基于雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的變結(jié)構(gòu)多模型自主導航方法
2021-12-06 03:13:14許曉偉賴際舟陸俊清白師宇胡華峰
中國慣性技術(shù)學報 2021年4期
許曉偉,賴際舟,呂 品,陸俊清,白師宇,胡華峰
(1.南京航空航天大學 自動化學院,南京 210096;2.湖北航天技術(shù)研究院 總體設(shè)計所,武漢 430040)
井下的煤炭開采的作業(yè)空間狹小,工作人員靠近大型機械,以及空氣中存在的易燃易爆氣體和粉塵都對井下安全帶來了挑戰(zhàn)。為了確保采煤效率和工人的工作安全,煤炭開采正在由人工向自動化方向轉(zhuǎn)變,其中采煤機定位是實現(xiàn)煤炭開采自動化的核心技術(shù)[1,2]。在GNSS拒止的井下定位環(huán)境中,慣導系統(tǒng)憑借其較好的自主性和可靠性被廣泛應(yīng)用于井下的復(fù)雜環(huán)境[3,4]。為了提高慣導系統(tǒng)的定位精度,零速校正是一種常用的誤差約束手段,但這種方式需要載體不斷地靜止實現(xiàn)載體的速度約束,不利于采煤機的連續(xù)開采。楊海等人[5]通過對采煤機振動引起的慣導系統(tǒng)計算誤差進行了相關(guān)研究,通過對振動頻譜特性的分析,建立了圓錐誤差和劃船誤差的補償模型,利用多子樣算法提高了慣導系統(tǒng)的計算精度。但是在隨機振動中,多子樣補償算法的效果不明顯[6]。受制于慣導系統(tǒng)自身定位機理,長時間的采煤過程導致慣導系統(tǒng)定位誤差不斷累積[7]。為保證慣導系統(tǒng)長期的定位精度,通常需要借助外部信息的周期性的修正慣性誤差。例如通過里程計和慣導系統(tǒng)的組合,減少了采煤機長時間切割過程中的位置發(fā)散,或者利用在井下環(huán)境中布置的UWB錨節(jié)點組成無線傳感網(wǎng)絡(luò)實現(xiàn)對慣導位置的約束[8]。Jonathon R等人利用熱成像相機,利用采煤機煤炭切割過程中截割部與不同成分的煤層摩擦產(chǎn)生的不同紅外特性,提高了煤層垂直面位置的定位精度[9]。由于井下惡劣的環(huán)境對傳感器的可用性、可靠性和安全性都提出了嚴格的要求。因此目前基于慣導/里程計的組合導航仍是最主要的導航方式。
為了分析井下慣導系統(tǒng)在振動環(huán)境下的輸出特性,采用陀螺零偏穩(wěn)定性為0.003°/h的慣導在某礦井下采集了采煤機工作時的實際陀螺輸出,如圖1、2所示。

圖1 井下開采靜止狀態(tài)陀螺實際輸出Fig.1 The output of the gyro at static state

圖2 井下開采切割狀態(tài)陀螺實際輸出Fig.2 Output of gyro under vibration
從圖中可以看出,開采靜止狀態(tài)的陀螺輸出基本符合慣導標稱的性能水平。但是在切割狀態(tài)下,慣導系統(tǒng)由于振動使陀螺輸出精度存在明顯下降。圖3是實際開采過程中慣導系統(tǒng)陀螺儀在井下振動環(huán)境的噪聲頻譜圖,其中存在著多種不同的振動頻率分量,導致噪聲水平多變。

圖3 井下開采實際陀螺噪聲頻譜Fig.3 Spectrum of noise under vibration
目前傳統(tǒng)的卡爾曼濾波估計通常基于固定噪聲模型,在濾波過程中由于模型參數(shù)失配導致濾波結(jié)果精度較差甚至發(fā)散,難以適用于井下定位環(huán)境。多模型估計(Multiple Model Estimation, MME)是一種能夠處理系統(tǒng)結(jié)構(gòu)和參數(shù)不確定的自適應(yīng)估計方法[10],被廣泛用于時變模型的故障檢測和診斷[11]、目標跟蹤[12]、組合導航[13,14]等領(lǐng)域。為了解決輪式里程計在輪胎出現(xiàn)滑動時誤差時變的問題,Hyoungki Lee等人[15]提出了一種交互式多模型的輪式里程計滑移檢測及補償方法,利用基于模糊邏輯輔助的交互式多模型逼近無滑移和滑移過程中的時變動力學模型,提高了載體的定位精度。為了解決GPS拒止的巷道環(huán)境下的車輛多動態(tài)高精度定位,王磊等人[16]針對組合導航系統(tǒng)中存在的時變或非高斯噪聲,提出了一種交互式多模型秩濾波算法,實驗結(jié)果表明算法能夠提高組合導航系統(tǒng)姿態(tài)、速度和位置估計精度。但是,傳統(tǒng)固定結(jié)構(gòu)多模型算法均針對較少的系統(tǒng)狀態(tài)。當時變系統(tǒng)運動狀態(tài)需要較多的模型集合來描述時,不僅計算更加復(fù)雜,而且模型之間的競爭會導致系統(tǒng)狀態(tài)的估計精度下降。變結(jié)構(gòu)多模型算法針對更加復(fù)雜的目標運動狀態(tài),能夠在不增加計算復(fù)雜度的情況下提高系統(tǒng)性能[17]。由于煤層復(fù)雜的組成成分以及機體的自身振動,導致采煤機在切割過程中的系統(tǒng)噪聲呈現(xiàn)時變特點,變結(jié)構(gòu)多模型估計算法能全面地描述不同開采工序下的采煤機系統(tǒng)模型參數(shù),提高采煤機的導航定位精度[18,19]。但目前仍然沒有有效理論指導模型集的設(shè)計,不能保證模型切換的時效性和正確率。
因此,本文針對井下復(fù)雜的振動環(huán)境,設(shè)計了基于變結(jié)構(gòu)多模型的定位方案。對傳統(tǒng)基于后驗概率進行模型切換的模型識別算法進行改進,提出了基于支持向量機(Support Vector Machine, SVM)和極限學習機(Extreme Learning Machine, ELM)相結(jié)合的雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識算法。實現(xiàn)快速準確的最佳模型集選擇以及模型集的激活和終止。相較于傳統(tǒng)模型集在線選擇算法[20]具有更快的模型切換效率和更高的準確性,提高了井下復(fù)雜環(huán)境慣導/里程計組合導航的定位精度。
1 慣導/里程計井下定位方案
綜合機械化采煤是一種利用機械化和自動化設(shè)備進行采煤工作的過程。設(shè)備主要包括常用的滾筒式采煤機、刮板輸送機和液壓支架,通過三者之間的緊密配合,實現(xiàn)破煤、運煤和支護任務(wù),具體結(jié)構(gòu)如圖4所示。綜合機械化采煤切割面大約有200-450 m寬,長度可以達到5 km,采煤機每次大約切割0.8 m厚的煤層,每次采煤機開機進行煤炭切割,都需要切割數(shù)百米的煤層,時間長達數(shù)小時。采煤機在開采過程中存在靜止、前進、倒退等不同的運動狀態(tài),對應(yīng)著不同的切割過程。由于采煤機切割過程中煤層成分的不確定導致截割部的受力變化,采煤機工作過程中會產(chǎn)生不同程度的機械振動,導致器件時變誤差特性時變。

圖4 綜合機械化采煤切割面結(jié)構(gòu)Fig.4 Structure of fully mechanized coal mining face
井下惡劣環(huán)境對于傳感器的選擇提出了苛刻的要求。需要在能夠保證井下安全的基礎(chǔ)上,提供可靠的導航信息。其中,無線電定位容易在巷道中產(chǎn)生多路徑和非視距效應(yīng),甚至信號被完全遮擋。視覺傳感器和激光雷達等主動傳感器容易被粉塵、泥漿等環(huán)境影響,可靠性和精度難以保證,因此并未得到廣泛應(yīng)用。
慣導系統(tǒng)更新頻率快,短時精度高,能夠獲得采煤機三維的速度、位置和姿態(tài)。里程計受采煤機振動的影響小,誤差的發(fā)散特性與其運動距離相關(guān),適合采煤機這種工作時間長,運動相對較慢的載體,能夠在較長時間保持較高的定位精度。基于卡爾曼濾波的慣導/里程計組合導航方案被廣泛應(yīng)用于井下采煤機定位。由于沒有考慮采煤機開采過程的時變噪聲對組合導航精度帶來的影響,導致采煤機的定位精度難以滿足實際的工程需求。綜上,本文設(shè)計了基于雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的慣導/里程計井下融合方案,綜合機械化采煤結(jié)構(gòu)和組合方案如圖5所示。

圖5 綜合機械化采煤導航系統(tǒng)結(jié)構(gòu)和組合方案Fig.5 Structure and combination scheme of the navigation system for fully mechanized mining
2 基于雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的改進變結(jié)構(gòu)多模型方法
傳統(tǒng)的模型集切換方法通常采用可能模型集算法(Likely Model Set, LMS)以及模型組切換算法(Model Group Switching, MGS),其中現(xiàn)有模型選擇策略較多,但沒有一種經(jīng)典理論指導模型集合的在線選擇,模型集自適應(yīng)選擇正確率和時效性不能得到保證。傳統(tǒng)算法為了盡量保證模型參數(shù)的匹配,會傾向于選擇模型較多的集合,因此這種模型集選擇的取向會在狀態(tài)估計和基于新激活的模型的濾波器的協(xié)方差中帶入誤差,導致濾波精度下降[20]。本文結(jié)合井下采煤工作時的運動特性,通過對可能模型集算法的改進,提出了基于雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的改進變結(jié)構(gòu)多模型方法,具體結(jié)構(gòu)如圖6所示。

圖6 基于雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的變結(jié)構(gòu)多模型框架圖Fig.6 Block diagram of Two-Layer Network Identification based Variable Structure Multi-Model
2.1 基于雙層神經(jīng)網(wǎng)絡(luò)的多模型參數(shù)辨識算法
系統(tǒng)噪聲的模型參數(shù)隨著采煤機的不同運動狀態(tài)產(chǎn)生相應(yīng)的變化,因此我們根據(jù)采煤機的切割、倒車和停止等多個狀態(tài)下的系統(tǒng)模型進行分類,這類系統(tǒng)噪聲之間的區(qū)別明顯,單層的神經(jīng)網(wǎng)絡(luò)分類算法可以較為準確的識別。但即使處在同一運動狀態(tài)下時,采煤機的振動變化會導致系統(tǒng)模型發(fā)生改變,這種變化相對于不同運動狀態(tài)下采煤機系統(tǒng)噪聲尺度變化小。當這些不同級別的系統(tǒng)噪聲全部用于對單層的神經(jīng)網(wǎng)絡(luò)分類算法的訓練時,由于不同數(shù)量級辨識的尺度不同,模型參數(shù)辨識的精度出現(xiàn)了明顯的下降,存在同量級的模型噪聲混淆的問題。為了提高模型的辨識精度,提出一種將SVM和ELM結(jié)合的雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識算法。

圖7 采煤機開采噪聲模型雙層神經(jīng)網(wǎng)絡(luò)辨識算法Fig.7 Two-layer neural network identification algorithm for mining noise model of shearer
雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識算法包括兩層分類處理,兩層分類依次銜接,構(gòu)成了針對噪聲量級的初步辨識和同一量級的細分辨識,構(gòu)成完整噪聲模型識別方案。大尺度粗辨識數(shù)據(jù)量較大,一旦出現(xiàn)辨識錯誤將影響后續(xù)的第二層辨識,因此需要足夠的穩(wěn)定性。考慮到增加辨識層會導致系統(tǒng)計算量的增加,第二層神經(jīng)網(wǎng)絡(luò)分類算法應(yīng)當具備較快的辨識速度,從而保證系統(tǒng)的實時性。本文針對大尺度粗辨識的穩(wěn)定性以及小尺度精辨識的小樣本特點,首先利用SVM識別噪聲所屬量級,然后針對已經(jīng)根據(jù)運動狀態(tài)分類的同一數(shù)量級特征采用相應(yīng)的ELM分類模型進行具體的噪聲模型識別。
SVM算法本質(zhì)是在樣本空間中找到一個超平面,將不同類別的樣本分開。通過找到“最大間隔”超平面,使得分類結(jié)果具有魯棒性,泛化性能最好,同時分類性能穩(wěn)定。首先假設(shè)分離超平面為:

點到平面距離為:

其中<w,x>為向量點積,當兩類樣本線性可分時,設(shè)滿足以下條件:

假設(shè)兩個平行超平面H1和H2作為間隔邊界以判斷樣本分類:

超平面H1和H2到原點的距離分別為和因此H1和H2的間距為時,分類間隔最大就是使最小,即:

其中w為法向量,ωs決定了超平面的方向,bs為位移項,ωs通過和sb確定劃分超平面。對于提取的慣導數(shù)據(jù)特征,采用SVM進行初步分類。將多分類簡化為多個二分類,采用的輸出為0、1輸出。
第二層模型參數(shù)辨識網(wǎng)絡(luò)通過ELM與上層辨識結(jié)構(gòu)相連,其模型如圖8所示,通過隨機初始化單隱層神經(jīng)網(wǎng)絡(luò)的輸入權(quán)重和偏置得到相應(yīng)的輸出權(quán)重,具有學習速度和運算速度快的優(yōu)勢,適合處理小樣本數(shù)據(jù)。
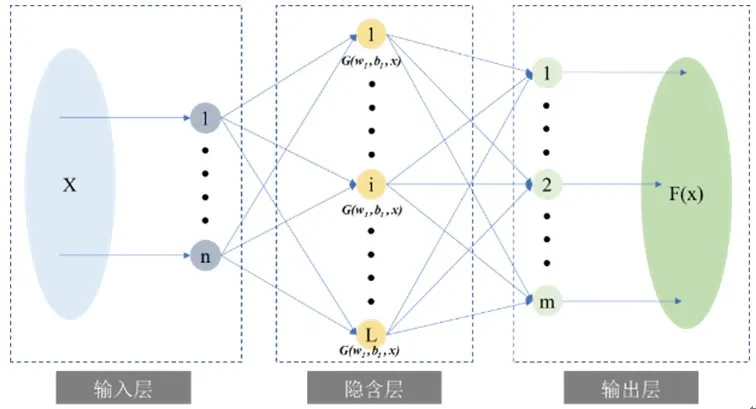
圖8 極限學習機結(jié)構(gòu)圖Fig.8 Structure diagram of extreme learning machine
針對已經(jīng)由上層辨識網(wǎng)絡(luò)獲得的不同數(shù)量級噪聲,訓練多個獨立的分類模型。對于上述的每一個類別,給定采集的N個訓練樣本(XNN,TNN) = {(xi,ti),i=1,2...N},此處XNN為提取的噪聲特征矩陣,TNN為對應(yīng)的期望輸出,N為該類別輸入的樣本個數(shù),xi=[xi1,xi2,...,xin]T表示XNN中的第i個樣本,n為輸入的樣本維,ti=[ti1,ti2,...,tim]T表示第i個樣本的對應(yīng)輸出,m表示輸出的向量維(與噪聲類別相同)。在本文中,期望輸出向量采用0、1標記方式標定,即樣本屬于第幾類噪聲模型,則將期望輸出向量位置中的第幾位標記為"1",其余位全均記為"0"。設(shè)單隱層神經(jīng)網(wǎng)絡(luò)的隱含層有L個節(jié)點,其輸出為:

其中,ωi為連接輸入神經(jīng)元與第i個隱含層節(jié)點的權(quán)向量,bi為第i個隱含層節(jié)點的偏置,βi是第i個隱含層節(jié)點的輸出權(quán)向量,g()·為激活函數(shù)。因此,可將式(8)簡化成:

其中,H是隱層節(jié)點的輸出,β為輸出權(quán)重,O為單隱層神經(jīng)網(wǎng)絡(luò)的輸出。
ELM的學習目標是通過最小化預(yù)測誤差損失函數(shù)之和來求解輸出權(quán)重,其運用最小范數(shù)得到最小誤差解:

因此根據(jù)上述公式可以推導出隱含神經(jīng)元與輸出神經(jīng)元的輸出權(quán)值矩陣最優(yōu)解:

其中H+是矩陣H的摩爾-彭羅斯廣義逆。通過雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識獲得當前運動狀態(tài)的模型參數(shù),從模型庫中選取與該參數(shù)標準差最小的多個模型組成模型集合帶入變結(jié)構(gòu)多模型算法,對當前采煤機的運動狀態(tài)進行估計。
根據(jù)數(shù)據(jù)特征構(gòu)建的雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識充分利用不同神經(jīng)網(wǎng)絡(luò)分類算法的優(yōu)勢,解決了傳統(tǒng)模型自適應(yīng)完全依賴于后驗概率模型導致的模型切換準確性和實時性難以保證的問題,能夠有效避免模型誤匹配帶來的濾波器發(fā)散。同時相較于單層模型參數(shù)辨識神經(jīng)網(wǎng)絡(luò),提高了小尺度模型之間的辨識精度,兼顧了多層神經(jīng)網(wǎng)絡(luò)的辨識效率。
2.2 基于模型參數(shù)辨識的改進變結(jié)構(gòu)多模型算法
2.2.1 系統(tǒng)及量測模型構(gòu)建
本文基于東北天導航坐標系來討論。為了描述采煤機的運動狀態(tài)和慣性儀表誤差以及里程計標度因數(shù)誤差,考慮狀態(tài)量設(shè)置如下:
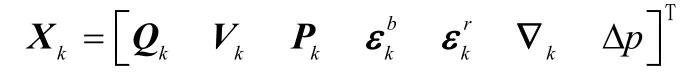
其中,Qk= [q1(k)q2(k)q3(k)q4(k)]為k時刻姿態(tài)四元數(shù),為k時刻載體東向、北向及天向速度;Pk=[λ(k)L(k)h(k)]分別是經(jīng)度、緯度和高度,和分別為3個軸向的陀螺儀的隨機常值零偏和一階馬爾可夫隨機噪聲,分別為3個軸向加速度計的一階馬爾可夫隨機噪聲,pΔ是里程計的標度因數(shù)誤差。
里程計每個采樣周期輸出的量測量如下:
對ITC數(shù)據(jù)進行切片,采用MATLAB對其進行可視化,得到網(wǎng)絡(luò)快照集合{G1,G2,…,Gn},G1表示初始時刻的網(wǎng)絡(luò)拓撲圖,G2表示時隔一個切片時長后的拓撲圖,依次類推,Gn表示最后一張拓撲圖,其演化過程如圖4 (a)~(c)所示.

里程計的位置遞推公式如下:

其中,Mk和Mk-1分別是k和k-1時刻的脈沖數(shù),Pk和Pk-1為k和k-1時刻導航系下采煤機的位置,為k-1時刻的姿態(tài)轉(zhuǎn)移矩陣,p為里程計的標度因數(shù),Δp是標度因數(shù)誤差。濾波時將導航系下的預(yù)測位置轉(zhuǎn)化為地心地固坐標系下的經(jīng)度、緯度和高度。本文采用直接法進行擴展卡爾曼濾波,狀態(tài)方程和量測方程構(gòu)建可以參考文獻[21]。
2.2.2 變結(jié)構(gòu)多模型算法
從量測模型可以看出,里程計的位置精度不僅取決于自身輸出,也受到載體姿態(tài)的影響。其中,航向角對里程計水平位置輸出的精度有直接影響。當系統(tǒng)噪聲模型和量測噪聲模型不準確時,系統(tǒng)難以準確估計預(yù)測和量測的誤差水平,使系統(tǒng)狀態(tài)估計精度下降,同時將不準確的航向信息再耦合進里程計量測中,導致量測的精度也難以保證。因此建立多個系統(tǒng)模型達到逼近實際模型的目的,有效降低了濾波器對系統(tǒng)數(shù)學模型的依賴性,有利于提高組合導航系統(tǒng)的濾波精度。
變結(jié)構(gòu)多模型算法能夠在沒有準確系統(tǒng)模型和先驗知識的情況下通過多個模型之間的自適應(yīng),避免模型失配導致濾波器發(fā)散。變結(jié)構(gòu)多模型由多個并行的擴展卡爾曼濾波器組成,根據(jù)模型集自適應(yīng)算法選出當前適合的模型集,將最優(yōu)模型集帶入濾波器,通過不同濾波器之間的殘差和方差獲得對應(yīng)模型的似然函數(shù)即條件概率密度函數(shù),進而通過貝葉斯公式計算各個模型的概率。最后將上一時刻的狀態(tài)估計和模型概率轉(zhuǎn)化為權(quán)重,初始化當前狀態(tài)及其協(xié)方差陣。具體計算步驟如下所示。
(1) 交互輸入
利用上一個周期的狀態(tài)和模型轉(zhuǎn)移概率獲得當前時刻的交互輸入,初始模型轉(zhuǎn)移概率為:
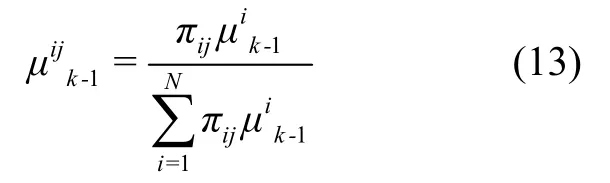
根據(jù)模型條件轉(zhuǎn)移概率重新初始化模型j的狀態(tài)與協(xié)方差陣為:

(2) 模型濾波
根據(jù)上述擴展卡爾曼濾波的過程,帶入辨識后的噪聲模型,計算模型的濾波殘差和方差:
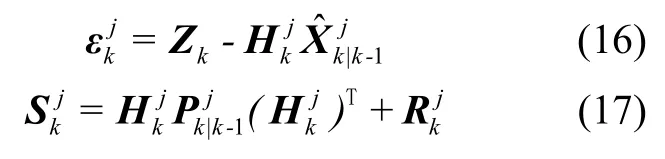
(3) 模型概率更新
根據(jù)假設(shè)檢驗原理,如果統(tǒng)計模型與實際模型匹配,則濾波殘差服從零均值高斯分布,由此獲得該模型的似然函數(shù)為:

模型概率可更新為:

其中,πij表示先驗的Markov模型轉(zhuǎn)移概率,為k-1時刻i模型的概率。
當模型檢測算法檢測到模型需要切換后,在當前運行模型中引入新的模型,重新分配新舊模型的權(quán)重,運行兩個模型集的并集。計算新模型集合和舊模型集合的概率,當新模型概率占總模型概率達到一定閾值時,丟棄舊模型,繼續(xù)運行新模型,通常閾值稍小于1,防止模型的直接切換可能帶來的模型跳變。最后對每個模型的濾波狀態(tài)進行加權(quán),獲得全局的狀態(tài)估計。
3 仿真與分析
3.1 參數(shù)設(shè)置
為了驗證本文提出的算法性能,通過MATLAB對算法進行仿真。平臺搭載intel i7 8700k處理器,主頻3.7 Ghz。根據(jù)采煤的實際工況,將其開采流程分為3個步驟。首先是對工作面的水平切割,隨后進行斜切進刀工序,進刀距離1 m,進刀完成后切割三角煤,重新回到端頭進行下一次的切割。但在切割過程中可能由于煤層中的雜質(zhì)等影響,導致采煤機暫停切割和倒退。每個工序根據(jù)采煤機與煤層接觸所產(chǎn)生振動情況設(shè)計相應(yīng)的模型噪聲以及采煤機可能的實際運動狀態(tài)進行仿真,仿真?zhèn)鞲衅髦饕ǜ呔葢T導系統(tǒng)和里程計。慣導系統(tǒng)的解算周期是0.02 s,里程計的解算周期是1 s,濾波周期與里程計解算周期相同。仿真軌跡按照實際可能的采煤機運動狀態(tài)進行模擬。在煤炭切割狀態(tài)速度為0.1 m/s,進刀狀態(tài)按照0.01 m/s。采煤機沿400 m切割面做往復(fù)運動,每次切割完畢向煤層推進0.9 m。全程共用4.4 h。變結(jié)構(gòu)多模型算法模型集合切換閾值設(shè)置為0.8,初始馬爾可夫轉(zhuǎn)移概率設(shè)置為:

真實運動軌跡設(shè)計如圖9所示,傳感器參數(shù)和多模型算法參數(shù)如表1所示。

表1 傳感器參數(shù)設(shè)置Tab.1 Parameters setting of sensors
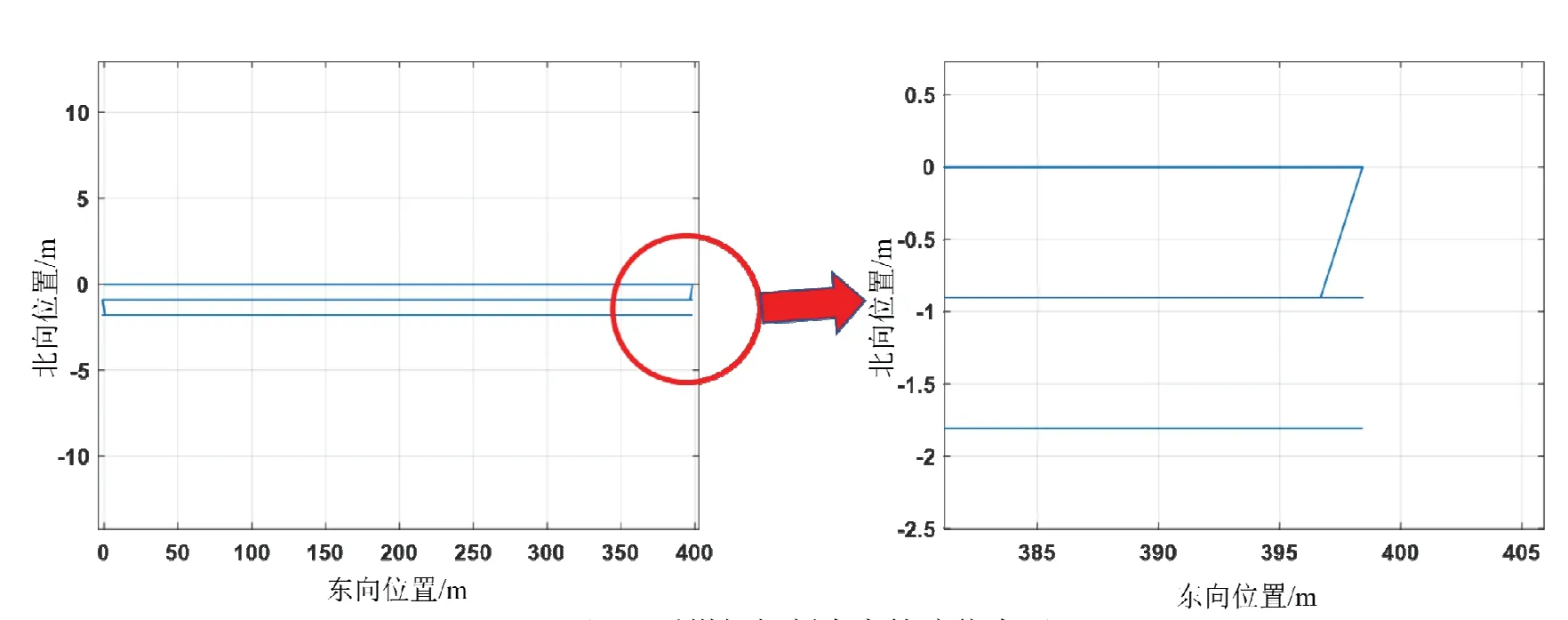
圖9 采煤機切割真實軌跡仿真圖Fig.9 Simulation diagram of the real trajectory of shearer cutting
3.2 雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識精度分析
為驗證雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的正確率和辨識精度。仿真4組不同的采煤機完整開采過程的慣導/里程計輸出,并且根據(jù)切割狀態(tài)對數(shù)據(jù)進行分割,共分成4種不同工作模式下的11種噪聲模型,將各類模型下的慣導/里程計輸出標準差、方差、最大值和極差作為數(shù)據(jù)并添加多分類模型標簽進行依次訓練。
針對訓練好的雙層神經(jīng)網(wǎng)絡(luò),重新仿真4組完整采煤機開采的慣導和里程計輸出作為測試集并且根據(jù)采煤機的實際工作狀態(tài)添加相應(yīng)模型分類標簽進行識別,將識別結(jié)果和添加的標簽進行對比,對比結(jié)果如表2所示。本文所提出的算法在模型切換時達到98%以上的識別率,相較于僅通過單層網(wǎng)絡(luò)辨識提高了12%以上的識別準確率,因此通過雙層辨識神經(jīng)網(wǎng)絡(luò)有效提高了系統(tǒng)的辨識精度。

表2 算法的辨識精度對比Tab.2 Comparison of the identification accuracy of algorithms
3.3 改進變結(jié)構(gòu)多模型定位精度分析
將訓練好的雙層神經(jīng)網(wǎng)絡(luò)用于變結(jié)構(gòu)多模型算法的模型參數(shù)辨識。為了驗證算法的實際融合效果,與傳統(tǒng)的交互多模型算法(Interacting Multiple Model,IMM)進行對比。根據(jù)仿真所設(shè)計的采煤機運動狀態(tài),設(shè)計了多分類模型下慣導/里程計的噪聲模型參數(shù),構(gòu)建了多分類模型庫,如表3所示。每個多分類模型中設(shè)計了具體模型參數(shù),分別對應(yīng)變結(jié)構(gòu)多模型算法中設(shè)計的4個濾波器噪聲信息。

表3 多分類模型庫設(shè)計Tab.3 Design of multi-classification model library
由于井下里程計受振動的影響較小,在采煤機運動方向上的誤差可以得到抑制,而航向完全基于陀螺儀輸出,陀螺系統(tǒng)噪聲的設(shè)置精度尤為重要,因此本文在多分類模型中構(gòu)建了更多噪聲模型進行匹配。
圖10是不同算法和真值的軌跡對比,可以看出本文算法的軌跡精度顯著高于傳統(tǒng)IMM算法。圖11、圖12和圖13分別對比了兩種算法的東向位置誤差、北向位置誤差和航向角誤差。結(jié)合表4可以得到以下結(jié)論:IMM算法由于在較多模型集合的選擇中不能分配較為精準的權(quán)重,系統(tǒng)模型參數(shù)失配,導致濾波精度不高。相較于傳統(tǒng)算法,本文所提出算法憑借可靠的模型參數(shù)辨識,獲得了明顯的井下定位、定向精度提升。其中,本文所提算法的東向位置誤差均方差為1.15 m,北向位置誤差均方差為2.44 m;傳統(tǒng)IMM算法的東向位置誤差均方差為1.55 m;北向位置誤差均方差為4.54 m,有效抑制了由于振動噪聲導致的航向發(fā)散,航向精度提升42%,東向精度提升26%,北向精度提升46%,水平精度總體提升43%。另外,通過多組仿真,得到本文算法單次信息融合平均解算時間耗時為0.86 ms,傳統(tǒng)IMM算法的平均解算時間為2.75 ms。值得注意的是,采煤機在切割過程中航向誤差存在4處比較明顯的跳變,這是由于采煤機在切割到工作面端頭后進行斜切進刀過程中航向明顯變化導致。綜上,本文算法相較于傳統(tǒng)的IMM算法提高了井下采煤機在不同運動階段慣導/里程計的融合的定位精度,同時保證了解算效率。

圖10 不同算法的自主導航定位精度對比Fig.10 Comparison of different algorithms

圖11 東向位置誤差對比Fig.11 Comparison of east position error

圖12 北向位置誤差對比Fig.12 Comparison of north position error
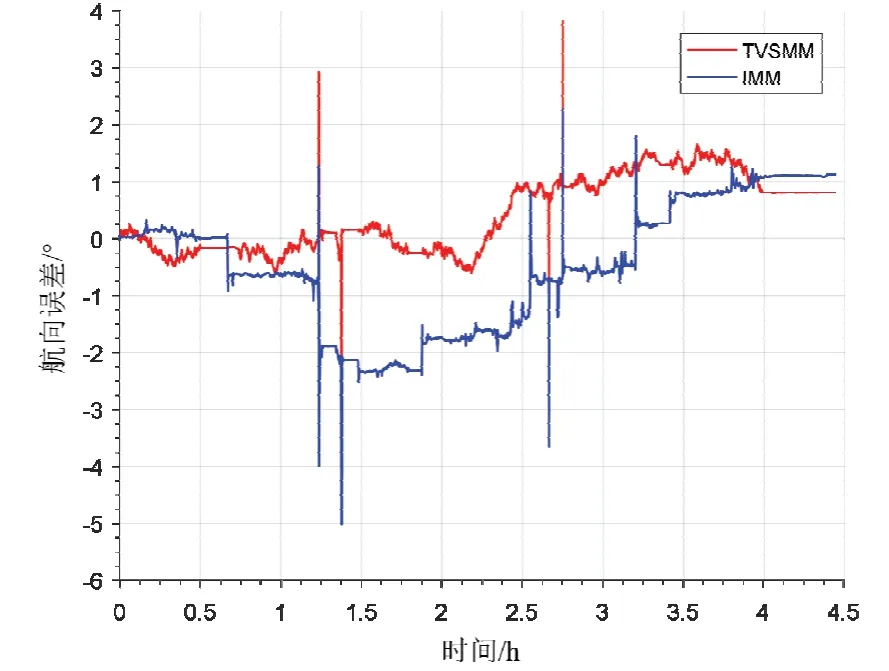
圖13 航向誤差對比Fig.13 Comparison of heading error

表4 算法定位精度對比Tab.4 Comparison of positioning accuracy of algorithms
4 結(jié) 論
本文針對井下采煤機采煤過程中的復(fù)雜運動狀態(tài),基于高精度慣導系統(tǒng)和里程計設(shè)計了一種基于雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識的變結(jié)構(gòu)多模型導航算法。利用慣導仿真數(shù)據(jù)針對不同運動模型的特征進行訓練,通過對數(shù)據(jù)分割與截取、特征建模、機器學習策略的研究,實現(xiàn)在采煤機運動模型在運動狀態(tài)變化時的精準切換。該算法不依賴于后驗概率,具有較快的模型切換的速度。通過變結(jié)構(gòu)多模型與雙層神經(jīng)網(wǎng)絡(luò)模型參數(shù)辨識算法的結(jié)合,解決了在GNSS拒止的復(fù)雜環(huán)境下時變系統(tǒng)的高精度定位問題。仿真結(jié)果表明,相較于傳統(tǒng)多模型導航算法,本文所提出算法能夠有效應(yīng)對復(fù)雜、時變的井下振動環(huán)境,實現(xiàn)了實時、高精度的導航定位。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
防爆電機(2022年1期)2022-02-16 01:14:06
河北畫報(2021年2期)2021-05-25 02:07:50
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
山西大同大學學報(自然科學版)(2016年2期)2016-12-12 03:19:28
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年18期)2014-02-27 14:14:58
河南科技(2014年4期)2014-02-27 14:07:18
