基于徑向基神經(jīng)網(wǎng)絡(luò)的漿液循環(huán)泵優(yōu)化研究
2022-01-07 06:59:12馮普鋒單濤陳靜孫晉志李方強
新型工業(yè)化 2021年9期
關(guān)鍵詞:實驗
馮普鋒,單濤,陳靜,孫晉志,李方強
(華電國際電力股份有限公司十里泉發(fā)電廠,山東 棗莊 277103)
0 引言
隨著國家對環(huán)境保護的日益重視,火力發(fā)電的節(jié)能環(huán)保要求也日益提高。為了降低污染物排放,滿足環(huán)保需求,大多數(shù)火力發(fā)電廠都已經(jīng)安裝了煙氣脫硫系統(tǒng)。現(xiàn)階段,石灰石-石膏的濕法脫硫方法是使用最廣泛的脫硫方法,該方法的建造和運營成本相對較高[1]。漿液循環(huán)泵系統(tǒng)設(shè)備是濕法脫硫系統(tǒng)主要的耗電設(shè)備之一,因此通過對脫硫系統(tǒng)的漿液循環(huán)泵系統(tǒng)進行分析及優(yōu)化,降低其電耗,能夠有效提高脫硫系統(tǒng)的節(jié)能能力,而且對提高發(fā)電系統(tǒng)的經(jīng)濟水平具有重要意義。
1 背景
漿液循環(huán)漿泵是脫硫系統(tǒng)的主要設(shè)備之一,其主要作用是提供脫硫過程所需的循環(huán)漿液量。如果提供的漿液少,則不能很好地進行脫硫反應(yīng);如果提供的漿液多,則對應(yīng)著相關(guān)的電耗增多,不利于節(jié)能環(huán)保工作的開展。文獻[8]指出大多數(shù)脫硫系統(tǒng)存在資源浪費的情況,不利于電廠的節(jié)能運行。
本文通過研究電廠脫硫優(yōu)化系統(tǒng)建設(shè),通過使用聚類算法對漿液循環(huán)泵工況指標進行工況劃分及最優(yōu)工況標記,實現(xiàn)漿液循環(huán)泵的工況庫建立,然后在實際運行時通過徑向基神經(jīng)網(wǎng)絡(luò)算法匹配歷史工況,預(yù)測工況的類別以及最低能耗,并進一步實現(xiàn)漿液循環(huán)泵系統(tǒng)的運行優(yōu)化。
2 基于聚類模型的工況劃分
在進行漿液循環(huán)泵優(yōu)化前,需要對漿液循環(huán)泵的運行數(shù)據(jù)進行工況劃分及標記,這樣才能實現(xiàn)運行工況的預(yù)測及優(yōu)化。本文中使用Kmeans聚類算法對漿液循環(huán)泵的工況指標數(shù)據(jù)進行聚類分析,實現(xiàn)漿液循環(huán)泵數(shù)據(jù)的工況劃分,仿真漿液循環(huán)泵不同情況下的運行工況。
工況劃分及工況標記:
劃分設(shè)備運行數(shù)據(jù)所采用的指標我們稱作為工況指標。獲取影響漿液循環(huán)泵運行的主要指標對應(yīng)的運行數(shù)據(jù),并對工況指標采用Kmeans聚類算法,將運行數(shù)據(jù)劃分為n個聚類簇,即得到n種工況,標記各個運行數(shù)據(jù)的工況類別。標記各個工況對應(yīng)的最優(yōu)工況,本文中最優(yōu)工況的確定方法為:尋找各個工況下最低能耗對應(yīng)的工況。
本文在進行工況劃分時,工況數(shù)n采用輪廓系法以及簇內(nèi)誤方差方法,綜合進行選取[2-4]。
通過以上過程對所有樣本進行運算,則完成了實驗用的工況庫的建立,工況庫中某條樣本的數(shù)據(jù)信息有:主要指標數(shù)據(jù)、工況類別標記以及對應(yīng)的最優(yōu)工況。
工況庫的有效建立,為實現(xiàn)漿液循環(huán)泵的工況識別和優(yōu)化操作,提供數(shù)據(jù)基礎(chǔ)和優(yōu)化依據(jù)。
3 預(yù)測優(yōu)化算法
3.1 徑向基神經(jīng)網(wǎng)絡(luò)算法概述
最常見的神經(jīng)網(wǎng)絡(luò)算法為:BP(back propagation)神經(jīng)網(wǎng)絡(luò),其結(jié)構(gòu)復(fù)雜,網(wǎng)絡(luò)參數(shù)多,耗時較長,這也限制了它的應(yīng)用場景。徑向基(Radial Basis Function,RBF)神經(jīng)網(wǎng)絡(luò)是一種前饋型神經(jīng)網(wǎng)絡(luò),結(jié)構(gòu)簡單、速度快、函數(shù)逼近能力強[6]。
與BP相比,RBF神經(jīng)網(wǎng)絡(luò)權(quán)值參數(shù)更少,以局部逼近網(wǎng)絡(luò)為基礎(chǔ),訓練耗時更短,應(yīng)用場景更加廣泛。
RBF神經(jīng)網(wǎng)絡(luò)一般有三層基本網(wǎng)絡(luò)結(jié)構(gòu)組成:輸入層、隱含層和輸出層,其中隱含層由徑向基函數(shù)組成,RBF神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)如圖1所示。
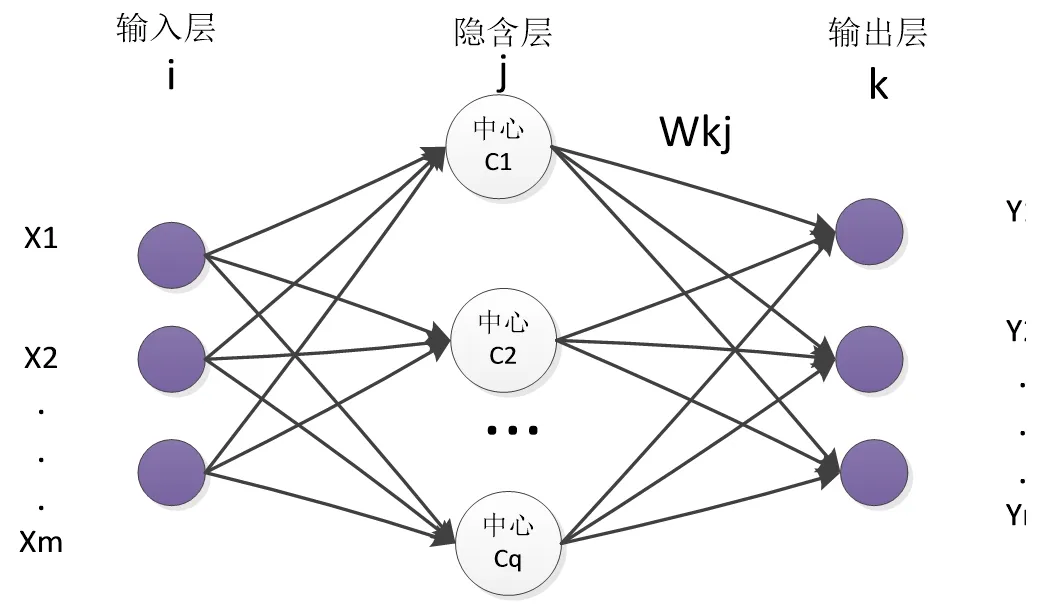
圖1 徑向基神經(jīng)網(wǎng)絡(luò)模型
RBF網(wǎng)絡(luò)的輸入層作用為:輸入數(shù)據(jù),并且數(shù)據(jù)不需要進行復(fù)雜運算,可以直接進入隱含層。因此輸入層和隱含層之間可以看作權(quán)值為1的連接。
隱含層與輸出層之間的數(shù)據(jù)連接采用組合方式,在進行網(wǎng)絡(luò)訓練時需要對相關(guān)的連接權(quán)值矩陣W進行調(diào)整。
由此可見,輸入層和隱含層之間的運算過程可以看作是非線性運算,而隱含層間和輸出層之間的運算可看作是線性運算[7]。
3.2 RBF分類建模步驟
RBF神經(jīng)網(wǎng)絡(luò)隱含層每個神經(jīng)元計算一個核函數(shù)[3],然后所有單元加權(quán)后輸出計算結(jié)果,構(gòu)成網(wǎng)絡(luò)的輸出。RBF 神經(jīng)網(wǎng)絡(luò)模型的參數(shù)向量包括:每個核函數(shù)的中心c,權(quán)值矩陣W,每個核函數(shù)的寬度δ。
網(wǎng)絡(luò)模型的訓練過程實質(zhì)上是訓練得到網(wǎng)絡(luò)的最優(yōu)參數(shù),其基本步驟如下:
假設(shè)神經(jīng)網(wǎng)絡(luò)輸入層神經(jīng)元為m個,隱含層神經(jīng)元為q個,輸出層神經(jīng)元個數(shù)為n。
i代表輸入層某個數(shù)據(jù),j代表隱含層某個神經(jīng)元數(shù)據(jù),k代表輸出層某個神經(jīng)元數(shù)據(jù)。
步驟1:設(shè)置輸入和輸出
選取訓練樣本的主要指標數(shù)據(jù),并作為輸入向量X=[X1,X2...Xm],m為輸入層神經(jīng)元的個數(shù),代表輸入樣本的特征或輸入指標的維數(shù)。
設(shè)置輸出向量Y=[Y1,Y2...Yn],若目標問題為回歸問題,則Y為連續(xù)值,若問題為分類問題,則Y為離散值,n代表輸出層的單元數(shù),本文中的目標問題為分類,因此輸出為離散值。
步驟2:初始化參數(shù)
初始化權(quán)重矩陣W
初始化某個權(quán)重值如下:

其中min和max分別對應(yīng)為某個輸出神經(jīng)元的期望輸出的最小、最大值,β為系數(shù)值,一般該值設(shè)置為1。
初始化神經(jīng)元的中心
初始化每個神經(jīng)元的中心,某個中心的計算如下:

其中minF,maxF分別對應(yīng)輸入的樣本數(shù)據(jù)的第i(i<=m)個指標或特征的最小、最大值。
(3)初始化寬度參數(shù)D

其中γ(γ<1)稱作為寬度調(diào)節(jié)系數(shù),該系數(shù)設(shè)置的主要目的是調(diào)節(jié)局部信息的感受能力。
步驟3:計算隱含層每一個神經(jīng)元的輸出
對于某個神經(jīng)元來說,其輸出結(jié)果為:

步驟4:計算輸出層每一個神經(jīng)元的輸出
對于某個神經(jīng)元來說,其輸出結(jié)果為:

步驟5:迭代訓練
設(shè)置目標損失函數(shù),采用梯度下降法迭代運算,調(diào)節(jié)網(wǎng)絡(luò)模型的參數(shù),直到算法收斂,最終中心、寬度和連接權(quán)重參數(shù)調(diào)節(jié)到最佳,則完成了網(wǎng)絡(luò)模型的整個訓練過程。
3.3 預(yù)測優(yōu)化
系統(tǒng)實際運行時,通過匹配實際運行數(shù)據(jù)與工況庫歷史數(shù)據(jù),預(yù)測實時運行工況可調(diào)節(jié)的最優(yōu)工況,并提出操作指導(dǎo)建議,指導(dǎo)漿液循環(huán)泵的調(diào)節(jié)運行,降低能耗值。
具體運算過程為:
(1)訓練過程:基于訓練樣本使用RBF神經(jīng)網(wǎng)絡(luò)訓練工況分類模型,輸入為影響漿液循環(huán)泵運行的主要指標數(shù)據(jù),輸出為工況類標記。
(2)實際運行過程:使用訓練好的RBF工況分類模型,輸入影響漿液循環(huán)泵運行的主要指標實時數(shù)據(jù),預(yù)測輸出實時樣本數(shù)據(jù)的工況類別,根據(jù)工況類別,查詢已建立的工況庫,并輸出所屬工況對應(yīng)的最優(yōu)工況,根據(jù)最優(yōu)工況的指標調(diào)節(jié)漿液循環(huán)泵的實際運行,從而實現(xiàn)對漿液循環(huán)泵系統(tǒng)設(shè)備的調(diào)節(jié)優(yōu)化。
4 實驗及運行
本文實驗數(shù)據(jù)來源于某電廠的脫硫系統(tǒng)實際運行數(shù)據(jù),利用Kmeans聚類算法進行工況劃分,利用RBF分類建立分類模型,實現(xiàn)預(yù)測優(yōu)化。該電廠的脫硫系統(tǒng)有A、B、C、D、E、F共計6臺漿液循環(huán)泵。
4.1 實驗設(shè)計
(1)數(shù)據(jù)來源。從數(shù)據(jù)庫中獲取影響漿液循環(huán)泵系統(tǒng)實際運行的主要指標的2個月的實驗數(shù)據(jù),數(shù)據(jù)采集時間段為:2017年8月1日-2017年9月31日,采集頻率為5分鐘。
(2)數(shù)據(jù)處理。
①指標篩選及加工。選取與漿液循環(huán)泵運行密切相關(guān)的指標測點,并根據(jù)指標特點進行加工處理,例如對相同位置指標取均值。最后得到入口二氧化硫折算濃度、吸收塔出口煙氣折算流量以及吸收塔液位等指標以作為運行工況的主要指標,各個漿液循環(huán)泵的電流作為能耗指標進行實驗。
②數(shù)據(jù)預(yù)處理。數(shù)據(jù)質(zhì)量影響數(shù)據(jù)模型的精確性,在進行數(shù)據(jù)建模前,對原始實驗數(shù)據(jù)進行數(shù)據(jù)清洗等工作以保障數(shù)據(jù)符合實驗要求。
根據(jù)脫硫系統(tǒng)實際運行,對實驗數(shù)據(jù)進行缺失值檢測,并刪除有缺失記錄的樣本;
依據(jù)運行專業(yè)人員經(jīng)驗結(jié)合運行規(guī)程給出主要指標正常運行情況的閾值,根據(jù)閾值過濾篩選含異常數(shù)據(jù)的樣本;
然后采用0-1歸一化方法對實驗數(shù)據(jù)的主要指標數(shù)據(jù)進行歸一化處理,以消除不同指標不同量綱對下一步數(shù)據(jù)分析及建模的影響。
經(jīng)過數(shù)據(jù)處理,共計刪除2135條樣本。
(3)最優(yōu)工況數(shù)選取及Kmeans工況劃分。
①最優(yōu)工況數(shù)選取。若劃分的工況數(shù)過小,則操作指導(dǎo)建議過粗,這將導(dǎo)致優(yōu)化指導(dǎo)的意義不大;若劃分的工況數(shù)過大,每個工況下樣本數(shù)目少,則操作指導(dǎo)過細,這也不利于優(yōu)化指導(dǎo)的進行,因此合理的工況數(shù)至關(guān)重要。結(jié)合實際運行,我們選取聚類數(shù)目為2-15,通過計算不同聚類數(shù)下的簇內(nèi)誤方差和輪廓系數(shù)值,選取最優(yōu)聚類數(shù)目進行聚類分析。
簇內(nèi)誤方差,一般來說越小越好;輪廓系數(shù)值,一般選取發(fā)生畸變幅度最大的點。
②Kmeans工況劃分。聚類數(shù)目即上一步選取的最優(yōu)工況數(shù)。采用機組負荷、出口二氧化硫折算濃度、入口二氧化硫折算濃度、以及吸收塔出口煙氣折算流量4個指標作為聚類指標將實驗數(shù)據(jù)聚類,即根據(jù)劃分工況的指標,對處理后的實驗主要指標數(shù)據(jù)采用Kmeans進行工況劃分,并標記各個工況的類別。
(4)自動標記工況最優(yōu)值。由于該電廠的6臺漿液循環(huán)泵為相同規(guī)格,一定程度上6臺泵的電流之和能反映出泵的電耗水平。因此,計算各個樣本的漿液循環(huán)泵電流之和Ihe,并作為“能耗值”,以此來代表漿液循環(huán)泵的電耗水平。
計算并標記各類工況下的最優(yōu)工況,計算各類工況下Ihe,并尋找最小的Ihe對應(yīng)的工況,作為最優(yōu)工況,而該工況對應(yīng)的能耗為最優(yōu)電耗。通過以上過程,則建立好了實驗數(shù)據(jù)使用的工況庫。
(5)分類預(yù)測模型。將處理好的實驗數(shù)據(jù)分成訓練數(shù)據(jù)和測試數(shù)據(jù),隨機選取實驗數(shù)據(jù)的70%為訓練數(shù)據(jù)作為RBF分類模型訓練用,剩余的30%樣本為測試數(shù)據(jù)作為進行RBF分類模型驗證用,亦用于模擬實時運行的過程。
訓練過程:輸入為主要指標,輸出為工況類標記,訓練RBF分類器。
預(yù)測及優(yōu)化運行過程,即測試過程:輸入主要指標,預(yù)測工況類別,查詢工況庫該工況類別的最優(yōu)能耗值作為預(yù)測能耗值,并指導(dǎo)漿液循環(huán)泵運行調(diào)節(jié),達到最優(yōu)能耗值。
4.2 實驗結(jié)果展示及分析
(1)工況劃分結(jié)果展示。
圖2展示了實驗數(shù)據(jù)在不同聚類數(shù)目即不同簇數(shù)量下對應(yīng)的簇內(nèi)誤方差結(jié)果曲線。

圖2 不同聚類數(shù)的簇內(nèi)誤方差
圖3展示了實驗數(shù)據(jù)在不同聚類數(shù)目即不同簇數(shù)量下對應(yīng)的輪廓系數(shù)值結(jié)果曲線。
從圖3中可以看出,輪廓系數(shù)值發(fā)生較大畸變的點對應(yīng)的聚類數(shù)有4、10以及14。從圖2中可以看出,聚類數(shù)越大,簇內(nèi)誤方差越小,即聚類數(shù)越大越好。綜合輪廓系數(shù)值以及簇內(nèi)誤方差值,本實驗中我們選取最優(yōu)聚類數(shù)目為14,然后對實驗數(shù)據(jù)進行工況劃分。
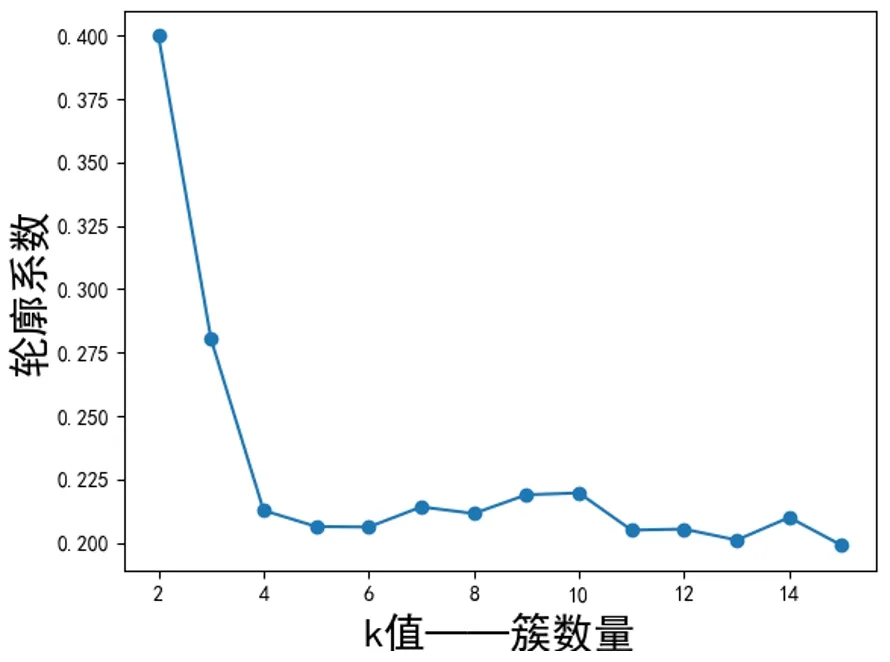
圖3 不同聚類數(shù)的輪廓系數(shù)
(2)預(yù)測及優(yōu)化。圖3展示了測試樣本的原始能耗值以及預(yù)測能耗值對比曲線圖。原始能耗值為樣本的真實能耗值,預(yù)測能耗值為通過本文實驗?zāi)P皖A(yù)測的樣本可參照調(diào)節(jié)的最優(yōu)能耗值。
由實驗結(jié)果圖可明顯看到,預(yù)測能耗比原始能耗明顯降低。
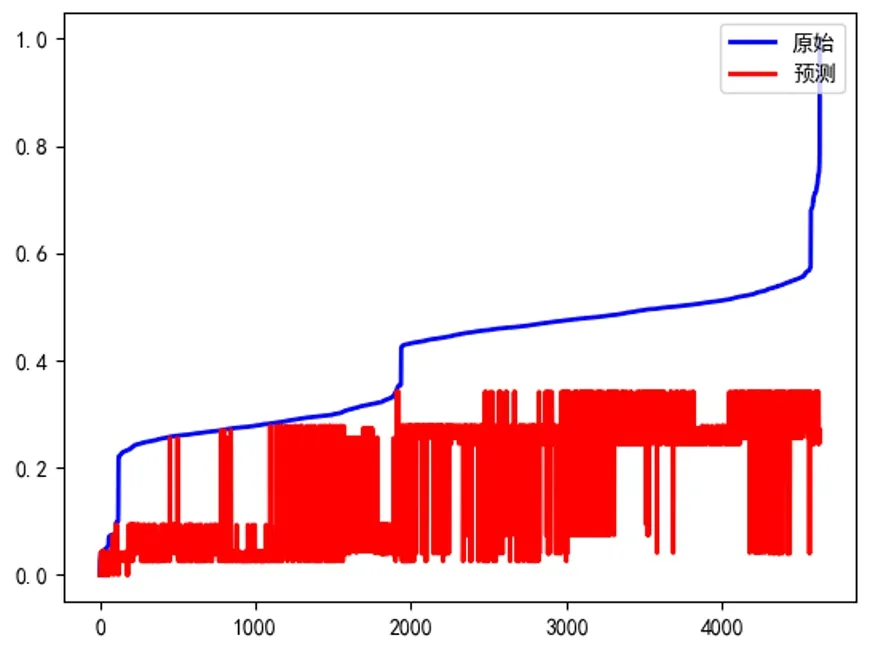
圖4 原始能耗及預(yù)測能耗值
通過以下公式計算測試樣本的節(jié)能水平:

其中y為所有樣本的原始能耗總和,y′為所有樣本的預(yù)測能耗綜合。通過公式(6)計算測試樣本的節(jié)能水平得到結(jié)果為56.11%,由此實驗結(jié)果表明:如果根據(jù)預(yù)測能耗調(diào)整漿液循環(huán)泵實際運行,漿液循環(huán)泵能耗能降低大概56.11%的能耗。
5 結(jié)語及展望
本文研究了脫硫優(yōu)化系統(tǒng)的建設(shè),基于Kmeans算法對漿液循環(huán)泵進行工況劃分及工況庫建立,然后在實際運行時基于工況庫通過RBF算法,預(yù)測工況的類別以及工況的最低能耗,實現(xiàn)漿液循環(huán)泵系統(tǒng)的運行優(yōu)化,實驗結(jié)果展示本方法可以取得較好的經(jīng)濟效益。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
