OpenVX 高效能并行可重構運算通路的設計與實現
2021-12-20 12:35:36邢立冬馮臻夫
計算機工程 2021年12期
王 宇,李 濤,邢立冬,馮臻夫
(西安郵電大學 電子工程學院,西安 710121)
0 概述
近年來,隨著電子計算機及半導體技術的快速發展,圖像處理與計算機視覺(Computer Vision,CV)作為計算機應用領域中的重要分支,在軍事、醫學、地質勘探、多媒體等領域應用廣泛[1]。由于人們對流暢視覺畫面及視覺感受的要求越來越高,圖形圖像處理器設計及基于加快圖像數據處理速度的計算機視覺算法優化不斷面臨新的挑戰[2]。
OpenVX 標準[3]能為跨平臺加速計算機視覺處理提供參照,從而實現計算機視覺處理性能和功耗的優化。其作為圖像處理、圖計算、深度學習和圖形預處理或輔助處理的標準,被諸多芯片企業(如NVIDIA、AMD、Intel、TI、Apple 等)采用,具有廣泛的應用前景。通過對OpenVX 硬件設計進行調研,發現國內目前專門為OpenVX 設計的硬件芯片較少。YAN 等[4]采用多態陣列架構(PAAG)處理器實現了OpenVX 核函數中的像素級圖像處理。HUANG 等[5]針對人臉識別項目中的預處理操作,提出基于OpenVX 的并行化處理方法。TAGLIAVINI等[6]介紹一個快速設計和優化OpenVX 應用程序的框架,SAJJAD 等[7]提出將視覺通道的OpenVX 圖形級規范(graph-level specification)合成優化的FPGA框架,ABEYSINGHE[8]提出一種基于性能模型的方法以優化OpenVX 圖形。以上方法均沒有給出底層核函數的硬件加速設計方案,缺少實現OpenVX 核函數的具體數據通路映射及分析。
本文設計一種支持OpenVX 1.3 標準的并行可重構數據通路運算器,通過配置指令重構數據通路完成圖像處理任務。此外,通過研究OpenVX 中大量kernel 函數算法,并采用相應的映射方案對不同類別的函數進行數據通路映射,從而設計出適合不同類別函數的數據通路運算器。
1 OpenVX 介紹
OpenVX中的圖概念如圖1所示,將OpenVX 中每一次對圖像的基本操作看成整個流程中的一個節點(node),該節點通過處理前后的圖像和其他node相連,形成圖(graph)。OpenVX 提供了一種自定義節點機制,用戶可根據需要編寫節點,并最終融合成圖。OpenCV 是一套完整的計算視覺軟件系統,提供了圖像處理的底層操作,雖然其有底層硬件加速函數(HAL),但OpenVX 提供了一套更全面且結合了圖計算(Graph Computing)方式的標準。

圖1 OpenVX 中的圖概念Fig.1 Graph concept in OpenVX
OpenVX 計算視覺標準支持最基本的圖像處理和計算視覺函數。OpenVX 中多數kernel 函數是針對圖像的像素級處理,這些kernel 函數構成了一個適用于硬件加速的函數子集[9]。這些像素級處理包括點處理、局部處理、全局處理、特征提取4 大類。OpenVX 1.3 支持的kernel 函數中包含的數據類型如表1 所示。
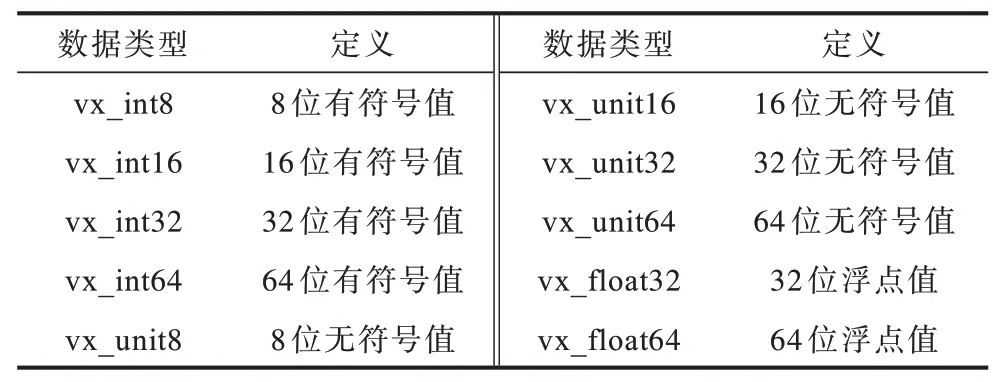
表1 OpenVX 1.3 支持的數據類型Table 1 Data types supported by OpenVX 1.3
2 OpenVX 函數的數據通路映射及分析
通過對不同函數進行相應數據通路的映射,使各個函數均具備高效的處理性能,得出不同函數實現所需運算器的種類及數目后,才能進行整體可重構數據通路運算器的設計。OpenVX 1.3 標準中共包含58 個kernel 函數,本文映射函數的數據通路中包含點處理類27 個,局部處理類10 個,全局處理類7 個,特征提取類7 個。由于相同種類函數的數據通路相似,本文著重介紹點處理中的基本運算類、圖像色系變換、仿射變換、透視變換、圖像局部處理中的Sobel 3×3、圖像全局處理中的均值及圖像特征提取中的Canny 邊緣檢測,并根據相應函數的映射方案和時序圖對整體數據通路運算器所需的運算單元進行分析。
2.1 數據通路映射方案
數據通路映射方案包含流水線數據通路、并行數據通路、并行結構結合流水線數據通路。
1)流水線數據通路
流水線處理電路[10]采用面積換取速度的思想,可以大幅提高電路的工作頻率,尤其對于圖像處理任務中的二維卷積運算、圖像濾波器、色系變換等。采用流水線設計可以保證一個時鐘輸出一個像素。由于對大部分圖像處理任務而言,處理過程均采用串行的處理思路,因此流水線是較好的設計方式[11]。如圖2 所示為典型的流水線結構,每個步驟獨立為一個單獨的處理單元,與其他處理單元同時運行,提高速度的同時也降低了設計的復雜度。
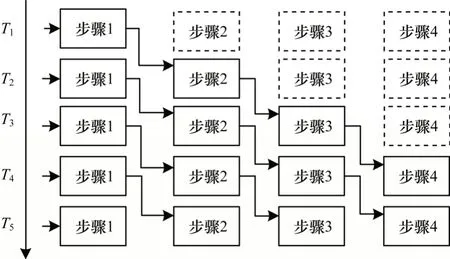
圖2 流水線處理結構Fig.2 Pipeline processing stucture
2)并行數據通路
在并行處理電路[12]中,多組并行排列的子電路同時接收整體數據的多個部分進行并行計算。并行處理電路的結構如圖3 所示,對每個處理數據支路均生成對應的處理電路,這樣雖然提高了整體電路的處理速度,但是卻造成了更大的資源消耗,即用面積換取速度。
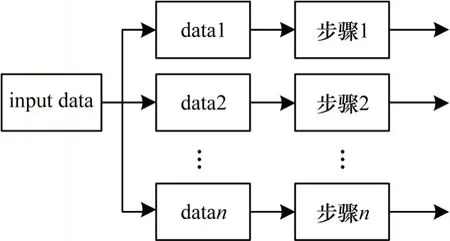
圖3 并行處理電路結構Fig.3 Parallel processing circuit structure
3)并行結構結合流水線數據通路
并行處理電路中的子電路可以是簡單的組合電路,也可以是復雜的時序電路,例如上面提到的流水線數據通路。如果受邏輯資源限制,無法同時處理全部數據,也可以依次處理部分數據直到完成全部數據的處理[13]。
2.2 函數映射
2.2.1 點處理函數映射
點處理函數映射包含基本運算類映射、圖像色系變換和仿射變換。
1)基本運算類映射
基本運算類包括算術類運算和邏輯類運算。算術類運算包括絕對差、算術加法和算術減法,數據類型為vx_unit8 和vx_int16。算術類運算可以通過配置指令將加法器配置為8 位或16 位定點加法或減法器進行并行計算,并輸出計算結果。邏輯運算類包括按位與、按位或、按位異或、按位非和邏輯移位。本文采取數據通路的合并,即邏輯類運算操作和加法操作進行數據通路的合并,以減小整體電路的面積。對于一個32 位的基本運算器,通過指令配置,可以在每個時鐘周期并行完成2 個16 位或4 個8 位的算術類運算或邏輯類運算。
2)圖像色系變換
該函數可以實現顏色的轉換,將指定格式的圖像轉換成另一種格式。以RGB 線性轉換為例,轉換公式如式(1)所示:

其中:R1、G1、B1代表原來的顏色通道;R2表示新的R通道。
對其進行數據通路映射如圖4 所示,分為3 級流水線:第1 級并行計算式(1)中的3 個乘積項;第2 級把前2 個乘積項結果送入加法器a0,并把第3 個乘積項進行寄存;第3 級把a0和寄存器值相加,并移位輸出。由圖4 可知,色系變換的流水線數據通路需要3 個定點乘法器及2 個定點加法器。

圖4 色系變換流水線Fig.4 Color convert pipeline
3)仿射變換
仿射變換對圖像進行仿射運算,支持的數據類型為vx_unit8和vx_float32。該函數使用2×3的仿射矩陣M對輸入像素進行仿射變換,具體計算如式(2)~式(4)所示:
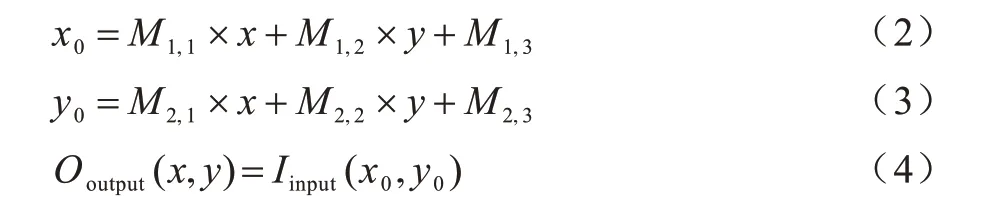
仿射變換數據通路的映射如圖5 所示,第1 級使用4 個浮點乘法器并行計算式(2)和式(3)中的乘積項;第2級將4個輸出結果兩兩相加;第3 級 將M1,3、M2,3分別和a0、a1相加并輸出最終計算結果。由圖5可知,仿射變換的流水線數據通路需要4 個浮點乘法器及4 個浮點加法器。
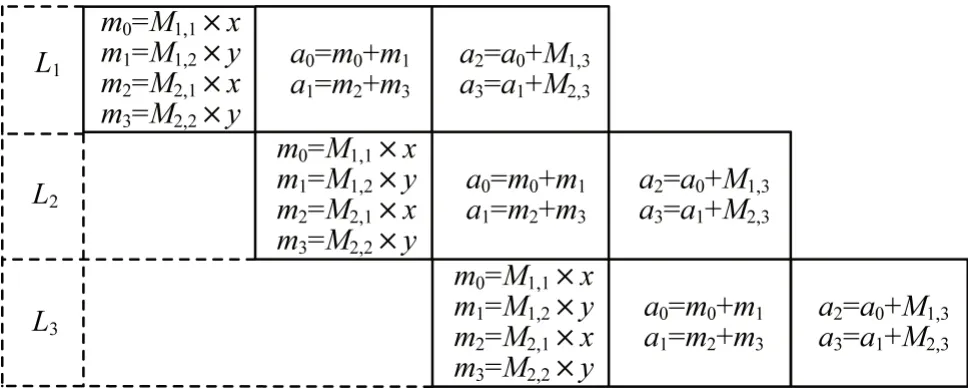
圖5 仿射變換流水線Fig.5 Affine transformation pipeline
透視變換對輸入圖像進行透視變換運算,支持的數據類型為vx_unit8 和vx_float32。該函數使用3×3 的透視矩陣M對像素進行透視變換,具體計算如式(5)~式(8)所示:
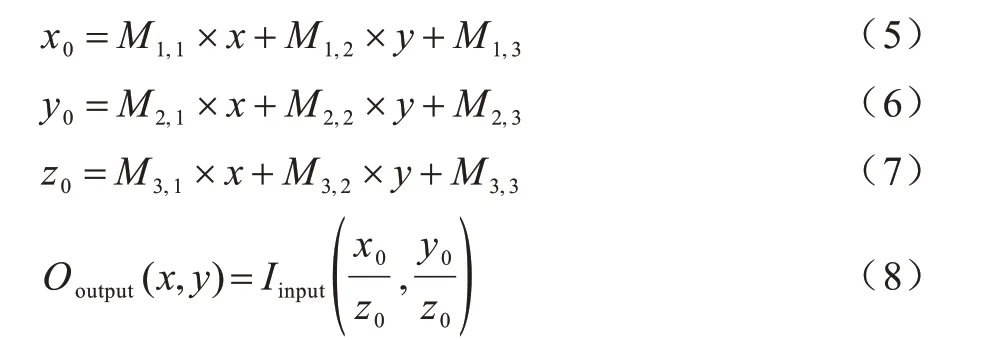
對其進行數據通路的映射如圖6 所示,分為4 級流水線:第1 級并行計算式(5)~式(7)中的乘積項;第2 級并行計算 式(5)~式(7)中的第1個加法;第3 級并行計算式(5)~式(7)中的第2 個加法;第4級并行計算x0/z0,y0/z0。由圖6 可知,透視變換的流水線數據通路映射需要6 個浮點乘法器、6 個浮點加法器、2 個浮點除法器。
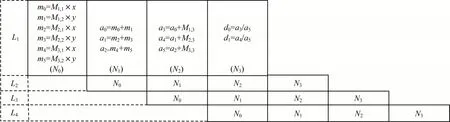
圖6 透視變換流水線Fig.6 Perspective transformation pipeline
2.2.2 局部處理函數映射
Sobel 圖像濾波支持的數據類型為vx_unit8,當濾波模板大小為3×3 時,需要將9 個像素p0~p8進行計算,其流水線數據通路如圖7 所示:第1 級并行計算8 個像素的加法,第2 級將上一級的結果兩兩相加,第3 級將上一級的結果相加,第4 級對最后一個像素進行加法計算并得出最終結果。由圖7 可知,Sobel 3×3 濾波流水線電路需要8 個定點加法器。

圖7 Sobel 濾波流水線Fig.7 Sobel filter pipelined
本文通過電路的擴展和配置指令,可將中間結果寫回寄存器堆或輸出,實現濾波模板大小的可配置,其擴展性和兼容性更好。當濾波模板大小為5×5 時,使用上述的流水線通路一次可計算9 個像素值,而5×5 模板需要計算鄰域內25 個像素值,需要循環此數據通路3 次。在前2 次循環中,需要將計算的中間結果寫回寄存器堆2 次,讀出寄存器堆2 次,第3 次循環結束時完成計算。對于7×7 的模板,需要寫回寄存器堆5 次,讀寄存器堆5 次,第6 次循環結束后完成計算。
2.2.3 全局處理函數映射
在進行全局參數計算時,由于運算器的資源有限,有時需要將部分計算或比較結果存入寄存器堆中。以計算輸入圖像的均值為例,輸入數據的類型為vx_unit8,輸出數據的類型為vx_float32。均值的計算如式(9)所示:

由于實現Sobel 3×3 濾波流水線電路需要8 個定點加法器,因此進行平均值計算最多需要8 個定點加法器約束,平均值計算采用并行結構結合流水線的的數據通路映射方案,如圖8 所示。映射過程為:第1 級對4 行像素并行累加計算,每1 行計算結束后進行換行操作,一直迭代到最后一行像素;第n+1 級用a4、a5對4 個累加結果兩兩計算;第n+2 級計算a4、a5的和以及W×H;第n+3 級計算浮點除法。完成平均值并行計算需要7 個定點加法器、1 個定點乘法器及1 個浮點除法器。
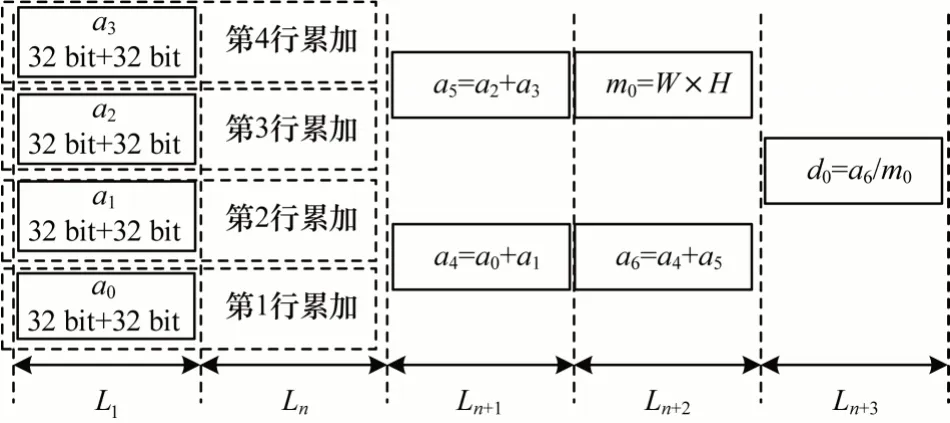
圖8 并行計算均值Fig.8 Parallel computing mean
2.2.4 特征提取類函數映射
Canny 邊緣檢測計算過程相對復雜,需要將中間結果寫回存儲中,處理過程主要分為3 步:梯度幅值和方向計算,非極大抑制及邊緣追蹤。
1)梯度幅值和方向計算
將輸入圖像與指定大小的垂直和水平方向的Sobel 算子進行卷積,使用兩個定向梯度圖像Gx和Gy計算梯度大小和梯度方向。當計算梯度的類型為VX_NORM_L1 時,梯度幅值為|Gx|+|Gy|。由于arctan(x)計算復雜,且在非極大值抑制中只需知道像素的梯度方向在哪塊區域即可,不需要求出實際的角度。因此,本文根據Gx、Gy的倍數關系及符號判斷梯度方向,將梯度方向劃分為4 個區域path_1、path_2、path_3 和path_4。計算梯度幅值和方向具體數據通路的映射如圖9 所示。其中:第1 級利用Sobel 算子計算水平、垂直方向的梯度幅值Gx和Gy以及符號類型;第2 級計算梯度幅值G,判斷path_1 及path_3 的類型;第3 級判斷path_2及path_4 的類型;第4 級把梯度幅值及梯度類型寫回存儲中。
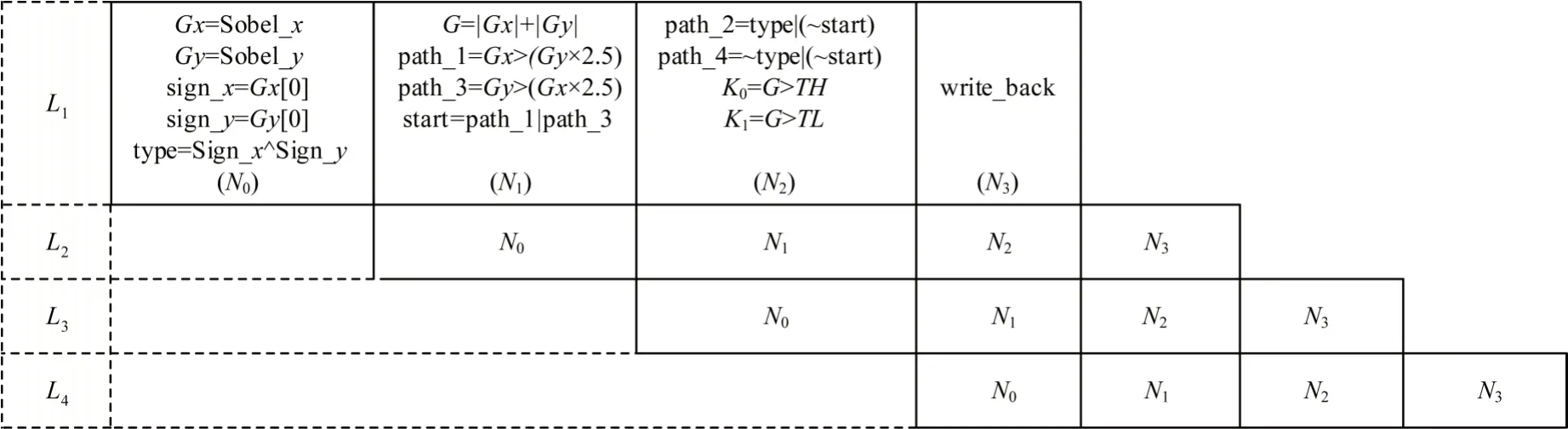
圖9 梯度幅值和方向計算Fig.9 Calculation of gradient amplitude and direction
2)非極大抑制
非極大抑制是僅當檢測像素的梯度大小在垂直于其邊緣方向上大于或等于像素時,才將檢測像素保留為潛在邊緣像素。例如,當像素的梯度方向為0°時,則其梯度幅值大于像素為90°和270°時的梯度幅值,才保留像素作為邊緣。非極大抑制的映射過程為:第1 級從緩存中讀出當前像素梯度及鄰域內8 個像素的梯度值及梯度方向類型{path_4,path_3,path_2,path_1};第2級根據{path_4,path_3,path_2,path_1}的值分別在4個方向進行像素梯度幅值的比較,并輸出比較結果;第3級將比較結果寫回存儲中。
3)邊緣追蹤
輸出圖像的最終邊緣通過雙閾值法進行識別。所有梯度幅度大于高閾值的像素均標記為已知邊緣像素(非0),小于等于低閾值的像素賦0。對于高閾值和低閾值間的像素使用8 連通區域確定,只有與高閾值像素連接時才被視為邊緣點。邊緣追蹤的映射過程為:第1 級從存儲中讀出非極大抑制后像素比較的結果;第2 級對大于高閾值的像素值直接賦255;大于低閾值的像素值進行8 個鄰域像素值與高閾值進行比較,若大于高閾值,則輸出255,否則輸出0。
2.3 所需運算單元分析
所需運算單元的分析如下:
1)所需運算單元種類的分析
由表1 可知,OpenVX 1.3 支持定點和浮點數據類型,所以設計的數據通路運算器中需要包含定點計算單元和浮點計算單元。根據上述函數的映射方案可知,色系變換中需要用到定點加法和定點乘法運算,仿射變換需用到浮點加法和浮點乘法運算,透視變換需用到浮點加法、浮點乘法和浮點除法計算,均值計算需用到定點加法、定點乘法、定點除法和浮點除法計算,Sobel 需要用到定點加法計算。綜上,設計的數據通路運算器需包含定點加法器、定點乘法器、定點除法器、浮點加法器、浮點乘法器和浮點除法器。
2)所需運算單元數目的分析
由于采用不同數目運算器構建的流水線映射方案不同,處理不同函數所需的時間也不同,因此需要用時序圖排序來分析各種OpenVX 函數是否達到或者接近最佳性能。當采用不同個數的運算器時,分別對色系變換函數、仿射變換函數、均值計算函數、Sobel 濾波函數進行時序圖的排序分析。
色系變換時序圖如圖10 所示。由圖10(a)可知,當采用1 個定點乘法器和2 個定點加法器時,色系變換函數在第5 個時鐘周期時處理完第1 個像素,流水線輸出時每隔2 個時鐘周期輸出1 個像素。由圖10(b)可知,當采用2 個定點乘法器和2 個定點加法器時,色系變換函數第5 個時鐘周期處理完第一個像素,流水線輸出時每隔1 個時鐘周期輸出一個像素,處理性能較好。由圖10(c)可知,當采用3 個定點乘法器和2 個定點加法器時,色系變換第3 個時鐘周期處理完第1 個像素,流水線輸出時每個時鐘周期產生1 個像素,處理性能最好。
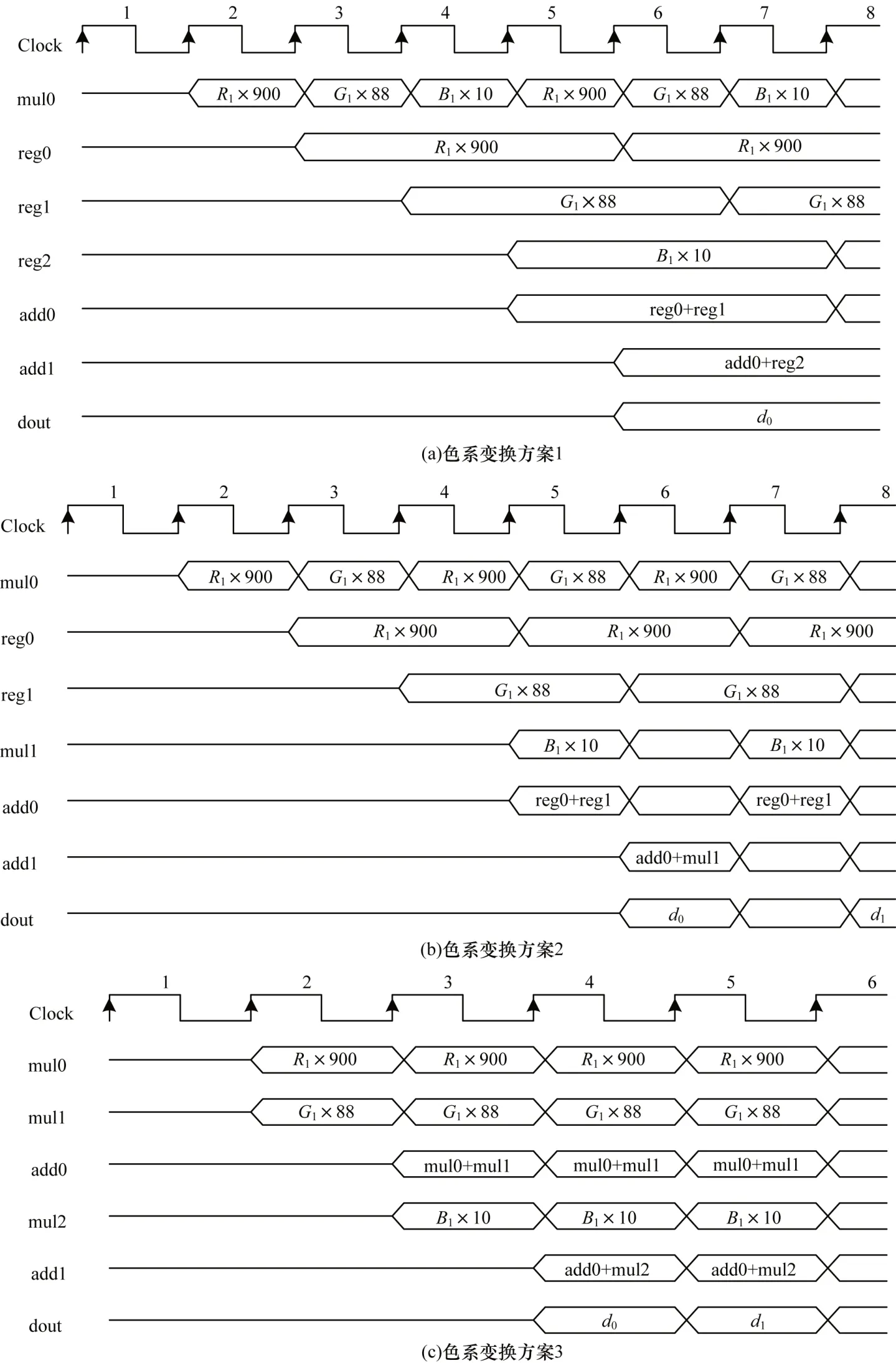
圖10 色系變換時序圖Fig.10 Sequence diagram of color convert
仿射變換時序圖如圖11所示。由圖11(a)可知,當采用1個浮點乘法器和4個浮點加法器時,仿射變換處理在第5個時鐘周期時處理完第1個像素,流水線輸出時每隔4個時鐘周期輸出1個像素。由圖11(b)可知,當采用2個浮點乘法器,4個浮點加法器時,仿射變換處理在第4個時鐘周期時處理完第1個像素,流水線輸出時每個時鐘周期產生1個像素,處理性能較好。由圖11(c)可知,當采用4個浮點乘法器、4個浮點加法器時,仿射變換處理第3個時鐘周期處理完第一個像素,流水線輸出時每個時鐘周期產生一個像素,處理性能較好。

圖11 仿射變換時序圖Fig.11 Affine transformation sequence diagram
Sobel濾波時序圖如圖12 所示。由圖12(a)可知,當采用4個定點加法器時,Sobel 3×3濾波在第7個時鐘周期時處理完第一個像素,流水線輸出時每隔1個時鐘周期產生1 個像素。由圖12(b)可知,當采用6 個定點加法器時,Sobel 3×3 濾波在第6 個時鐘周期時處理完第1 個像素,流水線輸出時每隔1 個時鐘周期產生1 個像素,處理性能較好。由圖12(c)可知,當采用8個定點加法器時,Sobel 3×3 濾波在第4 個時鐘周期時處理完第1 個像素,流水線輸出時每個時鐘周期輸出1 個像素,處理性能最好。
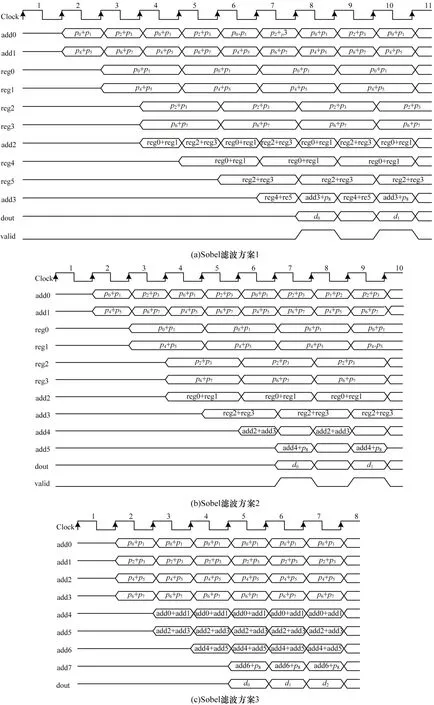
圖12 Sobel 濾波時序圖Fig.12 Sobel filtering sequence diagram
均值計算時序圖如圖13 所示。由圖13(a)可知,當采用1 個定點加法器、1 個定點乘法器、1 個浮點乘法器時,均值計算函數在第11 個時鐘周期時處理完第1 個像素,流水線輸出時每隔9 個時鐘周期完成1 次均值計算。由圖13(b)可知,當采用3 個定點加法器、1 個定點乘法器、1 個浮點乘法器時,均值計算函數第6 個時鐘周期處理完第1 個像素,流水線輸出時每隔4 個時鐘周期輸出1 個像素,處理性能較好。由圖13(c)可知,當采用7 個定點加法器、1 個定點乘法器、1 個浮點乘法器時,均值計算函數第4 個時鐘周期處理完第1 個像素,流水線輸出時每隔2 個時鐘周期輸出1 個像素,處理性能最好。

圖13 均值計算時序圖Fig.13 Mean calculation sequence diagram
從函數處理的性能和電路面積以及電路的可編程性、靈活性考慮,確定定點加法器數目為8 個,定點乘法器數目為4 個,定點除法器數目為2 個,浮點加法器數目為4 個,浮點乘法器數目為2 個,浮點除法器數目為2 個,從而滿足上述函數的高效通用處理要求。
3 數據通路運算器的設計
3.1 數據通路運算器的整體結構
根據OpenVX 1.3 中各類函數的實現方法,將所需計算單元進行分析后,設計出的OpenVX 并行可重構數據通路運算器[14-15]如圖14 所示,包括基本運算單元(arithmetic unit)、數 據 交 叉 互 聯 模 塊(cross-bar interconnect)、指令配置模塊(ins_config)、指令存儲(ins_cache)、數據寄存器堆(register file)和讀/寫控制模塊(rd/wr_ctl)。基本運算單元的設計是根據具體函數的映射要求,將加法器和乘法器設計為并行可拆分的結構,以適應多種數據格式的要求。數據通路運算器的執行過程如下:指令配置單元從指令存儲中取出相應的指令,發送給數據交叉互聯模塊、rd/wr_ctl 單元和基本運算單元。rd/wr_ctl 模塊根據指令從寄存器堆中取出相應的運算數據并進行譯碼及截位處理,并輸出到交叉互聯電路。交叉互聯電路根據相應的配置信息將數據送入運算單元。運算單元根據相應指令配置進行計算,并將計算結果寫回到交叉互聯電路或輸出。
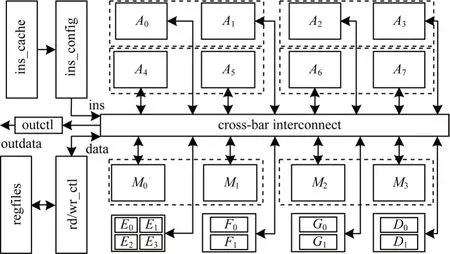
圖14 數據通路運算器的總體結構Fig.14 Overall structure of the data path arithmetic unit
數據通路運算器支持的計算類型和計算速度直接影響整體處理器的性能參數[16]。本文設計的數據通路運算器共有22 個基本計算單元,包括:8 個定點加法器(A0~A7),4 個定點乘法器(M0~M3),2個定點除法器(D0,D1),4個浮點加法器(E0~E3),2個浮點乘法器(F0,F1)及2個浮點除法器(G0,G1)。各運算單元之間采用數據通路合并、功能單元共享、電路資源復用等方法,以減少整體面積占用[17]。各運算單元支持多種數據類型,定點計算單元支持8位有/無符號數、16位有/無符號數、32位有/無符號數的運算,浮點單元支持32 位浮點數的運算。
3.2 子模塊內部結構
3.2.1 定點單元設計
定點單元支持的計算類型包括定點算術類和定點邏輯類計算,其中定點算術類計算包括定點加、減、乘、除、絕對值和比較。定點邏輯類計算包括邏輯與、邏輯或、邏輯非、邏輯異或和邏輯移位。
1)定點加法器
定點加法器的設計依照數據通路的映射方案及數據類型,根據指令配置可并行計算2 個32 位,或4 個16 位,或8 個8 位的有符號、無符號數定點加法。加法運算的關鍵路徑在進位鏈上[18],為縮短這一關鍵路徑,加法器的設計采用進位選擇加法器(CSA),并設計基本單元為8 位的進位選擇加法器。
2)定點乘法器
定點乘法器的設計采用混合乘加結構(Fused Multiply Add,FMA),依照數據通路的映射方案及數據類型,混合乘加運算器可根據控制信號完成32 位的混合乘加運算,支持2 組32 位、4 組16 位、8 組8 位定點數的加法或乘法運算,提高數據并行計算的能力。采用混合乘加運算數據通路,可以減小邏輯電路大小。混合乘加器的電路設計如圖15 所示,功能復用上述的進位選擇加法器,從而減少整個電路的面積。混合乘加器可根據控制信號對加法進位鏈進行截斷,并輸出相應的加法計算結果或乘法計算結果。

圖15 混合乘加器結構Fig.15 Fused multiply adder structure
3)定點除法器
定點除法器的設計采用牛頓迭代(Newton Raphson)算法[19],該算法利用乘法運算代替除法運算,算法的主要步驟為求1/b,設f(x)=1/x-b,則在x=1/b處f(x)=0。應用牛頓迭代公式,可得:

傳統的牛頓迭代除法器將式(10)中的2 次乘法和1 次加法并行計算,增加了路徑延遲,具體電路如圖16所示。本文在其基礎上做的改進如圖17 所示,設計中復用定點運算中的定點加法和定點乘法模塊,從而加快運算速度;針對迭代運算,將乘法和加法計算拆分為3 級流水線,以縮短路徑延遲及提高運行速率。
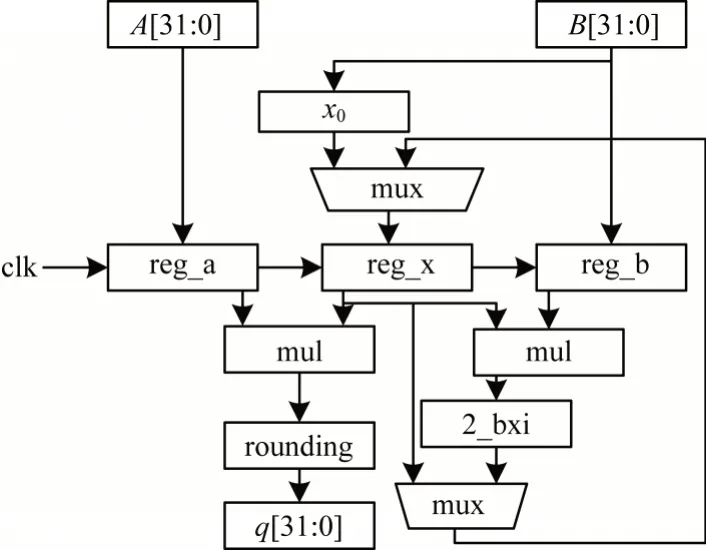
圖16 傳統的牛頓迭代除法器Fig.16 Traditional newton raphson divider

圖17 改進的牛頓迭代除法器Fig.17 Improved newton raphson divider
3.2.2 浮點單元設計
浮點單元設計如下:
1)浮點加法器
浮點加法器支持單精度浮點運算類型,包括浮點加、減定浮點轉換。浮點加法器設計為3 級流水線:操作數階碼對齊、尾數計算級、輸出結果規格化。流水線浮點加法器可以在每個時鐘周期接收一條浮點加法或減法指令[20]。
2)浮點乘法器
浮點乘法器是在Booth 算法、Wallace 樹型結構[21]以及進位選擇加法器基礎上,設計為3 級流水線,具體電路如圖18 所示。第1 級流水線通過異或門計算乘數和被乘數的符號位。第2 級流水線將乘數的指數部分和被乘數的指數部分偏置相加,根據溢出情況和尾數最高位調整指數后對指數規范化處理,此外,采用基4 的Booth 算法減少部分積的個數,用Wallace 樹形乘法器計算部分積。第3 級流水線完成尾數部分的計算及調整輸出結果。

圖18 浮點乘法器Fig.18 Floating point multiplier
3)浮點除法器
浮點除法器的設計采用基于牛頓迭代算法的流水線浮點除法器,尾數計算部分采用24 位牛頓迭代除法器模塊。浮點除法器的設計如圖19 所示,其流水線劃分為4 級:牛頓迭代計算,部分積計算,定點加法運算和規格化輸出。
4 實驗結果與分析
4.1 實驗結果
通過Modelsim SE-64 10.4 仿真驗證平臺編寫相應的測試程序,并對色系變換、腐蝕、膨脹、Sobel和Canny邊緣檢測函數進行功能仿真,實驗結果如圖20 所示。其中,圖20(a)表示未經處理的640 像素×480 像素的原圖像,圖20(b)表示經過色系變換后得到的結果,圖20(c)表示經過腐蝕操作后的結果,圖20(d)表示經過膨脹操作后的結果,圖20(e)表示經過Sobel 3×3 濾波后的結果,圖20(f)表示經過Canny邊緣檢測后的結果。由圖20可知,使用不同算法在測試程序上進行功能仿真,均可達到預期處理目的,且和軟件處理結果相同。
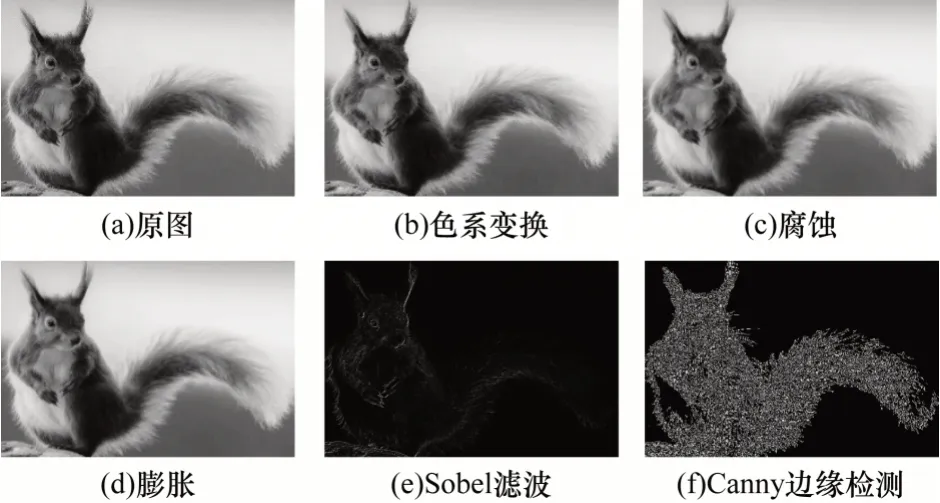
圖20 不同函數的功能仿真結果Fig.20 Functional simulation results of different function
將上述函數的算法在數據通路運算器上進行映射后,對每秒處理后的圖像幀數進行統計如表2 所示。由表2可知,當屏幕刷新率為640像素×480像素@60 Hz,800像素×600像素@60 Hz,1 024像素×768像素@60 Hz及以下標準時,色系變換、Sobel、腐蝕和膨脹均可達到快速刷新并顯示的要求。
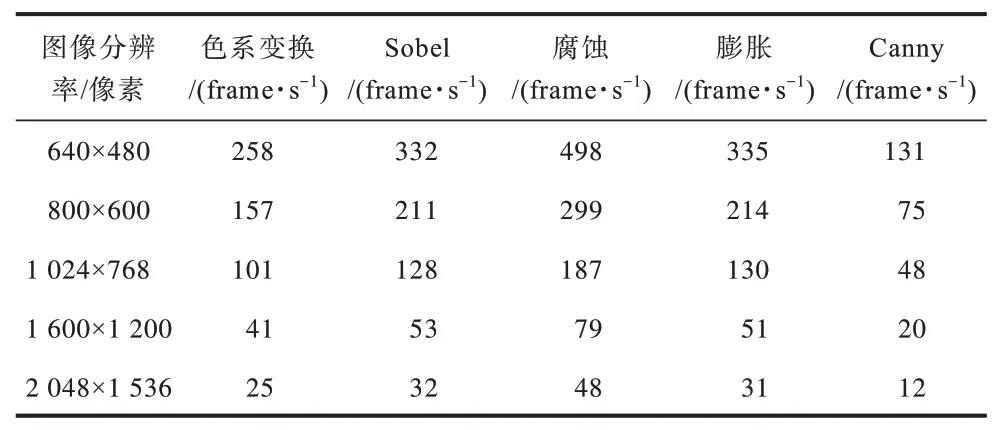
表2 不同分辨率下每秒處理的圖像幀數Table 2 Image frames per second processed under different resolutions
當處理圖片的分辨率在1 600 像素×1 200 像素、2 048 像素×1 536 像素及以上時,單個數據通路運算器無法滿足實時性及高速率的通用圖像處理要求,此時需要將多個數據通路運算器采用互聯拓撲結構組合構成OpenVX 并行處理器,在并行處理器上獲得處理性能的提升,達到實時處理的目的。
4.2 性能分析
采用Synopsys 公司綜合工具Design Compiler,鏈接SMIC 65nm CMOS 工藝庫對整體電路及各運算器進行綜合實現,并得到時序報告、面積報告和功耗報告。對于32 位的除法運算,本文改進的牛頓迭代除法器最大主頻可達520 MHz,相同實驗條件下,對比傳統的牛頓迭代除法器,其速率提升了22%。根據綜合結果對整體電路進行性能分析,結果如表3 所示,電路的時延為2 ns,且1/2 ns=500 MHz,因此系統最高時鐘頻率達500 MHz,系統的吞吐量為1.86 GB/s。

表3 整體電路性能分析Table 3 Overall circuit performance analysis
5 結束語
本文對OpenVX 1.3 標準中kernel函數算法進行分析與映射,根據映射后電路的時序圖分析運算器數目,并基于分析結果對可重構數據通路運算器構建整體結構及內部子模塊。此外,對可重構數據通路運算器進行靈活編程,設計基于OpenVX 1.3 標準的kernel 函數算法,完成通用的圖像處理。實驗結果表明,基于OpenVX 的并行可重構數據通路運算器能滿足實時及高速率的通用圖像處理要求。下一步將優化各運算單元性能,通過設計處理性能更好的運算器及編寫相應的微指令,實現上層復雜特征提取函數的數據通路映射。
