基于動態概率抽樣的標簽噪聲過濾方法
2022-01-05 02:31:22張增輝姜高霞王文劍
計算機應用 2021年12期
張增輝,姜高霞,2,王文劍,2*
(1.山西大學計算機與信息技術學院,太原 030006;2.計算智能與中文信息處理教育部重點實驗室(山西大學),太原 030006)
(?通信作者電子郵箱wjwang@sxu.edu.cn)
0 引言
噪聲可以被定義為由與產生數據分布無關的外生因素引起的對數據項收集的信息的部分或全部改變[1]。對于分類任務,一般噪聲按照其出現的位置可以劃分為兩類:特征噪聲和標簽噪聲[2]。噪聲的存在對建模產生許多影響,其中特征噪聲的分量在統計上彼此更加獨立,并且大多數的分類器在面對特征噪聲時更加魯棒[3],而有研究表明,由標簽噪聲引入的偏差更大,因此通常情況下它比特征噪聲具有更大的破壞力[4],會導致模型復雜度增加,分類精度下降,并且更容易出現過擬合現象[5]。然而,無論是特征中出現噪聲還是標簽中出現噪聲,機器學習算法都會將其看做標簽噪聲[6]。因此,標簽噪聲的處理成為近些年來亟待解決的機器學習問題之一。
現有的處理標簽噪聲的方法可以劃分為三大類:修改現有模型使其對標簽噪聲具有魯棒性,構建基于模型預測的標簽噪聲過濾器,以及標簽噪聲校正方法。雖然對算法本身進行魯棒性改進可以使學習器直接處理帶有標簽噪聲的數據,但這樣的方式不適用于所有學習方法,因此,使用基于模型預測的標簽噪聲過濾器對樣本進行預處理的方式更為常見。過濾器是通過模型預測的方式識別樣本集中的潛在噪聲并將其移除的方式來提高樣本質量。
從模型的角度來看,標簽噪聲過濾方法主要通過基于集成的方法、基于迭代的方法和基于分區的方法來實現。其中多分類器的集成使用最廣泛,集成分類器方法分為同質集成和異質集成。MVF(Majority Vote Filter)[7]和CVF(Consensus Voting Filter)[8]均屬于異質集成分類器;HARF(High Agreement Random Forest Filter)[9]則由多棵C4.5 決策樹集成而得,是同質集成分類器的典型代表。迭代方法是將上一次分類結果作為下一階段訓練的輸入,直至達到事先規定的迭代跳出條件為止,代表算法有IPF(Iterative Partition Filter)[10]和 INFFC(Iterative Noise Filter based on Fusion of Classifiers)[11]。分區的思想主要是針對大型數據集或分布式數據集,將訓練集劃分為多個子模塊分別訓練,再將訓練結果匯總投票[12]。若將過濾過程抽象為一個抽樣過程,標簽噪聲過濾器方法可以分為0-1 抽樣方法和概率抽樣方法。現有的經典過濾算法CVF、MVF 和HARF 等均屬于0-1 抽樣,即給定確定閾值,依據閾值和集成算法的投票結果的大小關系過濾潛在的噪聲樣本。這種傳統的0-1 抽樣方式無法精確表達不同樣本之間的差異性,因此,近年來有學者創造性地提出了概率抽樣的思想,即為每一個樣本提供一個概率,這個概率指的是該樣本為干凈樣本的可能性大小,將這個概率作為依據,抽樣得到干凈樣本集,代表算法有PSAM(Probabilistic Sampling)[13-14]和局部概率抽樣(Local Probability Sampling,LPS)[15],利用多分類器集成投票獲取樣本置信度,全區間隨機生成閾值進行抽樣。概率抽樣的思想能夠有效利用置信度區分同一數據集內部樣本與樣本之間的差異性,但是仍然無法避免人為設置閾值區間的主觀性,且現有的概率抽樣方法對不同數據集采用相同的過濾策略,忽視了數據集之間的差異性,影響了過濾器在不同數據集上的噪聲識別性能。
本文了提出一種動態概率抽樣(Dynamic Probability Sampling,DPS)的標簽噪聲過濾算法。在本文算法中,通過統計樣本的標簽置信度在區間內的分布頻率,分析置信度分布頻率的信息熵走勢變化來決定進行概率抽樣的樣本范圍。由于不同數據集之間置信度分布差異巨大,置信度分布頻率的信息熵走勢差異明顯,因此本文算法能夠敏銳探測不同數據集之間樣本差異性,合理規劃閾值區間,以達到較強的標簽噪聲識別能力。
1 DPS算法
1.1 置信度分布分析
對于一個可能存在標簽噪聲的樣本集DT,為了獲取每個樣本的可信程度,有效區分樣本之間的差異性,應對其每個樣本合理估計其標簽置信度。隨機森林(Random Forest,RF)模型集成了多棵決策樹,其隨機過程有效地解決了決策樹容易產生的過擬合問題,并且置信度的精度可以通過集成決策樹的數量靈活調整,模型中集成的決策樹越多,最終估計出的標簽置信度精度越高。因此本文推薦使用隨機森林模型對樣本進行置信度估計。計算方法為:
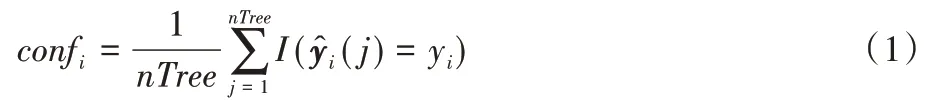
其中:confi表示樣本集DT中某一樣本的標簽置信度,nTree為模型中集成的決策樹個數;表示模型對訓練集樣本的預測標簽向量,表示向量的第i個元素。
從預測準確性來看,隨機森林由多個彼此獨立的決策樹集成,因此,它的預測結果比基模型非獨立的集成模型更準確;其次,隨機森林中的隨機過程可以有效解決單一決策樹中的過擬合問題;除此之外,在評估置信度的過程中,nTree越大,標簽置信度的差異就越細化,因此nTree可以調節清潔度差異的細化程度;最后,對于這樣基于最大似然估計的方法,實驗次數越多,置信度估計就越準確。
標簽置信度雖然能夠合理展現出樣本標簽的可信賴程度,但是由于數據集之間的差異性,使得數據集的標簽置信度分布也具有很大的差異。圖1 和圖2 分別展示了在理想情況下置信度分布和實際情況下各個數據集的置信度實際分布(各個數據集的詳細描述見3.1 節)。在理想條件下,使用集成分類模型計算樣本的標簽置信度時,每一個基分類器都能夠準確預測樣本的真實標簽,因此,干凈樣本的標簽置信度均為1,噪聲樣本的標簽置信度均為0。然而由于在計算標簽置信度時分類器本身存在一定的誤差,且不同的樣本分布情況也影響著分類器的預測結果,因此,實際各個數據集的標簽置信度往往與理想情況相差甚遠。
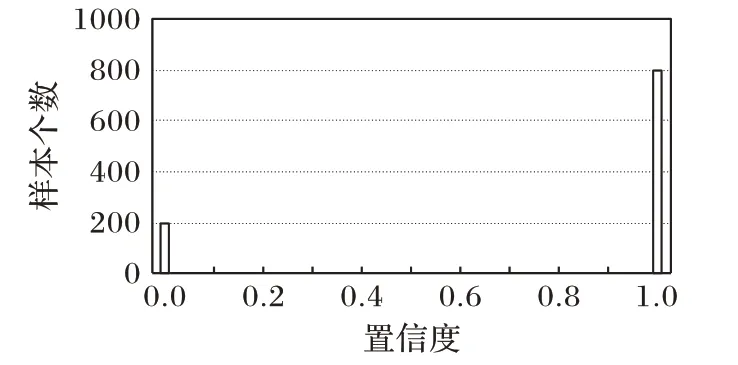
圖1 理想情況下的置信度分布Fig.1 Confidence distribution in ideal condition
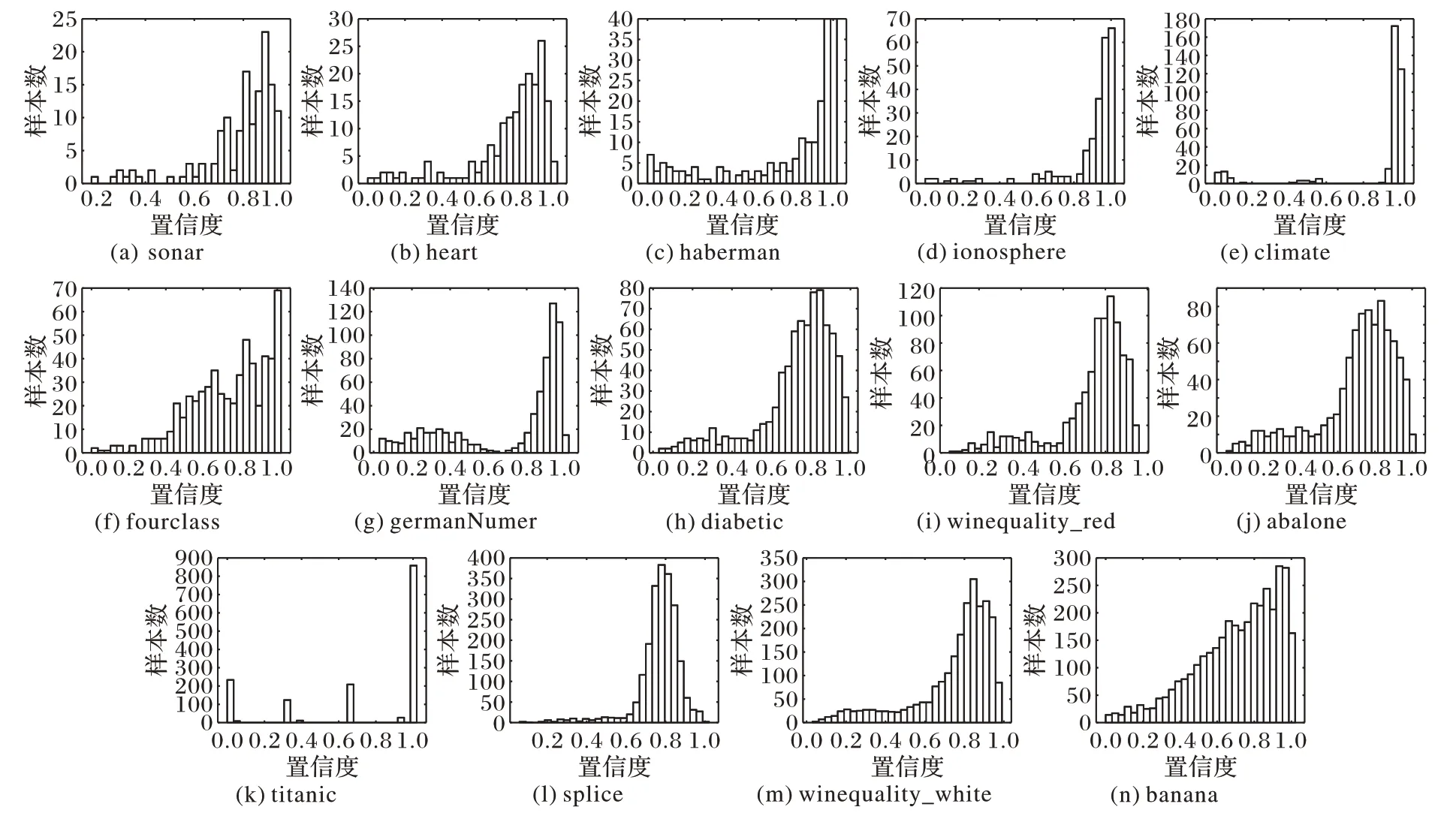
圖2 不同數據集置信度分布Fig.2 Confidence distribution of different datasets
顯然,在置信度分布差異巨大的情況下,針對各種置信度分布的數據集采用一致的標簽噪聲過濾策略是不可行的,因此,本文提出的DPS 算法使用信息熵對樣本的標簽置信度分布情況進行分析。
信息熵被定義為離散隨機事件的出現頻率,是數學上一個用于衡量信源的不確定度的抽象概念,信息熵越小,表示信源不確定性越低。在本文的問題中,將樣本的標簽置信度的值看作隨機變量X,X的取值范圍為[0,1]。將[0,1]平均劃分為b份,有b+1,那么P(x∈(xi,1])為b個隨機事件發生的概率,統計b個隨機事件出現的頻率并計算信息熵,公式為:
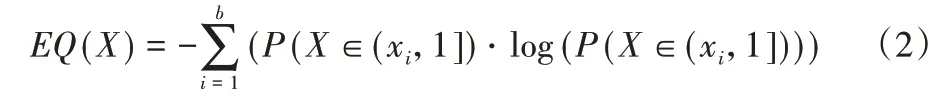
隨機變量X的信息熵EQ(X)是一個單調遞減函數,隨著i的增加,區間(xi,1]逐漸減小,此時EQ(X)減小,意味著X事件的確定性逐漸增大,因此,尋找EQ(X)一階差分最小值點e,在e點處EQ(X)下降速度最快,此時將e更新為閾值選擇區間的右端點。EQ(X)在e點處下降速度最快意味著不確定性流失最快。
然而,此時的e點并不是最終要尋找的最佳臨界點,最佳臨界點應該選取信息熵開始大幅下降的瞬間,也就是信息熵EQ(X)的拐點處,因此,最佳臨界點應該滿足兩個條件:1)在信息熵EQ(X)產生大幅下降的點(即一階差分最小值點)之前;2)處在EQ(X)的某一拐點處。此時從e點出發向前搜索,繼續尋找EQ(X)二階差分最小值,就能夠找到最佳臨界點。事先尋找EQ(X)下降最快的點而不直接尋找拐點的原因是,無法確定拐點只有一個,部分數據集的信息熵EQ(X)可能存在兩個或多個拐點,先利用一階差分更新點e能夠縮小拐點尋找范圍,避免最佳臨界點的尋找陷入局部最優。
尋找到最佳臨界點e后,令e的橫坐標xe作為閾值區間的右端點,xe-w為左端點,w為進行概率抽樣的范圍,此時就得到了最優閾值區間[xe,xe-w],利用局部概率抽樣的方式,在區間內隨機生成閾值r,利用閾值r和每個樣本的標簽置信度的大小關系對樣本進行識別。由于概率抽樣方法基于最大似然估計,因此需要進行多次的獨立重復實驗,抽樣過程連續進行SamplingNum次,匯總最終各個樣本的識別結果進行過濾。
1.2 DPS算法
根據1.1 節中的描述尋找最佳臨界點后,在閾值區間中利用概率抽樣的方式進行標簽噪聲的過濾,得到DPS 算法。DPS算法的主要步驟如下:
輸入 初始樣本集DT;
參數 隨機森林集成的決策樹個數nTree,置信度劃分區間個數b;
輸出 預測標簽集L。
步驟1 利用隨機森林模型構建nTree棵決策樹投票獲得訓練集DT中每個樣本的標簽置信度confi。
步驟2 將置信度區間[0,1]平均劃分成b個子區間[xi,xi+1],統計置信度處于各個子區間的概率,并通過式(2)計算置信度處于不同區間的信息熵EQ(xi)。
步驟3 計算EQ在每個xi處的一階差分FD(xi),將最佳臨界點e更新為FD的最小值點。
步驟4 計算EQ在每個xi處的二階差分SD(xi),從e出發向前搜索,尋找到SD的極小值點xe,此時最佳閾值區間為[xe-0.2,xe]。
步驟5 在[xe-0.2,xe]區間內隨機生成閾值r,保留conf值高于r的樣本構成干凈樣本集CT,剩余樣本被標記為噪聲。基于CT構建分類器hj。
步驟6 重復步驟1~5 共SamplingNum次,最終構建SamplingNum個分類器hj,對訓練集樣本進行過濾。
在DPS 算法中,構建隨機森林模型的時間復雜度為O(nTree?N?C?log(N)),置信度計算的時間復雜度為O(nTree?N),在對置信度分布分析的過程中,時間復雜度為O(b),最終過濾過程的時間復雜度為O(N),上述的各個過程均為串行,且重復進行了SamplingNum次,因此,DPS 算法總體時間復雜度為O(SamplingNum?nTree?N?C?log(N))。
2 實驗結果與分析
2.1 實驗數據與實驗環境
本文在14 個經典UCI 數據集上驗證本文DPS 算法的有效性,數據集描述見表1。為避免不平衡數據對分類性能的影響,對winequality_red 和winequality_white 抽取了其中的第5 和第6 類,對abalone 抽取了其中的第9 類和第10 類。數據的平滑、擬合以及實驗部分均在Matlab環境下實現。
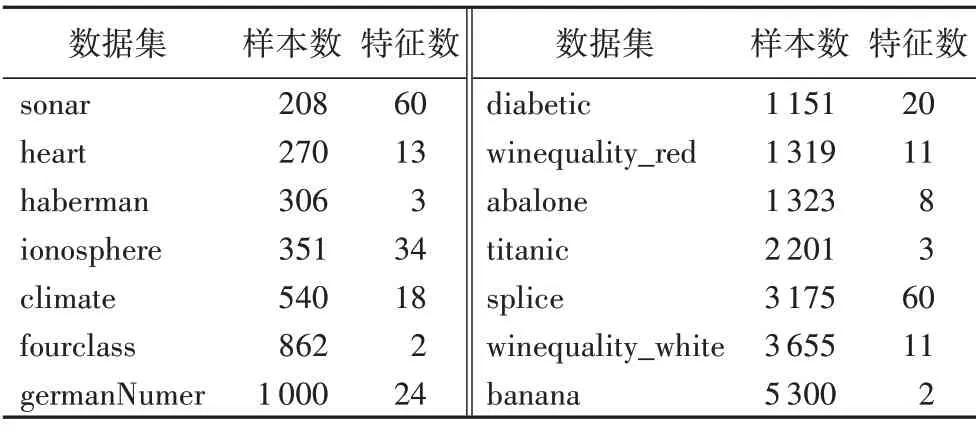
表1 實驗數據集描述Tab.1 Experimental dataset description
2.2 數據設計
實驗前先將數據集劃分為兩個部分,取其中2/3作為訓練集,剩余1/3作為測試集。將訓練集按照實驗要求隨機加入噪聲,即隨機改變一定比例樣本的原始標簽。在對比實驗中,選取四種標簽噪聲過濾算法與DPS 算法進行比較,分別是隨機森林(RF)、MVF、HARF和LPS,其中:RF、HARF和LPS都是基于隨機森林提出的方法,在構建森林時構建決策樹的數量均為500;MVF 是異質集成分類器,由3NN、樸素貝葉斯、隨機森林三種模型集成而得;HARF的閾值設置為0.7;LPS和DPS的抽樣次數設置為11。在標簽噪聲過濾后將保留下的樣本利用隨機森林訓練為一個分類器對測試集進行分類,以該分類結果判斷該標簽噪聲過濾算法的分類泛化性能。為避免實驗隨機性的影響,實驗結果均為重復10次求取的平均值。
本文中對比實驗指標使用了識別準確率Acc(Accuracy)、召回率Re(Recall)、查準率Pre(Precision)、F1和Classif(分類準確率),具體計算方式如下:

其中:TP表示實際標簽和預測標簽均為正類的樣本數;FP表示實際標簽為負類,預測標簽為正類的樣本數;TN表示實際標簽和與預測標簽均為負類的樣本數;FN表示實際標簽為正類,預測標簽為負類的樣本數。
2.3 實驗結果與分析
2.3.1 信息熵走勢分析
本組實驗主要驗證信息熵走勢對探索最佳臨界點的有效性。圖3展示了在14個數據集下,由式(2)計算出的信息熵的一階差分圖隨置信度的變化情況,為避免局部內的微小波動對實驗造成的影響,將原信息熵一階差分函數利用三次樣條插值進行平滑處理,圖3為處理后的一階差分曲線。從圖3中可以看出,不同數據集的信息熵差分的走勢差異很大,但它們也存在一些共同點:在所有數據集的信息熵一階差分圖像中,函數值在某一點或某個小區間內會出現至少一次大幅度下降。這是因為橫坐標每向右移動一個點,就會損失一個置信度子區間中所包含的信息量,當移動到某點,函數值出現大幅下降時,說明當損失該置信度子區間的信息量時,獲取到的信息的不確定性驟降,因此,最佳臨界點應當出現在該點附近。然而,對于部分數據集,信息熵差分極小值點不止一個,針對這樣的情況,則選取最小值點,即信息熵下降最快的點作為探索最佳臨界點的起點。
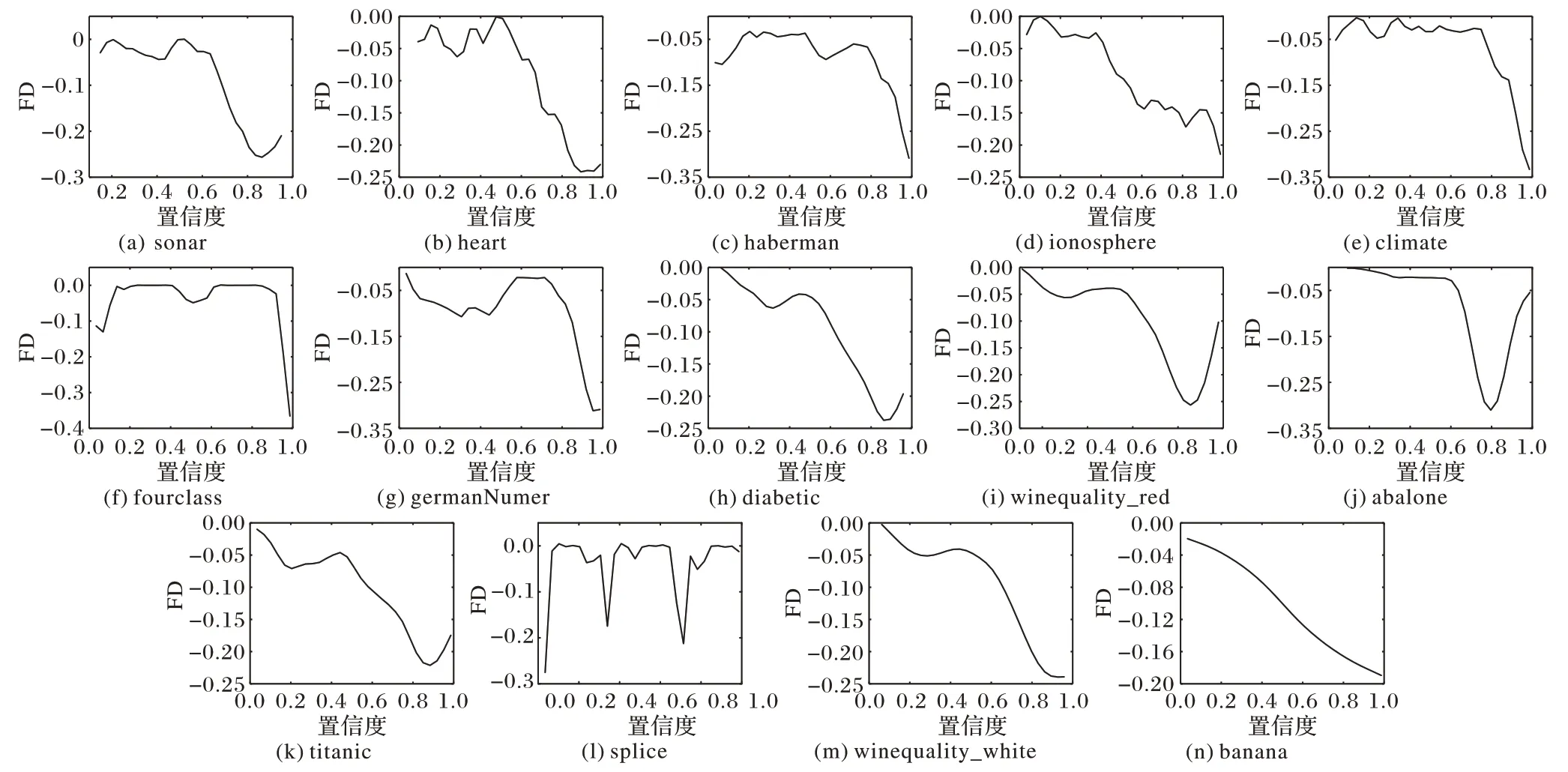
圖3 14個數據集的一階差分圖Fig.3 First-order difference graphs of 14 datasets
若直接將信息熵一階差分最小值點作為最佳臨界點,帶來的問題是損失大量有效信息。因為從圖3 中可以看出,對于部分數據集(如sonar、heart、diabetic、winequality_white 等),一階差分值都不是在某一點突然下降的,而是在某個區間內連續下降,且下降幅度都比較明顯,當一階差分下降到最小值時,信息已經產生較大損失。因此,為解決這樣的問題,應當利用二階差分尋找一階差分圖像的拐點作為最佳臨界點。
2.3.2 噪聲識別性能
本組實驗主要對比了DPS與RF、MVF、HARF 及LPS的噪聲識別能力,噪聲比例ratio從5%到30%,每次以5%的幅度遞增。圖4(a)展示了五個算法在14 個數據集下的噪聲識別準確率Acc的匯總結果,結果由不同噪聲比例下14 個數據集實驗結果的均值得來。五個算法中,RF、MVF、HARF為0-1抽樣算法,LPS、DPS是概率抽樣算法。從噪聲識別率來看,概率抽樣算法的噪聲識別能力明顯高于0-1 抽樣算法。DPS 算法因采用了動態過濾策略,其噪聲識別能力相比LPS 也有一定的提高,尤其在噪聲比例較低的情況下,噪聲識別能力的優勢更加明顯。
圖4(b)和(c)分別展示了五個算法在14個訓練集下噪聲識別的召回率和精確率,從圖中可以看出,DPS的召回率遠高于HARF 和LPS,且這三個算法的召回率幾乎不隨噪聲比例ratio的增長而變化,RF 和MVF 召回率較低且不夠穩定,隨ratio的變化比較明顯。從精確率來看,五個算法在噪聲比例為5%時幾乎沒有表現出差異,隨著ratio的增加,各個算法的精確率逐漸顯現出差異,其中,HARF 和DPS 下降速度較快,而MVF 的Pre指標在此時顯示出一定的穩定性,下降速度相比其他算法更加緩慢。從圖4(b)和(c)可以看出:DPS 和HARF 更傾向于保留干凈樣本,會不可避免地保留部分噪聲,因此精確率較低;而MVF 更傾向于過濾噪聲樣本,在過濾的過程中也會過濾掉部分干凈樣本,嚴重時還會造成過度過濾現象。
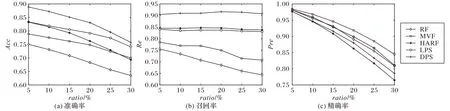
圖4 五種算法的Acc、Re和Pre指標對比Fig.4 Comparison of Acc Re and Pre of 5 algorithms
為綜合Re和Pre的實驗結果,圖5 展示了五個算法在14個數據集上的F1值,從圖中可以看出,在絕大部分情況下,HARF、LPS 和DPS 的F1值在不同的數據集上表現各有優勢,且明顯優于其他兩種算法。
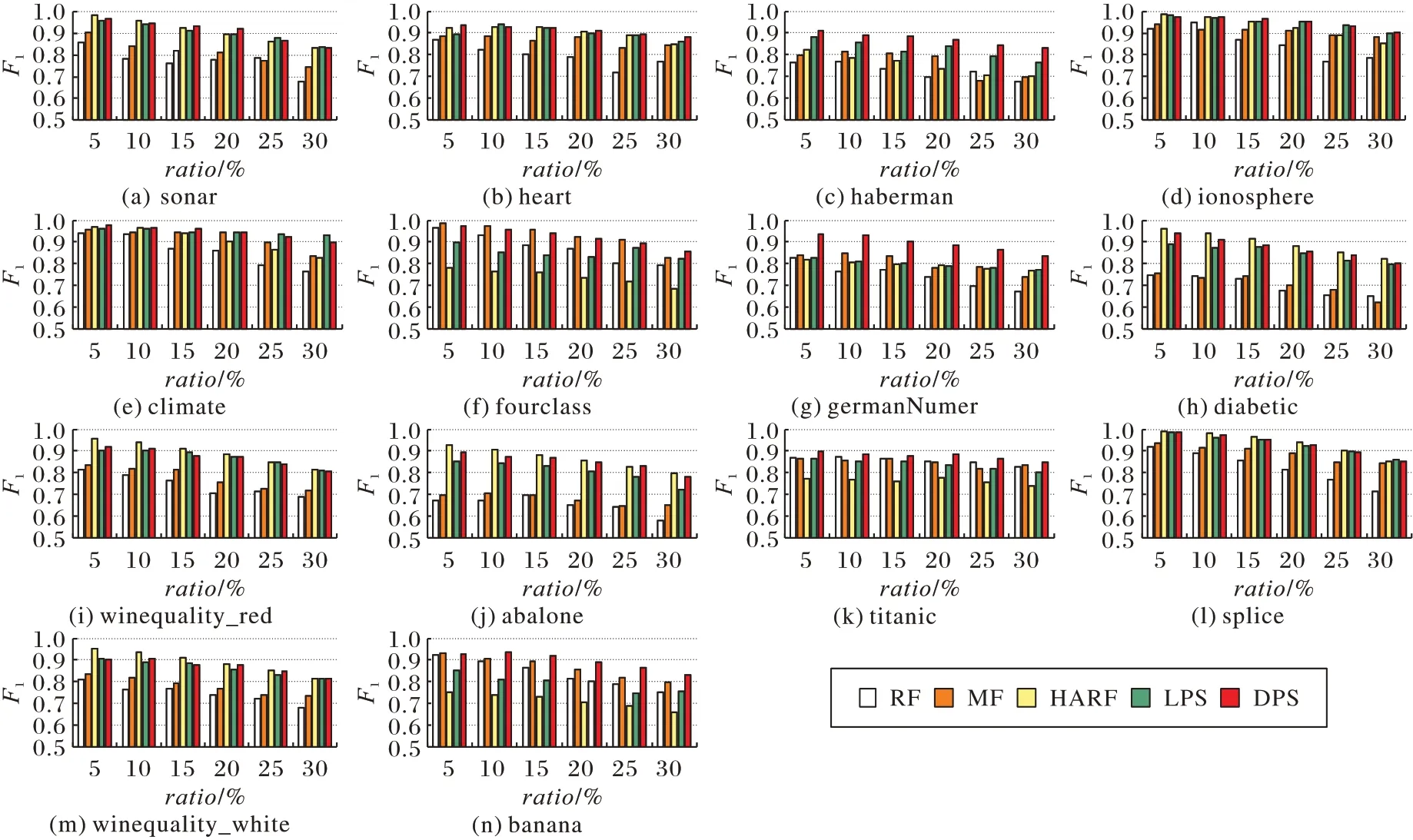
圖5 五種算法的F1指標對比Fig.5 Comparison of F1 of 5 algorithms
為了更好地比較五種方法的F1指標,圖6 對14 個數據集的F1指標求取平均值,總體來看,在F1指標下,概率抽樣方法仍然具有較大的優勢,其中DPS 的F1指標在各個噪聲比例下均能夠保持較高水平。
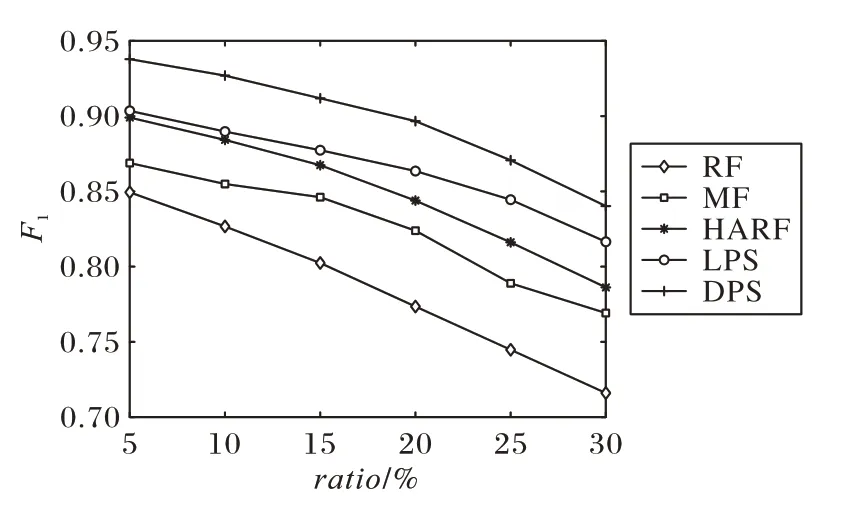
圖6 五種算法的F1均值對比Fig.6 Comparison of F1 mean value of 5 algorithms
2.3.3 分類性能比較
圖7 對比了五種算法在14 個數據集下的分類泛化能力,Classif越高,表示數據集在經由該算法過濾后,訓練出的分類器分類能力越好。從圖7 中可以看出,DPS 的分類準確率在大多數情況下比其他算法表現更好,在低噪聲的情況下,DPS更具優勢。除了DPS 外,LPS 在少部分數據集下的分類準確率也表現出了一定的優勢,而HARF 的分類能力相比其他算法表現最差。
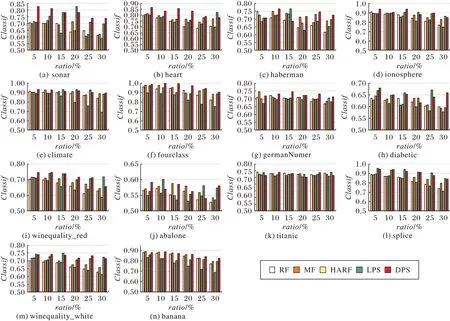
圖7 五種算法的Classif指標對比Fig.7 Comparison of Classif of 5 algorithms
14 個數據集Classif的平均值如圖8 所示,可以看出,隨著噪聲比例的增大,五個算法的Classif基本呈下降趨勢,其中DPS 下降速度最慢,且Classif指標最高,說明其概率抽樣方法受噪聲影響更小,魯棒性更高。
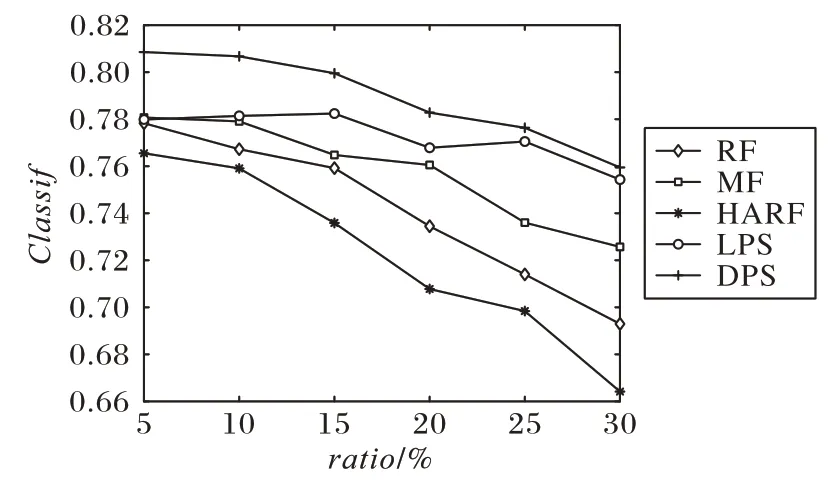
圖8 五種算法的Classif均值對比Fig.8 Comparison of Classif mean value of 5 algorithms
3 結語
本文主要針對置信度分布差異較大的各類數據集無法適應統一的標簽噪聲過濾策略的問題,提出了一種基于動態概率抽樣的標簽噪聲過濾方法,該方法通過統計不同數據集的樣本置信度出現的頻率來分析置信度的分布特點,利用此概率的信息熵尋找過濾的最佳臨界點,再結合概率抽樣的思想,在使得過濾器達到高識別率、高分類準確率的目標的同時,也增強了過濾器在不同數據集上的普適性。
