基于改進Prophet模型的用電量預測研究
2021-12-10 09:06:34吳文培宋亞林魏上斐
計算機仿真 2021年11期
吳文培,宋亞林,魏上斐
(河南大學智能網絡系統研究所,河南 開封 475000)
1 引言
用電量預測是智能用電研究的重要問題之一,為國家電力資源的合理分配、地方供電平衡、線路電量損耗計算提供了重要參考信息,對智能用電管理工作具有積極的指導意義。
用電量預測是典型的時間序列預測問題,分析時間序列目的是預測未來發展趨勢。關于如何發掘用電量數據之間的規律,建立準確可靠的數學模型,一直是中外學者們研究的問題[1]。傳統的預測方法如移動平均法,是對時間數列進行修勻處理[2],加大移動平均法的期數(即加大n值)會使平滑波動效果更好,但會使預測值對數據實際變動更不敏感[3];移動平均時距項數N為奇數時,只需一次移動平均,移動平均值作為移動平均項數中間一期的趨勢代表值;而當移動平均項數N為偶數時,移動平均值對應的是偶數項的中間位置,無法對正某一時期,需要再進行一次相臨兩項平均值的移動平均,才能使平均值對正某一時期[4]。隨著人工智能的發展,各類機器學習算法與深度學習算法[5]涌現出來。如長短時記憶網絡[6](Long Short Term Memory Network,LSTM),能夠成功解決原始循環神經網絡(RNN)難以記住時間間隔較長的數據特征缺陷。RNN的梯度問題在LSTM及其變種里面得到了一定程度的解決[7],可以處理100個量級的序列,但對于1000個量級[8]及更長的序列依然顯得棘手。隨機森林[9]能夠提供有效的方法來平衡數據集誤差,但在解決回歸問題時,并不能給出一個連續的輸出[10]。當進行回歸時,隨機森林不能夠做出超越訓練集數據范圍的預測[11],這會導致在某些特定噪聲的數據進行建模時出現過度擬合[12]。對于小數據或低維數據[13](特征較少的數據),并不能產生很好的分類(回歸)效果。Prophet模型具有簡單、易解釋[14]的周期性結構,能很好地兼容并解釋節假日等時間節點,但Prophet模型易在特殊時間點陷入過擬合[15],這將導致部分預測行為的誤差偏大。對此,本文提出了利用XGBoost模型優化Prophet模型的策略,使融合模型兼具兩個子模型的優勢,減小預測誤差。實驗證明,改進后的預測模型X-Prophet,與原模型相比,預測誤差更小。
2 Prophet模型
2017年2月,Facebook開源了一款基于 Python 和 R 語言的數據預測工具——“Prophet”[16]。該算法是基于時間序列分解和機器學習的擬合而設計的,不僅可以處理時間序列存在一些異常值的情況,也可以處理部分缺失值的情形,還能夠幾乎全自動地預測時間序列未來的走勢。其中在擬合模型時使用了 pyStan 這個開源工具,因此能夠在較快的時間內得到需要預測的結果。
Prophet是一種加法模型,由趨勢項、周期項、節假日項、誤差項四項組成
p(t)=g(t)+s(t)+h(t)+εt
(1)
g(t)表示趨勢項,表示時間序列在非周期上面的變化趨勢;s(t)表示周期項,也可以稱為季節項,默認情況下,以周或年為單位;h(t)表示節假日項,表示當天是否存在節假日;表示誤差項。
趨勢項g(t)是Prophet中的一個重要項,g(t)有兩個重要函數,一個是基于分段線性函數,另一個是基于邏輯回歸函數。
基于分段邏輯回歸增長模型如
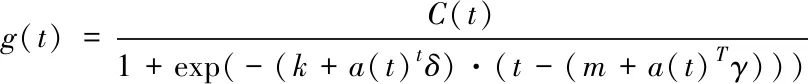
(2)
其中
a(t)=(a1(t),…,as(t))T
δ=(δ1,…,δs)T
γ=(γ1,…,γs)T
(3)
C(t)表示模型容量,k表示增長率,δ表示增長率的變化量。隨著t的增加,g(t)趨于C(t)。使用Prophet的growth=’logistic’的時候,需要提前設置好C(t)的取值。
基于分段線性函數的模型形如
g(t)=(k+a(t)δ)·t+(m+a(t)Tγ)
(4)
k表示增長率,δ表示增長率的變化量,m表示offset parameter。
周期(季節)s(t)中的周期性函數可以通過正玄或余玄函數來表示。用傅立葉級數來模擬時間序列的周期性,如
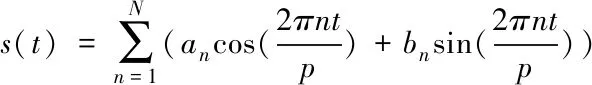
(5)
對于以年為周期的序列(P=365.25),N=10;對于以周為周期的序列,N=3。參數可以形成向量
β=(a1,b1,…,aN,bN)T
(6)
當N=10時
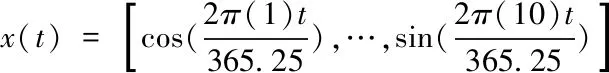
(7)
當N=3時
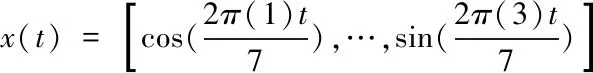
(8)
因此,時間序列的季節項是:s(t)=x(t)β,β的初始化是β~Normal(0,σ^2)。σ=seasonality_prior_scale,σ值越大,表示季節的效果越明顯。
節假日項h(t)模型形如
Z(t)=(1{t∈Di},…,1{t∈DL}),k=(k1,…,kL)T
(9)
k的初始化是k~Normal(0,v^2),v=holidays_prior_scale,默認值是10,當值越大時,表示節假日對模型的影響越大。
3 X-Prophet改進模型
3.1 X-Prophet模型原理
X-Prophet改進模型是在原模型Prophet的基礎上,增加了一個置信值優化模塊。該模塊的作用是結合Prophet和XGBoost兩個子模型,利用XGBoost模型優化Prophet模型,減小模型預測誤差。X-Prophet模型如圖1所示。
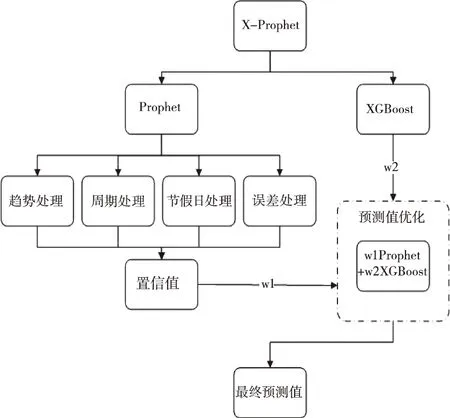
圖1 X-Prophet模型圖
結合Prophet模型實現原理和流程分析,原數據經過趨勢項、季節項、節假日項、誤差項處理后(參照式(1)),給出一系列預測值的置信區間,置信區間有上限yhat_upper和下限yhat_lower。每個時間節點上下限之間的所有值都有可能成為該時間節點的預測值。Prophet以每個時間節點預測值yhat作為最終預測結果。而節假日等特殊時間節點是時間序列預測問題中的一個重要特征,顯示加入對節假日等特殊時間節點的處理,對最終的預測結果有明顯的影響。對Prophet模型而言,其中h(t)項是對節假日的專門處理項,為了將節假日效應發揮至最大,模型默認將節假日影響力參數置為最大值,以此提升整個模型的預測性能。但是最大節假日影響力參數易使Prophet模型在節假日等時間節點的預測行為陷入過擬合,影響模型的穩定性,使預測誤差偏大。
XGBoost模型是一種強分類器模型[17],能夠快速準確地挖掘數據中的節假日等特殊時間點的特征,而且該模型具有正則化項,在對時間序列數據進行分析預測的過程中,能夠避免預測行為陷入過擬合[18]。因此,這里提出改進模型X-Prophet。X-Prophet模型中增加預測值優化模塊,如圖1所示。目的是通過優化模塊引入XGBoost項,利用XGBoost具有正則項的特性來優化Prophet,使這兩個模型優勢互補,得到X-Prophet改進模型,最終達到減小預測誤差,提高預測準確率的目的。對于引入XGBoost優化項后的X-Prophet模型,模型構建可用如下公式表示
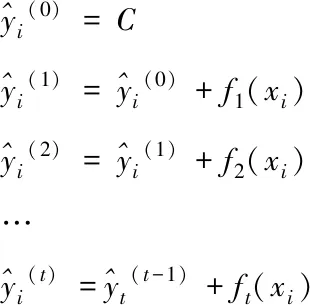
(10)
ft(x)=wq(x)
(11)
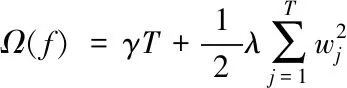
(12)
(13)
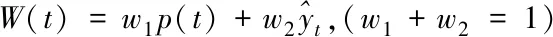
(14)
式(10)表示X-Prophet模型分析數據得到相應時間點的最優解;式(12)表示模型的懲罰項 ,懲罰項用來控制模型的復雜度;式(13)表示模型的損失函數,在每一輪迭代過程中,損失函數obj使得預測值和損失值的誤差和達到最小,即完成了最優模型的構建。式(14)表示模型的最終預測值。
3.2 X-Prophet模型構建
3.2.1 數據集
本文的實驗數據集采用的是數據平臺Kaggle提供的美國加州地區2008~2017年10年的小時用電數據。
3.2.2 模型構建
對原數據進行建模分析,為防止數據因為時間亂序對實驗結果產生影響,預先對數據按時間進行排序。X-Prophet模型進行預測時需要兩列數據分別是‘ds’和‘y’,其中‘ds’表示時間戳,‘y’表示時間序列的值,因此,在處理數據時,需要修改數據的列名。原數據也是兩列數據,包括時間列和用電量列(k-Wh)。X-Prophet對缺失數據具有很好的處理方式,首先去除數據中的異常點(outlier),直接賦值為none,X-Prophet可以通過插值處理缺失值,所以這里不需要額外對原數據的缺失值進行處理。通過以上對原數據的處理,得到處理后的數據,如表1所示。
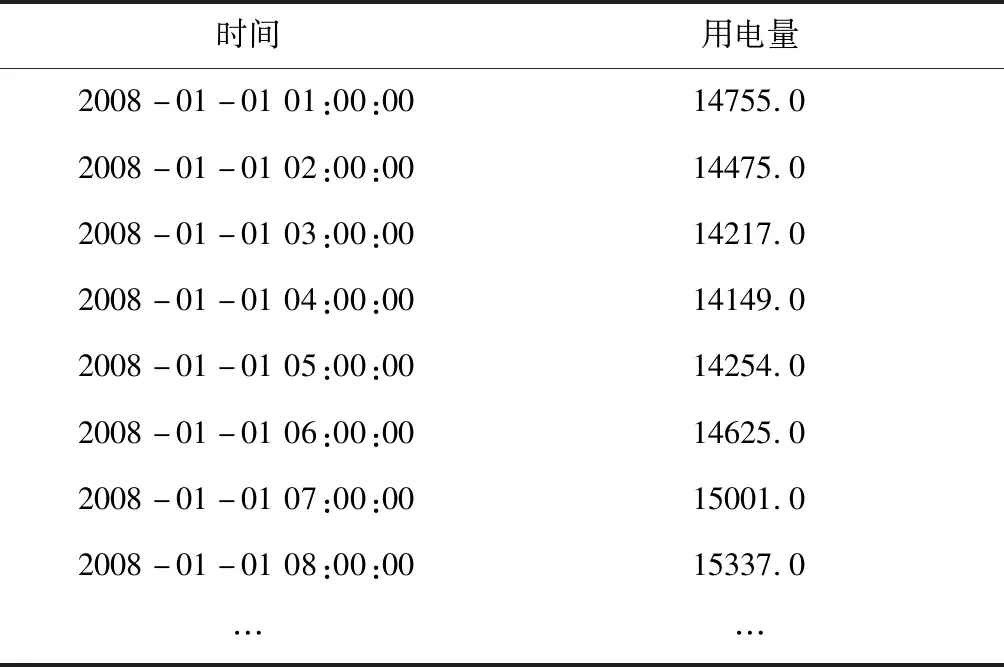
表1 預處理后的數據
周期性(季節性)是X-Prophet模型中的一個重要組成部分,采用標準傅里葉級數,年、周的周期性(seasonality)近似值分別為20和6,周期性成分(seasonal component)在正常情況下是平滑狀態。如果時間序列超過兩個周期,X-Prophet將默認適合每周和每年的季節性。對于日(sub-daily)時間序列,也將適合每日的季節性。節假日處理是X-Prophet模型中一個重要模塊,為了充分發揮X-Prophet的性能,本文加入節假日信息。因為采用的美國加州的用電數據,所以需要加入一些美國主要的節假日信息,如超級碗(橄欖球比賽),以及一些美國的傳統日期,如元旦、感恩節、圣誕節。節假日信息表如表2 所示。
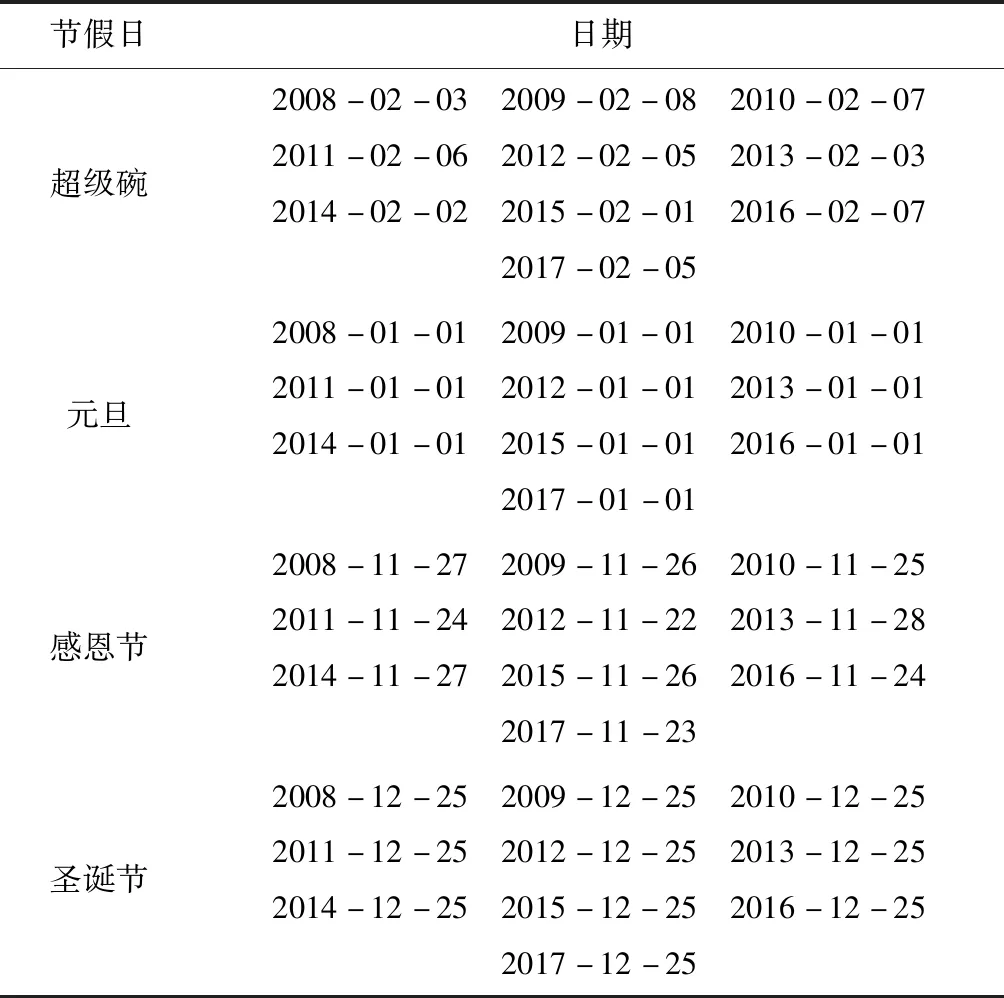
表2 節假日信息表
將處理好的以“小時”為時間粒度的數據,按訓練集70%、測試集30%的比例進行劃分,以便更好地評估X-Prophet模型預測的準確率。改進模型X-Prophet提供了一系列參數協助模型調優,表3是模型參數初始化列表。
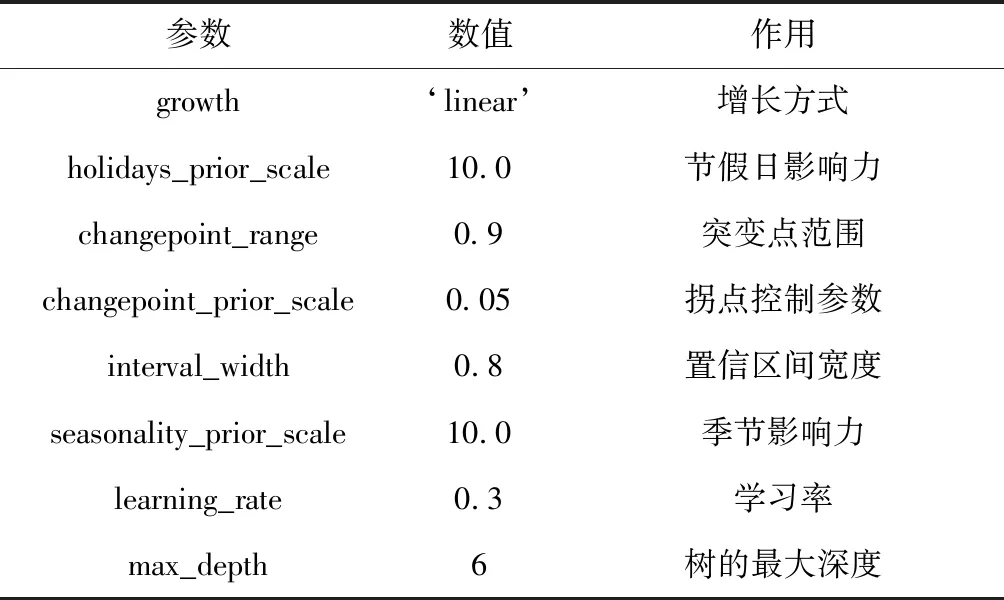
表3 模型參數初始化表
選擇趨勢模型,控制參數是“growth”,默認使用分段線性的趨勢“growth=linear”,但是如果認為模型的趨勢是按照log函數方式增長的,可設置growth=′logistic′從而使用分段log的增長方式。默認情況下,只有在時間序列的前80%才會推斷出突變點,以便有足夠的長度來預測未來的趨勢,并避免在時間序列的末尾出現過度擬合的波動,默認值可以在大多數情況下工作。修改changepoint_range參數,changepoint_range=0.9表示將在時間序列的前90%處尋找潛在的變化點。如果趨勢的變化被過度擬合(即過于靈活)或者擬合不足(即靈活性不夠),可以利用輸入參數 changepoint_prior_scale 來調整稀疏先驗的程度。默認下,這個參數被指定為 0.05 。增大該值,會導致趨勢擬合得更加靈活。如果發現節假日效應被過度擬合了,可以通過設置參數 holidays_prior_scale調整它們的先驗規模來使之平滑,默認情況下該值取 10 。減小該值會降低假期效果。seasonality_prior_scale 參數可以用來調整模型對于季節性的擬合程度。learning_rate表示學習率,可以縮減每一步的權重值,使得模型更加健壯;max_depth表示樹的最大深度,值越大,樹越復雜。可以用來控制過擬合,典型值是3-10。
4 實驗分析
將訓練集的數據作為模型的輸入數據,查看預測的成分分析,如圖2所示。
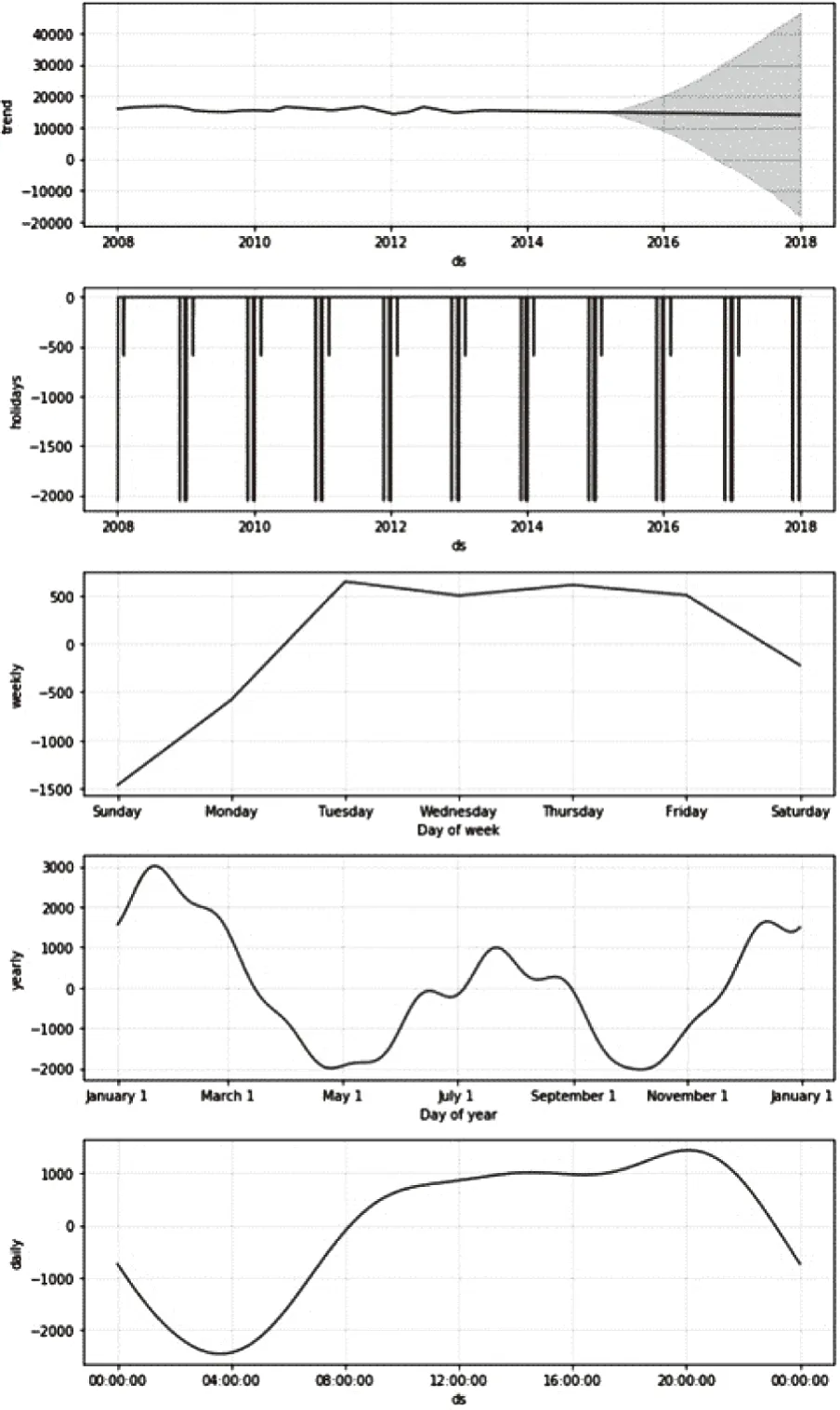
圖2 預測成分分析圖
圖2給出了模型對訓練集數據各成分單獨分析的結果。從上至下依次是美國加州地區2008~2014年用電量被Prophet加法模型分解的增長趨勢(trend)、節假日趨勢(holidays)、周趨勢(weekly)、年度趨勢(yearly)、日趨勢(daily)。增長趨勢中訓練集到測試集10年的年用電量波動不大,基本保持平衡;年度趨勢中,2月、8月、12月存在波峰,說明這三個月是加州地區每年用電量最多的月份;5月、10月存在明顯的波谷,說明這兩個月是加州每年用電量最少的兩個月。周趨勢中,周日到周二的用電量存在明顯的線性急速增長趨勢,接近正比。增長趨勢到周二后消失,周二至周五,用電量波動很小,基本趨向平穩。周五至周六,用電量開始下降。說明每周周末用電量最低,周二至周五用電量最多,基本趨向平穩。日趨勢中,每天4點是用電量的低谷,20點事用電量的高峰,0點到4點用電量存在明顯下降趨勢,4點到10點明顯增長,10點到18點用電量趨勢基本維持平穩,20點到24點,用電量迅速下降。
將訓練集的數據分別作為Prophet模型和改進后的X-Prophet模型的輸入,進行數據分析,將訓練好的模型用于測試集,對預測效果進行分析。本文選用平均百分比誤差(MAPE)和均方根誤差(RMSE)作為評估原模型和改進模型預測效果的標準,表達式如下
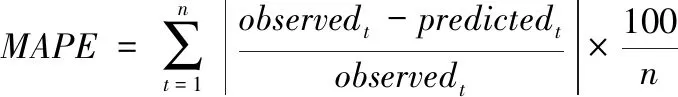
(15)
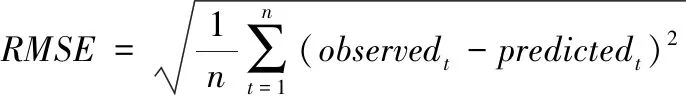
(16)
observed為每個小時的實際用電量,predicted為每個小時的預測量,n為小時的總數。用以上誤差公式計算原模型和改進模型在測試集數據上的預測誤差。Prophet模型誤差如表4所示;X-Prophet模型根據不同權值產生多組誤差,如表5所示。

表4 測試集Prophet模型誤差表

表5 權值系數w1和w2對應的X-Prophet模型誤差
表5中數據顯示,當w1=0.2,w2=0.8時,改進模型X-Prophet在測試集上的預測綜合誤差最小,即此時模型最優,MAPE=7.69,RMSE=1557.1。
Prophet模型和當w1=0.2、w2=0.8時X-Prophet模型在測試集上的預測效果圖如圖3、圖4所示。
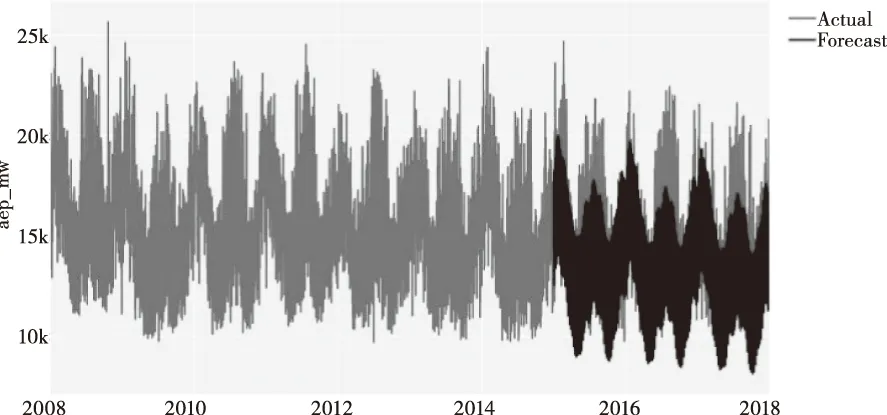
圖3 Prophet測試集預測效果圖
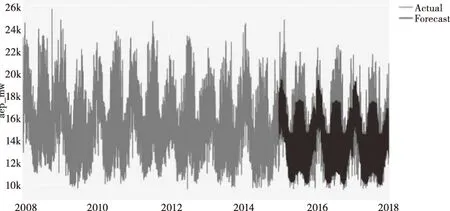
圖4 X-Prophet測試集預測效果圖
圖3、圖4中顯示,深灰色曲線表示測試集中用電量的預測值,淺灰色曲線表示用電量的真實值。結果表明改進后的模型X-Prophet在測試集數據上的的曲線擬合效果比Prophet模型要好。
對比Prophet模型在測試集上的預測誤差,以及w1=0.2,w2=0.8時X-Prophet模型的預測誤差,見表6。
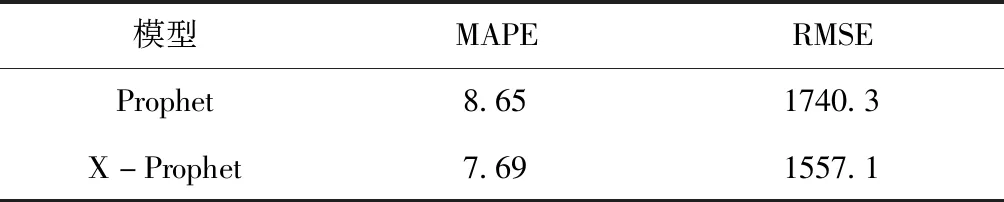
表6 兩種模型誤差對比表
分析上表發現,與原模型相比,改進后的模型在測試集上,預測誤差MAPE減少了約11%,RMSE同樣減少了約11%。改進后的模型具有更準確的預測結果。
綜上所述,改進模型X-Prophet與原模型Prophet相比,預測誤差更小,模型更穩定,預測效果更佳。
5 結論
本文提出了一種基于Prophet的改進預測模型X-Prophet。該模型引入了優化項XGBoost對Prophet預測值進行優化,使Prophet與XGBoost優勢互補,提高預測準確率。實驗結果表明,與原模型相比,X-Prophet改進模型使預測誤差減小了約11%,在預測行為上比原模型具有更高的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
第一財經(2021年6期)2021-06-10 13:19:08
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
Coco薇(2017年9期)2017-09-07 21:23:49
光學精密工程(2016年6期)2016-11-07 09:07:19
紡織服裝流行趨勢展望(2016年2期)2016-05-04 03:47:15
中國衛生(2015年7期)2015-11-08 11:09:38
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車科技(2015年1期)2015-02-28 12:14:44
