多機器人智能化協同技術研究進展
2021-12-31 09:22:56張迎雪陳金寶陳傳志
載人航天 2021年6期
張迎雪, 陳 萌,2*, 陳金寶, 陳傳志
(1.南京航空航天大學航天學院, 南京 211106; 2.上海宇航系統工程研究所, 上海 201109)
1 引言
機器人技術多機系統突破了單個機器人負載和數據處理等方面的瓶頸,可加快執行速度,提高效率,并具有更強的環境適應能力和容錯能力。協作是多機系統特色,系統中多個機器人既相互制約又相互配合[1],實現了“1+1>2”的效果。 團隊中的異構機器人通過優勢互補,為系統提供更豐富的解決方案,不僅滿足多變的環境和嚴苛的需求,還可以降低整體制造成本,目前已被應用于工業自動化、軍事國防、救援搶險、深空探測等眾多領域[2-3]。
多機協同的系統架構主要分為集中式、分布式和混合式共3 種,詳細對比見表1。
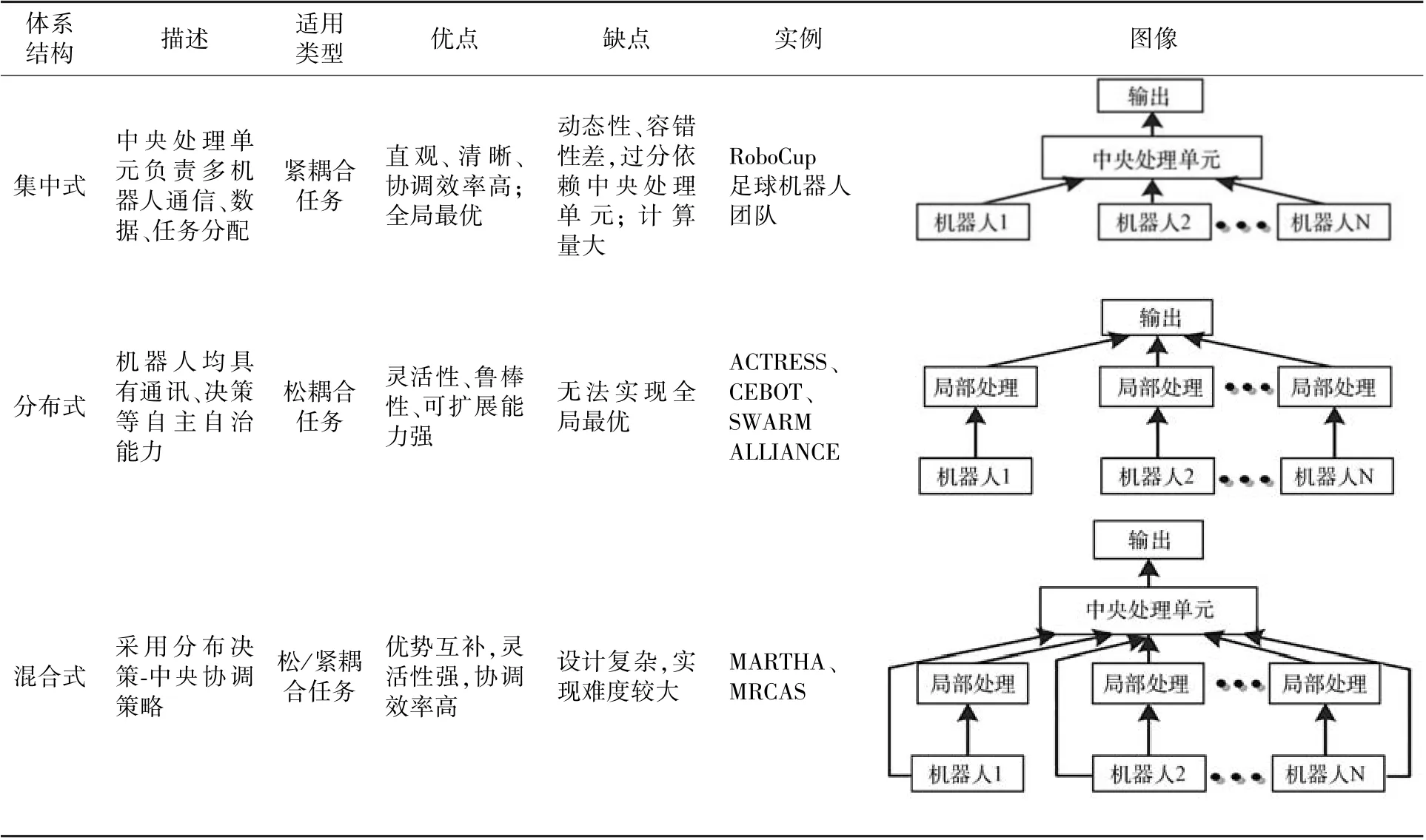
表1 多機協同體系結構Table 1 Architecture of multi-robot cooperative system
多機協同是集合多種功能于一體的復雜系統。 其中,同步定位與地圖構建(Simultaneous Localization And Mapping,SLAM)是多機系統完成全自主移動的前提條件和復雜探索的必要基礎;路徑規劃、任務分配是異構多機器人實現智能化探測和作業的核心關鍵技術;多機系統與強化學習的結合是未來多機協同發展的必然路徑。 本文從以上4 個方面對多機協同系統進行分析和總結,歸納關鍵技術,探討該領域目前存在的主要問題,并展望多機器人智能化協同技術未來的發展趨勢。
2 多機器人系統的發展概況
多機系統的研究可以追溯到20 世紀80 年代。 日本對于多機系統的研究起步最早。 1988年基于分布式體系架構的CEBOT (Cellular Robotic System)[4]通過重構,組成能夠實現學習的復雜機器人系統。 1989 年研制的Actress[5]異構機器人具備自主操作能力,并利用通信協議實現多機協同。
1994 年,美國加州大學開發的大規模分布式SWARM 系統通過機器人之間的交流獲得群體智能[6]。 1998 年美國的ALLIANCE 異構機器人團隊[7],利用焦躁和默許2 種類型的動機以此調節機器人的工作狀態。 同年,歐盟研制出MARTHA混合式系統結構[8],通過相互協調進行路線規劃和軌跡生成。
進入21 世紀,各國紛紛投身于多機系統的研究,并不斷加大對該領域的投入。 2004 年美國DARPA 中MARS-2020 計劃[9]的研究目標之一,就是在動態及危險環境中,通過地面與空中多機器人的團隊協作實現通信偵查作業。 2006年該機構的另一個項目SDR[10]開發了由大約80 個機器人組成的異構機器人團隊,旨在大型室內環境中探索,繪制空間地圖并檢測有價值的目標物體,實現保護等特定任務。 2013 年歐盟的AVERT 項目[11]研發用于搜救和干預危險行動的多機器人團隊,在協同過程中完成緊耦合任務。 2014 年美國 NASA 研制的名為Swarmie 小型機器人[12],模擬蟻群的工作方式,用于搜救和偵查,并有望用于深空探測中尋找水源,如圖1 所示。

圖1 NASA 研制的Swarmie 小型機器人[12]Fig.1 Swarmie robot developed by NASA[12]
2015 年俄羅斯開始打造機器人衛星部隊[13],以“整體打包,太空釋放”的方式將其部署到近地軌道完成太空裝配及檢修任務。 2018 年美國明尼蘇達大學MARS 實驗室通過在不同機器人建立的地圖之間增加點和線特征的幾何約束構成大規模3D 環境地圖[14]。
中國最早開展多機系統研究的是上海交通大學和中科院沈陽自動化研究所,研制的DAMAS[15]利用Petri 網建立了分布式的集中裝配系統。 蔡自興等[16]系統地闡述了多機系統,并提出利用遺傳算法提升地圖構建的效率和精確度,引入離散PSO 解決多機協同分配,并針對異構多機器人不同感知能力的特點設計了協同定位算法,增強系統位置預測能力[17]。 王浩等[18]提出分層追逃算法來處理多機系統中出現的追捕,以及如何解決追逃過程中的約束條件、追捕聯盟等問題。 魏明珠[19]通過一致步長迭代和更新,實現了月面多機器人分布式協同定位,提升了月面定位的效率和精度。 于曉強[20]提出基于擴展一致性的拍賣算法,利用多航天器之間的協同,完成在軌裝配的任務分配問題。
為提升空間探索效率,國際空間站的機械臂也由單臂向多臂協同發展。 國際空間站靈巧機械手SPDM 與機器人航天員R2 采用雙臂構型,協同實現空間站裝配與維修[21]。 日本實驗艙機械臂JEMRMS[22],在小臂工作時由主臂接收能源和數據,形成串聯構型,協同完成復雜靈巧操作任務,如圖2 所示。
圖2 日本實驗艙機械臂JEMRMS[22]Fig.2 Japanese robotic arm JEMRMS[22]
天宮二號機械臂系統在空間實驗室任務中順利完成人機協同、在軌維修等關鍵技術的驗證[23],見圖3。 中國空間站為核心艙和實驗艙分別配備2 套機械臂,2 套機械臂可獨立或協同執行任務,也可串聯成組合臂,擴大空間作業范圍[24],如圖4 所示。

圖3 天宮二號航天員與機械手的人機協同試驗Fig.3 Man-Machine Collaboration Test between astronauts and manipulator in Tiangong-2

圖4 中國空間站核心艙與實驗艙機械臂級聯Fig.4 The core module and experimental module manipulator cascade in the Chinese space station
多機協同理念已被應用于中國空間站的建造,輔助或替代航天員完成在軌組裝及維修等任務,大幅提高了空間操作的安全性,對于未來開展大規模集群操作,深空探測復雜任務等均具有重要意義。
3 多機器人同步定位與地圖構建
SLAM 即機器人對其所在環境構建空間模型,并在該環境中迅速定位。 2004 年美國NASA發射的機遇號和勇氣號火星探測器以基于視覺的SLAM(Visual-based SLAM)為主,完成了高精度的定位。 2021 年毅力號火星車搭載機智號火星直升機成功降落在火星表面,火星直升機將實時創建的地圖發送給火星車,實現天地協同SLAM,如圖5 所示。

圖5 機智號火星直升機和毅力號火星車Fig. 5 Ingenuity helicopter and Perseverance Mars rover
目前,已將單機器人的SLAM 成功擴展至多機協同SLAM,通過融合各機器人觀測信息,提升SLAM 的精度。 本文按照數據處理的主要方式,將多機器人SLAM 分為以下3 類。
3.1 基于濾波器的SLAM
基于濾波器的SLAM 常以擴展卡爾曼濾波(Extended Kalman Filter,EKF)算法通過更新以及預測不斷迭代,解決地圖和位姿估計。 隨著機器人數量和所在環境逐漸擴大,累積誤差會嚴重影響濾波效果。 Roumeliotis[25]將地圖重疊問題轉換成地標約束,減少地圖對齊過程中因噪聲引起的位置估計誤差。 Huang[26]提出新的信息感知方法,用可觀測性約束提升EKF 的一致性。 然而基于濾波的方法,其時間和空間復雜度均為o(n2),因此更適用于小規模地圖環境的構建。
將協方差矩陣變為信息矩陣,可得到擴展信息濾波器(Extended Information Filter,EIF)EIFSLAM 算法。 奔粵陽等[27]利用聯合分布狀態和信息濾波參數的稀疏性,從時間和計算兩方面減少復雜度,確保協同定位的精度和有效性。
不同于EKF-SLAM,粒子濾波器(Particle Filter,PF)可以處理任意噪聲模型。 Roh[28]利用多假設分析的地圖合并技術和粒子群優化算法,解決缺乏特征或局部極大值的多機器人地圖合并,提高地圖融合精度。 但是粒子的多樣性會隨時間推移而發生退化。 因此Havangi[29]提出了無跡Fast SLAM 算法,改進重采樣步驟,讓粒子集向概率密度函數值較大的區域移動,克服粒子貧化。
EKF-SLAM 是解決該問題的經典方法,然而受到算法一致性、數據關聯問題以及計算成本三方面限制。 EIF-SLAM 由于信息的可加特性,更適合擴展至多機器人系統。 PF-SLAM 在處理非線性、非高斯系統上魯棒性強,運算精度更高。
3.2 基于優化的SLAM
基于優化的方法中,圖優化SLAM(Graphbased SLAM)利用約束條件和目標函數,把問題變為基于圖的構建和優化。 Campos R[30]利用水下編隊機器人,通過融合地理參考光和導航數據建立空間地圖,并加入光學約束對地圖進行優化。然而Graph-based SLAM 需要建立在正確數據關聯的基礎上,計算要求較高。
Submap-SLAM 中[31],子地圖的匹配將局部地圖融合,組成大規模全局地圖,有效抑制了全局誤差的累積。 Vidal-Calleja[32]利用濾波和平滑方法將協同地空多機系統中各自生成的3D 子地圖進行組合拼接,成功解決了大型戶外環境的SLAM 問題。 但是在利用Submap-SLAM 得到整體地圖時,需要調整子地圖的尺寸。
不同于濾波方法僅利用當前較少數據進行軌跡更新,基于優化的方法分析所有觀測數據,更新整條軌跡。 通過對關鍵節點的維護,優化SLAM問題,具有計算量小且精度高等優點。
3.3 基于人工智能的SLAM
隨著人工智能的興起,利用智能化方法解決有關濾波和優化,提升SLAM 算法得到了快速發展。神經網絡對于非線性模型具有強大的擬合能力。Omid 等[33]利用徑向基網絡彌補噪聲假設和線性化過程中的系統誤差,降低SLAM 的不確定性。Havangi 等[34]將模糊運算與濾波器相結合,用模糊推理系統監督無跡卡爾曼濾波的性能,用于特征位置估計,使算法具有更高的精度和魯棒性。
近年來已有學者利用深度學習解決多機器人SLAM 中如閉環檢測、語義地圖的生成等問題。閉環檢測的目標是識別移動機器人之前曾達到的場景,可顯著降低隨時間累加的位置誤差,建立一致性地圖。 張浩然[35]借鑒深度學習能夠提取復雜圖像中的抽象特征,將循環神經網絡(Recurrent Neural Network,RNN)用于閉合檢測,提升檢測準確率的同時降低了運算量。 為繪制更加精確的空間地圖,在包含環境的幾何信息之外,還會加入語義信息的描述。 Mccormac[36]從多個視點中得到的卷積神經網絡(Convolutional Neural Networks,CNN)語義預測融合到地圖中,不僅能夠建立稠密的3D 語義地圖,而且可以改善僅使用單幀執行分割的基線方法。 將深度學習與SLAM 結合,展示了深度學習在精確度和復雜性方面的強大優勢,提升了系統的學習能力和智能化水平,未來極具發展潛力。 多機SLAM 方法對比如表2 所示。
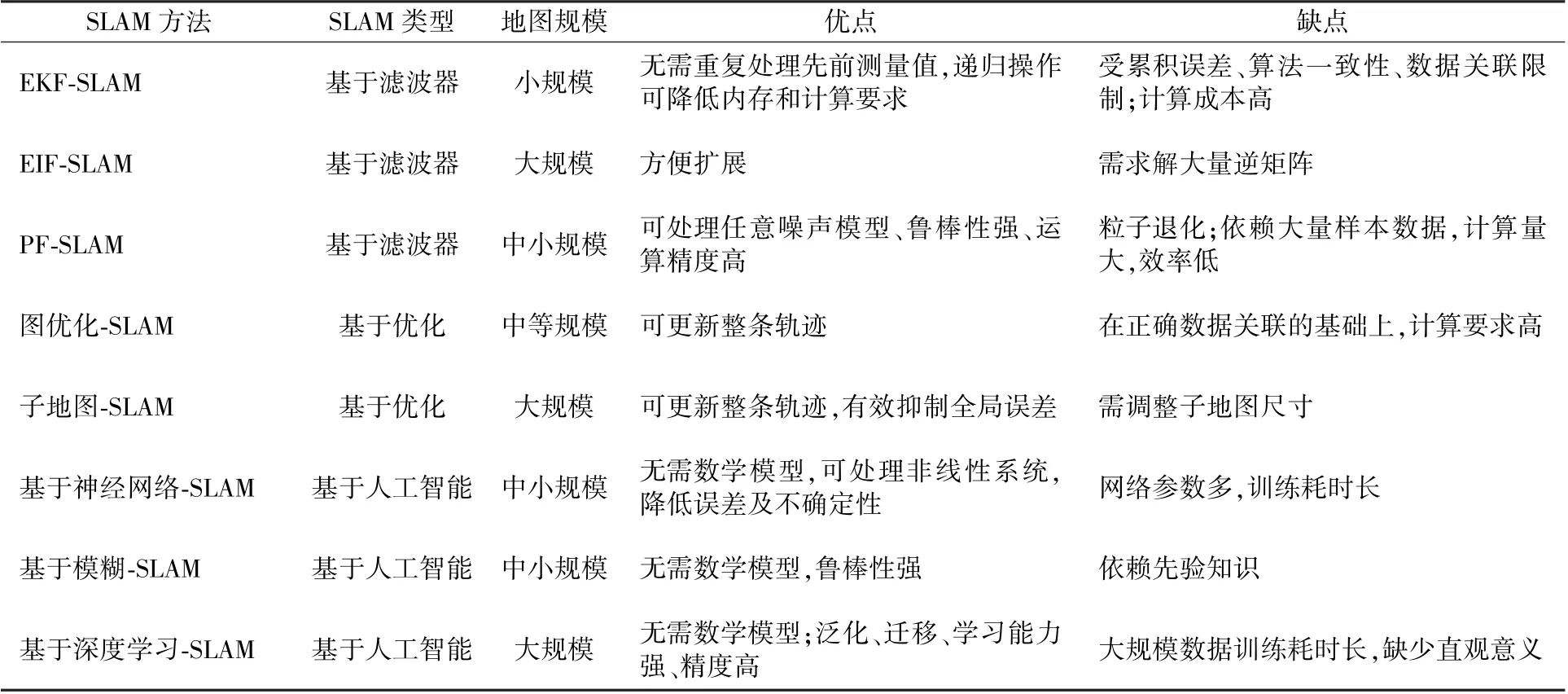
表2 多機SLAM 方法對比表Table 2 Comparison of multi-robot SLAM
在多機SLAM 中,機器人構建環境地圖與協同定位相輔相成,高精度的定位手段搭配不同地圖創建方式,是未來多機器人SLAM 的重要方向。目前多機協同SLAM 存在的問題有:
1)協同SLAM 中,需要較大的通訊量,如何降低通訊代價和復雜度;
2)如何提供更可靠、安全、抗干擾的定位服務,提高定位精度和實時性;
3)如何更好地利用人工智能、深度學習等手段,提升SLAM 的智能化水平,實現更高程度的人機交互。
4 多機器人任務分配
隨著系統在規模和功能上的愈加復雜,多機器人任務分配(Multi-Robot Task Allocation,MRTA)成為多機協同研究的熱點問題之一,其策略的優劣會對任務執行效果產生直接的影響。 MRTA 最初注重系統對任務的完成情況;近年來,在完成任務的前提下,更關注分配過程中的協調與合作。
早期任務分配方法多以集中式分配為主,基于運籌學的匈牙利算法、單純形法等傳統方法被應用于機器人之間的任務分配。 當任務規模和機器人數量不斷擴大,遺傳算法、蟻群算法等進化算法充分發揮了啟發式算法的優勢。 其中,蟻群算法[37]通過感知環境中信息素濃度,利用正負反饋機制來尋找最短路徑,是一種全局優化算法。Zheng 等[38]提出了一種基于蟻群算法的集中式、離線優化策略,利用2 種信息素記錄任務分配的傾向性和任務處理順序,從而實現任務優化分配和調度。 遺傳算法通過模擬生物進化過程,通過自然選擇以及遺傳學機理,最終得到系統最優解。Jose[39]面對復雜任務分配的組合優化問題時,在遺傳算法中加入了兩種貪婪策略,提高全局搜索能力。
集中式任務分配中,中小規模的分配問題可通過枚舉得到全局最優,其最優解的獲取大多以犧牲機器人的自主性為代價。 然而,MRTA 是一個非確定性多項式困難(Non-deterministic Polynomial-hard,NP-hard)組合優化問題,計算復雜度隨機器人數量的遞增,呈指數型增長,因此集中式分配不利于解決大規模任務分配。 此外,該方法普遍適用于機器人和環境均保持不變的情況,由于任務分配通常是一個動態的決策過程,因此在實際應用中存在一定的局限性。
分布式任務分配依靠各機器人自身傳感器規劃其行為,對動態變化環境適應性更強,反應速度更快。 基于行為和基于市場機制是較為常用的兩種分布式分配方法。 基于行為的分配方式在狀態信息與行為之間構成映射,通過設定的刺激,觸發相應的行為。 Parker 提出的ALLIANCE 就是典型的采用激勵行為的任務分配系統。 以利益最大化為準則,用更少的通訊實現協作屬于市場機制的任務分配模式[40],其經典代表為合同網模型。Wang 等[41]在傳統合同網方法中加入焦慮模型,提高任務分配效率。
拍賣算法使用更加明確的市場規則確定任務的分配,近年來用以改進傳統合同網模型。 根據算法需要競拍的回合數、每個回合能夠參與機器人的數量以及參與競拍的任務數量,可主要分為3 種類型[42]:組合拍賣(Combinatorial Auction)、并行拍賣(Parallel Auction)以及單項順序拍賣(Sequential-Single-Item Auction, SSI)算法。
在組合拍賣中,每一個機器人都可以對目標子集進行投標,是唯一能夠獲得最佳解決方案的拍賣手段[43]。 Cui 等[44]將平衡判斷公式和平衡評價因子引入到在線任務分配方法中,用于處理動態任務分配中的不平衡問題。
在并行拍賣中,拍賣只持續一輪,任務同時競標,并立即分配。 Zhang 等[45]在并行拍賣的收益矩陣中加入修正函數,使得該算法在總成本和完成時間上取得更好的性能。
初始條件已知的情況下,標準的單項順序拍賣算法考慮了目標之間的協同作用,通過多輪拍賣進行分配[46]。 Wei 等[47]為解決任務執行過程中出現的拍賣順序約束條件,將SSI 算法擴展到動態分配。 由于分配任務的性質逐漸由傳統單次、確定性向動態、再分配、不確定性轉變,以分布式為主的任務分配結構適用范圍更廣。
基于行為和基于市場機制的策略均需要利用一定的先驗知識來完成。 強化學習、神經網絡等智能任務分配理論減少了對先驗知識的依賴,因此得到了快速發展與廣泛應用。 Dai[48]在合同網算法中加入BP 神經網絡,用于融合多機器人拍賣時的競標價格,提升動態任務分配的快速性和實時性。 強化學習在應用于多機器人時高維度的狀態空間有時會引發維度災難。 Kawano[49]采用分層強化學習巧妙解決了維度爆炸問題,逐步進行子任務的分解和學習。
表3 分析對比了不同分配方法的任務規模、適用類型以及優缺點等,可針對不同應用環境、任務需求,選擇適當的分配方式,或組合其中算法,優化性能。 目前任務規劃仍存在如下幾個方面的問題:
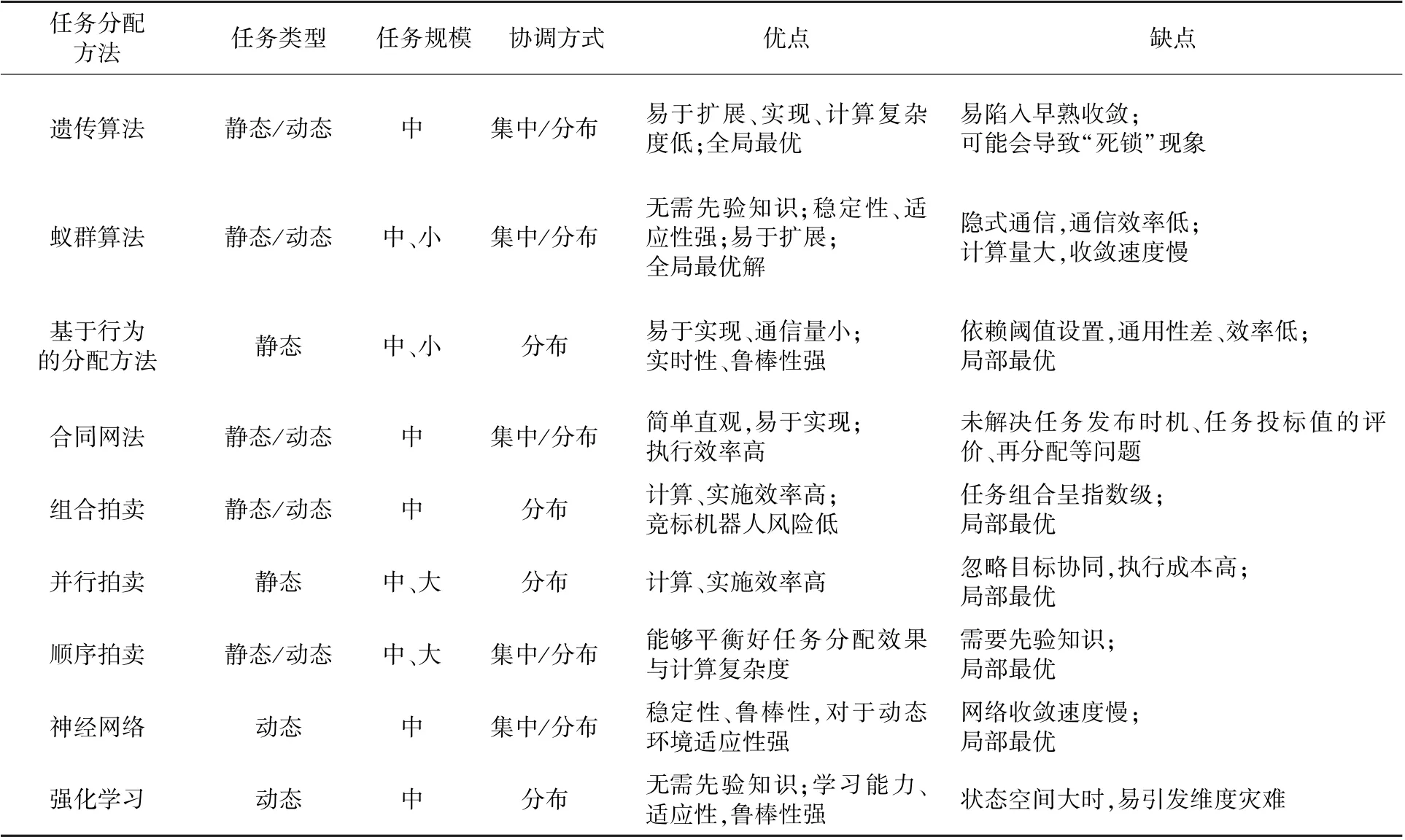
表3 不同任務分配方法對比Table 3 Comparison of different task allocation methods
1)如何對異構機器人的能力進行定義和分類,任務分配時,如何根據異構機器人的能力劃分任務。
2)面對機器人突發故障,或無法完成既定任務,如何撤銷并及時調整任務;如何處理動態任務以及任務的再分配過程。
3)如何更好地平衡分配過程中的通訊成本,解決通訊延時與約束。
目前在該領域主要采取的是理論研究和仿真分析,實驗驗證正在逐步建立與豐富。 未來的研究方向如圖6 所示。
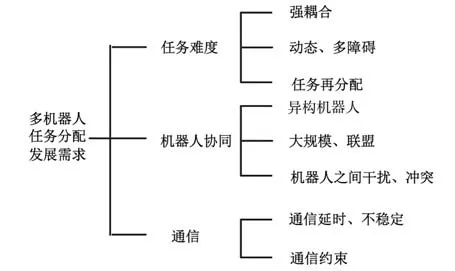
圖6 多機器人任務分配發展需求Fig.6 Development needs of multi-robot task allocation
5 多機器人路徑規劃
多機器人路徑規劃(Multi-Robot Path Planning,MRPP)不僅需要保證機器人均能順利安全抵達目標點,還需要滿足一定的優化標準[50],這是多目標、多約束的組合優化問題,體現了系統在復雜環境自主規劃與組織協調能力。
集中式路徑規劃通過統一調度為每個機器人構造最佳無碰路徑。 這種結構整體的協調性較好,但是容錯性、柔性較差。 人工勢場充分利用斥力場和引力場的相互作用力,尋找無碰自由路徑,是一種實時考慮空間構型的規劃手段。Matoui 等[51]采用集中式方法,用改進的人工勢場解決多機器人在線避碰,提升對動態環境的適應性。
分布式路徑規劃中單個機器人均可自行安排運動路線,實現更加復雜的協同任務。 盡管系統整體柔性以及靈活性更強,但是全局規劃能力較差。 夏清松等[52]將基于蟻群算法的全局路徑規劃與局部作業避障規則相結合,設計出較短、無碰的組合路徑。 粒子群算法可用于多約束組合優化問題的求解,運行效率高,但是無法保證全局最優解。 Bilbeisi 等[53]設計了優化粒子群算法,無需先驗知識,實現動態避障的同時,通過協同合作到達目標點。 D*算法是通過遍歷全部節點,實現最短路徑的全局規劃算法。 Peng 等[54]利用改進的D*算法,通過機器人之間的交互快速重新規劃,找到時間最短路徑。 然而,該方法不適用于較大的空間搜索范圍。 人工蜂群算法根據對蜜蜂覓食過程的觀察,利用正負反饋機制尋找到更優質的食物源。 Wang 等[55]改進了蜂群算法中覓食和淘汰機制,保證能夠同時實現多目標優化,提高了算法的運行效率。 該算法自組織能力強,能與其他啟發式算法相結合,實現優勢互補。 Zhao 等[56]開發了2 種模糊控制器,分別用于避障和目標定向,實現了多機系統未知動態障礙物環境下的路徑選擇。 將神經網絡用于路徑規劃中,使系統擁有自學習能力,可應對動態變化環境以及較多障礙物情況,魯棒性強。Zhang 等[57]將最短路徑表示為線性規劃問題,采用有偏一致性神經網絡進行有效的分布式求解,得到最短的軌跡路線。
混合式路徑規劃中單個機器人不具備完全的自主能力,仍會依賴中央處理單元。 張丹露等[58]采用集中和分布控制相結合的方法,利用交通規則、預約表和改進的A*算法解決碰撞和死鎖。其中A*算法是目前使用較多的一種啟發式搜索算法,可用于全局路徑規劃。
表4 歸納總結了不同的規劃算法。 通過融合多種路徑規劃,并引入智能及優化方法,以獲得更強大的性能是新的發展趨勢。
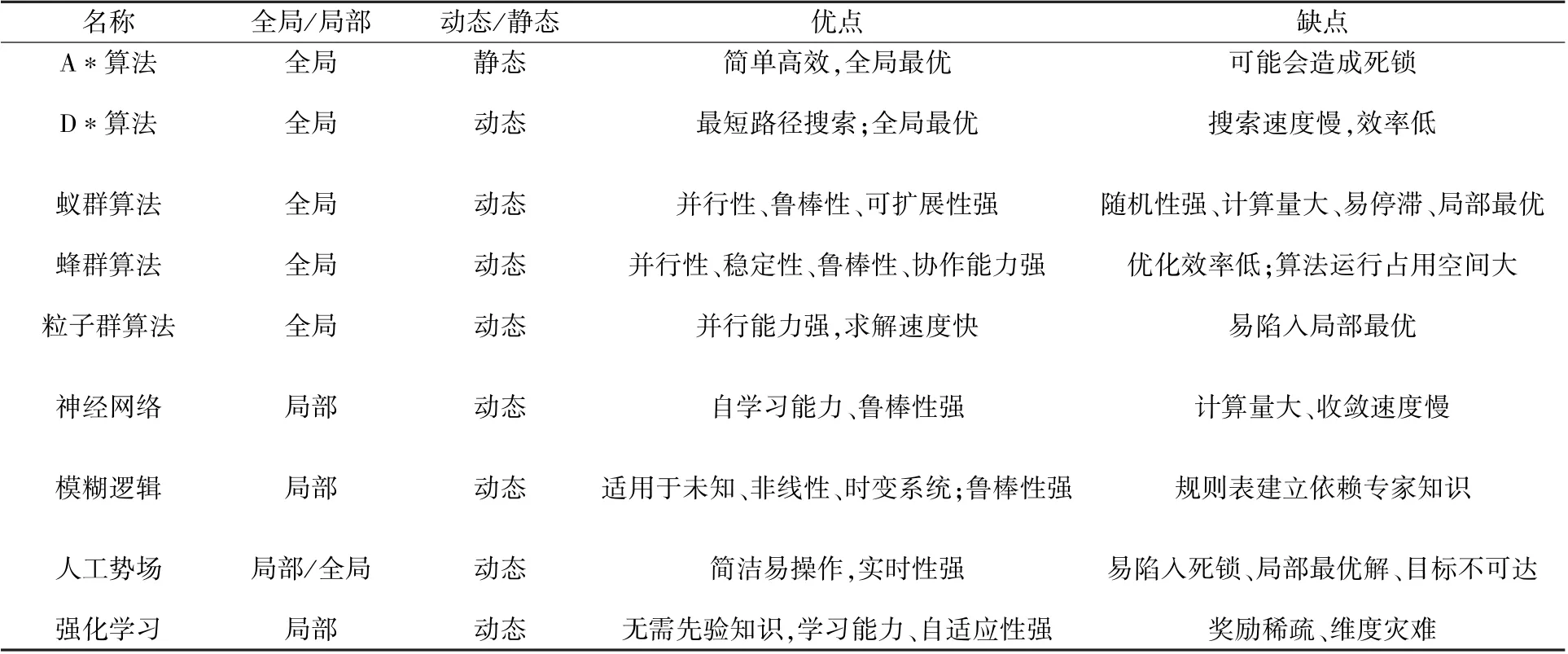
表4 路徑規劃方法對比表Table 4 Comparison of path planning methods
目前路徑規劃存在的問題主要體現在如下幾點:
1)復雜環境下,全局路徑規劃實時性差,可能導致行動滯后于環境變化,導致避障失敗。
2)大部分路徑規劃難以處理好可達性、安全性等性能指標的約束以及計算量、求解時間之間的平衡。
3)大多數的路徑規劃僅在仿真平臺上進行驗證,實物系統的發展有待加強。
因此,路徑規劃研究方向總結如圖7。
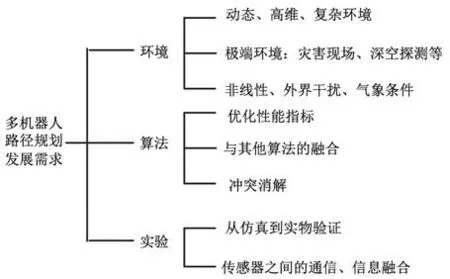
圖7 多機器人路徑規劃發展需求Fig.7 The development needs of multi-robot path planning
6 多機協同與強化學習結合的理論與方法
傳統的機器人控制對先驗知識的依賴性較強,這類機器人無法應對復雜變化或未知的環境。強化學習(Reinforcement Learning,RL)作為一種在線學習的方法,能夠在智能體與環境的交互中,不斷修正行為,獲得對環境的適應性。 將RL 應用于多機系統,無疑會帶來新的突破,進一步擴展其應用范圍[59]。
多機協同的強化學習不僅是對獨立機器人學習情況的簡單疊加,更要考慮信息交互,協商與信度分配等問題[60]。 學習的難度和復雜度將遠大于單機器人的學習。 多機強化學習系統按照結構劃分,可分為集中和分布兩種模式。
集中式RL 利用中央單元進行協同目標的統一學習。 群體中的單個機器人僅用作數據采集和執行任務的載體,并不具備獨立學習的能力。 隨著機器人數量增加而出現的靈活性差、維度災難、難以收斂等問題,限制了集中式強化學習的發展。
在分布式RL 中,機器人自身即為一個獨立主體,在相互通訊、協作中,不僅需要學習有利于個體的最優策略,也要兼顧全局的學習目標[61],實現更高層次的智能化。 分布式RL 學習中包含:中央RL、獨立RL、群體RL 和社會RL。
在中央RL 系統中[62],單個機器人無法采取主動學習的方式,只能被動地接受學習結果,而由中央機器人承擔全局性的學習任務(圖8)。
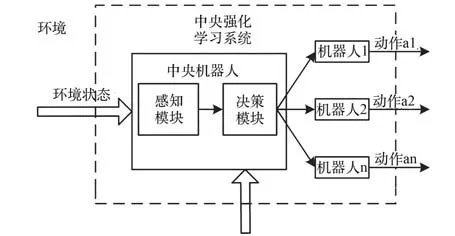
圖8 中央強化學習Fig.8 RL Centrally
獨立RL 如圖9 所示[62],雖然單個機器人可以感知周圍環境,選擇能夠實現最大回報的動作策略。但是系統中的機器人僅依據自身利益選擇動作,而不考慮團體的發展,因此這種學習方式很難實現全局最優的目標。 適合解決系統中包含個體數目較多并且松散耦合的任務情況。 其中根據智能體強化信號分配結構信度是亟待解決的難點問題。
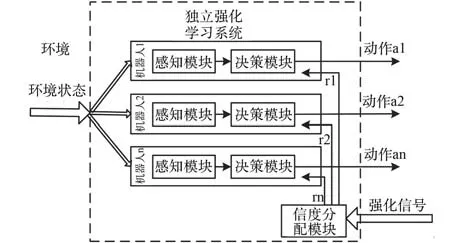
圖9 獨立強化學習[63]Fig.9 RL Individually[63]
群體RL 系統如圖10 所示[63],每個機器人在進行動作策略的選擇時,都在維護系統的整體利益。 因此,該種學習方式中狀態空間或動作空間的規模龐大,是機器人數目的指數倍,交互關系和學習難度會隨之增加變得復雜,出現學習速度緩慢的情況。 群體強化學習系統還需要進一步優化數據結構,加快運算速度及收斂過程。 然而,狀態空間和動作空間的維度災難問題仍是群體強化學習的弱點之一。
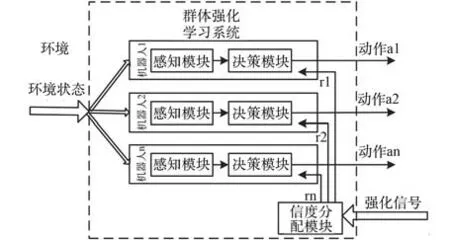
圖10 群體強化學習Fig.10 RL in Groups
社會RL 在系統里引入了社會或經濟模型,從管理學、社會學的角度調節機器人之間的關系,實現系統整體的學習,以此提高智能化水平,其本質上是獨立強化學習的擴展。 然而社會強化學習克服了獨立強化學習中機器人之間自私的缺點,可以建立更加復雜的系統結構,動作策略選擇更優。 不同強化學習之間的對比匯總如表5 所示。
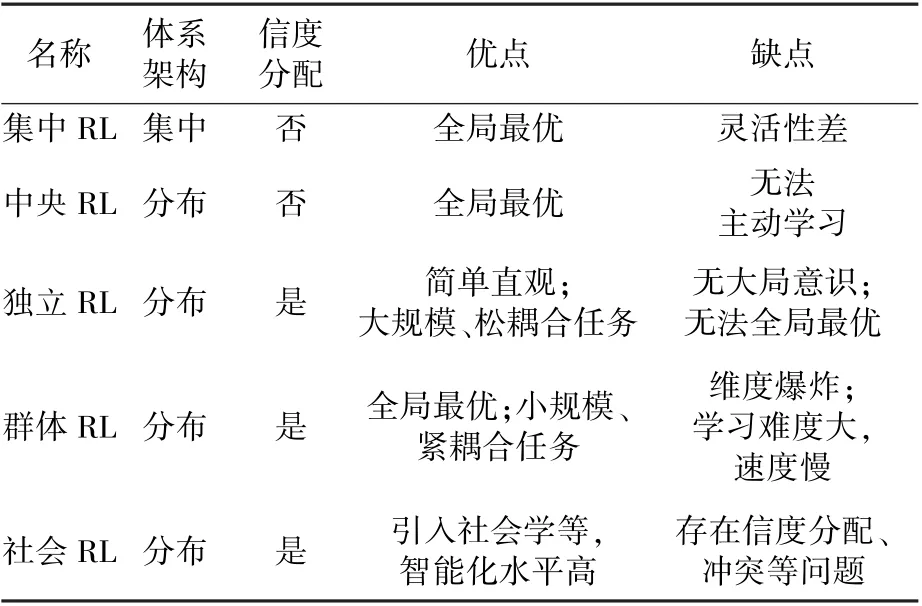
表5 多機器人強化學習對比Table 5 Comparison of multi-robot RL
未來多機協同會更加注重群體智能、對最優策略的自學習以及對環境的自適應能力。 強化學習與多機器人的融合具有更為廣闊的發展前景,未來該領域的發展趨勢有:
1)有效化解機器人執行任務時的沖突,獲得更合理的結構信度分配。
2)充分利用不同機器人的知識和經驗,提升團隊協作的效率。
3)設計在線強化學習算法,保證多機器人均能實現有限時間收斂,提升算法的實時性和快速性。
4)團隊中開展多目標學習。 目標之間可以相互關聯或存在沖突,不僅需要研究機器人之間的協同效應,還需研究目標之間的協調與決策。
7 總結與展望
多機器人協同系統利用機器人的相互協作實現更多復雜功能,在眾多領域給人類社會帶來巨大變革。 對于中國未來高效開展航天探測任務,實現大規模集群操作等目標影響深遠。 未來多機系統的總體趨勢體現在如下方面:
1)團隊中的機器人能夠形成更加緊密的協作,從單一功能向多功能發展,滿足復雜多變的任務需求,不斷提高系統整體性能,降低開發成本。
2)處理好異構機器人之間的通信,平衡好團隊數量及工作質量,進一步提升團隊協作效率。
3)充分應用人工智能、強化學習等技術提升團隊自主判斷、智能分析規劃以及操作的能力是未來重要的發展方向。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
領導決策信息(2018年50期)2018-02-22 06:17:16
家庭影院技術(2017年9期)2017-09-26 03:41:45
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
中國工程咨詢(2016年4期)2016-02-14 07:28:28
