“互聯網+”環境下多源東盟文獻信息資源融合與揭示研究
2021-12-08 01:57:52蘇瑞竹肖龍翔
圖書館界 2021年5期
蘇瑞竹,肖龍翔
(1.廣西民族大學管理學院,廣西 南寧 530006;2.華中師范大學信息管理學院,湖北 武漢 430070)
1 引 言
“互聯網+”是指把互聯網環境下的創新成果與經濟社會各領域深度融合,推動技術進步、效率提升與組織變革,提升實體經濟創新力與生產力,發展一種經濟的新模式。2015年7月,國務院發布《國務院關于積極推進“互聯網+”行動的指導意見》,闡明互聯網各種各樣的創新成果和其他領域有機結合的重要性與必要性。該文件指出,加快推進“互聯網+”發展,建立公共服務一種前所未有的全新模式,有利于進一步推動經濟發展。
“互聯網+”也為圖書館的發展帶來了機遇與挑戰,可以積極地借助“互聯網+”的技術進步與政策助力,將“互聯網+”融入圖書館實際工作中,主動進行業務創新,通過“互聯網+”驅動數字資源的互聯融合,使圖書館服務逐漸向以融合為基礎的服務生態系統轉變。“互聯網+”環境對圖書館多源東盟文獻信息資源融合與揭示帶來了新的機遇,充分結合東盟國家多種來源信息,對圖書館運用包括大數據在內的多種方法進行綜合融合與分析,全面了解東盟國家各方面發展態勢的方法策略并進行規劃與設計,為科學決策提供更有利的情報支撐,以期服務于“一帶一路”倡議。
2 多源東盟文獻信息資源體系的建設、融合及其研究現狀
2.1 多源東盟文獻信息資源體系建設、融合現狀
2.1.1 公共圖書館。中國國家圖書館為我國最大的圖書館,它的外文數據庫收藏著大量的多語種、多來源的東盟文獻信息資源,擁有多語言及多種來源的東盟文獻資料庫。
此外,很多的公共圖書館對東盟信息資源的建設也愈加重視,如廣東、廣西、福建、云南等毗鄰東盟、與東盟交流密切的省份,均充分發揮自身區位優勢逐步建立東盟文獻信息資源體系。例如,廣西壯族自治區圖書館、云南省圖書館等公共圖書館都建有專門的東盟文獻書庫,廣西壯族自治區圖書館還融合大量的信息資源制作了東南亞研究論文庫和東南亞風情資源庫。
2.1.2 高校圖書館。東盟信息資源是東盟語言教育和研究的重要支持資源。東盟信息資源創建因語言限制、人才、處理難度等原因仍面臨諸多困難。但是,通過高校圖書館的共享,許多高校在已有基礎上,拓展東盟文獻方面的信息資源,幫助學校師生開展教學和科學研究。例如,廣西民族大學圖書館設有東盟文獻信息中心,收藏了包括越南、老撾、柬埔寨等多個東盟國家的原版圖書 50 000 余冊。其中,詩琳通公主泰文資料中心、越南語文獻信息中心等多個東盟文獻信息中心構建了完整的東盟文獻信息資源體系,在相關教育和研究機構中形成較大影響力。為推進資源共享,廣西民族大學圖書館還利用阿帕比數字出版全流程解決方案對收藏的東盟紙質文獻資源進行數字化,建成東盟原版圖書庫和東盟文獻庫。又如,暨南大學東南亞研究所建設的新加坡研究數據庫也獲得了廣泛認可;CALIS資助建設的廈門大學東南亞及閩臺研究數據庫和暨南大學華僑華人文獻信息專題數據庫,也成為多語種、多數據源和東盟信息資源融合的代表性項目。
2.1.3 東盟研究機構。“一帶一路”倡議引導許多研究機構將研究重心轉向東盟國家。這些機構將學術著作、學術期刊和其他出版物與已有的數據庫相融合成為信息資源服務體系,為研究者提供信息支撐。例如,暨南大學東南亞研究所、廈門大學東南亞研究中心、廣西大學東盟研究院等研究機構,充分利用了自身所具備的東南亞地區信息資源優勢,在東盟的科研方面取得良好成績;這些研究成果的收藏也豐富了本機構的東盟文獻信息資源。又如,廣西大學融合網絡信息構建了中國—東盟全息綜合數據平臺。通過該平臺的建設,可以實時、直觀、形象、逼真地互動展現中國—東盟地區政治、經濟、文化、地理、歷史、資源等相關全息信息,面向各級專家領導、科研團隊、數據加工團隊、公眾用戶等提供專業的信息咨詢服務,為中國—東盟研究院各類課題研究、日常教學、專題會議提供各個層次的研究數據和實用工具,從資源層面提升研究院的基礎研究能力,為確保廣西大學在中國—東盟研究領域在全國的領先地位奠定堅實的基礎和技術保障。
2019年9月,中國東盟信息港與廣西大學國際學院聯合成立中國—東盟信息港大數據研究院,其中,最重要的是6大數據平臺:以區塊鏈作為底層技術的中國—東盟金融合作大數據平臺,瀾滄江—湄公河流域生態與經濟大數據平臺、中新互聯互通南向通道數據庫建設、“泛南海合作”全息數據庫平臺、人工智能技術應用與“數字廣西”大數據平臺以及全球價值鏈與中國—東盟生產貿易鏈大數據平臺,建立一個面向全國乃至整個東盟的國際網絡信息資源系統。
1995年,南海研究院圖書館開創了建設我國南海問題研究的南海文獻數據庫的先河,內容涉及國際上與南海問題有聯系的各類英文資源以及清朝以來內地和港澳臺與南海問題相關的文獻資源,包括各個時期的各類地圖、政府文件檔案以及與東盟國家的往來書信資源,還有電話稿件等相關資源,更不乏各種會議記錄、影像照片以及第二次世界大戰以后我國關于接收西南沙群島的一系列重要文獻等,極大地支持了我國對南海問題相關合法權益的維護。
2.2 多源東盟文獻信息資源融合研究
我國關于多源東盟文獻信息資源融合的研究較少,在CNKI以“篇關摘”為入口,以“東盟信息*融合”為檢索詞查詢到84篇論文,基本上是教育學、信息基礎設施、金融、經濟等方面的論文,沒有一篇是研究多源東盟文獻信息資源融合的。
但是,有關多源信息資源融合的研究不少,如化柏林對多源信息融合的方法進行研究,他還與李廣建利用多源信息融合技術開展競爭情報研究,他們的另一份研究則關注多源數據融合,用競爭情報方法加上主流的大數據方法,形成一個互補的組合,并使用多源信息融合理論與競爭情報、大數據等相關領域進行深度融合研究。這些研究成果對多源東盟文獻信息資源的融合具有借鑒意義。
3 “互聯網+”多源東盟文獻信息資源融合
“互聯網+”環境的到來,對圖書館提出了新的要求。圖書館傳統的多源東盟文獻信息館藏已無法滿足用戶的需求,需要將文獻信息資源進行數字化,并從各個渠道尋求更多資源來滿足用戶更高的信息需求,這就使圖書館對多源東盟文獻信息資源融合的需求更為迫切。
3.1 多源東盟文獻信息資源組成類型
多源文獻資源的融合包括以不同方式、從不同渠道獲得的各類資源,以統一的形式融合組織成易于使用的數據庫。這些資源的來源主要有3個部分:融合的網站資源、本館數字化的館藏資源、整合的訂購數字資源(見圖1)。
3.1.1 融合的網站資源。網絡信息的蓬勃發展,使網站資源的重要性達到了前所未有的高度。聚合網站資源是指圖書館從東盟國家的網絡上采集時事新聞、市場信息、經濟信息資源。這些網絡信息資源能精準地反映各東盟國家的政治、經濟等多方面現狀,將其聚合與分析可以為圖書館開展東盟信息服務和支持用戶決策提供重要的信息資源基礎。
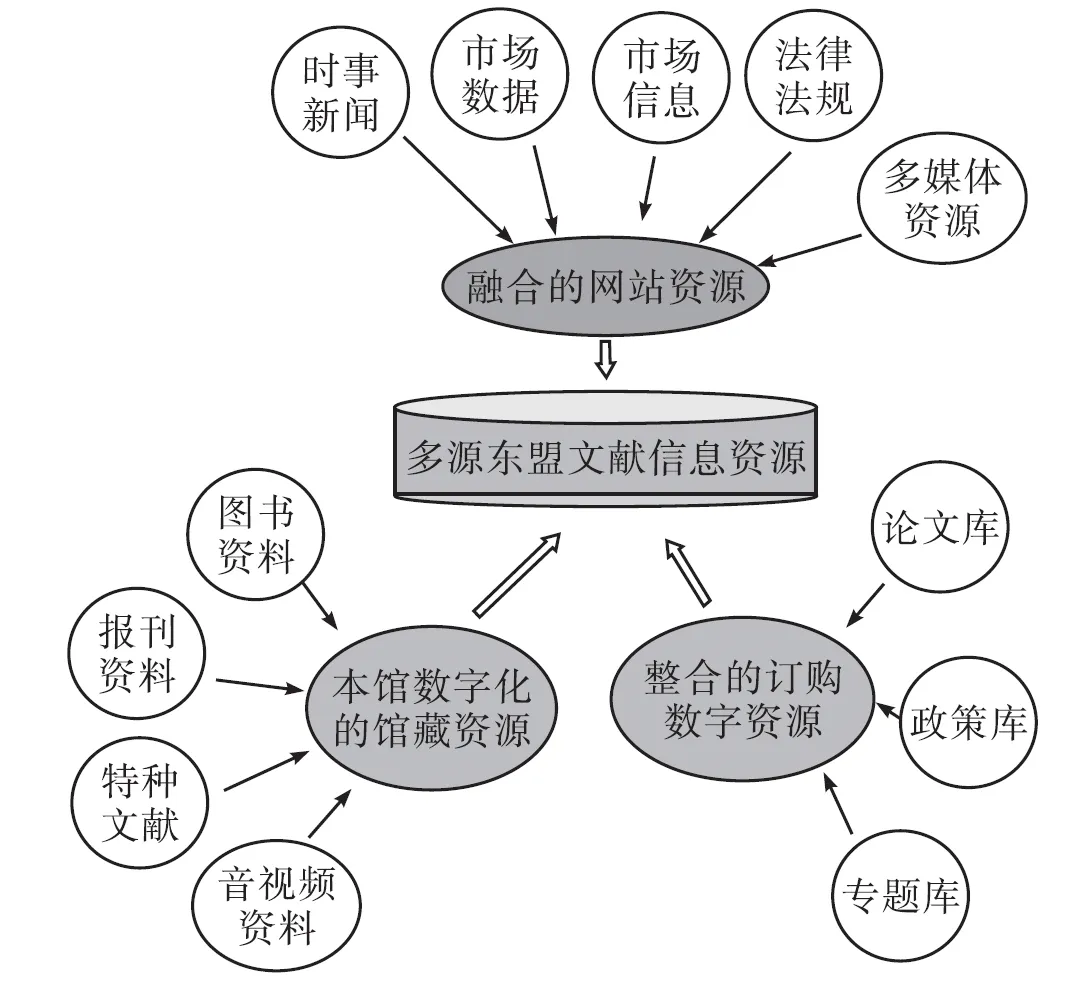
圖1 多源東盟文獻信息資源組成類型
3.1.2 本館數字化的館藏資源。以文獻資源建設為主要工作之一的圖書館,收藏東盟各種類型的書籍、報紙、原版音視頻文獻(光盤)以及其他相關資源。圖書館通過對本館館藏東盟紙質文獻的數字化,聚合所購買的東盟原版音視頻文獻,形成數字化的東盟館藏資源,極大地豐富圖書館的多源東盟文獻信息資源體系。
3.1.3 整合的訂購數字資源。就目前而言,由于資金、館藏政策、語言等多種條件的限制,單一的圖書館或若干個圖書館組成的圖書館聯盟并沒有建設完整而全面的多源東盟文獻信息資源體系的條件與能力。因此,在需要東盟信息資源但無力建設的情況下,購買外部資源便是一個很好的方式。圖書館可以向數據提供商、咨詢公司、情報研究所等機構購買有關東盟各個國家的專利數據庫、政策數據庫、論文數據庫等數據庫,利用這些數據庫專業性、權威性、實用性為圖書館的有關服務提供幫助。
3.2 多源文獻信息來源的類型
3.2.1 同型異源平臺文獻信息。東盟文獻信息來源類型多樣,像文獻信息數據庫、各種機構網站以及微博、博客、微信公眾號等就是東盟文獻信息的載體。信息的主體和形式分布在同一類別的信息平臺中,但每一個都有不同的信息搜集渠道、信息處理系統和信息處理標準,使之服務的內容和用戶各有不同。同一類型平臺的不同形式或不同來源渠道的信息就是同型異源的信息。所購置的各類數據庫信息以及機構知識庫中有來自各種信息平臺的信息,如微信公眾號里的信息也屬于這一類。同型異源的信息往往在各自的平臺中對相關的權益人展開服務。
3.2.2 異型異源平臺信息。不同類型的東盟文獻信息平臺存在不同形式的信息,如東盟文獻信息數據庫主要是由圖書、期刊等學術信息構成,非常系統;東盟微博為短文本形式信息;東盟博客則以篇章博文的形式產生長文本信息;同時還有一些平臺的語音、視頻等形式的信息。這些不同類型的平臺及其不同形式的信息組合構成了異型異源信息。
3.2.3 多語種平臺信息。多語種平臺信息實際上是東盟國家各自建立的本國語種的信息媒體平臺發布的信息。雖然語種多樣,但東盟國家發布的這些不同語種,內容類型多樣的信息,是人們在互聯網時代對東盟科技信息、經濟信息、生活信息以及學術信息的需求和獲取上不可忽視的信息源。
3.3 多源信息融合
多源信息融合,按照多源信息的不同類型,主要包括同型異源信息融合、異質異構信息融合以及多語種信息融合三種類型。跨界融合是“互聯網+”的一個顯著特點,它為信息源、供應商、用戶等融合創造了條件。
3.3.1 同型異源信息的融合。同型異源信息的融合,實際上是對這些信息的聚合,也就是針對同一類型的信息平臺進行信息聚合。這里主要指對所購買的文獻信息資源數據庫以及對新媒體平臺東盟信息的聚合。
圖書館所獲取的同一類型的東盟文獻信息資源皆為不同來源,具有不同形式、不同標準和不同服務模式的不同書目資源提供者。在數據庫方面,中文期刊的圖書館資源一般由中文數據庫提供商提供,如CNKI、維普等,而外文期刊的資源取自外文數據,如EBSCO、ELSEVIER等。這些數據庫資源存在著同型異源的特點。而各新媒體平臺的信息資源如果單從同一類型的平臺來說也有同型異源的特點。
對不同來源的東盟文獻信息資源,需要進行集中的整合與處理,通過統一字段格式、同類字段識別轉化等方法將這些同型異源文獻信息資源進行聚合分析,使這些同型異源的東盟文獻信息資源可被統一的獲取與利用,更好地為服務與決策提供支撐。
3.3.2 異型異源信息的融合。由于“互聯網+”的推動以及影響,單一的文獻信息資源類型已經不能滿足用戶與決策者的需求。十大文獻信息資源以外的資源如包括社交媒體數據等零次、一次文獻,如微博、博客、微信公眾號也開始成為圖書館信息資源建設研究與分析的新重點,東盟文獻信息資源需求可以考慮從這些資源入手。在“互聯網+”的全新挑戰下,圖書館應當從不同來源和不同類型這兩個角度對東盟文獻信息資源進行全面系統的搜集和整理,也就是說對東盟文獻信息資源的融合需要考慮異型異源信息的融合。
圖書館在不同的條件下搜集論文資源、書籍、報刊、專利、東盟各國不同類型的政策資源和微信、微博等不同平臺類型的異型異源文獻信息資源,通過子字段拆分、融合分析等方法,進行統一整合,并對融合過的結果進行計量研究、關聯分析,以便更好地反映東盟各國的發展態勢,為東盟國家及其國家的用戶提供良好的多層次和多種類的信息服務。對異型異源信息的融合,可提升東盟文獻信息資源的多樣性表達,同時使文獻信息資源的豐富程度得到多層次提升,多樣化的東盟文獻信息形式還能吸引更多用戶,有助于用戶發現所需的文獻信息資源,幫助用戶提高獲取文獻信息資源的速度。
3.3.3 多語種信息的融合。多源東盟文獻信息資源,除了類型和來源不同,語言不同也是一大特征。由于東南亞國家聯盟的特殊歷史條件,東盟國家除了具有自己民族特色的本土語言,如馬來語、越南語、泰語和菲律賓語以外,在一些地方還有法語、英語、俄語、日語、葡萄牙語等語種作為半官方語言。因此,東盟文獻信息資源的語種包括本土語言和上述提及的非本土語言等多語種與東盟相關的文獻信息資源。在實際采集東盟國家文獻資源的過程中,圖書館會搜集以各種語言呈現的東盟文獻信息資源。此外,由于某些語言的特殊性,除了少數專業人士,大多數圖書館員無法在短時間內了解大量的東盟文獻和信息資源。為了融合這些多語言信息,需要使用翻譯工具將多種東盟語言的信息資源自動翻譯成中文,以便館員進行文獻信息的分類標引和分析挖掘,使融合的東盟文獻信息資源服務平臺能為用戶提供東盟多語種文獻信息資源服務。
3.4 多源信息融合層次
多源信息融合的實現,有著不同的采集和抽象層次,通常來說包括以下4層:基礎層、數據層、特征層和決策層(見圖2)。
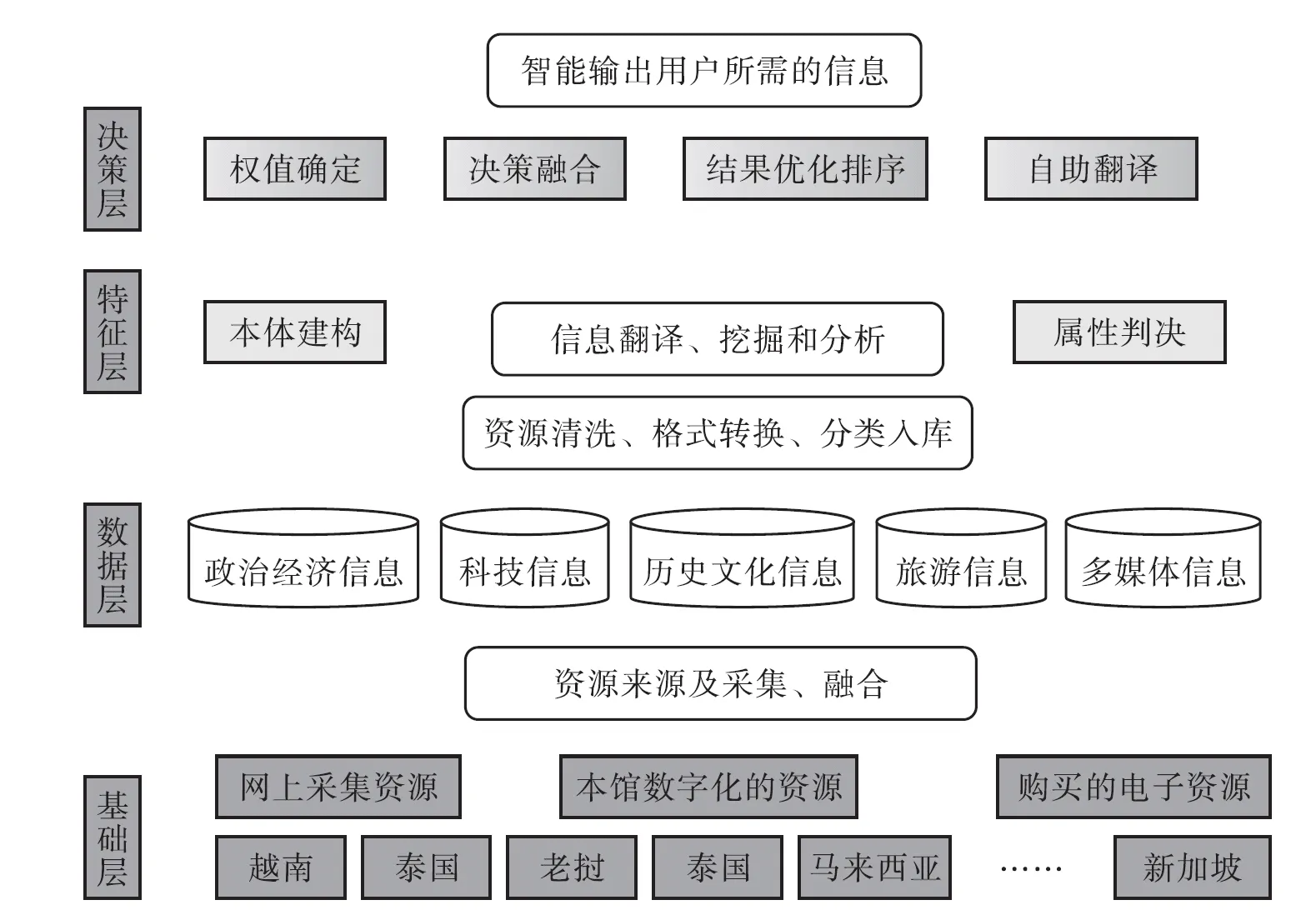
圖2 多源東盟文獻信息資源融合的層次
3.4.1 基礎層。基礎層由網上采集到的東盟各國數據和對館藏紙質資源進行數字化所形成的數字化的資源以及圖書館采購的各語種電子資源(數據庫)組成,是數據融合的基礎。
3.4.2 數據層。數據層資源融合是指在采集到的原始數據層上直接進行融合,對各個信息源獲得的未經處理的數據進行綜合與分析,通常采用信息資源統一操作的融合方法。這個層次的信息融合實際上屬于低層次、低維度的簡單融合。
在數據層整合東盟文獻信息資源,意味著圖書館將直接整合分析東盟國家的各類數據,無需任何其他操作,可以最大限度地保證東盟國家相關數據的原始性,完整地掌握和分析相關數據。
但是,這種融合需要面對大量、機械的數據處理,需要極強的對數據處理的能力要求。融合過程還要求數據具有相同的類型和格式。但圖書館所搜集到的東盟相關文獻信息資源來源多樣、復雜、異構,難以在數據層面整合東盟文獻信息資源。
3.4.3 特征層。與數據層融合不同的是,特征層的信息融合是一個中間步驟。特征層的融合第一步便是提取之前搜集好的有關數據信息的關鍵特征,根據這些特征對信息進行科學的組織和分類。通過提前進行特征提取,這一層次的融合對信息總量進行壓縮,從而幫助用戶在檢索時根據自己的需要快速檢索信息,同時,在瀏覽信息時,更利于用戶理解與掌握。
東盟文獻信息資源在特征層信息融合所體現的就是從數據庫內各個來源匯集的數據中篩選出它們各自的特征,并對這些特征的融合進行先關的包括分析和處理在內的一系列操作(見圖3)。
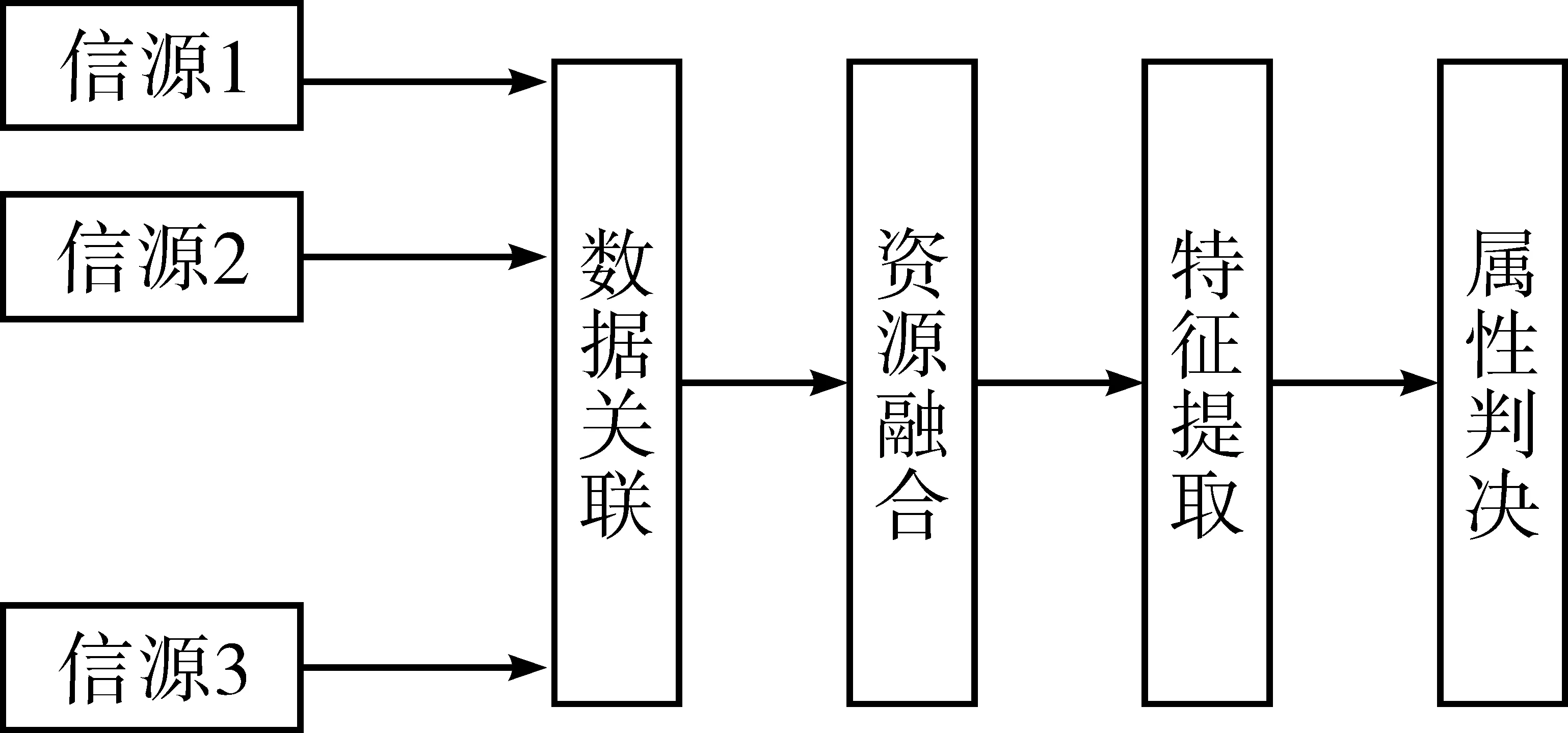
圖3 特征層信息資源融合圖
特征層的信息融合可以篩除一些不需要的重復操作,精簡信息處理步驟和計算量,對數據處理能力的要求不再那么高,更容易進行長時間的高效操作。
圖書館通過對東盟國家相關數據的具體特征進行提取和分析,可以對來自各個數據源的數據進行一定的分析,融合結果可以直接為決策分析提供信息支持。為國家決策東盟國家有關事務提供科學依據。
3.4.4 決策層。決策層的信息融合,是將每條文獻信息源的數據從宏觀和全局的角度進行整體協調。通過對不同來源數據提取的特征進行分析和融合,直接為決策提供支持。
決策層的東盟文獻信息資源融合,針對的是在對有關東盟國家具體問題進行決策時,對之前所提取的東盟不同類型文獻信息資源進行特征分析。這可以直接結合決策定制展開,最大限度地分析多選決策方案的優劣,最大限度地協助決策者作出最科學的決策和合理的決定。另外,為了幫助用戶以最快的速度作出決策,當用戶獲取決策層的信息時,還會有一些處理使后期的利用更加高效,這些處理涉及多語言機器的自動翻譯、多源信息資源檢索結果可視化顯示等一系列功能。這些功能在一定程度上提高用戶的檢索效率,優化用戶體驗,輔助用戶作出科學合理的決策。
4 “互聯網+”環境下多源東盟文獻信息資源揭示
為了使融合的多源東盟文獻信息資源更好地服務于信息用戶,對文獻資源的揭示顯得尤為重要,通過對文獻資源在描述層、聚合層和應用層的處理與揭示,為多源東盟文獻信息資源更好的服務呈現提供基礎(見圖4)。
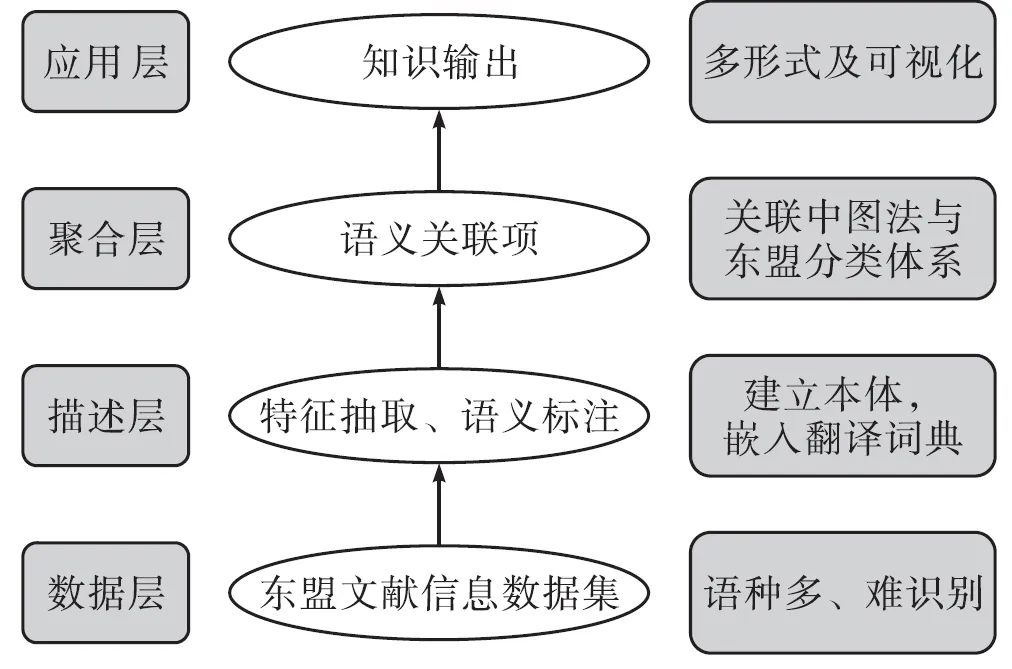
圖4 多源東盟文獻信息資源處理與揭示過程
4.1 資源揭示基礎元數據化
要對多源東盟文獻信息資源進行揭示,就必須采集東盟國家各種類型信息的元數據,對同一類型的同一來源和不同來源的資源,以用不同類型不同來源的資源進行元數據提取。將這些元數據進行標準格式轉換,使文獻資源揭示實現元數據化,標準化的元數據多源東盟文獻信息資源揭示,能很好地描述所藏文獻信息資源的特征,也可對少量多源東盟文獻信息資源進行壓縮、組織,為多源東盟文獻信息資源的集中揭示提供基礎。對數量龐大的文獻資源進行壓縮、組織,以利于之后的資源利用。
元數據標準的制訂決定了元數據化是否能高效有效地完成。目前,Dublin Core核心元數據是使用最多的國際性元數據解決方案,內容主要涵蓋了資源標識符(Identifier)、標題(Title)、主題(Subject)、創作者(Creator)、資源類型(Type)、資源描述(Description)等15個核心元素。針對電子圖書、網絡資源、期刊論文、學位論文、電子連續性資源、圖像資源、音頻資源、視頻和資源古籍文獻等,中國國家圖書館也提出了對相應的元數據標準與著錄規則。由于東盟文獻信息資源來源的復雜性、文獻信息語言的多樣性以及著錄人員缺乏東盟語言支撐,圖書館必須構建一個統一的元數據格式,以此作出一個詳細且符合規范的描述來規范著錄的格式,以便實現信息的共建共享。對不同的數字化多源東盟文獻信息資源,無論是圖書、報刊、特種文獻還是網絡資源,我們認為著錄的元數據應以從Dublin Core核心元數據主要包含的15個核心元素選擇部分元素為標準:資源標識符(Identifier)、標題(Title)、主題(Subject)、創作者(Creator)、資源類型(Type)、資源描述(Description)、日期(Date)、格式(Format)、語言(Language)、出版者(Publisher)。一方面,這些元數據基本上能揭示資源的主要特征;另一方面,也減輕信息組織者的語言負擔。只有建立一致的元數據格式,才能進行之后的元數據記錄。
一旦確定圖書館的標準格式,就可以首先從數據庫第一個單一元數據模型記錄的各種信息資源類型搜集之前統一格式的元數據。通過元數據機制,將不同類型的書目載體轉換成多源東盟文獻信息資源,在下一周期部署工具,并統一處理資源。
4.2 資源組織方式機構倉儲化
機構倉儲化,是指建立一個統一的元數據存儲體系,將經過搜集、標準制訂、整合之后的元數據集中到一個倉儲系統之中,實現機構倉儲一體化管理(見圖5)。
對多源東盟文獻信息資源而言,異型異源、同型異源及多語種等多種類型的文獻資源經歷了數據搜集、元數據標準制訂等步驟之后,便可以進行元數據的整合與倉儲化存儲。在“互聯網+”的環境下,如何更好地利用圖書館所搜集到的各類東盟文獻信息資源,是圖書館東盟國家情報支撐的重要環節。
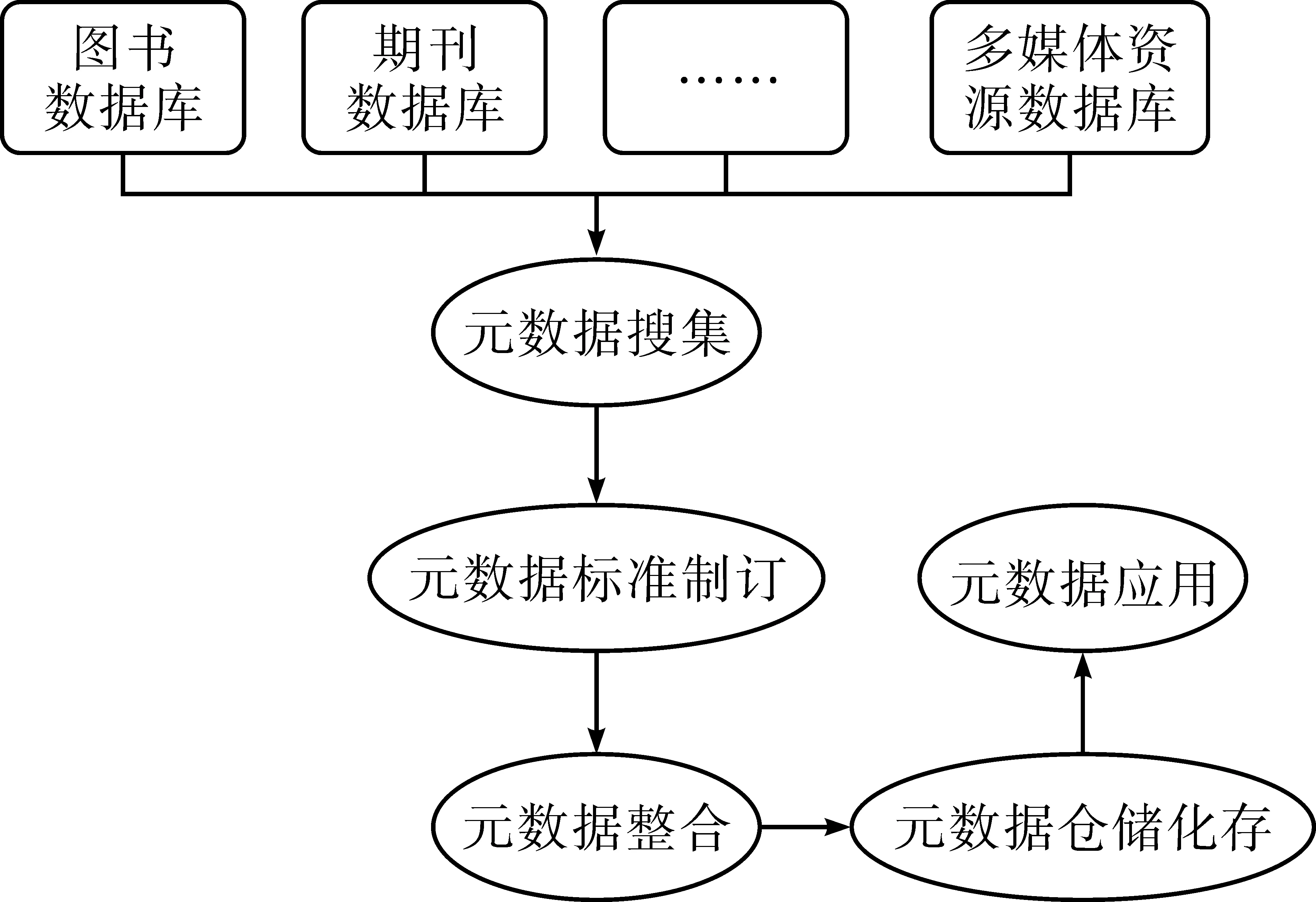
圖5 資源組織方式機構倉儲化
對于完成對多源東盟文獻信息資源描述的元數據,圖書館必須在處理重復元數據后進行適當的研究、清理和規范。
元數據存儲系統,將多樣化的元數據導入元數據存儲設施中,為所有元數據提供統一的存儲和集成,可以大大增加多源東盟文獻信息資源的可用性和實用性。通過集成的檢索平臺,可以檢索所有存儲在元數據倉儲系統中的數據,統一內存為統一使用恢復提供一個有效平臺。
4.3 資源描述語義化
多源東盟文獻信息資源的來源各異、形式多樣,具有多元化、分布式、異構化的特點,在進行文獻資源描述時,可對所有的元數據進行語義描述,通過語義關聯數據增加資源的內部關聯,促進圖書館多源東盟文獻信息資源的深度聚合展示。
多源東盟文獻信息資源的開發利用,可借助知識單元的語義關聯實現。語義化的資源描述,經過對多源東盟文獻信息數據集中的數據進行資源描述、知識聚合等程序,最終應用于知識輸出。
規范的元數據格式是進行語義關聯的重要基礎,對海量的多源東盟文獻信息資源的統一描述,需要在進行標準確定、特征提取、加工之后存儲在元數據庫之中。
多源東盟文獻信息資源描述,主要為揭示不同類型東盟文獻信息資源的語義關聯,實現知識層面的聚合。多源東盟文獻信息資源的元數據關聯聚合,主要通過元數據值匹配關聯和相似性關聯的方法實現文獻資源的語義關聯。對不同資源的同一元數據,可以通過元數據取值關聯的方法,在相應的元數據項之中建立關聯關系,如多源東盟文獻信息資源的作者、主題等。針對不同的內容,可采用元數據語義相似性關聯的方法,建立文獻資源的語義互聯關系,這種方法將元數據進行細化劃分,再實現關聯,是一種細粒度的知識組織方式。
4.4 情境智能設計,資源關聯發現
通過元數據記錄、倉儲化管理和語義化描述以及最終的使用水平,可以改善東盟文獻資源的利用。作為東盟相關決策的重要參考依據,圖書館必須提高信息資源利用效率,通過提供個性化和普遍的資源搜索服務來獲得搜索結果的準確性。
圖書館的不同訪問用戶,會有個性化的特點與要求,圖書館情景智能設計,就是通過對用戶的需求分析、訪問方式分析等類似判斷操作,將最合理、最符合用戶需求的資源提供給用戶。
而搜索結果的呈現方式,對多個圖書館來說,由于多源東盟文獻信息資源可以相互關聯,互為補充,可將結果整合為一個均勻的知識獲取平臺,當用戶進行相關的操作時,采用改進的方法進行研究,以完善的過程分析,從多個東盟文獻來源中提取相關信息,從圖書館中搜集、分析和鏈接,為用戶提供更好的服務。
5 結 語
在多源東盟文獻信息資源現狀很難滿足信息需求的情況下,將資源融合作為解決資源匱乏、資源利用率較低等困難的技術手段有著廣闊的發展前景。本文在詳細分析多源東盟文獻信息資源的特點與建設現狀的基礎上,對科學有效的多源東盟文獻信息資源融合技術路線進行一定的分析研究,通過多源東盟文獻信息資源的信息整合與揭示利用,以有效滿足用戶的東盟信息需求為核心,希望可以解決一些現實工作中的問題,為多源東盟文獻信息資源融合的發展提供一定的理論支撐。
