基于CycleGAN的真實場景到動漫風格圖的轉換應用
2021-12-17 11:18:50張格格李丹
電子測試 2021年22期
張格格,李丹
(四川大學錦城學院,四川成都,611731)
1 介紹
CycleGAN是一個可以用于未配對數據的轉換的對抗網絡。它做的事情是在一個圖片集中捕獲出特殊的特征,然后將這些特征轉移到其他圖片集上。可以將這個問題描述為圖像到圖像的轉換或翻譯。它是從一個給定場景的表示形式中轉換圖像,例如將現實生活中的場景轉化為某一種風格的畫作(例如將玫瑰花照片轉換為梵高風格畫作的圖片)。雖然CV研究圖像加工、計算攝影技術和圖像學經過多年的研究,在有監督的情況下已經產生了強大的可用成對出現的樣本圖片轉換系統[1]。但獲得配對好的圖像數據于我們而言是一件困難且需要耗費很大成本的事情,而現有的CycleGAN可以實現任意類似數據圖像的轉換。因此我們可以將CycleGAN模型用于此方面的轉換,或者運鏡時的視頻轉換。而此篇文章主要是使用CycleGAN來實現現實世界中的場景到動漫風格圖片的轉換。
2 相關工作
2.1 生成性對抗網絡
生成性對抗網絡在圖像生成[2,3]、圖像編輯[4]和表示法學習[3,5,6]上早已獲得令人贊嘆的結果,而生成性對抗網絡成功的關鍵是對抗性損失想法的提出,即強迫生成圖像在一次次的訓練中逼近真實圖片,使得鑒別器無法將生成圖像成功的鑒別為假。這個損失在圖像生成任務中的功能很強,而循環一致性對抗網絡就采用了一個對抗損失來學習這個映射,從而使得生成圖像很逼真。
2.2 圖像到圖像的轉換
Hertzmann等人提出的圖像類比[7]推動了人們對圖像到圖像的轉換的想法。他們是在一個單一輸入輸出的訓練圖像對上使用一個非參數化的紋理模型,而循環一致性對抗網絡則是在建立在Isola等人的pix2pix框架基礎之上提出的。pix2pix也是在成對的數據集上進行,它使用了一個條件式對抗網絡來學習一個輸入圖像到輸出圖像的映射。
2.3 未配對圖像之間的轉換
除了CycleGAN之外,也有其他的方法可以處理未配對的情況。這些方法的目標都是關聯兩個數據域X和Y。而CycleGAN作者的構想不依賴于任何任務的特異性。即在輸入和輸出間的預定義的相似度函數中,并不假設輸入和輸出處于相同的低維嵌入空間。這樣一來,CycleGAN就成為了許多視覺和圖形任務的通用解決方案。
2.4 循環一致性
循環一致性使用傳遞性作為規劃結構數據的方式已經有了很長的一段歷史。CycleGAN則是使用了類似于一個循環一致性損失作為用傳遞性來監督CNN訓練的途徑[8,9]的損失去推動G和F的一致性。
2.5 圖像風格遷移
它基于匹配預訓練的深度特征的Gram矩陣統計數據來將一個圖像的內容和另一個圖像的風格進行結合來綜合出一個新的圖像。而CycleGAN則是把重點放在兩個圖像集的映射而不是兩個特定的圖像。這也為我將現實場景轉換為動漫風格圖像提供了條件。
2.6 AnimeGAN和AnimeGANv2
AnimeGAN[10]是基于CartoonGAN[11]的改進,它可以將現實場景進行動漫畫風的圖像轉換。它提出了一個更加輕量級的生成器結構,也提出了三個全新的損失函數(灰度風格損失、灰度對抗損失、顏色重建損失)用來提升風格化的動漫視覺效果。
AnimeGANv2則是基于AnimeGAN的改進,與后者相比,它的生成器網絡的參數數量更少。它目前支持宮崎駿、新海誠和今敏的三種畫風的風格遷移,同時也支持視頻圖像的風格轉換。而CycleGAN相較于它們有更廣泛的圖像風格轉換空間。
3 所用公式
循環一致性對抗網絡中的關鍵在于他的循環損失計算,總循環損失公式為:

來計算出由域X生成的圖像G(x)與域Y的目標風格圖像的差值損失,鑒別器Y則用于鑒別G(x)和域Y的圖像哪個為真哪個為假。生成器與鑒別器的對抗網絡使得該損失不斷的降低。這樣不斷的對抗訓練可以使得生成器G能夠產生更加逼近真實圖像的圖像。反之理論一樣。循環一致性對抗網絡希望找到能使該循環損失降到最低的情況,這樣就能使由域X和域Y生成的圖像越來越逼近于真實圖像。
理論上來說,對抗性訓練可以學習映射函數G和F,使它們分別產生與目標域Y和X相同分布的輸出。嚴格來說,需要的G和F是隨機的函數[16]。然而當具有足夠大的容量時,對抗網絡可以將相同的一組輸入圖像映射到目標域中任意隨機排列的圖像,其中任何學習過的映射都可以產生與目標分布相匹配的輸出分布。因此,只有對抗性損失并不能保證學習過的好的函數可以將單獨的輸入xi映射到需要的輸出yi。
為了防止生成器學習到具有欺騙性的造假數據(不是根據輸入得到的生成圖),以及進一步減少可能的映射函數的區間,學習過的映射函數就應該是循環一致的,如圖1(b)中顯示的那樣,對于每個X域中的圖片x,應該確保圖像循環轉換應該能讓x回到原來的圖像,即x→G(x)→F(G(x))≈x。將其稱為前向循環一致性。同樣地,對于每個Y域的圖像y,G和F也應該滿足反向循環一致性:y→F(y)→G(F(y))≈y。因此,使用循環一致性損失函數Lcyc(G,F)來得到這樣的表現:
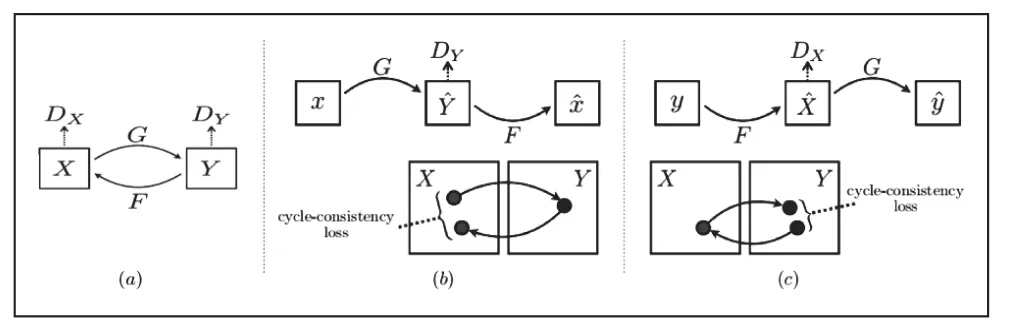
圖1 循環一致損失

該循環損失約束了生成的圖像要盡力的去保留源域的內容和貼近目標域的風格,以不致生成的圖像丟失了源域的內容而只是去盲目地貼合目標域的風格。
4 網絡體系結構與訓練細節
CycleGAN的網絡結構來自Johnson等人的可生成式網絡結構。CycleGAN網絡使用6個128x128的圖像塊和9個256x256的圖像塊以及高分辨率的訓練圖像,同后者一樣使用歸一化的實例進行研究。CycleGAN的鑒別器網絡是70*70的PatchGANs[12,13,14],PatchGANs主要是對70*70大小的重疊的圖像斑塊的真假進行分類。
模型的訓練從開始到穩定,一共用了兩個過程,首先對于方程式(2),它用一個最小二乘函數替換了負數對數的客觀存在二點可能性。這使得訓練過程更加穩定,生成結果有更高的質量。第二,為了減少模型的震蕩,CycleGAN引用了Shrivastava等人的策略,使用由最新生成器產生的圖片更新鑒別器。CycleGAN使用了一個緩沖區來存儲50張之前的生成圖片,在方程式(1)中設置λ的值為10,使用批處理大小為1的Adam求解程序[15]。所有的網絡都從學習率為0.0002開始訓練,在前100個輪次里保持相同的學習率,并在接下來的100輪將速率線性降低至零。
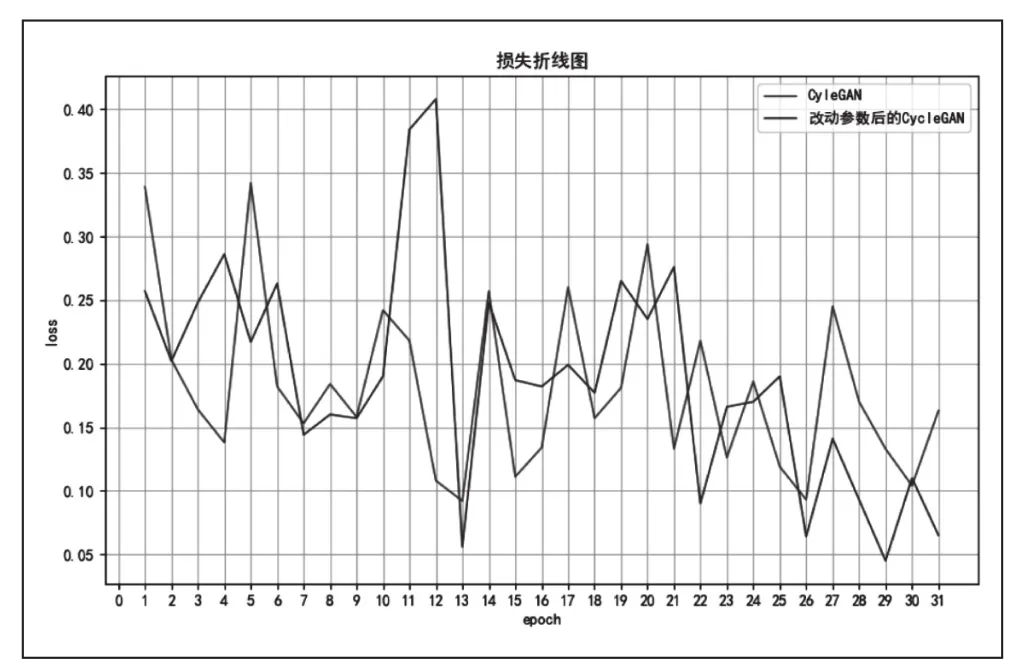
圖2 訓練過程的損失折線圖
在我這次所做的將實物場景圖轉換為動漫風格圖像過程中,我在netG參數中新加了一個ResnetGenerator_1網絡,它與原來的ResnetGenerator網絡的差別在于,我將上采樣由兩層改為一層,并將λA的值由10改為30,這樣做的結果可以使生成圖像更加清晰和契合目標圖像的風格,原模型與改進后的模型訓練過程損失值變動如圖3所示。

圖3 測試結果圖展示
5 結果
圖3中展示了原圖與原CycleGAN模型以及和我改動部分參數之后的模型測試結果圖。圖中可以很清楚地看出,改動參數之后的模型產生的圖像比原模型的生成圖像更加符合目標圖像設想。
6 使用兩個指標的結果評價
PSNR,即峰值信噪比,它是最普遍和使用最廣泛的一種評價圖像的客觀標準,但它是基于對應像素點間的誤差,也就是說是基于誤差敏感的圖像質量評價。因為它并不考慮人眼的視覺特性,因此它的評價結果與人的感覺常常不一致。
SSIM,結構相似性,它用于衡量兩幅圖像的相似度,它使用一張未經壓縮的無失真圖像和一張失真后的圖像。取值的范圍為-1到1。它的公式基于樣本x和y之間的亮度、對比度和結構的比較衡量。
表1展示了PSNR和SSIM兩個指標對原模型和我改動參數后的模型進行評價的結果。我在改動模型參數后,兩個指標都有所提升。

表1 PSNR和SSIM指標的評價結果
雖然改動后的模型測試結果相較原模型更好,但仍在圖像清晰度和圖像風格契合度上有所不足。
7 現實場景圖轉換為動漫風格圖的實際應用
在現代生活中,動漫被很多年齡段的人所需求即動漫有著很廣泛的市場。且相較于真實演繹的作品而言,動漫的制作更加的依賴于電子產品。而制作動漫往往要消耗很多精力和時間。聯想到很多現實世界中的場景效果是可以直接或者稍加修改之后放到動漫中使用的。圖4展示了該算法在實例中的實現流程,即:首先對現實場景進行拍攝,然后使用CycleGAN算法對其進行動漫風格的轉換,之后將其應用到具體動漫的制作過程中。如此一來就可以使得動漫中部分過程的制作變得簡單,使整個動漫的制作變得相對輕松一點。通過將現實中的場景照片轉化為動漫風格的照片可以在一定程度上節約資源,也便于更多的場景聯想。

圖4 轉換應用流程圖
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
歷史教學問題(2021年4期)2021-11-05 07:02:34
中醫眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國公共安全(2017年11期)2017-02-06 05:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
燕山大學學報(2015年4期)2015-12-25 02:19:49
