基于深度殘差生成對抗網絡的運動圖像去模糊
2021-12-16 08:15:28魏丙財張立曄孟曉亮王康濤
液晶與顯示 2021年12期
魏丙財, 張立曄, 孟曉亮, 王康濤
(山東理工大學 計算機科學與技術學院,山東 淄博 255000)
1 引 言
由于相對運動、鏡頭抖動、相機內部傳感器噪聲、天氣因素(霧霾等)、相機散焦等原因,導致圖像在拍攝、傳輸和儲存時會產生一定的退化,造成圖像質量下降,產生模糊[1]。其中運動模糊圖像主要是由于相機與物體在短曝光時間內發生相對運動造成的。為了從運動模糊圖像中提取有用的信息,圖像復原已成為圖像處理的一個重要研究方向,也是數字圖像處理的一個重要應用。圖像復原技術可以消除或減少圖像退化的問題,獲得更清晰的圖像。
早期的圖像去模糊研究,一般是在去模糊過程中假設模糊特征,利用圖像的先驗知識估計模糊核。因此,圖像去模糊的重點之一是確定模糊核。根據模糊核的已知與否,去模糊方法可以分為兩大類:一類模糊核已知,稱為非盲復原;另一類模糊核未知,稱為盲復原。
非盲復原又稱為傳統圖像復原算法,此種方法會根據已知的模糊核,進行解卷積操作,如逆濾波、L-R算法、維納濾波等算法。由于在實際應用中很難獲得精確的模糊核,因此非盲復原表現較差,無法得到清晰的復原圖像。
現實場景中盲復原的應用場景更廣泛。早期的研究大多使用圖像先驗,包括全變差、重尾梯度先驗或超拉普拉斯先驗,它們通常以由粗到細的方式應用于圖像,如Pan等人提出了基于圖像暗通道先驗的模糊核估計方法[2],Levin等利用一種超拉普拉斯先驗建模圖像的梯度來估計模糊核[3]。
近年來,隨著深度學習算法的發展,以卷積神經網絡(Convolutional Neural Network, CNN)為代表的深度學習算法被大量應用到圖像盲去模糊領域。相比于早期根據圖像先驗信息的盲去模糊算法,深度學習算法可以做到比圖像先驗更好的效果。Xu等人引入了一種新穎的、可分離結構的卷積結構來進行反卷積,取得了不錯的去模糊效果[4]。Su等人利用CNN進行端到端訓練,利用視頻中幀與幀之間信息,實現了視頻去模糊[5]。
在真實數據集上,由于圖像模糊核未知,文獻[6]和文獻[7]中提出利用CNN預測圖像模糊核,實現模糊數據集的合成,最終實現了圖像去模糊。然而,核估計涉及到幾個問題。首先,假設簡單的核卷積不能模擬一些具有挑戰性的情況,如閉塞區域或深度變化。其次,核估計過程是微妙的,對噪聲和飽和度敏感,所以模糊模型必須花費大量精力進行精心設計。第三,為動態場景中的每個像素尋找空間變化的模糊核需要大量的內存和算力。當模糊核參數無法進行準確估計時,上述方法都無法獲得理想的效果[8]。因此,文獻[8]和文獻[9]摒棄了模糊核的估計過程,直接使用CNN實現了端到端的動態去模糊。
2014年,Goodfellow等人[10]提出了生成對抗網絡(Generative Adversarial Networks, GAN)。GAN由兩個相互競爭的網絡構成,一個稱為生成器,一個稱為判別器。生成器負責接收隨機噪聲輸入,然后合成數據樣本,它的目標是令其盡量像正式數據樣本,以“欺騙”判別器。判別器負責判斷輸入數據是生成器合成的“偽造”樣本還是真實樣本,它的目標是盡量將二者區分開。一個好的生成對抗網絡目標就是讓判別器判斷真偽的概率接近0.5,即無法判斷是否是生成器產生的樣本。
由于性能強大,GAN很快被用于圖像去模糊領域。生成對抗網絡中的生成器負責接受模糊圖片,將其復原,目標是生成類似清晰圖像的去模糊圖像,以騙過判別器;而判別器負責分別接收原始清晰圖片以及生成器去模糊后的圖片,盡量將二者區分。
Mao等人針對的是標準GAN生成的圖片質量不高以及訓練過程不穩定這兩個缺陷進行改進,在判別器中使用最小二乘損失,提出了LSGAN,能夠生成較高質量的圖像[11]。Johnson等人提出用于風格遷移任務的網絡,提出了感知損失函數,可以較好地衡量模型的質量[12]。Kupyn等人提出DeblurGAN[13],運用條件生成式對抗網絡和內容損失函數(Content Loss Function)實現了運動圖像模糊的去除。由于單個神經網絡同時用于模糊與清晰數據的訓練得到的合成模糊圖像不能精確模擬真實場景的模糊過程,Zhang等人提出利用兩個GAN,將其中一個負責圖像的模糊,另一個負責圖像的去模糊,實現了真實模糊去模糊[14]。
受到上述研究的啟發,本文對GAN進行了改進。首先,改進了PatchGAN的結構,在網絡參數只增加2.38%的前提下,將其最底層感受野提升至原先的兩倍以上。其次,改進了殘差塊的結構,增加了卷積層數量,用以提升復原圖像的質量。最后,基于GOPRO數據集和Lai數據集的仿真結果驗證了本文提出的算法的有效性。
2 圖像模糊與去模糊
2.1 圖像的模糊
圖像模糊模型可以表示為:
IB=K*IS+N,
(1)
其中:IB為模糊后的圖像,IS為原圖像,K為卷積核,N為加性噪聲,*為卷積操作。
另外,模糊圖像也可以通過逐幀模糊產生。對于模糊空間變化的圖像,沒有相機響應函數(Camera Response Function, CRF)的估計技術[15],CRF可以近似為已知的CRF的平均值[14],如公式(2)所示:
g(IS(i))=IS′(i)γ,
(2)
其中γ是一個參數,一般認為其等于2.2。潛在的清晰圖像IS(i)可通過觀察到的清晰圖像IS′(i)得到。仿真的模糊圖像IB可以通過式(3)得到:
(3)
其中:M代表清晰幀的個數,t代表某個時間,IS(t)代表時間t對應的清晰幀。
而真實的模糊圖像實際上是多幀清晰圖像的集成[16],可表示為式(4):
(4)
其中T為曝光時間周期。
現實世界的真實模糊圖像如圖1所示。

圖1 現實生活中的運動模糊圖片Fig.1 Motion blurred images in real life
2.2 圖像的去模糊
圖像去模糊就是對給定的模糊圖像進行復原,得出相應的原始圖像[17]。
非盲去模糊是指通過給定的已知模糊核進行圖像的去模糊,而盲去模糊問題是指從給定噪聲圖像Y中估計出原圖像X和模糊核Z。
盲去模糊過程可以表示為:
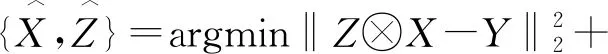
(5)
其中:φ(X)和θ(Z)分別是預期的清晰圖像的正則化項和可能的模糊核。
3 相關工作
3.1 生成對抗網絡
生成對抗網絡(GAN)中包含兩個相互競爭、相互對抗的網絡——生成器和判別器(圖2)。GAN中的對抗思想可以追溯到博弈論的納什均衡,對抗的雙方分別是生成器和判別器。二者對抗的目標函數可以描述為:
(6)
其中:x表示來自Pdata(x)真實樣本,Ex~Pdata(x)為輸入清晰圖像的期望,D(·)表示判別器D的輸出,G(·)表示生成器G的輸出。

圖2 GAN的結構Fig.2 Structure of GAN
GAN自發明以來,一直是深度學習領域研究的重點,又有多種變體,如DCGAN,將生成對抗網絡與卷積神經網絡結合,幾乎完全使用卷積神經網絡代替全連接層;條件生成對抗網絡CGAN,在原始GAN的輸入上進行改進,將額外條件信息如標簽在輸入階段即傳遞給生成器與判別器;WGAN,在損失函數方面對GAN進行改進,提出wassertein距離損失函數與權重截斷(Weight Clipping)措施,進一步提升了GAN的性能[18];WGAN-GP[19],在WGAN基礎上進行改進,提出權重懲罰措施,有效防止WGAN可能發生的梯度消失、梯度爆炸以及權重限制困難等問題。
3.2 殘差塊及其改進
殘差塊[20]包括:兩個權重層,中間包含一個ReLU激活函數,然后是一個跳躍連接塊,之后是一個ReLU激活函數。跳躍連接塊可實現梯度的跨層傳播,有助于克服梯度衰減現象。通過添加殘差塊,可以在加深網絡結構的情況下,較好地解決梯度消失和梯度爆炸的問題。殘差塊結構如圖3所示。
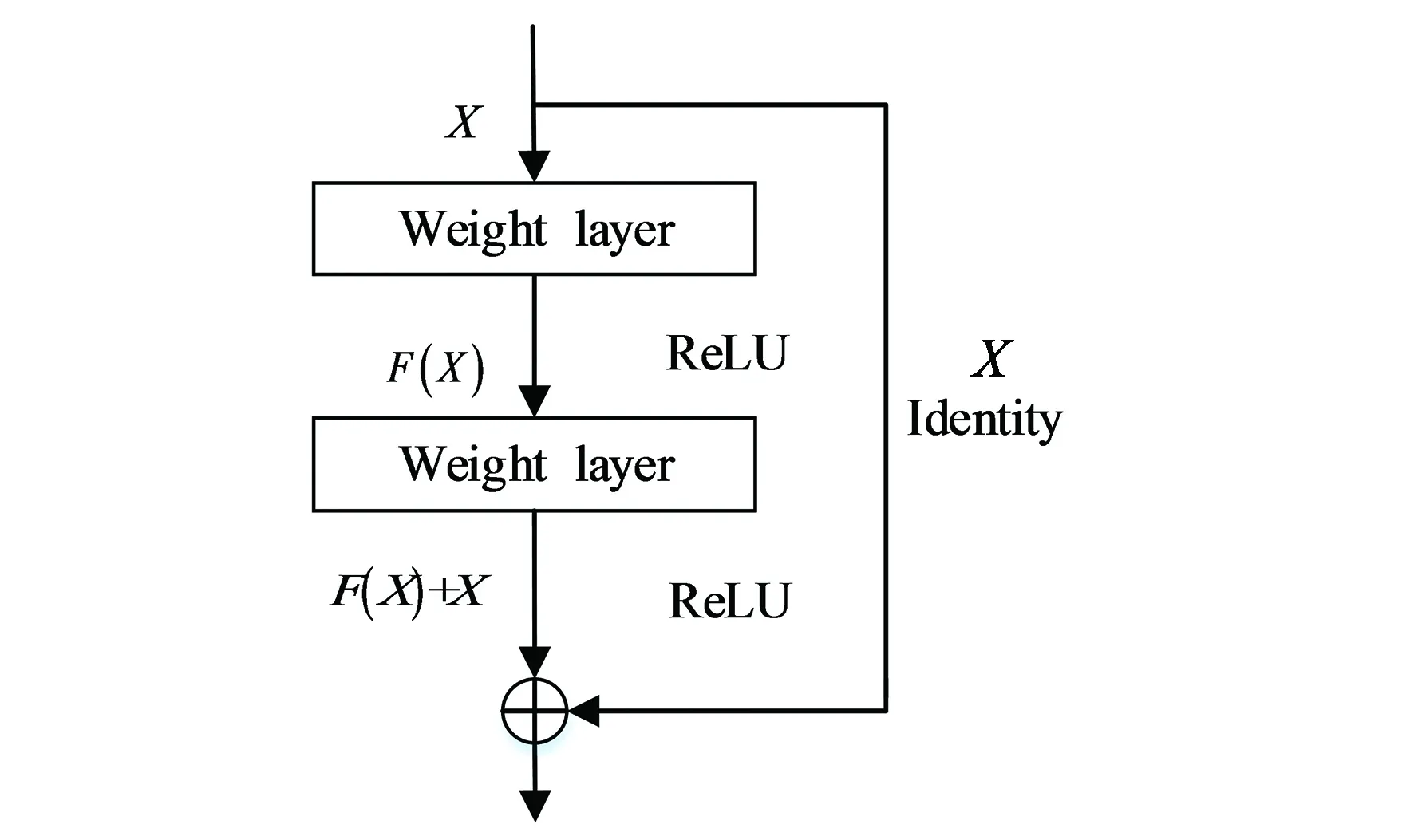
圖3 殘差塊的結構Fig.3 Structure of res-block
本文改進的殘差塊包括:3個卷積層,每個卷積層都是3×3的卷積核。使用兩個ReLU激活函數,這樣可以達到較快的收斂速度,并且在第一個卷積層與第二個卷積層之間添加一個概率為0.5的Dropout層,這樣有助于防止模型過擬合,同時加快模型訓練速度。最后是一個跳躍連接模塊,有助于解決梯度消失問題以及梯度爆炸問題。同時由于BN層已被證明會增加計算復雜性,并且降低性能[8],因此本文的判別器去除了批歸一化(Batch Normalization, BN)層,同時,本研究領域內使用深度學習去模糊的研究,大都使用小批次進行訓練,如Nah[8]等,訓練批次為2;Kupyn[13]等提出的DeblurGAN,訓練批次為1;Zhang[14]等提出的基于真實模糊去模糊,批次為4;使用小批次訓練時不適合使用批歸一化層。結構如圖4所示。
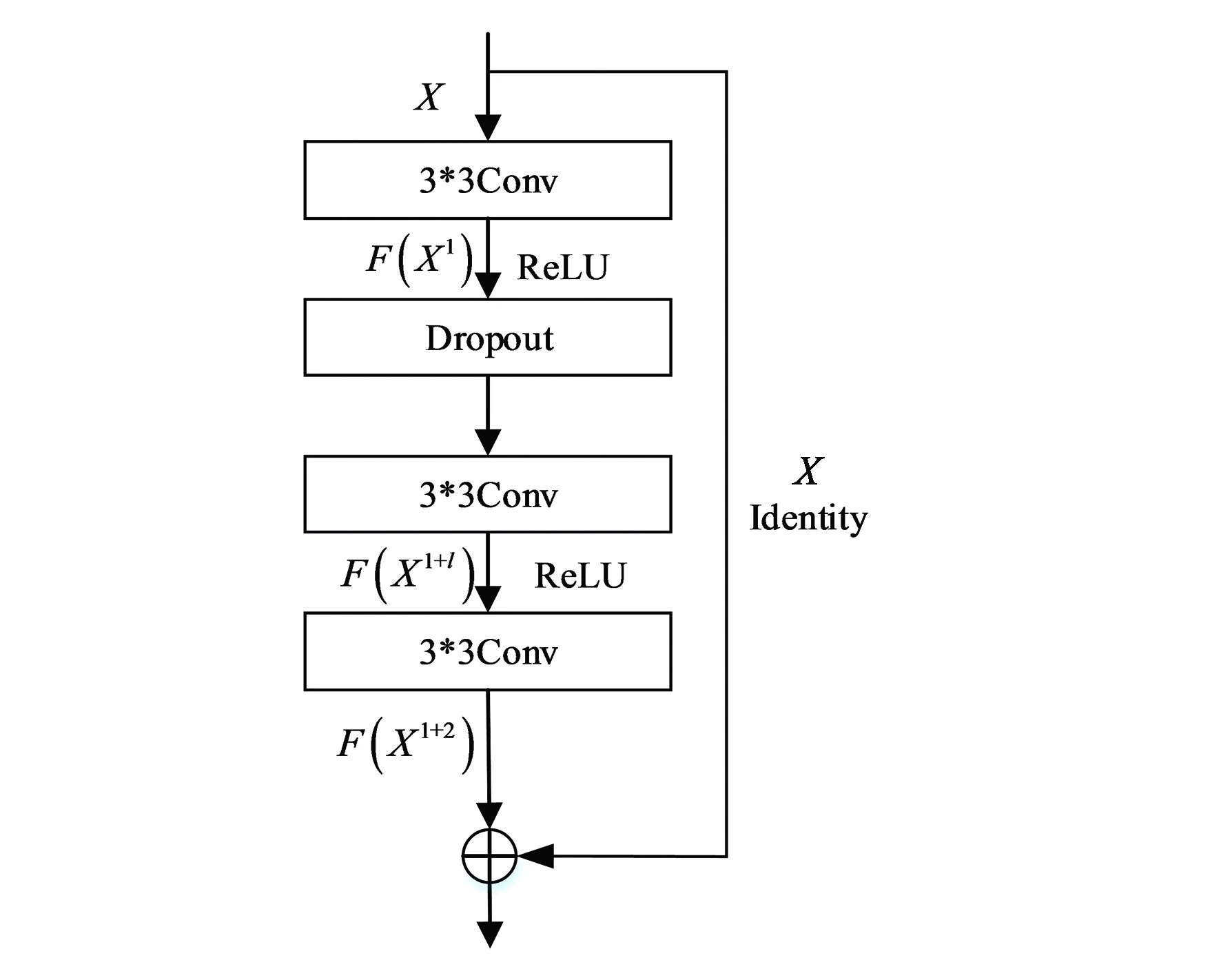
圖4 改進殘差塊的結構Fig.4 Structure of improved Res-block
3.3 損失函數
本文使用WGAN[18]中的Wassertein距離為判別器的損失函數,其定義如下:
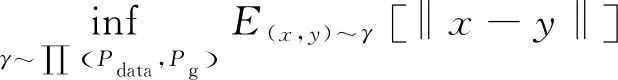
(7)
其中,x和y分別表示真實樣本和生成樣本,∏(Pdata,Pg)是Pdata和Pg的聯合分布的集合,(x,y)~γ表示其中的采樣,inf表示對采樣出的真實樣本和生成樣本的距離期望,即E(x,y)~γ[‖x-y‖]取下限。
同時,本文使用內容損失[12](Content loss)作為生成器的損失函數。內容損失是一種基于生成圖像和目標圖像的CNN特征圖差異的L2損失,不同于普通的L2損失,內容損失通過預訓練的網絡某一層的輸出特征來定義:
(8)
其中:Φi,j代表通過預訓練卷積神經網絡提取的特征圖,本文使用的預訓練模型為VGG16。Wi,j和Hi,j為特征圖的大小。
4 網絡結構
4.1 生成器的網絡結構
受到Johnson[12]等提出的用于風格遷移任務的網絡的啟發,本文生成器網絡結構如圖5所示。其中的編碼器層(Encoder)和解碼器層(Decoder)均包含3層卷積層,每個卷積層后面還包括一個ReLU激活函數層。生成器中所有卷積層的填充方式均為same。最后的激活函數使用tanh激活函數,除此層外,生成器的激活函數均為ReLU激活函數。在這些結構之上,生成器中還包含一個跳躍連接塊,用于解決由網絡深度過深帶來的梯度消失、梯度爆炸等問題。
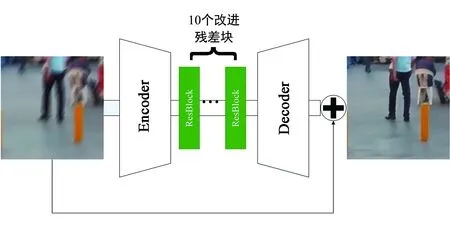
圖5 生成器的網絡結構Fig.5 Network structure of generator
4.2 判別器的網絡結構
PatchGAN是由Phillip Isola等[21]提出的一種馬爾科夫判別器。馬爾科夫判別器可以將圖像有效地建模為馬爾科夫隨機場。PatchGAN判別器試圖對圖像中的每個N×N塊進行分類,以確定其真假,在圖像上卷積運行這個鑒別器,對所有響應進行平均,作為最終的判別器輸出。Patch通過5層卷積層的疊加,將最底層卷積層的感受野擴展為70×70。
受到PatchGAN判別器的啟發,本文對其進行改進,在參數數量只增加2.38%的前提下,將最底層感受野提升至142,而運行時間幾乎沒有增加。在PatchGAN中,最后對網絡輸出的特征圖取均值作為判別器的最后輸出。為了進一步降低算法復雜度,改進的網絡在網絡最后使用全局平均池化層代替均值操作,同樣可以做到求取特征圖均值的效果。PatchGAN結構以及本文改進的PatchGAN結構如表1和表2所示。
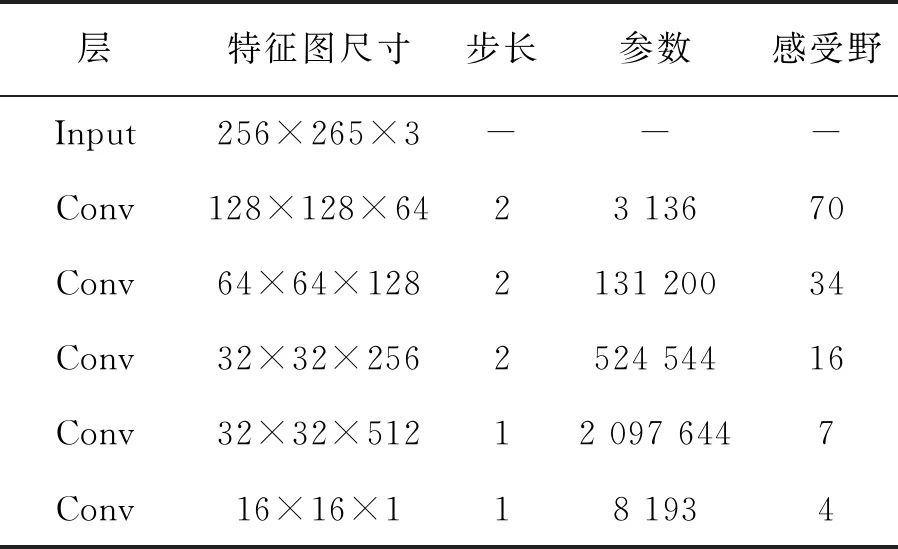
表1 PatchGAN結構圖Tab.1 Structure of PatchGAN
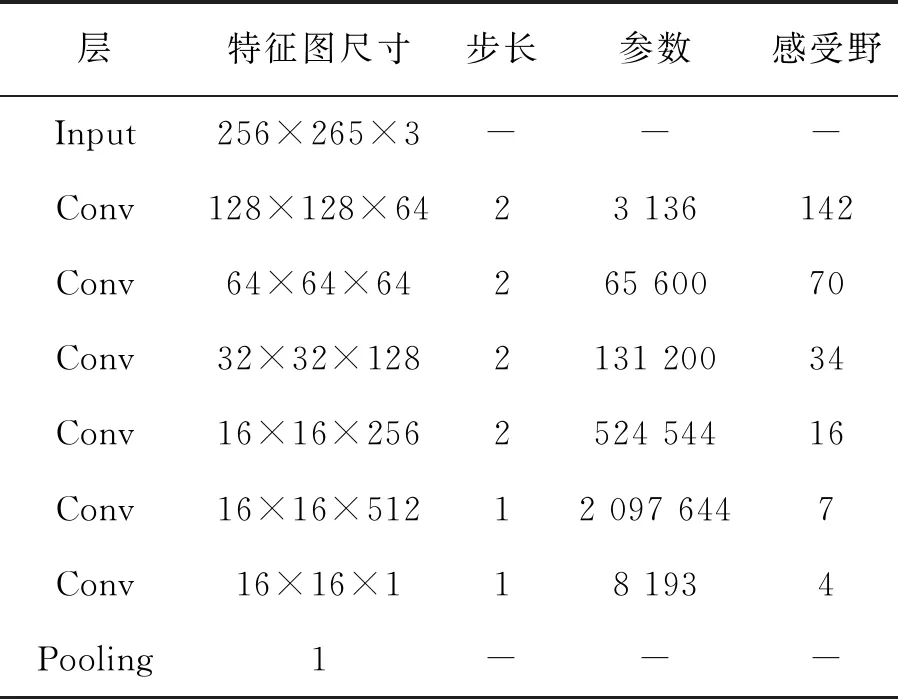
表2 本文提出的改進PatchGAN結構圖
5 實驗結果與分析
本文的仿真實驗在配置有Tesla-P100的服務器上進行,服務器系統為CentOS 7,使用TensorFlow2框架與Adam優化器,初始學習率設置為10-4。經過若干次迭代訓練,最終學習率線性衰減到10-7。
由于本文網絡結構的輸入要求,需要將訓練數據集中的圖片剪裁成256×256大小的圖片。而生成器中全部都是卷積層,不存在全連接層,屬于全卷積(Fully Convolutional Networks, FCN)神經網絡,可以應用于任意大小的圖像。
5.1 數據集信息
本文采用GOPRO數據集和Lai數據集[24]對本文算法的復原效果進行測試。
GOPRO數據集是目前進行圖像去模糊研究的最常用的數據集之一,其使用GOPRO4相機拍攝240幀/s的視頻,然后生成模糊圖片來模擬真實的運動模糊。該數據集由3 214對清晰和模糊的圖像組成,每張圖像的分辨率都是1 280×720。我們采用其中2 103張圖片作為訓練集,其余1 111張圖片作為測試集,并將其剪裁為256×256大小的圖片,作為神經網絡的輸入。
Lai數據集是一系列真實世界的模糊圖像,是在真實場景中由不同的相機、不同的設置與不同的用戶處捕捉的,沒有清晰的對照物,無法進行定量分析。
5.2 圖像質量客觀評價
圖像復原仿真實驗的結果通常選用峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和結構相似性(Structural Similarity, SSIM)兩項指標進行衡量。
表1的實驗結果表明,在GOPRO數據集上,本文提出的基于深度殘差生成對抗網絡的運動去模糊算法具有更好的復原能力,可達到更高的PSNR和較高的SSIM。部分實驗效果如圖6所示,其中左側部分是模糊圖像,中間部分是去模糊效果圖,最右側是清晰圖像。
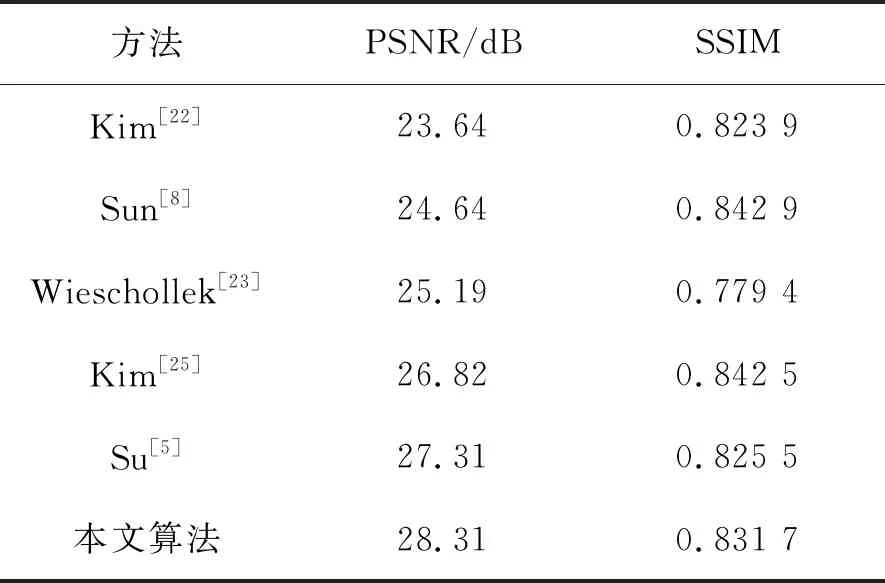
表3 GOPRO數據集上不同算法質量評估結果

圖6 GOPRO數據集復原效果Fig.6 Restoration effects of GOPRO dataset
5.3 Lai數據集主觀評價
圖7是Lai數據集中測試圖像face2去模糊效果比較圖,第一行圖片從左至右依次是模糊圖像,Sun[26]等、Krishnan[27]等、Whyte[28]等的結果;第二行圖像從左至右依次是Nah[8]等、Pan[2]等、Xu[29]等、本文算法的結果。從圖中可以看出,本文提出的算法能夠很好地獲得復原效果,從圖中可以清楚地獲取圖片人物的細節信息。

圖7 Lai 數據集去模糊效果定性比較Fig.7 Qualitative comparison of deblurring effects of Lai datasets
6 結 論
本文對圖像去模糊領域進行了研究,提出了一種基于深度殘差生成對抗網絡的運動去模糊算法,實現了精度更高的運動模糊圖像盲復原。改進了殘差塊的結構,使之能更好的地適應圖像去模糊領域的應用,改進了PatchGAN的結構,在網絡參數只增加2.38%的前提下,將其最底層感受野提升至原先的兩倍以上。實驗結果表明,在GOPRO數據集中,本文提出算法復原的圖像可達到較高的客觀評價指標,峰值信噪比PSNR可達到28.31 dB,結構相似性SSIM可達到0.831 7,可以恢復出較高質量的清晰圖像。在Lai數據集上,復原的圖像可以達到較好的主觀視覺效果。
