融入學習者模型在線學習資源協同過濾推薦方法
2021-11-27 00:48:46劉芳田楓李欣林琳
智能系統學報 2021年6期
劉芳,田楓,李欣,林琳
(1.東北石油大學 計算機與信息技術學院,黑龍江 大慶 163318;2.訥河市第一中學,黑龍江 訥河 161300)
近年來,隨著互聯網技術高速發展,在線教育平臺的使用越來越被學習者所接受,尤其新型冠狀病毒爆發之后,線上學習是在不能正常進行線下學習的情況下優選的學習模式。數據表明,截至2020 年12 月,我國在線教育用戶規模達3.42億,占網民整體的34.6%。該項數據在2020 年3 月時達到高峰,為4.23 億,占比數據為46.8%[1]。面對巨大的在線學習需求,在線教育機構提供免費在線課程,共享在線教學資源,在線教育行業呈現爆發式增長趨勢。然而隨著在線學習平臺的廣泛使用,在線學習資源的數量也急劇增長,在數量龐大的在線學習資源中,學習者很難快速定位自己需要的資源,導致“信息迷航”。
信息推薦是解決用戶從海量對象中迅速有效地篩選出符合自己偏好特征的對象的方法[2]。目前,信息推薦技術被廣泛應用于諸多領域。將信息推薦技術應用到在線教育,實現在線教育過程中學習資源的個性化推薦是解決“信息迷航”問題的一個有效途徑。協同過濾算法是目前信息推薦技術的主流算法,該算法的相關研究工作大多集中在相似度計算和用戶對資源評分的優化上[3]。在相似度計算方面,Wang 等[4]提出了基于Kullback-Leibler 散度的項目相似度計算方法來改進相似度計算,提高推薦準確率;Jiang 等[5]提出了基于Quasi-norm 的用戶相似度計算方法,來提高推薦精度;Mu 等[6]提出了一種改進的Pearson 相關系數的方法改進相似度計算從而改善推薦結果。他們都是通過提高用戶相似性的度量來提高信息推薦的質量。但是協同過濾在應用到學習資源個性化推薦方面,僅靠提高相似度很難提高推薦質量,將學習者這一學習資源推薦的主體與信息資源推薦的用戶相對比,學習者的學習風格、偏好、背景、認知水平等個性化特征更為復雜,學習者的復雜特征對在線學習資源推薦質量影響較大,國內外諸多研究人員對學習者展開研究。Wang等[7]設計了自適應的推薦模型,該模型研究了學習者的興趣偏好特征,并以學習者和學習資源的相關性為依據,挖掘基于本體的學習資源的語義關系;Segal 等[8]將社會選擇特征融入傳統的協同過濾算法,提出了Edu Rank 算法,該算法可適應個性化教學;Zhang 等[9]提出基于本體的語義關系模型,并將協同過濾算法與改模型融合;Aleksandra 等[10]提出采用聚類方法的學習者學習風格模型,并改進矩陣分解方法進行推薦。
學習者是在線學習的參與者,學習資源推薦的個性化程度,直接決定著學習者的學習效果,因此在推薦時不僅要考慮相似度的計算方法的改進,更要研究學習者的個性化特征。個性化的學習者模型的構建是學者們研究的重點[11-13],但大多研究都較集中在學習者行為數據分析、學習資源特征分析、語義特征分析等單一方面,缺乏對學習者整體特征的綜合分析和學習者多維度特征的個性化研究。本文以在線學習平臺中的學習者真實數據為依托,以學習者為中心,提出融合學習者多維度模型的在線學習資源協同過濾推薦方法,優化在線教學學習效果,進一步提高在線教育的個性化程度。
1 多維度學習者模型構建
學習者是在線學習的主體,具有靜態和動態的個性化特征,學習者模型用于描述學習者特征,該模型的構建是提高在線學習資源推薦性能,優化推薦精度,實現個性化推薦的核心。在構建學習者模型時首選要確定學習者的個性化特征,本文依據CELTS-11 學習者信息模型規范[14],以學習風格理論[15]和教育目標分類理論[16]為指導,將學習者特征分為靜態特征和動態特征兩個部分,其中,靜態特征包括學習者基本信息、學習風格和靜態興趣偏好,動態特征包括認知水平和動態興趣偏好。靜態特征是學習者的初始特征,在整個學習過程中不能隨著學習深入而發生變化,不能表示學習者的個性化特征程度,但作為基本特征可以解決初始用戶在推薦過程中存在的冷啟動問題。動態特征是指隨著學習行為的發生,學習者的一些隱含特征逐漸顯現,如學習認知狀態和對某些資源的學習評價等都會隨著時間發生變化,因此動態特征是構建學習者模型的重點。學習者的靜態和動態數據通過采集層進行數據采集,在數據層完成信息歸類,數據分析層將歸類好的信息進行進一步數據挖掘,為表示層的學習風格、認知水平、靜態和動態興趣偏好特征提供數據基礎。學習者模型構建過程如圖1所示。

圖1 學習者模型構建過程Fig.1 Building process of learner model
1.1 數據采集
學習者的初始靜態數據和動態行為數據是構建學習者模型的數據基礎。通過學習者注冊時所填寫的問卷、量表等獲取學習者模型的基本信息、學習風格以及靜態的興趣偏好等特征信息;通過調取學習平臺的章節知識點測評數據和各類學習者行為數據獲取學習者的認知水平和動態興趣偏好特征。通過數據采集層實現基礎數據的獲取與收集,為下一步的歸類分析挖掘以及特征表示做基礎。
1.2 學習風格的特征表示
學習風格的概念是1954 年由美國賽倫首次提出的,它是反應學習者生理、心理等需要的概念,學習風格的研究為學習者模型的個性化要求提供了依據[17]。以Felder-Silverman 風格模型為基礎,以所羅門學習風格量表(index of learning style questionnaire,ILSQ)[18]為手段,將學習者的學習風格從感知、輸入、處理和理解4 個維度進行量化,在數據采集層每一個學習者都要填寫學習風格調查量表,將獲取的ILSQ 量表結果送入數據層和分析層,在表示層構建學習風格特征。
學習風格特征量化的具體流程如下:
1)以四元組

2)學習者填寫ILSQ 量表時,共44 道題,每題包含兩個選項A 和B,答題結果的值定義為Pj,其中j表示題號;
3)根據Pj的結果篩選處理,分類累加,最后的累加結果用a和b表示;
4)對a和b值的大小進行判斷,如果a>b,則Vi=(a?b)a;如果a 5)學習風格特征的測試結果四元組LS則為學習者的學習風格特征量化結果。 學習者的興趣偏好特征分為靜態興趣偏好特征和動態興趣偏好特征。將數據集中的學習資源通過部分人工標注,再將剩余的資源通過相似度計算、最近鄰排序等方法,實現自動標注,最后通過人工查詢相關反饋機制進行校核,保證學習資源特征表示的準確性。以學習資源特征構成的規范化標簽集合為選項,構建靜態興趣偏好問卷,在數據采集層每一個學習者都要填寫靜態興趣偏好問卷,將獲取的結果送入數據層和分析層,在表示層構建靜態興趣偏好特征。 學習者的學習過程是一個動態變化的過程,學習過程中各種操作都會產生相應的行為信息,該信息反映了當前學習者的興趣偏好,本文將隨著時間變化產生的興趣偏好稱為動態興趣偏好[19],具體的量化過程如下: 1)學習者行為分類及權重計算 學習者行為主要分為5 類,即瀏覽行為、收藏行為、分享行為、下載行為以及評價行為,不同的行為所代表的學習者的隱含偏好程度是不同的[20],這里引入權重來表示不同的學習行為的貢獻程度。權重的確定方法有很多種,專家評測或者經驗主義權重具有一定的主觀性,本文采用熵權法確定權重[21]學習者行為分類、權重分布及本文最后采用的權重數值,如表1 所示,其中wi表示第i個行為所占的權重分配。 表1 學習者行為分類及權重分布Table 1 Learner behavior classification and weight distribution 2)學習者?學習資源評分矩陣構建 依據學習行為及其所占的權重分配構建學習者?資源評分矩陣Pm×n,該矩陣可作為學習者對學習資源的評價依據,Pm×n為 Pm×n矩陣中的每個值都表示學習者um對資源in的行為權重,如果su i=0,那么說明學習者uj并未對ik產生任何行為,如果矩陣元素全為0,則說明學習者uj并沒有開始學習。 3)學習資源?學習標簽矩陣構建 為了建立學習者與學習資源標簽的直接關聯關系,首先構建學習資源標簽矩陣來表征學習資源的特征: Qn×l矩陣中的元素rjk表示資源ij是否擁有標簽tk,rjk=1 表示標簽tk標注了資源ij;rjk=0 表示未被標注,因此矩陣Qn×l是一個由0 和1 構成的矩陣。 依據學習者?學習資源評分矩陣Pm×n和學習者?學習資源標簽矩陣Qn×l構建學習者?標簽矩陣Tm×l: 4)學習者動態興趣偏好行為特征表示 學習者的不同行為操作在學習資源上累積可以用動態興趣偏好矩陣Tm×l來表示,學習者對資源的偏好程度體現著學習者之間的差異,這一差異在表征學習者的行為特征屬性時是一個漸增函數,其計算公式為 式中:guk(1 ≤k≤l)是學習者興趣偏好在學習資源上的累加值,是學習者u在關聯資源的標簽tk上不斷累加的行為之和;v是學習者平均興趣偏好值;λ是學習者行為累加和的最小值,用來消除不同學習者間興趣偏好偏差。 5)時間因素調整動態興趣偏好特征的偏移 學習者的興趣偏好特征會隨著學習的深入產生偏移,動態興趣偏好特征的調整包括各類行為的特征表示和時間因素,行為特征采用上述的漸增函數,而時間因素表征了學習者基于時間參數的特征,采用時間衰減函數來進行計算[22]。學習者的動態興趣偏好特征時間因素的計算公式為 式中:tnow為當前時間;表示學習者u被標簽tk標注的時間集合里的最近值;超參數θ∈[0,1]可以影響時間因素對動態興趣特征的計算,二者表現為負相關。 將行為特征和時間權重特征進行綜合,得到學習者的動態興趣偏好特征,即 學習者的認知水平特征描述的是學習者在學習某個知識點之后,對該知識點對應的試題進行測試,獲取的對該知識點的掌握程度。 以“布魯姆教育目標分類理論”為依據,知識點對應的學習資源的學習目標被分為6 個等級(如圖2),這6 個等級代表著不同學習者對核心知識點掌握程度,即認知水平。在學習過程中,采集層的章節知識測試數據代表了績效信息,通過分析章節知識點和試題測試成績,獲取認識水平特征,由于該項指標分為6 個等級,不同的學習者會有不同的整體認知水平,同一個學習者不同時期對于不同的知識點也會有不同的水平狀態,因此認知水平體現著學習者的個性化特征。學習者的認知水平特征表達式為 圖2 學習資源知識點掌握程度的表示方法Fig.2 Representation method of learning resources knowledge points master degree 式中:ki表示第i個知識點;li表示對第i個知識點的掌握程度,即認知水平,n是學已學過的知識點數量。 協同過濾是信息推薦技術中經典的推薦方法[23-26],本文采用協同過濾作為在線學習資源推薦的基本算法,實現基本的推薦,在基本推薦的基礎上融合學習者模型的多維度特征,進行精準推薦。 經典協同過濾技術的推薦過程分成3 個部分:1)收集學習者對學習資源的評分,構建學習者-學習資源評分矩陣;2)學習者-學習資源評分矩陣隱含著學習者對學習資源的興趣偏好,因此可以通過相似度計算求出與被推薦的學習者具有相似興趣偏好的學習者集合,構成K近鄰學習者集合;3)計算K近鄰學習者集合中每個學習者對學習資源的評分,產生被推薦學習者對學習資源的預測評分,按照評分進行排序,產生學習資源推薦集合,在該集合中篩選出沒有被被推薦學習者學習過的Top-N 個資源,這Top-N 個資源就是最后的推薦結果。 冷啟動問題是推薦系統的共性問題,它指的是在面對剛剛進入推薦系統的新學習者時,由于行為數據較少,因此系統無法獲取初始學習者的隱含偏好信息,本文構建的學習者模型的靜態特征可以較好地解決冷啟動問題。在數據采集層通過問卷、量表等方式獲取學習者的學習風格以及靜態的興趣偏好等特征信息,通過加權融合計算學習者靜態綜合特征相似度,按相似度排序構成K近鄰學習者集合,根據K近鄰學習者的學習資源列表完成初始學習者的推薦。 1)靜態興趣偏好特征相似度計算 學習者un的初始興趣偏好標簽個數為q,學習者um的初始興趣偏好標簽個數為p,學習者un和um之間含相同標簽數目為k,相似度計算公式為 2)學習風格特征相似度計算 學習風格包括4 個維度,不同維度的分數值表示為S={s1,s2,s3,s4},將S值標準化之后,利用歐幾里得距離公式計算學習風格距離,其計算公式為 um和un的學習風格相似度計算公式為 3)靜態綜合特征相似度計算 將學習風格特征相似度和靜態興趣偏好特征相似度加權融合形成學習者靜態綜合特征相似度,超參數α∈[0,1]可以影響學習風格和靜態興趣偏好的影響程度,α的具體數值通過實驗統計數據的經驗獲得,靜態綜合相似度計算公式為 為豐富推薦結果的多樣性,提高推薦結果的準確性,在融合靜態特征推薦的基礎上,引入學習資源-學習標簽矩陣,結合基礎協同過濾算法中用到的學習者-學習資源評分矩陣,構建學習者-學習標簽矩陣,更新動態興趣偏好特征。通過分析章節知識點和試題測試成績,獲取認識水平特征,通過計算融合動態興趣偏好特征和認知水平特征的相似度,得到融合學習者動態特征的K近鄰學習者集合,由K近鄰集合得到推薦資源列表的過程與基于協同過濾的方法一致。 1)融合行為特征和時間權重特征的興趣偏好相似度計算 以學習者對學習資源的評分來描述學習者的興趣偏好特征是不全面不準確的,在構建學習者模型動態興趣偏好特征時,融入各類學習行為,再對這些行為加權計算,構建融合行為加權的學習者-學習資源評分矩陣,從而構建學習者-學習標簽矩陣,再融合時間因素,表示學習者動態興趣偏好特征隨著學習行為的持續和時間的深入產生的偏移問題。 融合行為特征和時間特征的興趣偏好特征向量表示為Fu={Fut1,Fut2,···,Futj},學習者um和un之間的相似性可以通過皮爾遜相關系數進行計算,即 式中:Tmn由學習者um和un的興趣偏好標簽的交集構成的標簽集合;Fm,ti和Fn,ti分別表示學習者um和un對標簽ti的興趣特征值;分別表示學習者um和un對集合中所有標簽的平均興趣值。計算學習者的興趣特征值相似度,并按相似度的高低進行排序,構建出與目標學習者興趣特征最為相似的近鄰學習者集合U={u1,u2,···,um,···,uk},這里k為超參數,具體數值通過經驗或實驗驗證給出。 2)融合認知水平特征的相似度計算 將學習者um在已學習過的知識點上的認知水平的集合表示為L(um)={L(um)=(k1um,h1um),(k2um,h2um),···,(kjum,hjum)}。其中,kjum表示學習者um掌握的第j個知識點;hjum表示對第j個知識點的學習者um的掌握程度,即認知水平。使用余弦相似度計算公式計算學習者的認知水平相似度,構建出與目標學習者認知水平特征最為相似的近鄰學習者集合,學習者um和un的認知水平相似度計算公式為 3)學習者動態綜合特征相似度計算 將2 種動態特征相似度加權,計算出學習者的動態綜合特征相似度。設置參數 β調整融合比例,具體計算公式為 以超星為在線學習資源推薦研究依托平臺,《C 程序設計》課程的學習資料為學習資源,東北石油大學《C 程序設計》學習者2020 年3 月到2020 年7 月時間段的學生的真實學習行為為數據開展實驗,數據集中主要有3 類文件:1)學習者特征中的靜態數據文件,包括學生基本信息、學習風格信息和學習興趣信息;2)學習者特征中的動態數據文件,包括知識點測評信息,學習資源瀏覽、收藏、下載、評價和分享行為數據;3)帶有標簽信息的學習資源數據。原始數據經過數據預處理后,共計數據20547 條,學生849 人,學習資源19876 個,其中靜態數據8567 條,動態數據11980 條。將數據集按照4∶1 的比例分為訓練集和測試集進行模型的訓練和測試。 準確率、召回率、F1是常用的用于評價推薦性能的評價標準。準確率是系統推薦給學習者的資源與學習者在測試集上感興趣的資源的交集和系統推薦給學習者的資源的比率,即 召回率是系統推薦給學習者的資源和學習者在測試集上感興趣的資源的交集與學習者在測試集上感興趣的資源的比率,即 式中:R(u)表示推薦產生的學習資源;T(u)表示學習者在測試集上關注的學習資源。隨著學習資源推薦個數的增多,準確率會有所下降,但是召回率有所上升。對測試集所有學習者的上述度量求均值計算平均準確率AP 和平均召回率AR,引入F1值度量整體推薦方法的性能,F1值越大,表示該推薦方法性能越好,F1值計算公式為 本文構建的學習者模型包括靜態特征和動態特征,其中,靜態特征包括靜態興趣偏好特征和靜態學習風格特征;動態特征包括動態興趣偏好特征和動態認知水平特征。從驗證融合學習者特征算法有效性角度出發,首先基于學習者對學習資源的評分矩陣,實現了基于經典協同過濾的推薦。在此基礎上融合各項動靜態特征,本文的經典協同過濾算法采用文獻[2]中的通過構建“用戶-項目”評分矩陣計算用戶相似度,匹配近鄰用戶進行推薦的方法。 1)融合學習者靜態特征實驗分析 基于協同過濾方法,融合學習者靜態特征,在學習資源推薦個數為5、10、15、20、25、30、35 時的準確率、召回率和F1值比較如圖3 所示。通過實驗結果可知,對比于只依靠學習者對學習資源評分矩陣的經典協同過濾推薦,融合了學習者模型的單項的靜態特征會提高整體推薦的性能,但是單項實驗并不會得出哪個特征對推薦結果的影響更大,而且多項特征的融合效果也不會通過單項實驗得到,因此多項特征的融合參數如何選擇也是要解決的問題。 圖3 融合學習者各項靜態特征的推薦性能Fig.3 Recommended performance of integrating learners’various static characteristics 實驗中涉及學習資源推薦個數k的實驗參數和靜態興趣偏好特征與靜態學習風格特征相融合的權重系數α。實驗過程中,先定義推薦的學習資源個數為5 個,再對融合參數α取值從0.1~1 的推薦結果計算準確率和召回率的F1值,如圖4 所示。當α取值為0.6 時F1值最高(見圖4),因此在后續測試結果中令α=0.6,再通過實驗測試對比分析融合靜態興趣偏好特征和靜態學習風格特征在不同學習資源推薦個數情況下的準確率和召回率。 圖4 靜態特征融合參數選擇比較Fig.4 Static feature fusion parameter selection comparison 2)融合學習者動態特征實驗分析 學習者動態特征融合包括學習者動態變化的認知水平和學習者對學習資源持續性的學習體現出的動態興趣偏好特征。通過多次實驗對比分析準確率、召回率和F1值,將時間參數θ、動態特征融合參數β調到最優值,最終在θ=0.2,β=0.7 時,推薦結果最準確。 3)綜合對比分析 綜合對比分析基于協同過濾的推薦、融合學習者靜態特征的推薦和融合學習者動態特征的推薦,從準確率、召回率和F1值3 個角度進行分析,實驗數據如圖5~7 所示。 圖5 不同推薦方法的準確率比較Fig.5 Accuracy comparison of different recommended methods 圖6 不同推薦方法的召回率比較Fig.6 Recall rate comparison of different recommended methods 圖7 不同推薦方法F1 值比較Fig.7 F1 value comparison of different recommended methods 通過綜合對比分析,得出結論:動態特征方面,融合行為特征和時間特征的動態興趣偏好特征對最后推薦結果影響相對較大;靜態特征方面,學習者的興趣偏好特征要比學習者學習風格特征影響大。整體上,融合學習者動態特征的推薦性能優于融合學習者靜態特征的推薦和基于協同過濾的推薦。 目前在線教育學習平臺中存在海量學習資源,然而提供的服務個性化程度卻不高,針對在線學習過程中的“信息迷航”問題,本文以在線學習平臺中的學習資源數據和學習者數據為采集層的基礎數據,通過數據分析和挖掘,構建了多維度的個性化學習者模型。該學習者模型包括學習者靜態特征和學習者動態特征,靜態特征包括學習風格特征和靜態興趣偏好特征,動態特征包括認知水平特征和動態興趣偏好特征。采用協同過濾作為在線學習資源的基礎方法,將學習者靜態特征和動態特征分別融入協同過濾的推薦方法中,通過實驗得到的數據證實,本文構建的學習者模型,以及基于該模型構建的學習資源推薦方法提高了在線學習資源協同過濾推薦的性能。該方法對于滿足個性化學習的需求、提高在線學習的學習效果具有重要意義。1.3 興趣偏好的特征表示







1.4 認知水平的特征表示

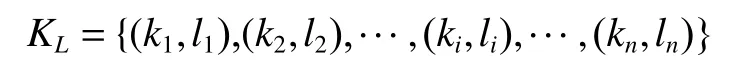
2 融合學習者模型的協同過濾改進
2.1 基于協同過濾的在線學習資源推薦
2.2 融合學習者靜態特征的協同過濾推薦改進




2.3 融合學習者動態特征的協同過濾推薦改進
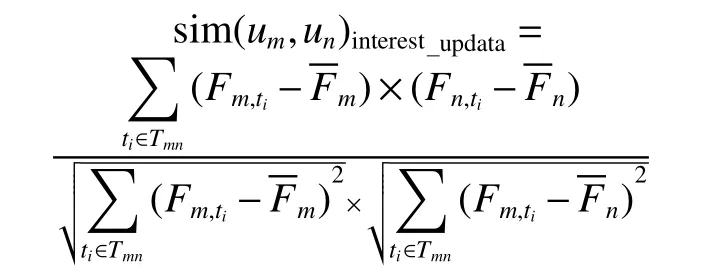


3 實驗結果與分析
3.1 實驗數據集
3.2 評價標準

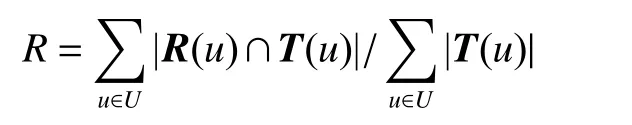
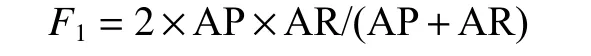
3.3 實驗結果與分析





4 結束語
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
