基于機器學習的數據庫系統自動調參研究
2021-11-28 11:56:16陳鐳
軟件導刊 2021年11期
陳 鐳
(1.南京審計大學 信息工程學院,江蘇 南京 211815;2.南京大學計算機軟件新技術國家重點實驗室,江蘇南京 210023)
0 引言
數據庫管理系統(Database Management System,DBMS)在管理大量數據和處理復雜工作的同時,自身也有成百上千個參數(Mysql 有幾百個,Oracle 則有上千個)需要配置,如緩存大小和讀寫磁盤頻率等。DBMS 的性能很大程度上依賴于這些參數的合理設置,但應用程序不能簡單地復用先前配置,最佳配置往往取決于其工作負載和底層硬件。配置參數大多不是獨立的,其間存在復雜的隱式關系,更改一個參數可能會影響另一個參數的最佳設置,如何找到最優參數配置是一個非確定性多項式(NP-hard)問題。因此,數據庫管理人員往往需要花費大量時間根據自身經驗調優數據庫參數。隨著數據庫規模與復雜性的不斷增長,以及工作負載的頻繁變化,數據庫管理人員的優化工作量已經超出其承受能力。
為解決上述問題,利用機器學習技術改進數據庫系統性能成為工業界和學術界的研究熱點。在工業界,Oracle公司于2017 年發布了無人駕駛數據庫,可以根據負載自動調優并合理分配資源;阿里云于2018 年啟動數據庫智能參數優化的探索[1],目前已經在阿里集團10 000 個實例上實現了規模化落地,累計節省12%的內存資源;華為于2019年發布了首款人工智能原生(AI-Native)數據庫,首次將深度學習融入分布式數據庫的全生命周期。在學術界,卡耐基梅隆大學數據庫研究組開發的OtterTune 系統[2]維護了一個調優歷史數據庫,可利用這些數據構建監督和無監督的機器學習模型組合,進而使用這些模型映射工作負載、推薦最優參數等,使DBMS 調優過程完全自動化;Zhang等[3]利用基于策略的深度強化學習方法提出一種端到端的云數據庫調參系統CDBTune,首先從用戶處采集工作負載,然后內置模型,根據當前工作負載狀態推薦參數,并在線下數據庫中執行負載,記錄當前狀態和性能用于訓練離線模型,同時對在線模型進行相應調整。此外,還有大量基于機器學習的數據庫系統綜述研究[4-9]。基于此,本文首先詳細介紹數據庫自動調參系統的結構和工作原理,然后對機器學習模型的應用場景進行分析,最后基于Otter?Tune 系統設計實驗,對PostgreSQL 關系數據庫進行自動化參數調優實驗。
1 數據庫自動調參系統介紹
數據庫自動調參系統通常包含客戶端和服務端兩個部分。客戶端安裝在DBMS 所在機器上,負責收集DBMS的統計信息,并上傳至服務端。服務端一般配置在云服務器上,負責訓練機器學習模型并推薦參數文件,客戶端接收到推薦的參數文件后將其配置到目標DBMS 上,評測其性能,直到用戶對推薦的參數滿意為止。
1.1 客戶端
客戶端通常由控制程序和驅動程序組成。控制程序通過訪問目標數據庫收集DBMS 的各種配置參數和度量(吞吐率、響應時間等)數據;驅動程序則負責實現客戶端的所有控制流,主要與服務端進行交互。
客戶端組件工作流程如圖1 所示,具體為:
(1)驅動程序首先清除緩存并重啟DBMS,檢查磁盤使用量是否過多,確保控制程序可以收集數據。
(2)工作負載生成,驅動程序啟動工作負載,并作為后臺作業運行。當準備開始測量時,驅動程序向控制程序發送一個信號,并等待基準完成。
(3)在測量前,控制程序首先收集旋鈕和度量數據。
(4)完成工作負載測量后,驅動程序向控制程序發送終止信號,控制程序再次收集數據。控制程序將所有收集到的數據以及元數據摘要(數據庫名稱和版本、觀察長度、開始/結束時間、工作負載名稱)發送回驅動程序。
(5)驅動程序將控制程序收集到的所有DBMS 數據上載至服務器,并定期檢查服務器是否已完成推薦的新配置。
(6)如果服務端已成功生成下一個配置,驅動程序將從服務端查詢新配置并將其安裝至目標DBMS。
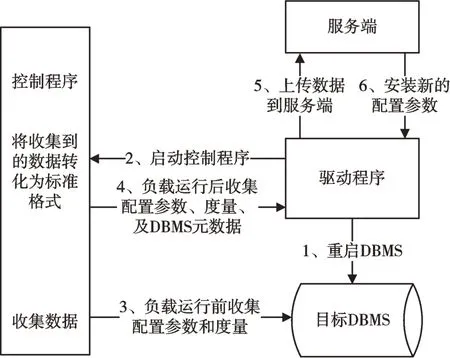
Fig.1 Client side workflow圖1 客戶端工作流程
1.2 服務端
服務端通常由調優管理和作業調度兩部分組成。調優管理負責處理和存儲調優數據,并可視化每個調優會話的結果;作業調度負責計算機器學習模型并提出配置建議。
如圖2 所示,當調優管理從控制器接收到目標DBMS的數據后,首先將這些信息存儲在數據存儲庫中,然后在前端可視化結果。作業調度負責調度任務,以便在機器學習管道中重新計算模型,將新的數據合并到機器學習模型中,計算DBMS 要嘗試的下一個配置。任務完成后,調優管理將任務狀態返回給客戶端,客戶端根據鏈接下載下一個推薦配置。

Fig.2 Server side workflow圖2 服務端工作流程
2 自動調優方法框架
從調優會話中收集到的數據需要使用機器學習模型進行處理,如圖2 中的作業調度模塊所示,數據應用場景為工作負載特征化、特征選擇與自動調優算法。
2.1 工作負載特征化
通常使用DBMS 內部運行時的度量數據描述工作負載行為,因為它們捕獲了數據庫運行時方方面面的信息,能夠提供工作負載的準確表示。然而,不同DBMS 提供的度量具有不同的名稱和粒度,有些度量是重復的,有些度量高度相關。修剪冗余度量能夠減少機器學習算法的搜索空間,降低機器學習模型的復雜性,加速整個調優過程。因此,有必要使用因子分析方法將高維度量指標轉換為低維數據,然后通過聚類算法從每個集群中選擇一個具有代表性的度量,即最靠近集群中心的度量,組成機器學習模型訓練需要的特征向量。
2.2 特征選擇
DBMS 有數百個配置參數,需要找到最能影響其性能的配置參數。使用特征選擇技術(例如lasso)對配置參數的重要性進行排序,可確定哪些配置參數對系統整體性能的影響最大。在提出配置建議時,還需決定使用多少個配置參數。使用過多參數會顯著增加優化時間,過少則會妨礙找到最佳配置。為自動完成該流程,推薦使用遞增的方法,即逐漸增加調優會話中配置參數的數量。
2.3 自動調優算法
自動調優算法需要識別先前調優會話中與當前工作最為相似的負載。首先確保所有度量標準具有相同的數量級,然后計算當前工作負載與存儲庫中歷史工作負載的差異(如歐式距離),差異值越小表示越相似。
典型的自動調優方法包括:①OtterTune 系統采用高斯過程回歸(Gaussian Process Regression,GPR)為工作負載推薦合適的參數,該模型可以預測DBMS 在每種配置參數下的性能,在推薦過程中,需要平衡探索(獲得新知識)和利用(根據現有知識進行決策),否則可能會陷入局部最優而無法達到全局最優;②CDBTune 系統使用深度強化學習算法將數據庫的調參過程刻畫成強化學習問題,狀態即參數文件,動作即調整某個參數的值,而反饋則是當前參數下數據庫的性能。其利用深度確定性策略梯度(Deep Deter?ministic Policy Gradient,DDPG)算法,最終達到了與Otter?Tune 系統近似的調優效果。
3 數據庫自動調優實驗
采用卡耐基梅隆大學數據庫研究組開發的OtterTune系統對PostgreSQL 關系數據庫進行自動化參數調優實驗。
3.1 實驗環境
主機硬件配置:Intel(R)Core(TM)i5-8500U CPU@3.00GHz 處理器,16GB DDR4 內存,240GB SSD 硬盤。Otter?Tune 分為服務端和客戶端兩部分:服務端包含Mysql 數據庫(用于存儲所有網站數據、調優數據,供機器學習模型使用),Django(前端網站);客戶端包含目標DBMS(存儲用戶的業務數據,支持多種DBMS),Controller(用于控制目標DBMS),Driver(用于調用Controller,入口文件為fabfile.py)。
軟件環境搭建步驟為[10-13]:
(1)準備兩臺Ubuntu18.04 的虛擬機,配置均為4 核心CPU,4GB 內存,40G 硬盤。一臺用作服務端,另一臺用作客戶端。
(2)配置好網絡連接。
(3)服務端、客戶端分別下載最新版OtterTune,按照官方配置安裝好必要的軟件包。
(4)OtterTune 需要Python3.6 版本以上配置,而Ubun?tu18.04 系統安裝的是Python2.7 和Python3.6,默認使用Py?thon2.7,因此需要通過ln-s 軟連接命令,修改系統默認使用Python3.6。
3.2 服務端配置
S1:安裝Mysql,新建名為ottertune 的數據庫。
S2:編輯配置文件,修改credentials.py 文件,并更新數據庫名稱、用戶名和密碼等信息,設置DEBUG=True。
S3:配置Django 網站后端,將需要的表放進MySQL 的ottertune 數據庫內。創建Django 網站的超級用戶,在MySQL 的ottertune 數據庫中建立數據表。值得注意的是,website_knobcatalog 和website_metriccatalog 兩個表中存儲了待觀測的信息。
S4:啟動Celery(用于調度機器學習任務)和Django Server,完成后通過瀏覽器打開http://127.0.0.1:8000,在其中建立一個tuning session,并記下upload_code,使用celery beat 啟動周期任務。
3.3 客戶端配置
C1:安裝PostgreSQL9.6(作為目標DBMS),安裝成功后會自動添加一個名為postgres 的系統用戶,密碼隨機,然后在postgres 用戶中新建名為tpcc 的數據庫,供oltpbench 用。
C2:下載最新版OltpBench Repo(數據庫測試框架),同樣存儲在用戶根目錄下。編輯tpcc_config_postgres.xml,配置oltpbench(用于周期性地在目標DBMS 上運行bench?mark)。
C3:配置Controller、Driver,編輯sample_postgres_config.json,driver_config.py,填入目標DBMS 類型、用戶名、密碼、oltpbench 路徑、配置文件等信息。對于save_path 這一項,要事先建立好對應的文件夾;對于upload_code 這一項,要與S4 中分配的upload_code 一致。
C4:加載初始化oltpbench 數據到目標DBMS(Post?greSQL)中。
C5:編譯Controller,執行gradle build。
C6:在完成上述步驟后,開始運行循環程序。在每個循環中收集目標DBMS 信息,上傳至服務端,獲取新的推薦配置,安裝配置并重啟DBMS,直到用戶對推薦的配置滿意為止。在驅動程序文件otertune/client/driver/fabfile.py 中定義loop 函數,fab loop:i=1 表示運行一個單循環,fab run_loops:max_iter=10 表示運行10 次循環,可通過修改命令中的數字更改迭代次數。
3.4 實驗效果
實驗環境配置完成后,通過瀏覽器打開網站主頁,使用S3 步驟設置的超級用戶賬戶進行登錄。登錄成功后首先需要創建一個新的project,然后在項目中創建session。
實驗過程按照“3.2”和“3.3”小節中S1、S2、C1、C2、C3、C4、C5、S3、S4、C6 的順序執行即可。實驗結果如圖3 所示,可以看出session 的參數以及工作負載情況。在剛開始運行時,數據比較少,機器學習模型缺乏足夠的訓練數據,Ot?terTune 傾向于探索而非利用,生成的配置參數可能是隨機的,因此系統的吞吐率較低,為個位數。但當服務端配置到云上,有多個客戶端訪問時,OtterTune 會將所有用戶嘗試的參數文件和對應的性能數據存儲起來進行利用。這意味著用戶越多,使用的時間越長,收集的訓練數據越多,推薦效果就會越好。從圖3 中可以看出,經過10 輪周期的調整,OtterTune 生成的最佳配置使得系統的吞吐率顯著提高,達到了百位數級別,幾乎與數據庫管理人員的經驗配置一樣好。
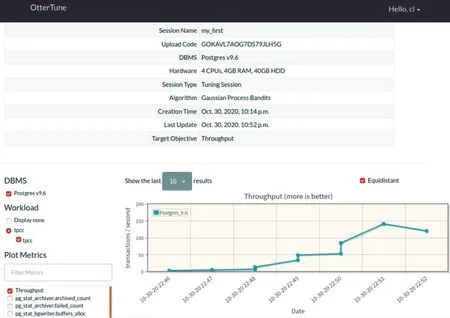
Fig.3 Operation effect of parameter adjustment experiment圖3 調參實驗運行效果
4 結語
本文詳細介紹并采用實驗驗證了基于機器學習的數據庫自動調參系統的原理與運行機制,取得了較佳的配置效果。對于數據庫領域來說,很多配置工作可嘗試與機器學習結合,參數文件調優只是其中一小部分,還可以發展到更核心的部分,如學習型數據庫索引[14]、優化器查詢優化[15]等,可以作為今后的研究方向。此外,由于自動調參系統與數據庫交互的只是一個參數文件,理論上也可以用于其他系統的調參,例如調優操作系統的內核參數,亦可取得不錯效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
核科學與工程(2015年4期)2015-09-26 11:59:03
