基于注意力交叉的點(diǎn)擊率預(yù)測(cè)算法
2021-12-14 01:28:42杜博亞楊衛(wèi)東
計(jì)算機(jī)應(yīng)用與軟件 2021年12期
杜博亞 楊衛(wèi)東
(復(fù)旦大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)系 上海 201203)
0 引 言
點(diǎn)擊率(CTR)預(yù)測(cè)在推薦系統(tǒng)中至關(guān)重要。用戶在電商頁面上點(diǎn)擊推薦的商品,意味著推薦信息與用戶偏好和需求之間存在一定的相關(guān)性。利用這種相關(guān)性數(shù)據(jù)建立點(diǎn)擊率預(yù)測(cè)模型,如果直接使用原始商品特征和用戶行為特征,往往難以奏效。因此,數(shù)據(jù)科學(xué)家通常會(huì)花費(fèi)大量精力研究和實(shí)施面向推薦算法的特征工程,以期得到最佳點(diǎn)擊率預(yù)估模型,其中一種主要手段即為特征組合的方法[1]。組合特征也稱交叉特征,例如:一個(gè)三維組合特征“AND(組織=復(fù)旦,性別=男,研究方向=機(jī)器學(xué)習(xí))”的值為1,即表示用戶所屬組織為復(fù)旦,性別為男且研究方向?yàn)闄C(jī)器學(xué)習(xí)方向。
傳統(tǒng)的特征組合方法主要有三個(gè)缺點(diǎn)。首先,由于高效組合特征往往依賴于具體業(yè)務(wù)場(chǎng)景,數(shù)據(jù)科學(xué)家需要花費(fèi)大量時(shí)間從產(chǎn)品數(shù)據(jù)中探索特征的潛在組成模式,然后才能提取出有意義的交叉特征,因此獲取高質(zhì)量的組合特征需要很高的人力成本;其次,在現(xiàn)實(shí)點(diǎn)擊率預(yù)估場(chǎng)景中,原始特征經(jīng)過編碼后往往可以達(dá)到上億維度,這使得手動(dòng)特征組合變得不可行;最后,人工特征工程難以挖掘出隱藏的交叉特征,限制了推薦系統(tǒng)的個(gè)性化程度。因此,利用模型自動(dòng)提取出高效的組合特征是一項(xiàng)十分有意義的工作。
對(duì)于特征組合方式,其中FM[2]將每個(gè)特征i映射到一個(gè)隱因子向量Vi=[vi1,vi2,…,viD],組合特征通過隱因子兩兩內(nèi)積進(jìn)行交叉:f(2)(i,j)=
上述模型都使用DNN來學(xué)習(xí)高階特征交互。然而,由于DNN模型是以隱式方式提取高階組合特征,目前并未有理論證明其表征特征對(duì)應(yīng)組合階數(shù)。此外,DNN學(xué)習(xí)到的非線性組合特征的含義難以解釋。因此,本文提出一種基于注意力機(jī)制的顯式特征交叉模型,實(shí)現(xiàn)Bit-wise級(jí)別的特征交叉,利用Attention機(jī)制對(duì)組合特征進(jìn)行賦權(quán),消除了暴力組合方式帶來冗余特征的影響。本文方法基于Deep & Cross Network(DCN)[8],但傳統(tǒng)的DCN只能通過交叉網(wǎng)絡(luò)進(jìn)行暴力顯式特征組合,不能區(qū)分各組合特征的重要性,這些特征中不僅包含了有效交叉特征,也同時(shí)涵蓋了大量冗余特征,其限制了最終的點(diǎn)擊率預(yù)估模型表現(xiàn)。
本文設(shè)計(jì)一種全新的Attention Cross Network(ACN)用于各階顯式特征自動(dòng)篩選,ACN實(shí)現(xiàn)了自動(dòng)提取指定階Bit-wise級(jí)顯式特征組合。同時(shí),該網(wǎng)絡(luò)巧妙地運(yùn)用了矩陣映射,使得模型空間復(fù)雜度隨網(wǎng)絡(luò)深度線性增長(zhǎng),大大降低了模型上線的負(fù)擔(dān)。然而,受限于ACN網(wǎng)絡(luò)參數(shù)規(guī)模的限制,保留了DNN用于隱式高階特征組合作為模型補(bǔ)充,整個(gè)模型以并行網(wǎng)絡(luò)結(jié)構(gòu)組織。本文模型不再需要人工特征工程,可自動(dòng)實(shí)現(xiàn)特征組合、抽取,完成端到端模型訓(xùn)練。
1 注意力交叉網(wǎng)絡(luò)結(jié)構(gòu)
DACN整體網(wǎng)絡(luò)一共由五部分組成,分別為輸入層、嵌入層、Attention Cross Network、DNN和輸出層,其整體網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。
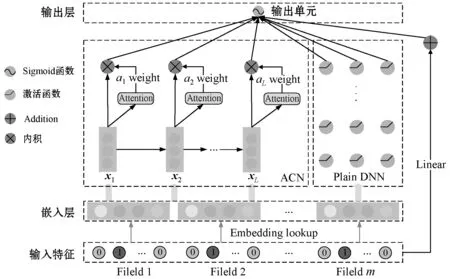
圖1 DACN模型結(jié)構(gòu)
圖1中,稀疏特征經(jīng)過嵌入層映射為Embedding,然后與稠密特征進(jìn)行堆疊,分別傳給ACN、DNN用于顯式特征、隱式特征提取,將提取特征傳送給輸出神經(jīng)元完成點(diǎn)擊率預(yù)估。
1.1 嵌入層和堆疊層
網(wǎng)絡(luò)結(jié)構(gòu)的輸入特征主要包含數(shù)值型特征和類別型特征,而在實(shí)際的CTR預(yù)估場(chǎng)景中,輸入主要是類別型特征,如“國(guó)家=中國(guó)”。這類特征通常需要進(jìn)行One-hot編碼,如“[0,1,0]”,當(dāng)對(duì)ID類特征進(jìn)行One-hot編碼時(shí),往往會(huì)造成嵌入空間的向量維度過大。
為了降低編碼導(dǎo)致的特征稀疏性,使用嵌入層將稀疏類特征轉(zhuǎn)換為向量空間的稠密向量(通常稱為嵌入向量):
xembed,i=Wembed,ixi
(1)
式中:xembed,i是嵌入向量;xi是第i類的二進(jìn)制輸入;Wembed,i∈Rne×nv是將與網(wǎng)絡(luò)中的其他參數(shù)一起進(jìn)行優(yōu)化的嵌入矩陣;ne和nv分別是輸入維度和嵌入向量維度。映射邏輯如圖2所示。
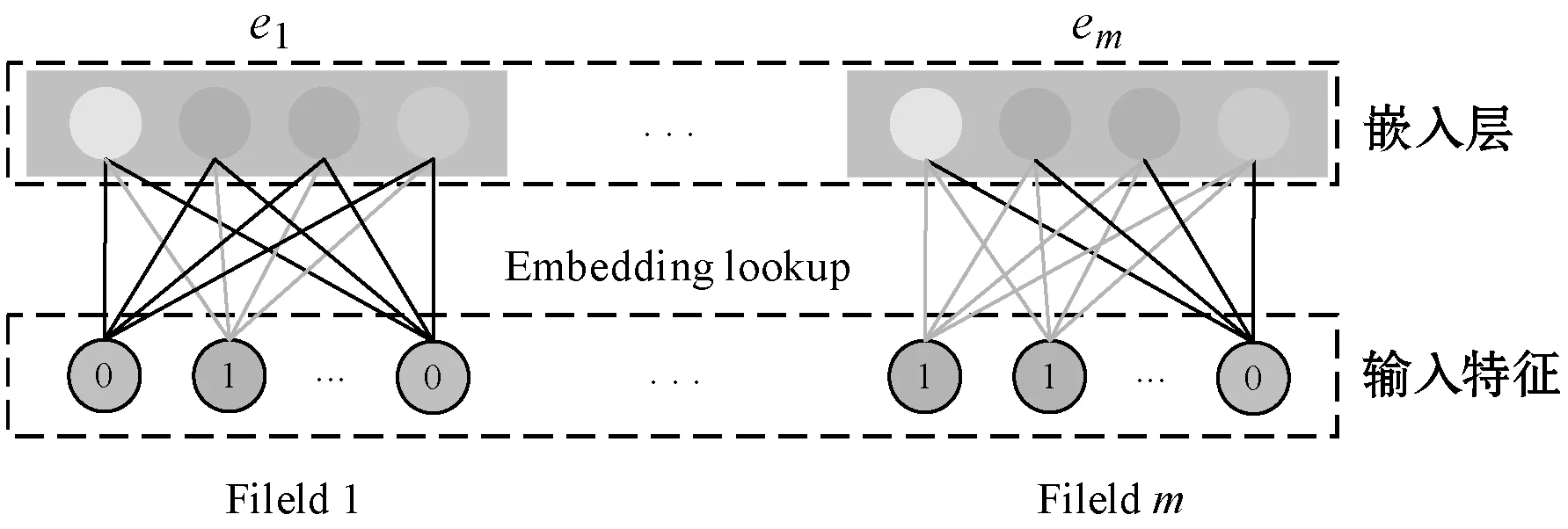
圖2 嵌入層網(wǎng)絡(luò)結(jié)構(gòu)
最后,將嵌入向量以及歸一化的稠密特征xdense堆疊到一個(gè)向量中:
(2)
將堆疊后的向量x0傳入ACN網(wǎng)絡(luò)進(jìn)行顯式特征提取,傳入DNN進(jìn)行隱式特征提取,完成CTR預(yù)估。
1.2 注意力交叉網(wǎng)絡(luò)
本文的注意力交叉網(wǎng)絡(luò)核心思想是利用交叉網(wǎng)絡(luò)完成Bit-wise級(jí)特征高階交叉,利用注意力機(jī)制完成顯式特征提取。其主體架構(gòu)如圖3所示。
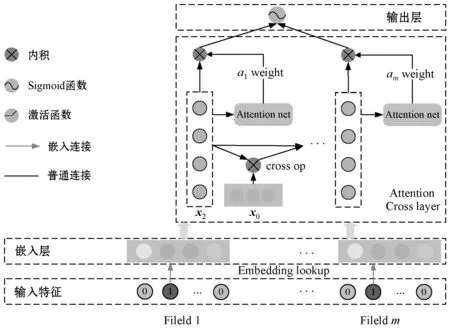
圖3 注意力交叉網(wǎng)絡(luò)結(jié)構(gòu)
注意力交叉網(wǎng)絡(luò)主要包含輸入層、交叉層、注意力層和輸出層。其中,輸入層完成從稀疏特征到稠密特征的嵌入,交叉層完成指定階顯式特征交叉,注意力層完成組合特征賦權(quán)。三者聯(lián)立完成特征自動(dòng)組合、交叉和篩選,最后傳遞給輸出神經(jīng)元進(jìn)行點(diǎn)擊率預(yù)測(cè)。
1.2.1交叉層
交叉層旨在以一種高效的方式進(jìn)行顯式特征組合。其中,每一層的神經(jīng)元數(shù)量都相同且等于輸入向量x0的維度,每一層都符合式(3),其中函數(shù)f擬合的是指定階顯式特征組合。
(3)
式中:Xl,Xl+1∈Rd是列向量,分別表示來自第l層和第l+1層交叉層輸出;Wl,Bl∈Rd是第l層的權(quán)重和偏差。圖4給出了一個(gè)交叉層的計(jì)算操作示例。
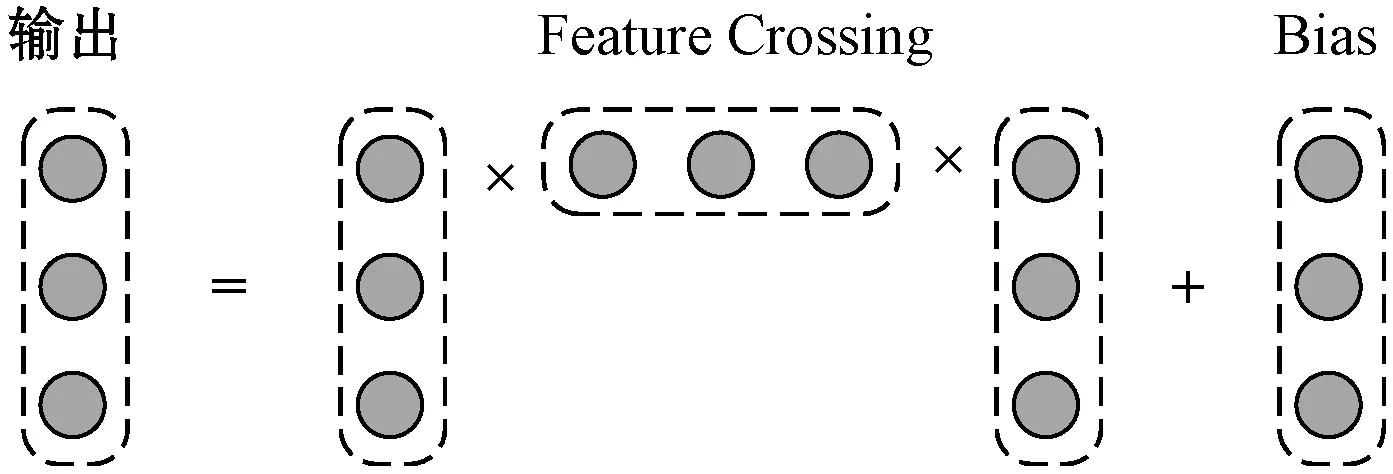
圖4 交叉層網(wǎng)絡(luò)結(jié)構(gòu)
從圖4中矩陣和向量運(yùn)算不難發(fā)現(xiàn),其輸入、輸出結(jié)果始終保持長(zhǎng)度為d,保證了交叉網(wǎng)絡(luò)單層空間復(fù)雜度為O(d)。同時(shí),交叉網(wǎng)絡(luò)的參數(shù)規(guī)模也限制了模型的顯式特征表達(dá)能力。為了捕獲高度非線性的交互特征,需要引入并行的DNN網(wǎng)絡(luò)。
1.2.2注意力層
注意力機(jī)制的核心思想為:當(dāng)把不同的部分壓縮在一起的時(shí)候,讓不同部分的貢獻(xiàn)程度不一樣。ACN通過在交叉層后接一個(gè)單隱層全連接神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)組合特征權(quán)重,從而實(shí)現(xiàn)特征自動(dòng)提取。
對(duì)于注意力權(quán)重,ACN采用一個(gè)Attention network來學(xué)習(xí)組合特征權(quán)重,Attention network采用單隱層的全連接神經(jīng)網(wǎng)絡(luò),激活函數(shù)使用ReLU,網(wǎng)絡(luò)大小用注意力因子表示。注意力網(wǎng)絡(luò)的輸入是完成指定階特征交叉之后的d維向量,輸出是組合特征對(duì)應(yīng)的注意力得分。最后,使用Softmax對(duì)得到的注意力分?jǐn)?shù)進(jìn)行規(guī)范化,其計(jì)算公式邏輯如下:
(4)
(5)
式中:W∈Rt×d,b∈Rt,h∈Rt是模型參數(shù)。注意力分?jǐn)?shù)通過Softmax進(jìn)行標(biāo)準(zhǔn)化,用于加速參數(shù)學(xué)習(xí)。注意力層輸出是d維矢向量,對(duì)應(yīng)各階特征系數(shù)。
因此,ACN網(wǎng)絡(luò)的輸出計(jì)算式如下:
(6)
(7)
式中:ai是注意力權(quán)重,表示不同組合特征對(duì)最終預(yù)測(cè)函數(shù)的貢獻(xiàn)程度。不難看出,對(duì)于交叉網(wǎng)絡(luò)的顯式組合特征,通過注意力機(jī)制實(shí)現(xiàn)組合項(xiàng)的動(dòng)態(tài)加權(quán),更高效地利用了組合特征,并消除了冗余特征對(duì)點(diǎn)擊率預(yù)測(cè)模型的影響。
1.3 多層感知機(jī)
注意力交叉網(wǎng)絡(luò)的參數(shù)規(guī)模限制了模型顯式特征提取能力,為了獲得高階非線性的組合特征,本文并行引入了多層感知機(jī),其網(wǎng)絡(luò)結(jié)構(gòu)如圖5所示。
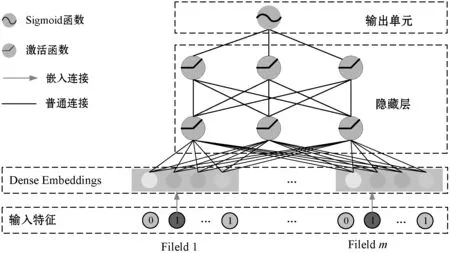
圖5 多層感知機(jī)結(jié)構(gòu)
該網(wǎng)絡(luò)是一個(gè)全連接前饋神經(jīng)網(wǎng)絡(luò),各層計(jì)算邏輯如下:
Hl+1=f(WlHl+Bl)
(8)
式中:Hl+1表示隱藏層;f(·)是ReLU函數(shù),通過全連接方式進(jìn)行網(wǎng)絡(luò)構(gòu)建,用于隱式高階特征提取。
1.4 輸出層
輸出層將注意力交叉網(wǎng)絡(luò)和多層感知機(jī)的輸出傳給標(biāo)準(zhǔn)Logits層,進(jìn)行點(diǎn)擊率預(yù)估,點(diǎn)擊率預(yù)估公式為:
(9)
式中:XL1∈Rd,HL2∈Rm分別是ACN和DNN的輸出;Wlogits∈R(d+m)是輸出層的權(quán)重向量;σ=1/(1+exp(-x))。損失函數(shù)為帶正則項(xiàng)的對(duì)數(shù)損失函數(shù):
(10)
式中:pi為點(diǎn)擊率預(yù)估模型輸出;yi為樣本對(duì)應(yīng)標(biāo)簽;N為訓(xùn)練樣本數(shù);λ為L(zhǎng)2正則項(xiàng)系數(shù)。通過對(duì)數(shù)損失函數(shù)進(jìn)行誤差反傳直至收斂,完成模型訓(xùn)練。
2 注意力交叉網(wǎng)絡(luò)分析
本節(jié)在理論層面對(duì)ACN做有效性分析,論述其進(jìn)行顯式特征交互的理論依據(jù),并對(duì)ACN網(wǎng)絡(luò)的空間復(fù)雜度進(jìn)行分析。
2.1 多項(xiàng)式近似
根據(jù)Weierstrass逼近定理[9],在特定平滑假設(shè)下任意函數(shù)都可以被一個(gè)多項(xiàng)式以任意的精度逼近,因此可以從多項(xiàng)式近似的角度分析交叉網(wǎng)絡(luò)。對(duì)于d元n階多項(xiàng)式,其表達(dá)式如下:
(11)
多項(xiàng)式參數(shù)量為O(dn),而ACN只需要O(d)參數(shù)量就可以生成同階多項(xiàng)式中出現(xiàn)的所有交叉項(xiàng)。
(12)
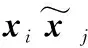
然而,正是受限于ACN的參數(shù)規(guī)模,其模型特征表征能力受限,為了提取高階非線性組合特征,本文并行引入了DNN。
2.2 因子分解機(jī)泛化
ACN本質(zhì)是對(duì)FM模型的進(jìn)一步推廣,從特征顯式二階交互到高階交互。
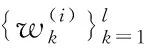
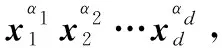
2.3 空間復(fù)雜度
對(duì)于ACN,假設(shè)Lc表示ACN層數(shù),d表示輸入向量x0的維度,Attention網(wǎng)絡(luò)隱層神經(jīng)元數(shù)量為m,則l層的交叉網(wǎng)絡(luò)組成了x1,x2,…,xd在l+1階的所有特征組合,對(duì)應(yīng)ACN的參數(shù)數(shù)目為(d×Lc+d×m)×2。
對(duì)于交叉網(wǎng)絡(luò),每一層的參數(shù)向量W和b都是d維,所以交叉層參數(shù)數(shù)量為d×Lc×2,而注意力網(wǎng)絡(luò)為單隱層全連接神經(jīng)網(wǎng)絡(luò),輸入輸出均是長(zhǎng)度為d的向量,對(duì)應(yīng)參數(shù)數(shù)量為d×m×2。
ACN網(wǎng)絡(luò)空間復(fù)雜度是輸入維度d的線性函數(shù),所以相比于DNN,ACN引入的復(fù)雜度微不足道,這樣就保證了整體網(wǎng)絡(luò)DACN的復(fù)雜度和DNN同屬一個(gè)數(shù)量級(jí)。
3 實(shí) 驗(yàn)
3.1 實(shí)驗(yàn)設(shè)置
3.1.1實(shí)驗(yàn)數(shù)據(jù)集
在以下兩個(gè)數(shù)據(jù)集上評(píng)估DACN的有效性和效率。
(1) Criteo數(shù)據(jù)集[10]。Criteo數(shù)據(jù)集包含4 500萬用戶的點(diǎn)擊記錄,共13個(gè)連續(xù)特征和26個(gè)分類特征。為方便訓(xùn)練,從中隨機(jī)抽取2 000萬條數(shù)據(jù)集分為兩部分,其中90%用于訓(xùn)練,其余10%用于測(cè)試。
(2) MovieLens數(shù)據(jù)集[11]。MovieLens數(shù)據(jù)包含13萬用戶對(duì)2萬多部電影的評(píng)分記錄,共21個(gè)特征,約2 000萬條評(píng)分?jǐn)?shù)據(jù)。為了使其適用于CTR預(yù)測(cè)場(chǎng)景,本文將其轉(zhuǎn)換為二分類數(shù)據(jù)集,電影的原始用戶評(píng)分是從0到5的離散值,本文將標(biāo)有4和5的樣本標(biāo)記為正,其余標(biāo)記為負(fù)樣本。
根據(jù)用戶ID從中隨機(jī)選取13萬用戶,將數(shù)據(jù)劃分為訓(xùn)練和測(cè)試數(shù)據(jù)集,隨機(jī)抽取10萬用戶作為訓(xùn)練集(約1 447萬個(gè)樣本),其余3萬用戶作為測(cè)試集(約502萬個(gè)樣本),則任務(wù)是根據(jù)用戶歷史行為來預(yù)測(cè)該用戶是否會(huì)對(duì)指定電影評(píng)分高于3(正標(biāo)簽)。
3.1.2評(píng)估指標(biāo)
使用AUC(ROC曲線下的面積)和Logloss(交叉熵)兩個(gè)指標(biāo)進(jìn)行模型評(píng)估,這兩個(gè)指標(biāo)從不同層面評(píng)估了模型的表現(xiàn)。
(1) AUC。AUC衡量模型對(duì)正負(fù)樣本的排序能力,表示隨機(jī)從樣本中抽取一對(duì)正負(fù)樣本,其中正樣本比負(fù)樣本排名要高的概率。此外,AUC對(duì)樣本類別是否均衡并不敏感。(2) Logloss。Logloss衡量各樣本預(yù)測(cè)值與真實(shí)值之差。廣告系統(tǒng)往往更依賴Logloss,因?yàn)樾枰褂妙A(yù)測(cè)的概率來估算排序策略的收益(通常將其調(diào)整為CTR×出價(jià))。
3.1.3對(duì)比模型
實(shí)驗(yàn)將DACN與LR(Logistic Regression)[12]、DNN、FM(Factorization Machines)[2]、Wide & Deep[1]、DCN(Deep & Cross Network)[8]和DeepFM[7]進(jìn)行對(duì)比。
如前文所述,這些模型與DACN高度相關(guān),是目前主流且經(jīng)過工業(yè)界驗(yàn)證的點(diǎn)擊率預(yù)估模型。因DACN旨在通過模型提取特征組合,為控制變量,本文將不對(duì)原始特征進(jìn)行任何人工特征工程。
3.1.4參數(shù)設(shè)置
1) DACN模型參數(shù)設(shè)置。本文在TensorFlow上實(shí)現(xiàn)DACN。對(duì)稠密型特征使用對(duì)數(shù)變換進(jìn)行數(shù)據(jù)標(biāo)準(zhǔn)化;對(duì)類別型特征,將特征嵌入到長(zhǎng)度為6×dimension1/4的稠密向量中;使用Adam[13]優(yōu)化器,采用Mini-batch隨機(jī)梯度下降,其中Batch大小設(shè)置為512,DNN網(wǎng)絡(luò)設(shè)置Batch normalization[14]。
2) 對(duì)比模型參數(shù)設(shè)置。對(duì)于對(duì)比模型,遵循PNN[6]中針對(duì)FNN和PNN的參數(shù)設(shè)置。其中,DNN模塊設(shè)置了Dropout為0.5,網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置為400- 400- 400,優(yōu)化算法采用基于Adam的Mini-batch梯度下降,激活函數(shù)統(tǒng)一使用ReLU,F(xiàn)M的嵌入維度設(shè)置為10,模型其余部分設(shè)置與DACN一致。
3.2 實(shí)驗(yàn)對(duì)比
3.2.1單模型表現(xiàn)對(duì)比
各單模型在兩公開數(shù)據(jù)集表現(xiàn)如表1所示。對(duì)比模型中,F(xiàn)M顯式度量2階特征交互,DNN建模隱式高階特征交互,Cross Network建模顯式高階特征交互,而ACN建模顯式高階特征交互并自帶特征篩選。
實(shí)驗(yàn)表明,本文所提的ACN始終優(yōu)于其他對(duì)比模型。一方面,對(duì)于實(shí)際的數(shù)據(jù)集,稀疏特征上的高階交互是必要的,這一點(diǎn)從DNN、Cross Network和ACN在上述兩個(gè)數(shù)據(jù)集上均明顯優(yōu)于FM得到證明;另一方面,ACN是最佳的個(gè)體模型,驗(yàn)證了ACN在建模顯式高階特征交互方面的有效性。
3.2.2集成模型表現(xiàn)對(duì)比
DACN將ACN和DNN集成到端到端網(wǎng)絡(luò)結(jié)構(gòu)中。其中ACN用于顯式組合特征提取及篩選,DNN用于隱式組合特征提取,通過兩者并行聯(lián)立,以期最大程度地進(jìn)行特征表征。比較了DACN與目前主流CTR預(yù)估模型在兩公開數(shù)據(jù)集上的表現(xiàn),結(jié)果如表2所示。
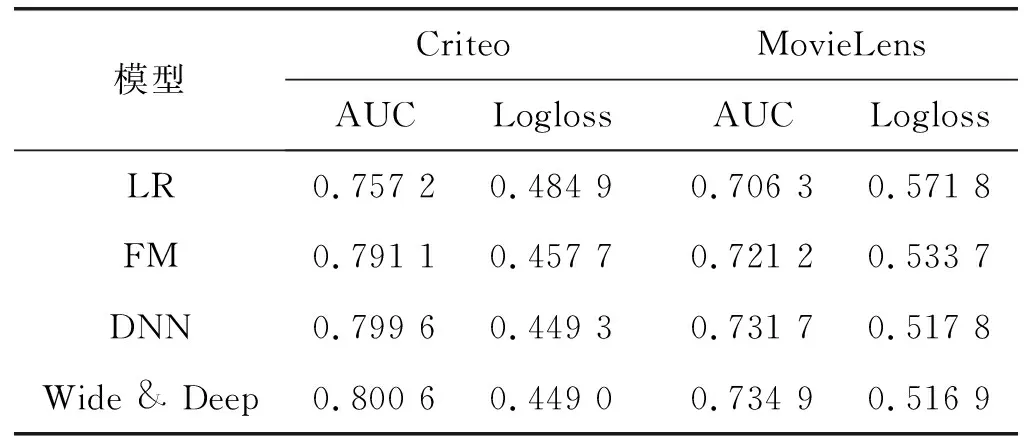
表2 集成網(wǎng)絡(luò)結(jié)果對(duì)比
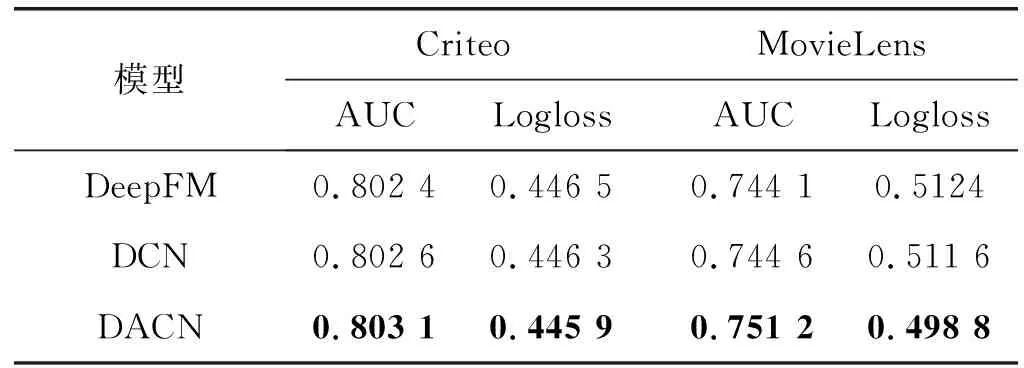
續(xù)表2
可以看出,LR比所有其他模型都差,這表明基于因子分解的模型對(duì)于建模稀疏類交互特征至關(guān)重要;而Wide&Deep、DCN和DeepFM則明顯優(yōu)于DNN,表明DNN隱式特征提取能力比較受限,通常需要借助人工特征工程彌補(bǔ)特征組合能力不足的短板。其次,DACN相比于DCN指標(biāo)提升明顯。前文已從理論角度論證了DACN相較DCN的優(yōu)勢(shì),通過添加Attention網(wǎng)絡(luò)結(jié)構(gòu)實(shí)現(xiàn)各指定階組合特征篩選,提升重要組合特征權(quán)重,消除冗余特征影響。實(shí)驗(yàn)結(jié)果證明,該結(jié)構(gòu)可有效地實(shí)現(xiàn)特征篩選,對(duì)整體模型表現(xiàn)具有較大提升。
最后,本文所提的DACN網(wǎng)絡(luò)在兩個(gè)公開數(shù)據(jù)集上均實(shí)現(xiàn)了最佳性能,這表明將顯式和隱式高階特征聯(lián)立,對(duì)原始特征表征更充分。同時(shí),實(shí)驗(yàn)結(jié)果也驗(yàn)證了使用ACN進(jìn)行指定階顯式特征組合對(duì)最終模型表現(xiàn)具有很大提升,從側(cè)面驗(yàn)證了該結(jié)構(gòu)的合理性。
3.2.3網(wǎng)絡(luò)參數(shù)數(shù)量對(duì)比
考慮到ACN引入的額外參數(shù),在Criteo數(shù)據(jù)集上對(duì)ACN、CrossNet及DNN進(jìn)行了對(duì)比,比較各模型實(shí)現(xiàn)最佳對(duì)數(shù)損失閾值所需的最少參數(shù)數(shù)量,因?yàn)楦髂P颓度刖仃噮?shù)數(shù)量相等,在參數(shù)數(shù)量計(jì)算中省略了嵌入層中的參數(shù)數(shù)量,實(shí)驗(yàn)結(jié)果如表3所示。

表3 相同對(duì)數(shù)損失對(duì)應(yīng)最少參數(shù)量
從實(shí)驗(yàn)結(jié)果不難看出,ACN和Cross Network的存儲(chǔ)效率比DNN高出近一個(gè)數(shù)量級(jí),主要原因是共有的特征交叉結(jié)構(gòu)實(shí)現(xiàn)以線性空間復(fù)雜度完成指定階特征交互。
此外,ACN與Cross Network參數(shù)量都屬同一數(shù)量級(jí),ACN引入的Attention網(wǎng)絡(luò)只包含一個(gè)隱層,所需參數(shù)數(shù)量可近似忽略,但對(duì)模型點(diǎn)擊率預(yù)測(cè)精度具有較大提升。
4 結(jié) 語
識(shí)別有效的特征組合已成為目前主流點(diǎn)擊率預(yù)測(cè)模型成功的關(guān)鍵,現(xiàn)有方法往往借助暴力枚舉或隱式DNN提取進(jìn)行特征組合,其中摻雜了大量無用、冗余特征,限制了點(diǎn)擊率預(yù)測(cè)模型的表現(xiàn)。本文提出的注意力交叉網(wǎng)絡(luò)DACN可以同時(shí)進(jìn)行顯示特征交叉和隱式特征提取,其Attention結(jié)構(gòu)自動(dòng)依據(jù)特征重要性完成特征篩選,有效地降低了冗余特征帶來的影響。實(shí)驗(yàn)結(jié)果表明,就模型準(zhǔn)確性和參數(shù)使用量而言,DACN都優(yōu)于目前主流點(diǎn)擊率預(yù)測(cè)模型。
未來將進(jìn)一步探索注意力交叉網(wǎng)絡(luò)作為顯式特征交叉模塊在其他領(lǐng)域的使用效果。此外,當(dāng)前DACN的顯式特征組合粒度較粗,如何在保證模型空間復(fù)雜度隨網(wǎng)絡(luò)層數(shù)線性增長(zhǎng)的前提下進(jìn)一步挖掘細(xì)粒度組合特征將作為研究工作的下一個(gè)目標(biāo)。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
