基于隨機森林的基坑監(jiān)測數據填補對比研究
2021-12-11 08:20:54程亮
城市地質 2021年4期
程 亮
(北京市地質勘察技術院,北京 100143)
基坑監(jiān)測作為保證基坑工程安全、深入研究基坑結構動態(tài)的重要方法,貫穿于整個基坑工程全壽命周期。基坑監(jiān)測工作過程中收集了大量數據,但受多方面因素影響,基坑監(jiān)測數據集經常會發(fā)生不同程度數據缺失的情況(張軍艦等,2020)。開展數據缺失的識別及填補方法的研究,對于完善監(jiān)測數據集具有顯著意義。
缺失數據填充方法較多,可基于回歸分析法、聚類分析法及神經網絡算法等多種方式進行填補。雷峰津等(2020)基于電網電能質量監(jiān)測分析系統提出了一種基于相關分析的缺失數據填充方法,通過分析找到與采樣周期一致的強相關性指標,然后使用分段回歸的方法建立回歸模型。林楓等(2020)基于布谷鳥算法,研究提出了優(yōu)化的K_means 聚類填充算法。王磊等(2020)采用基于圖像數據結構可視化的相關技術,應用小波變換與快速行進算法進行電成像數據空白帶填充和響應畸變修復,也取得了良好效果。分段回歸的方法準確度較高,但是運行效率相對較低。布谷鳥算法優(yōu)化的K_means聚類算法是對傳統聚類算法的優(yōu)化改進,一定程度上解決了聚類算法無法度量缺失數據間的相似性問題。小波變換與快速行進算法主要應用于電成像測井數據處理,取得了不錯的效果。
針對基坑監(jiān)測數據的差異化特點和缺失值產生原因,應結合工程實際情況進行針對性的分析,進而從數據自身出發(fā),選擇最為恰當的填充方法,并對采用的數據填充方法給出適用性的解釋(施虹等,2020)。隨機森林方法作為一種集成學習方法,有學者將其利用在結構損傷識別方面,可高準確率識別多種脫空工況(謝坤明,2020),在我國陜北黃土高原典型黃土地貌區(qū)域的地貌分類中也取得了較好的結果(曹澤濤等,2020)。本文主要研究應用隨機森林模型進行數據填充的方法,探討了方法的適用性,并與其他填充方法進行對比分析,以期達到合理、高效地填充基坑監(jiān)測缺失值的目的。
1 工程概況
某基坑工程基坑面積約54000 m2。其中包含8棟主樓及其裙樓,地下車庫、人防車庫及配套用房。擬建建筑物±0.000 m的絕對標高為18.6/18.5 m(主樓/地下車庫);現自然地面標高為17.50~18.00 m,地形較為平坦。槽底絕對標高為8.04~15.44 m,基坑開挖深度為2.56~9.96 m。
基坑側壁安全等級為二級和三級,基坑支護方案采用樁錨支護和掛網放坡支護型式。
已進行的主要監(jiān)測項目:1)支護結構頂部水平位移、沉降;2)基坑周邊地表豎向位移;3)地下水位觀測;4)錨桿軸力監(jiān)測;5)周邊建筑物沉降監(jiān)測;6)安全巡視。
監(jiān)測頻率:基坑開挖深度≤5 m,1次/2 d;基坑開挖深度5~10 m,1次/d。底板澆筑后時間,≤7 d,1次/2 d;7~14 d,1次/3 d;14~28 d,1次/5 d;>28 d,1次/10 d。
監(jiān)測點分布見圖1。
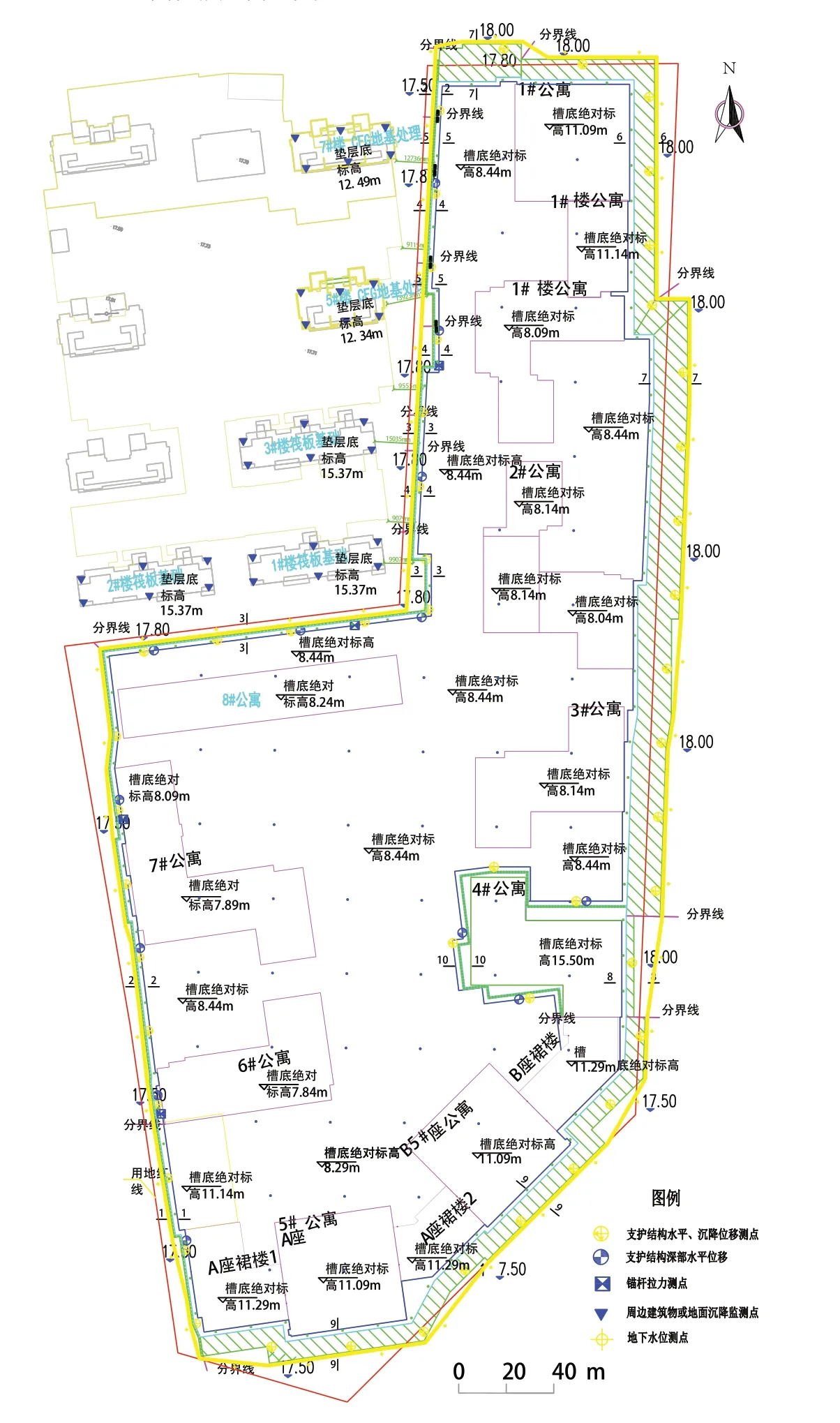
圖1 監(jiān)測點平面布置圖Fig. 1 Location of monitoring points
2 基坑監(jiān)測數據
2.1 原始監(jiān)測數據的基本情況
對于已經取得的原始數據,應該從服務項目分析的角度出發(fā),從數據的使用目的、數據的可用性、數據充足程度(是否滿足分析的需要)以及數據的可靠度、數據質量的好壞做出整體的判斷和評估。
就本項目而言,數據主要用于評估基坑的變形動態(tài),基坑監(jiān)測與工程施工的進度一致,數據整體的連續(xù)性、可靠性都能夠得到保障,數據的精度嚴格按照既定的監(jiān)測方案及相關規(guī)范要求執(zhí)行,能夠滿足評估基坑安全及進行項目分析的需要。
2.2 原始監(jiān)測數據產生缺失值的原因
(1)產生缺失值的原因
缺失值是指在原始數據集中,因為各種原因產生的數據空缺或丟失。數據缺失在原始監(jiān)測數據集里較為常見,是在采集監(jiān)測類成果或進行相關監(jiān)測任務時經常遇到的問題。
監(jiān)測數據缺失值的發(fā)生有很多原因,對于基坑工程,比較常見的有:1)基坑監(jiān)測工作是隨著作業(yè)面觀測條件的完備而逐漸展開的,尤其是項目初期,存在部分點位無法監(jiān)測或者暫時不具備監(jiān)測條件的情況;2)實施監(jiān)測任務時場地條件受限。施工現場是動態(tài)變化的,個別點位在觀測時出現影響正常監(jiān)測的觀測障礙較為普遍;3)儀器動態(tài)監(jiān)測或人工監(jiān)測時出現的偶發(fā)采樣數據缺失。
(2)監(jiān)測數據的基礎特征
監(jiān)測數據的基礎特征是指監(jiān)測數據的一般性分類特性,數據是屬于數值型變量還是離散變量,應根據數據的特點進行初步劃分。
(3)與異常值的區(qū)別
異常值一般是指偏離正常值較多,且利用現有的理論或者觀測狀況不能給出合理解釋的一類數值或某些數據。統計意義上認為良好的數據集應該是符合正態(tài)分布規(guī)律的,偏離過大的數據就存在異常的可能。
異常值是客觀存在于所取得的數據集中的實際量,與缺失值有本質區(qū)別。本文主要討論監(jiān)測數據缺失值的填補,暫不對異常值的辨識和處理進行探討。
2.3 監(jiān)測數據缺失值處理的一般流程
原始監(jiān)測數據缺失值處理所面臨的首要問題是缺失值的識別和分類。
主要包括識別不同字段的缺失值分布狀態(tài),比如缺失值的占比、缺失值出現位置等基本情況,然后根據初判結果分別進行處理。
如果缺失值較多,單一分類內缺失值占比較高,且對整體的數據分布不產生顯著的影響,考慮直接刪除。但此類情況需要謹慎使用,有條件的需要做多模型對比試驗分析,以確定缺失值直接刪除的合理區(qū)間(陳志江等,2021)。
如果缺失值較少,單一分類內缺失值占比較低,對整體數據的影響不能忽略,則需要進行填補,可以考慮采用均值、插值等多種方式進行操作。
3 隨機森林算法填充數據缺失值
3.1 算法概述
隨機森林也被稱作隨機決策森林,它是用于分類、回歸和其他類似任務的集成學習方法。它經常被用作“黑盒子”模型,因為它們可以在廣泛的數據范圍內生成合理的預測,而只需要很少的配置(馬源等,2017)。
該算法是通過在模型訓練時構造多個決策樹,并輸出分類結果,即單個樹的分類或均值預測(回歸模式下)。它的基本單元是決策樹,而它的本質屬于機器學習的集成學習分支。隨機決策可以糾正普通決策樹過度擬合的訓練集合,且性能通常優(yōu)于普通決策樹(石禮娟等,2017)。
3.2 算法流程
以分類問題為例,首先根據分析數據集,使用自助法進行采樣,生成n個訓練集。n個訓練集可以訓練n個決策樹,故決策樹不必進行修剪,可以保留全部數據集特征進行訓練。
每個訓練集具有獨立分類器(即單獨的分類樹),利用其進行分類。每個獨立分類器根據不同的分類指標進行分類決策,決策的形式是分類器內部進行投票。最終的結果匯總成為隨機森林的輸入結果,要依據各分類器投票情況來確定,獲得票數最多的類別就是森林的分類結果。由于每個分類器都是獨立的,99.9%不相關的分類器做出的預測結果涵蓋所有的情況,且互斥的分類結果會彼此抵消。將若干個弱分類器的分類結果進行投票選擇,從而組成一個強分類器,少數優(yōu)秀的分類器的預測結果將會做出一個好的預測。
對于數據預測,一般是根據分類過程中構造的回歸樹進行決策的同時,采用待填充數據集的均值或者中位值作為預設值,使用全部數據構建模型,構建過程中記錄每組數據在決策樹中每一分支的分類路徑,搜索出與缺失值最為接近的路徑。路徑的長短表征了已知數據與待預測數據之間的相似程度,再根據相似度和權重大小進行填補。
3.3 待填充數據基本情況
以基坑(H7—H58)號點樁頂豎向位移變化量為例,選取的監(jiān)測周期為2019年6月11日—2020年2月18日。
從H7—H58號點缺失值基本情況統計表(表1)和分布圖(圖 2)上看,H30—H32點缺失值的分布不集中,但占比高(27%~43.2%),這些樣本在數據分析時會被直接忽略,本次填充不涉及。其他數據列存在的缺失值均小于2.7%。缺失值占比略高,不影響整體數據分布,均可以進行填充處理。H50—H58號點數據完整,無缺失。
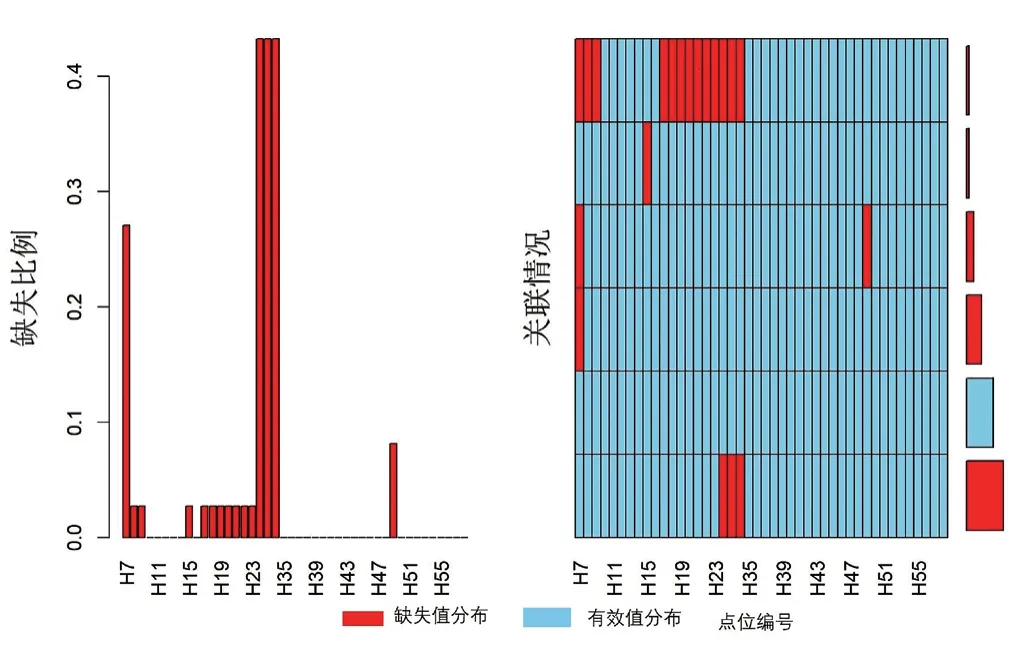
圖2 H7-H58號點樁頂豎向位移缺失值可視化Fig.2 Missing value of vertical displacement visualization at h7-h58
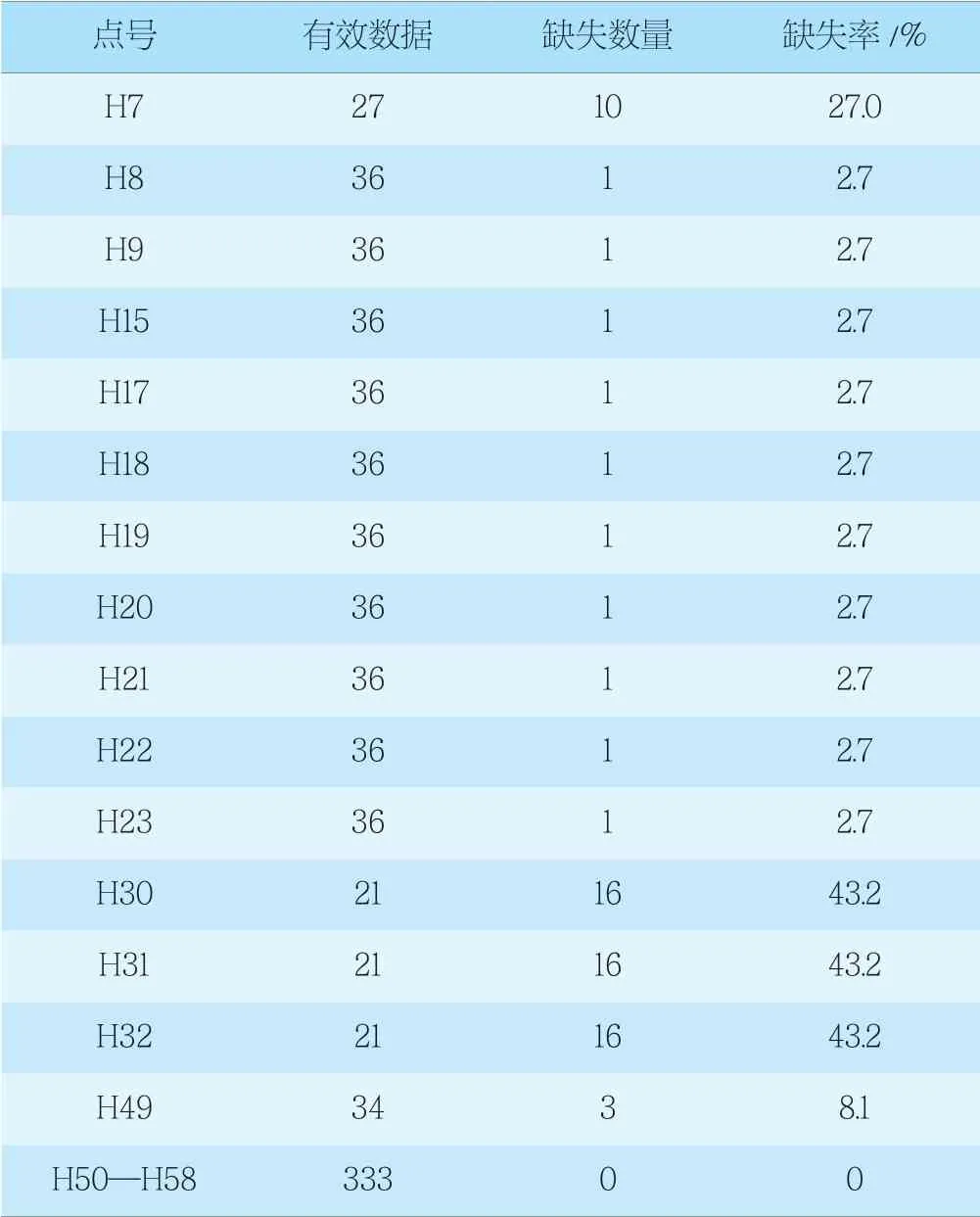
表1 H7—H58號點樁頂豎向位移數據缺失情況統計表Tab. 1 Missing data of vertical top displacement of pile for H7-H58
從H7、H8、H9、H49點樁頂豎向位移監(jiān)測數據(圖3)可見,H7、H8、H9、H49點曲線上都存在間斷。
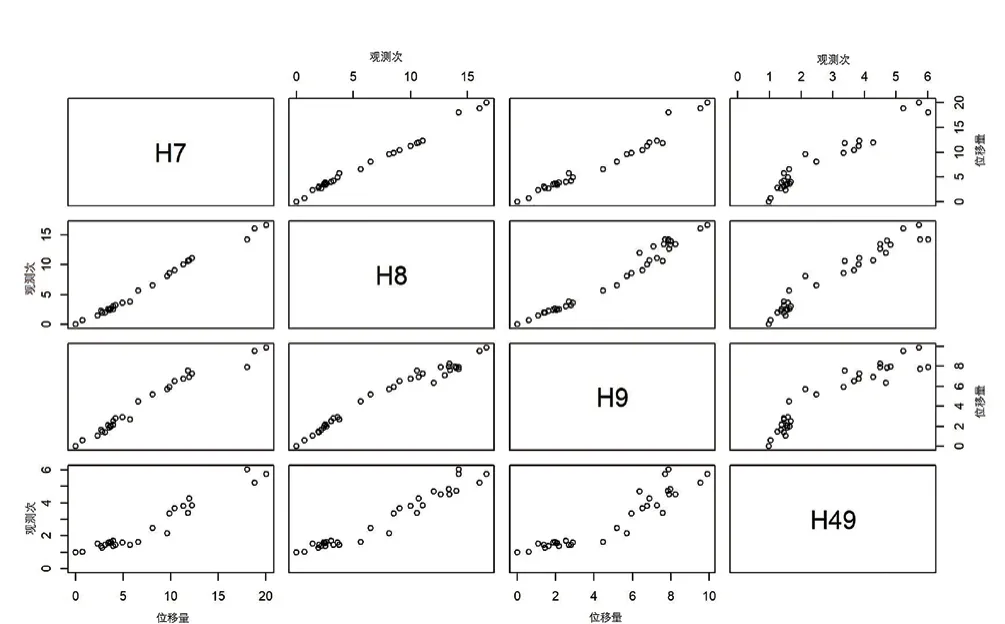
圖3 H7、H8、H9、H49點樁頂豎向位移原始數據散點圖Fig. 3 Basic vertical displacement data of H7, H8, H9 and H49
H7間斷(空缺)最為明顯,產生原因就是缺失值的存在(表2)
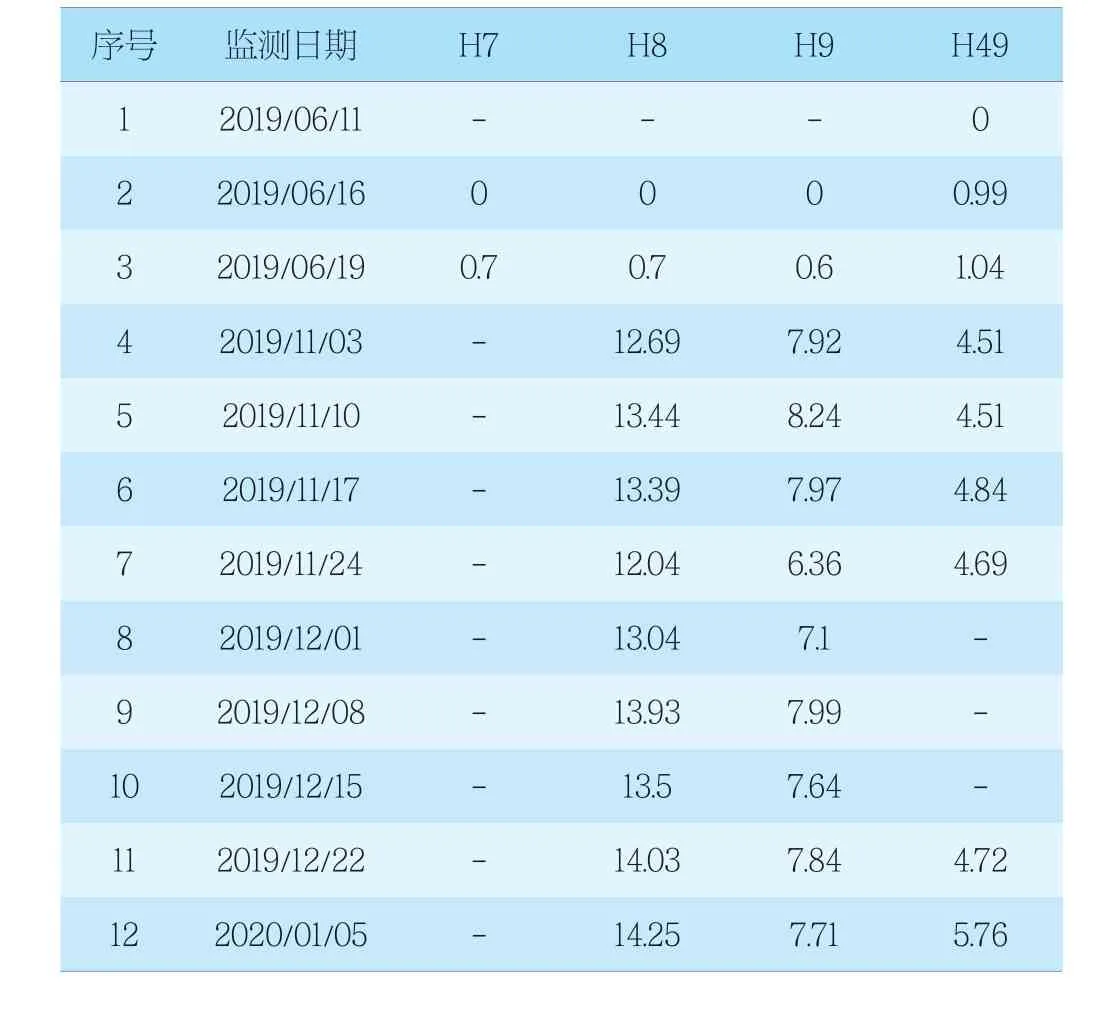
表2 H7、H8、H9、H49點存在缺失值的行統計表Tab. 2 Lines with missing values at H7, H8, H9 and H49
H7、H8、H9、H49點的數據統計分析結果見表3。
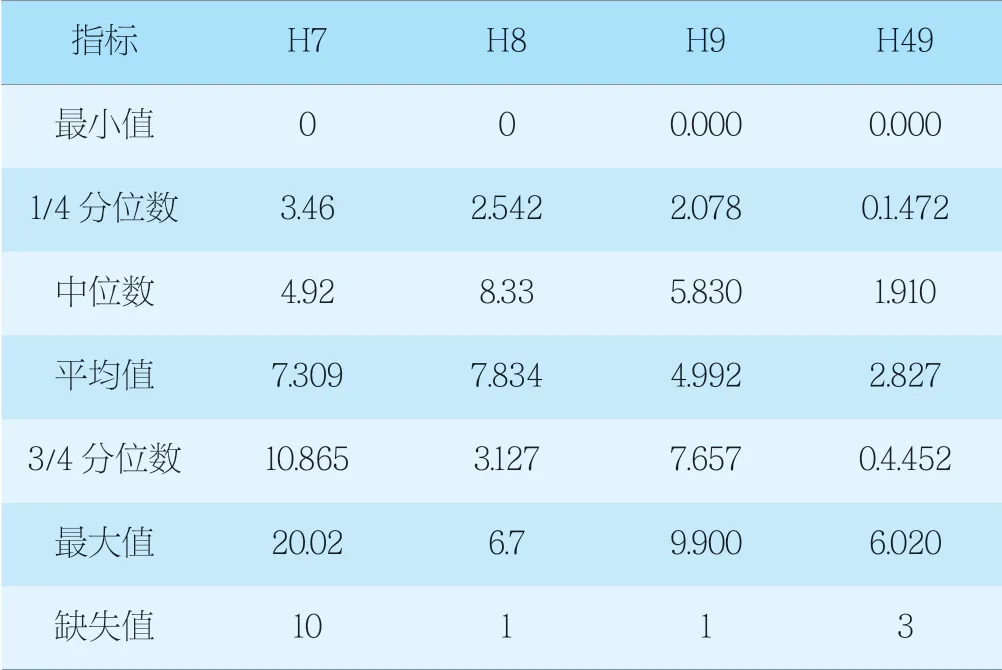
表3 H7、 H8、H9、H49號點樁頂豎向位移數據統計表Tab. 3 Statistics of vertical displacement of pile for H7, H8, H9, H49
3.4 填充結果
R語言的MICE包提供了多種缺失值填充的方法,并對填充模式及方法做了封裝,便于實際工程調用。其可選模塊中可添加RandomForest包,利用隨機森林算法解決分類和回歸問題(米霖,2020),直接利用前處理后數據對該模型進行缺失值填補。
根據填充結果(圖 4)可見,邊界處的數據填除H8號點外基本符合基坑變形的實際狀態(tài),且對邊界處的填補效果較好。數據列內的填補結果除個別點位突出后,與周邊數據相關性較強。在填充后的曲線圖形上,還可以看到填補后數據分類性質明顯,具有明顯的歸類特征,符合決策樹算法的歸類決策特點。
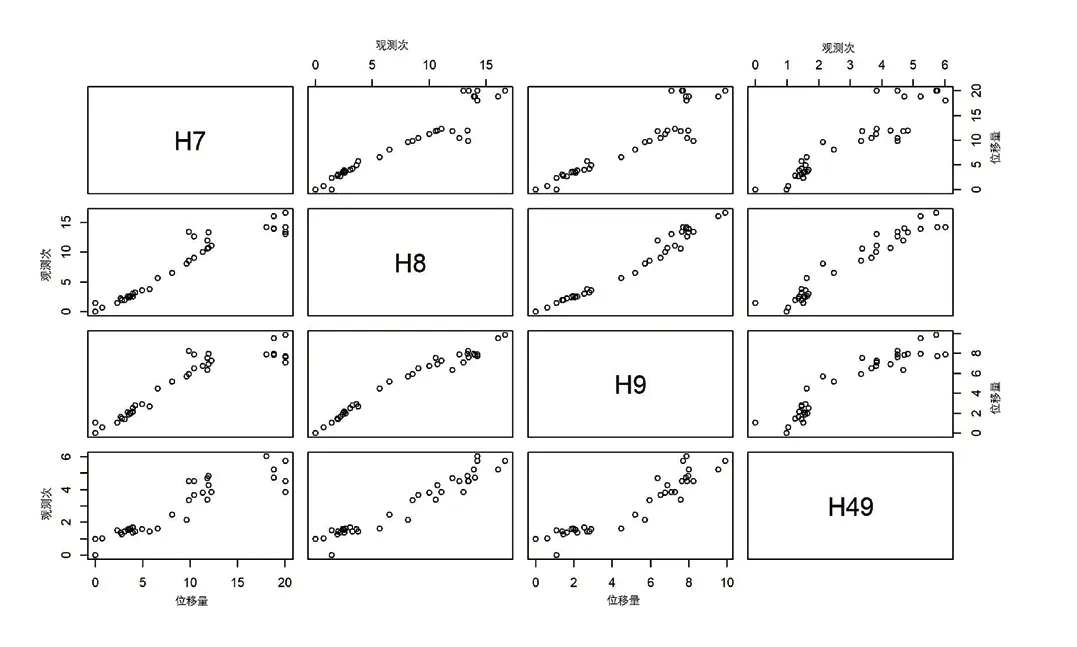
圖4 H7、H8、H9、H49點樁頂豎向位移缺失值隨機森林填充Fig. 4 Filling vertical displacement for missing values by random forest at H7, H8, H9 and H49
4 與其他填充方法的對比
缺失值數據集通常也可以采用均值、插值、回歸等多種方式進行填充(王愛國等,2016)。
4.1 均值、中位數填充
以H7、H8、H9、H49點為例,樁頂豎向位移監(jiān)測數據填充結果見圖5。
均值填充是以控制所在列的空值以外數據的平均值進行填充,以平均值填充后結果見圖5a。可以看到,對缺失值用平均值進行了填充,但對于H7、H8、H9號點2019年6月11日監(jiān)測數據的填充,初始值為0的情況下,0值之前點位填充平均值不符合實際。在中部連續(xù)出現的缺失,直接利用平均值填充,未考慮數據變化趨勢,其點位偏離較為明顯,也不盡合理。
同理,采用中位數填充(圖5b)結果與采用平均值填充情況類似。
4.2 KNN填充
KNN法(K- Nearest Neighbor法,即K最鄰近法)是以待求測點周圍若干已知測點值c1,c2, ...,ci為基準,來估計某其他時刻目標點測量值cx的填充方法,本質上也是一種考慮權重的插值填充方法。
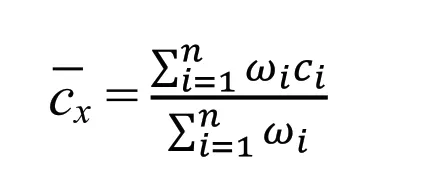
其中,權重ω與距離d(鄰點與目標點)成反比,即ω=1/d,n為已知測點的個數。
從填充結果(圖5c)看,待填充值在兩側的數據取值區(qū)間以內,與均值法相比,填充后曲線較為平滑,沒有出現明顯的數據偏離,與基坑變形動態(tài)情況基本相符。
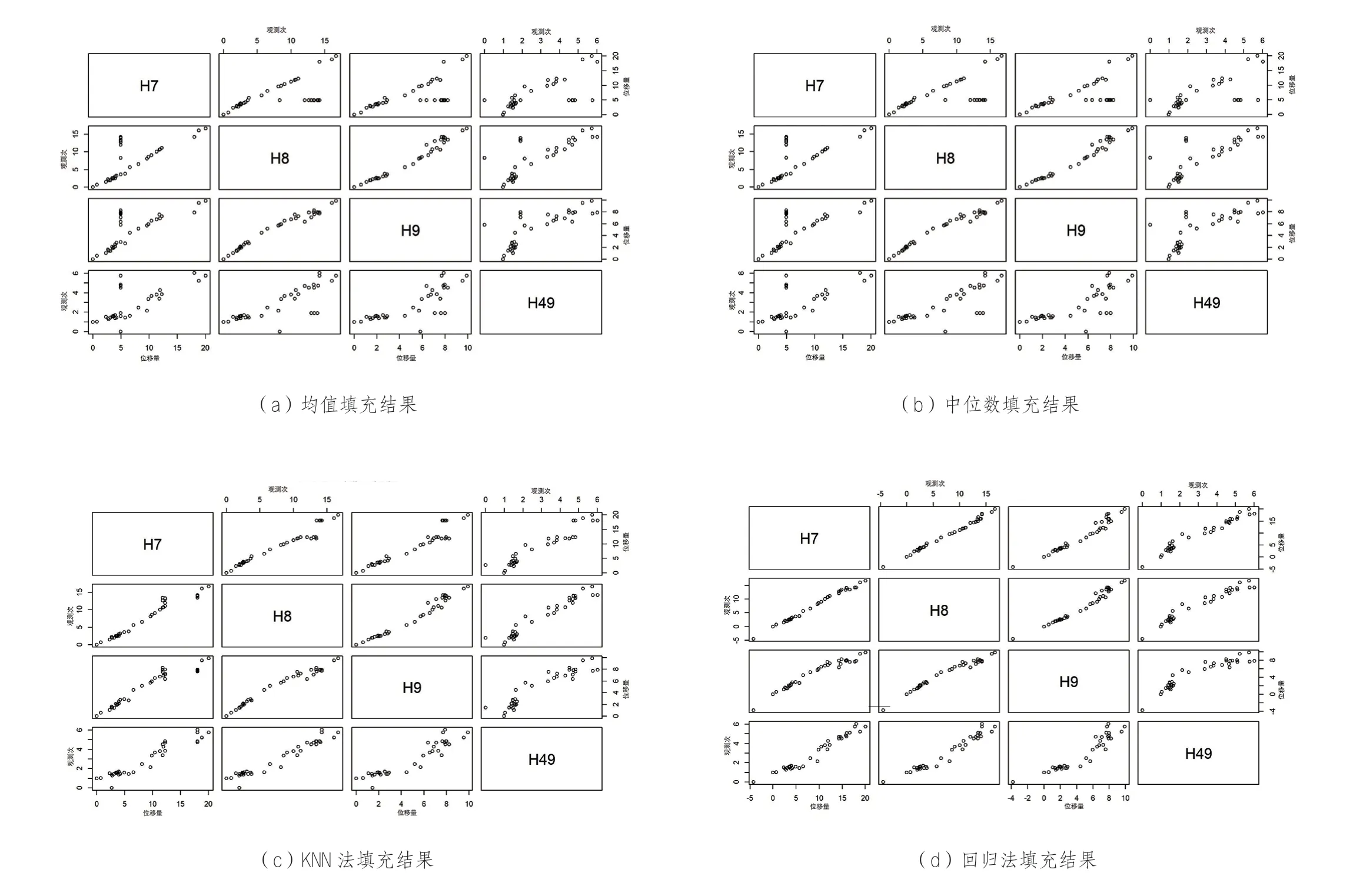
圖5 H7、H8、H9、H49點樁頂豎向位移監(jiān)測數據填充結果Fig.5 vertical displacement 7 filled curves of H7, H8, H9 and H49
4.3 回歸分析結果填充
回歸分析假定目標(待預測值作為因變量)和預測依據(已知觀測數據作為自變量)之間存在一定的因果關系,利用該假設進行結果預測。一般適用于待預測值和已知觀測數據存在顯著關系的情況。回歸分析也能夠顯示出待預測值和已知觀測數據之間的關聯強度。
利用本次選取的數據集,缺失值列作為因變量,選取了多列不包含缺失值的列作為已知觀測數據,進行回歸分析,選取H11—H44號點中的完整數據集作為模型輸入,相關性分析結果見表4。
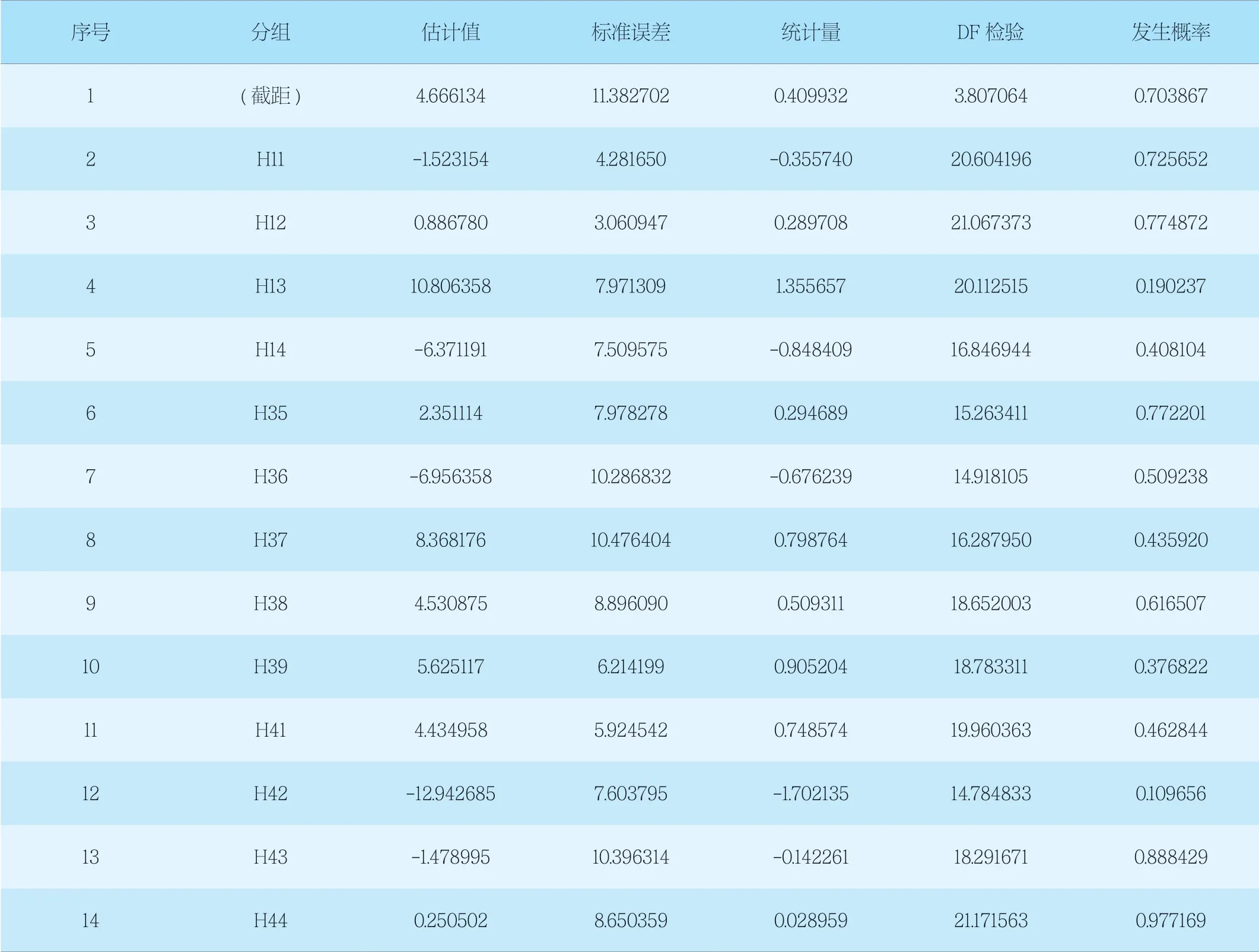
表4 H11—H44號點樁頂豎向位移數據相關性分析表Tab. 4 Correlation analysis of vertical displacement data of pile
通過分析結果可見,假定值出現的概率均大于0.05,說明采用回歸分析的已知數據集與待填補值之間的關聯程度低,不能支持數據間具有因果關系的假設,不適用于已知數據集與待填補值之間回歸模型的建立。
驗證該結果進行缺失值填補(圖5d)可見,邊界處填充值為負值,小于初始值,與實際變形情況不符。中間缺失數據填充主要依據缺失值出現區(qū)間兩側的數值,不能夠很好反映整體的變形規(guī)律,在曲線上顯示局部偏離嚴重,后期分析使用時可能會造成局部誤差過大。填補結果都不理想,回歸分析填充方式不適用于本數據集。
5 結論
(1)基于隨機森林算法的填充方式能夠判斷各分類的重要程度,優(yōu)選出強影響因素,結合權重進行填充,填充結果較為理想。
(2)隨機森林沒有對數據集各特征參數進行降維或壓縮,可以適應大數據集、多特征的要求,最終采用投票的結果,可以最大限度地體現關鍵特征對模型的影響。
(3)隨機森林作為一種集成算法,不用單獨構造測試集,可以依托數據集自動提取測試集,極大地簡化工作量,且能夠內部進行對比、評估。
(4)為了達到合理的填充結果,在填充操作前需要進行必要的填充方式判斷,確定填充范圍后,還需要了解數據的基本統計特征。
監(jiān)測數據的處理作為基坑變形位移規(guī)律分析的重要前置環(huán)節(jié),不容忽視。應該根據基坑工程的實際變形特征或趨勢,根據分析處理階段的不同,合理優(yōu)選適宜的數據處理方式,才能夠更好地利用現場實測數據,讓數據更為全面、完整地提供給模型分析,更有助于實現科學、有效的分析判斷。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:24
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
中國中醫(yī)藥現代遠程教育(2014年11期)2014-08-08 13:23:44
