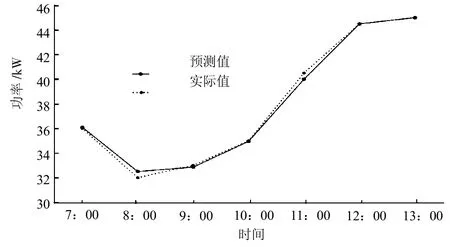
圖4 區域1短時預測值與實際值
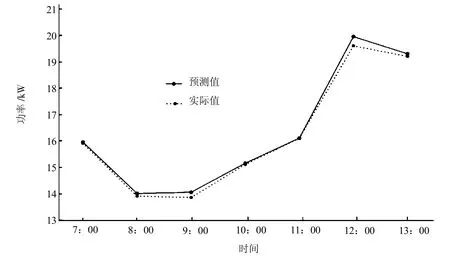
圖5 區域2短時預測值與實際值
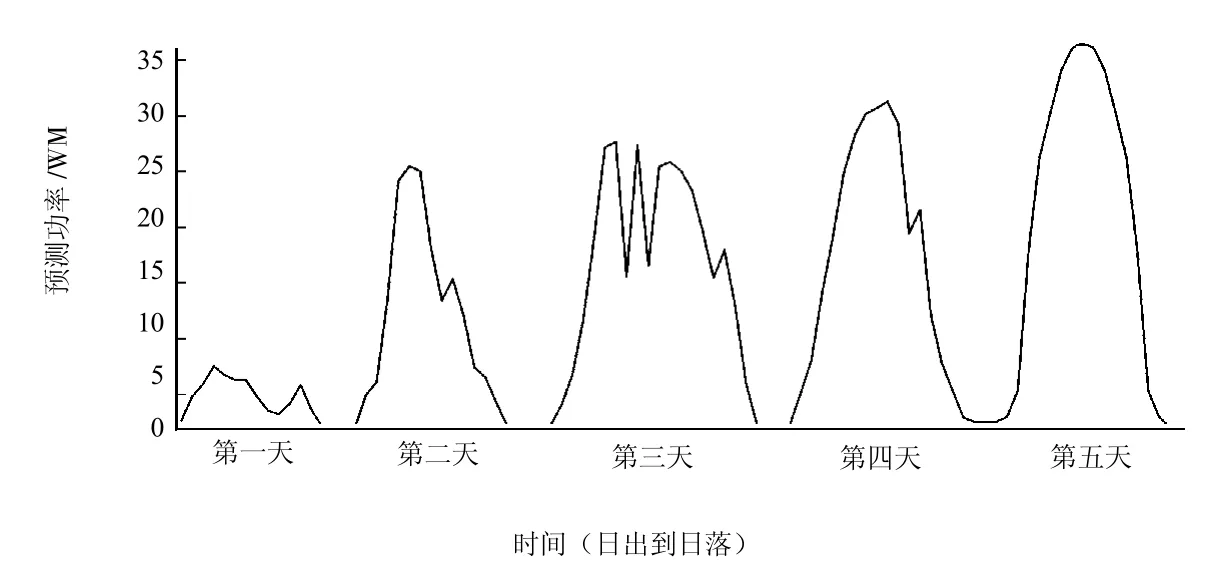
圖6 區域3長時預測值

圖7 區域3長時實際值
實驗結果表明,模型被正確訓練,誤差率最小化,發電量預測值與實際值非常接近。本模型可以識別數據正確模式,準確進行預測。
6 結 論
本文提出了一個全面、可實行的分布式發電場站歷史數據挖掘、實時數據預測功率的建模方法,利用相關度分析、系統聚類、K聚類等算法實現了對分布式發電場站功率和時、日等時間尺度變化規律的分析,并進行建模。根據本方法所建立的模型可使用Rapid Miner方便快捷地進行數據分析和預測,而且對于新場站、歷史數據比較少或者數據還在積累過程中的情況,可進行實時學習和預測,并不斷調整,在短時間內即可進行功率預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:36:04
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年12期)2021-08-05 07:45:46
當代陜西(2021年2期)2021-03-29 07:41:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國塑料(2016年3期)2016-06-15 20:30:00
冰雪運動(2016年4期)2016-04-16 05:54:56
