利用高斯徑向基函數的擬神經網絡重力反演方法
2021-12-06 02:49:58譚紹泉陳學國
石油地球物理勘探 2021年6期
相 鵬 譚紹泉 陳學國 劉 佳
(①中國石化勝利油田分公司勘探開發研究院,山東東營 257000;②中國石化勝利油田分公司石油開發中心,山東東營 257000)
0 引言
重力反演作為一種重要的定量解釋手段,可以得到地下的密度分布特征,為地質解釋提供支持。然而,重力反演的垂向分辨率低、多解性強,制約了其在高精度勘探領域中的應用。上述問題的根本原因在于重力反問題的不適定性。首先,重力資料采集密度低,數據量小,而高分辨率反演需要對地下半空間進行精細的網格剖分,使網格數量(即反演的未知參數數量)遠大于數據數量,導致反演方程組嚴重欠定;其次,重力正演核函數隨深度加大而迅速衰減,淺層網格的核函數與深層網格的核函數之間相差多個數量級,反演方程組穩定性差,當反演方程組欠定時,反演結果趨膚。因此,反演結果會被重力數據噪聲、網格剖分誤差和計算誤差等嚴重污染,分辨率和可靠性均低。
目前,基于廣義線性反演理論的重力反演方法已經取得了大量的研究成果,這些方法可大致分為三類。
第一類方法通過增加重力數據數量,改善反演方程組的欠定性。有學者提出了等維反演方法[1-2],綜合利用不同高度上的位場數據聯合反演,在一定程度上能解決重磁位場反演的“上漂”問題,提高重磁位場異常反演的垂向分辨率。近年來,隨著航空重力梯度技術的發展,產生了利用重力梯度張量數據的反演方法[3-4]。另外,還有利用井中重力數據或者重力梯度數據聯合地面重力數據反演的方法[5-7]。
第二類方法主要是通過核函數處理以改善反演方程組的適定性。目前,大部分反演方法都可歸為該類方法。其中,用深度對核函數加權[8]是最具有代表性和影響力的方法,這種方法能夠有效解決反演趨膚的問題。同時,多種與之類似的不同加權方法也被提出[9-10]。此外,各種約束類反演方法,如聚焦約束、平滑約束和先驗模型約束等方法[2,6,11-13]也被歸為第二類。因為約束方程的加入,可被看作是一種對正演核函數矩陣進行行擴展的處理方式。
第三類方法主要是利用某種函數作為密度函數代替離散化的密度模型矢量,減少反演參數數量,從而改善反演方程組的適定性。該類方法通常要求根據密度函數具體形式推導不同的正演公式。近年來,在重磁正演領域已經出現了大量研究成果,可以實現復雜形體的不同形式密度函數的變密度正演[14-16],但目前這些成果在反演領域的應用較少。劉潔等[17]利用高階多項式作為密度函數實現了重力反演,但是多項式函數是連續平滑的,模型表達能力有限,而表達能力強的密度函數,其正演公式往往推導難度大,甚至無法推導解析公式。為了解決復雜函數形式正演公式推導難的問題,Tontini 等[18]仍采用核函數矩陣,利用高斯函數生成模型矢量,提出了一種高斯包絡磁力反演方法。該方法雖然沒有對正演公式進行改進,但是與現在機器學習領域的壓縮感知[19-20]和字典學習等技術[21-22]的核心思想有著異曲同工之處。
與廣義線性反演不同,基于神經網絡的重力反演方法是一種非線性反演方法[23-24]。此類方法的特點在于采用分層結構,網絡結構清晰,神經元節點采用感知機模型,反向傳播訓練算法易于實現,魯棒性強。神經網絡反演方法分為訓練和預測兩個步驟,通過樣本數據集(重力場—密度模型對)訓練神經網絡,建立重力場和對應模型的非線性映射關系;再在預測步驟里將實測重力場輸入,神經網絡輸出預測密度模型,即反演結果。基于神經網絡的重力反演方法存在以下幾個方面的問題:第一,建立訓練數據集困難,訓練數據集中需要包含大量不同類型的模型和重力場,否則,實用效果大打折扣,而設計不同的模型并計算其重力場工作量巨大;第二,基于感知機模型的單隱層神經網絡非線性映射能力弱,難以解決復雜非線性問題,使用深層網絡則存在過擬合、梯度消失、梯度爆炸等問題,訓練困難;第三,神經網絡隱層可解釋性差,尤其是深層神經網絡,每層對應的物理意義不明確。針對神經網絡存在的問題,有學者提出了擬神經網絡的反演方法[25-26]。模擬神經網絡的分層結構,但不需要樣本數據集訓練,且網絡層具有較好的可解釋性。但是,前人提出的擬神經網絡各層定義不清晰,層間耦合嚴重,神經元多采用Sigmoid激活函數,模型表達能力弱。
本文在梳理了大量已有的重力反演方法基礎上,提出了一種利用徑向基函數(Radial Basis Function,RBF)的擬神經網絡重力反演方法。該方法利用高斯徑向基函數壓縮模型空間,在保證復雜模型表達能力的前提下,實現反演參數的降維;提出一種擬神經網絡結構,不需要訓練樣本標簽,可以克服建立訓練數據集的困難。理論模型試算和實際資料應用表明,基于該網絡結構實現的重力反演提高了垂向分辨率,同時增強了可靠性,并且具有較強的抗噪能力。
1 方法原理
1.1 高斯徑向基函數
徑向基函數是沿徑向對稱的標量函數,通常被定義為空間中任一點到某一中心點之間歐氏距離的單調函數。其作用往往是局部的,即當空間某點遠離中心點時,函數取值很小,調整局部函數值大小和作用范圍可以靈活地擬合復雜函數。本文采用最常用的高斯徑向基函數,它在計算機視覺、人工智能、圖像壓縮和數據擬合等領域有著廣泛的應用。其三維公式為
(1)
式中:(x,y,z)是網格中心坐標;(μx,μy,μz)是徑向基函數中心坐標;δx、δy、δz是徑向基函數分布半徑。二維公式則為
(2)
根據高斯函數擬合原理[27],密度模型可以表示為多個不同振幅的高斯函數的疊加求和,即
(3)
式中:NG是高斯徑向基函數個數;Wi是第i個高斯徑向基函數的振幅。高斯徑向基函數具有很強的模型表達能力,使用遠少于剖分網格個數的高斯徑向基函數就可以對復雜模型進行較高精度地擬合。對于圖1a復雜模型,分別使用不同數量的高斯徑向基函數擬合,效果如圖1b~圖1d所示。由圖可見,當僅用25個高斯徑向基函數擬合模型時,盡管分辨率較低,但已經能較好地恢復模型的背景;隨著高斯徑向基函數數量的增加,越來越多的模型細節被恢復。為保證反演方程組不欠定,用于表示密度模型的高斯徑向基函數的數量理論上應該滿足ND/NG≥5(二維反演)和ND/NG≥7(三維反演),其中ND是重力數據的數量。但是,后文中模型試驗和實測資料反演結果表明,ND/NG低于上述比例時亦可獲得較好效果。
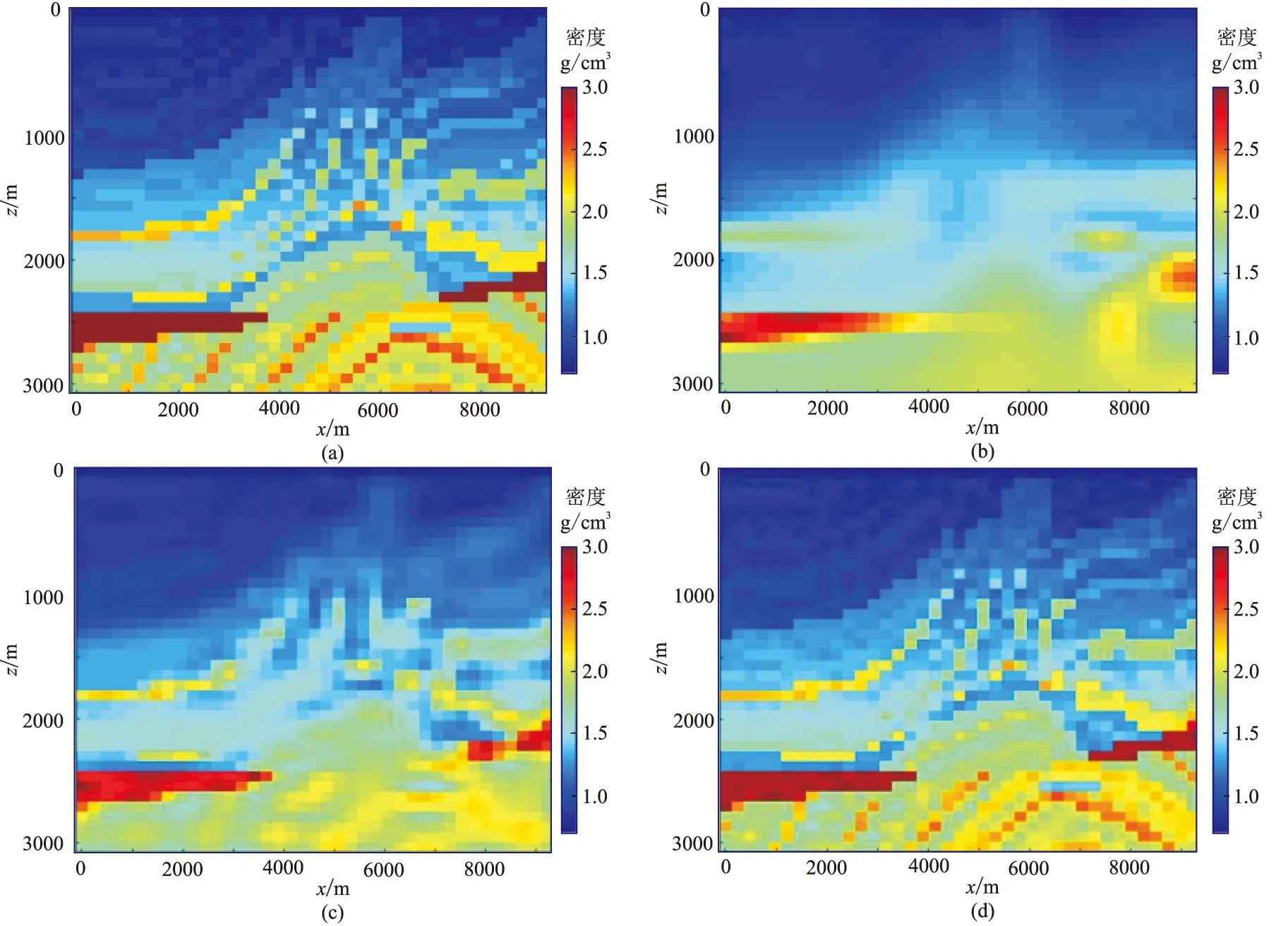
圖1 復雜模型(a)及25(b)、100(c)、400(d)個高斯徑向基函數的擬合結果
1.2 基于高斯徑向基函數的重力正演公式
本文采用常密度立方體重力公式[28]作為正演公式,即
g=Kρ
(4)
式中K是核函數矩陣,即
(5)
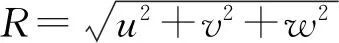
(6)
由于高斯徑向基函數是徑向基函數中心和分布半徑的非線性函數,因此重力正演公式由線性變成了非線性,反演參數由網格密度變成了徑向基函數的振幅W、中心(μx,μy,μz)和半徑(δx,δy,δz)。式(6)仍然保留正演核函數矩陣,與采用g=f(m)形式的正演公式相比,具有以下優點。
正演核函數矩陣僅是觀測點和網格坐標的函數,與密度解耦,在反演過程中只需計算一次,因而避免了計算量最大部分的重復計算。每次迭代只需計算高斯徑向基函數生成密度矢量,增加的計算量很小,而不能將密度解耦的非線性正演公式在每次迭代時,都需要進行計算量巨大的正演和靈敏度矩陣計算。
式(6)的形式與壓縮感知理論有著很好的對應關系。其中,核函數矩陣對應測量矩陣,高斯徑向基函數生成稀疏基矩陣,高斯徑向基函數的振幅對應稀疏系數。因此,可借鑒、應用壓縮感知的相關理論和技術。當固定徑向基函數的中心和半徑而只是反演振幅時,可利用壓縮感知的稀疏性原理實現稀疏約束反演,經典算法有OMP[29]和LASSO算法[30];當同時反演徑向基函數的振幅、中心和半徑時,可以利用字典學習技術中經典的MOD[31]和KSVD算法[21]快速實現。
1.3 基于高斯徑向基函數的擬神經網絡
在定義了基于高斯徑向基函數的重力正演公式之后,本文提出了一種如圖2所示的擬神經網絡結構。該網絡由輸入層、徑向基函數層、權重連接層和正演輸出層組成。其中,徑向基函數層的節點為高斯徑向基函數,權重連接層的節點為高斯徑向基函數振幅,正演輸出層的節點為重力正演核函數。與傳統神經網絡相比,本文提出的擬神經網絡主要有以下幾點不同。
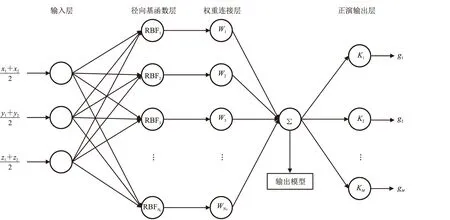
圖2 徑向基函數的擬神經網絡結構圖M為觀測點數量
(1)本文方法的輸入數據是模型網格中心的坐標,而傳統神經網絡重力反演方法中輸入數據通常為重力樣本數據集。
(2)本文方法的輸出數據是正演重力值,而傳統神經網絡重力反演方法中輸出數據通常為密度模型數據集。
(3)本文方法的損失函數是計算正演重力數據與實測重力數據之間的殘差,而傳統神經網絡重力反演方法中損失函數是計算預測密度模型與密度模型樣本之間的殘差。損失函數的不同決定了神經網絡各層的含義不同,本文擬神經網絡各層可解釋性清晰、明確,而傳統神經網絡中,若存在多個隱含層,則各層可解釋性不明確,只能將整個網絡解釋為重力正演函數的反函數。
(4)本文方法在訓練結束后,徑向基函數權重連接層的輸出即為最終反演結果,即密度模型。而傳統神經網絡重力反演方法中,先使用樣本數據集訓練神經網絡,再利用訓練后的神經網絡執行預測步驟,在網絡輸出層獲得最終反演結果。
2 理論模型測試
為了驗證本文方法的有效性,在文獻[32]中的實驗模型基礎上設計了三維組合模型。如圖3a所示,模型大小為9240m×9240m×3040m,模型網格剖分為15×15×10個小長方體。三個地質異常體(簡稱地質體)中,地質體1(黃色)的剩余密度為0.3g/cm3,尺寸為616m×6160m×608m,中心埋深為912m;地質體2(桔色)的剩余密度為0.4g/cm3,尺寸為3696m×3696m×1216m,中心埋深為2128m;地質體3(紅色)的剩余密度為0.5g/cm3,尺寸為2464m×1232m×1216m,中心埋深為1216m。地質體1和地質體2為垂向疊置。觀測系統范圍x方向為0~10000m,y方向為0~10000m,觀測點高度為0,每個方向均勻設置20個觀測點。正演重力場如圖3b所示。
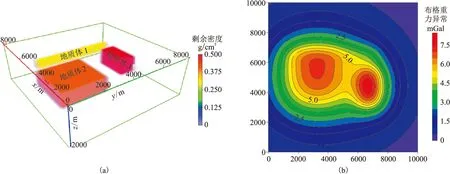
圖3 理論模型(a)及正演重力場(b)
實驗一采用與正演網格相同的剖分方案,即初始模型剖分為15×15×10個小長方體,徑向基函數中心初始設置為在地下剖分空間均勻分布,x方向5個,y方向5個,z方向5個,徑向基函數層共有5×5×5=125個節點,權重連接層初始權重均設為0,數據和徑向基函數數量的比值為ND/NG=3.2,學習率為0.1,最大訓練次數為2000,訓練精度為1×10-6,訓練算法為自適應距估計算法,反演結果如圖4所示。由圖可見,無井約束反演可以恢復地質體的形態(圖4左),其中,地質體1的邊界較為尖銳,與地質體2垂向疊加部分得到準確分離,但接近地質體3的部分較為模糊;地質體3的邊界非常清晰,但下界面偏淺;地質體2的頂界面較準確,但因為埋深加大,邊界較為模糊。有井約束反演可以使地質體1和2的邊界更加清晰(圖4右),地質體3的下界面更接近真實深度。實驗結果證明:由于反演參數的減少,在不施加任何約束的情況下,重力反演亦能獲得較高的橫向和垂向分辨率,垂向疊加的地質體能夠準確恢復;在施加先驗約束信息后,反演結果的橫向和垂向分辨率得以提高,地質體的邊界反演精度更高。
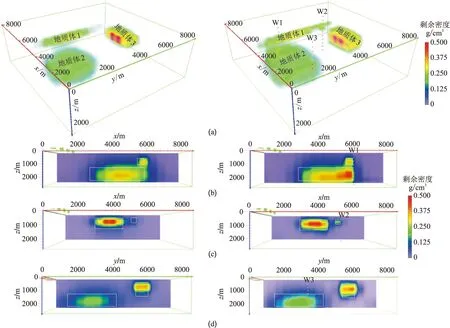
圖4 實驗一無井(左)和有井(右)約束反演結果(a)重力反演結果;(b)過W1井的x方向反演剖面;(c)過W2井的x方向反演剖面;(d)過W3井的y方向反演剖面。三口井坐標分別為(6450m,2770m)、(6450m,6450m)和(3380m,3380m),圖5同
實驗二的初始模型剖分為31×31×21個小長方體,對重力異常添加3%的白噪聲,模擬在反演實測重力時存在網格剖分誤差和數據噪聲的情況,其他參數設置與實驗一相同。反演結果如圖5所示。由圖可見,無井約束反演結果橫向和垂向分辨率遠低于圖4(圖5左)。除網格剖分誤差和數據噪聲外,網格剖分數量是造成分辨率下降的主要原因。實驗二的網格數量是實驗一的8倍多,導致正演核函數矩陣的性狀(條件數、列相關性)變差。盡管反演參數數量沒有變化,但是在殘差反向傳播過程中,受到正演核函數矩陣性狀變差的影響,反演分辨率下降。有井約束反演結果橫向和垂向分辨率提高很大(圖5右),除了地質體1與地質體3相鄰處和地質體3的下界面有些模糊外,整體反演效果甚至優于圖4中的約束反演,尤其是地質體2不僅與垂向疊加的地質體1準確分離,而且邊界更接近真實模型。實驗結果說明:在無約束信息時,模型網格剖分數量不宜過多;但是加入少量先驗約束信息,即使在正演核函數矩陣性狀很差時(即網格數量遠大于重力數據數量時),仍可以得到較理想的反演結果。本文方法能夠充分利用先驗信息的約束作用,并具有良好的抗噪性能。
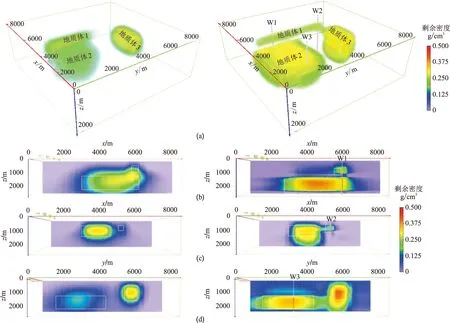
圖5 實驗二無井(左)和有井(右)約束反演結果(a)重力反演結果;(b)過W1井的x方向反演剖面;(c)過W2井的x方向反演剖面;(d)過W3井的y方向反演剖面
3 實際資料應用
為檢驗方法的實用性,對車鎮凹陷的重力資料進行反演,開展古潛山和洼陷的識別。
渤海灣盆地是疊置在華北克拉通基底之上的中、新生代斷陷盆地,濟陽坳陷是渤海灣盆地的坳陷之一,依據地層與潛山的關系大致可以將地層劃分為兩個構造層,即潛山內幕層和蓋層。潛山內幕層由魯西地塊的基底、太古界泰山群、古生界和中生界組成;蓋層由古近系孔店組、沙河街組、東營組和新近系館陶組、明化鎮組及第四系平原組組成。車鎮凹陷是濟陽坳陷最北部的一個凹陷,南北夾于義和莊凸起與埕子口凸起之間,西為慶云凸起,地表為第四系覆蓋。該區地層密度特征如表1所示。
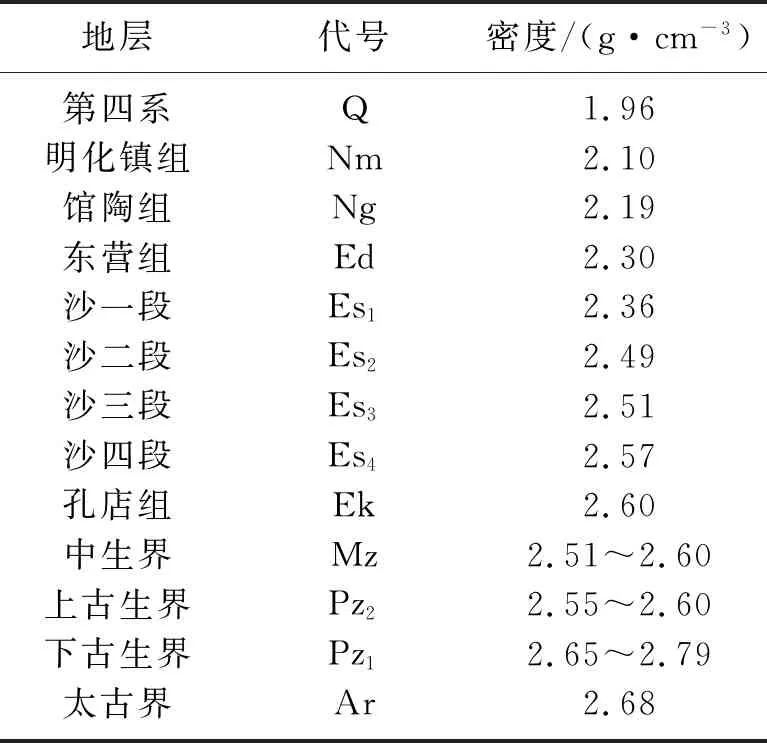
表1 車鎮凹陷地層密度統計表
密度資料顯示,館陶組與東營組、沙一段與沙二段、上下古生界之間存在密度界面。由區域地質背景可知,東營組沉積后,構造運動導致的界面起伏不大,對重力異常形態的影響較小。下古生界起伏變化大,直接影響重力異常形態。下古生界與上覆地層構成的密度界面為主要密度界面,依據地層與潛山的關系,大致可以將該密度界面作為車鎮凹陷的潛山頂界面。該區潛山表現為高密度、高阻抗的特征。相較于潛山,潛山之上地層呈現低密度特征。潛山與上覆地層的密度差最大可達0.18g/cm3,這為利用重力資料研究潛山構造提供了物性基礎[17,33]。
對研究區布格重力異常采用延拓分離法進行場分離,得到剩余布格重力異常(圖6)。由圖可見,重力低值區對應斷陷或凹陷,重力高值區對應基底隆起,相互之間吻合關系較好。重力高值區與低值區之間有較明顯的梯度帶出現,反映凹凸之間為斷裂或者地層產狀突變。

圖6 車鎮凹陷剩余布格重力異常
將重力覆蓋區域剖分成為500m×500m×250m的立方體網格,反演深度為8km,網格總數約為49.5萬個。在x、y、z方向分別設置15、25、8個徑向基函數,共計有3000個,在地下空間均勻分布。初始權重均設為0,重力觀測點為20181個。數據量與徑向基函數數量的比值為ND/NG=6.727。根據研究區地層密度資料,結合剩余布格重力異常的值域范圍,通過多次實驗、分析后確定了剩余密度的下限為-0.75g/cm3。反演得到的三維剩余密度模型如圖7所示,模型的剩余密度范圍為-0.75~0.05g/cm3,與研究區地層密度最大值和最小值的差異范圍基本一致。
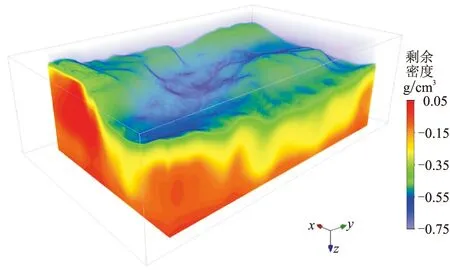
圖7 車鎮凹陷三維剩余密度模型
根據地層密度的統計結果,提取研究區下古生界的密度界面制作下古生界頂面構造圖,如圖8所示。密度界面清晰地反映了車鎮地區下古生界的分布情況,最深處位于大王北洼陷,最淺處位于埕子口凸起西部。研究區兩凸一凹的格局非常清楚,埕子口凸起及義和莊凸起上的洼突分布比較明顯,較低洼處反映為古沖溝。凹陷內不僅各級次洼清晰,凹陷深部的潛山也較清晰。另外,還清晰地顯示了埕南大斷層上的臺階狀斷塊及義和莊凸起北部緩坡帶上的近北東向斷裂。
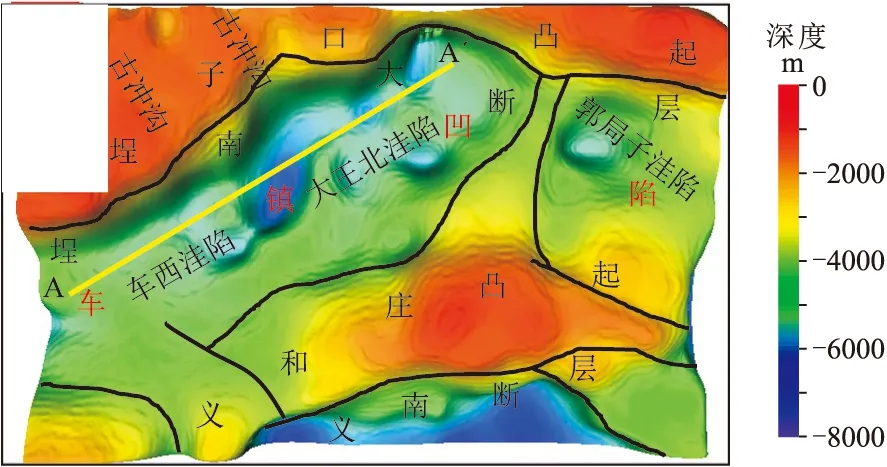
圖8 車鎮凹陷下古生界頂面構造圖黃線為圖9中剖面位置
從三維剩余密度模型中提取剖面與相鄰的地震剖面進行對比(圖9)。由圖可見,實測重力異常與擬合重力異常的誤差非常小,重力高、低值區與構造凸凹之間對應關系很好(圖9a)。地震剖面上(圖9c)新生界成像清晰,且與剩余密度剖面(圖9b)形態對應關系較好。參考地震層位解釋方案,在密度剖面解釋了新生界層位。因為地震剖面為時間域剖面,所以剩余密度剖面的解釋方案與地震解釋方案形態相似但不完全相同。地震剖面上新生界以下的地層成像較差,根據鉆井資料在剖面左側可以解釋下古生界頂界面,而剖面右側則難以解釋。在剩余密度剖面上,可根據密度分布解釋下古生界和太古界頂界面,下古生界頂界面左側與地震解釋方案基本一致,由此推斷右側的解釋方案具有較高的可信度。太古界頂界面在地震剖面上無法識別,剩余密度剖面上所解釋的太古界頂界面雖無法證實,但可作為研究深層目標的參考。

圖9 剩余密度剖面與地震剖面對比(a)實測與擬合重力異常;(b)剩余密度剖面;(c)地震剖面
4 結束語
本文利用高斯徑向基函數作為激活函數,定義了一種結構清晰明確的擬神經網絡,在保證復雜模型表征能力的前提下,降低了重力反演參數的數量,改善了重力反演的不適定性,能夠更充分的利用重力數據所包含的信息,反演結果更客觀。模型實驗表明在無約束或少量先驗信息約束的情況下,本文方法可以獲得較高橫向和垂向分辨率的反演結果。將本文方法應用于車鎮凹陷,得到的剩余密度模型與鉆井、地震資料解釋成果吻合度較高,較好地揭示了該地區下古生界的構造格局與潛山發育規律,檢驗了本文方法反演實測資料的有效性。車鎮凹陷密度模型是在未施加層位和鉆井等強約束信息的情況下反演得到的,證明該方法在低勘探程度區具有較大的實用價值和應用潛力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
