基于BERT信息抽取的電力客服知識圖譜構建方法
2021-12-31 01:20:04國網河南信通公司張向聰王冰潔何軍霞
電力設備管理 2021年13期
國網河南信通公司 張向聰 王 浩 王 磊 王冰潔 何軍霞
隨著智能電網的快速發展,在電力行業,人工智能正快速地與電網領域相結合,信息通信技術迅速集成到電網的生產和企業管理中。信息通信系統是支持生產和管理開發的智能網格的“中心神經”。在信息通信方面,電力管理客服中存在著很多系統,對每個系統問答知識匹配時,需要收集足夠多的問題以及對知識內容的存儲,傳統的關系型數據庫可以支撐問答系統,但是在存儲復雜的關系網絡時,關系型數據庫就表現得不如知識圖譜有效。之所以選擇知識圖譜,是因為人們在邏輯上通常很自然使用類似圖的結構來模擬或描述它們的特定問題域。知識圖譜最有效、最直觀地表達出實體間、問答間的關系。本次研究將提供一種基于BERT+BiLSTM+CRF[1]模型,從原始的操作手冊中抽取實體、實體關系以及問答對,構建電力客服知識圖譜[2]。
1 相關理論技術與研究
Bert(Bidirectional Encoder Representation from Transformers)[3]是一個預訓練模型。傳統的語言模型是把單向語言模型或者是把兩個獨立的語言模型在淺層進行一個拼接的方法進行預訓練,他強調的并不是這種傳統的語言,而是采用新的masked language model(MLM),以致能生成深度的雙向語言表征。Bert 論文發表時提及在11個自然語言處理任務中獲得到的新結果,比以往的模型表現的都要好,令人驚訝。
模型的介紹以及優點如下:采用MLM 對雙向的Transformers 進行預訓練,以生成深層的雙向語言表征;進行完預訓練之后,再疊加一個輸出層,進行fine-tune 操作,這樣就可以在不同的下游任務當中提取到它的state-of-the-art 表現。有一個好處就是在這整個的一個過程當中,不需要對模型的特定結構進行修改。
條件隨機場(Conditional Random Fields)[4]是一個判別式模型。在條件隨機場當中,有很多的特征函數,正是因為這些特征函數才使得序列進行了約束,得到一個條件概率,最后進行標注。比如在詞性標注任務當中,如果名詞后面還是名詞的話就是負分,在副詞后面是動詞的話就是正分等。
影視領域問答系統:利用知識圖譜的關系表達屬性,將收集的數據可以更加“擬人化”的存儲起來,再利用NLP 意圖識別的技術,可以很好地對電影、演員進行相關問答;知識圖譜推薦系統:通過知識圖譜的以擴展性以及本體連接性,將人物信息以本體形式存儲,將人與人之間、人與事物之間緊密聯系,可以實現相互信息的推薦與推理。
2 電力服務數據處理及BERT+BiLSTM+CRF 信息抽取
隨著計算機和互聯網的發展,我們已經從工業時代進入信息時代。人工智能的時代已經到來,知識圖譜是信息時代通用的深化應用和擴展。本次針對的是一體化線損管理系統,主要處理的數據是業務系統的操作手冊說明書,對于一般用戶問的問題基本上能查找到,但是如果本身不是業務人員,面對一系列的操作手冊,也會無從下手,不知如何精確找到相關答案。針對這類問題,是將操作手冊數據梳理成知識圖譜數據,配合意圖識別[5],就可以實現問答系統,實現用戶即使不是業務人員,也可以自己解決80%甚至更多的問題。
從電力知識獲取到圖譜構建整體流程如下:獲取電力系統中的一體化線損管理系統所有操作手冊,構建原始文檔庫;抽取操作手冊word 文檔數據,梳理成初步結構化數據,存儲至Excel 中;對一體化線損管理系統初步知識數據進行標注;基于BERT 模型,微調進行訓練,實現一體化線損管理系統結構化文檔數據的語義特征提取;基于BiLSTM+CRF 模型對語義特征進行實體識別,提取知識概念以及相互聯系,構建知識圖譜。
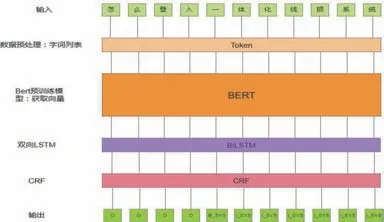
對Bert 進行fine-tune,在輸出層后疊加CRF層,這樣做的好處就是在這整個的過程當中,不需要對模型的特定結構進行修改。
輸入層:將句子輸入到模型中;數據預處理:將每個單詞映射到一個更高維度的空間,即字詞向量表征;Bert 層:bert 的主要框架是Transformer,使用的是一個雙向模型,所以可以更好地獲取到文本中的上下文關系,使用此模型來替代嵌入層;BiLSTM層:使用雙向LSTM 計算嵌入向量實際上是雙向LSTM 計算單詞向量,從而獲得更高級句子的向量。
CRF 層:CRF 通俗來說就是對結果的合理性進行過濾,因為標簽本身是存在一些約束的,比如在詞性標注時,名詞后面不能接名詞,CRF 就是用來添加類似這樣的約束,并且在訓練CEF 時可以自動學習這樣的約束。通過這一層,可以過濾掉一些不合理的結果,從而增加整體模型的準確率;輸出層:將上一層輸出的特征輸入到Softmax 層,就是對所有的預測類別進行打分,挑選其中最大的一個作為預測結果。
3 電力知識圖譜的構建與應用
構建知識圖譜的第一步,就是選擇知識圖譜的schema[6],不同schema 的知識圖譜對應解決不同的問題,由于是電力服務問答方面的數據,本身沒有很大的復雜性,所以我們采用三元組的形式將數據領域、關鍵字、問題、答案串聯起來。針對數據,主要的還是從中挑選哪些作為本體存儲,哪些作為屬性存儲。本體指的是某個領域內抽象概念的集合,它可以描述某個范圍內一切事物的共有特征以及事物間的關系。將數據按上所說形式生成CSV 文件,這樣可以更快地導入neo4j 圖數據庫中。對領域、關鍵字、問題、答案使用CSV 導入語句,將數據按照不同聯系統一導入neo4j 圖數據庫中。
知識圖譜構建成功后就可設計應用層面,本次構建的是關于一體化線損管理系統中的客服數據,所以此次圖譜設計的schema 主要是針對知識問答。知識問答又涉及到另一個模型了,就是意圖識別模型,在這里不做延伸,提供一個知識問答的構建思路。先要介紹一下Flask,因為在知識問答系統中,用它來和前后端傳輸數據,Flask 是由python 開發的輕量的web 框架,小巧,靈活,一個腳本就可以啟動一個web 項目,開發的難度比較大,flask 好多的模塊是按照django 的思路開發的。
知識問答的構建,首先是對實體識別、意圖識別兩個模型進行封裝,在調用模型時就更加方便,并且可以加快模型運算速速(模型只加載一次);然后是要對不同的意圖編寫不同的neo4j 查詢語句,這樣就可以對模型輸出的數據進行實時的查詢返回真實的數據;最后使用flask 將以上兩者整合,實現API 接口對傳進來的數據返回對應的查詢值。
4 結語
隨著信息化的進展,電力服務數據慢慢地積累了下來。通過構建電力服務[7]領域的知識圖譜,可以從龐大的數據中提取客服知識,并合理有效地管理、共享和應用,這對于今天以及未來的電力服務行業非常重要,對很多企業和研究機構來說也是研究的熱點。從知識圖譜的構建和應用的角度來看,本文實現了一體化線損管理系統知識圖譜的創建和應用。電力服務知識圖譜通過結合圖譜和客服知識,切實促進電力數據的自動化和智能處理,為電力行業帶來新的發展機會。知識圖譜很有發展前景,現在在社會中的很多領域都慢慢和人工智能聯系起來。在如今這個計算機、網絡、大數據、人工智能、機器學習等前沿科技迅速發展的大潮流下,相信知識圖譜的研究可以有更多的創新和突破!
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
