基于改進AlexNet卷積神經網絡的手寫體數字識別
2021-12-23 07:48:30謝東陽李麗宏苗長勝
河北工程大學學報(自然科學版) 2021年4期
謝東陽, 李麗宏, 苗長勝
(河北工程大學 信息與電氣工程學院,河北 邯鄲 056038)
手寫體數字識別是光學字符識別(Optical Character Recognition,OCR)的一個分支,是利用計算機將圖片中的文字信息轉換為計算機語言的過程。數字識別是一種圖像分類問題,一直是機器深度學習的一個熱點研究問題,在快遞單號、財務報表、手寫票據等領域廣泛應用[1-2]。數字識別的重點在于算法對圖像本身的特征提取,傳統的分類算法都存在特征提取不充分的問題,如貝葉斯分類法、K最近鄰算法、支持向量機(Support Vector Machines,SVM)、BP(Back Propagation)神經網絡等[3]。
卷積神經網絡(Convolutional Neural Network,CNN)的出現,極大地提高了手寫數字識別的準確率。CNN是由美國學者Cun提出的一種深度前饋人工神經網絡,包括卷積層、池化層、全連接層和輸出層[4]。CNN通過對提取到的圖像特征自動學習,能夠獲得更高層次的特征表達,使學習到的特征信息具有更好的泛化能力[5]。鄧長銀等[6]通過改變LeNet-5模型的網絡層數、激活函數以及輸入圖片的尺寸,相較傳統方法識別率有所提高。茹曉青[7]等提出了一種基于形變卷積神經網絡的識別方法,利用形變卷積代替VGG16模型中的普通卷積,提高了多變外觀數字的識別精度。陳玄等[8]提出了一種融合卷積神經網絡,通過融合兩種網絡的高級特征,增加網絡層的高級尺寸,增強網絡的表達能力,識別的精度高于兩種模型單獨使用。
盡管卷積神經網絡在圖像分類任務中表現優(yōu)越,但是對于分辨率較小的圖像,深度網絡會浪費過多的計算資源。本文以AlexNet網絡結構為基礎,減小模型的卷積核尺寸與數量,引入Inception-Resnet模塊提升算法的特征提取能力,并使用批標準化 (Batch Normalization,BN)加快模型的訓練速度。通過對實驗結果的分析,驗證了本文方法的有效性。
1 相關工作
1.1 AlexNet網絡
AlexNet是由多倫多大學的Krizhevsky等[9]在2012年提出的,并在當年的ImageNet大賽上打破了圖像分類的記錄獲得了比賽的冠軍,使圖像分類的準確率提高了一倍多。
AlexNet的網絡結構如圖1所示,AlexNet網絡模型結構簡潔,由5層卷積層、2層隱藏全連接層和一層輸出全連接層組成。整個網絡結構使用ReLu代替Sigmoid作為激活函數,能有效地解決Sigmoid在層數較多的網絡結構中出現的梯度彌散問題。同時網絡在全連接層后添加Dropout操作,利用隨機隱退神經元個數的方法,在網絡的訓練過程中減少模型的參數量,能夠有效地防止過擬合現象的出現。在Relu激活函數后添加局部響應歸一化(Local Response Norm,LRN),通過對局部神經元創(chuàng)建響應競爭機制,提高了網絡的泛化能力。使用重疊的最大池化層代替平均池化,很好地解決了平均池化的模糊問題,同時在一定程度上提高了圖像特征的豐富性。AlexNet模型相比于LeNet5和傳統的機器學習方法具有更高的識別精度,但是本身的參數量巨大,模型的訓練時間長,識別速度慢。

圖1 AlexNet網絡模型Fig.1 AlexNet network model
1.2 Inception-Resnet模塊
Inception模塊將多個卷積層與一個池化層并聯在網絡中,模型在訓練的過程中自主選擇使用哪種方式獲取特征信息,不需要人為地確定參數,是一種高效的稀疏結構,有利于提取到豐富的特征[10]。使用多種尺寸的卷積核,提取不同層次的特征,增加了特征的多樣性。Inception將不同尺寸的特征融合在一起有利于后面的分類任務。并利用小卷積代替大卷積,使用1×n,n×1的非對稱卷積代替n×n的卷積核,大大減少了網絡的參數量,提升了網絡的運算速度。Inception結構增加了網絡的寬度,在深層卷積神經網絡中能提高網絡的魯棒性和泛化能力。
殘差網絡(Residual Network,ResNet)是He[11]在2016年提出的一種深層卷積神經網絡結構,用于解決在模型深度加大時出現的網絡退化現象,提升網絡的深度。ResNet運用殘差學習的思想,在數據傳輸過程中添加一個shortcut連接,使信息可以直接傳輸到任一層,保護了信息的完整性,能獲得表達能力更強的特征,加速網絡的訓練。
Inception-Resnet-v2模型是谷歌團隊在2016年發(fā)布的卷積神經網絡,是Szegedy在Inception結構的基礎上與ResNet相結合提出的一種新的網絡結構,使網絡的深度進一步增加,并增強了網絡的非線性,加速了網絡的訓練。
1.3 Batch Normalization

(1)
(2)
對輸入進行歸一化處理
(3)
式中:ε為一個極小值,防止分母為0,k表示當前的維度。這樣就將每個batch的輸入數據歸一化到N(0, 1)的正態(tài)分布。但是只對數據進行歸一化可能會改變原本輸入數據的特性或分布,會影響到當前層所學習到的特征,所以又引入了兩個超參數對正態(tài)分布進行平移和縮放:

(4)
式中:γ表示縮放,β表示平移,一般初始化γ=1,β=0。
BN層使模型可以使用大的學習率,加快網絡的收斂速度;有類似于Dropout和正則化的效果,能防止網絡的過擬合問題,提高模型的泛化能力。
2 算法改進
原始AlexNet模型的輸入尺寸為224×224,為了使AlexNet模型能應用于MINIST數據集,將模型的第一個卷積層的卷積核從11×11改為5×5,步長從4改為1,改變后的模型剛好能實現分辨率為28×28的MINIST數據集的識別任務,得到了99.33%的識別精度。
更改后的AlexNet模型雖然能實現手寫數字識別,但是Conv1和Conv2使用的是5×5的大卷積核,相對于28×28分辨率的圖像來說尺寸較大,不能提取到足夠的細節(jié)特征。為了提取更多的細節(jié)特征,使用兩個3×3的卷積核堆疊,以獲取和5×5卷積核相同的感受野,同時能減少模型的參數量。將模型中前兩層最大池化的池化核從3×3修改為2×2,縮小特征圖尺寸的同時,進一步地減少了模型的參數量。
但是AlexNet的Conv3、Conv4和Conv5這三個卷積層的特征圖尺寸都為3×3,特征圖尺寸過小,通過卷積層的堆疊并不能提取到足夠的特征信息,反而會浪費計算資源。為了獲得更加豐富的特征信息,使用改進后的Inception-resnet結構替換原模型中的Conv3和Conv4,使模型能學習到不同尺寸的特征信息,提升模型的特征提取能力,有助于分類器的分類。改進后的Inception-resnet結構如圖2所示,在模塊中每層卷積層之后添加BN層,將數據規(guī)范化處理,增快網絡的收斂速度。

圖2 添加的Inception-resnet模塊Fig.2 Inception-resnet module added
在AlexNet模型中使用了兩個隱藏全連接層,由于全連接層的參數量巨大,因此刪除一個全連接層,降低模型的參數量。為了使模型能夠快速收斂,在每一個卷積層之后,激活函數之前使用BN對數據進行規(guī)范化處理,加速網絡的訓練。改進后模型的具體參數說明如表1所示。

表1 改進模型具體參數
3 實驗與分析
3.1 實驗平臺
本實驗平臺為戴爾筆記本,處理器為Intel(R) Core(TM) i5,4 GB內存,主頻:1.7 GHz。運行環(huán)境為Win10 64操作系統,編譯器為Pycharm,編程語言為Python。
3.2 實驗數據集
MNIST數據集是一個手寫體數字識別數據集,包含50 000條訓練數據集和10 000條測試數據集。數據集包含250個不同人手寫的阿拉伯數字0~9,共10類手寫體數字圖像。每條數據集由圖像和標簽組成,每張圖像的大小為28×28=784的一維數組,標簽類型為One-Hot-Encoding編碼格式。部分數據集圖像如圖3所示。

圖3 MNIST數據集部分圖像Fig.3 Partial images of the MNIST data set
3.3 實驗結果
本文以AlexNet模型為基礎融合Inception-ResNet-C結構進行算法的改進,在MNIST數據集上進行驗證,設置訓練的mini-batch為32,訓練周期為30次,每次的訓練樣本數為1 875。使用Adam優(yōu)化器對梯度反向傳播進行優(yōu)化,初始學習率設置為0.001,經過2個世代val-Loss不減少將學習率下調為原來的一半,加入Early Stopping機制,當val-loss經過6個世代不再減少時停止網絡的訓練。圖4(a)為AlexNet網絡與本文算法在MNIST數據集上的訓練損失函數曲線圖,可以看出本文算法在訓練過程中的收斂速度快于AlexNet網絡,說明改進后的算法提高了模型的訓練速度。圖4(b)為兩種算法的測試準確率曲線圖,可以看出改進后的算法在測試時的識別率高于AlexNet模型,說明改進后的方法有效地提升了手寫數字識別的精度。
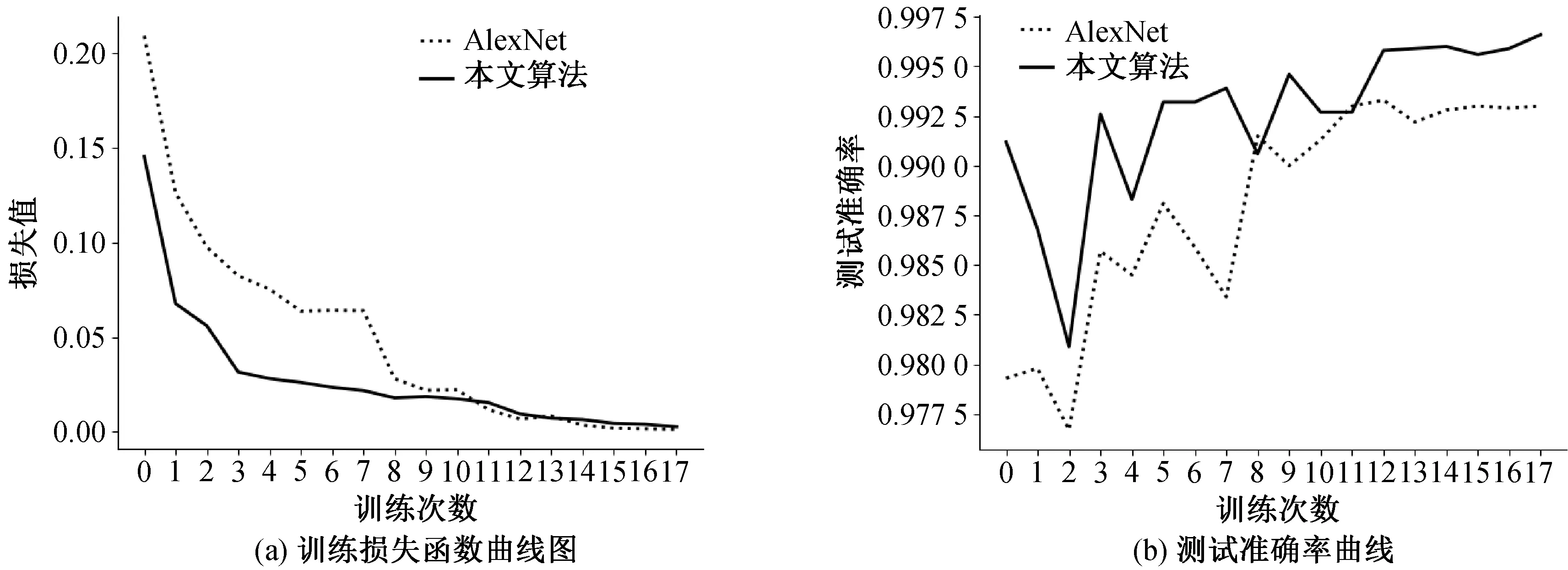
圖4 模型訓練與測試效果對比圖Fig.4 Comparison of model training and test results
本文方法是在AlexNet基礎上進行的改進,其參數量從2.1×107減少到8×105為原來的1/26,模型訓練一個世代的時間從1 400 s減少到280 s,為原來的1/5,大大加快了訓練的速度,并且比AlexNet的準確率提高了0.33%。為了驗證本文算法的有效性,與其他算法進行比較,結果如表2所示。實驗結果表明改進后的算法有效地提高了網絡的檢測精度。
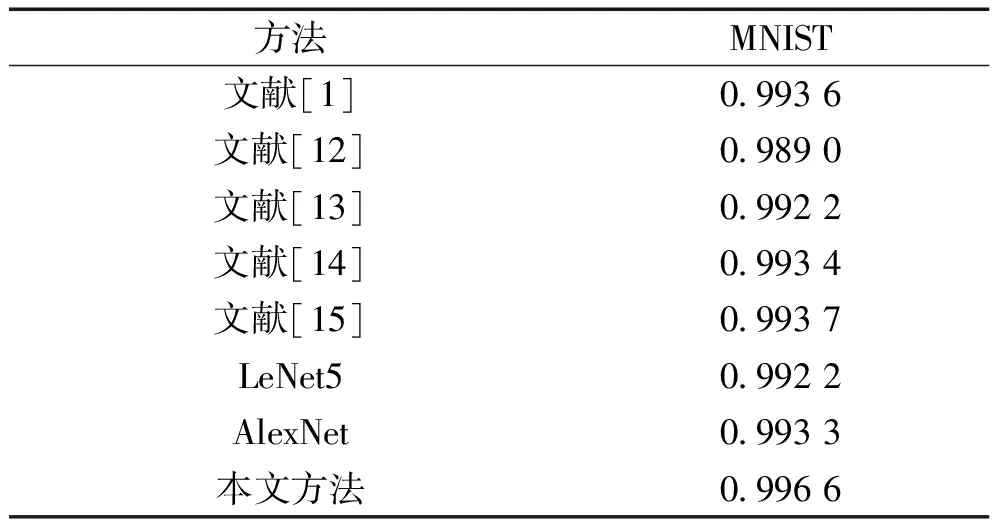
表2 不同算法的比較
4 結論
本文提出基于改進AlexNet卷積神經網絡的手寫體數字識別方法,利用Inception-resnet模塊提取多層特征并融合,提高了模型特征的學習能力;通過BN層對輸入數據進行批歸一化處理,有效地提升了模型的泛化能力;減少模型卷積核的數量,大大減少了網絡的參數量,提升了模型的訓練速度。利用MNIST手寫體數字集進行實驗,本文算法的檢測精度達到了99.66%,相比于AlexNet模型提升了0.33%,與LeNet5模型相比提升了0.44%,證明了本文算法的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
