基于專利語義表征的技術預見方法及其應用
2021-11-28 11:55:44賴朝安高晗
中國集體經濟 2021年36期
賴朝安 高晗
摘要:技術預見是支持政府制定產業政策、企業進行戰略布局的重要手段。當前廣泛采用的技術預見方式是基于專家經驗的定性方式,易受到專家水平和觀點的影響,定量分析相比定性分析更加科學準確。文章對Doc2Vec模型進行改進,提出KWE-Doc2Vec模型,使用該模型提取專利摘要的編碼表示,計算得出專利相似度,以此為基礎提出一種技術預見分析框架。并結合自然語言處理領域的發展狀況進行實證研究,識別出該領域的技術發展路徑,對未來的技術機遇進行了預測。
關鍵詞:專利挖掘;技術預見;Doc2Vec;自然語言處理
一、研究背景
技術預見是一項社會系統工程,通過前瞻性戰略研究,對未來的發展中具有重要戰略地位的研究領域做出預測。其綜合了科學、技術、經濟和社會多方面的因素,確定在未來的發展中能給經濟、社會帶來最大化利益的研究領域與技術,對有限資源的優化配置提供相應的決策依據,以期實現經濟與社會利益的最大化。自20世紀90年代以來,無論是英、美等發達國家,亦或是發展中國家,都積極地開展了大量的技術預見活動,儼然已成為世界潮流。這一潮流的形成主要是因為,近年來科學技術的發展呈幾何式增長,人們的生產方式也因此進入了快速而深刻的變革。國家在國際舞臺上的競爭力很大程度上取決于核心科技的掌握以及技術創新的能力。如何快速定位最具發展潛力的領域成為政府和企業關注的核心問題。
目前的技術預見已經形成了一套較為系統的理論體系,通常采用基于專家主觀經驗的定性方法,主要有頭腦風暴法、德爾菲法、同行評議法、專家咨詢法等,這些方式依賴于專家學者的討論,因此其客觀性、科學性往往難以保證,從而導致技術預見結果的可靠性不高。將技術預見與定量的統計學模型相結合,有助于提升技術預見的效率與質量。Lintonnen等在2014年組織芬蘭的43名藥物專家組建了一個德爾菲專家小組,對芬蘭2020年的藥物形式變化趨勢開展了預見研究;王金鵬在2011年研究了在技術預見的過程中引入科學計量方法的必要性,并通過實證分析論證了科學計量方法在技術預見中應用的可行性和有效性;韓毅等利用了基于引文的主路徑方法分析了富勒烯領域的演化結構,證明了主路徑分析方法的獨特性;Yoon等在2010年開發了一個基于關鍵詞的科學地圖,用于制定支持有前景的研發領域的政策和計劃。表1展示了本文采用的研究方法與經典技術預見文獻采用的研究方法的對比。
據研究表明,專利反映了最新的科學技術與商業信息,包含了世界全部科技知識的90%~95%,如果能夠將其中蘊含的知識資源充分利用,識別出核心技術,挖掘其中的潛在價值,在此基礎上進行技術創新活動將會極大地提升創新的成功率。對于專利信息的分析,一方面可以對專利的被引次數、引用關系網絡、創新度或者中心度評估等文獻計量學的視角進行研究。但上述方法對于專利的分析粒度較粗,往往只能得出宏觀上的普遍規律,難以起到具體的戰略指導作用。另一方面,專利的標題、摘要、說明書中有大量的文本內容,對技術的使用場景、具體方案、原理、效果的詳細描述,對于專利中的大量的非結構化數據分析,需要采用文本挖掘的方法,從專利中抽取有價值的知識信息。然而原始的文本內容無法直接參與到數學模型構建過程中,需要將文本轉化為特征向量才能進行各種交互運算。目前較為成熟的專利特征提取方式有基于關鍵詞的分析法(keyword-based-analysis,KWA)以及SAO分析法(Subject-Action-Object)。關鍵詞法本質上是將專利當做詞袋模型進行處理,選取出該領域的關鍵詞,忽略專利文本中的詞語的順序,只記錄關鍵詞出現的次數,以此構建專利的空間向量模型。而SAO分析方法是提取出專利文本中的“主-謂-賓”結構,使用該種結構以及單詞的相似度從而計算出專利之間的相似度。得到專利之間的相似度后,通過專利網絡或者專利地圖進行降維處理,將高維的專利數據映射到二維平面之上,采用可視化的方式展現專利簇中的核心專利以及專利地圖空位,作為技術演進趨勢分析、技術機遇預測的依據。
但是上述兩種文本表征方式都存在著一些不足之處。KWA方法中的關鍵詞往往都是名詞或者名詞詞組,所以這種方法容易損失掉詞語之間的關聯信息,并且忽略語序也會導致語義的偏差,而SAO分析方法也無法表征出特定場景下詞語的含義變化,并且將專利分解成一個個SAO結構,反映的是碎片化的信息,無法從整體上對專利信息做出良好的表征。為了克服上述兩種文本表征方式的缺點,本文采用Doc2Vec算法從專利摘要中提取特征向量,該算法在提取特征時不僅考慮到了詞語的語序,并且摘要中的所有內容都會經過模型的編碼輸出最終的特征向量,包含了摘要中全部的語義信息,能更好地對文本內容做出表達。
二、研究設計
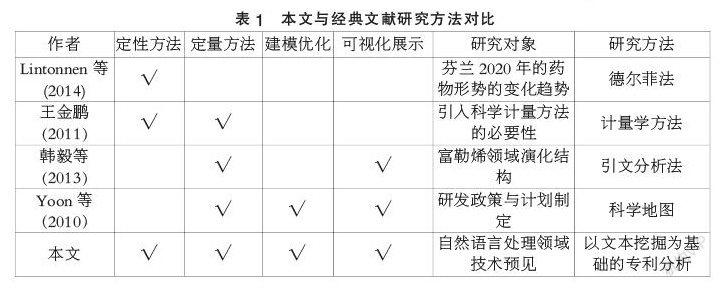
本文的研究路線如圖1所示。首先通過專利平臺收集特定領域的專利數據構建了該領域的專利數據庫,通過KWE-Doc2Vec算法將所有的專利摘要及題目編碼成為固定長度的向量,使用該向量作為專利的表征,以此為基礎計算專利之間的相似度,構建專利的關聯矩陣。然后結合社會網絡學的理論,將高維的專利數據進行降維操作,映射到二維的知識圖譜中。在可視化的圖譜中,可以從海量的專利信息里提取出核心專利,識別技術空位,將其中所蘊含的有價值的信息分析歸納,對自然語言處理領域的發展脈絡、技術路徑以及未來技術機遇做出預測,為政府的產業規劃以及企業的發展戰略制定提供有力的支撐。
文本是一種非結構化的數據,在進行規模較大的文本挖掘任務時,需要將大量的文本數據轉化成為計算機可以直接處理的數字類型的數據。為了對大量數據進行批量的快速處理,往往會對數據格式有更高的要求,需要固定數據的維度。因此提取出專利的合適的表征是本方法的核心部分。本文中使用的Doc2Vec算法是一種無監督的算法,經過在由本文的專利數據庫構建的語料庫訓練后,可以將每一篇專利的摘要提取成特定長度的稠密向量表示,使用該向量表示繼續進行下游的任務。
(一)特征提取算法
Doc2vec算法是受到一些關于使用神經網絡學習詞向量表征的工作啟發,對Word2Vec的模型結構進行簡單改進從而使得模型在學習詞向量的同時可以得到整個段落的向量表征。本文中針對專利數據的特征對普通的Doc2Vec算法進行了改進,提出了附加關鍵詞擴展的KWE-Doc2Vec算法。
1. Word2Vec
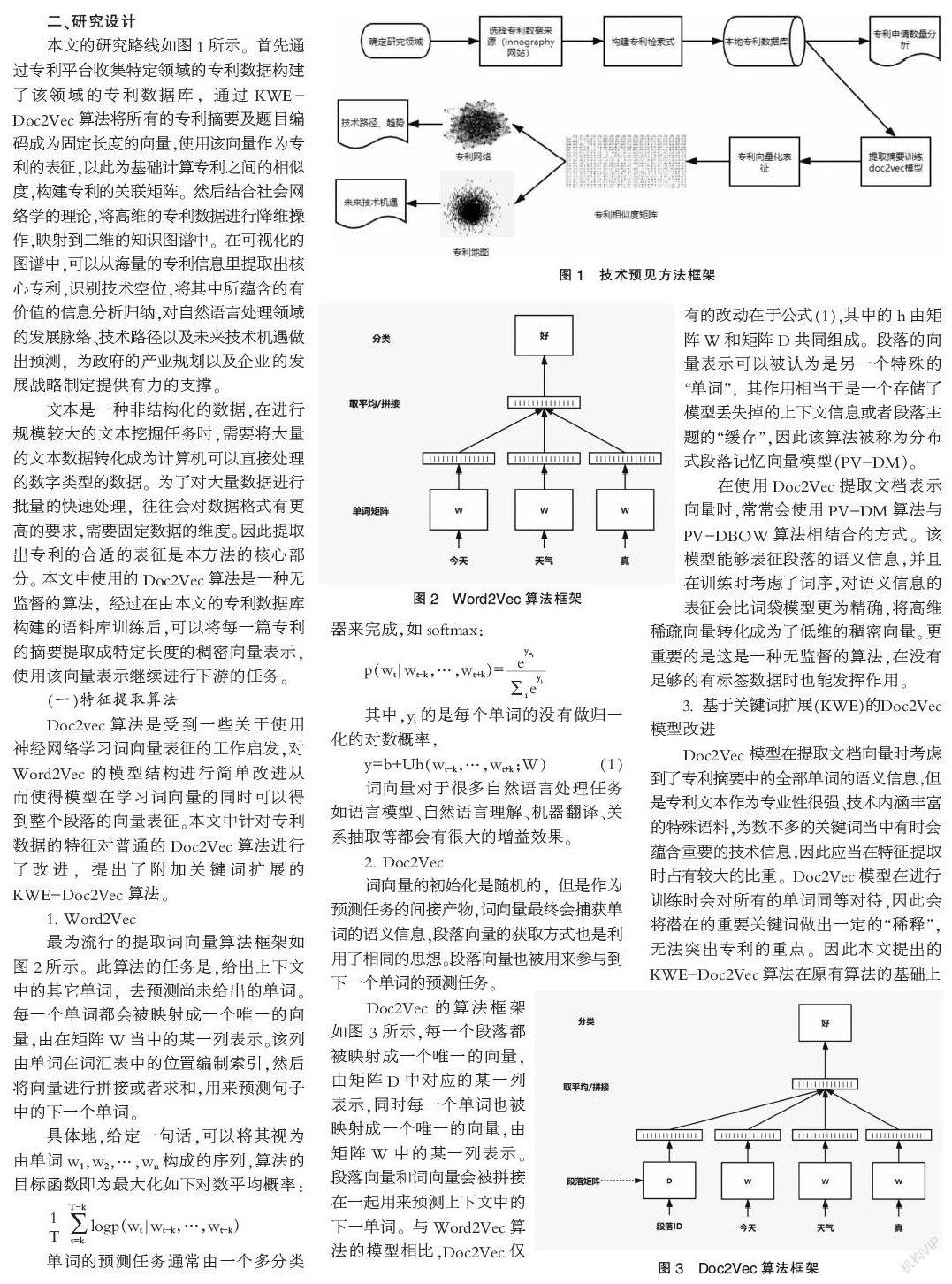
最為流行的提取詞向量算法框架如圖2所示。此算法的任務是,給出上下文中的其它單詞,去預測尚未給出的單詞。每一個單詞都會被映射成一個唯一的向量,由在矩陣W當中的某一列表示。該列由單詞在詞匯表中的位置編制索引,然后將向量進行拼接或者求和,用來預測句子中的下一個單詞。
具體地,給定一句話,可以將其視為由單詞w1,w2,…,wn構成的序列,算法的目標函數即為最大化如下對數平均概率:
詞向量對于很多自然語言處理任務如語言模型、自然語言理解、機器翻譯、關系抽取等都會有很大的增益效果。
2. Doc2Vec
詞向量的初始化是隨機的,但是作為預測任務的間接產物,詞向量最終會捕獲單詞的語義信息,段落向量的獲取方式也是利用了相同的思想。段落向量也被用來參與到下一個單詞的預測任務。
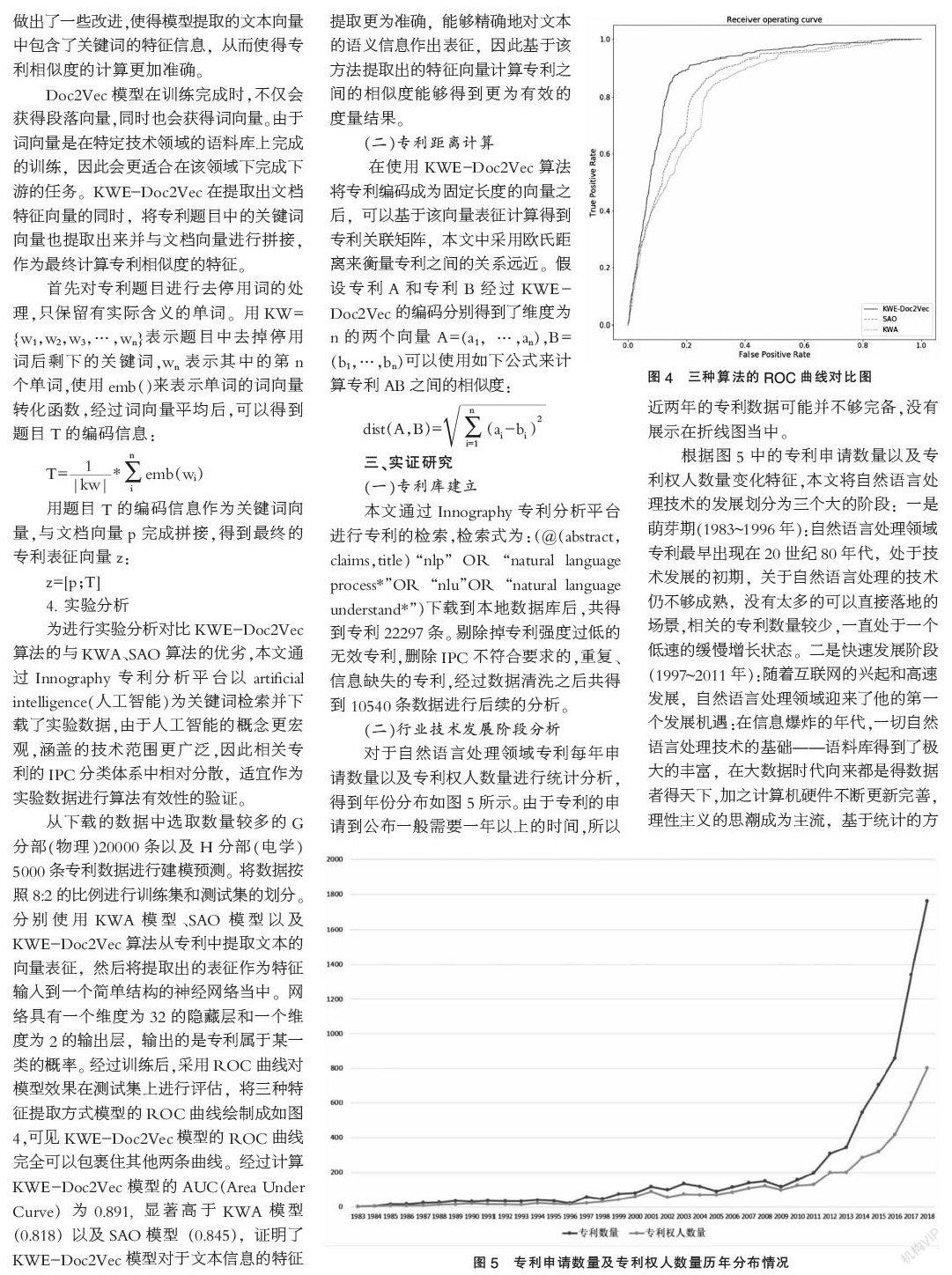
Doc2Vec的算法框架如圖3所示,每一個段落都被映射成一個唯一的向量,由矩陣D中對應的某一列表示,同時每一個單詞也被映射成一個唯一的向量,由矩陣W中的某一列表示。段落向量和詞向量會被拼接在一起用來預測上下文中的下一單詞。與Word2Vec算法的模型相比,Doc2Vec僅有的改動在于公式(1),其中的h由矩陣W和矩陣D共同組成。段落的向量表示可以被認為是另一個特殊的“單詞”,其作用相當于是一個存儲了模型丟失掉的上下文信息或者段落主題的“緩存”,因此該算法被稱為分布式段落記憶向量模型(PV-DM)。
在使用Doc2Vec提取文檔表示向量時,常常會使用PV-DM算法與PV-DBOW算法相結合的方式。該模型能夠表征段落的語義信息,并且在訓練時考慮了詞序,對語義信息的表征會比詞袋模型更為精確,將高維稀疏向量轉化成為了低維的稠密向量。更重要的是這是一種無監督的算法,在沒有足夠的有標簽數據時也能發揮作用。
3. ?基于關鍵詞擴展(KWE)的Doc2Vec模型改進
Doc2Vec模型在提取文檔向量時考慮到了專利摘要中的全部單詞的語義信息,但是專利文本作為專業性很強、技術內涵豐富的特殊語料,為數不多的關鍵詞當中有時會蘊含重要的技術信息,因此應當在特征提取時占有較大的比重。Doc2Vec模型在進行訓練時會對所有的單詞同等對待,因此會將潛在的重要關鍵詞做出一定的“稀釋”,無法突出專利的重點。因此本文提出的KWE-Doc2Vec算法在原有算法的基礎上做出了一些改進,使得模型提取的文本向量中包含了關鍵詞的特征信息,從而使得專利相似度的計算更加準確。
Doc2Vec模型在訓練完成時,不僅會獲得段落向量,同時也會獲得詞向量。由于詞向量是在特定技術領域的語料庫上完成的訓練,因此會更適合在該領域下完成下游的任務。KWE-Doc2Vec在提取出文檔特征向量的同時,將專利題目中的關鍵詞向量也提取出來并與文檔向量進行拼接,作為最終計算專利相似度的特征。
首先對專利題目進行去停用詞的處理,只保留有實際含義的單詞。用KW={w1,w2,w3,…,wn}表示題目中去掉停用詞后剩下的關鍵詞,wn表示其中的第n個單詞,使用emb()來表示單詞的詞向量轉化函數,經過詞向量平均后,可以得到題目T的編碼信息:
用題目T的編碼信息作為關鍵詞向量,與文檔向量p完成拼接,得到最終的專利表征向量z:
z=[p;T]
4. 實驗分析
為進行實驗分析對比KWE-Doc2Vec算法的與KWA、SAO算法的優劣,本文通過Innography專利分析平臺以artificial intelligence(人工智能)為關鍵詞檢索并下載了實驗數據,由于人工智能的概念更宏觀,涵蓋的技術范圍更廣泛,因此相關專利的IPC分類體系中相對分散,適宜作為實驗數據進行算法有效性的驗證。
從下載的數據中選取數量較多的G分部(物理)20000條以及H分部(電學)5000條專利數據進行建模預測。將數據按照8:2的比例進行訓練集和測試集的劃分。分別使用KWA模型、SAO模型以及KWE-Doc2Vec算法從專利中提取文本的向量表征,然后將提取出的表征作為特征輸入到一個簡單結構的神經網絡當中。網絡具有一個維度為32的隱藏層和一個維度為2的輸出層,輸出的是專利屬于某一類的概率。經過訓練后,采用ROC曲線對模型效果在測試集上進行評估,將三種特征提取方式模型的ROC曲線繪制成如圖4,可見KWE-Doc2Vec模型的ROC曲線完全可以包裹住其他兩條曲線。經過計算KWE-Doc2Vec模型的AUC(Area Under Curve)為0.891,顯著高于KWA模型(0.818)以及SAO模型(0.845),證明了KWE-Doc2Vec模型對于文本信息的特征提取更為準確,能夠精確地對文本的語義信息作出表征,因此基于該方法提取出的特征向量計算專利之間的相似度能夠得到更為有效的度量結果。
(二)專利距離計算
在使用KWE-Doc2Vec算法將專利編碼成為固定長度的向量之后,可以基于該向量表征計算得到專利關聯矩陣,本文中采用歐氏距離來衡量專利之間的關系遠近。假設專利A和專利B經過KWE-Doc2Vec的編碼分別得到了維度為n的兩個向量A=(a1,…,an),B=(b1,…,bn)可以使用如下公式來計算專利AB之間的相似度:
三、實證研究
(一)專利庫建立
本文通過Innography專利分析平臺進行專利的檢索,檢索式為:(@(abstract,claims,title)“nlp” OR“natural language process*”OR“nlu”OR“natural language understand*”)下載到本地數據庫后,共得到專利22297條。剔除掉專利強度過低的無效專利,刪除IPC不符合要求的,重復、信息缺失的專利,經過數據清洗之后共得到10540條數據進行后續的分析。
(二)行業技術發展階段分析
對于自然語言處理領域專利每年申請數量以及專利權人數量進行統計分析,得到年份分布如圖5所示。由于專利的申請到公布一般需要一年以上的時間,所以近兩年的專利數據可能并不夠完備,沒有展示在折線圖當中。
根據圖5中的專利申請數量以及專利權人數量變化特征,本文將自然語言處理技術的發展劃分為三個大的階段:一是萌芽期(1983~1996年):自然語言處理領域專利最早出現在20世紀80年代,處于技術發展的初期,關于自然語言處理的技術仍不夠成熟,沒有太多的可以直接落地的場景,相關的專利數量較少,一直處于一個低速的緩慢增長狀態。二是快速發展階段(1997~2011年):隨著互聯網的興起和高速發展,自然語言處理領域迎來了他的第一個發展機遇:在信息爆炸的年代,一切自然語言處理技術的基礎——語料庫得到了極大的豐富,在大數據時代向來都是得數據者得天下,加之計算機硬件不斷更新完善,理性主義的思潮成為主流,基于統計的方法也逐漸替代了基于規則的方法。在這個階段,基于數學和統計模型的方法使得自然語言處理技術取得了一些實質性的突破,已經可以從實驗室走出,走向工業界的實際應用。三是井噴爆發階段(2012年以后):隨著計算機算力的大幅提升,基于深度學習的自然語言處理技術迎來了爆發。有了GPU計算速度的加成,使得RNN、LSTM、GRU等模型的大規模矩陣運算成為可能。深度學習與自然語言處理的結合,在機器翻譯、機器閱讀等細分領域都取得了很大的成功。甚至可以利用深度學習技術將自然語言處理任務進行端到端的訓練,免去了傳統的pipeline方法的麻煩。
(三)關聯矩陣計算
本文提取出所有專利的摘要和標題作為KWE-Doc2Vec模型訓練的語料庫。使用python編程語言調用開源的第三方自然語言處理工具包gensim來進行Doc2Vec模型的訓練,設置模型的迭代次數為100,輸出向量的維度為10,再提取出專利標題的特征向量并進行拼接。使用歐氏距離計算兩兩專利之間的距離,得到專利之間的關聯矩陣。
(四)基于專利網絡的分析
使用可視化網絡分析工具ucinet,對自然語言處理領域的專利數據繪制專利網絡。每個節點的大小代表專利的中心度,即與該專利相連的其它專利數量,中心度越高的專利在圖中的節點越大,通過該指標可以識別專利群中的核心專利。調整專利網絡的距離顯示閾值以及展示節點的中心度閾值,可以畫出自然語言處理領域的專利網絡如圖6。
在自然語言處理技術發展的早期,相關的概念提出較早,但是實驗室中的技術還沒能轉化為可落地的生產力。早期的核心專利主要是一些基礎性的工作,涉及到的多是語法、句法分析,基于規則的方法仍然是主流,有時會輔助以基于統計的方法。該階段的另一大特點是,專利往往以搭載了自然語言處理技術的某種設備或終端的形式展現,主要有微型計算機、顯示器或者音頻交互設備,技術的研究本身并不是目的,最終都是要服務于人,在該階段便初步產生了通過自然語言處理技術進行人機交互的趨勢。直到20世紀90年代中期,得益于計算機運算速度以及存儲設備容量的大幅增加,自然語言處理技術的物質基礎有了極大的改善,同時Internet的商業化進程快速啟動以及網絡技術的發展使得自然語言處理技術所需的語料數據呈現指數級的增長,語料庫技術成為自然語言處理領域較為重要的技術之一。大規模的真實語料,經過不同程度的加工,為研究自然語言的統計學性質提供了必要的基礎,使得該領域的研究方式不用再像以前的那樣,針對少量詞條或者典型句子抽取規則,而是可以采用基于統計的技術方法,從真實的數據中學習規律。同時為某些特定專業領域編制定制化的計算機可用詞典對于下游的自然語言處理任務的提升也是非常之大。另一方面,隨著互聯網的普及,海量的網頁催生了自動檢索技術。并且在這一階段的末期,已經有少量的專利嘗試將深度學習、遷移學習技術應用于自然語言處理任務。根據摩爾定律的描述,處理器的性能每過兩年翻一倍,在2012年后,深度學習這種需要大規模計算能力的技術蓬勃發展,使得自然語言處理技術與深度學習的技術融合成為可能。在這一嶄新的階段,各種網絡結構如CNN、LSTM、GRU在自然語言處理領域的應用層出不窮,并且都取得了不錯的效果,同時將研究者從繁瑣的手工設計、提取特征工作中解放出來。在深度學習基礎上發展出來的預訓練模型,融合了超大規模的語料庫當中的語義信息,相當于為模型注入了類似于人類常識一樣的背景知識。2018年谷歌發布具有劃時代意義的預訓練模型BERT并且刷新了自然語言處理領域的11項任務的最好成績,從此BERT成為各項任務的baseline。另一方面,深度學習技術的引入使得自然語言處理技術的許多應用得以走出實驗室,成為正式的可商用的產品,落地比較成功的應用包括機器翻譯、搜索引擎、對話機器人等。從中可以發現一個較強的趨勢,自然語言處理技術正在迅速與人工智能領域的其它技術如計算機視覺、語音識別、語音合成等技術進行深度的融合交互。谷歌、微軟、Facebook 和百度均擁有能夠讓用戶搜索或者自動整理沒有識別標簽圖片的技術。商業化落地比較成功的對話機器人也已經能夠完成語音識別—自然語言理解—自然語言生成—語音合成的一整套流程,用戶完全可以只通過說話的方式完成與機器人的交互。
自然語言處理領域的技術從早期的專家人工編制規則的處理方式,到基于大量語料數據的統計學方法,以及近期的深度學習技術與自然語言處理相結合,人工參與的程度逐漸降低,模型的學習能力越來越強,可以自動的從大量的真實文本中“學習”到其中蘊含的知識。與此同時,自然語言處理技術也一步步走出實驗室,逐步商業化落地,為技術的發展提供了更多的動力。預計今后在計算力繼續提升的助力之下,一方面,可以將研究方向在商業化的應用的更大范圍的部署到如智能手機、智能家居之上,真正實現萬物互聯,并且可以采用人類語言的方式完成與設備的交互。另一方面,預訓練模型的潛力還未完全開發,采用更大規模、覆蓋面更廣的訓練語料,進行時間更長、迭代次數更多、任務更加困難的訓練,可以使預訓練模型學習到語料庫中更深層次的知識,從而提升下游任務的效果,加速自然語言處理技術的落地。
(五)基于專利地圖的分析
自然語言處理領域的技術日新月異,本文選取井噴爆發期(2012年以后)的專利數據,使用ucinet軟件繪制專利地圖如圖7所示,專利地圖上的空位指示了未來可以挖掘的技術方向,本文識別出6個技術空位,對其周圍的專利進行具體研究分析,可以對該領域的發展趨勢和重要機遇做出預測。
1. 與風險管理領域的深度融合
空位1周圍的專利主要涉及到自動化風險預測、管理的相關技術,包括關于電子合同的潛在風險條款注釋提醒、基于社交媒體的風險預警、對于患者的健康風險自動評估等技術。當前的合規與風險治理領域采用的多是基于專家的主觀經驗的評估,難以將風險進行量化,然而目前的問題是進行風險分析的主要數據為半結構化或者非結構化的,難以對海量的管理信息做出有效評估。因此今后采用自然語言處理技術對非結構化的文本材料進行解析,抽取其中的關鍵信息并且轉化為易于處理的結構化數據,在采用風險評估模型進行預警將是一個極具潛力的研究方向。從上述技術路徑中,采用自然語言處理技術從海量的文本數據中,快速地抽取重要的結構化信息,同時保證其準確性,是該方案的順利施行關鍵,也是未來需要投入大量精力解決的問題。
2. 底層支撐技術的發展為自然語言處理的實現創造機遇
空位2周圍的專利主要涉及到與自然語言處理領域技術相關的底層軟硬件支持。由于音視頻資料中的大量對白或演講等內容包含了大量的知識信息,采用語音識別技術可以從中獲取到大量有價值的語料數據,因此開發支持大規模存儲查詢音視頻數據這類非結構化數據的數據庫系統已成為一個研究的熱點方向,同時也研發能夠精準采集特定場景下的音視頻數據的傳感器從而能夠幫助系統更好地完成上游的數據采集任務。另一方面,進入深度學習時代以后數據量、模型復雜度以及求解模型的計算量都成指數級增長,而GPU作為進行矩陣并行運算的主要硬件,提高其性能也是未來可研究的一個重要方向。
3. 人機對話技術的場景化、個性化,實現互聯
空位3周圍的專利主要涉及到對話機器人、問答系統、智能助手、終端部署設備以及定制化的語料庫設計等相關技術。人機對話技術自其誕生以來就一直是自然語言處理領域的一個重要分支,然而目前的對話系統依然是基于大量的規則以及算法模型,距離真正的智能還有很遠的距離,但是已經可以幫助人們完成一些簡單的任務。因此目前階段為了提升用戶的使用體驗,將對話系統進行場景化、個性化的定制就顯得尤為重要,任務導向型的對話系統因為有明確的目標,所以更加容易引導用戶完成對話。未來可采用定制化的語料庫來完成對話系統的訓練,并且在后端可以連接知識圖譜等數據庫,完成對用戶的特征描述,構建出可以完成“千人千面”的對話系統。另一個值得發掘的研究方向就是將對話系統更多地部署在智能手表、智能家電等終端上,研發與應用場景相適應的嵌入式系統以及高效的無線數據傳輸技術,真正實現萬物互聯。
4. 與人工智能其它領域的交互
空位4周圍的專利主要涉及到基于深度學習的OCR、跨模態數據匹配、圖像自動標注、可視化檢索等相關技術。自然語言處理作為人工智能皇冠上的明珠,從來都不是孤立地發展,與其它領域如計算機視覺、語音識別等都有著深層次的交流。自從2010年后人工智能進入深度學習時代以來,自然語言處理、計算機視覺的整體研究工具和模式都有趨同的跡象,這也就給了不同領域之間直接溝通交流的便利。在現實生活中,文本、圖像、語音等數據都是同時存在的,不可能將其完全割裂開來單獨研究,因此將來對各種模態的數據進行跨模態學習是人工智能發展的一大趨勢。在跨模態學習中,面臨的首要問題即是如何將異質的信息投影到同一個表征空間,還要最大限度的保持數據原有的語義信息,提取到有用的特征。采用深度學習的方式,可以對數據進行各種方向的映射,完成各種來源數據的交互融合,需要研究比單模態數據更加復雜、表達能力更強的模型結構,以期在提取特征的同時保存原有信息。
5. 自然語言處理+具體行業的商業化落地
空位5周圍的專利主要涉及醫學領域的命名實體識別、自動駕駛當中的語音交互、電力需求工單的自動分類等技術。自然語言處理技術的研究本身并不是目的,技術的最終歸宿還是要服務于某個行業,為人類創造價值。用自然語言處理技術為行業賦能,需要準確地找到技術的切入點,要求行業本身具有大量的規范文本數據作為語料庫,并且行業需要是智力密集型的服務行業。自然語言處理技術在金融風控、醫療領域已經有了初步的落地應用,但是目前也只是能夠承擔一些重復性的輔助工作。因此自然語言處理技術與具體行業的結合將會是將來很長一段時間內的熱點趨勢。在自然語言處理技術有了大跨步的進展,真正實現了理解語義并且能夠掌握專業領域知識的情況下,會滲透到教育、司法、交通等更多行業。
6. 更大、更深、更重的模型
空位6周圍的專利主要涉及深度學習模型的定制化損失函數、基于attention機制的語義網絡、基于廣度門的聯合模型回收等技術。可見我們需要表征能力更加強大的模型才能勝任更有挑戰性的任務。由于人類在溝通時都已經是具備了一定的常識或者是某些方面的專業知識,因此在一些簡短的對話或者文本當中可能蘊含著巨大的信息量,然而這些所謂“常識”卻是計算機所不具備或者難以理解的。因此堆疊更深、更復雜的模型,提高模型的表達能力是目前的一個研究趨勢。另外自從2018年谷歌發布了BERT模型之后,自然語言處理領域開啟了屬于預訓練模型的時代。Bert采用Transformer模型的decoder在維基百科等語料庫上進行了大規模的預訓練,采用“博覽群書”的方式讓模型本身具備了一定的背景知識。近年來更是有XLNet、RoBERTa等結構更加復雜、迭代次數更多、語料更加豐富的預訓練模型出現,但這些模型具有數量龐大的參數,訓練和使用成本都極為高昂,在這樣的大背景下,采用更有挑戰性的預訓練任務或者更加合理的模型結構,從而提升模型的表達能力同時降低其使用成本,將是未來一個重要的技術發展方向。
根據以上的技術機遇分析,本文提出如圖8的技術路徑圖。橫軸代表時間,框體的寬度代表了技術的研發周期。任務的研發成本與其研發周期的長度是成正比的。圖中的箭頭表示不同的對象之間的支持關系。
四、結語
21世紀是科學技術飛速發展的時代,在現代化浪潮中要想占據領先優勢,需要具有敏銳的感知力對技術機遇做出準確的預見,這是技術創新的前提和基礎。專利當中蘊含了大量的技術知識,以專利文本挖掘為切入點,可以在短時間內對一個領域的發展脈絡做出梳理,并且預測未來的發展趨勢。本文采用的KWE-Doc2Vec算法可以克服已有方法的缺點,提取出更準確的篇章級別的專利文本內容的向量表征,并基于此向量表征計算專利相似度。然后使用該技術預見方法對自然語言處理領域進行了實證分析,對已有專利的技術演進路徑進行了描述和分析,并且對未來的路徑走向做出了預測。結合生成的專利地圖識別出未來發展的6個技術機遇,提出了自然語言處理領域未來技術路徑圖,為政府的政策制定或相關企業的未來戰略規劃提供了有力的決策支持,同時本文提出的研究方法也可以應用到其它技術領域,為其它研究者提供可供參考的思路。
參考文獻:
[1]吳貴生.技術創新管理[M].北京:清華大學出版社,2000.
[2]Frster B, von der Gracht H. Assessing Delphi panel composition for strategic foresight—A comparison of panels based on company-internal and external participants[J].Technological Forecasting and Social Change, 2014, 84: 215-229.
[3]Lintonen T, Konu A, Rnk?S, et al. Drugs foresight 2020: a Delphi expert panel study[J].Substance abuse treatment, prevention, and policy, 2014, 9(01):18.
[4]王金鵬.基于科學計量的技術預見方法優化研究[D].武漢:華中師范大學,2011.
[5]韓毅,童迎,夏慧.領域演化結構識別的主路徑方法與高被引論文方法對比研究[J].圖書情報工作,2013,57(03):11-16.
[6]Yoon B, Lee S, Lee G. Development and application of a keyword-based knowledge map for effective R&D planning[J]. Scientometrics,2010,85(03):803-820.
[7]Janghyeok Yoon,Kwangsoo Kim. An analysis of property-function based patent networks for strategic R&D planning in fast - moving industries: The case of silicon - based thin film solar cells[J]. Expert Systems with Applications,2012,39(01):7709-7717.
[8]Lee C, Kang B, Shin J. Novelty-focused patent mapping for technology opportunity analysis[J].Technological Forecasting and Social Change,2015,90:355-365.
[9]Yoon J, Park H, Kim K. Identifying technological competition trends for R&D planning using dynamic patent maps: SAO-based content analysis[J].Scientometrics,2013,94(01):313-331.
[10]陳二靜,姜恩波.文本相似度計算方法研究綜述[J].數據分析與知識發現,2017,1(06):1-11.
[11]阮光冊,夏磊.基于Doc2Vec的期刊論文熱點選題識別[J].情報理論與實踐,2019,42(04):107-111+106.
[12]Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781,2013.
[13]Le Q, Mikolov T. Distributed representations of sentences and documents[C].//International conference on machine learning,2014:1188-1196.
[14]徐翼龍,李文法,周純潔.基于深度學習的自然語言處理綜述[A].中國計算機用戶協會網絡應用分會.中國計算機用戶協會網絡應用分會2018年第二十二屆網絡新技術與應用年會論文集[C].中國計算機用戶協會網絡應用分會:北京聯合大學北京市信息服務工程重點實驗室,2018:4.
[15]丁恒,陸偉.基于相關性的跨模態信息檢索研究[J].現代圖書情報技術,2016(01):17-23.
[16]王金鳳,吳敏,岳俊舉,吳漢爭,馮立杰創新過程的技術機會識別路徑研究——基于專利挖掘和形態分析[J].情報理論與實踐,2017,40(08):82-86.
(作者單位:華南理工大學工商管理學院)
